参考文献:
http://www.blogjava.net/xylz/archive/2010/07/08/325587.html
一、Lock与ReentrantLock
前面的章节主要谈谈原子操作,至于与原子操作一些相关的问题或者说陷阱就放到最后的总结篇来整体说明。从这一章开始花少量的篇幅谈谈锁机制。
上一个章节中谈到了锁机制,并且针对于原子操作谈了一些相关的概念和设计思想。接下来的文章中,尽可能的深入研究锁机制,并且理解里面的原理和实际应用场合。
尽管synchronized在语法上已经足够简单了,在JDK 5之前只能借助此实现,但是由于是独占锁,性能却不高,因此JDK 5以后就开始借助于JNI来完成更高级的锁实现。
JDK 5中的锁是接口java.util.concurrent.locks.Lock。另外java.util.concurrent.locks.ReadWriteLock提供了一对可供读写并发的锁。根据前面的规则,我们从java.util.concurrent.locks.Lock的API开始。
void lock();
获取锁。
如果锁不可用,出于线程调度目的,将禁用当前线程,并且在获得锁之前,该线程将一直处于休眠状态。
void lockInterruptibly() throws InterruptedException;
如果当前线程未被中断,则获取锁。
如果锁可用,则获取锁,并立即返回。
如果锁不可用,出于线程调度目的,将禁用当前线程,并且在发生以下两种情况之一以前,该线程将一直处于休眠状态:
- 锁由当前线程获得;或者
- 其他某个线程中断当前线程,并且支持对锁获取的中断。
如果当前线程:
- 在进入此方法时已经设置了该线程的中断状态;或者
- 在获取锁时被中断,并且支持对锁获取的中断,
则将抛出 InterruptedException,并清除当前线程的已中断状态。
Condition newCondition();
返回绑定到此 Lock 实例的新 Condition 实例。下一小节中会重点谈Condition,此处不做过多的介绍。
boolean tryLock();
仅在调用时锁为空闲状态才获取该锁。
如果锁可用,则获取锁,并立即返回值 true。如果锁不可用,则此方法将立即返回值 false。
通常对于那些不是必须获取锁的操作可能有用。
Lock lock = ...;if (lock.tryLock()) {try {// manipulate protected state} finally {lock.unlock();}} else {// perform alternative actions}
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
如果锁在给定的等待时间内空闲,并且当前线程未被中断,则获取锁。
如果锁可用,则此方法将立即返回值 true。如果锁不可用,出于线程调度目的,将禁用当前线程,并且在发生以下三种情况之一前,该线程将一直处于休眠状态:
- 锁由当前线程获得;或者
- 其他某个线程中断当前线程,并且支持对锁获取的中断;或者
- 已超过指定的等待时间
如果获得了锁,则返回值 true。
如果当前线程:
- 在进入此方法时已经设置了该线程的中断状态;或者
- 在获取锁时被中断,并且支持对锁获取的中断,
则将抛出 InterruptedException,并会清除当前线程的已中断状态。
如果超过了指定的等待时间,则将返回值 false。如果 time 小于等于 0,该方法将完全不等待。
void unlock();
释放锁。对应于lock()、tryLock()、tryLock(xx)、lockInterruptibly()等操作,如果成功的话应该对应着一个unlock(),这样可以避免死锁或者资源浪费。
相对于比较空洞的API,来看一个实际的例子。下面的代码实现了一个类似于AtomicInteger的操作。
package xylz.study.concurrency.lock;import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class AtomicIntegerWithLock {private int value;private Lock lock = new ReentrantLock();public AtomicIntegerWithLock() {super();}public AtomicIntegerWithLock(int value) {this.value = value;}public final int get() {lock.lock();try {return value;} finally {lock.unlock();}}public final void set(int newValue) {lock.lock();try {value = newValue;} finally {lock.unlock();}}public final int getAndSet(int newValue) {lock.lock();try {int ret = value;value = newValue;return