pandas核心数据结构
pandas是以numpy为基础的,还提供了一些额外的方法
Series
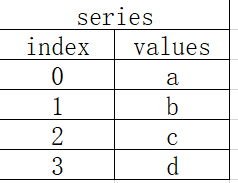
series用来表示一维数据结构,与python内部的数组类似,但多了一些额外的功能。
series内部由两个相互关联的数组组成:主数组用来存放数组,可以是numpy中的任意数据类型;另一个数组用来存放索引,索引默认从0开始。朱数组中每个元素又有一个与之关联的索引。
创建series对象
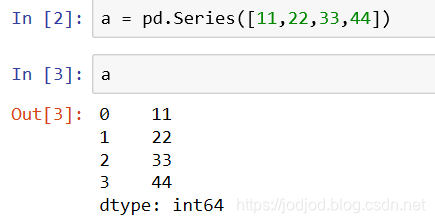
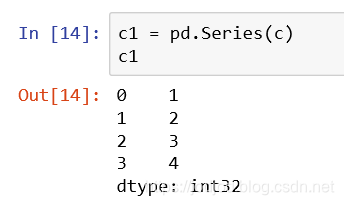
1、通过series的构造方法,参数为数组
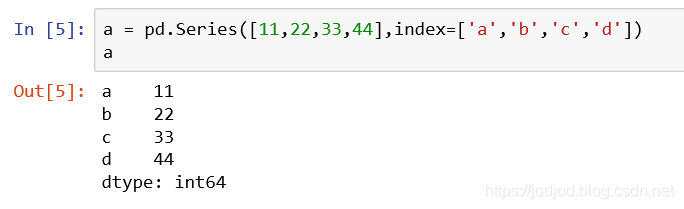
通过参数index也可以指定索引
2、也可以通过传入ndarray创建series
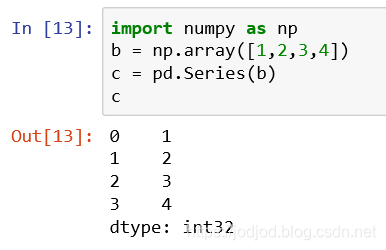
注意:此时修改series中元素会对原ndarray有影响
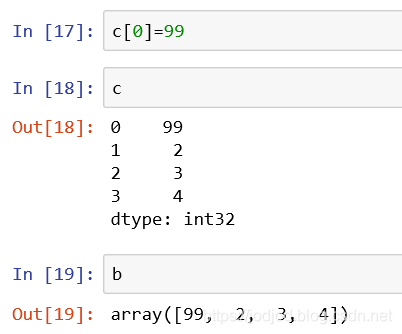
3、还可以传入一个series对象,会返回一个新的series对象但仍指向同一地址
注意:此时修改series中的对象会对原series产生影响

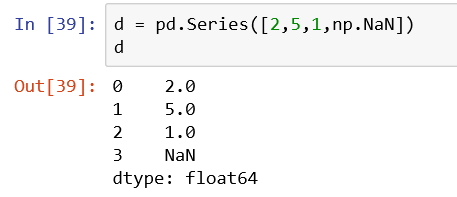
4、可以传入空类型np.NaN对象
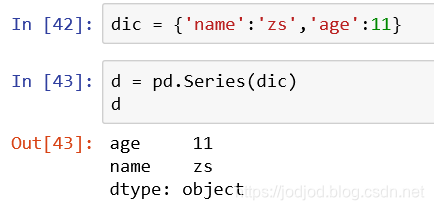
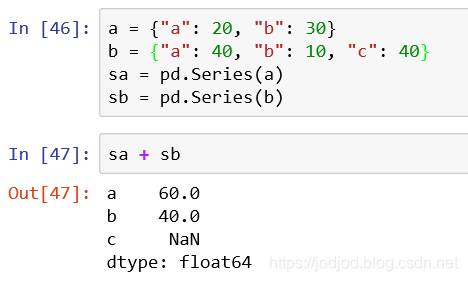
5、传入字典
在series的构造函数中传入一个字典,那么字典的key则为index,value为series的values元素
series对象的属性与方法
1、查看series的索引和值

2、series的长度
3、获取不重复的series
通过调用series对象的unique()方法返回一个无重复元素的series

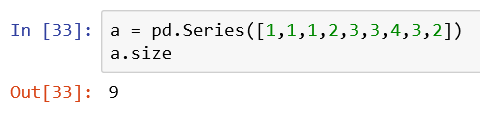
4、统计重复元素出现的次数
series对象的value_counts()会返回一个统计了元素-次数的series
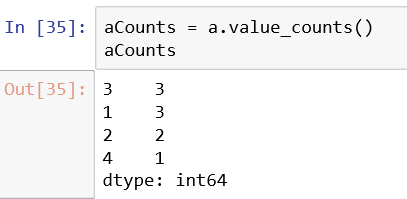
5、判断是否包含某些元素
isin()方法传入一个条件可以判断series是否包含某些元素,返回的是一个series

返回的布尔类型series传给原series可以进行筛选满足条件的元素
6、判断元素是否为null或非null
isnull()返回一个布尔类型的series
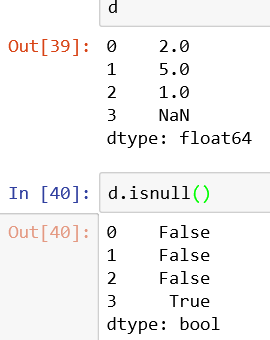
非空即调用notnull()方法
通过isnull()方法
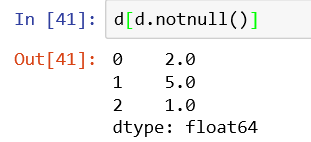
7、获取最小最大值的索引
通过调用idxmin()与idxmax()
获取内部元素
支持使用从0开始的索引访问元素或指定索引值

