11.1 前言
統計的技巧與資料分析常常形影不離。一般統計使用加法、累加法、平均值,中間值等等,由於處理的對象是矩陣資料,故其基本統計之技巧已經廣為應用,其觀念也會在正常之運作中出現。統計學中比較特殊應用者為機率、亂數、常態分配等,而配合應用者為其相關之圖表。在MATLAB中,有一個統計學工具箱,內藏各種統計學上需要應用的指令,可以執行上述與統計學有關之內容。這些相關的指令大部份以M-檔案組成,所以可利用type 這個功能檢視其內容。甚至可以更改其檔案名稱與內容,增加自己需要的功能,使其成為新的指令。此外,有些指令尚搭配繪圖介面,因而可以在繪圖模式下,進行資料與圖之適配,形成具體的方程式或實驗式,以供未來研究者使用。
統計工具箱中提供約二百餘個指令檔案,其中對機率分配方面則提供廿餘種機率型態,每種均有其相關的函數,諸如:
- 機率密度函數(pdf)
- 累積分佈函數(cdf)
- 累積分佈函數之反函數
- 亂數產生器
- 均數與變異數
11.2.1平均值MEAN
統計學上對資料處理常用趨中的處理,求取均值或中間值等,均會取中的特徵。求取一個矩陣或向量之平均值時可用指令MEAN,其格式如下:
M=mean(A,dim)
若A為向量,其結果M為單一值,亦即向量中各元素之平均;若A為矩陣,則結果M為一列向量,其中元素為各行之平均值。dim為方向性參數,其預設值為1,表示結果係行向平均,故M為列向量;若dim=2,則係沿列向平均,結果M為行向量。例如:
A = [1 2 3; 3 3 6; 4 6 8; 4 7 7]
A =
1 2 3
3 3 6
4 6 8
4 7 7
M1=mean(A), M2=mean(A,2)
M1 =
3.0000 4.5000 6.0000
M2 =
2
4
6
6
11.2.2中間值median
中間值亦可利用平均值的指令型式求得,其正式指令名稱為median。但其求得之值若非正好中間值,則會以接近中間值之兩值加以平均,其結果與mean之平均值仍有不同,下面以前述之B矩陣為例,比較median 與mean兩者執行後之不同處。
M1=median(B),M2=mean(B)
M1 =
5.5000 5.5000 5.0000 6.0000
M2 =
5.0000 5.5000 4.7500 6.0000
其他的平均值則有:
幾何平均(geomean):各元素乘積再開總數之次方。中間有零值時,其結果為零。
調諧平均(harmmean):各元素倒數和之倒數乘以總數。
修剪平均(trimmean):去頭去尾再平均的方式,其頭尾部份為第二參數(%)之一半比例。
下面的例子為這些平均值的比較:
X=1:2:20
locate=[geomean(X) harmmean(X) mean(X) median(X) trimmean(X,25)]
X =
1 3 5 7 9 11 13 15 17 19
locate =
7.6139 4.6877 10.0000 10.0000 10.0000
由上述這些值看來,有些的結果相同,有些則因其分離的情況而有異。中間值及修剪平均值是不管偏異的大小,一般為避免有極端的數值的影響,採用這種平均法。
11.2.3最大值與最小值 MIN & MAX
要求一矩陣或向量中元素之最大與最小值時,其指令之型式如下:
C = max|min(A)
C = max|min(A,B)
C = max|min(A,[],dim)
[C,I] = max(...)
若A為向量,其結果C為單一值,亦即向量中各元素之最大或最小;若A為矩陣,則結果C為一列向量,其中元素為各行之最大或最小。dim為方向性參數,其預設值為1,表示結果係行向取得最大或最小,故C為列向量;若dim=2,則係沿列向操作,結果M為行向量。注意要dim之參數時,需加在第三位置。此外,在輸出項中,I表示最大或最小元素之位置,不過此項功能僅求最大值時適用。例如:
A= [7 2 3 4; 2 4 5 6; 4 6 8 5; 6 7 6 1];
[C,Index]=max(A)
A =
7 2 3 4
2 4 5 6
4 6 8 5
6 7 6 1
C =
7 7 8 6
Index =
1 4 3 2
在這個指令中,比較特殊的是兩個矩陣A與B之最大或最小比較,其結果C應為與A或B相同的矩陣,但比較A與B中對應元素間之最大與最小。例如:
B=[1 8 7 6;4 6 2 8;7 5 6 4;8 3 4 6]
[Cab]=min(A,B)
B =
1 8 7 6
4 6 2 8
7 5 6 4
8 3 4 6
Cab =
1 2 3 4
2 4 2 6
4 5 6 4
6 3 4 1
11.2.4變方值VAR
變方值為各樣本品與平均值差之平方和。又稱為變值常態檢定公式,其指令型式為var(X,1)。其計算之公式如下:
VAR(X)=[(X1-r)²+(X2-r)²+...+(Xn-r)²]/(n-1)
式中,n為其總項目,若n>1,則採用n-1以獲得無偏差之變方值。相關指令如下:
Y=var(X)
Y=var(X,1)
Y=var(X, w)
Y=var(X, w, dim)
Y=var(X)為執行上式計算之無偏差變方,Y=var(X,1)則採用n為除數。另w則為加權值向量,此權值必須為正值,且長度與X相同。
若X為矩陣時,通常預設為行向計算,但可以利用dim=2參數改為以列向為計算基礎,其結果為行向量。var指令會將其元素除以總和,因此權值總和為一。若w值為零,其結果如var(X);若為1則如var(X,1)。
範例
>> x=1:9
x =
1 2 3 4 5 6 7 8 9
>> var(x) %除以(n-1)
ans =
7.5000
>> var(x,1) %除以n
ans =
6.6667
>> w=[1 1 1 1 1 0.5 0.5 0.5 0.5] %設為權值,向量與x同
w =
1.0000 1.0000 1.0000 1.0000 1.0000 0.5000 0.5000 0.5000 0.5000
>> var(x,w)
ans =
5.9184
11.2.5標準差STD
標準誤差為各樣本品與平均值間之常態差,其值實際上為上述變方var執行結果之開方值,其計算公式如下:
11.2.6 共方差COV
共方差為兩向量之觀察值與其平均差之乘積和,其計算之函數定義如下:
cov(x1,x2)=E[(x1-u1)(x2-u2)]
其中 ui=Exi
根據上式,其相關指令格式為:
C = cov(X)
C = cov(x,y)
在COV之指令,若 X為向量,其回應值應為變方值。若其為矩陣,則各列為觀察值,各行則成為變數,而COV(X)則為共方矩陣。其對角線元素 DIAG(COV(X))即為每行之變方差向量。若將之排序後,即SQRT(DIAG(COV(X))),其結果為標準差之向量。以下為例:
>> x=[4 -2 1; 9 5 7]
C1=cov(x)
M=diag(cov(x))
sort(diag(cov(x)))
x =
4 -2 1
9 5 7
C1 =
12.5000 17.5000 15.0000
17.5000 24.5000 21.0000
15.0000 21.0000 18.0000
M =
12.5000
24.5000
18.0000
ans =
12.5000
18.0000
24.5000
COV(X,Y)則是求取 X與 Y兩等長度之向量之共方差, X與 Y兩向量即使為列向量亦會自動改為行向量,其效果等於COV( [X(:) Y(:)] )。這兩個指令均設法加以常態化,故母數除以N-1,以消除偏差。若要維持使用N為母數,則可增加參數1,即採用 COV(X,1) 或 COV(X,Y,1)指令之型式。
11.2.7相關係數 corrcoef
兩個變數相關性可由相關係數求得。其指令型式如下:
R = corrcoef(X)
R = corrcoef(x,y)
[R,P]=corrcoef(...)
[R,P,RLO,RUP]=corrcoef(...)
[...]=corrcoef(...,'param1',val1,'param2',val2,...)