ret;} finally {lock.unlock();}}public final boolean compareAndSet(int expect, int update) {lock.lock();try {if (value == expect) {value = update;return true;}return false;} finally {lock.unlock();}}public final int getAndIncrement() {lock.lock();try {return value++;} finally {lock.unlock();}}public final int getAndDecrement() {lock.lock();try {return value--;} finally {lock.unlock();}}public final int incrementAndGet() {lock.lock();try {return ++value;} finally {lock.unlock();}}public final int decrementAndGet() {lock.lock();try {return --value;} finally {lock.unlock();}}public String toString() {return Integer.toString(get());}
}
类AtomicIntegerWithLock是线程安全的,此结构中大量使用了Lock对象的lock/unlock方法对。同样可以看到的是对于自增和自减操作使用了++/--。之所以能够保证线程安全,是因为Lock对象的lock()方法保证了只有一个线程能够只有此锁。需要说明的是对于任何一个lock()方法,都需要一个unlock()方法与之对于,通常情况下为了保证unlock方法总是能够得到执行,unlock方法被置于finally块中。另外这里使用了java.util.concurrent.locks.ReentrantLock.ReentrantLock对象,下一个小节中会具体描述此类作为Lock的唯一实现是如何设计和实现的。
尽管synchronized实现Lock的相同语义,并且在语法上比Lock要简单多,但是前者却比后者的开销要大得多。做一个简单的测试。
public static void main(String[] args) throws Exception{final int max = 10;final int loopCount = 100000;long costTime = 0;for (int m = 0; m < max; m++) {long start1 = System.nanoTime();final AtomicIntegerWithLock value1 = new AtomicIntegerWithLock(0);Thread[] ts = new Thread[max];for(int i=0;i<max;i++) {ts[i] = new Thread() {public void run() {for (int i = 0; i < loopCount; i++) {value1.incrementAndGet();}}};}for(Thread t:ts) {t.start();}for(Thread t:ts) {t.join();}long end1 = System.nanoTime();costTime += (end1-start1);}System.out.println("cost1: " + (costTime));//System.out.println();costTime = 0;//final Object lock = new Object();for (int m = 0; m < max; m++) {staticValue=0;long start1 = System.nanoTime();Thread[] ts = new Thread[max];for(int i=0;i<max;i++) {ts[i] = new Thread() {public void run() {for (int i = 0; i < loopCount; i++) {synchronized(lock) {++staticValue;}}}};}for(Thread t:ts) {t.start();}for(Thread t:ts) {t.join();}long end1 = System.nanoTime();costTime += (end1-start1);}//System.out.println("cost2: " + (costTime));
}static int staticValue = 0;
在这个例子中每次启动10个线程,每个线程计算100000次自增操作,重复测试10次,下面是某此测试的结果:
cost1: 624071136
cost2: 2057847833
尽管上面的例子不是非常正式的测试案例,但上面的例子在于说明,Lock的性能比synchronized的要好得多。如果可以的话总是使用Lock替代synchronized是一个明智的选择。
