孤注一掷——基于文心Ernie-3.0大模型的影评情感分析
文章目录
- 孤注一掷——基于文心Ernie-3.0大模型的影评情感分析
- 写在前面
- 一、数据直观可视化
- 1.1 各评价所占人数
- 1.2 词云可视化
- 二、数据处理
- 2.1 清洗数据
- 2.2 划分数据集
- 2.3 加载数据
- 2.4 展示数据
- 三、RNIE 3.0文心大模型
- 3.1 导入模型
- 3.2 模型训练
- 3.3 可视化训练曲线
- 3.5 模型预测
- 四、总结
- 写在最后
- 参考文献
- 作者简介
写在前面
前些天看了《孤注一掷》,感觉是一个很不错的电影,狠狠劝赌!
-
人有两颗心,一颗贪心,一颗不甘心,诱惑的背后只有陷阱,恐惧的尽头只剩绝望。
-
希望大家提高防诈骗意识,别信,别贪,别冲动!

-
这个项目使用文言一心大模型,对爬取的电影评论数据进行小样本的预训练学习。
-
使用Ernie-3.0-medium-zh大模型(感谢三岁大佬),为百亿参数知识增强的大模型,能够快速解决中文数据学习困难,准确率低的问题。
-
项目环境:
PaddlePaddle2.4.0,PaddleNLP2.4.2
一、数据直观可视化
电影《孤注一掷》豆瓣短评数据信息如下(感谢马哥公众号老男孩的平凡之路)
- 共30页,600条数据
- 含6个字段:页码,评论者昵称,评论星级(1-5星),评论时间,评论者IP属地,评论内容
- 豆瓣短评页面上最多显示30页,再往后翻页就会显示“加载中”,获取不到后面的数据,所以只有30页
- 对数据进行简单的处理,由于涉及到情感分类,将评星低于三星的认为差评,等于三星的认为中立,高于三星的认为好评
1.1 各评价所占人数
由于存在一定误差(比如三星的评论可能是好评也可能是差评,低于三星的评论也可能是好评,还有一些没有价值的评论),故用误差棒使结果更加严谨,从数据中统计可得:
好评:218人中立:159人差评:223人
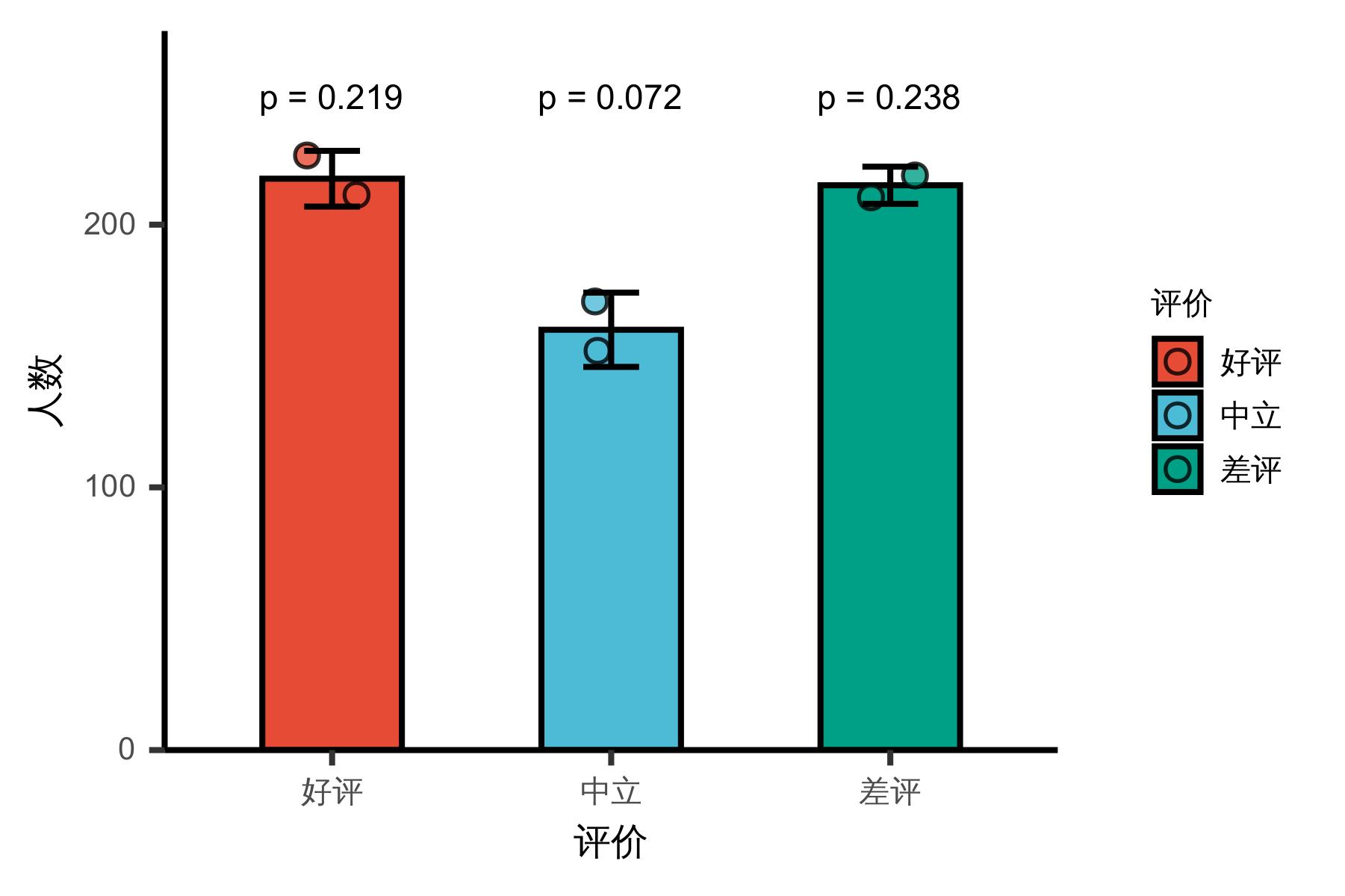
可以看出三个评价的人数基本相近
1.2 词云可视化
-
词云可视化可以帮助用户快速识别影评中的关键词和热门话题。通过将频率较高的词语放大显示,用户可以一目了然地了解影评的主题和重点。
-
我将背景设置成一个骷髅,不知道大家能不能看出来

-
由于aistudio里面词云字体会出现打不开的情况,所有我是在本地跑的,现在将代码贴在这里,感兴趣的小伙伴可以copy下来在自己的本地环境里面跑一下。
from wordcloud import WordCloud # 词云库
import matplotlib.pyplot as plt # 数学绘图库
import numpy as np
from PIL import Image# 读数据
with open("output.txt", "r", encoding='utf-8') as f:text = f.read()mask = np.array(Image.open("img_7.png"))
wc1 = WordCloud(background_color="white", # 背景为白色font_path='C:/Windows/Fonts/msyh.ttc', # 使用的字体库:当前字体支持中文max_words=2000, # 最大显示的关键词数量width=1000, # 生成词云的宽height=860, # 生成词云的高collocations=False, # 解决关键词重复:是否包括两个词的搭配mask=mask# stopwords=STOPWORDS, #屏蔽的内容
)
wc2 = wc1.generate(text)plt.imshow(wc2)
plt.axis("off")
plt.savefig('词云.jpg', dpi=2600, bbox_inches='tight')
plt.show()**<font size=6 color=green>接下来正式开始大模型之旅!**## 二、更新PaddleNLP
`clear_output`主要是为了清除输出信息,对更新没有影响,为了最后项目的美观,所以在最后加上了一句 `clear_output````python
# 清除输出,使项目更清晰
from IPython.display import clear_output
!pip install paddlenlp==2.4.2 -i https://pypi.org/simple
# 清除输出
clear_output()
查看版本号是否正确
paddlepaddle的版本为2.4.0,paddlenlp的版本为2.4.2- 如果版本不匹配的话可能后面会出现cannot import name
'AutoModelForSequenceclassification' from paddlenlp.transfomers的错误
import paddle
import paddlenlp
print("paddle版本",paddle.__version__)
print("paddlenlp版本",paddlenlp.__version__)
paddle版本 2.4.0
paddlenlp版本 2.4.2
二、数据处理
- 利用`正则表达式清理数据
- 利用
paddlenlp.datasets中的DatasetBuilder函数对数据进行处理 - 数据变成了[{‘text_a’: ‘data’, ‘label’: label},……] 的格式
