明天考试去,滚吧
提醒与分值:1*40(选择)+5*3(填空)+10+15+20
比如今年的一个题目是要求随机抽一个手机品牌,这道题目的关键点在于你要使用seed()函数覆盖原来的给定的种子seed(1),因为要求“随机”,假如你只用了random,结果是不会随机的,因为seed(1)这个种子控制了random必然出现的是同一个结果,所以自己为了保险起见,可以自己多调试几次;再来说说4-5题是简单应用题,这2个题目也不难,比如就是分段函数用if等待,或者是turtle画图的函数,这些只要搞清楚,turtle画图的角度,长度,画笔等等基本都没问题。
可以说,最难的是最后一道题目,要想获得优秀或者及格,这道题目基本奠定了整体,只要你这道题没做出来,估计前面再错的比较多,那就有点危险了;好了,再说说这道题是怎么出的,一般是分词或者是排序,或者是整理数据,文件io之类的,这种题目需要比较扎实的基础,如果想要优秀,毋庸置疑,这道题目必须做对;一般情况下,题目会给出基本的代码框架,一般的这道题目是可以修改代码的(按照自己的思路,当然具体要求还是要看题目给出),这种题目是结果导向的,也就是说只要运行结果对了,它就判对,但是如果你人工操作得到答案肯定是不行的,一方面,数据量大没法操作,另一方面,系统判分系统应该会识别你是否通过运行python得到结果,所以投机取巧的心态就不要有了。好好复习吧。
错题记录:选择题
2. 关于线性链表?的描述,以下选项中正确的是
A存储空间不一定连续,且前件元素一定存储在后件元素的前面
B存储空间必须连续,且前件元素一定存储在后件元素的前面
C存储空间必须连续,且各元素的存储顺序是任意的
D存储空间不一定连续,且各元素的存储顺序是任意的
3. 在深度为 7 的满二叉树?中,叶子结点的总个数是
A 31 B 64 C 63 D 32
百度:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。从图形形态上看,满二叉树外观上是一个三角形。
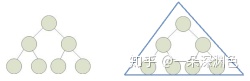
从数学上看,满二叉树的各个层的结点数形成一个首项为1,公比为2的等比数列。某节点的深度是指从根节点到该节点的最长简单路径边的条数
高度是指从该节点到叶子节点的最长简单路径边的条数
以图为例:

以上分析全是废话:只需要知道树是什么;深度是什么(这里就是层数);满二叉树是什么;叶子是什么就够了;2^(7-1)
6. 关于软件危机?,以下选项中描述错误的是
A 软件成本不断提高
B 软件质量难以控制
C 软件过程不规范?不知道搞软件的都在干啥,可能……也能理解
D 软件开发生产率低
8. 以下选项中用树形结构表示实体之间联系的模型?是
A 网状模型 B 层次模型 C 静态模型 D 关系模型
对层次,网状,想想结构
关系模型中的一些术语:
1)关系:一个关系对应通常说的一张表;
2)元组:表中的一行即为一个元组;
3)属性:表中的一列即为一个属性,给每一个属性起一个名称即属性名;
4)码:也称为码键,表中的某个属性组,它可以唯一确定一个元组;
5)域:一组具有相同数据类型的值的集合。属性的取值范围来自某个域;
6)分量:元组中的一个属性值。
7)关系模式:对关系的描述,一搬表示为:关系名(属性1,属性2,…,属性n)
关系模型的数据操纵与完整性约束
关系模型的数据操纵主要包括查询、插入、删除和更新数据,它的数据操纵是集合操作,操作对象和操作结果都是关系。
这些操作必须满足关系的完整性约束条件:实体完整性、参照完整性和用户定义的完整性。
18. 关于 Python 字符串,以下选项中描述错误的是 选A
A 可以使用 datatype() 测试字符串的类型?
B 输出带有引号的字符串,可以使用转义字符
C 字符串是一个字符序列,字符串中的编号叫“索引”
D 字符串可以保存在变量中,也可以单独存在(?可能是说可以print出来的意思)
22. 关于 Python 组合数据类型,以下选项中描述错误的是
A 组合数据类型可以分为 3 类:序列类型、集合类型和映射类型
B 序列类型是二维元素向量,元素之间存在先后关系,通过序号访问
C Python 的 str、tuple 和 list 类型都属于序列类型
D Python 组合数据类型能够将多个同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序、更容易
组合数据类型:
序列类型 (字符串、元组、列表)
集合类型 (集合)
映射类型 (字典)
25. 以下选项中不是 Python 对文件的写操作方法?的是 选C
A writelines
B write 和 seek?seek()方法用于移动文件读取指针到指定位置。
seek() 方法语法如下:
fileObject.seek(offset[, whence])
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
(donot care)C writetext?
D write
31.下面代码的输出结果是
x = 0o1010print(x)A 520
B 1024
C 32768
D 10
正确答案: A?o八进制;暴力运行就行了
32.下面代码的输出结果是 猜的
x=10y=3print(divmod(x,y))A (1, 3)
B 3,1
C 1,3
D (3, 1)
正确答案: D(直接在idle试试就好了,没必要记)
divmod(x, y, /) Return the tuple(x//y, x%y). Invariant: div*y + mod ==x.
33. 下面代码的输出结果是
for s in"HelloWorld":if s=="W":continue ?print(s,end="")A Hello
B World
C HelloWorld
D Helloorld(this is continue……,跳过条件,继续执行循环)
正确答案: D
34.给出如下代码:
DictColor ={"seashell":"海贝色","gold":"金色","pink":"粉红色","brown":"棕色", "purple":"紫色","tomato":"西红柿色"}以下选项中能输出“海贝色”的是
A print(DictColor.keys())
B print(DictColor["海贝色"])
C print(DictColor.values())
D print(DictColor["seashell"])
正确答案: D(cv and idle)
35. 下面代码的输出结果是(列表切片?)
s =["seashell","gold","pink","brown","purple","tomato"]
print(s[1:4:2])?(1到4-1,间隔2)A ['gold', 'pink', 'brown']
B ['gold', 'pink']
C ['gold', 'pink', 'brown', 'purple','tomato']
D ['gold', 'brown']
正确答案: D
36. 下面代码的输出结果是
d ={"大海":"蓝色", "天空":"灰色", "大地":"黑色"}
print(d["大地"], d.get("大地", "黄色"))?A 黑的 灰色
B 黑色 黑色
C 黑色 蓝色
D 黑色 黄色
正确答案: B don‘t care “黄色”
37. 当用户输入abc时,下面代码的输出结果是
try:n = 0n = input("请输入一个整数: ")def pow10(n):return n**10
except:print("程序执行错误")A 输出:abc
B 程序没有任何输出
C 输出:0
D 输出:程序执行错误
正确答案: B
请仔细看代码,def定义后的函数并没有执行,仅仅是干扰
39.文件 book.txt 在当前程序所在目录内,其内容是一段文本:book,下面代码的输出结果是
txt =open("book.txt", "r")
print(txt)
txt.close()A book.txt
B txt
C 以上答案都不对
D book
正确答案: C
打印文本文件对象的时候绝对不是这样的,而是类似于 <_io.TextIOWrapper name='book.txt'mode='r' encoding='utf-8'>
选择题到这暂停:
note:凡是可以暴力运行的,不允许出错!
重点是最后一个操作:
前面的只是练练手:
1.数字格式化
下表展示了 str.format() 格式化数字的多种方法:
>>> print("{:.2f}".format(3.1415926));
3.14| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11)'{:o}'.format(11)'{:x}'.format(11)'{:#x}'.format(11)'{:#X}'.format(11) | 1011 1113b0xb0XB | 进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,
print ("{} 对应的位置是 {{0}}".format("runoob"))
输出结果为:
runoob 对应的位置是 {0}考点:格式控制符
2.jieba库
支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,
pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade。PaddlePaddle官网
主要功能
- 分词
jieba.cut方法接受四个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型;use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射
ps:中文标点也是中文字符!
考点:jieba使用
再看看下面这个东西……
0x4DC0 是一个十六进制数,它对应的 Unicode 编码是中国古老的《易经》六十四卦的第一卦,请输出第 51 卦(震卦)对应的 Unicode 编码的二进制、十进制、八进制和十六进制格式。
don't care 0x4DC0 是个啥……
答案:print("二进制{0:b}、十进制{0}、八进制{0:o}、十六进制{0:x}".format(0x4DC0+50))
3.turtle库:入门级的图形绘制函数库
空间坐标体系&角度坐标体系:画布上真实游走的一海龟
rgb色彩体系:略
前者:海龟坐标;绝对坐标;前者:初始向右,x轴;后者:略
后者:略
函数:
1、运动命令forward(a) 向前移动a长度 fd(d)backward(a) 向后移动a长度 bk(d)
circle(r,angle)
为海龟坐标
right(a) 向右转动a度left(a) 向左移动a度
海龟角度
goto(x, y) 移动到坐标(x, y)位置:最简单的画线方式
speed(speed) 笔画绘制速度[0, 10]
2、笔画命令up() 笔画抬起,移动会不绘图
down() 笔画落下,移动会绘图
setheading(a) 改变朝向a° seth(angle):只改变行进方向,参数为绝对角度
角度坐标体系
pensize(a) 画笔宽度a
pencolor(colorstr) 画笔颜色
reset() 回复所有设置,清空窗口,重置turtle状态
clear() 清空窗口,不重置turtle状态
circle(r[, e]) 绘制一个圆形,r为半径,e为次数(多少次画成圆)
begin_fill()
fillcolor(colorstr) 填充颜色
end_fill()
3、其他命令
done() 程序继续执行
undo() 撤销上一次动作
hideturtle() 隐藏海龟
showturtle() 显示海龟
screensize() 窗口尺寸全国计算机等级考试二级Python 语言程序设计考试大纲(2018 年版)
6. 了解Python 计算生态在以下方面(不限于)的主要第三方库名称:网络爬虫、数据分析、数
据可视化、机器学习、Web 开发等。3. 字符串类型及格式化:索引、切片、基本的format()格式化方法。
4. 字符串类型的操作:字符串操作符、处理函数和处理方法。
5. 类型判断和类型间转换。
3. 程序的循环结构:遍历循环、无限循环、break 和continue 循环控制。
4. 程序的异常处理:try-except。
四、函数和代码复用
1. 函数的定义和使用。
2. 函数的参数传递:可选参数传递、参数名称传递、函数的返回值。
3. 变量的作用域:局部变量和全局变量。五、组合数据类型1. 组合数据类型的基本概念。2. 列表类型:定义、索引、切片。3. 列表类型的操作:列表的操作函数、列表的操作方法。4. 字典类型:定义、索引。5. 字典类型的操作:字典的操作函数、字典的操作方法。
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |













)
--HASP运行环境)


函数详解)