基本上,R=CORRCOEF(X)在於計算一個R矩陣,其內有X陣列行間之相關係數。而CORRCOEF(X,Y)則計算 X 與 Y兩行向量之相關係數,其意義與CORRCOEF([X Y])相同。
假設 C為共方矩陣,且 C = COV(X),則R=CORRCOEF(X)之定義為:
R(i,j) = C(i,j)/sqrt{C(i,i)C(j,j)}
輸入項中除XY等資料矩陣外,尚可輸入其他特定變數與常數。這些可以用 'PARAM1',VAL1成對表示,其項目包括:
參數值:
'alpha' 顯著水準,預設值為0.05(即95%信任區間)
'rows' 使用 'all' (預設值)表示使用所有列值;
'complete'表示使用沒有含NaN 值之列;
'pairwise'表示計算R(i,j)時使用不含
NaN值之 i行或 j行。
輸出值中, P表示檢驗無關係假設之P值矩陣。每一個P值代表隨機可以觀察得到之最大值域。若 P(i,j)值很小,例如小於 0.05,則R(i,j) 之關係甚為顯著。
此外,有RLO與RUP代表95%信任水準之下限與上限矩陣,其大小與R相同。
例一
>> x=1:5
x =
1 2 3 4 5
>> y=x.^3
y =
1 8 27 64 125
>> r=corrcoef(x,y)
r =
1.0000 0.9431
0.9431 1.0000
答案中r之值愈接近於1,其相關性愈高。此例中,對角線為自己對自己(即x對x;y對y)故其相關性為1,其餘x對y或y對x,兩者相關性一樣,其數值為0.9431,也相當高。
例二
利用常態分配亂數指令randn產生30X4大小之資料,開始時先利用第四行建立與其他行間之關係,以橫向加總於第四行。其後以corrcoef求相關係數r及機率p。就機率而言,p值愈小,表示兩者之相異性更強,其結果可利用find指令找出小於0.05以下之機率項目。
x = randn(20,4); % uncorrelated data
x(:,4) = sum(x,2) % introduce correlation
[r,p] = corrcoef(x)
% compute sample correlation and p-values
[i,j] = find(p<0.05);
% find significant correlations [i,j]
x =
0.0828 -0.5703 -0.0716 -0.5850
0.7662 -1.4986 -2.4146 -4.2576
2.2368 -0.0503 -0.6943 2.2430
0.3269 0.5530 -1.3914 -0.0113
0.8633 0.0835 0.3296 0.7592
0.6794 1.5775 0.5985 2.2962
0.5548 -0.3308 0.1472 -0.3822
1.0016 0.7952 -0.1014 2.6212
1.2594 -0.7848 -2.6350 -2.4089
0.0442 -1.2631 0.0281 -1.3408
-0.3141 0.6667 -0.8763 -1.7822
0.2267 -1.3926 -0.2655 -1.1188
0.9967 -1.3006 -0.3276 2.0588
1.2159 -0.6050 -1.1582 -0.2577
-0.5427 -1.4886 0.5801 -2.8740
0.9122 0.5585 0.2398 1.9573
-0.1721 -0.2774 -0.3509 -2.2362
-0.3360 -1.2937 0.8921 -0.5890
0.5415 -0.8884 1.5783 -0.4617
0.9321 -0.9865 -1.1082 -0.4434
r =
1.0000 0.1950 -0.3475 0.5143
0.1950 1.0000 0.0929 0.5785
-0.3475 0.0929 1.0000 0.3822
0.5143 0.5785 0.3822 1.0000
p =
1.0000 0.4100 0.1333 0.0203
0.4100 1.0000 0.6969 0.0075
0.1333 0.6969 1.0000 0.0963
0.0203 0.0075 0.0963 1.0000
ans =
4 1
4 2
1 4
2 4
11.2.8群組函數grpstats
前面討論到之平均值求法,通常應用於整個陣列之值,若要應用到比較複雜的分組平均問題,則必須使用不同的函數才能達成。此項指令之格式如下:
means = grpstats(X, group)
[means, sem, counts, name] = grpstats(X, group, whichstats)
grpstats(x, group, alpha)
輸入參數中X為求平均值之對象,X可為多行,其平均結果也會多行。group則為與X同列長之陣列,可能由多項分組之向量組成,其內容可為字串列或細胞陣列之文字,如{G1 G2 G3}。若X中之元素同屬分組中之一項,則其平均值會出現在該項下。
在輸出項中,第一項means為群組平均,sem為組內標準差,counts為各組之項數,name則為各組之名稱。上述項目並非一成不變,亦可以在輸入參數whichstats內依自己之需要進行設定,這個設定有特定的名稱,其名稱必須使用細胞陣列。項目包括:
- 'mean' 組平均
- 'sem' 組標準差
- 'numel' 各組之數目
- 'gname' 各組之名稱
- 'std' 標準差
- 'var' 變異值
- 'meanci' 平均值之95%上下範圍
- 'predci' 新值預測之95%信任範圍
輸入參數中有alpha,可改變其顯著水準,其預設值為0.05,或為95%之信任水準。
輸出項中,means 即為各分組項之平均值,sem為該分組項之標準差,counts為該分組下之觀察值數目,而name則為該分組之名稱。
範例一:
x = 1 2 3 4 5 6 7 8 9 10
group= 1 1 1 1 1 2 2 2 2 2;
>> grpstats(x,group)
ans =
3
8
上述結果為分兩組的平均,前五項為一組,後五項為一組。結果第一組平均為3,第二組為8。
組別間,其項數並不一定要相同,例如:
範例二:
x =
1 2 3 4 5 6 7 8 9
>> group=[1 1 1 1 2 2 2 2 2]
group =
1 1 1 1 2 2 2 2 2
>> [m,s,c]=grpstats(x,group)
m =
2.5000
7.0000
s =
0.6455
0.7071
c =
4
5
其輸出之第一項為平均值,第二項為標準差,第三項為各組之項數。故即使各組之樣本數不同也可以得到對應組之統計資料。
範例三:
設有200個觀測值分成四小組,每一觀測值分成五項,其平均範圍由1-5。為製造這樣的數據,下面之例子實際上應用了許多特定的函數:
- unidrnd(4,100,1) 平均製造一個100X1的陣列,其中之數值分配為1:4的整數範圍,以每項分別以1,2,3,4隨機出現。
- normrnd(true_mean,1) 常態分配之亂數函數,其平均值為true_mean,其標準差為1。
- true_mean((ones(100,1),:) 利用原來設定之(ones(100,1),:)陣列,重覆100次。
執行此程式後,由於n為細胞陣列,故全改為字串才能同時顯現其結果,其結果如下:
group = unidrnd(4,100,1);%create a 100X1 matrix in random [ 1,2,3,4 ]
true_mean = 1:5;
true_mean = true_mean(ones(100,1),:); %100X5 matrix
x = normrnd(true_mean,1); %randomize
[m, s, c,n] = grpstats(x,group);
[n num2cell(m)]
ans =
'1' [0.9584] [1.8200] [2.8412] [4.1669] [5.0220]
'2' [0.8972] [1.8393] [2.9423] [4.0044] [4.9437]
'3' [0.9768] [2.1093] [3.1565] [3.9860] [5.0585]
'4' [1.1164] [2.2249] [2.8920] [4.1323] [5.3251]
範例四:
利用matlab所附的carsmall.mat示範檔案,其中參數項目包括重量(Weight)、年份(Model_Year)等資料,利用該項資料求其年份下之平均車重、預測值、年份名稱及各年份下之數量。最後並利用errorbar繪出其範圍。
% cargroup.m
load carsmall
[Weight Model_Year]'
[means,p,year,count] = grpstats(Weight,Model_Year,...
{'mean','predci','gname','numel'})
n = length(means);
errorbar((1:n)',means,p(:,2)-means)
set(gca,'xtick',1:n,'xticklabel',year)
title('95% prediction intervals for mean weight by year')
先將上述程式存為cargroup.m檔案,執行後應有許多資料,其中僅選擇本題所需要者。其過程如下:
>> cargroup
ans =
Columns 1 through 7
3504 3693 3436 3433 3449 4341 4354
70 70 70 70 70 70 70
Columns 8 through 14
4312 4425 3850 3090 4142 4034 4166
70 70 70 70 70 70 70
= == == == == == == == == == == ==
Columns 92 through 98
2835 2665 2370 2950 2790 2130 2295
82 82 82 82 82 82 82
Columns 99 through 100
2625 2720
82 82
means =
1.0e+003 *
3.4413
3.0787
2.4535
p =
1.0e+003 *
1.7770 5.1056
1.3832 4.7742
1.7184 3.1887
year =
'70'
'76'
'82'
count =
35
34
31
11.2.9表列函數tabulate
TABLE = tabulate(x)
這個指令可將一向量X之觀測值製成一表格,其第一行為X向量中之相同數值,第二行為該數值出現之次數,最後一行為該值出現之百分比。若X值為含有文字串之陣列或細胞陣列,則第一行為陣列內之獨一的名稱,其餘兩行則相同。下面為利用rand之隨機函數取100個值作比較。
tabulate(round(rand(100,1)*6))
Value Count Percent
0 8 8.00%
1 16 16.00%