同样series也支持切片

筛选元素
可以对series对象直接进行逻辑运算,但回返回一个布尔类型的series
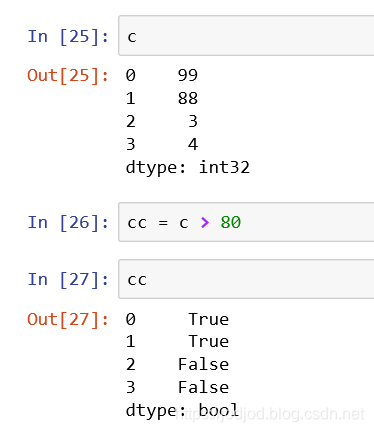
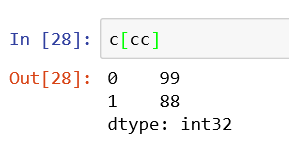
通过传递布尔类型的series可以进行筛选元素
series的运算
1、series的运算是针对values中的每一个元素的
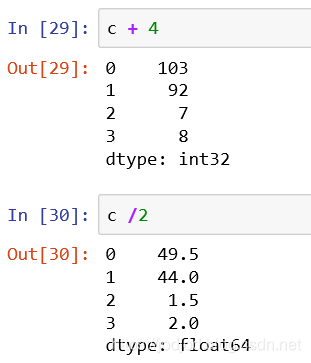
numpy提供了许多运算方法,都可以将series传入
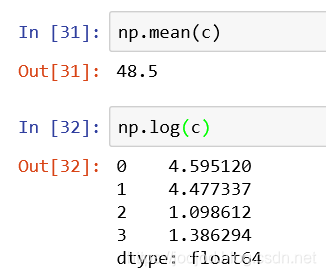
2、多个series进行运算时,具有相同index的value会进行运算,若无相同idex,则该value的运算结果为NaN
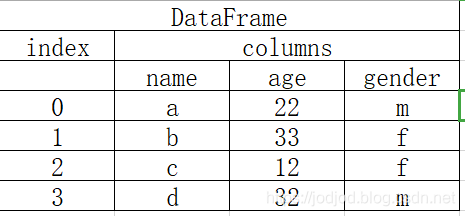
DataFrame
DataFrame数据结构与关系型表格类似,是多维的series,它的"values"为colunms,即多列,每一列的数据类型可以不相同
创建DataFrame对象
1、传递一个字典对象给DataFrame的构造函数,dict的key为每一列的列名,value作为列元素
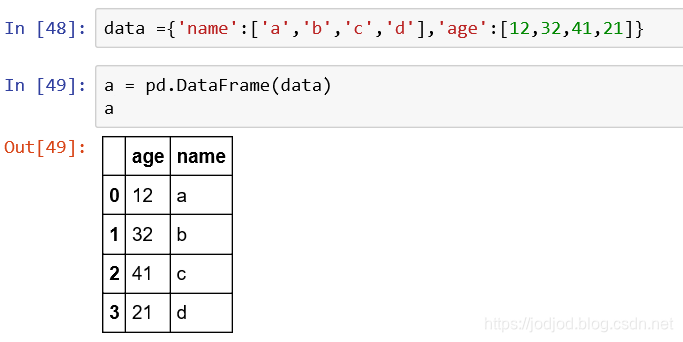
还可以指定字典中的部分kv对装载到dataframe中
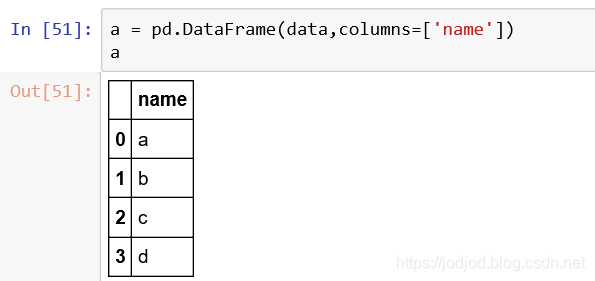
自然也可以自定义行标签index
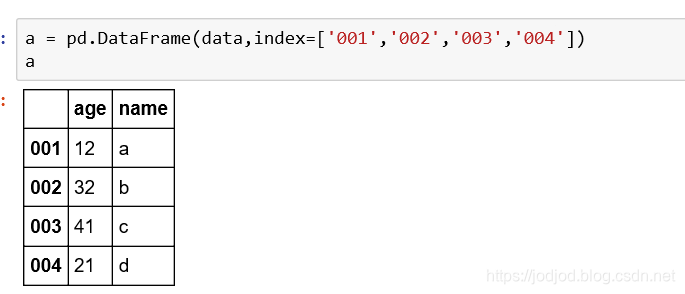
2、传入元素数组、index数组和列名数组
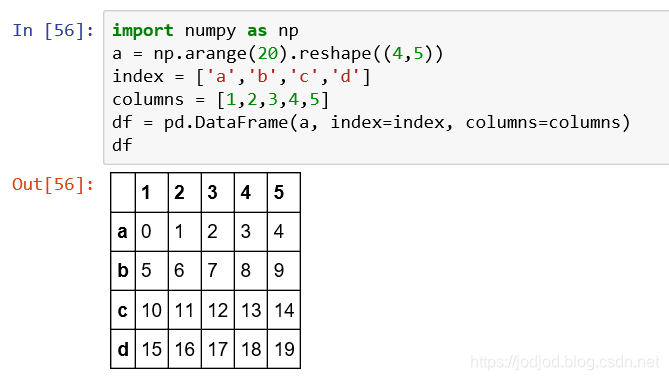
获取元素
1、通过columns属性查看列名

2、通过index属性查看行名

3、通过values属性获取元素

4、获取某一列的内容
用列名检索
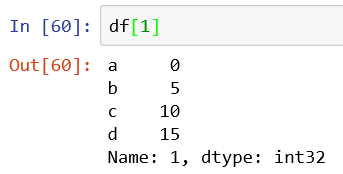
若列名为字符串类型,可以直接通过以列名为属性获取