2.1 清洗数据
- 使用
正则表达式去除音频中的中文标点符号,并和标签一起写入txt文件中 - 用到的正则表达式为
re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]+', ' ', content)
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
import re
# 遍历每一行,将内容存入txt文件
with open('output.txt', 'w') as file:for index, row in df.iterrows():content = row['content']content = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]+', ' ', content)label = row['label']file.write(f"{label}\t{content}\n")- 清洗完的数据如下:

2.2 划分数据集
import random# 读取output.txt文件中的内容
with open('output.txt', 'r') as file:lines = file.readlines()# 随机打乱数据
random.shuffle(lines)# 计算切分的索引
total_lines = len(lines)
train_end = int(total_lines * 0.7)
validation_end = int(total_lines * 0.9)# 切分数据
train_data = lines[:train_end]
validation_data = lines[train_end:validation_end]
test_data = lines[validation_end:]# 将数据写入train.txt
with open('train.txt', 'w') as file:file.writelines(train_data)# 将数据写入validation.txt
with open('validation.txt', 'w') as file:file.writelines(validation_data)# 将数据写入test.txt
with open('test.txt', 'w') as file:file.writelines(test_data)2.3 加载数据
# 导入DatasetBuilder
from paddlenlp.datasets import DatasetBuilder
class NewsData(DatasetBuilder):SPLITS = {'train': '/home/aistudio/train.txt', # 训练集'dev': '/home/aistudio/validation.txt', # 验证集'test': '/home/aistudio/test.txt'}def _get_data(self, mode, **kwargs):filename = self.SPLITS[mode]return filenamedef _read(self, filename):"""读取数据"""with open(filename, 'r', encoding='utf-8') as f:for line in f:if line == '\n':continuedata = line.strip().split("\t") # 以'\t'分隔各列label, text_a = datatext_a = text_a.replace(" ", "")if label in ['0', '1']:yield {"text_a": text_a, "label": label} # 此次设置数据的格式为:text_a,label,可以根据具体情况进行修改def get_labels(self):return label_list # 类别标签
# 定义数据集加载函数
def load_dataset(name=None,data_files=None,splits=None,lazy=None,**kwargs):reader_cls = NewsData # 加载定义的数据集格式print(reader_cls)if not name:reader_instance = reader_cls(lazy=lazy, **kwargs)else:reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)return datasets
# 加载训练和验证集
label_list = ['0', '1']
train_ds, dev_ds, text_t = load_dataset(splits=['train', 'dev', 'test'])
<class '__main__.NewsData'>
2.4 展示数据
train_ds[:5]