二、AQS
AbstractQueuedSynchronizer,简称AQS,是J.U.C最复杂的一个类,导致绝大多数讲解并发原理或者实战的时候都不会提到此类。但是虚心的作者愿意借助自己有限的能力和精力来探讨一二(参考资源中也有一些作者做了部分的分析。)。
首先从理论知识开始,在了解了相关原理后会针对源码进行一些分析,最后加上一些实战来描述。
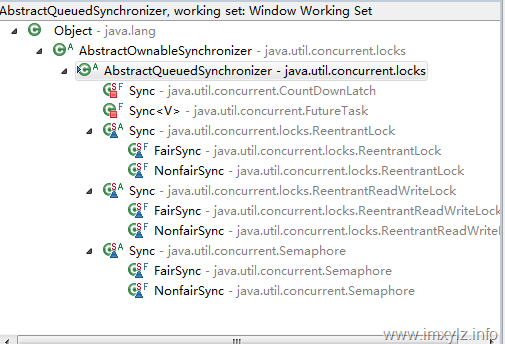
上面的继承体系中,AbstractQueuedSynchronizer是CountDownLatch/FutureTask/ReentrantLock/RenntrantReadWriteLock/Semaphore的基础,因此AbstractQueuedSynchronizer是Lock/Executor实现的前提。公平锁、不公平锁、Condition、CountDownLatch、Semaphore等放到后面的篇幅中说明。
完整的设计原理可以参考Doug Lea的论文 The java.util.concurrent Synchronizer Framework ,这里做一些简要的分析。
基本的思想是表现为一个同步器,支持下面两个操作:
获取锁:首先判断当前状态是否允许获取锁,如果允许就获取锁,否则就阻塞操作或者获取失败,也就是说如果是独占锁就可能阻塞,如果是共享锁就可能失败。另外如果是阻塞线程,那么线程就需要进入阻塞队列。当状态位允许获取锁时就修改状态,并且如果进了队列就从队列中移除。
while(synchronization state does not allow acquire){
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;
释放锁:这个过程就是修改状态位,如果有线程因为状态位阻塞的话就唤醒队列中的一个或者更多线程。
update synchronization state;
if(state may permit a blocked thread to acquire)
unlock one or more queued threads;
要支持上面两个操作就必须有下面的条件:
- 原子性操作同步器的状态位
- 阻塞和唤醒线程
- 一个有序的队列
目标明确,要解决的问题也清晰了,那么剩下的就是解决上面三个问题。
状态位的原子操作
这里使用一个32位的整数来描述状态位,前面章节的原子操作的理论知识整好派上用场,在这里依然使用CAS操作来解决这个问题。事实上这里还有一个64位版本的同步器(AbstractQueuedLongSynchronizer),这里暂且不谈。
阻塞和唤醒线程
标准的JAVA API里面是无法挂起(阻塞)一个线程,然后在将来某个时刻再唤醒它的。JDK 1.0的API里面有Thread.suspend和Thread.resume,并且一直延续了下来。但是这些都是过时的API,而且也是不推荐的做法。
在JDK 5.0以后利用JNI在LockSupport类中实现了此特性。
LockSupport.park()
LockSupport.park(Object)
LockSupport.parkNanos(Object, long)
LockSupport.parkNanos(long)
LockSupport.parkUntil(Object, long)
LockSupport.parkUntil(long)
LockSupport.unpark(Thread)
上面的API中park()是在当前线程中调用,导致线程阻塞,带参数的Object是挂起的对象,这样监视的时候就能够知道此线程是因为什么资源而阻塞的。由于park()立即返回,所以通常情况下需要在循环中去检测竞争资源来决定是否进行下一次阻塞。park()返回的原因有三:
- 其他某个线程调用将当前线程作为目标调用
unpark; - 其他某个线程中断当前线程;
- 该调用不合逻辑地(即毫无理由地)返回。
其实第三条就决定了需要循环检测了,类似于通常写的while(checkCondition()){Thread.sleep(time);}类似的功能。
有序队列
在AQS中采用CHL列表来解决有序的队列的问题。

AQS采用的CHL模型采用下面的算法完成FIFO的入队列和出队列过程。
对于入队列(enqueue):采用CAS操作,每次比较尾结点是否一致,然后插入的到尾结点中。
do {
pred = tail;
}while ( !compareAndSet(pred,tail,node) );
对于出队列(dequeue):由于每一个节点也缓存了一个状态,决定是否出队列,因此当不满足条件时就需要自旋等待,一旦满足条件就将头结点设置为下一个节点。
while (pred.status != RELEASED) ;
head = node;
实际上这里自旋等待也是使用LockSupport.park()来实现的。
AQS里面有三个核心字段:
private volatile int state;
private transient volatile Node head;
private transient volatile Node tail;
