TcMalloc 的核心是分层缓存,前端没有锁竞争,可以快速分配和释放较小的内存对象(一般是 256 KB)前端有两种实现,分别是 pre-CPU 和 pre-Thread 模式,前者申请一块大的连续内存,每一个逻辑 CPU 将获得其中的一段。这种模式下 TcMalloc 通过保存额外的元数据来动态地调整每种大小类的实际缓存大小。Per-Thread 模式为每个线程分配一个本地缓存,线程缓存中每种大小类的可用对象通过链表连接。
当前端缓存耗尽时,将会向中端请求新的缓存,中端分为两部分:传输缓存和中央空闲列表。传输缓存可以将其他前端返还给中端的内存快速分配给请求申请内存的前端,如果传输缓存无法满足就会向中央空闲列表申请,中央空闲列表以 Span 为单位管理内存,Span 是一组连续的 TcMalloc 页,Span 通过基数树管理。
当中端缓存耗尽或应用申请较大内存时,需要后端参与,后端一方面会管理一部分已经申请的页面,同时还需要与 OS 交互真正申请和释放内存。后端有两种,传统 pageheap 通过一个 256 位的链表数组管理特定长度的连续页面;Hugepage Aware Allocator 包含三种缓存,可以根据请求的内存大小动态确定使用哪种缓存。
【译】TcMalloc: Thread-Caching Malloc
原文链接
动力
TcMalloc 是一种内存分配器,它作为系统默认分配器的一种替代方案被设计,具有以下特征:
- 快,他可以无竞争地分配和释放大部分的对象。根据模式不同,这些对象是按线程(per-thread)或逻辑 CPU (per-CPU)缓存的。大部分的分配不需要抢占锁,因此在多线程程序中它的锁竞争更少,伸缩性也更好。
- 内存使用更灵活,因为释放的内存可以用于其他不同大小的对象,或返回给操作系统。
- 通过分配拥有相同大小的对象的“页面”来降低每个对象的内存开销。使得对小对象的空间表示更高效。
- 采样开销更低,能够详细地了解应用程序的内存使用情况。
使用
您可以通过将 Bazel 中二进制规则的 Malloc 属性指定为 TCMalloc 来使用它。
概览
下面的框图显示了 TCMalloc 的大致内部结构:

我们可以将 TCMalloc 分为三个组件:前端、中端和后端。我们将在下面的部分中更详细地讨论这些。职责的大致划分如下:
- 前端是一个缓存,为应用程序提供快速的内存分配和回收。
- 中间端负责重新填充前端缓存。
- 后端处理从操作系统获取内存。
请注意,前端既可以在 per-CPU(逻辑 CPU) 模式下运行,也可以在传统的 per-thread 模式下运行,而后端既可以支持巨型页面堆(hugepage),也可以支持传统的页面堆(legacy pageheap)。
TcMalloc 前端
前端处理特定大小的内存请求。前端有一个内存缓存,它可以用于分配或持有空闲内存。该缓存一次只能被一个线程访问,应此不需要任何锁,因此大多数的分配和释放是很快的。
对于任何请求,如果前端有适当大小的内存缓存,它就可以满足。如果特定大小的缓存为空,前端将从中端请求一批内存来重新填充缓存。中端包括 CentralFreeList 和 TransferCache。、
如果中端内存已耗尽,或者请求的大小大于前端缓存所能处理的最大大小,则请求将转到后端,以满足较大的分配,或者重新填充中端缓存。后端也称为 PageHeap。
TCMalloc 前端有两种实现:
- 开始时只支持的 per-thread(每线程)缓存(这也是 TcMalloc 名字的由来)。但是,这会导致内存占用随着线程数量的增加而增加。现代应用程序可能有很多的线程数,这导致要么聚集大量的 per-thread 内存,要么许多线程拥有非常小的 per-thread 缓存。
