原文网址
参考网址
请你来说一下map和set有什么区别,分别又是怎么实现的?
- map和set都是C++的关联容器,其底层实现都是红黑树(RB-Tree)。由于 map 和set所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 map 和set的操作行为,都只是转调 RB-tree 的操作行为。
map和set区别在于
- (1)map中的元素是key-value(关键字—值)对:关键字起到索引的作用,值则表示与索引相关联的数据;Set与之相对就是关键字的简单集合,set中每个元素只包含一个关键字。
- (2)set的迭代器是const的,不允许修改元素的值;map允许修改value,但不允许修改key。其原因是因为map和set是根据关键字排序来保证其有序性的,如果允许修改key的话,那么首先需要删除该键,然后调节平衡,再插入修改后的键值,调节平衡,如此一来,严重破坏了map和set的结构,导致iterator失效,不知道应该指向改变前的位置,还是指向改变后的位置。所以STL中将set的迭代器设置成const,不允许修改迭代器的值;而map的迭代器则不允许修改key值,允许修改value值。
- (3)map支持下标操作,set不支持下标操作。map可以用key做下标,map的下标运算符[ ]将关键码作为下标去执行查找,如果关键码不存在,则插入一个具有该关键码和mapped_type类型默认值的元素至map中,因此下标运算符[ ]在map应用中需要慎用,const_map不能用,只希望确定某一个关键值是否存在而不希望插入元素时也不应该使用,mapped_type类型没有默认值也不应该使用。如果find能解决需要,尽可能用find。
请你来介绍一下STL的allocaotr
- STL的分配器用于封装STL容器在内存管理上的底层细节。在C++中,其内存配置和释放如下:
- new运算分两个阶段:(1)调用::operator new配置内存;(2)调用对象构造函数构造对象内容
- delete运算分两个阶段:(1)调用对象析构函数;(2)调用::operator delete释放内存
- 为了精密分工,STL allocator将两个阶段操作区分开来:内存配置有alloc::allocate()负责,内存释放由alloc::deallocate()负责;对象构造由::construct()负责,对象析构由::destroy()负责。
- 同时为了提升内存管理的效率,减少申请小内存造成的内存碎片问题,SGI STL采用了两级配置器,当分配的空间大小超过128B时,会使用第一级空间配置器;当分配的空间大小小于128B时,将使用第二级空间配置器。第一级空间配置器直接使用malloc()、realloc()、free()函数进行内存空间的分配和释放,而第二级空间配置器采用了内存池技术,通过空闲链表来管理内存。
参考链接
- 标准库 STL :Allocator能做什么?
- C++中std::allocator的使用
- 第10篇:C++ 堆内存管理器-allocator

请你来说一说STL迭代器删除元素
- 这个主要考察的是迭代器失效的问题。
- 1.对于序列容器vector,deque来说,使用erase(itertor)后,后边的每个元素的迭代器都会失效,但是后边每个元素都会往前移动一个位置,但是erase会返回下一个有效的迭代器;
- 2.对于关联容器map set来说,使用了erase(iterator)后,当前元素的迭代器失效,但是其结构是红黑树,删除当前元素的,不会影响到下一个元素的迭代器,所以在调用erase之前,记录下一个元素的迭代器即可。
- 3.对于list来说,它使用了不连续分配的内存,并且它的erase方法也会返回下一个有效的iterator,因此上面两种正确的方法都可以使用。
请你说一说STL中MAP数据存放形式
- 红黑树。unordered map底层结构是哈希表
请你讲讲STL有什么基本组成
- 容器、算法、迭代器、函数对象、适配器、内存分配器这 6 部分构成,其中后面 4 部分是为前 2 部分服务的
| STL的组成 | 含义 |
|---|
| 容器 | 一些封装数据结构的模板类,例如 vector 向量容器、list 列表容器等。 |
| 算法 | STL 提供了非常多(大约 100 个)的数据结构算法,它们都被设计成一个个的模板函数,这些算法在 std 命名空间中定义,其中大部分算法都包含在头文件 <algorithm> 中,少部分位于头文件 <numeric> 中。 |
| 迭代器 | 在 C++ STL 中,对容器中数据的读和写,是通过迭代器完成的,扮演着容器和算法之间的胶合剂。 |
| 函数对象 | 如果一个类将 () 运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象(又称仿函数)。 |
| 适配器 | 可以使一个类的接口(模板的参数)适配成用户指定的形式,从而让原本不能在一起工作的两个类工作在一起。值得一提的是,容器、迭代器和函数都有适配器。 |
| 内存分配器 | 为容器类模板提供自定义的内存申请和释放功能,由于往往只有高级用户才有改变内存分配策略的需求,因此内存分配器对于一般用户来说,并不常用。 |
头文件
- <iterator> <functional> <vector> <deque> <list> <queue> <stack> <set> <map> <algorithm> <numeric> <memory> <utility>
注意事项
- 分配器给容器分配存储空间
- 算法通过迭代器获取容器中的内容
- 仿函数可以协助算法完成各种操作