2 22 22.00%
3 21 21.00%
4 10 10.00%
5 16 16.00%
6 7 7.00%
tabulate(fix(rand(100,1)*6))
Value Count Percent
0 14 14.00%
1 14 14.00%
2 21 21.00%
3 15 15.00%
4 22 22.00%
5 14 14.00%
由上面之結果比較可以看出:利用四捨五入法之round函數,其在兩端之機率顯然少很多。
利用前節之汽車carsmall.mat資料,亦可以tabulate指令作簡單之統計:
load carsmall
>> tabulate(Origin)
Value Count Percent
USA 69 69.00%
France 4 4.00%
Japan 15 15.00%
Germany 9 9.00%
Sweden 2 2.00%
Italy 1 1.00%
看起來美國地區還是美國車多。
上述tablulate指令之左邊若不給予參數,則會自動產生上述之格式,分成三行,即名稱、數量及百分比。若結果給予一個參數時,其內容會轉為細胞陣列。因此必要時,須利用cell2mat函數轉換為數值陣列。以上述資料為例,下面的型式會有不同的結果:
>> a=tabulate(Origin)
a =
'USA' [69] [69]
'France' [ 4] [ 4]
'Japan' [15] [15]
'Germany' [ 9] [ 9]
'Sweden' [ 2] [ 2]
'Italy' [ 1] [ 1]
顯然其內容均是細胞陣列,若要作成餅圖,則必須稍微變換:
>> pie(cell2mat(a(:,2)),a(:,1))
11.2.10百分值prctile
在一般大量樣本之情況下,可以利用百分值去確定樣本之合理對應值,由此百分比與對應值之關係可以瞭解資料之外形、位置以及擴散度。其指令格式如下:
Y = prctile(X, p)
此指令計算X之樣本值中一個大於p%部份之對應值位置,此值並不一定是原有之觀測值,只求其比例位置。輸入參數 p 必須落在[0 100]間,可為常數或向量。若 p = 50% 時,則Y值應對應X之中間值(median)。X之資料可為向量或矩陣,而 p 則可能為一向量或其中之常數。下表說明可能之之四種狀況:
X p Y= prctile(X, p)
==== ======== ===========================================
向量 數值常數 數值等於X中第p級百分值
矩陣 數值常數 列向量含X中每一行內第p級百分值,其中
y(i)=prctile(X(:,j),p)
向量 向量 Y向量與p同,其第i項為X中第p(i)級百分值
y(i)=prctile(X,p(i))
矩陣 向量 Y矩陣中,其第(i,j)項為X中第j行第p(i)級百分值
y(i,j)=prctile(X(:,j),p(i))
==== ======== ===========================================
執行例:
>> x=randn(100,1);
>> Y=prctile(x,[10:10:90])
Y =
-1.2258 -1.0402 -0.6829 -0.4320 -0.2074 0.0287 0.3215 0.6855 1.2649
%Y與p之向量相同,與X為列或行向量無關。
%X2若為矩陣,則p先與X之行向量作百段分值。
X2 =
0 1 2 3 4
1 2 3 4 5
2 3 4 5 6
>>Y2=prctile(X2,50)
Y2 =
1 2 3 4 5
>>X2=[0:4;1:5; 2:6],Y2=prctile(X2,[20 30 50])
X2 =
0 1 2 3 4
1 2 3 4 5
2 3 4 5 6
>>Y2 =
0.1000 1.1000 2.1000 3.1000 4.1000
0.4000 1.4000 2.4000 3.4000 4.4000
1.0000 2.0000 3.0000 4.0000 5.0000
X2若為矩陣,p為向量時,每個p(i)先與X之行向量作百段分值,並Y依序完成行向量之值。
11.2.11細分值quantile
細分值與百分值之意義類似,但其區間為小數,介於[0 1]之間,以配合累積密度函數之使用,其指令格式如下:
Y = quantile(X, p)
Y = quantile(X, p, dim)
其輸出值Y為X觀測值中傳回值,p為數值或累積機率值之向量。當X為向量時,Y之大小與p相同,而Y(i)則是第p(i)之細分對應值。當X為矩陣,則Y之第i列為第p(i)對X之行向量之細分值。
其細分方向亦可利用dim設定,但Y在dim指定的方向長度應與p之長度相同。
細分值常應用於累加機率,故其範圍為[0 1]。若X為一具N元素之向量,則QUANTILE依下列方式運算:
- 1)X值經過排序,並細分為(0.5/N), (1.5/n), ..., ((N-0.5)/N) 細分段
- 2) 線性內插法用於計算 (0.5/N) 與 ((N-0.5)/N)間機率之細分段。
- 3) X中之最大值與最小值作為機率外圍之細段。
X=1:10;y=quantile(X,.50)
y =
5.5000
y = quantile(X,[.025 .25 .50 .75 .975])
y =
1.0000 3.0000 5.5000 8.0000 10.0000
堆疊矩陣之使用,前面也曾述及,其相關語法如下:
B = repmat(A,m,n)
B = repmat(A,[m n])
B = repmat(A,[m n p...])
這是一個處理大矩陣且內容有重複時使用之。其功能是以A之內容堆疊在一(M x N)的矩陣B中。B矩陣之大小由MXN及A矩陣之內容決定。例如:
>>B=repmat( [1 2;3 4],2,3)
B =
1 2 1 2 1 2
3 4 3 4 3 4
1 2 1 2 1 2
3 4 3 4 3 4
其結果變為4X6。A也可以置放文字串,如:
>>C=repmat(' Long live the king!', 2,2)
C =
Long live the king! Long live the king!
Long live the king! Long live the king!
也可置放特定常數:
>> D=repmat(NaN,2,5)
D =
NaN NaN NaN NaN NaN
NaN NaN NaN NaN NaN
11.2.13中央慣性矩MOMENT
統計分析之技巧中,通常以觀察值之平均值為參考標,經處理後再進行判定。MOMENT的指令就是採用相差距離之次方作為計算之基準,如:
mk = E(x-u)k
式中之m值變成以不同k值產生之中央慣性矩,也是各種差異度之期望值。k值為與均值差之次方,又稱階數(order),其值必須為正。利用觀察資料依各值對中央均值之值距作階數之乘方而累加之和,再除以樣本數。當k=1時稱為第一慣性矩,所得結果應為零,亦即為均值之位置;k=2時即為第二慣性矩,即為上述討論之變方,只是此時之除數為n。其指令型式如下:
舉例:
m = moment(X,order)
>> X=randn(4,6)
m1=moment(X,1)
m2=moment(X,2)
m3=moment(X,3)
m4=moment(X,4)
X =
-1.7258 0.1387 1.1508 -0.3735 -1.5731 -0.2433
0.8132 -0.8595 -0.6080 -0.8320 2.0157 0.1733
1.4419 -0.7523 0.8062 0.2869 -0.0720 0.9232
0.6723 1.2296 0.2171 -1.8189 2.6289 -0.1786
m1 =
0 0 0 0 0 0
m2 =
1.4524 0.7053 0.4445 0.5872 2.8011 0.2149
m3 =
-1.6611 0.3293 -0.1237 -0.1293 -1.1069 0.0795
m4 =
4.6600 0.8526 0.3402 0.6391 11.1516 0.0919
上述之結果可知,m1均為零,m2與m4因為偶數次方故均為正數;m3則有正負。
11.2.14歪度SKEWNESS
歪度為第三中央慣性矩除以標準差之三次方,由此可以測出分佈的偏向,或稱為費雪(Fisher)歪度公式。其計算方式如下:
s = E(x-μ)3/σ3
其中μ為x之平均值,σ為標準差,E表示括號內之期望值。y即為所謂之歪度。其指令之型式如下:
s = skewness(X)
s = skewness(X,flag)
輸入參數flag為校正偏差用,flag=1時不作校正,為其預設值;flag=0時則有校正。通常少量之樣本代表一群體時,所得歪度會產生偏差,故視樣本大小需進行校正。因此,修正時,必須執行skewness(X,0)指令。
若x為向量,則s 會得到樣本歪度,或為單一值。當X為矩陣時,s歪度將以列向量表示。若其結果s等於零,表示對稱分佈;s>0則為正偏(即高峰偏左);s<0為負偏(高峰在右)。進行判斷時,若其絕對值小於1.96,則屬常態分配,大於1.96則為非常態。例如:
>> X=randn(4,5)
s=skewness(X)
X =
2.0941 1.6820 -0.1586 -0.5266 0.2486
0.0802 0.5936 0.8709 -0.6855 0.1025
-0.9373 0.7902 -0.1948 -0.2684 -0.0410
0.6357 0.1053 0.0755 -1.1883 -2.2476
s =
0.2794 0.4979 0.9682 -0.4978 -1.1201
由歪度結果得知,這此數值雖屬常態分佈,但也有中央偏向問題。第一、二、三行之高峰偏左,第四及第五行則高峰偏右。
11.2.15峰度KURTOSIS
峰度是採用第四中央慣性矩除以標準差的四次方而得。其公式如下:
k =E(x-μ)4/σ4
此處k值稱為kurtosis,其指令格式如下:
k = kurtosis(X)
k = kurtosis(X,flag)
其中flag之功能與skewness相同,為校正偏差用,flag=1時為其預設值,不作校正;flag=0作校正。kurtosis(X)之意義在於表示峰度之趨勢分佈。在常態分配中,峰度值為3。大於3時其峰度將高於常態峰度;小於3時則低於常態峰度。以此可以作為山峰高度之判斷。
例如:
X=randn(100,5);k=kurtosis(X)
k =
3.1023 2.6613 2.7877 3.5796 2.7580
這種常態分佈狀態下,當樣本增多時,峰度值將趨近於3。上述五行之資料當中,第一及四行之山峰較高,其餘之峰頂則較低。(峰度值3即表示標準的山形的意識,也比較容易記)
在大部份之機率分佈計算中,有些指令尚提供參數及信任水準的計算方法。為獲得相關指令,可以使用help stats進行查詢。例如:
>> help stats
Statistics Toolbox
Version 5.0 (R14) 05-May-2004
Distributions.