- 最近,TCMalloc 支持 per-CPU 模式。在这种模式下,系统中的每个逻辑 CPU 都有自己的缓存来分配内存。注意: 在 x86 上,逻辑 CPU 相当于超线程(hyperthread)。
per-thread 和 per-CPU 模式之间的差异完全局限于 malloc/new 和 free/delete 的实现。
小对象和大对象分配
小对象的分配被映射到 60 ~ 80 个可分配大小类中的一个。例如,一个 12 字节的分配将被四舍五入到 16 字节大小类。大小类的设计目的是尽量减少四舍五入到下一个最大大小类时所浪费的内存。
当用 __STDCPP_DEFAULT_NEW_ALIGNMENT__ <= 8 编译时,对于用 ::operator new 分配的原始存储,我们使用一组大小与 8 字节对齐的大小类。对于许多常见的分配大小(24、40 等),这种更小的对齐可以最大限度地减少浪费的内存,否则这些大小将被四舍五入到 16 字节的倍数。在许多编译器上,此行为由 -fnew-alignment=... 标志控制。当没有指定 __STDCPP_DEFAULT_NEW_ALIGNMENT__ 或指定的值大于 8 字节时,对 ::operator new 我们使用标准的 16 字节对齐,然而,对于16字节以下的分配,我们可能会返回一个对齐较低的对象,因为空间中不能分配具有较大对齐要求的对象。
当请求给定大小的对象时,使用 SizeMap::GetSizeClass() 函数将该请求映射到特定大小类的请求,返回的内存来自该大小类。这意味着返回的内存至少与请求的大小一样大。大小类的分配由前端处理。
大于 kMaxSize 大小的对象直接从后端分配。因此,它们不会缓存在前端或中间端。大对象分配请求的大小将被四舍五入到 TCMalloc 页面大小(TCMalloc page size) 。
释放
当对象呗释放时,编译器会提供对象的大小,但如果不知道大小,将会在页面映射中查找。如果对象很小,它会被放回前端缓存。如果大小大于 kMaxSize 它将会被直接返回给 pageheap。
Pre-CPU 模式
在 Pre-CPU 模式下,只会有一个大的内存块被分配。下图展示了这个内存片是如何在 CPU 之间进行分配的以及每个 CPU 如何使用片的一部分来保存元数据以及指向可用对象的指针。
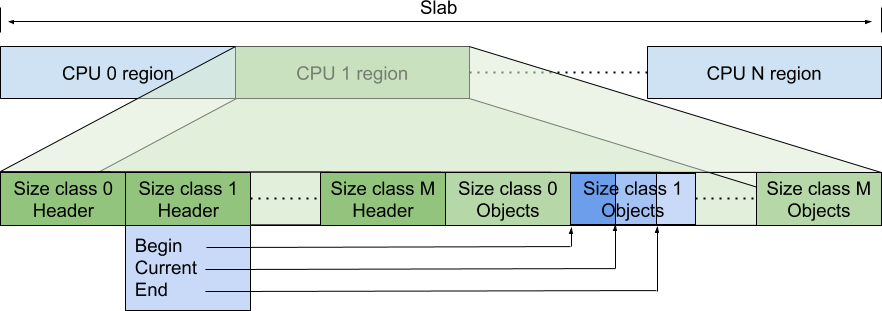
每个逻辑 CPU 都被分配了该内存的一部分,以保存元数据和指向特定大小类的可用对象的指针。元数据包括每个大小类的一个 /header/ 块。header 有一个指向每个大小类数组头部的指针(Begin)以及一个指向当前动态最大容量(End)和该数组段中的当前位置(Current)的指针。每个每个大小类指针数组的静态最大容量在开始时由该大小类的数组的开始和下一个下一个类的数组的开始之间的差确定。
header 有三个指针,Begin 指向当前大小类内存起始位置,Current 指向当前大小类已分配的内存位置,end 指向动态可分配的最大内存地址(动态可分配不是可分配,这部分区域是已经划给当前大小类的,但并不是说大小类只能分配到 End)
在运行时,可以存储在每个 CPU 块中的特定大小类的最大条目数量会有所变化,但它永远不会超过启动时静态确定的最大容量。
当请求特定大小类的对象时,将从该数组中删除该对象,当释放该对象时将其添加到数组中。如果数组耗尽,则使用中端的一批对象重新填充数组。如果数组溢出,则从数组中删除一批对象并返回到中端。