- 配接器用来套接适配仿函数
参考链接
请你说说STL中map与unordered_map
Map映射
- map 的所有元素都是 pair,同时拥有实值(value)和键值(key)。pair 的第一元素被视为键值,第二元素被视为实值。所有元素都会根据元素的键值自动被排序。不允许键值重复。
- 底层实现:红黑树
- 适用场景:有序键值对不重复映射
Multimap
- 多重映射。multimap 的所有元素都是 pair,同时拥有实值(value)和键值(key)。pair 的第一元素被视为键值,第二元素被视为实值。所有元素都会根据元素的键值自动被排序。允许键值重复。
- 底层实现:红黑树
- 适用场景:有序键值对可重复映射
请你说一说vector和list的区别,应用,越详细越好
Vector
- 连续存储的容器,动态数组,在堆上分配空间,本质是链表
- 底层实现:数组
- 两倍容量增长:
- vector 增加(插入)新元素时,如果未超过当时的容量,则还有剩余空间,那么直接添加到最后(插入指定位置),然后调整迭代器。
- 如果没有剩余空间了,则会重新配置原有元素个数的两倍空间,然后将原空间元素通过复制的方式初始化新空间,再向新空间增加元素,最后析构并释放原空间,之前的迭代器会失效。
性能:
- 访问:O(1)
- 插入:在最后插入(空间够):很快
- 在最后插入(空间不够):需要内存申请和释放,以及对之前数据进行拷贝。
- 在中间插入(空间够):内存拷贝
- 在中间插入(空间不够):需要内存申请和释放,以及对之前数据进行拷贝。
- 删除:在最后删除:很快
- 在中间删除:内存拷贝
- 适用场景:经常随机访问,且不经常对非尾节点进行插入删除。
List
- 动态链表,在堆上分配空间,每插入一个元数都会分配空间,每删除一个元素都会释放空间。
- 底层:双向链表
性能
- 访问:随机访问性能很差,只能快速访问头尾节点。
- 插入:很快,一般是常数开销
- 删除:很快,一般是常数开销
- 适用场景:经常插入删除大量数据
区别
- 1)vector底层实现是数组;list是双向 链表。
- 2)vector支持随机访问,list不支持。
- 3)vector是顺序内存,list不是。
- 4)vector在中间节点进行插入删除会导致内存拷贝,list不会。
- 5)vector一次性分配好内存,不够时才进行2倍扩容;list每次插入新节点都会进行内存申请。
- 6)vector随机访问性能好,插入删除性能差;list随机访问性能差,插入删除性能好。
应用
- vector拥有一段连续的内存空间,因此支持随机访问,如果需要高效的随即访问,而不在乎插入和删除的效率,使用vector。
- list拥有一段不连续的内存空间,如果需要高效的插入和删除,而不关心随机访问,则应使用list。
请你来说一下STL中迭代器的作用,有指针为何还要迭代器
1、迭代器
- Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
- 由于Iterator模式的以上特性:与聚合对象耦合,在一定程度上限制了它的广泛运用,一般仅用于底层聚合支持类,如STL的list、vector、stack等容器类及ostream_iterator等扩展iterator。
2、迭代器和指针的区别
- 迭代器不是指针,是类模板,表现的像指针。他只是模拟了指针的一些功能,通过重载了指针的一些操作符,->、*、++、--等。迭代器封装了指针,是一个“可遍历STL( Standard Template Library)容器内全部或部分元素”的对象, 本质是封装了原生指针,是指针概念的一种提升(lift),提供了比指针更高级的行为,相当于一种智能指针,他可以根据不同类型的数据结构来实现不同的++,--等操作。
- 迭代器返回的是对象引用而不是对象的值,所以cout只能输出迭代器使用*取值后的值而不能直接输出其自身。
3、迭代器产生原因
- Iterator类的访问方式就是把不同集合类的访问逻辑抽象出来,使得不用暴露集合内部的结构而达到循环遍历集合的效果。
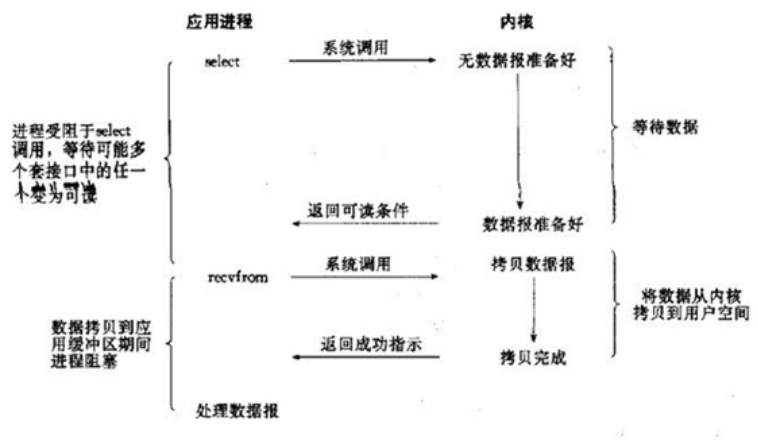
请你说一说epoll原理
- 调用顺序:
- int epoll_create(int size);
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
- 首先创建一个epoll对象,然后使用epoll_ctl对这个对象进行操作,把需要监控的描述添加进去,这些描述如将会以epoll_event结构体的形式组成一颗红黑树,接着阻塞在epoll_wait,进入大循环,当某个fd上有事件发生时,内核将会把其对应的结构体放入到一个链表中,返回有事件发生的链表。
参考链接
n个整数的无序数组,找到每个元素后面比它大的第一个数,要求时间复杂度为O(N)
#include <iostream>
#include <vector>
#include <stack>
using namespace std;//n个整数的无序数组,找到每个元素后面比它大的第一个数,要求时间复杂度为O(N)
vector<int> find(vector<int> &num)