其中state描述的有多少个线程取得了锁,对于互斥锁来说state<=1。head/tail加上CAS操作就构成了一个CHL的FIFO队列。下面是Node节点的属性。
volatile int waitStatus; 节点的等待状态,一个节点可能位于以下几种状态:
- CANCELLED = 1: 节点操作因为超时或者对应的线程被interrupt。节点不应该留在此状态,一旦达到此状态将从CHL队列中踢出。
- SIGNAL = -1: 节点的继任节点是(或者将要成为)BLOCKED状态(例如通过LockSupport.park()操作),因此一个节点一旦被释放(解锁)或者取消就需要唤醒(LockSupport.unpack())它的继任节点。
- CONDITION = -2:表明节点对应的线程因为不满足一个条件(Condition)而被阻塞。
- 0: 正常状态,新生的非CONDITION节点都是此状态。
- 非负值标识节点不需要被通知(唤醒)。
volatile Node prev;此节点的前一个节点。节点的waitStatus依赖于前一个节点的状态。
volatile Node next;此节点的后一个节点。后一个节点是否被唤醒(uppark())依赖于当前节点是否被释放。
volatile Thread thread;节点绑定的线程。
Node nextWaiter;下一个等待条件(Condition)的节点,由于Condition是独占模式,因此这里有一个简单的队列来描述Condition上的线程节点。
AQS 在J.U.C里面是一个非常核心的工具,而且也非常复杂,里面考虑到了非常多的逻辑实现,所以在后面的章节中总是不断的尝试介绍AQS的特性和实现。
这一个小节主要介绍了一些理论背景和相关的数据结构,在下一个小节中将根据以上知识来了解Lock.lock/unlock是如何实现的。
三、加锁的原理lock unlock
接上篇,这篇从Lock.lock/unlock开始。特别说明在没有特殊情况下所有程序、API、文档都是基于JDK 6.0的。
public void java.util.concurrent.locks.ReentrantLock.lock()
获取锁。
如果该锁没有被另一个线程保持,则获取该锁并立即返回,将锁的保持计数设置为 1。
如果当前线程已经保持该锁,则将保持计数加 1,并且该方法立即返回。
如果该锁被另一个线程保持,则出于线程调度的目的,禁用当前线程,并且在获得锁之前,该线程将一直处于休眠状态,此时锁保持计数被设置为 1。
从上面的文档可以看出ReentrantLock是可重入锁的实现。而内部是委托java.util.concurrent.locks.ReentrantLock.Sync.lock()实现的。java.util.concurrent.locks.ReentrantLock.Sync是抽象类,有java.util.concurrent.locks.ReentrantLock.FairSync和java.util.concurrent.locks.ReentrantLock.NonfairSync两个实现,也就是常说的公平锁和不公平锁。
1.公平锁和非公平锁
如果获取一个锁是按照请求的顺序得到的,那么就是公平锁,否则就是非公平锁。
在没有深入了解内部机制及实现之前,先了解下为什么会存在公平锁和非公平锁。公平锁保证一个阻塞的线程最终能够获得锁,因为是有序的,所以总是可以按照请求的顺序获得锁。不公平锁意味着后请求锁的线程可能在其前面排列的休眠线程恢复前拿到锁,这样就有可能提高并发的性能。这是因为通常情况下挂起的线程重新开始与它真正开始运行,二者之间会产生严重的延时。因此非公平锁就可以利用这段时间完成操作。这是非公平锁在某些时候比公平锁性能要好的原因之一。
二者在实现上的区别会在后面介绍,我们先从公平锁(FairSync)开始。
前面说过java.util.concurrent.locks.AbstractQueuedSynchronizer (AQS)是Lock的基础,对于一个FairSync而言,lock()就直接调用AQS的acquire(int arg);
public final void acquire(int arg) 以独占模式获取对象,忽略中断。通过至少调用一次
tryAcquire(int)来实现此方法,并在成功时返回。否则在成功之前,一直调用tryAcquire(int)将线程加入队列,线程可能重复被阻塞或不被阻塞。
在介绍实现之前先要补充上一节的知识,对于一个AQS的实现而言,通常情况下需要实现以下方法来描述如何锁定线程。
tryAcquire(int)试图在独占模式下获取对象状态。此方法应该查询是否允许它在独占模式下获取对象状态,如果允许,则获取它。此方法总是由执行 acquire 的线程来调用。如果此方法报告失败,则 acquire 方法可以将线程加入队列(如果还没有将它加入队列),直到获得其他某个线程释放了该线程的信号。也就是说此方法是一种尝试性方法,如果成功获取锁那最好,如果没有成功也没有关系,直接返回false。