[{'text_a': '人有两颗心一颗是贪心一颗是不甘心', 'label': 0},{'text_a': '一边张灯结彩一边天人永别太讽刺了', 'label': 0},{'text_a': 'C从我自己的观影感受里就可以感知到观众对于真正的中国犯罪电影有多么的渴望犯罪链条上每一个奇观展现都让我觉得抓眼带感这不是所谓的短视频猎奇而是我们真的想要看国内电影里存在这样的东西一些陆家嘴之狼CBD风云最大的问题当然是没有人物也没有主题为正的导向更是让它不可能具有任何的人性深度但值得肯定的是申奥还是一定程度上把人对金钱的狂热拍了出来','label': 0},{'text_a': '暑期档继续发疯紧张刺激', 'label': 0},{'text_a': '请不要在反诈宣传片里插播偶像剧', 'label': 1}]
三、RNIE 3.0文心大模型
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation 论文摘要:经过预训练的语言模型在各种自然语言处理(NLP)任务中取得了最先进的结果。GPT-3已经表明,扩大预先训练的语言模型可以进一步开发它们的巨大潜力。最近提出了一个名为ERNIE3.0的统一框架,用于预训练大规模知识增强模型,并训练了一个具有100亿个参数的模型。ERNIE3.0在各种NLP任务上的表现优于最先进的模型。为了探索扩大ERNIE3.0的性能,我们在飞桨平台上训练了一个名为ERNIE3.0Titan的数百亿参数模型,其参数高达2600亿。此外,我们设计了一个自监督的对抗性损失和一个可控的语言建模损失,使ERNIE3.0 Titan生成可信和可控的文本。为了减少计算开销和碳排放,我们为ERNIE3.0 Titan提出了一个在线蒸馏框架,教师模型将同时教授学生和训练自己。ERNIE3.0泰坦是迄今为止中国最大的密集预训练模型。经验结果表明,ERNIE3.0 Titan在68个NLP数据集上的性能优于最先进的模型。
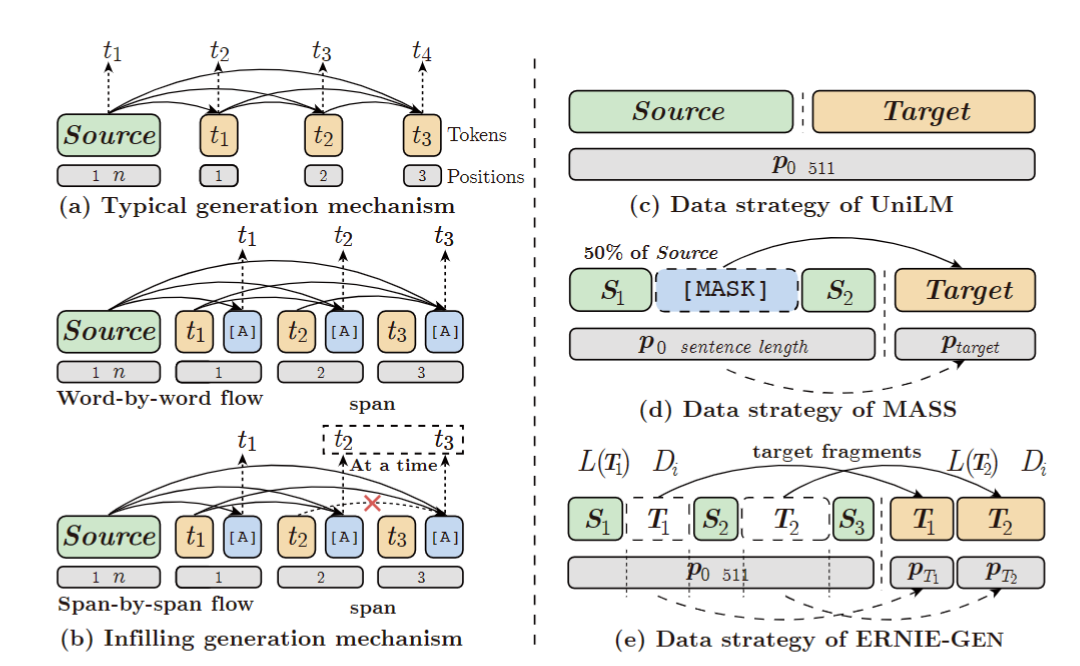
两种生成机制的示意图(左)和预训练的数据策略(右)。绿色、橙色和蓝色的方块表示源文本、目标文本和人造符号。

消融研究结果
3.1 导入模型
详细教程可以参考PaddleNLP Transformer预训练模型
import os
import paddle
import paddlenlp
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "ernie-3.0-medium-zh"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
[2023-08-20 17:09:48,154] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.modeling.ErnieForSequenceClassification'> to load 'ernie-3.0-medium-zh'.
[2023-08-20 17:09:48,159] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh
[2023-08-20 17:09:48,162] [ INFO] - Downloading ernie_3.0_medium_zh.pdparams from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh.pdparams
100%|██████████| 313M/313M [00:09<00:00, 32.9MB/s]
W0820 17:09:58.220381 204 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0820 17:09:58.224973 204 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-08-20 17:10:01,278] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'ernie-3.0-medium-zh'.
[2023-08-20 17:10:01,282] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh
[2023-08-20 17:10:01,285] [ INFO] - Downloading ernie_3.0_medium_zh_vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt
100%|██████████| 182k/182k [00:00<00:00, 9.63MB/s]
[2023-08-20 17:10:01,391] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/tokenizer_config.json
[2023-08-20 17:10:01,394] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/special_tokens_map.json
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloader
# 模型运行批处理大小
batch_size = 32