Parameter estimation.
betafit - Beta parameter estimation.
binofit - Binomial parameter estimation.
dfittool - Distribution fitting tool.
evfit - Extreme value parameter estimation.
expfit - Exponential parameter estimation.
gamfit - Gamma parameter estimation.
lognfit - Lognormal parameter estimation.
mle - Maximum likelihood estimation (MLE).
mlecov - Asymptotic covariance matrix of MLE.
nbinfit - Negative binomial parameter estimation.
normfit - Normal parameter estimation.
poissfit - Poisson parameter estimation.
raylfit - Rayleigh parameter estimation.
unifit - Uniform parameter estimation.
wblfit - Weibull parameter estimation.
Probability density functions (pdf).
betapdf - Beta density.
binopdf - Binomial density.
chi2pdf - Chi square density.
evpdf - Extreme value density.
exppdf - Exponential density.
fpdf - F density.
gampdf - Gamma density.
geopdf - Geometric density.
hygepdf - Hypergeometric density.
lognpdf - Lognormal density.
mvnpdf - Multivariate normal density.
nbinpdf - Negative binomial density.
ncfpdf - Noncentral F density.
nctpdf - Noncentral t density.
ncx2pdf - Noncentral Chi-square density.
normpdf - Normal (Gaussian) density.
pdf - Density function for a specified distribution.
poisspdf - Poisson density.
raylpdf - Rayleigh density.
tpdf - T density.
unidpdf - Discrete uniform density.
unifpdf - Uniform density.
wblpdf - Weibull density.
Cumulative Distribution functions (cdf).
betacdf - Beta cdf.
binocdf - Binomial cdf.
cdf - Specified cumulative distribution function.
chi2cdf - Chi square cdf.
ecdf - Empirical cdf (Kaplan-Meier estimate).
evcdf - Extreme value cumulative distribution function.
expcdf - Exponential cdf.
fcdf - F cdf.
gamcdf - Gamma cdf.
geocdf - Geometric cdf.
hygecdf - Hypergeometric cdf.
logncdf - Lognormal cdf.
nbincdf - Negative binomial cdf.
ncfcdf - Noncentral F cdf.
nctcdf - Noncentral t cdf.
ncx2cdf - Noncentral Chi-square cdf.
normcdf - Normal (Gaussian) cdf.
poisscdf - Poisson cdf.
raylcdf - Rayleigh cdf.
tcdf - T cdf.
unidcdf - Discrete uniform cdf.
unifcdf - Uniform cdf.
wblcdf - Weibull cdf.
Critical Values of Distribution functions.
betainv - Beta inverse cumulative distribution function.
binoinv - Binomial inverse cumulative distribution function.
chi2inv - Chi square inverse cumulative distribution function.
evinv - Extreme value inverse cumulative distribution function.
expinv - Exponential inverse cumulative distribution function.
finv - F inverse cumulative distribution function.
gaminv - Gamma inverse cumulative distribution function.
geoinv - Geometric inverse cumulative distribution function.
hygeinv - Hypergeometric inverse cumulative distribution function.
icdf - Specified inverse cdf.
logninv - Lognormal inverse cumulative distribution function.
nbininv - Negative binomial inverse distribution function.
ncfinv - Noncentral F inverse cumulative distribution function.
nctinv - Noncentral t inverse cumulative distribution function.
ncx2inv - Noncentral Chi-square inverse distribution function.
norminv - Normal (Gaussian) inverse cumulative distribution function.
poissinv - Poisson inverse cumulative distribution function.
raylinv - Rayleigh inverse cumulative distribution function.
tinv - T inverse cumulative distribution function.
unidinv - Discrete uniform inverse cumulative distribution function.
unifinv - Uniform inverse cumulative distribution function.
wblinv - Weibull inverse cumulative distribution function.
Random Number Generators.
betarnd - Beta random numbers.
binornd - Binomial random numbers.
chi2rnd - Chi square random numbers.
evrnd - Extreme value random numbers.
exprnd - Exponential random numbers.
frnd - F random numbers.
gamrnd - Gamma random numbers.
geornd - Geometric random numbers.
hygernd - Hypergeometric random numbers.
iwishrnd - Inverse Wishart random matrix.
lognrnd - Lognormal random numbers.
mvnrnd - Multivariate normal random numbers.
mvtrnd - Multivariate t random numbers.
nbinrnd - Negative binomial random numbers.
ncfrnd - Noncentral F random numbers.
nctrnd - Noncentral t random numbers.
ncx2rnd - Noncentral Chi-square random numbers.
normrnd - Normal (Gaussian) random numbers.
poissrnd - Poisson random numbers.
randg - Gamma random numbers (unit scale).
random - Random numbers from specified distribution.
randsample - Random sample from finite population.
raylrnd - Rayleigh random numbers.
trnd - T random numbers.
unidrnd - Discrete uniform random numbers.
unifrnd - Uniform random numbers.
wblrnd - Weibull random numbers.
wishrnd - Wishart random matrix.
Statistics.
betastat - Beta mean and variance.
binostat - Binomial mean and variance.
chi2stat - Chi square mean and variance.
evstat - Extreme value mean and variance.
expstat - Exponential mean and variance.
fstat - F mean and variance.
gamstat - Gamma mean and variance.
geostat - Geometric mean and variance.
hygestat - Hypergeometric mean and variance.
lognstat - Lognormal mean and variance.
nbinstat - Negative binomial mean and variance.
ncfstat - Noncentral F mean and variance.
nctstat - Noncentral t mean and variance.
ncx2stat - Noncentral Chi-square mean and variance.
normstat - Normal (Gaussian) mean and variance.
poisstat - Poisson mean and variance.
raylstat - Rayleigh mean and variance.
tstat - T mean and variance.
unidstat - Discrete uniform mean and variance.
unifstat - Uniform mean and variance.
wblstat - Weibull mean and variance.
Likelihood functions.
betalike - Negative beta log-likelihood.
evlike - Negative extreme value log-likelihood.
explike - Negative exponential log-likelihood.
gamlike - Negative gamma log-likelihood.
lognlike - Negative lognormal log-likelihood.
nbinlike - Negative likelihood for negative binomial distribution.
normlike - Negative normal likelihood.
wbllike - Negative Weibull log-likelihood.
Descriptive Statistics.
bootstrp - Bootstrap statistics for any function.
corr - Linear or rank correlation coefficient.
corrcoef - Linear correlation coefficient with confidence intervals.
cov - Covariance.
crosstab - Cross tabulation.
geomean - Geometric mean.
grpstats - Summary statistics by group.
harmmean - Harmonic mean.
iqr - Interquartile range.
kurtosis - Kurtosis.
mad - Median Absolute Deviation.
mean - Sample average (in MATLAB toolbox).
median - 50th percentile of a sample.
moment - Moments of a sample.
nanmax - Maximum ignoring NaNs.
nanmean - Mean ignoring NaNs.
nanmedian - Median ignoring NaNs.
nanmin - Minimum ignoring NaNs.
nanstd - Standard deviation ignoring NaNs.
nansum - Sum ignoring NaNs.
nanvar - Variance ignoring NaNs.
prctile - Percentiles.
quantile - Quantiles.
range - Range.
skewness - Skewness.
std - Standard deviation (in MATLAB toolbox).
tabulate - Frequency table.
trimmean - Trimmed mean.
var - Variance (in MATLAB toolbox).
Linear Models.
addedvarplot - Created added-variable plot for stepwise regression.
anova1 - One-way analysis of variance.
anova2 - Two-way analysis of variance.
anovan - n-way analysis of variance.
aoctool - Interactive tool for analysis of covariance.
dummyvar - Dummy-variable coding.
friedman - Friedman's test (nonparametric two-way anova).
glmfit - Generalized linear model fitting.
glmval - Evaluate fitted values for generalized linear model.
kruskalwallis - Kruskal-Wallis test (nonparametric one-way anova).
leverage - Regression diagnostic.
lscov - Least-squares estimates with known covariance matrix.
lsqnonneg - Non-negative least-squares.
manova1 - One-way multivariate analysis of variance.
manovacluster - Draw clusters of group means for manova1.
multcompare - Multiple comparisons of means and other estimates.
polyconf - Polynomial evaluation and confidence interval estimation.
polyfit - Least-squares polynomial fitting.
polyval - Predicted values for polynomial functions.
rcoplot - Residuals case order plot.
regress - Multivariate linear regression.
regstats - Regression diagnostics.
ridge - Ridge regression.
robustfit - Robust regression model fitting.
rstool - Multidimensional response surface visualization (RSM).
stepwise - Interactive tool for stepwise regression.
stepwisefit - Non-interactive stepwise regression.
x2fx - Factor settings matrix (x) to design matrix (fx).
Nonlinear Models.
nlinfit - Nonlinear least-squares data fitting.
nlintool - Interactive graphical tool for prediction in nonlinear models.
nlpredci - Confidence intervals for prediction.
nlparci - Confidence intervals for parameters.
Design of Experiments (DOE).
bbdesign - Box-Behnken design.
candexch - D-optimal design (row exchange algorithm for candidate set).
candgen - Candidates set for D-optimal design generation.
ccdesign - Central composite design.
cordexch - D-optimal design (coordinate exchange algorithm).
daugment - Augment D-optimal design.
dcovary - D-optimal design with fixed covariates.
ff2n - Two-level full-factorial design.
fracfact - Two-level fractional factorial design.
fullfact - Mixed-level full-factorial design.
hadamard - Hadamard matrices (orthogonal arrays).
lhsdesign - Latin hypercube sampling design.
lhsnorm - Latin hypercube multivariate normal sample.
rowexch - D-optimal design (row exchange algorithm).