5、获取某一行的内容
通过DataFrame.icon[index]实现
还可以通过行名进行索引
索引多行在icon后传入列表即可
6、切分
同样dataframe底层为ndarray

7、获取某一值
需要指定两个维度,注意列名在前

dataframe为行列起名
index和columns默认名为空

dataframe相关操作
1、添加一列
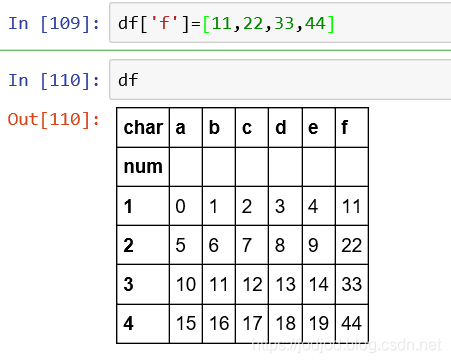
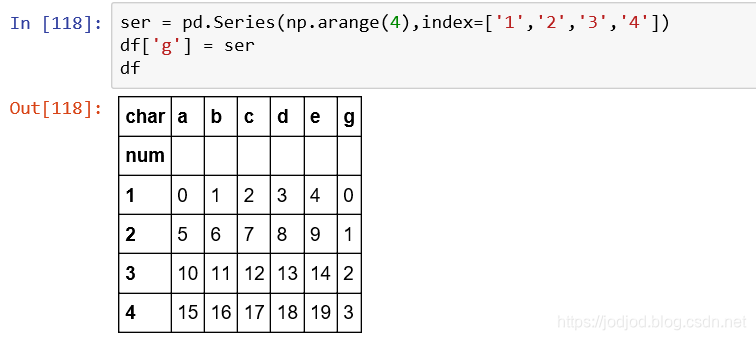
一列即为一个series,所以可以直接传入一个series。注意series中的index需要与dataframe中的行名相同
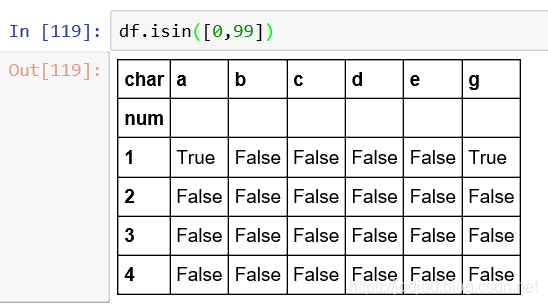
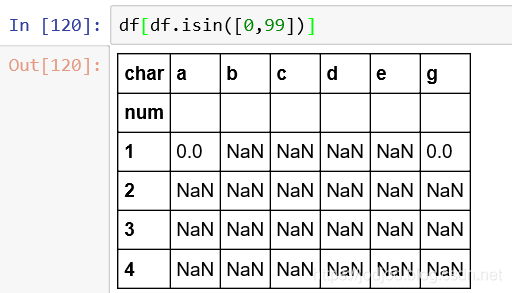
2、判断是否包含某元素
与series相同,可以使用isin()方法,并获取符合条件的元素
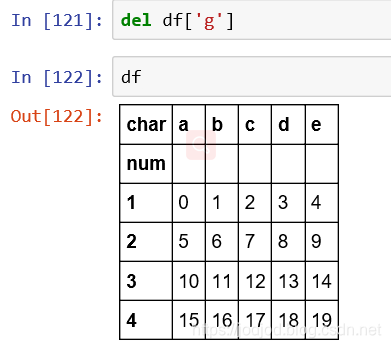
3、删除某列
通过del()方法
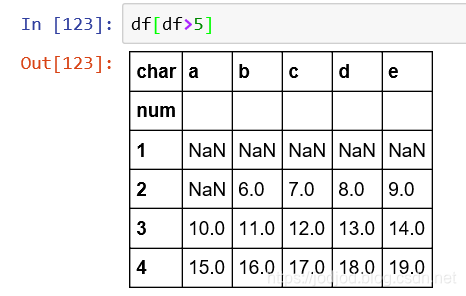
4、支持逻辑运算符进行筛选
与series相同
5、行列交换
底层为二维ndarray,即矩阵,可转置。通过T属性