max_seq_length = 128trans_func = partial(convert_example,tokenizer=tokenizer,max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id), # inputPad(axis=0, pad_val=tokenizer.pad_token_type_id), # segmentStack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(train_ds,mode='train',batch_size=batch_size,batchify_fn=batchify_fn,trans_fn=trans_func)
dev_data_loader = create_dataloader(dev_ds,mode='dev',batch_size=batch_size,batchify_fn=batchify_fn,trans_fn=trans_func)
3.2 模型训练
数据量太少了,很容易过拟合,这里的的
- epoch设置成20
- weight_decay 设置成0.1
- learning_rate 设置成 5e-6
- 大概两分钟即可训练完成
import paddlenlp as ppnlp
import paddle
from paddlenlp.transformers import LinearDecayWithWarmup# 训练过程中的最大学习率
learning_rate = 5e-6
# 训练轮次
epochs = 20 #3
# 学习率预热比例
warmup_proportion = 0.3
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.1num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=weight_decay,apply_decay_param_fun=lambda x: x in [p.name for n, p in model.named_parameters()if not any(nd in n for nd in ["bias", "norm"])])criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
import paddle.nn.functional as F
from utils import evaluate
all_train_loss=[]
all_train_accs = []
Batch=0
Batchs=[]
global_step = 0
for epoch in range(1, epochs + 1):for step, batch in enumerate(train_data_loader, start=1):input_ids, segment_ids, labels = batchlogits = model(input_ids, segment_ids)loss = criterion(logits, labels)probs = F.softmax(logits, axis=1)correct = metric.compute(probs, labels)metric.update(correct)acc = metric.accumulate()global_step += 1if global_step % 10 == 0 :print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))Batch += 10 Batchs.append(Batch)all_train_loss.append(loss)all_train_accs.append(acc)loss.backward()optimizer.step()lr_scheduler.step()optimizer.clear_grad()evaluate(model, criterion, metric, dev_data_loader)model.save_pretrained('/home/aistudio/checkpoint')
tokenizer.save_pretrained('/home/aistudio/checkpoint')
eval loss: 0.75054, accu: 0.43902
global step 10, epoch: 2, batch: 2, loss: 0.66468, acc: 0.59375
eval loss: 0.75193, accu: 0.43902
global step 20, epoch: 3, batch: 4, loss: 0.57682, acc: 0.64062
eval loss: 0.75422, accu: 0.43902
global step 30, epoch: 4, batch: 6, loss: 0.64896, acc: 0.56771
eval loss: 0.74524, accu: 0.43902
global step 40, epoch: 5, batch: 8, loss: 0.62321, acc: 0.62205
eval loss: 0.75564, accu: 0.43902