Statistical Process Control (SPC).
capable - Capability indices.
capaplot - Capability plot.
ewmaplot - Exponentially weighted moving average plot.
histfit - Histogram with superimposed normal density.
normspec - Plot normal density between specification limits.
schart - S chart for monitoring variability.
xbarplot - Xbar chart for monitoring the mean.
Multivariate Statistics.
Cluster Analysis.
cophenet - Cophenetic coefficient.
cluster - Construct clusters from LINKAGE output.
clusterdata - Construct clusters from data.
dendrogram - Generate dendrogram plot.
inconsistent - Inconsistent values of a cluster tree.
kmeans - k-means clustering.
linkage - Hierarchical cluster information.
pdist - Pairwise distance between observations.
silhouette - Silhouette plot of clustered data.
squareform - Square matrix formatted distance.
Dimension Reduction Techniques.
factoran - Factor analysis.
pcacov - Principal components from covariance matrix.
pcares - Residuals from principal components.
princomp - Principal components analysis from raw data.
rotatefactors - Rotation of FA or PCA loadings.
Plotting.
andrewsplot - Andrews plot for multivariate data.
biplot - Biplot of variable/factor coefficients and scores.
glyphplot - Plot stars or Chernoff faces for multivariate data.
gplotmatrix - Matrix of scatter plots grouped by a common variable.
parallelcoords - Parallel coordinates plot for multivariate data.
Other Multivariate Methods.
barttest - Bartlett's test for dimensionality.
canoncorr - Cannonical correlation analysis.
cmdscale - Classical multidimensional scaling.
classify - Linear discriminant analysis.
mahal - Mahalanobis distance.
manova1 - One-way multivariate analysis of variance.
mdscale - Metric and non-metric multidimensional scaling.
procrustes - Procrustes analysis.
Decision Tree Techniques.
treedisp - Display decision tree.
treefit - Fit data using a classification or regression tree.
treeprune - Prune decision tree or creating optimal pruning sequence.
treetest - Estimate error for decision tree.
treeval - Compute fitted values using decision tree.
Hypothesis Tests.
ranksum - Wilcoxon rank sum test (independent samples).
signrank - Wilcoxon sign rank test (paired samples).
signtest - Sign test (paired samples).
ztest - Z test.
ttest - One sample t test.
ttest2 - Two sample t test.
Distribution Testing.
jbtest - Jarque-Bera test of normality
kstest - Kolmogorov-Smirnov test for one sample
kstest2 - Kolmogorov-Smirnov test for two samples
lillietest - Lilliefors test of normality
Nonparametric Functions.
friedman - Friedman's test (nonparametric two-way anova).
kruskalwallis - Kruskal-Wallis test (nonparametric one-way anova).
ksdensity - Kernel smoothing density estimation.
ranksum - Wilcoxon rank sum test (independent samples).
signrank - Wilcoxon sign rank test (paired samples).
signtest - Sign test (paired samples).
Hidden Markov Models.
hmmdecode - Calculate HMM posterior state probabilities.
hmmestimate - Estimate HMM parameters given state information.
hmmgenerate - Generate random sequence for HMM.
hmmtrain - Calculate maximum likelihood estimates for HMM parameters.
hmmviterbi - Calculate most probable state path for HMM sequence.
Statistical Plotting.
andrewsplot - Andrews plot for multivariate data.
biplot - Biplot of variable/factor coefficients and scores.
boxplot - Boxplots of a data matrix (one per column).
cdfplot - Plot of empirical cumulative distribution function.
ecdfhist - Histogram calculated from empirical cdf.
fsurfht - Interactive contour plot of a function.
gline - Point, drag and click line drawing on figures.
glyphplot - Plot stars or Chernoff faces for multivariate data.
gname - Interactive point labeling in x-y plots.
gplotmatrix - Matrix of scatter plots grouped by a common variable.
gscatter - Scatter plot of two variables grouped by a third.
hist - Histogram (in MATLAB toolbox).
hist3 - Three-dimensional histogram of bivariate data.
lsline - Add least-square fit line to scatter plot.
normplot - Normal probability plot.
parallelcoords - Parallel coordinates plot for multivariate data.
probplot - Probability plot.
qqplot - Quantile-Quantile plot.
refcurve - Reference polynomial curve.
refline - Reference line.
surfht - Interactive contour plot of a data grid.
wblplot - Weibull probability plot.
Statistics Demos.
aoctool - Interactive tool for analysis of covariance.
disttool - GUI tool for exploring probability distribution functions.
polytool - Interactive graph for prediction of fitted polynomials.
randtool - GUI tool for generating random numbers.
rsmdemo - Reaction simulation (DOE, RSM, nonlinear curve fitting).
robustdemo - Interactive tool to compare robust and least squares fits.
File Based I/O.
tblread - Read in data in tabular format.
tblwrite - Write out data in tabular format to file.
tdfread - Read in text and numeric data from tab-delimitted file.
caseread - Read in case names.
casewrite - Write out case names to file.
Utility Functions.
combnk - Enumeration of all combinations of n objects k at a time.
grp2idx - Convert grouping variable to indices and array of names.
hougen - Prediction function for Hougen model (nonlinear example).
statget - Get STATS options parameter value.
statset - Set STATS options parameter value.
tiedrank - Compute ranks of sample, adjusting for ties.
zscore - Normalize matrix columns to mean 0, variance 1.
事件發生的機率雖然可以估計,但是必須由過去發生的事實去統計,並以此預測未來將發生的事件。這種運作的方式在模擬的作業上有實際的困難,故僅能依靠亂數產生器模擬事件之發生。亂數的特性是發生時間或次數均屬隨機性,每次發生的機率均依循其特定的模式,常用者為均勻分佈的亂數型態,每一事件出現之機率是相等的。利用亂數產生之數值可以模擬機械之故障率、顧客來訪的時機、旅客搭機的安排,甚或穀物乾燥中心作業的動線規劃等。
在MATLAB中常用的亂數產生指令為rand,這是個依均勻機率分配出現之原則產生一個或一組在[0, 1]間之亂數,每次呼叫其值均不一樣。這些數值雖有其範圍,但產生之後可以作適當調整,以符合實際所需。所產生之數值可為單一數字,亦可為特定之矩陣,其大小由其後之參數界定之。若僅輸入一個參數(n),其所產生之結果為一nxn之方矩陣;若為(m, n)則得 m x n之矩陣。
例如:
>>rand
ans =
0.9501
>>rand(2,4)
ans =
0.2311 0.4860 0.7621 0.0185
0.6068 0.8913 0.4565 0.8214
除均勻機率分配產生者外,亦可使用randn之指令,其產生之亂數則係依常態分態的型式。例如:
>> randn(5,6)
ans =
0.8956 0.5689 -0.2340 0.6232 0.2379 0.3899
0.7310 -0.2556 0.1184 0.7990 -1.0078 0.0880
0.5779 -0.3775 0.3148 0.9409 -0.7420 -0.6355
0.0403 -0.2959 1.4435 -0.9921 1.0823 -0.5596
0.6771 -1.4751 -0.3510 0.2120 -0.1315 0.4437
利用常態分佈之指令randn可以產生正負值,其值也可能大於一。其他分配所需之亂數產生器可以參考如下之各項指令。注意每項指令之後可能需要相關之參數,讀者可以利用help之輔助指令獲得所需之資訊。
亂數產生器(Random Number Generators)
依據實際之用途,可以有不同之亂數指令可以應用,
均勻分佈亂數rand
常態分佈亂數randn
常態亂數(Normal (Gaussian))-normrnd.
貝他亂數(Beta)-betarnd.
二項式亂數(Binomial)- binornd.
X's亂數(Chi square)-chi2rnd.
極值亂數(Extreme value)-evrnd.
指數亂數(Exponential)-exprnd.
F亂數(F)-frnd.
伽瑪亂數(Gamma)-gamrnd.
伽瑪亂數( Gamma (unit scale))-randg.
幾何亂數(Geometric)-geornd.
超幾何亂數(Hypergeometric)-hygernd.
反威夏亂數(Inverse Wishart)-iwishrnd.
常態對數亂數(Lognormal)-lognrnd.
多變異亂數(Multivariate normal)-mvnrnd.
多變T亂數( Multivariate t)-mvtrnd.
負二項式亂數(Negative binomial)-nbinrnd .
非中央F亂數(Noncentral F)-ncfrnd .
非中央亂數(Noncentral)-nctrnd.
非中央X's亂數(Noncentral Chi-square)-ncx2rnd.
波義松亂數(Poisson)-poissrnd.
定群樣本亂數(finite population)-randsample .
魏利亂數( Rayleigh )-raylrnd .
T亂數(T)- trnd .
離散均勻亂數( Discrete uniform)-unidrnd .
均勻亂數(Uniform)-unifrnd .
魏伯亂數(Weibull)-wblrnd .
威夏亂數矩陣( Wishart)-wishrnd .