Index对象
index对象在series和dataframe中都十分重要,很多操作都是针对index对象进行优化
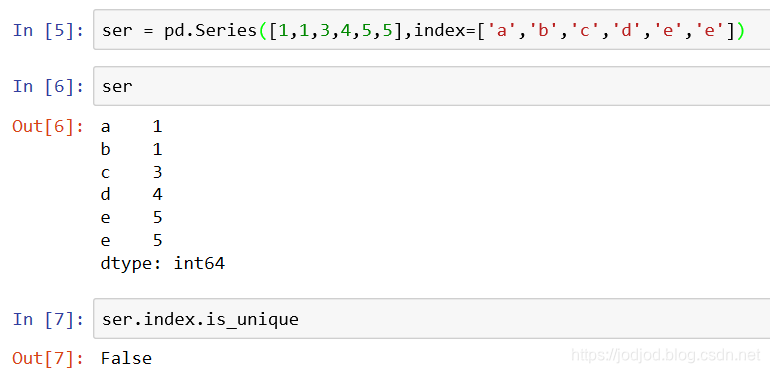
判断index是否唯一
通过index对象的is_unique属性判断
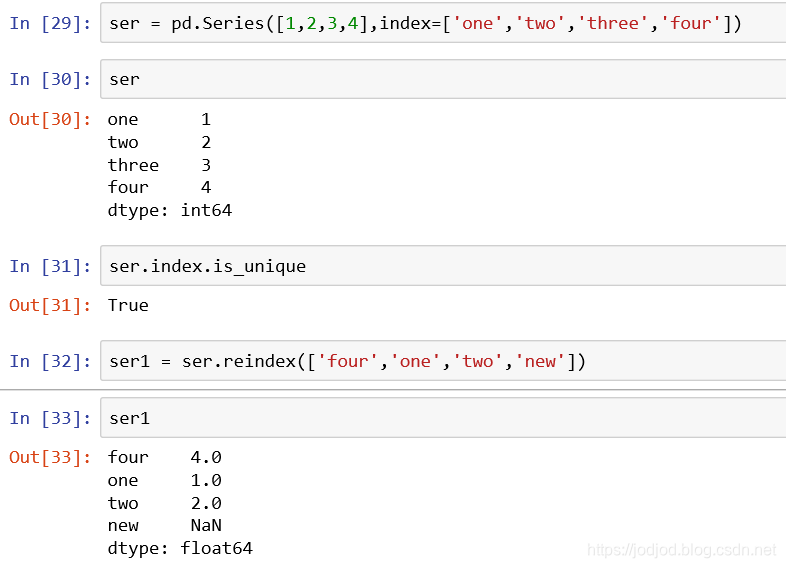
更换索引
通过series的reindex()方法可以交换原先索引位置,对于未出现过的索引名对应的元素为NaN
填充索引
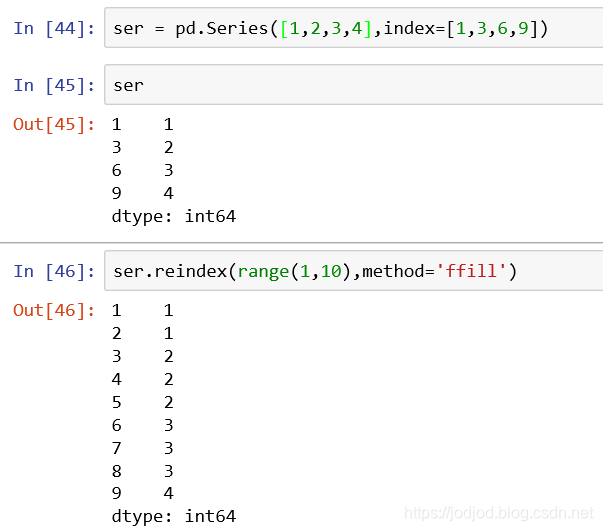
若series对象中索引缺失了很多项,也可以通过reindex()来填充索引
1、method为ffill(forward fill),即向前填充。缺失的索引对应的元素为之前的第一个出现索引的值
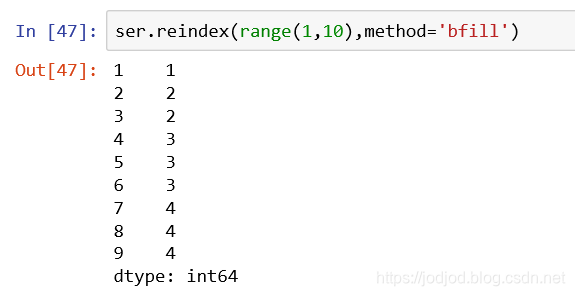
2、bfill即backward fill,向后填充。缺失的索引对应的元素为之后的第一个出现索引的值
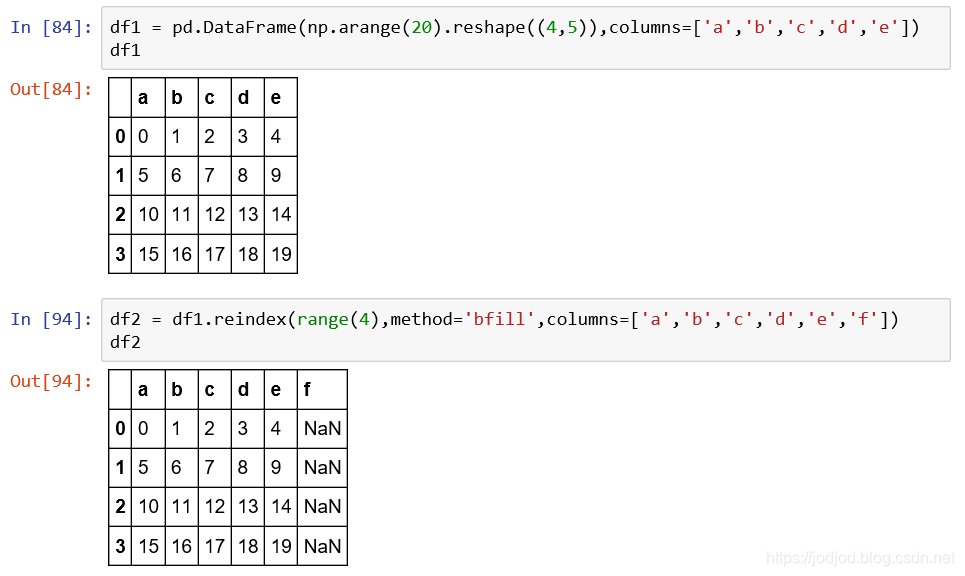
3、对于dataframe的reindex
同样可以对dataframe进行填充列
bfill为向后(右)填充,ffill为向左
删除索引
1、通过drop()方法删除索引,并返回删除的索引-值,会返回一个新的series
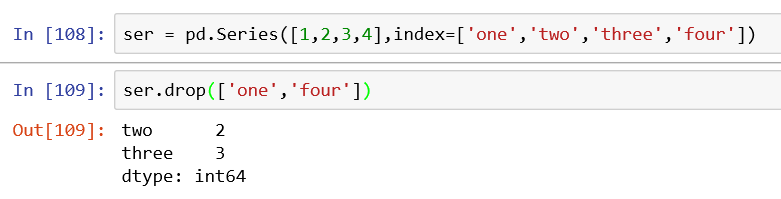
原series不会发生变化
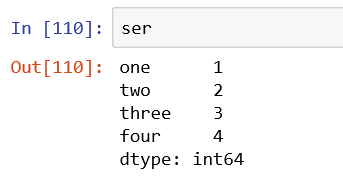
2、dataframe中删除索引
同样返回一个新的dataframe