eval loss: 0.77395, accu: 0.43902
global step 50, epoch: 7, batch: 2, loss: 0.56548, acc: 0.65625
eval loss: 0.73238, accu: 0.43902
global step 60, epoch: 8, batch: 4, loss: 0.57789, acc: 0.67969
eval loss: 0.74135, accu: 0.46341
global step 70, epoch: 9, batch: 6, loss: 0.57494, acc: 0.70312
eval loss: 0.71202, accu: 0.51220
global step 80, epoch: 10, batch: 8, loss: 0.43934, acc: 0.76378
eval loss: 0.72221, accu: 0.53659
eval loss: 0.71013, accu: 0.57317
global step 90, epoch: 12, batch: 2, loss: 0.44184, acc: 0.87500
eval loss: 0.72470, accu: 0.57317
global step 100, epoch: 13, batch: 4, loss: 0.34039, acc: 0.90625
eval loss: 0.71655, accu: 0.63415
global step 110, epoch: 14, batch: 6, loss: 0.21924, acc: 0.93229
eval loss: 0.78495, accu: 0.62195
global step 120, epoch: 15, batch: 8, loss: 0.21976, acc: 0.95669
eval loss: 0.78816, accu: 0.64634
eval loss: 0.88699, accu: 0.59756
global step 130, epoch: 17, batch: 2, loss: 0.13201, acc: 0.95312
eval loss: 0.83912, accu: 0.64634
global step 140, epoch: 18, batch: 4, loss: 0.13333, acc: 0.97656
eval loss: 0.79599, accu: 0.65854
global step 150, epoch: 19, batch: 6, loss: 0.11692, acc: 0.98958
eval loss: 0.89906, accu: 0.63415
global step 160, epoch: 20, batch: 8, loss: 0.11152, acc: 0.96457
eval loss: 0.91676, accu: 0.63415[2023-08-20 17:10:31,859] [ INFO] - tokenizer config file saved in /home/aistudio/checkpoint/tokenizer_config.json
[2023-08-20 17:10:31,863] [ INFO] - Special tokens file saved in /home/aistudio/checkpoint/special_tokens_map.json('/home/aistudio/checkpoint/tokenizer_config.json','/home/aistudio/checkpoint/special_tokens_map.json','/home/aistudio/checkpoint/added_tokens.json')
3.3 可视化训练曲线
import matplotlib.pyplot as plt
def draw_train_acc(Batchs, train_accs,train_loss):title="training accs"plt.title(title, fontsize=24)plt.xlabel("batch", fontsize=14)plt.ylabel("acc", fontsize=14)plt.plot(Batchs, train_accs, color='green', label='training accs')plt.plot(Batchs, train_loss, color='red', label='training loss')plt.legend()plt.grid()plt.show()
draw_train_acc(Batchs,all_train_accs,all_train_loss)

3.5 模型预测
# 加载模型参数
import os
import paddle
params_path = 'checkpoint/model_state.pdparams'
if params_path and os.path.isfile(params_path):state_dict = paddle.load(params_path)model.set_dict(state_dict)print("Successful Loaded down!")
