在线性回归算法求解中,常用的是最小二乘法与梯度下降法,其中梯度下降法是最小二乘法求解方法的优化,但这并不说明梯度下降法好于最小二乘法,实际应用过程中,二者各有特点,需结合实际案例具体分析。
最后有两份最小二乘法和逻辑斯特推导方法
1.最小二乘法求解线性回归
线性回归的基本模型设定为:
在此基础上构建代价函数:
通过代价函数 求偏导并令其等于零,所得到 的即为模型参数的值:
最终得到:
这便是由最小二乘法所求得的模型参数θ的值。这里需要满的条件是(XTX)-1存在的情况。在机器学习中,(XTX)-1不可逆的原因通常有两种,一种是自变量间存在高度多重共线性,例如两个变量之间成正比,那么在计算(XTX)-1时,可能得不到结果或者结果无效;另一种则是当特征变量过多,即复杂度过高而训练数据相对较少(m小于等于n)的时候也会导致(XTX)-1不可逆。(XTX)-1不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。
2.梯度下降法求解线性回归
梯度下降法是一种在学习算法及统计学常用的最优化算法,其思路是对theta取一随机初始值,可以是全零的向量,然后不断迭代改变θ的值使其代价函数J(θ)根据梯度下降的方向减小,直到收敛求出某θ值使得J(θ)最小或者局部最小。其更新规则为:
其中alpha为学习率。J(θ)对θ的偏导决定了梯度下降的方向,将J(θ)带入更新规则中得到:
对于上式由于每一次迭代都需要遍历所有训练数据一次,如果训练数据庞大,则复杂度比较高,便使得收敛速度变得很慢,所以被称作批量梯度下降法。当更新参数的时候,不必遍历全部训练数据,只要一个训练数据就可以,这种方法会比较快地收敛,所以区别于批量梯度下降法被称为随机梯度下降法。
梯度下降法中学习率alpha代表了逼近最低点的速率,既不能太大也不能太小,过大可能会出现不断地在最低点附近反复震荡的情况,无法收敛;而过小,则导致逼近的速率太慢,即需要迭代更多次才能逼近最低点。因此,可以用一些数值试验。
另外,在解决实际问题中,往往会出现x里的各个特征变量的取值范围间的差异非常大,如此会导致在梯度下降时,由于这种差异而使得J(θ)收敛变慢,特征缩放便是解决该类问题的方法之一,特征缩放的含义即把各个特征变量缩放在一个相近且较小的取值范围中,例如-1至1,0.5至2等,其中,较简单的方法便是采用均值归一化,也就是标准化处理。
3. 二者的应用比较
相对于最小二乘法来说,梯度下降法须要归一化处理以及选取学习速率,且需多次迭代更新来求得最终结果,而最小二乘法则不需要。
相对于梯度下降法来说,最小二乘法须要求解(XTX)-1,其计算量为o(n3),当训练数据集过于庞大的话,其求解过程非常耗时,而梯度下降法耗时相对较小。
所以,当模型相对简单,训练数据集相对较小,用最小二乘法较好;对于更复杂的学习算法或者更庞大的训练数据集,用梯度下降法较好,一般当特征变量小于10的四次方时,使用最小二乘法较稳妥,而大于10的四次方时,则应该使用梯度下降法来降低计算量。
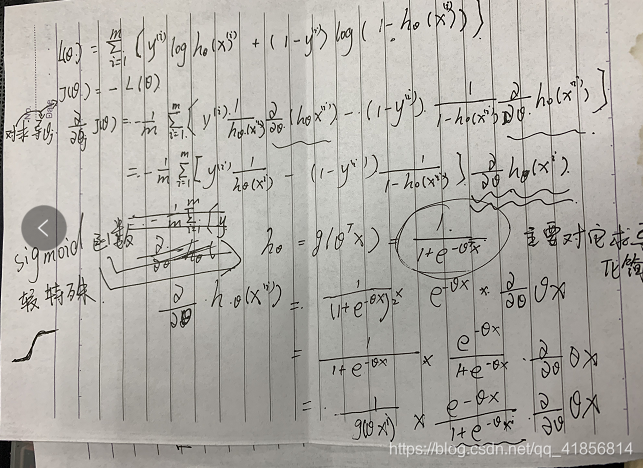
## 个人推导笔记仅供参考




struts2核心知识II)



)






和numpy的广播机制)




)