每个 CPU 可以缓存的内存量由参数 MallocExtension::SetMaxPerCpuCacheSize 限制。这意味着缓存的内存总量取决于活跃的每个 CPU 中缓存的数量。因此,具有更多 CPU 数量的机器可以缓存更多的内存。
为了避免不长时间运行程序的 CPU 占用大量内存,MallocExtension::ReleaseCpuMemory 会释放保存在指定 CPU 缓存中的对象。
在 CPU 中,内存的分布是跨所有大小类管理的,以便使缓存的最大内存量低于限制。注意,它管理的是可缓存的最大数量,而不是当前缓存的数量。平均而言,实际缓存的量应该是限制的一半左右。
当某一大小类的对象耗尽时,该大小类的容量会增加。同时,当申请较多对象时,也会考虑增加该大小类的容量。我们可以扩大某一大小类的容量直到总缓存占用达到每个 CPU 的限制或某一大小类的容量达到该大小类硬编码的限制。如果大小类没有达到硬编码的限制,那么为了增加容量,它可以从同一 CPU 上的另一个大小类窃取容量。
可重启序列和 Pre-CPU TCMalloc
为了正确工作,Pre-CPU 模式依赖于可重启序列(man rseq(2))。可重新启动序列只是(汇编语言)指令块,很大程度上像一个典型的函数。可重启序列的一个限制是它们不能将部分状态写入内存,最终指令必须是更新状态的单次写入。可重启序列的想法是,如果一个线程在执行可重启序列时从 CPU 中换出(例如上下文切换),该序列将从从头开始执行。因此,序列要么不间断地完成,要么反复重启,直到它不间断地完成。这是在不使用任何锁定或原子指令的情况下实现的,从而避免了序列本身的任何竞争。
这对 TCMalloc 的实际意义是,代码可以使用可重启的序列(如 TcMallocSLab_Internal_Push)从每个 CPU 数组中获取元素或将元素返回到该数组,而不需要锁定。可重新启动序列可以确保在不中断线程的情况下更新数组,或者在线程中断时重新启动序列(例如,通过上下文切换,允许在该 CPU 上运行另一个线程)。
关于设计选择和实现的其他信息将在特定的设计文档中进行讨论。
传统的 Per-Thread 模式
在 Per-Thread 模式中,TCMalloc 为每个线程分配一个线程本地缓存。这个线程本地缓存满足较小的分配。根据需要,将对象从中端移动到线程本地缓存中或从线程本地缓存中移出。
一个线程缓存包含每个大小类的一个空闲对象列表的单独的链表(所以如果有 N 个大小类,就会有 N 个相应的链表),如下图所示。

在分配时,将从对应大小类链表中删除一个对象,释放时,将会将对象插入到链表头部。可以访问中端以获取更多对象和返回一些对象到中端来处理下溢或溢出。
每个线程缓存的最大容量是由参数 MallocExtension::SetMaxTotalThreadCacheBytes 设置的。但是,总大小可能会超过这个限制,因为每个线程缓存的最小大小 KMinThreadCacheSize 通常是 512KiB。如果一个线程希望增加它的容量,它需要从其他线程中窃取容量。
当线程退出时,他们的缓存内存将返还给中端。
前端缓存的运行时大小
对前端缓存空闲列表的大小进行优化调整非常重要。如果空闲列表太小,我们将需要经常访问中端空闲列表。如果空闲列表太大,我们将浪费内存,因为对象在其中处于空闲状态。
请注意,缓存对于回收和分配的重要性是一样的。如果没有缓存,每次释放都需要将内存移动到中央空闲列表(Central free)。
Pre-CPU 和 Pre-Thread 模式有不同的动态缓存大小算法的实现。
- 在 Pre-Thread 模式中,每当需要从中间端获取更多对象时,可以存储的最大对象数量都会增加到一个限制。同样,当我们发现缓存了太多对象时,容量也会降低。如果缓存对象的总大小超过每个线程的限制,缓存的大小也会减小。
