常用的几种卷积神经网络介绍
标签(空格分隔): 深度学习
这是一篇基础理论的博客,基本手法是抄、删、改、查,毕竟介绍这几个基础网络的博文也挺多的,就算是自己的一个笔记吧,以后忘了多看看。主要是想介绍下常用的几种卷积神经网络。卷积神经网络最初为解决图像识别问题而提出,目前广泛应用于图像,视频,音频和文本数据,可以当做深度学习的代名词。目前图像分类中的ResNet, 目标检测领域占统治地位的Faster R-CNN,分割中最牛的Mask-RCNN, UNet和经典的FCN都是以下面几种常见网络为基础。
LeNet
网络背景
LeNet诞生于1994年,由深度学习三巨头之一的Yan LeCun提出,他也被称为卷积神经网络之父。LeNet主要用来进行手写字符的识别与分类,准确率达到了98%,并在美国的银行中投入了使用,被用于读取北美约10%的支票。LeNet奠定了现代卷积神经网络的基础。
网络结构
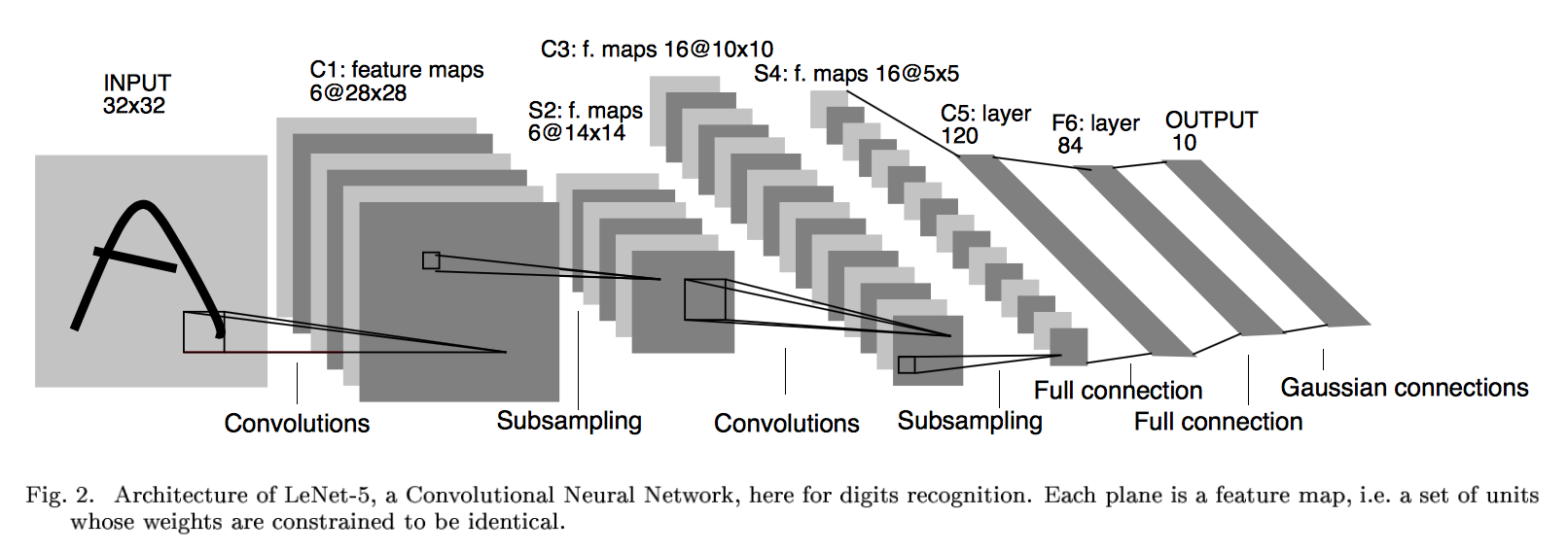
上图为LeNet结构图,是一个6层网络结构:三个卷积层,两个下采样层和一个全连接层(图中C代表卷积层,S代表下采样层,F代表全连接层)。其中,C5层也可以看成是一个全连接层,因为C5层的卷积核大小和输入图像的大小一致,都是5*5(可参考LeNet详细介绍)。
网络特点
每个卷积层包括三部分:卷积、池化和非线性激活函数(sigmoid激活函数)
使用卷积提取空间特征
降采样层采用平均池化
AlexNet
网络背景
AlexNet由Hinton的学生Alex Krizhevsky于2012年提出,并在当年取得了Imagenet比赛冠军。AlexNet可以算是LeNet的一种更深更宽的版本,证明了卷积神经网络在复杂模型下的有效性,算是神经网络在低谷期的第一次发声,确立了深度学习,或者说卷积神经网络在计算机视觉中的统治地位。