Successful Loaded down!
from utils import predict
batch_size = 32
data = text_t
label_map = {0: '0', 1: '1',2:'2'}
results = predict(model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):print('Data: {} \t Lable: {}'.format(text, results[idx]))
Data: {'text_a': '阿才太帅了纯爱战神啊阿天那条线是最令人唏嘘的阿天母亲的演的太好了这边哭天抢地下一个镜头就是放鞭炮庆祝的转场戏剧性拉满', 'label': 0} Lable: 0
Data: {'text_a': '这种宣传片为啥不在电视或网络上免费普及给广大群众呢还让人民群众花银子受俩小时的教育把坏人往有血有肉有情有义里演成大活人把好人往假大空伟光正里演成稻草人真是的', 'label': 1} Lable: 1
Data: {'text_a': '这个故事告诉我们只要长的好看有才华就算被拐卖到境外也可以被编剧老师眷顾这部片跟奈飞的距离差了3个陈思诚反诈宣传片从预告片就开始在诈骗', 'label': 1} Lable: 0
Data: {'text_a': '反诈宣传片但是现实绝对比电影更残酷', 'label': 0} Lable: 0
Data: {'text_a': '母亲从门框伸出的手拉不回被贪心拖向地狱的儿荷官从屏幕伸出的手推下了想要上岸却坠落的人这边是关在牢笼里绑在石头上的动物那边是晒出来也会发霉刺进去不会流血的黑心我以为吞得下秘密你以为赚得到真金用筷子夹了一张纸钞从抽屉拿走了一块玉镯我用它来孤注一掷却满盘皆输', 'label': 1} Lable: 1
Data: {'text_a': '很现实电信诈骗真的远远比我们想的恐怖就在前段时间我的朋友才刚刚被骗了几万块就渐渐被带进去了当突然意识到的时候已经晚了每个人物都很饱满很现实是因为结局并不是合家欢的这真的除不尽不仅要靠国家更要靠自己甄别并不是聪明就不会被骗全员演技在线算是这段时间让人眼前一亮的电影了', 'label': 0} Lable: 0
Data: {'text_a': '命题作文中表现较好的但现实里不会有坏人的仁慈', 'label': 0} Lable: 0
Data: {'text_a': '炸裂今年最牛最棒最赞最精彩国产片', 'label': 0} Lable: 0
Data: {'text_a': '开头很好后面就编得不行主次不分了不过7分没问题为了正常上映很多黄暴没有拍出来点到为止放在90年代的香港拍那就更好了', 'label': 0} Lable: 0
Data: {'text_a': '现实主义题材是目前国内适时应该出现的反诈电影本片用三分之一段落描述潘生和梁安娜被骗进诈骗团伙有用三分之一的段落完整揭示一个真实上当人生被毁的案例后三分之一是艰难反诈斗争的正能量宁浩在本片虽然之挂名监制但很明显给导演申奥的助力很多孤注一掷的节奏很好而且第二段真实诈骗段落的展开深入精彩有力而且孤在强调犯罪者的狡诈和阴险之外还保留了他们的人性让孤的结局更真实更有余味', 'label': 0} Lable: 0
Data: {'text_a': '潘生安娜阿天三条故事线都很有警示作用瓦里只会比电影中更残忍更癫狂推荐观看全民防诈少一点人间悲剧上一次看孙阳还是在过春天上一次看王传君还是无名所以阿才和陆经理又是怎么上的贼船呢很高兴这俩角色都没完全偏平化还有最后一个镜头脑袋发麻申奥导演可以的', 'label': 0} Lable: 0
Data: {'text_a': '看哭了咱就是说阿天的父母该有多么心痛啊', 'label': 0} Lable: 0
Data: {'text_a': '比较碎人物描摹和事件编排节奏都虎头蛇尾空有一个略显不伦不类的花架子几次视角的转换不如直接做成接力式的叙事结构暴力氛围也一般想想南车摩托车飞头的突然震撼最吃惊的是张艺兴这拉胯演技对标的竟是胡歌被抓前的一段妆造都是比着胡歌来的吧咏梅封后后的表演面瘫感更重了不能说演的不好就有种随它吧老娘想演就来一段不想演你也给我瞪着眼看着的感觉', 'label': 1} Lable: 1
Data: {'text_a': '几个人物挺出彩的前半段远好于后半段教育意义远大于艺术价值', 'label': 0} Lable: 0
Data: {'text_a': '更像网剧一些剧作可以再顺畅一些张艺兴这人设在片头的动机太牵强了在线教育老总那条线也直接断了倒是任务片里的私货在线教育和传销作比民众围殴警察有点意思7', 'label': 0} Lable: 0