还可以删除列,通过指定axis=1

算数和数据对齐
1、相同数据结构之间的运算
两个series进行运算时,只有相同索引的元素才会进行运算
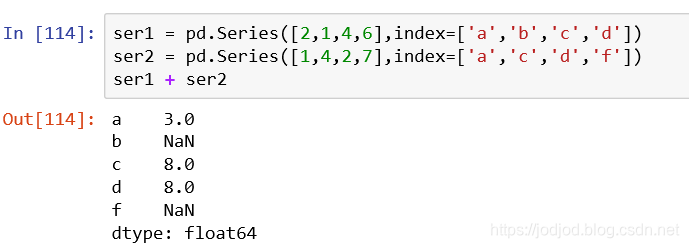
dataframe也是类似的,只有列名和index相同的元素才会运算
2、series和dataframe之间的与运算

实际上的df中的每一列与serise进行运算
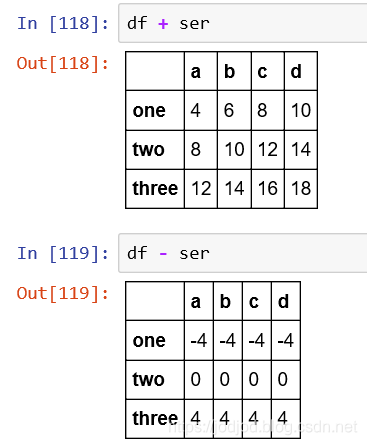
若存在不共有的index,则该index对应的值为NaN
numpy函数应用与自定义函数
pandas是以numpy为基础的,ufunc就是经过扩展的通用函数,这类函数能够读数据结构中的元素进行操作
numpy中的函数
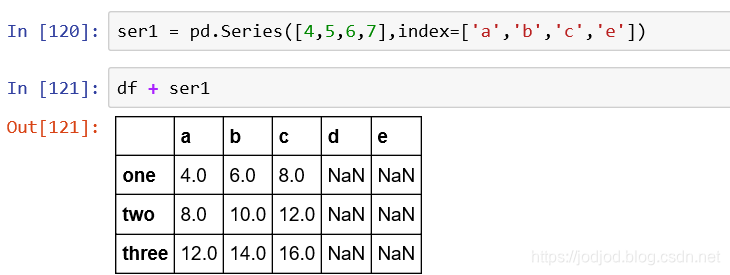
1、例如求平方根
可以直接通过numpy中的sqrt()方法,传入一个series或dataframe对象
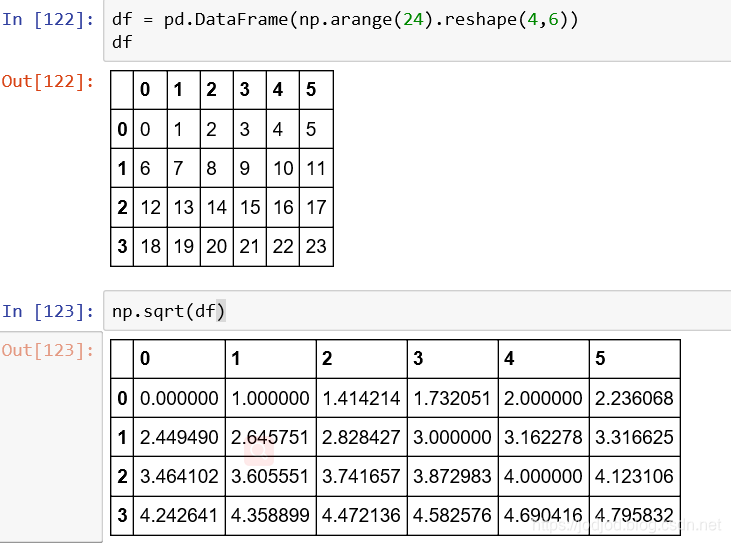
2、统计函数
使用axis=0指定应用于列,axis=1指定应用于行