tryRelease(int)试图设置状态来反映独占模式下的一个释放。 此方法总是由正在执行释放的线程调用。释放锁可能失败或者抛出异常,这个在后面会具体分析。tryAcquireShared(int) 试图在共享模式下获取对象状态。tryReleaseShared(int) 试图设置状态来反映共享模式下的一个释放。isHeldExclusively() 如果对于当前(正调用的)线程,同步是以独占方式进行的,则返回true。
除了tryAcquire(int)外,其它方法会在后面具体介绍。首先对于ReentrantLock而言,不管是公平锁还是非公平锁,都是独占锁,也就是说同时能够有一个线程持有锁。因此对于acquire(int arg)而言,arg==1。在AQS中acquire的实现如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
这个看起来比较复杂,我们分解以下4个步骤。
- 如果tryAcquire(arg)成功,那就没有问题,已经拿到锁,整个lock()过程就结束了。如果失败进行操作2。
- 创建一个独占节点(Node)并且此节点加入CHL队列末尾。进行操作3。
- 自旋尝试获取锁,失败根据前一个节点来决定是否挂起(park()),直到成功获取到锁。进行操作4。
- 如果当前线程已经中断过,那么就中断当前线程(清除中断位)。
这是一个比较复杂的过程,我们按部就班一个一个分析。
tryAcquire(acquires)
对于公平锁而言,它的实现方式如下:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (isFirst(current) &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
在这段代码中,前面说明对于AQS存在一个state来描述当前有多少线程持有锁。由于AQS支持共享锁(例如读写锁,后面会继续讲),所以这里state>=0,但是由于ReentrantLock是独占锁,所以这里不妨理解为0<=state,acquires=1。isFirst(current)是一个很复杂的逻辑,包括踢出无用的节点等复杂过程,这里暂且不提,大体上的意思是说判断AQS是否为空或者当前线程是否在队列头(为了区分公平与非公平锁)。
- 如果当前锁有其它线程持有,c!=0,进行操作2。否则,如果当前线程在AQS队列头部,则尝试将AQS状态state设为acquires(等于1),成功后将AQS独占线程设为当前线程返回true,否则进行2。这里可以看到compareAndSetState就是使用了CAS操作。
- 判断当前线程与AQS的独占线程是否相同,如果相同,那么就将当前状态位加1(这里+1后结果为负数后面会讲,这里暂且不理它),修改状态位,返回true,否则进行3。这里之所以不是将当前状态位设置为1,而是修改为旧值+1呢?这是因为ReentrantLock是可重入锁,同一个线程每持有一次就+1。
- 返回false。
比较非公平锁的tryAcquire实现java.util.concurrent.locks.ReentrantLock.Sync.nonfairTryAcquire(int),公平锁多了一个判断当前节点是否在队列头,这个就保证了是否按照请求锁的顺序来决定获取锁的顺序(同一个线程的多次获取锁除外)。
现在再回头看公平锁和非公平锁的lock()方法。公平锁只有一句acquire(1);而非公平锁的调用如下:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
很显然,非公平锁在第一次获取锁,或者其它线程释放锁后(可能等待),优先采用compareAndSetState(0,1)然后设置AQS独占线程而持有锁,这样有时候比acquire(1)顺序检查锁持有而要高效。即使在重入锁上,也就是compareAndSetState(0,1)失败,但是是当前线程持有锁上,非公平锁也没有问题。
addWaiter(mode)
tryAcquire失败就意味着入队列了。此时AQS的队列中节点Node就开始发挥作用了。一般情况下AQS支持独占锁和共享锁,而独占锁在Node中就意味着条件(Condition)队列为空(上一篇中介绍过相关概念)。在java.util.concurrent.locks.AbstractQueuedSynchronizer.Node中有两个常量,
static final Node EXCLUSIVE = null; //独占节点模式
static final Node SHARED = new Node(); //共享节点模式
addWaiter(mode)中的mode就是节点模式,也就是共享锁还是独占锁模式。
前面一再强调ReentrantLock是独占锁模式。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
上面是节点如队列的一部分。当前仅当队列不为空并且将新节点插入尾部成功后直接返回新节点。否则进入enq(Node)进行操作。
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
Node h = new Node(); // Dummy header
h.next = node;
node.prev = h;