{int len = num.size();//空数组,返回空if(len == 0)return {};stack<int> notFind;//栈:num中还未找到符合条件的元素索引vector<int> res(len, -1);//返回结果:初始化-1,表示未找到int i = 0;while(i < len)//遍历数组{//如果栈空或者当前num元素不大于栈顶,将当前元素压栈,索引后移if(notFind.empty() || num[notFind.top()] >= num[i])notFind.push(i++);else//有待处理元素,且num当前元素大于栈顶索引元素,符合条件,更新结果数组中该索引的值,栈顶出栈。{res[notFind.top()] = num[i];notFind.pop();}}return res;
}int main()
{vector<int> num = {1, 3, 2, 4, 99, 101, 5, 8};// vector<int> num = {1, 1, 1, 1, 1, 1, 1};// vector<int> num = {};vector<int> res = find(num);for(auto i : res)cout << i << " ";return 0;
}
请你回答一下STL里resize和reserve的区别
- resize():改变当前容器内含有元素的数量(size()),eg: vector<int>v; v.resize(len);v的size变为len,如果原来v的size小于len,那么容器新增(len-size)个元素,元素的值为默认为0.当v.push_back(3);之后,则是3是放在了v的末尾,即下标为len,此时容器是size为len+1;
- reserve():改变当前容器的最大容量(capacity),它不会生成元素,只是确定这个容器允许放入多少对象,如果reserve(len)的值大于当前的capacity(),那么会重新分配一块能存len个对象的空间,然后把之前v.size()个对象通过copy construtor复制过来,销毁之前的内存;
- vector 的reserve增加了vector的capacity,但是它的size没有改变!而resize改变了vector的capacity同时也增加了它的size!
- 原因如下: reserve是容器预留空间,但在空间内不真正创建元素对象,所以在没有添加新的对象之前,不能引用容器内的元素。加入新的元素时,要调用push_back()/insert()函数。
- resize是改变容器的大小,且在创建对象,因此,调用这个函数之后,就可以引用容器内的对象了,因此当加入新的元素时,用operator[]操作符,或者用迭代器来引用元素对象。此时再调用push_back()函数,是加在这个新的空间后面的。
- resize增加大的容量超过reserve,会将capacity和size一样
- resize减少容量 不会影响到capacity
- 通过 shrink_to_fit 将capacity保持和size一致的大小
参考链接
测试代码
#include <iostream>
#include <vector>
using namespace std;
int main() {vector<int> a;a.reserve(100);a.resize(50);cout<<a.size()<<" "<<a.capacity()<<endl;//50 100a.resize(150);cout<<a.size()<<" "<<a.capacity()<<endl;//150 150a.reserve(50);cout<<a.size()<<" "<<a.capacity()<<endl;//150 150a.reserve(200);cout<<a.size()<<" "<<a.capacity()<<endl;//150 200a.resize(50);cout<<a.size()<<" "<<a.capacity()<<endl;//50 200a.shrink_to_fit();cout<<a.size()<<" "<<a.capacity()<<endl;//50 50
}
请你说一说stl里面set和map怎么实现的
- 集合,所有元素都会根据元素的值自动被排序,且不允许重复。
- 底层实现:红黑树
- set 底层是通过红黑树(RB-tree)来实现的,由于红黑树是一种平衡二叉搜索树,自动排序的效果很不错,所以标准的 STL 的 set 即以 RB-Tree 为底层机制。又由于 set 所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 set 操作行为,都只有转调用 RB-tree 的操作行为而已。
- 适用场景:有序不重复集合
- map映射。map 的所有元素都是 pair,同时拥有实值(value)和键值(key)。pair 的第一元素被视为键值,第二元素被视为实值。所有元素都会根据元素的键值自动被排序。不允许键值重复。
- 底层:红黑树
- 适用场景:有序键值对不重复映射





![C语言二维数组 int arr[2][3]](https://img-blog.csdnimg.cn/6ad7df989fab4a41b46f1fe84e6ace6a.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ1NDAyOTE3,size_16,color_FFFFFF,t_70)


![C语言 指针数组-字符指针数组整型指针数组 char*s[3] int*a[5] 数组指针int(*p)[4]](https://img-blog.csdnimg.cn/4549e7d2de1c486888026243c597a3d3.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ1NDAyOTE3,size_16,color_FFFFFF,t_70)