网络结构
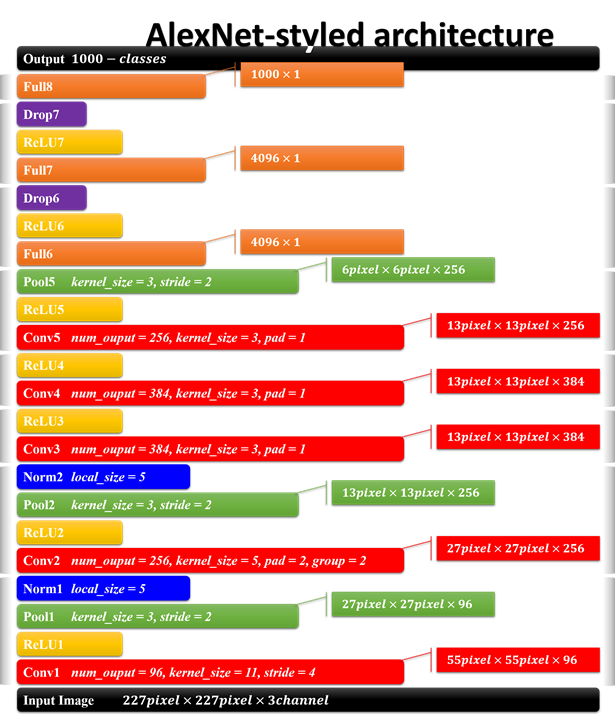
AlexNet的结构及参数如上图所示,是8层网络结构(忽略激活,池化,LRN,和dropout层),有5个卷积层和3个全连接层,第一卷积层使用大的卷积核,大小为11*11,步长为4,第二卷积层使用5*5的卷积核大小,步长为1,剩余卷积层都是3*3的大小,步长为1。激活函数使用ReLu(虽然不是他发明,但是他将其发扬光大),池化层使用重叠的最大池化,大小为3*3,步长为2。在全连接层增加了dropout,第一次将其实用化。(参考:AlexNet详细解释)
网络特点
使用两块GPU并行加速训练,大大降低了训练时间
成功使用ReLu作为激活函数,解决了网络较深时的梯度弥散问题
使用数据增强、dropout和LRN层来防止网络过拟合,增强模型的泛化能力
VggNet
网络背景
VGGNet是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,并取得了2014年Imagenet比赛定位项目第一名和分类项目第二名。该网络主要是泛化性能很好,容易迁移到其他的图像识别项目上,可以下载VGGNet训练好的参数进行很好的初始化权重操作,很多卷积神经网络都是以该网络为基础,比如FCN,UNet,SegNet等。vgg版本很多,常用的是VGG16,VGG19网络。
网络结构
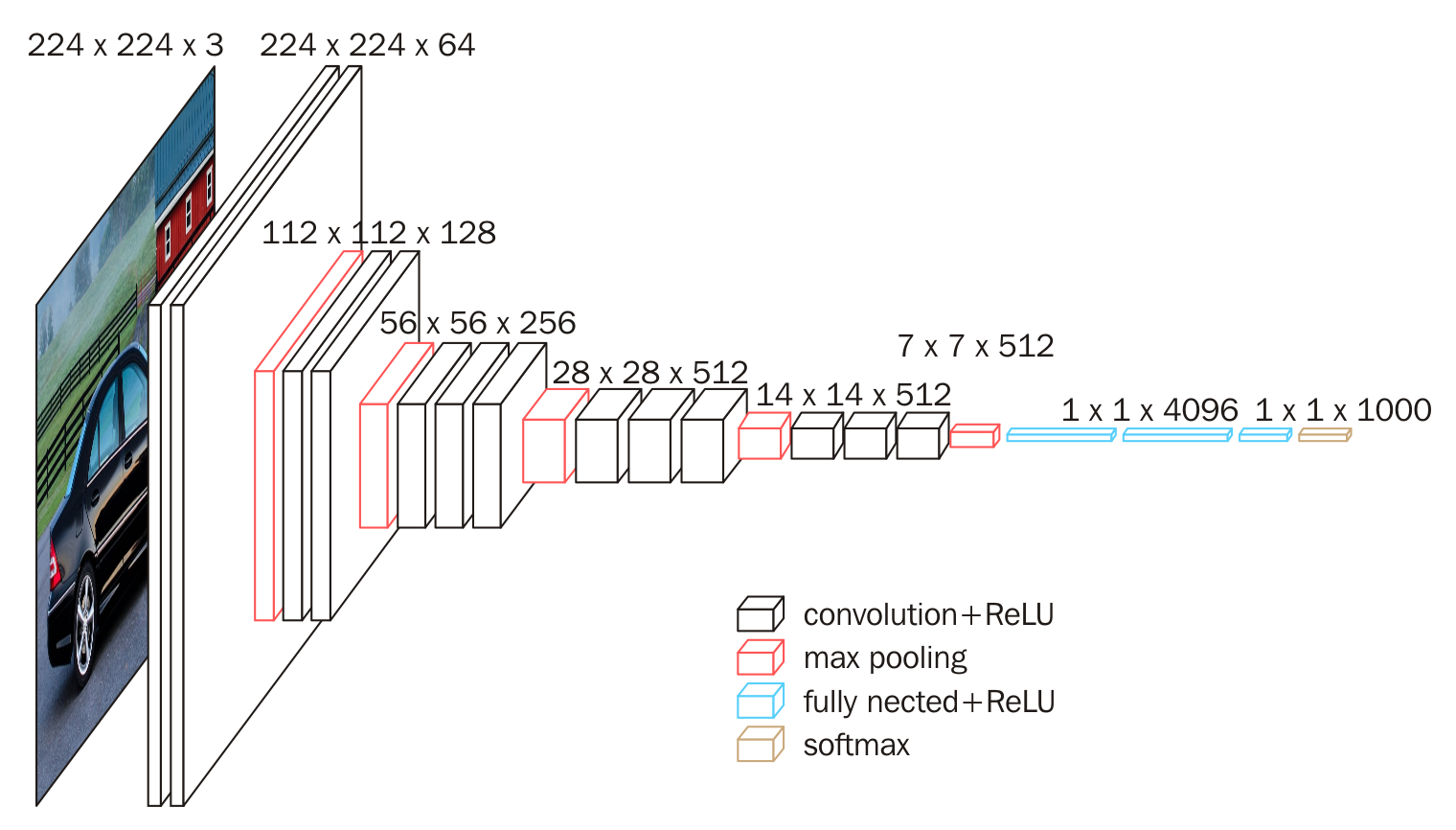