其他sum,max等函数皆可用
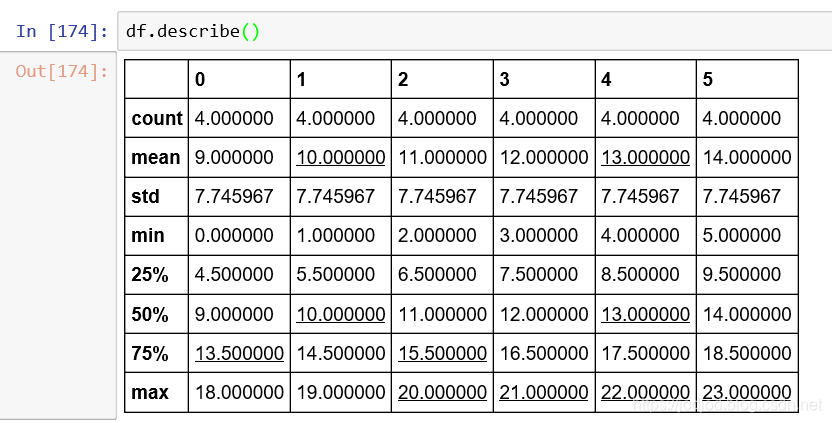
使用describe()函数可以查看所有统计量
自定义函数
自定义函数是对一维数组进行运算的,返回结构是一个数值。使用dataf或seri上的apply()方法应用自定义函数。针对每一行或每一列,使用axis=0指定应用于列,axis=1指定应用于行
1、dataframe上自定义函数求行或列的平方和
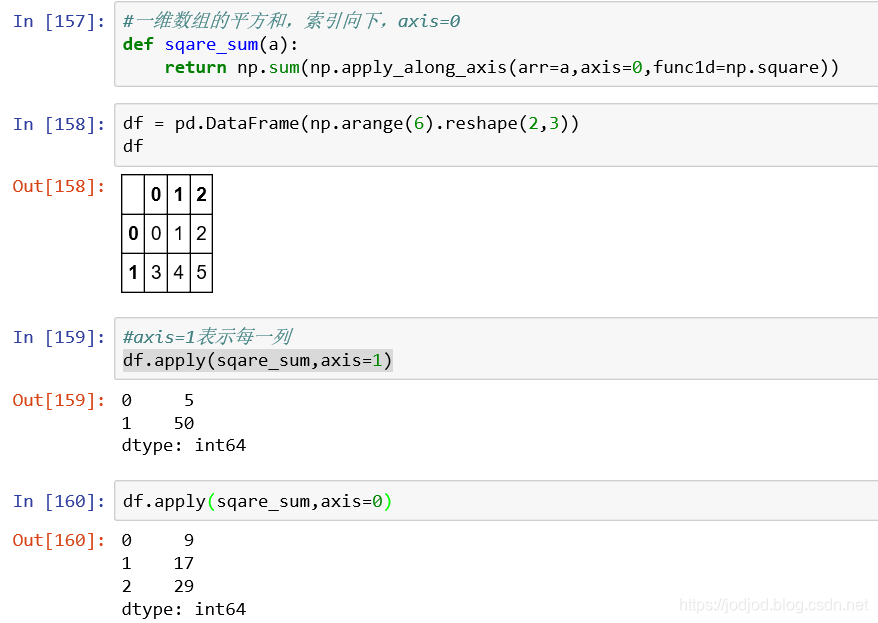
关于axis=1还是0:
2、使用lamdba表达式
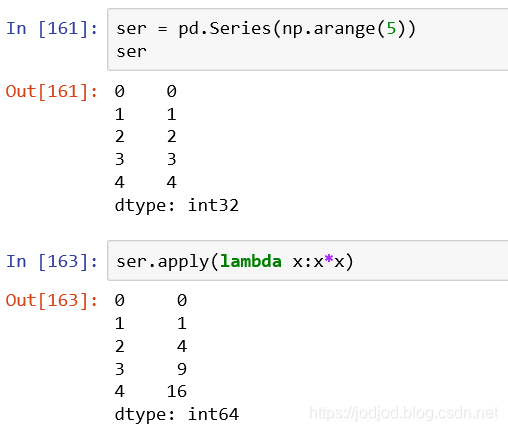
series上自定义函数求平方可以直接写lambda表达式
3、自定义函数返回series
apply函数并不一定返回一个标量,也可以是一个series
例如求dataframe中每一行或每一列的最大值和最小值



Series和DataFrame的排序和排位
Series排序
1、按index排序
通过sort_index()方法,ascending为True则为升序。默认升序

2、按元素值排序
通过sort_values()方法。默认升序

dataframe排序
1、按索引排序
同上sort_index()。ascending默认为True,axis默认为0

2、按column排序
sort_index()中声明axis为1
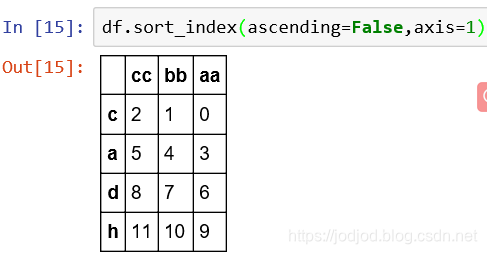
3、列中按元素值排序
sort_index()中by指定需要排序的列
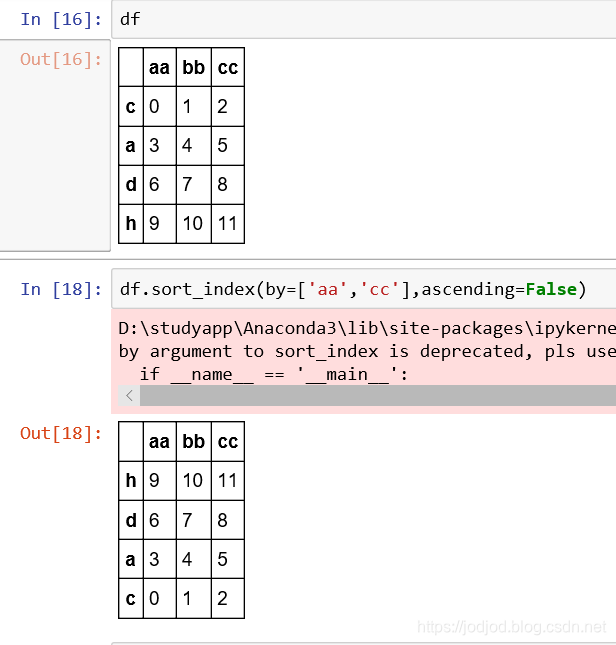
注意:sort_values()不支持同一行的排序
排位
排位指的是对元素值大小进行排序后返回在序列中的位置,比如从小到大排在第几位
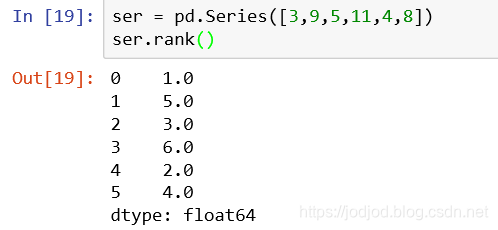
1、Series的排位
通过rank()
2、DataFrame的排位
为series类似,但需要指明axis,0为每列排位,1位每行排位
相关性和协方差
相关性correlation和协方差covariance是两个重要的统计量,分别用corr()和cov()两个函数表示,用来度量两个对象的相关性。相关系数位于-1~1之间
相关系数为1:表示完全正相关
相关系统为0:表示完全不相关
相关系统为-1:表示完全正相关
这连个统计量通常涉及到两个series对象
相关性
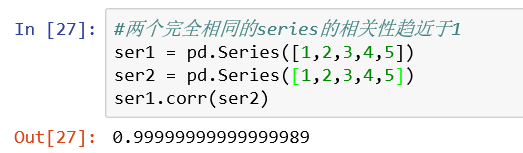
1、series中的相关性




