本系列用大白话,手把手带你实现上百个BAT公司内部真实的常用中型系统。评论抽奖送书
与培训班/营销号/忽悠人的低水平作者,不同的是:
保证听懂(小白也可以,这是我的一贯风格,字典式小白式的输出,大家容易交流)
绝对真实(保证业内调查过、BAT级别公司实现过,有的作者异想天开的自嗨,能看到一堆漏洞)
欢迎讨论(你进步我也进步,最好怼死我,让我知道我是井底之蛙)
什么?你问我为啥只写中型系统不写大型系统?第一,我自己还没玩明白呢就不误人子弟了。第二、大系统敏感信息很难完全清干净,怕被告。第三、能真正看懂的人也少。
一、背景
引子是让你明白本文可以作为供应商/合作方管理系统的实现,你也可以应用在其他系统中。
首先,读者应该明白,现如今独自一套系统就能服务于用户的情况很少,大多都要请求本系统外的其它系统(这些系统可能是内部的或是外部的),大家互相交互才形成了可以服务于真正用户的互联网功能,我随便举几个例子:
1)腾讯视频做的,开通腾讯会员+任意合作方会员的组合,需要和多个合作方(酷狗、酷我、体育)的系统进行交互。
2)腾讯自选股(或者任何买卖股票的app),他可能自己卖股票吗?不可能的,内部对接了不知多少券商(业内一般称为“上游”,即实际提供服务方)
3)支付宝/微信充话费,是支付宝自己能操作你手机号里的钱吗?不是,是支付宝对接了移动联通电信三大运营商,包括全国总公司、省级分公司、市级供货商等等
这也引出了一个问题:你内部系统的服务质量,基本依赖于你的对接方系统质量。
比如,我们内部系统做的特别好,0.01秒就为用户做好了一切工作,有用吗?并没有,因为真正提供服务的是你的合作方(上文提到的炒股app对券商、支付宝充话费对中国移动,以下统称为合作方),如果合作方的系统特别烂,买个股票永远成交失败,冲个话费三天才到账,你的系统再好也没有。
二、需求分析
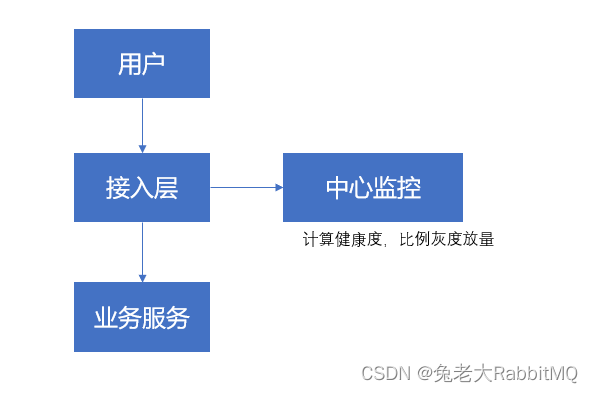
基于上文提到的背景,大部分公司都会有这么一种诉求:健康度系统,它可以识别外部系统的健康度,并根据健康度控制流量。
说简单点就是,你(合作方)系统老是办理失败,那我就不让用户从你的系统办了,否则降低收入不说(因为成功率低),我的用户还会骂我(还是成功率低/耗时高)。
三、目标明确
目标很明显,只要我们知道某个合作方是不健康的,就生成一条记录,代表他被打入冷宫,我们的系统查到记录就不会让用户访问它。
当然,完全自动识别健康度是不可靠的(毕竟是机器),我们必须有人工介入的手段,首先我们允许合作方主动通知我们系统不健康(比如在维护升级、在调整东西、服务出问题、不在交易时间内等等),我们得到这个消息就可以做相应的调整(不让用户看到他家产品)
目标一:正确接收到合作方系统不健康的消息
其次,也不能完全信合作方的操作,我们系统内部也要有人为干预的手段,方便我们管理。比如我们观察到某个合作方质量很差,就手动给他标为不健康。如果我们和某个合作方挣钱很多,就算质量差,我们可能也会手动给他删除不健康记录。
目标二:系统内部可以操作不健康消息(增加/删除/修改/查询)
保证两边人工操作没问题后,我们再做自动识别:
目标三:系统自动识别不健康合作方,并生成不健康记录
有心人看到这里肯定会问了:你这不健康就永远不合作了?永远打入冷宫了?当然不是,我们识别到健康度达标(可能人家系统恢复了、优化了),要继续让用户来这个合作方消费。
目标四:系统自动识别健康度再次达标的合作方,并删除不健康记录
至此,我们的功能就算是说完了,接下来分析一下我们的系统需要注意的问题
四、系统设计重点
大部分系统的重点一般在:性能、可用性、安全三方面来说。
4.1 性能
因为考虑到每个用户请求进来,都要获取各个合作方的健康度信息(为了动态推荐商品之类的),为了速度考虑,最好所有信息都在某块内存(redis),可以直接查到。
所以我们最好将所有的数据生成工作提前做好,这里包括但不限于:
1)获取合作方提供的健康度信息(不可能每个用户请求都去请求合作方系统)
2)判断健康度需要的数据的获取(包括是否连通、成功率、平均耗时、配置等)
3)健康状态的判断和灰度逻辑(不可能每个用户请求来现场算是否健康)
4)健康状态信息缓存(存redis加快读取速度)
4.2 可用性
需要明白的是,我们的系统始终是一个可旁路系统,首先要考虑我们的系统挂了或者经常超时怎么办?绝对不能影响主系统主流程的运行。
为了达到这个目的,我们可能的策略包括但不限于:
1)某些降级策略,如健康度功能不可用时,根据配置的默认顺序来推荐合作方。
2)可配置超时时间,按时没运行完也要返回
其次,我们要保证误判尽量的少,保证最大的正确性,为此,我们可能的策略是:
1)合理的判定不健康算法、平滑的过渡方式
2)判断健康的所有指标都可配置,实现精细化运行,根据具体合作方的实际情况配置。
4.3 安全
保证和外部交互健康度数据、内部存储健康度数据都是安全的。
和外部交互时:签名+加密
内部存储时:签名
这里普及一些基本知识,后续文章不会再提:大家提到安全老是说签名和加密,他们的作用是不同的。
签名主要功能是防篡改,是无限集合(真实内容)向有限集合(签名)的映射,根据签名是无法还原内容的,接收方收到内容后,按约定的算法和密钥算出签名,和收到的签名一样就是没被篡改。
加密主要功能是防泄漏,是无线集合向无限集合的映射,因为陌生人即使拿到了整个消息,依旧看不懂写的什么,而接收方解密拿到明文可以进行处理。
至于签名和加密的算法的种类本系列也不会再科普,可以自己上网搜一下。
五、方案设计概述
由于功能较多,我们大概分两阶段实现:
第一步先把合作方和本系统内部的人为干预手段做好,并且搭起基本架构,开始对外提供服务(即,其他服务可查询合作方是否健康了)
第二步我们再把自动判定健康的数据获取、判定健康、根据健康度控制流量等功能补齐。
为了方便,我们把代表某合作方不健康的一条记录,称为“公告”,
意思是我(合作方)发公告告诉所有关心的模块:我不健康了