上述諸多指令,可以實際統計上之需要實際選取應用。例如:以亂數的理念,產生一群數字作排例時,可用randperm(n)指令,以產生不同之排列組合:
>> randperm(7)
ans =
1 3 7 6 2 5 4
>> randperm(7)
ans =
7 6 3 5 4 2 1
>> randperm(7)
ans =
4 1 7 2 6 3 5
其結果每次顯示不同組合,均為整數。此指令因此可以模擬擲骰子,若改用randperm(6),則成為每趟擲六次,顯現排列數據。這個指令與rand指令不同,若使用rand則必須先化成整數,然後利用程式進行模擬擲骰之動作,其過程比較複雜。
MATLAB亦提供一示範指令,randtool。此指令可以示範各種型態之分配機率,利用下拉式清單可以選擇所需的分配型式,並直接設定所需之範圍與變異量。其結果以對應之質方圖顯示。
>> randtool
由於不同之分佈,有不同的指令,不容易記清楚。不過,MATLAB提供一個通用的指令,其型式如下:
random('name', a1,a2,m,n)
這個指令則可在name處置放各種指令名稱,其後可依需要再加上對應之參數,其中a1、a2為該函數所需之參數,而最後之[m,n]則為最後之矩陣大小,變成一個相當有彈性的指令,例如:
random('normal',0,1,3,3)
ans =
-0.1867 2.1832 1.0668
0.7258 -0.1364 0.0593
-0.5883 0.1139 -0.0956
其中之'name'名稱可以為 'beta', 'binomial', 'chi-square' 或 'chi2', 'extreme value' 或 'ev', 'exponential', 'f', 'gamma', 'geometric', 'hypergeometric' 或 'hyge', 'lognormal', 'negative binomial' 或 'nbin', 'noncentral f' 或 'ncf', 'noncentral t' 或 'nct', 'noncentral chi-square' 或 'ncx2', 'normal', 'poisson', 'rayleigh', 't', 'discrete uniform' 或 'unid', 'uniform', 'weibull' 或 'wbl'等等。部份字母符合亦可,且大小寫不拘。如此可以免去背記上述指令之苦。
常態分配之亂數中,不像均勻分佈的型態,基本上它會集中在某區域,故最常發生的事件會集中在平均值附近。在均勻分佈型態應用上,常需設定上下界,讓其出現限定在特定範圍內;常態分配則無明顯的上下界限,且由於集中存在平均值附近,故與均值間之距離會有正負差。其表示方法如下:
y = μ+σx
其中μ為平均值,而σ為其標準差,亦即常態分配之亂數值。在MATLAB中以randn之指令函數產生標準差值σ。此指令係以標準差為1,而平均值為0作成亂數結果,故若有某一群組分佈平均為10,標準差為5,且樣本為200點,則產生後必須乘以所需之標準差5再加上平均值10,其做法如下表示:
y=10+5*randn(1, 200)
>>hist(10+5*randn(1,200))
這是一個交談式的指令,可以直接變換參數並得其結果:
>> disttool
這是一個展示各種分配及機率分佈之指令。沒有任何參數,但可以在圖中更改所要的參數。開始時可選分佈種類,如常態、貝他、二項式、指數、二極值、F、伽瑪、幾何、常態對數等等。選定其一後立即會顯示。其後選擇所需函數名稱。僅有機率分配(pdf)、累積分配函數(cdf)等二項。上兩項選定後,即可輸入X值,求得對應之機率,或選定機率求得對應之X值。亦可利用滑鼠直接在圖上點出位置,顯示其對應之X值與機率。此外,在其左下方有參數設定值,可以利用滑尺為之。
單向變異分析(ANOVA1)旨在尋找不同類別下之資料是否具有相同均值,亦即決定不同類別下,各量測值是否具有差異特性。在線性模式下,單向變異分析是最簡單的狀況。任何量測值可以矩陣表示如下:
yij = αjεij
其中,yij中每行j代表不同類別,並具有類別內之平均值 。在工具箱中存有hogg.mat資料,下載後可以作為執行anova1函數之用,其過程如下:
>> load hogg
>> hogg
hogg =
24 14 11 7 19
15 7 9 7 24
21 12 7 4 19
27 17 13 7 15
33 14 12 12 10
23 16 18 18 20
ANOVA指令之型式如下:
P = ANOVA1(X,GROUP,DISPLAYOPT)
此指令會將X組合之樣本矩陣中之各行視為比較之組別,以此決定組別間之平均值是否會相等。GROUP為分組向量,其長度應與X之行數相同,其內容即為各組之名稱。指令左邊為結果之機率,其值愈小表示相等之機率愈小,亦即顯著性之差異愈大。GROUP向量可以容許使用字串或細胞陣列,但必須以行表示。若不使用組別名稱則可以空格。
DISPLAYOPT為顯示開關,可用 'on' (預設值)或 'off'決定是否顯示結果圖。若要文字輸出ANOVA表,則可在左邊加一參數如ANOVATAB:
[P,ANOVATAB, stats] = ANOVA1(...)
參數ANOVATAB為細胞陣列,stats則為一些統計參數。
例:
>> [p,tbl,stats]=anova1(hogg)
p =
0.00011971
tbl =
'Source' 'SS' 'df' 'MS' 'F' 'Prob>F'
'Columns' [ 803] [ 4] [200.75] [9.0076] [0.00011971]
'Error' [557.17] [25] [22.287] [] []
'Total' [1360.2] [29] [] [] []
stats =
gnames: [5x1 char]
n: [6 6 6 6 6]
source: 'anova1'
means: [23.833 13.333 11.667 9.1667 17.833]
df: 25
s: 4.7209

在本例中,hogg之資料實際上各行代表不同處理之細菌繁殖情形。利用ANOVA變異分析表之結果亦可做 F-test,以證明不同處理是否仍然具有相同的結果。此例所得之p值約為 0.0001,這是一個相當小的值。換句話說,此種結果強烈顯示不同的處理其結果之差異是顯著的。若就或然率考慮,每10,000次實驗當中只有一次有結果相同的機會。對於研究者而言,這是一個很大的鼓舞,因為至少由統計分析結果可證明:不同處理比較下,應有很大的差異性的。當然,上述p值要正確,其基本假設是各項變異應獨立,且屬常態分配,其變異值也是固定。這些差異性由圖也可以看出端倪。
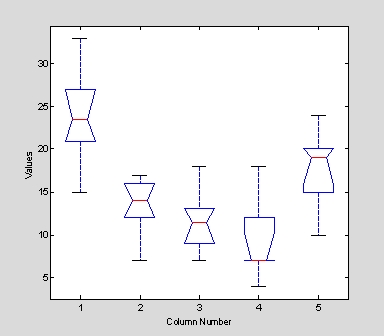
上述之指令,若要加上各行之名稱,則可另以如下之指令為之:
>> [p,tbl,stats]=anova1(hogg,{'A1','A2','A3','A4','A5'}')
其執行結果與前述無異,但在最後之組別圖中會出現分組之組名。
11.7.1Multiple Comparisons
有些時候光比較眾處理之間有無差異仍然不足,有時必須知道那一對有顯著的差異。當然此時也可以藉助一連串的t-test逐對比較,但這種方式仍有缺點。在做t-test時,通常會先計算t的過程中與一特定值比較。此值之選定通常是認為各處理之均值超過此值很小(例如5%)。當均值有顯著差異時,統計的數據超過該值的機率反而變大,容易造成誤判。利用MULTCOMPARE指令可以解決此問題,並可執行平均值之多重比較。其語法如下:
COMPARISON = MULTCOMPARE(stats)
參數stats為統計資料,可以直接得自 anova1, anova2, anovan, aoctool等函數之輸出值,其輸出參數COMPARISON則是一個矩陣,每一列中具有五行,第 1-2行是被比較之兩樣本編號,第 3-5 則分別為其差異之最低值、估計值及最高值。
>>COMPARISON = MULTCOMPARE(stats)
COMPARISON =
1 2 2.4953 10.5 18.505
1 3 4.1619 12.167 20.171
1 4 6.6619 14.667 22.671
1 5 -2.0047 6 14.005
2 3 -6.3381 1.6667 9.6714
2 4 -3.8381 4.1667 12.171
2 5 -12.505 -4.5 3.5047
3 4 -5.5047 2.5 10.505
3 5 -14.171 -6.1667 1.8381
4 5 -16.671 -8.6667 -0.66193
單變異與雙變異分析上不同的地方是後者具有兩組類別,其所定義的特性不相同。例如某汽車公司有兩家工廠,每家工廠均生產相同的三車種。此時生產之汽車之里程數作合理的比較時,其差異可能有兩項:其一是甲乙兩工廠間之差異,其二是車型間之差異。 此時工廠別與車型別兩者均會影響汽車之里程數。其間差異可能來自工廠間之製造,也可能是因車種設計或規格上的問題,後者之問題可能與工廠無關。 此外,某工廠也可能對生產某一車種有獨到的製造能力(可能因為有較佳的生產線吧!),卻製造其他車種則與另一工廠不相上下,這種效應稱為加減性,或兩項類別間之交互作用所產生之影響。
雙變異分析(ANOVA)是線性模式之特殊狀況。就汽車之里程數可以表示如下:
yijk=μ+α.j+βi.+γij+εijk
其中,yijk為里程數之觀察資料(列指標為i,行指標為j,重複標為k)。μ整個矩陣之平均值。α.j為由於車型j與μ差異之均值,βi.則是工廠別i與μ差異之均值,γij為交互作用項,其在行向之和或列向之和為零。εijk 為整個隨機之變異量。
由上述汽車之製造例可知,其觀察之里程數變成一種矩陣的型式,具有j行與i列的組別項,此時由行與列構成之組別或稱為處理(Treatment),對應於行列方向之交叉點即為細胞(Cell),每個細胞位置必須重複置放樣本觀察數,或稱為重複數( repetition)。若以矩陣表示,此重複數必須置於k方向。
ANOVA2為分析雙變異數之指令。其格式如下:
ANOVA2(X, REPS, DISPLAYOPT)
輸入參數X為觀察之資料矩陣,其行與列均需二項以上,以作為比較之基準。在各行的資料代表一類別;各列者則為另一類別。若每一對應細胞有多個觀察資料,則由REPS指定。若REPS=3,代表每個細胞位置有三筆資料,這些資料依列之類別依序置於列中。因此若REPS=3,則在列中每三筆資料屬其中一組,下三筆屬第二組,如此類推,其總列數因而應為三(REPS)的倍數。另外參數DISPLAYOPT之定義與前述指令之用法相同。
輸出參數則表示如下:
[P, TABLE, stats] = ANOVA2(...)