Data: {'text_a': '在网络世界里看着形形色色的人可能一直被锤炼一直不服输的张艺兴就是申奥导演最想要抓住的人物特质张艺兴也做到了演绎潘生不仅是把绝地求生的人物体现出来也是把希望送给了每一位观影的观众', 'label': 0} Lable: 0
Data: {'text_a': '和现实最大的区别就是阿才不会心软', 'label': 0} Lable: 0
Data: {'text_a': '16最恶劣的那种电影之一简单粗暴非常剥削在大旗下一步一步一段一段逼人接受请君入瓮仿佛新秩序式的那种缺点在看似复杂的行动中对观众的操纵性过强不留一点空间', 'label': 1} Lable: 0
Data: {'text_a': '说不上哪里好但又不觉得差给五星觉得高但不给五星又觉得对不起我观看时不由自主的种种反应里面所有以前我认为演戏突兀尴尬的几位在里面表演都出奇的流畅和合适一点不出戏节奏把控也很好还真挺震撼的但不是因为血腥是因为心底的恐惧代入到自己身上的绝望美中不足阿才长太帅了要是个又丑又邋遢猥琐的放了顶多觉得良心发现或者还有后招但是这个演员太帅了放了的场景让我衍生出了几秒恋爱脑降低了本片的警示意味和严肃性真是不应该啊不应该是说我见缝插针恋爱脑不应该', 'label': 0} Lable: 0
Data: {'text_a': '前面还是电影后面就成宣传片了主角从受害人变成了咏梅关键破案过程也不好看神兵天降加反派降智叙事混乱加节奏仓促我不知道那个馒头是怎么如此精准地投递给张艺兴的而他又怎么瞬间就明白了火柴盒的用途还有个让我不满但也许观众会觉得很爽的地方就是影片有很多暴力与性暗示镜头这些更多是商业噱头看不出对这些受害者有什么人文关怀', 'label': 1} Lable: 0
Data: {'text_a': '呃我就说一句能不能别把反派里的男人塑造的情深似海了逃出缅北靠爱情就真的不要这样好烦啊', 'label': 1} Lable: 1
Data: {'text_a': '放走金晨那段纯属强行给反派降智', 'label': 1} Lable: 1
Data: {'text_a': '为什么从广州去新加坡还需要转机这么离谱从一开始故事就不成立了槽点不胜枚举年度诈骗电影', 'label': 1} Lable: 0
Data: {'text_a': '拍出了受害者的可恨拍出了诈骗者的迫不得已良心未泯反诈宣传片诈骗工厂宣传片', 'label': 1} Lable: 1
Data: {'text_a': '看似反诈科普实则利用血腥和暴力场面恫吓国民让大家趁早打消出国念头把钱留给内循环这与中式家长动辄恐吓小孩的祖传教育思想如出一辙近年来国产商业片只要涉及异域必定要服膺一种外国即地狱风景这边独好的保守主义思潮这当然是一场属于部分民众和宣传工具的双向奔赴你甚至很难苛责一个背刺字幕组和靠抖音热门拍片的导演拍出这样一部前一半剥削电影后一半战狼出征的怪胎毕竟他最后会带着大几十亿的票房骄傲地反问你一句人民群众喜闻乐见你不喜欢你算老几', 'label': 1} Lable: 0
Data: {'text_a': '王大陆演技不错', 'label': 0} Lable: 0
Data: {'text_a': '影片本身承担了很重的责任在这个框架内主创已经尽力拉高了影片的可看性在一切都为一个大的主题辅助的前提下角色符号化几乎是不可避免的看完影片观众记住电信诈骗的危害就行了关心不关心角色不是重点但我还是想呼吁适当的分级或者统一审查标准不要那边要求不能出现红色的血这边人脑袋上扎钉子', 'label': 0} Lable: 0
Data: {'text_a': '骗子太可恶了', 'label': 0} Lable: 1
Data: {'text_a': '演员张艺兴值得信赖为了过审只能舍掉一些细节理想化一下结局', 'label': 0} Lable: 0
Data: {'text_a': '不开玩笑这个开分绝对偏低了不说剧情紧张刺激猎奇更多的是影片本身的普世价值和社会意义过审不容易目睹过身边的人赌博以及被骗的真实经历一点也不夸张真诚地推荐所有人以及带着家人一起看对小广告深恶痛绝反诈宣传从我做起', 'label': 0} Lable: 0
Data: {'text_a': '有教育意义诈骗戏份可大学生和警察戏份比较不好看喜欢里面的孙阳', 'label': 0} Lable: 0
Data: {'text_a': '极其扯淡的电影甚至骂都是浪费时间和人生大事一样浪费好题材整部电影一盘散沙从被骗到诈骗的经历再到受害者的故事再到破获案件的过程没有一个部分拍好的花钱去看电影就好比你花钱去看cctv的公益广告整部电影亮点只有王传君但如此傻逼的剧情把这个角色都搞得水泄不通诈骗犯有兄弟情有爱情TM来搞笑的伟光正男主真的全场尬住ok申奥可以拉进黑名单了', 'label': 1} Lable: 1