- 在 Pre-CPU 模式中,空闲列表的容量增加取决于我们是否在下溢和上溢之间交替(这表明更大的缓存可能会停止这种交替)。当容量一段时间没有增长,因此可能会出现容量过剩时,就会减少容量。
TcMalloc 中端
中端负责向前端提供内存并将内存返回给后端。中端包括 传输缓存 (Transfer Cache) 和 中央空闲列表(Central free list)。虽然它们通常写作单数,但每个大小类都有一个传输缓存和一个中央空闲列表。这些缓存都由互斥锁保护 —— 因此访问它们需要序列化代价。
传输缓存
当前端申请或返还内存时,它将接触到传输缓存。
传输缓存持有一个指向空闲内存指针的数组,他可以快速地将对象移动到这个数组中或者代表前端从此数组中获取对象。
传输缓存得名于这样一种情况: 一个 CPU(或线程) 分配到由另一个 CPU(或线程) 释放的内存。传输缓存允许内存在两个不同的 CPU(或线程) 之间快速流动。
如果传输缓存无法满足内存请求,或者没有足够的空间来保存返回的对象,它将访问中央空闲列表。
中央空闲列表
中央空闲列表以 span 为单位管理内存,一个 span 是一个或多个 “TCMalloc 内存页” 的集合。这些术语将在接下来的几节中进行解释。
对于申请一个或多个对象的请求,中央空闲列表会不断通过向 Span 获取对象直到该请求被满足。如果 span 中没有足够的可用对象,则会向后端请求更多 span。
当对象返还到中央空闲列表时,每个对象被映射并释放到它所属的 span (使用页面映射 Pagemap )。如果驻留在特定 span 中的所有对象都返还给了它,则整个 span 返还给后端。
Pagemap 和 span
由 TCMalloc 管理的堆被分为多个页,其大小由编译时确定。连续页面的运行由一个 Span 对象表示。一个 Span 可以用于管理交付给应用程序的大对象,也可以作为已经被拆分成一系列小对象的页运行。如果 span 管理的是小对象,则 span 中会记录对象的大小类。
pagemap 用于查找对象所属的 span 或标识给定对象的大小类。
TCMalloc使用两层或三层的 基数树 radix-tree 将所有可能的内存位置映射到 span 上.
下面的图显示了如何使用两层 radix-tree 将对象的地址映射到控制对象所在页面的 span 上。在图中,span A 涵盖两页,span B 涵盖三页。
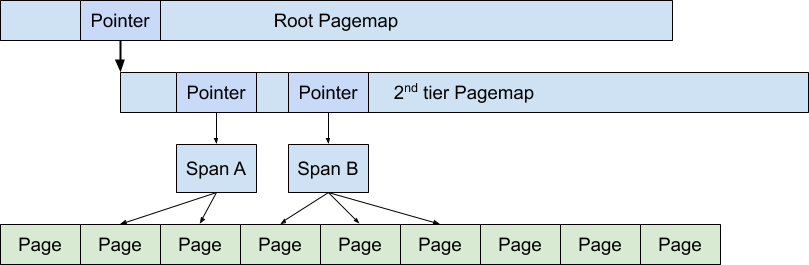
span 在中端用来确定将返回的对象放在哪里,并在后端用来管理页面范围的处理。
在 span 中存储小对象
span 包含一个指向 TcMalloc span 控制页面基地址的指针。对于小对象,这些页面最多分为 2162^{16}216 个对象。选择这个值是为了在 span 内通过两个字节的索引引用对象。
这意味着我们可以使用松散链表来保存对象。例如,如果我们有 8 个字节的对象,如果我们有八个字节的对象,我们可以存储三个随时可用的对象的索引,并使用第四个槽来存储链中下一个对象的索引。这种数据结构减少了全链接列表上的缓存丢失。
使用两个字节索引的另一个好处是,我们可以使用 span 本身的空闲容量来缓存四个对象。
当某大小类没有可用对象时,需要从页面堆中获取一个新的 span 并填充它。
TCMalloc 页大小
可以使用不同的页大小构建 TCMalloc。请注意,这些与底层硬件的 TLB 中使用的页面大小不对应。TCMalloc 的页面大小目前为 4KiB、8KiB、32KiB 和 256KiB。
TcMalloc 的页可以容纳特定大小的多个对象,也可以作为容纳超出单个页大小的对象的一组页面的一部分。如果整个页面空闲了,它将被返还给后端。以后可以重新利用它来保存不同大小的对象(或返回到操作系统)。