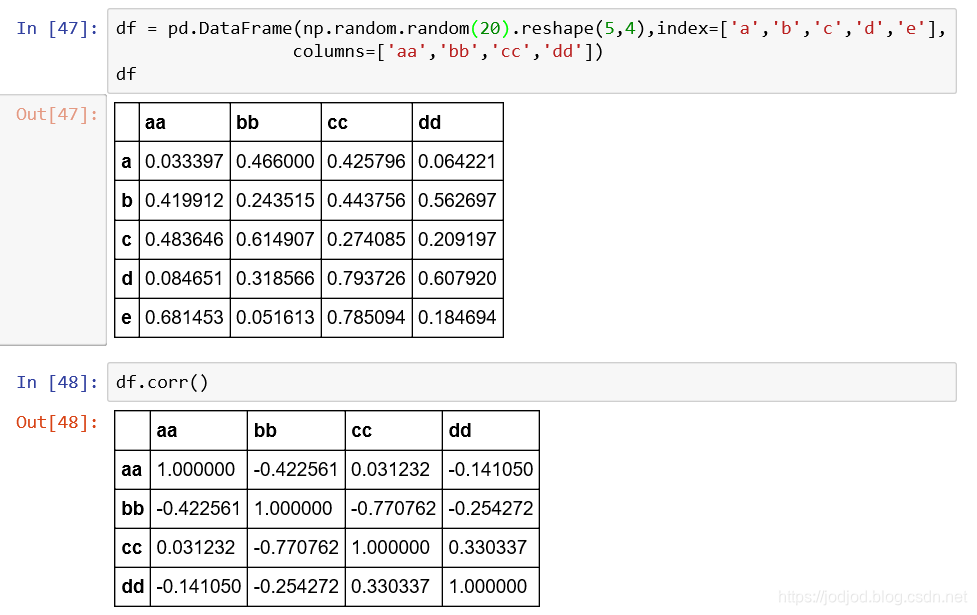
2、dataframe中每一列的相关性
dataframe中的相关性一般用来比较该df中的每一列与其他列之间的相关性
调用corr()方法得到的是一个矩阵
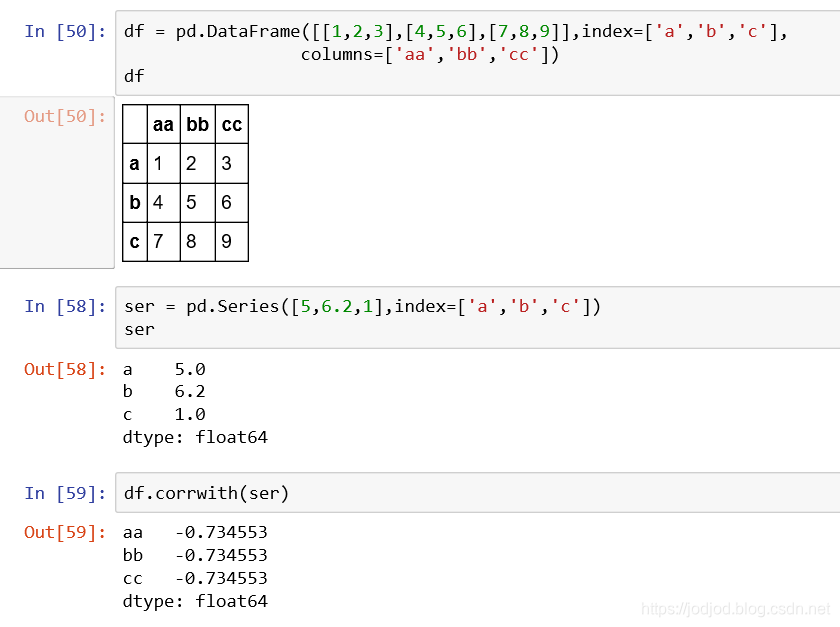
3、dataframe与series之间的相关性
dataframe相当于多维series,通过df对ser的相关性比较,实则是df中的每一列与series的比较
通过corrwith()方法实现
4、dataframe与dataframe之间的相关性
也是通过corrwith()方法,分别比较相同列名中的元素的相关性
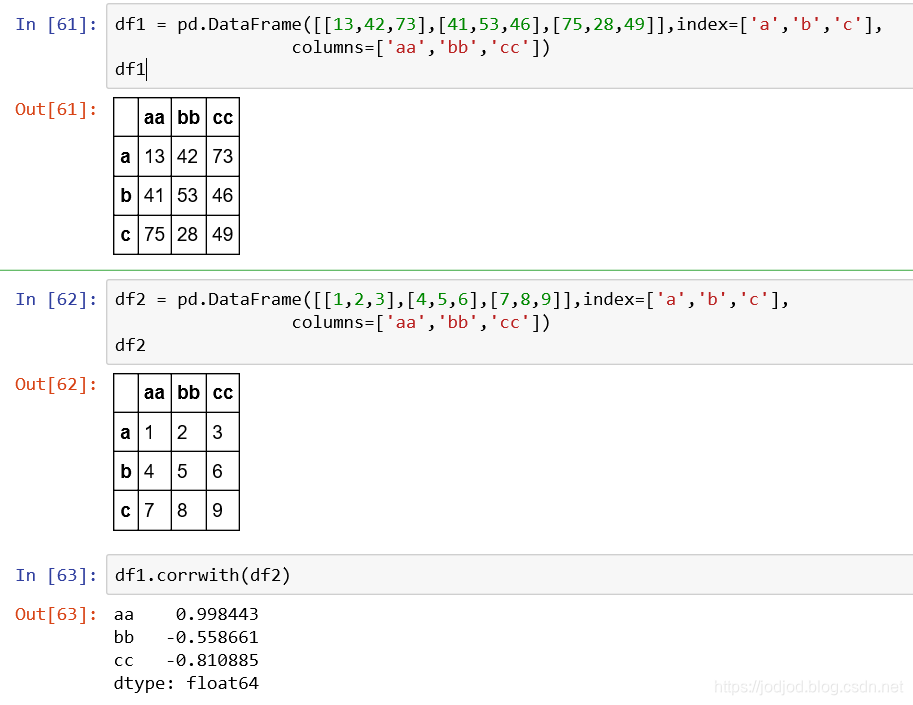
可以在dataframe分别取出series互相比较