上图为VGG16的网络结构,共16层(不包括池化和softmax层),所有的卷积核都使用3*3的大小,池化都使用大小为2*2,步长为2的最大池化,卷积层深度依次为64 -> 128 -> 256 -> 512 ->512。
网络特点
网络结构和AlexNet有点儿像,不同的地方在于:
主要的区别,一个字:深,两个字:更深。把网络层数加到了16-19层(不包括池化和softmax层),而AlexNet是8层结构。
将卷积层提升到卷积块的概念。卷积块有2~3个卷积层构成,使网络有更大感受野的同时能降低网络参数,同时多次使用ReLu激活函数有更多的线性变换,学习能力更强(详细介绍参考:TensorFlow实战P110页)。
在训练时和预测时使用Multi-Scale做数据增强。训练时将同一张图片缩放到不同的尺寸,在随机剪裁到224*224的大小,能够增加数据量。预测时将同一张图片缩放到不同尺寸做预测,最后取平均值。
ResNet
网络背景
ResNet(残差神经网络)由微软研究院的何凯明等4名华人于2015年提出,成功训练了152层超级深的卷积神经网络,效果非常突出,而且容易结合到其他网络结构中。在五个主要任务轨迹中都获得了第一名的成绩:
ImageNet分类任务:错误率3.57%
ImageNet检测任务:超过第二名16%
ImageNet定位任务:超过第二名27%
COCO检测任务:超过第二名11%
COCO分割任务:超过第二名12%
作为大神级人物,何凯明凭借Mask R-CNN论文获得ICCV2017最佳论文,也是他第三次斩获顶会最佳论文,另外,他参与的另一篇论文:Focal Loss for Dense Object Detection,也被大会评为最佳学生论文。
网络结构