较小的页面能够以较少的开销更好地处理应用程序的内存需求。例如,使用了一半的 4KiB 页面将剩余 2KiB,而32KiB 的页面将剩余 16KiB。小页面也更有可能变得空闲。再例如,4KiB 页可以容纳 8 个 512 字节的对象,而32KiB 页可以容纳 64 个对象;64 个对象同时空闲的可能性比 8 个对象空闲的可能性要小得多。
大页面减少了从后端获取和返回内存的需要。单个 32KiB 页面可以容纳 8 倍于 4KiB 页面的对象,这可能会导致管理较大页面的成本较小。映射整个虚拟地址空间所需的大页面也更少。TCMalloc 有一个页面映射,它将虚拟地址映射到管理该地址范围内的对象的结构上。较大的页面意味着页面映射需要较少的条目,因此较小。
因此,对于内存占用小的应用程序,或者对内存占用大小敏感的应用程序,使用较小的 TCMalloc 页面大小是有意义的。占用较大内存的应用程序可能会受益于较大的 TCMalloc 页面大小。
TcMalloc 后端
TcMalloc 后端干三件事:
- 管理未使用的大块内存。
- 当没有合适大小的内存来满足分配请求时,它负责从操作系统获取内存。
- 它负责将不需要的内存返回给操作系统。
TcMalloc 后端有两种:
- 管理 TcMalloc 中 page 大小内存块的 Legacy pageheap (传统页堆)
- 以 hugepage 大小为单位管理内存的 hugepage aware pageheap(超大页感知分配器)。以 hugepage 为单位管理内存,使分配器能够通过减少 TLB 未命中来提高应用程序性能。
Legacy pageheap
传统页堆是一个可用内存中连续页面的特定长度的空闲列表的数组。当 k < 256 时,它的第 k 个节点就是一个由 k 个 TcMalloc 页组成的空闲运行列表。第 256 个节点是长度大于 256 页的空闲运行列表。
大白话就是 Legacy pageheap 是一个长度为 256 的数组,数组每一位保存一个可用内存的链表,链表的每个节点都是连续的 i 个 TcMalloc 页。i 由链表在数组中的位置决定,大于 255 的 i 都保存在数组最后一位。
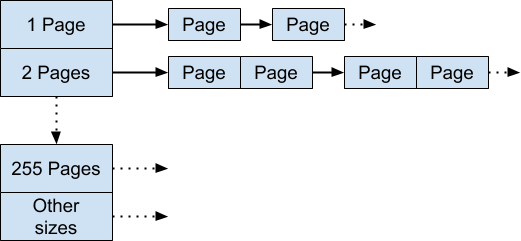
我们可以通过查找第 k 个空闲列表来满足 k 个页面的分配。如果那个空闲列表是空的,我们就查找下一个空闲列表,依此类推。最后,如果需要,当我们查找到最后一个空闲列表依然失败时,我们将通过系统的 mmap 获取内存。
如果长度大于 k 的页面满足了对 k 个页面的分配,则结点剩余的部分将被重新插入到适当的空闲列表中。
假设要申请两个页面,但第二条空闲列表空了,第三条列表中每个节点有三个页面,分配掉两个后,余下一个会被插入到第一条列表中
当向页面堆返回一定范围的页面时,将检查相邻的页面,以确定它们现在是否形成了一个连续的区域,如果是这样,则将这些页面连接起来并放置到适当的空闲列表中。
尽量减少碎片
Hugepage Aware Allocator
Hugepage Aware Allocator 的目标是将内存保存在 hugepage 大小的块中。在 x86 上,一个 hugepage 的大小是 2MiB。为此,后端有三个不同的缓存:
-
填充缓存(filler cache)保存已从其分配了一些内存的 hugepage。可以认为这类似于 Legacy pageheap ,因为它保存特定数量的 TCMalloc 页的内存链表。(通常)从填充缓存返回对小于 hugepage 大小的大小的分配请求。如果填充缓存没有足够的可用内存,它将请求额外的 hugepage 来分配。