NaN的数据处理
1、创建NaN数据
在构造数据时,可以直接赋值NaN,即调用numpy的nan
构造series过程中为series的值赋值为nan
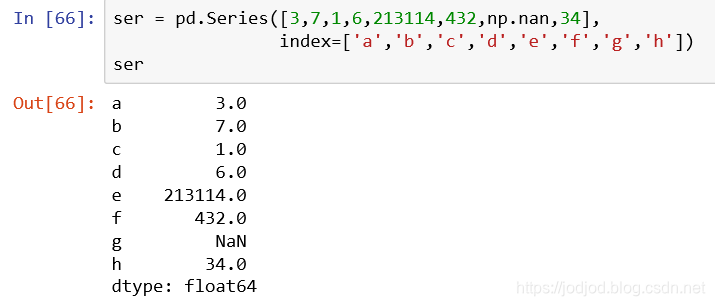
也可以None来赋值
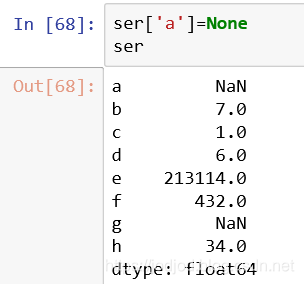
2、删除NaN数据
若NaN在整个数据集中占比较小,可考虑直接删除
通过dropna()实现

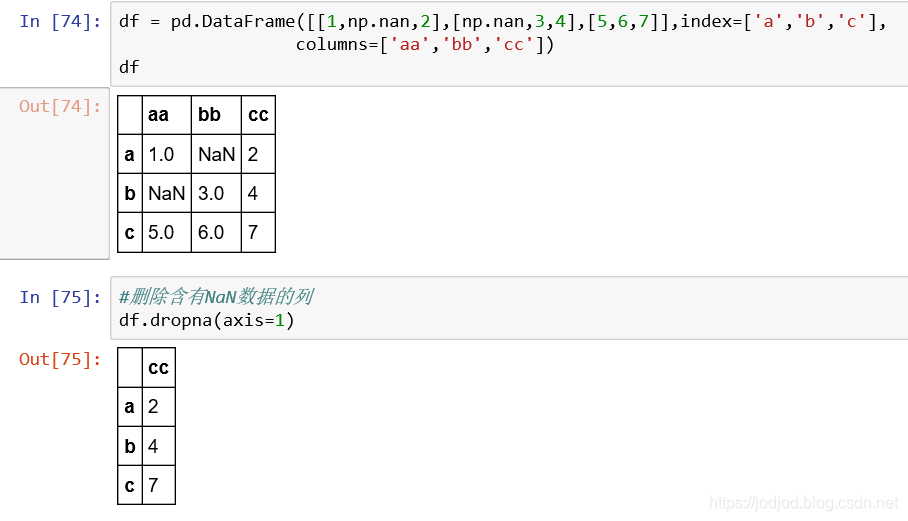
在dataframe中需要指明axis,会删除含有NaN数据的一整行或一整列
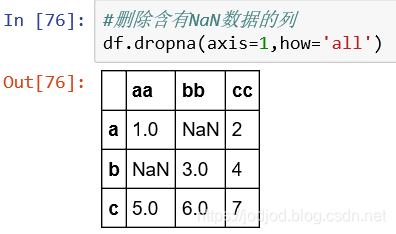
还可以设置删除策略,在dropna()函数中how为'all'是整行或整列全为NaN时才会删除。默认为'any'
3、判断为空或非空
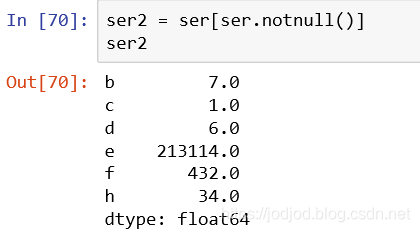
但最好在副本上进行删除,通过notnull()可以返回索引对应值是否为空的布尔类型series
判断为空则调用isnull(),可以筛选出为NaN的数据

4、填充空值
1、通过fillna()实现,传入参数表示填的值
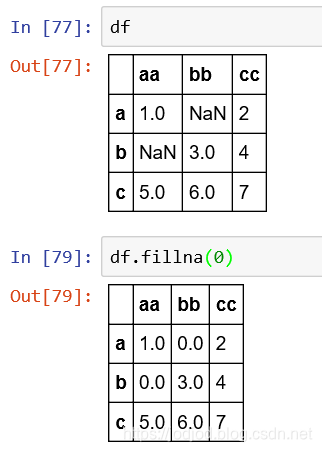
2、还可以在fillna()中传入字典指定列名与填充值


源代码)

















![[Grid Layout] Place grid items on a grid using grid-column and grid-row](http://pic.xiahunao.cn/[Grid Layout] Place grid items on a grid using grid-column and grid-row)