举例:有10个用户,输出在订单表中下单数最多的5个人的名字。
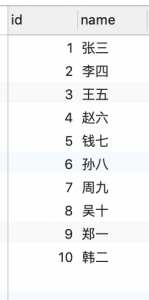
my_user 表数据
my_order,uid对应my_user表的id

测试数据生成
写一个存储过程,随机插入10000条数据:
CREATE DEFINER=root@localhost PROCEDURE test_loop( )
BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
i < 10000 DO
INSERT INTO my_order ( oid, uid )
VALUES
(
CONCAT( 'o_', DATE_FORMAT( now( ), '%Y%m%d%h%i%s' ), FLOOR(1000 + RAND( )*(9999-1000) )),
FLOOR( 1 + RAND( ) * 10 )
);
SET i = i + 1;
END WHILE;
END
查询语句:
SELECT
count( o.uid ) count_num,
u.NAME
FROM
my_user u
JOIN my_order o ON u.id = o.uid
GROUP BY
o.uid
HAVING
COUNT( o.uid )
ORDER BY
COUNT( o.uid ) DESC
LIMIT 5;
查询结果:
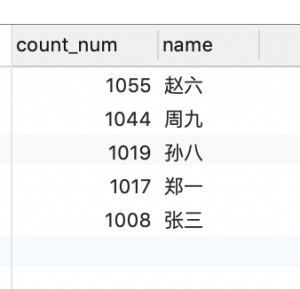
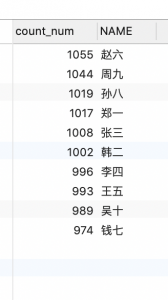
统计所有的用户订单数,结果如下:
SELECT
count( o.uid ) count_num,
u.NAME
FROM
my_user u
JOIN my_order o ON u.id = o.uid
GROUP BY
o.uid
HAVING
COUNT( o.uid )
ORDER BY
COUNT( o.uid ) DESC
该sql 主要考察 group by 和 having 的使用,然后 order by 和 desc 排序。
★sql 的执行顺序如下:
1、FORM: 对FROM左边的表和右边的表计算笛卡尔积,产生虚表VT1。
2、ON: 对虚表VT1进行ON过滤,只有那些符合的行才会被记录在虚表VT2中。
3、JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3。
4、WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中。
5、GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5。
6、HAVING: 对虚拟表VT5应用having过滤,只有符合的记录才会被 插入到虚拟表VT6中。
7、SELECT: 执行select操作,选择指定的列,插入到虚拟表VT7中。
8、DISTINCT: 对VT7中的记录进行去重。产生虚拟表VT8.
9、ORDER BY: 将虚拟表VT8中的记录按照进行排序操作,产生虚拟表VT9.
10、LIMIT:取出指定行的记录,产生虚拟表VT10, 并将结果返回。










![java ee程序设计师_软件设计师:Java EE开发四大常用框架[1]](http://pic.xiahunao.cn/java ee程序设计师_软件设计师:Java EE开发四大常用框架[1])