if (compareAndSetHead(h)) {
tail = node;
return h;
}
}
else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
enq(Node)去队列操作实现了CHL队列的算法,如果为空就创建头结点,然后同时比较节点尾部是否是改变来决定CAS操作是否成功,当且仅当成功后才将为不节点的下一个节点指向为新节点。可以看到这里仍然是CAS操作。
acquireQueued(node,arg)
自旋请求锁,如果可能的话挂起线程,直到得到锁,返回当前线程是否中断过(如果park()过并且中断过的话有一个interrupted中断位)。
final boolean acquireQueued(final Node node, int arg) {
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
}
下面的分析就需要用到上节节点的状态描述了。acquireQueued过程是这样的:
- 如果当前节点是AQS队列的头结点(如果第一个节点是DUMP节点也就是傀儡节点,那么第二个节点实际上就是头结点了),就尝试在此获取锁tryAcquire(arg)。如果成功就将头结点设置为当前节点(不管第一个结点是否是DUMP节点),返回中断位。否则进行2。
- 检测当前节点是否应该park(),如果应该park()就挂起当前线程并且返回当前线程中断位。进行操作1。
一个节点是否该park()是关键,这是由方法java.util.concurrent.locks.AbstractQueuedSynchronizer.shouldParkAfterFailedAcquire(Node, Node)实现的。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int s = pred.waitStatus;
if (s < 0) return true;
if (s > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else compareAndSetWaitStatus(pred, 0, Node.SIGNAL);
return false;
}
- 如果前一个节点的等待状态waitStatus<0,也就是前面的节点还没有获得到锁,那么返回true,表示当前节点(线程)就应该park()了。否则进行2。
- 如果前一个节点的等待状态waitStatus>0,也就是前一个节点被CANCELLED了,那么就将前一个节点去掉,递归此操作直到所有前一个节点的waitStatus<=0,进行4。否则进行3。
- 前一个节点等待状态waitStatus=0,修改前一个节点状态位为SINGAL,表示后面有节点等待你处理,需要根据它的等待状态来决定是否该park()。进行4。
- 返回false,表示线程不应该park()。
selfInterrupt()
private static void selfInterrupt() {
Thread.currentThread().interrupt();
}
如果线程曾经中断过(或者阻塞过)(比如手动interrupt()或者超时等等,那么就再中断一次,中断两次的意思就是清除中断位)。
大体上整个Lock.lock()就这样一个流程。除了lock()方法外,还有lockInterruptibly()/tryLock()/unlock()/newCondition()等,在接下来的章节中会一一介绍。
四、锁释放与条件变量
本小节介绍锁释放Lock.unlock()。
Release/TryRelease
unlock操作实际上就调用了AQS的release操作,释放持有的锁。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
前面提到过tryRelease(arg)操作,此操作里面总是尝试去释放锁,如果成功,说明锁确实被当前线程持有,那么就看AQS队列中的头结点是否为空并且能否被唤醒,如果可以的话就唤醒继任节点(下一个非CANCELLED节点,下面会具体分析)。
对于独占锁而言,java.util.concurrent.locks.ReentrantLock.Sync.tryRelease(int)展示了如何尝试释放锁(tryRelease)操作。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
整个tryRelease操作是这样的:
- 判断持有锁的线程是否是当前线程,如果不是就抛出IllegalMonitorStateExeception(),因为一个线程是不能释放另一个线程持有的锁(否则锁就失去了意义)。否则进行2。
- 将AQS状态位减少要释放的次数(对于独占锁而言总是1),如果剩余的状态位0(也就是没有线程持有锁),那么当前线程就是最后一个持有锁的线程,清空AQS持有锁的独占线程。进行3。
- 将剩余的状态位写回AQS,如果没有线程持有锁就返回true,否则就是false。