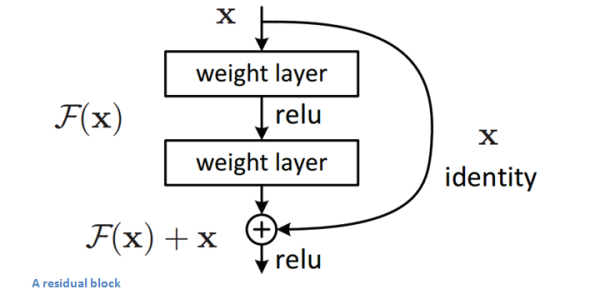
上图为残差神经网络的基本模块(专业术语叫残差学习单元),输入为x,输出为F(x)+x,F(x)代表网络中数据的一系列乘、加操作,假设神经网络最优的拟合结果输出为H(x)=F(x)+x,那么神经网络最优的F(x)即为H(x)与x的残差,通过拟合残差来提升网络效果。为什么转变为拟合残差就比传统卷积网络要好呢?因为训练的时候至少可以保证残差为0,保证增加残差学习单元不会降低网络性能,假设一个浅层网络达到了饱和的准确率,后面再加上这个残差学习单元,起码误差不会增加。(参考:ResNet详细解释)
通过不断堆叠这个基本模块,就可以得到最终的ResNet模型,理论上可以无限堆叠而不改变网络的性能。下图为一个34层的ResNet网络。
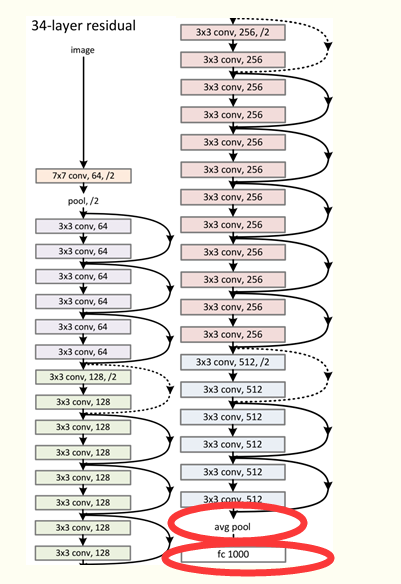
网络特点
使得训练超级深的神经网络成为可能,避免了不断加深神经网络,准确率达到饱和的现象(后来将层数增加到1000层)
输入可以直接连接到输出,使得整个网络只需要学习残差,简化学习目标和难度。
ResNet是一个推广性非常好的网络结构,容易和其他网络结合
论文地址:
1. LeNet论文
2. AlexNet论文
3. VGGNet论文
4. ResNet论文
---------------------
作者:feixian15
来源:CSDN
原文:https://blog.csdn.net/qq_34759239/article/details/79034849
版权声明:本文为博主原创文章,转载请附上博文链接!
爆力)







)


)


)