六、手动设计
为了方便理解方案,一种可能的基本存储结构是这样的:
6.1 db存储结构
create table xxtable
(Fid bigint not null auto_increment,F***_id varchar(64) not null default '' comment '供应商id',F***_id varchar(64) not null default '' comment '公告id',Fcreatetime DATETIME not null comment '公告创建时间',Fupdatetime DATETIME not null comment '公告更新时间',Fuserid varchar(64) not null default '' comment '操作用户id',Fbegintime DATETIME not null comment '公告开始时间',Fendtime DATETIME not null comment '公告结束时间',Fty int unsigned not null default 0 comment '类型0:运营商1:后台2:自动’,Fstatu int unsigned not null default 0 comment '状态 0:无效 1:生效中',Fchanged_count
);当然,这是基本字段,有需要你再加。
ckv的区别是增加一个合作方公告开关
6.2 Ckv存储结构
//不健康信息
//供应商公告keykey: {"ID":"xxservice_gddianxin"}//前缀+供应商id //Boss后台配置的公告keykey: {"ID":" xxservice_gddianxin_boss"}//前缀+供应商id+后缀value: [ { "":"gddianxin", //供应商id "ID":"123123123", //记录序列id "begin":"2020-7-2 00:00:00", //开始时间 "end":"2020-7-3 00:00:00", //结束时间 "eff":true //是否生效,部分供应商可能存在取消的情况 }] //公告开关key: //前缀+供应商id+后缀{"ID":"xxservice_gddianxin_flag "} value:1(2)//1:打开,2:关闭6.3 协议设计
和合作方交互的接口可能长这个样子:
我方请求合作方:
1. <?xml version="1.0" encoding="UTF-8"?>
2. <req>
3. <timestamp>1514736000</timestamp>
4. <signmsg>XXX</signmsg>
5. <channel>zhifubao</channel>
6. </req>
合作方的返回(解密后):
1. <?xml version="1.0" encoding="UTF-8"?>
2. <rtn>
3. <code>0</code>
4. <msg>同步成功</msg>
5. <channel>0</channel>
6. <upgradeInfo>
7. <item>
8. <upgradeID> UC-051-20200702-96038</upgradeID>
9. <upgradeContent>系统故障</upgradeContent >
10. <beginTime>2020-7-2 00:00:00</beginTime>
11. <endTime >2020-7-3 00:00:00</endTime>
12. <effective>true</effective>
13. </item>
14. <item>
15. <upgradeID> UC-051-20200703-96000</upgradeID>
16. <upgradeContent>系统升级</upgradeContent >
17. <beginTime>2020-7-3 00:00:00</beginTime>
18. <endTime >2020-7-4 00:00:00</endTime>
19. <effective>true</effective>
20. </item>
21. </upgradeInfo>
22. </rtn>
Code是返回码,upgradeInfo是公告列表,含有多个公告主体。公告主体含有升级序列id、升级内容、开始时间、结束时间、生效标志等字段。注意:如某公告被取消,不应在运营商返回的报文中直接消失,而是应将effective置为false;
科普一种可能用到的通信时加密签名算法-
sha256_HMAC作为签名的算法,案例如下:
第一步,假若传入如下参数:bank_type=WX;fee_type=1,body=XXX;
第二步,按照参数key值进行字典排序(按照字段名的ASCII 码从小到大排序),并且使用”&”作为分隔符,把参数串成字符串。bank_type=WX&body=XXX&fee_type=1;
第三步,用双方约好的密钥secret_key,对组装的字符串进行加密signmsg=sha256_HMAC_func(secret_key , bank_type=WX&body=XXX&fee_type=1)。
其它协议如:我方服务的查询接口、定时任务接口、合作方主动推送接口,请自行设计,字段都非常简单,不再说了。
定完协议我们可以看基本架构是什么样子
6.4 架构设计
在设计前,我们再次明确之前提到的设计重点:性能、可用性、安全,忘了的同学翻上去看。
基于性能考虑,我们需要读写分离,读操作直接读redis,节省时间。
基于可用性考虑,我们的定时任务链路和查询都需要层层注意。
基于安全考虑(信息的安全和服务本身的安全),我们的外部交互协议和运营后台很重要。
基于这些考虑,设计是这样的:

介绍一下模块:
定时任务负责定时触发查询
运营商接入服务负责调取运营商接口,向上屏蔽运营商接口的不一致性,对内提供标准接口。同时方便做一些安全的校验。
公告服务提供核心的查询和写入功能。
了解模块后,详细解释一下三条链路的策略:
(性能读redis很快就不说了,主要是挑战1:可用,挑战2:安全)
首先看定时任务链路(左方蓝线):
1)定时任务请求获取公告接口。它应部署在多台脚本机,如果其中一台出现问题,其它机器依然正常工作。万一真的都挂了,就要触发监控和报警,通过微信或电话直接提示负责人,尽快解决问题。
2)链路往下走,获取公告接口,负责调用运营商接入服务获取信息,并写入redis。
3)而运营商接入服务,负责调取运营商接口,向上按标准参数返回。由于查询的无状态,可以多机部署,某台机器挂了可以自动切量。
总体看一下这条链路,各模块有自己的机制保证可用性,如果确实整条链路失效了,公告信息就会暂停更新,不会造成更坏的影响。
然后看查询主链路(中间红线):
1)和其他服务交互部分,请求查询公告接口。如果请求异常,会有降级策略:返回系统未维护。另外由于查询是无状态的,多机部署(采用类cl5的策略)保证可用性。
2)链路往下走,查询公告接口,它会查询公告信息redis,然后返回结果。这里对查询结果的各种情况的处理就非常关键。
对于明确成功的结果,就正常返回。对于超时、明确失败、未知情况,都会有降级策略,返回运营商未维护。其中,对于超时情况,笔者设置了超时时间为50ms,保证主链路不会耗时过长。
笔者解决了第一个挑战,再看第二个挑战 是由运营后台链路(右方黑线)加入了人工干预手段,保证了系统故障时有人为干涉的兜底策略。
总体看笔者的系统:除了redis其他地方都是无状态的,所以可以多机部署,任何机器出现问题,都会有其他机器保证可用。而对于redis,笔者有查询降级策略和设置超时时间,即使挂了也不影响主链路。所以总体来说,笔者解决了上面提到的两个挑战。
七、自动设计
刚才我们实现了人工干预手段和公告服务的基本框架,接下来我们完善自动健康度的功能。
那么一个健康度系统的第一步,就是如何判定不健康。
7.1 准备需要的信息
我们需要读到成功率、耗时、探测等数据,考虑到不能因为新系统需要的操作就影响老流程,我们必须做成异步写的,下面我列举几种可能的方法:
7.1.1 其他服务写redis
数据是由redis存储的,记录分钟内请求成功失败数量,最后一次请求是否成功,下面是某示例:
Key 供应商_id + 接口 + 时间 + req_num
key: Gmccactive_order_202010101500_req_num
value: 22
key: Gmccactive_order_202010101500_succ_num
value: 50
key:Gmccactive_last_req
value: 1当然,写操作可以自己决定一下是否异步。
可以自己实现异步,也可以同步(毕竟写redis操作还是挺快的)
7.1.2 其他服务生产消息
让其他服务放一个消息在消息队列里(rabbitmq、kafka等),里面有本次请求成功失败和耗时,公告服务来消费即可。
7.1.3 公告服务读DB
一般情况下,其它系统都会有订单DB、请求流水DB、日志DB等等,如果评估可以使用,就不需要别的服务上报,配置脚本去捞DB信息即可。
7.1.4 建议
一般情况下我建议你方法1和方法2中选择方法1(毕竟一个redis物尽其用,没必要引入消息队列)
剩下这两种方案各有利弊,实时上报单次计算成功率的耗时更少,但是需要暂存下单数据,会影响下单流程。而拉流水不用暂存数据也不会影响下单流程,但是单次计算成功率耗时会多一些,包括了拉取流水和计算。
7.2 判定不健康