参考上一节的分析就可以知道,这里c==0决定了是否完全释放了锁。由于ReentrantLock是可重入锁,因此同一个线程可能多重持有锁,那么当且仅当最后一个持有锁的线程释放锁是才能将AQS中持有锁的独占线程清空,这样接下来的操作才需要唤醒下一个需要锁的AQS节点(Node),否则就只是减少锁持有的计数器,并不能改变其他操作。
当tryRelease操作成功后(也就是完全释放了锁),release操作才能检查是否需要唤醒下一个继任节点。这里的前提是AQS队列的头结点需要锁(waitStatus!=0),如果头结点需要锁,就开始检测下一个继任节点是否需要锁操作。
在上一节中说道acquireQueued操作完成后(拿到了锁),会将当前持有锁的节点设为头结点,所以一旦头结点释放锁,那么就需要寻找头结点的下一个需要锁的继任节点,并唤醒它。
private void unparkSuccessor(Node node) {
//此时node是需要是需要释放锁的头结点//清空头结点的waitStatus,也就是不再需要锁了
compareAndSetWaitStatus(node, Node.SIGNAL, 0);//从头结点的下一个节点开始寻找继任节点,当且仅当继任节点的waitStatus<=0才是有效继任节点,否则将这些waitStatus>0(也就是CANCELLED的节点)从AQS队列中剔除
//这里并没有从head->tail开始寻找,而是从tail->head寻找最后一个有效节点。
//解释在这里 http://www.blogjava.net/xylz/archive/2010/07/08/325540.html#377512Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}//如果找到一个有效的继任节点,就唤醒此节点线程
if (s != null)
LockSupport.unpark(s.thread);
}
这里再一次把acquireQueued的过程找出来。对比unparkSuccessor,一旦头节点的继任节点被唤醒,那么继任节点就会尝试去获取锁(在acquireQueued中node就是有效的继任节点,p就是唤醒它的头结点),如果成功就会将头结点设置为自身,并且将头结点的前任节点清空,这样前任节点(已经过时了)就可以被GC释放了。
final boolean acquireQueued(final Node node, int arg) {
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
}
在setHead中,将头结点的前任节点清空并且将头结点的线程清空就是为了更好的GC,防止内存泄露。
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
对比lock()操作,unlock()操作还是比较简单的,主要就是释放响应的资源,并且唤醒AQS队列中有效的继任节点。这样所就按照请求的顺序去尝试获取锁了。
整个lock()/unlock()过程完成了,我们再回头看公平锁(FairSync)和非公平锁(NonfairSync)。
公平锁和非公平锁只是在获取锁的时候有差别,其它都是一样的。
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
在上面非公平锁的代码中总是优先尝试当前是否有线程持有锁,一旦没有任何线程持有锁,那么非公平锁就霸道的尝试将锁“占为己有”。如果在抢占锁的时候失败就和公平锁一样老老实实的去排队。
也即是说公平锁和非公平锁只是在入AQS的CLH队列之前有所差别,一旦进入了队列,所有线程都是按照队列中先来后到的顺序请求锁。
Condition
条件变量很大一个程度上是为了解决Object.wait/notify/notifyAll难以使用的问题。
条件(也称为条件队列 或条件变量)为线程提供了一个含义,以便在某个状态条件现在可能为 true 的另一个线程通知它之前,一直挂起该线程(即让其“等待”)。因为访问此共享状态信息发生在不同的线程中,所以它必须受保护,因此要将某种形式的锁与该条件相关联。等待提供一个条件的主要属性是:以原子方式 释放相关的锁,并挂起当前线程,就像 Object.wait 做的那样。
上述API说明表明条件变量需要与锁绑定,而且多个Condition需要绑定到同一锁上。前面的Lock中提到,获取一个条件变量的方法是Lock.newCondition()。
void await() throws InterruptedException;
void awaitUninterruptibly();
long awaitNanos(long nanosTimeout) throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
以上是Condition接口定义的方法,await*对应于Object.wait,signal对应于Object.notify,signalAll对应于Object.notifyAll。特别说明的是Condition的接口改变名称就是为了避免与Object中的wait/notify/notifyAll的语义和使用上混淆,因为Condition同样有wait/notify/notifyAll方法。