其中 P為p值之向量,而 TABLE則為細胞陣列,包括ANOVA表的內容。stats則為分析後之統計資料,可以作為其他指令如MULTCOMPARE函數之輸入。
若有非平衡變異資料則可採用ANOVAN指令進行分析,詳細情形可以參考手冊或輔助資料。
茲以工具箱中存有mileage.mat之車型生產資料為例,可以作為本節之分析示範:
>>load mileage
>>mileage
mileage =
33.3 34.5 37.4
33.4 34.8 36.8
32.9 33.8 37.6
32.6 33.4 36.6
32.5 33.7 37
33 33.9 36.7
此為三種車型(行)及二家工廠製造之汽車每加侖里程資料,其reps=3,故第1-3列代表第一家工廠製造之車輛,第4-6列代表第二家工廠。將相關參數代入anova2指令,可得結果為:
>>[p,tbl,stats] = anova2(mileage,3)
p =
2.4278e-010 0.0039095 0.84106
tbl =
'Source' 'SS' 'df' 'MS' 'F' 'Prob>F'
'Columns' [53.351] [ 2] [ 26.676] [ 234.22] [2.4278e-010]
'Rows' [ 1.445] [ 1] [ 1.445] [ 12.688] [ 0.0039095]
'Interaction' [ 0.04] [ 2] [ 0.02] [0.17561] [ 0.84106]
'Error' [1.3667] [12] [0.11389] [] []
'Total' [56.203] [17] [] [] []
stats =
source: 'anova2'
sigmasq: 0.11389
colmeans: [32.95 34.017 37.017]
coln: 6
rowmeans: [34.944 34.378]
rown: 9
inter: 1
pval: 0.84106
df: 12
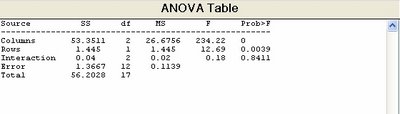
除文字及統計數據外,尚有一個標準的 ANOVA表,其中第一行為行,其平方和(SS)、自由度(df)及均方值 (MS=SS/df), F 檢定及或然率 p-值等。 F檢定可以檢驗車型間、工廠間及車型X工廠之交互作用(經過調整後之增加效應)產生之里程數是否相同。由於 p-值在車型間之效應幾乎近於零(至小數四位),表示車型對里程數之變異甚大,有顯著之影響。經由 F檢定結果,因車型而發生同平均值之情況,其機率為萬分之一。若使用MULTCOMPARE指令比較:
>>COMPARISON = MULTCOMPARE(stats)
Note: Your model includes an interaction term. A test of main
effects can be difficult to interpret when the model includes
interactions.
COMPARISON =
1 2 -1.5865 -1.0667 -0.54686
1 3 -4.5865 -4.0667 -3.5469
2 3 -3.5198 -3 -2.4802
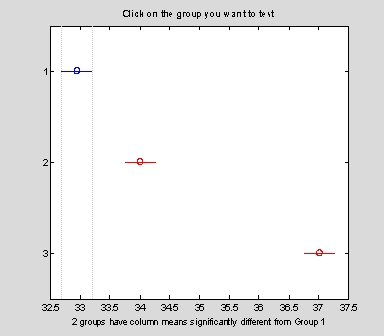
利用multcompare函數比較結果,三車型之差異有明顯之不同。而 p-值對工廠間之機率值為 0.0039,這也是一個非常顯著之差異。顯然,某一工廠製造的汽車,其里程數是比另一廠為高。由其 p-值得知,只有千分之四的機率兩工廠製造的汽車之里程數才會相同。就工廠X車型間交互作用之影響而言,則不顯著。其 p-值僅 0.8411,亦即結果中,可能百分八四機率會出現無交互作用之影響。當然,此處顯示之 p-值若要正確,基本上整個樣本之分佈必須獨立、常態分配並有固定的變異常數。
11.7.3多變異分析ANOVAN
在變異分析的過程中,有些資料並非刻意形成,而是因調查或分析產生的特定資訊,無法事先規劃作出等量分組或先經實驗分組。例如,有一些汽車銷售資訊,在銷售單中可能有不同車種、型號、排氣量,甚至出產國別等。若就其分類有些數量並不一定對等,或處於非平衡狀態。多變異分析可以同時處理平衡或非平衡資料,其功能與anova1、anova2略有不同。此模式之架構如下: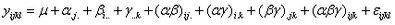
其中有相乘之兩項或三項者,即為其間之交互作用(interaction)產生之效應。在所需之X資料向量中,應有其對應之類別資訊。依其類別資訊可以區分為若干層次,此時可將要設為層次之行歸納在一個細胞陣列 group中。其內可有N層之名單,以此指認X資料之歸屬。在group細胞中之名單可以是一向量、文字陣列或文字細胞陣列,以大括符集合起來,惟其個數需與X中之項目相符。其相關語法如下:
p = anovan(x,group)
p = anovan(x,group,'Param1',val1,'Param2',val2,...)
[p,table] = anovan(...)
[p,table,stats] = anovan(...)
[p,table,stats,terms] = anovan(...)