Data: {'text_a': '我这辈子是不去东南亚了', 'label': 0} Lable: 1
Data: {'text_a': '完成度一般演技也掉线叙事缺逻辑编剧不给力安娜和潘生出戏让人懵宁浩加申奥效果不太妙', 'label': 1} Lable: 0
Data: {'text_a': '那么多国产片歌功颂德描绘盛世粉饰太平至少它直面了人生的恶人性的恶人的恶哪怕只是一小部分走出影院是夏日傍晚热浪蝉鸣车流人群街道路边摊即使裹挟着灰尘与嘈杂但一切都很真实充满烟火气仿佛自己也刚经历了一场暗夜之行而重返人间忽然好想去找家小店坐下来喝碗粉丝汤', 'label': 0} Lable: 0
Data: {'text_a': '烂', 'label': 1} Lable: 0
Data: {'text_a': '七位主角和一众黄金配角的戏非常精彩让影片远超我预期逻辑硬漏洞不去想不去提单纯为看到周也开心也为看到咏梅孙阳王传君开心孙阳演技大进步', 'label': 0} Lable: 0
Data: {'text_a': '孙阳像辣椒炒肉油辣得刚好黄艺馨演受刑比金晨好500个张艺兴', 'label': 1} Lable: 0
Data: {'text_a': '用一组狂派以暴制暴莫名想起王道吉', 'label': 0} Lable: 0
Data: {'text_a': '片子本身挺扎实作为半命题作文故事完整演员发挥OK除了某些不得不做的戏剧性设置如金晨被孙阳恋爱脑给救了基本拥有了与其宣传话题匹配的可看性抖音密集投放两个月的短视频宣传也被证明这是抓住大陆下沉市场以获得最大路人关注榨取最广大345678线城市票房的最优手段当然这样的宣传手段也得益于本片自身所拥有的优秀话题性即非常贴合时下缅北诈骗这一社会热点两相结合之下本片与最广大普通观众群体神奇地达成了双向奔赴那句最朴实的价值观念多一人观影少一人受骗的口号也发挥出了实实在在的作用个人看完之后听到身边很多人都在交流是被前期宣传吸引来的看完之后也确实得到了一点关于诈骗的小小震撼和警示私以为这就很不错了豆瓣这群文青们一个个自恃智商奇高不会受骗反而纷纷以观看此片为受诈也挺可笑', 'label': 0} Lable: 0
Data: {'text_a': '社会热点自然会很火但确实把赌博境外诈骗这个产业链有好好表达了最重要是这就发生在我们每个人身边希望这更有社会现实意义的电影被更多人看到', 'label': 0} Lable: 0
: ‘社会热点自然会很火但确实把赌博境外诈骗这个产业链有好好表达了最重要是这就发生在我们每个人身边希望这更有社会现实意义的电影被更多人看到’, ‘label’: 0} Lable: 0
可以看到有正确的也有错误的,整体来说还是正确的多一些,我觉得主要的问题在于数据量太少了,训练的数据量至少要上万,但是由于这是个小demo初体验项目,影刺没有爬取太多的数据,只有区区600条,用于训练的只用420条数据,很容易造成过拟合的情况,导致模型在测试集、验证集上面的效果并不好。

四、总结
- 通过这个项目了解了文心大模型Ernie-3.0的使用方法
- 采用超小样本的预训练对现在非常火的孤注一掷电影影评进行分析
- 整体来说,效果还算不错
- 大多数人进了缅北的人,并没有成为潘生,多数是悲惨的一生
- 珍爱生命,远离诈骗,远离赌博!

写在最后
参考文献
- 三岁大佬的基于Ernie-3.0的电影评论情感分析
- ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
- PaddleNLP Transformer预训练模型
- PaddleNlp-Github
作者简介
- 作者为一名在校大三学生,人工智能专业
- 学习方向:深度学习和计算机视觉
- 百度飞桨PPDE,百度飞桨领航团成员,阿里云开发者社区博客专家,csdn人工智能领域新星创作者 万粉博主
- Github主页:https://github.com/lzypython
- 个人博客主页:https://www.lizhiyang.xyz/
- CSDN主页:https://lizhiyang.blog.csdn.net/
欢迎关注,交流学习!
最后给大家推荐强化学习的一本书:理论完备,涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点实战性强,每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;配套丰富,逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学。


)






![[静态时序分析简明教程(十一)]浅议tcl语言](http://pic.xiahunao.cn/[静态时序分析简明教程(十一)]浅议tcl语言)