挂起公告实例图
(1)探测、多维度检测实时成功率、耗时进行判断。
(2)大概的代码逻辑应该是这样:
if 探测失败次数高于阈值:挂起公告
if 请求量大于阈值 and (成功率低于某阈值 or 耗时高于某阈值):挂起公告。这两方面分别保证的系统正常(ping通就可以)和业务正常(具体成功率耗时达标)。
7.3 如何探测
7.3.1 类CL5健康度方案:

类CL5健康度方案图
每隔1个周期ping探测运营商接口联通性,如果ping成功,则开始放量真实量,统计周期内失败数量与失败率,如果高于阈值时按照一定比例开始恢复。
单机方案在此场景不可用,因为Ping 探测接口连通性,不能解决业务错误问题。
7.3.2 全局灰度方案:
全局灰度方案图
由健康度服务进行选择灰度放量,进行真实量探测。当成功量上升时,灰度比例增大到直接放开;当成功率下降时,灰度比例下降,延长时间。
经评估缺点如下:损失业务真实量、开发成本较高、量级波动大时,成功率变化时,会出现反复较少放大比例的问题。
7.3.3 重放线上真实量
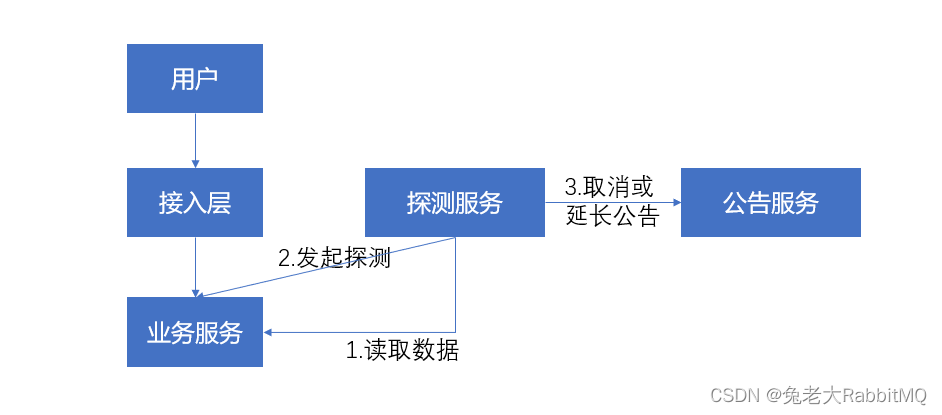
图3-8 重放线上真实量图
获取线上真实请求,周期内进行n次重试,计算成功率,连续m个周期内,成功率达标后,放开公告。优点是用户无感知,实时性高,但是如果用户未黑名单用户,可能会误以为系统异常。
对于重放的接口有多种选择,重放办理接口和重放查询接口的选择:只能是重放查询接口,因为部分运营商不支持幂等,重复办理风险。(就是存在一人重复办理多笔单的风险,但只是查询商品就无所谓)。
既然恢复可以用重放探测,笔者提出一个假设:一直重放,仅按照重放的量来计算如何挂公告。因为部分运营商在办理成功后,下次查询就会失败。而且对于量小的运营商,重放量可能大于正常量。因此,不适合只用重放量来计算健康度。
提示:因为考虑法律问题,我们没有权利替用户发起任何请求请求,包括查询商品请求,所以方案三一般不考虑。
7.3.4 总结
如果不考虑方案三的话,可能比较优秀的做法就是方案1+方案2结合起来看,稍作修改即可。
方案2的缺点正好可以被方案1弥补,我们先做探测,如果达标再进行方案2的灰度。
大概的流程粗略看可能是这样:

7.4 完成设计
有了大概思路,我们应该把所有的想法用公式和图表示出来:


关于更具体的代码,我希望你能自己写出来,我在这里提供一种简单的方法,你可以把心里的详细状态扭转全部画出来,然后转化成表格形式,我们剩下的工作就这是看着表格写代码而已,非常方便。(只是自动机的一点用法,acm大佬可忽略)


小提示:如果对这种思想比较感兴趣,我想你一定做过leetcode第八题,字符串转换整数 (atoi),可以看看这个题解来入门这种思想:题解
八、总结和QA
8.1 全局架构图
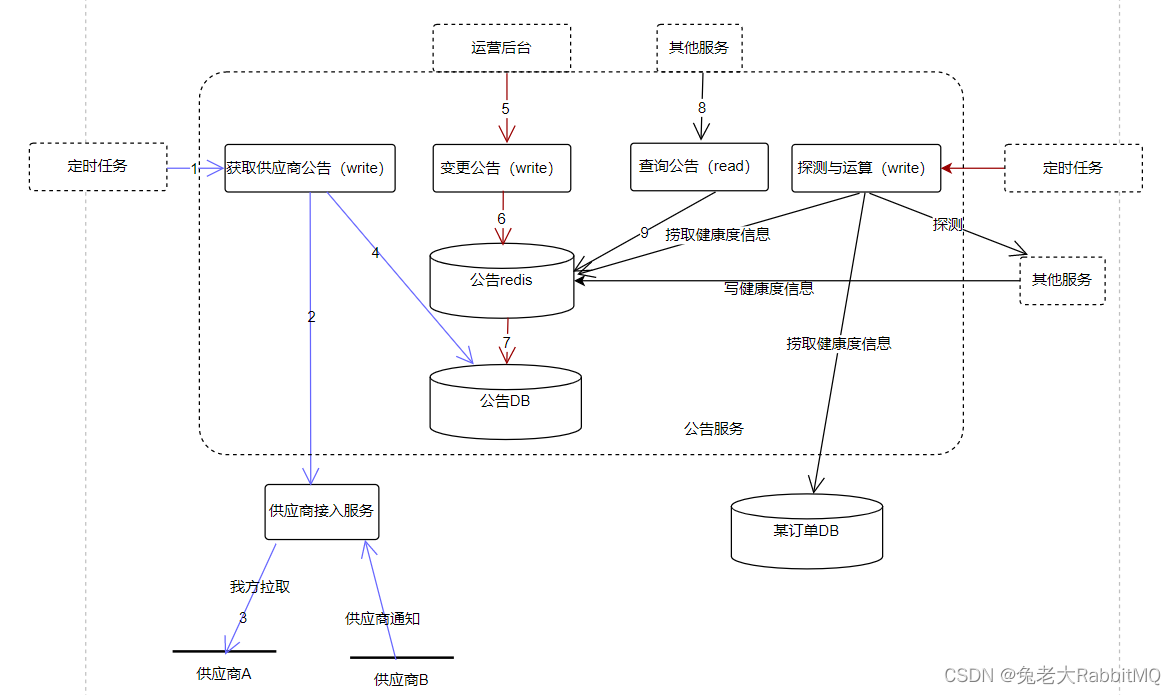
8.2 为何让其他服务直接操作redis?
刚说了不使用消息队列是因为嫌麻烦。
同时,其他服务也不是直接操作redis,它们也并不知道怎么操作。肯定是公告服务提供的接口呀。(图中没画了)
8.3 说为了安全要加密外部交互信息,但文中协议没有
是为了让读者理解,协议是解密之后的明文。
8.4 看完还是一脸懵,不会写
实在有需要可以找我,我可能会给你时序图之类的资料,但是代码不可以。
8.5 为何必须有redis缓存?我想结构简单一点
如果你想服务内本地缓存,也可以,只是缓存命中率会比较低,因为真实环境动辄几十上百个进程。

定时系统(延时队列))

)






【上】)

【下】)