其參數定義大體上與anova1、anova2等指令相同,每個 GROUP中之變數則必須具有與X等量之元素。在分析後之變異數分析表中,將列出GROUP中之變數名稱。另外增加之參數'Paramx',valx,則可說明如下:
| 'Paramx' | valx |
|---|---|
| 'sstype' | 1, 2, 或 3(預設值)平方和之型式 |
| 'varnames' | 組別名稱預設為 'X1', 'X2', 'X3', ..., 'XN' ,但可利用此參數定義新名稱 |
| 'display' | 顯示ANOVA表,'on' | 'off' |
| 'random' | 以一向量指定群組參數是否為隨機。 |
| 'alpha' | 信任水準(預設值為0.05或95%) |
| 'model' | 決定採用何種函數,如 'linear'其p值僅計算N主效應(預設值); 'interaction'除主效應外尚計算兩者間之交互效應; 'full'計算所有主效應及交互效應。若為整數k(k<=N),則表示計算至k層級。如k=3,表示主效應+兩者間及三者間之交互效應。 若為零壹值矩陣之定義,如[1 0 0] A主效應、[0 1 0] B主效應、[0 0 1 ] C主效應、[1 1 0] AB交互效應、[1 0 1] AC交互效應、[0 1 1] BC交互效應、[1 1 1] ABC交互效應等。 |
在輸出項當中,TERMS矩陣可作為下一次執行ANOVA時,其 MODEL輸入之引數。若MODEL參數不採用隨機型態,其變異分析表T 中之欄位將為TERMS 、SS、DF、奇偶數、均方、F檢測及P值等。若具隨機功能時,則會顯示TERMS之型態(即固定或隨機)、期望均方、F值之除數均方、F值之除數自由度、除數定義、變異項估計值、低限值及高限值等。
輸出參數STATS 的結構包括使用MULTCOMPARE函數之參數及如下項:
coeffs 估計係數
coeffnames 各係數之名稱
vars 組別參數值矩陣
resid 適配模式下之餘數。
具隨機效應時,則另有下列欄位:
ems 期望均方值。
denom 分母定義。
rtnames 隨機項名稱。
varest 變異項估計值(每一隨機項一個)。
varci 各變異項之信任區間
實際上anova2與anovan也可以通用,只是其安排的語法略有不同而已。anova2是將重複的觀察值置於列向,用reps來計算其每組之重複次數,而anovan則必須另外建相關的行作為指示其階數之用。例如下面的例子,假設屬anova2之資料,且是二重複,即reps=2:
X = [25 17 21; 28 18 65; 45 5 60; 42 10 95]
X =
25 17 21
28 18 65
45 5 60
42 10 95
p=anova2(X,2)
p =
0.0175 0.1930 0.2321
上述資料格式若要改為適用anovan,則必須建立對應之行向量。首先建立一個對應三欄的位置m1;其次再建立對應重複的群組m2:
m1=repmat(1:3,4,1)
m2=[ones(2,3);2*ones(2,3)]
m1 =
1 2 3
1 2 3
1 2 3
1 2 3
m2 =
1 1 1
1 1 1
2 2 2
2 2 2
其次,再將X,m1,m2以行向對應起來,如:
X=X(:);m1=m1(:);m2=m2(:);
[X m1 m2]
ans =
25 1 1
28 1 1
45 1 2
42 1 2
17 2 1
18 2 1
5 2 2
10 2 2
21 3 1
65 3 1
60 3 2
95 3 2
此時就可以利用anovan執行分析了。
anovan(X, {m1 m2},2)
ans =
0.0175
0.1930
0.2321
其結果與上述anova1相同。看起來使用naovan好像比較複雜,那是因為轉換為anova1之型式複雜的綠故,若準備資料時就朝naovan之需要處理,則會簡單許多。指令中之參數2即為'model'=2的意思,表示分析結果包括交互作用之影響。若不考慮交互作用,則可以免去,其結果將完全與anova1相同。
下面是一個具三方變異分析之例子,設y為觀察之資料,其餘三組g1、g2、g3為對應之組合項,各組內僅有兩種內容,g1為[1 2]、g2['hi' 'lo']、g3['june' 'may']。由三組內容可知,其項目可為數值,可為文字,但文字必須使用文字字串。
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]';
g1 = [1 2 1 2 1 2 1 2];
g2 = {'hi';'hi';'lo';'lo';'hi';'hi';'lo';'lo'};
g3 = {'may'; 'may'; 'may'; 'may'; 'june'; 'june'; 'june'; 'june'};
利用上述資料進行三方變異分析如下:
>>p = anovan(y, {g1 g2 g3})
p =
0.4174
0.0028
0.9140
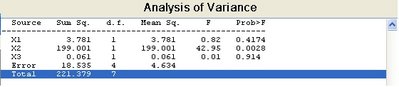
輸出項P值包括三個主項所產生之效應,由其變異分析表可知分為x1、x2、x3對應g1、g2、g3等三組。由於沒有第三項參數,故僅列示主效率部份。若需其交互效應則必須加入2之參數在最後一項,或令'model' = 2。三個P值則對應個別零假設(Null Hypothesis)Ho1、Ho2、Ho3之機率值。基本上P值趨近零,對於零假設的成分愈小。例如,Ho2之對應P值0.0028已足夠小到可以認定該組合項下之某一樣本平均值無法與另一組有顯著之差別。在進行此項研斷之前,通常必須先選定P值之顯著水準門檻值,常用的的有0.005或 0.001,依問題的特性而定。
上述的結果並未考慮交互效應,若要增加此項功能,必須在參數方面設定,即令'mode'=2,或直接使用2即可。例如:
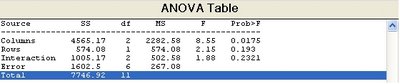
>>[p,table]=anovan(y, {g1 g2 g3},'model',2)
p =
0.0347
0.0048
0.2578
0.0158
0.1444
0.5000
table =
'Source' 'Sum Sq.' 'd.f.' 'Singular?' 'Mean Sq.' 'F' 'Prob>F'
'X1' [ 3.7812] [ 1] [ 0] [ 3.7812] 336.1111] [0.0347]
'X2' [199.0013] [ 1] [ 0] [199.0013] [1.7689e+004] [0.0048]
'X3' [ 0.0612] [ 1] [ 0] [ 0.0612] [ 5.4444] [0.2578]
'X1*X2' [ 18.3012] [ 1] [ 0] [ 18.3012] [1.6268e+003] [0.0158]
'X1*X3' [ 0.2112] [ 1] [ 0] [ 0.2112] [ 18.7778] [0.1444]
'X2*X3' [ 0.0113] [ 1] [ 0] [ 0.0113] [ 1] [0.5000]
'Error' [ 0.0113] [ 1] [ 0] [ 0.0113] [] []
'Total' [221.3788] [ 7] [ 0] [] [] []
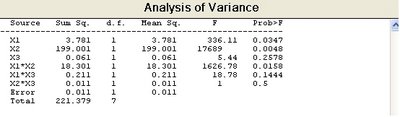
結果會有三項值,其內容大致相同。P值之首三項為主效應,其餘三項為交互效應。在名稱上均預設為x1、x2、x3,此名稱亦可自行設定:
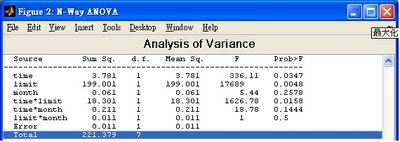
>>p= anovan(y,{g1 g2 g3},'varnames',{'time' 'limit' 'month'},'model',2);
>> aoctool
Note: 6 observations with missing values have been removed.
AOCTOOL 適合單向變異分析(ANOCVA)及繪製變量圖。其執行格式如下:
AOCTOOL(X,Y,G,ALPHA)
上式之輸入參數:X,Y為對應之資料,其中X為已知值,Y為回應值。G則是作為分組之變數。而ALPHA則是信任水準,其預設值為0.05,亦即其信任水準為95%。
執行這個程式後,將出現三個圖表,其中一個為交談曲線圖,可以調整參數使其產生預測值變化,其二為為變異分析表(ANOVA),另一為參數值預測。
除上述輸入參數外, 各參數尚可指定名稱,其圖表亦可開關。其指令型式如下:
AOCTOOL(X,Y,G,ALPHA,XNAME,YNAME,GNAME,DISPLAYOPT,MODEL)
其中XNAME,YNAME,GNAME分別為X軸、Y軸及組別名稱。 DISPLAYOPT 則控制圖形是否顯示('on'為預設值,或否'off'), MODEL 則控制最初適配時之選項,包括:
1 'same mean' (共同均值)
2 'separate means' (分開均值)
3 'same line' (共同預測線)
4 'parallel lines' (平行預測線)
5 'separate lines' (分離預測線)
此外,此一指令亦容許有輸出,其型式如下:
[H,ATAB,CTAB,STATS] = AOCTOOL(...)
其中 H代表圖中各線之握把, ATAB 與 CTAB則為ANOVA表及係數表之內容,而 STATS則為多重均值比較之結果,亦即為 MULTCOMPARE 函數執行的結果。
下面的例子中為利用load carsmall下載最近十餘年(1970-1982)的汽車相關資料。其中包括車重(Weight)、加侖里程數(MPG)及年份(Model_Year)。其資料內容如下,請特別注意在加侖里程之資料中有六點之資料從缺。
>> Weight'
3504 3693 3436 3433 3449 4341 4354
4312 4425 3850 3090 4142 4034 4166
3850 3563 3609 3353 3761 3086 2372
2833 2774 2587 2130 1835 2672 2430
2375 2234 2648 4615 4376 4382 4732
2464 2220 2572 2255 2202 4215 4190
3962 4215 3233 3353 3012 3085 2035
2164 1937 1795 3651 3574 3645 3193
1825 1990 2155 2565 3150 3940 3270
2930 3820 4380 4055 3870 3755 2605
2640 2395 2575 2525 2735 2865 3035
1980 2025 1970 2125 2125 2160 2205
2245 1965 1965 1995 2945 3015 2585
2835 2665 2370 2950 2790 2130 2295
2625 2720
>> MPG'
18.0000 15.0000 18.0000 16.0000 17.0000 15.0000 14.0000 14.0000
14.0000 15.0000 NaN NaN NaN NaN NaN 15.0000
14.0000 NaN 15.0000 14.0000 24.0000 22.0000 18.0000 21.0000
27.0000 26.0000 25.0000 24.0000 25.0000 26.0000 21.0000 10.0000
10.0000 11.0000 9.0000 28.0000 25.0000 25.0000 26.0000 27.0000
17.5000 16.0000 15.5000 14.5000 22.0000 22.0000 24.0000 22.5000
29.0000 24.5000 29.0000 33.0000 20.0000 18.0000 18.5000 17.5000
29.5000 32.0000 28.0000 26.5000 20.0000 13.0000 19.0000 19.0000
16.5000 16.5000 13.0000 13.0000 13.0000 28.0000 27.0000 34.0000
31.0000 29.0000 27.0000 24.0000 23.0000 36.0000 37.0000 31.0000
38.0000 36.0000 36.0000 36.0000 34.0000 38.0000 32.0000 38.0000
25.0000 38.0000 26.0000 22.0000 32.0000 36.0000 27.0000 27.0000
44.0000 32.0000 28.0000 31.0000
>> Model_Year'
70 70 70 70 70 70 70 70 70 70 70 70 70 70
70 70 70 70 70 70 70 70 70 70 70 70 70 70
70 70 70 70 70 70 70 76 76 76 76 76 76 76
76 76 76 76 76 76 76 76 76 76 76 76 76 76
76 76 76 76 76 76再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
——技巧学习篇)
)

