-
区域缓存(region cache),用于处理大于一个 hugepage 的分配。这个缓存允许跨多个 hugepage 的分配,并将多个这样的分配打包到一个连续的区域中。这对于稍微超过一个大页面大小的分配尤其有用(例如,2.1 MiB)。
Essentially, the path of an allocation goes like this:(本质上,分配思路是这样的:)
-
If it is sufficiently small and we have the space we take an existing, backed, partially empty hugepage and fit our allocation within it.(如果它足够小,并且我们有足够的空间,我们就使用一个现有的、有支持的、部分空的 hugepage,并将我们的分配放在其中。)
-
If it is too large to fit in a single hugepage, but too small to simply round up to an integral number of hugepages, we best-fit it into one of several larger slabs (whose allocations can cross hugepage boundaries). We will back hugepages as needed for the allocation.(如果它太大了,不能放在一个 hugepage 中,但又太小了,不能简单地四舍五入到一个整数 hugepage,那么我们最好把它放在几个更大的 slab 中(它们的分配可以跨越 hugepage 边界)。我们将根据分配的需要支持 hugepage。)
-
Sufficiently large allocations are rounded up to the nearest hugepage; the extra space may be used for smaller allocations.(足够大的分配被四舍五入到最近的 hugepage;额外的空间可用于较小的分配。)
-
-
hugepage 缓存处理至少一个 hugepage 的大量分配。与区域缓存的使用有重叠,但区域缓存仅在确定(在运行时)分配模式将使其受益时才启用。
有关 HPAA 的设计和选择的其他信息在其特定设计文档中进行讨论。
注意事项
TCMalloc 将在启动时为元数据保留一些内存。元数据的数量将随着堆的增长而增长。特别是,页面映射将随着TCMalloc 使用的虚拟地址范围而增长,span 将随着内存的活动页面数量的增长而增长。在 pre-CPU 模式下,TCMalloc 将为每个 CPU 保留一个内存片(通常为 256 KiB),这在具有大量逻辑 CPU 的系统上可能会导致几兆字节的占用空间。
值得注意的是,TCMalloc 以大块(通常为 1 GiB 区域)的形式向操作系统请求内存。地址空间是保留的,但在使用之前不会得到物理内存的支持。由于该方法,应用的 VSS 可以比 RSS 大得多。这样做的一个副作用是,在应用程序使用了那么多物理内存之前,试图通过限制 VSS 来限制应用程序的内存使用将会失败很久。
不要试图将 TCMalloc 加载到运行的二进制文件中(例如,在 Java 程序中使用 JNI)。二进制文件将使用系统 Malloc 分配一些对象,并可能尝试将它们传递给 TCMalloc 以进行释放。TCMalloc 将无法处理此类对象。










)





临时数据库(tempdb))