每一个Lock可以有任意数据的Condition对象,Condition是与Lock绑定的,所以就有Lock的公平性特性:如果是公平锁,线程为按照FIFO的顺序从Condition.await中释放,如果是非公平锁,那么后续的锁竞争就不保证FIFO顺序了。
一个使用Condition实现生产者消费者的模型例子如下。
package xylz.study.concurrency.lock;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class ProductQueue<T> {
private final T[] items;
private final Lock lock = new ReentrantLock();
private Condition notFull = lock.newCondition();
private Condition notEmpty = lock.newCondition();
//
private int head, tail, count;public ProductQueue(int maxSize) {
items = (T[]) new Object[maxSize];
}public ProductQueue() {
this(10);
}public void put(T t) throws InterruptedException {
lock.lock();
try {
while (count == getCapacity()) {
notFull.await();
}
items[tail] = t;
if (++tail == getCapacity()) {
tail = 0;
}
++count;
notEmpty.signalAll();
} finally {
lock.unlock();
}
}public T take() throws InterruptedException {
lock.lock();
try {
while (count == 0) {
notEmpty.await();
}
T ret = items[head];
items[head] = null;//GC
//
if (++head == getCapacity()) {
head = 0;
}
--count;
notFull.signalAll();
return ret;
} finally {
lock.unlock();
}
}public int getCapacity() {
return items.length;
}public int size() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}}
在这个例子中消费take()需要 队列不为空,如果为空就挂起(await()),直到收到notEmpty的信号;生产put()需要队列不满,如果满了就挂起(await()),直到收到notFull的信号。
可能有人会问题,如果一个线程lock()对象后被挂起还没有unlock,那么另外一个线程就拿不到锁了(lock()操作会挂起),那么就无法通知(notify)前一个线程,这样岂不是“死锁”了?
await* 操作
上一节中说过多次ReentrantLock是独占锁,一个线程拿到锁后如果不释放,那么另外一个线程肯定是拿不到锁,所以在lock.lock()和lock.unlock()之间可能有一次释放锁的操作(同样也必然还有一次获取锁的操作)。我们再回头看代码,不管take()还是put(),在进入lock.lock()后唯一可能释放锁的操作就是await()了。也就是说await()操作实际上就是释放锁,然后挂起线程,一旦条件满足就被唤醒,再次获取锁!
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
上面是await()的代码片段。上一节中说过,AQS在获取锁的时候需要有一个CHL的FIFO队列,所以对于一个Condition.await()而言,如果释放了锁,要想再一次获取锁那么就需要进入队列,等待被通知获取锁。完整的await()操作是安装如下步骤进行的:
- 将当前线程加入Condition锁队列。特别说明的是,这里不同于AQS的队列,这里进入的是Condition的FIFO队列。后面会具体谈到此结构。进行2。
- 释放锁。这里可以看到将锁释放了,否则别的线程就无法拿到锁而发生死锁。进行3。
- 自旋(while)挂起,直到被唤醒或者超时或者CACELLED等。进行4。
- 获取锁(acquireQueued)。并将自己从Condition的FIFO队列中释放,表明自己不再需要锁(我已经拿到锁了)。
这里再回头介绍Condition的数据结构。我们知道一个Condition可以在多个地方被await*(),那么就需要一个FIFO的结构将这些Condition串联起来,然后根据需要唤醒一个或者多个(通常是所有)。所以在Condition内部就需要一个FIFO的队列。
private transient Node firstWaiter;
private transient Node lastWaiter;
上面的两个节点就是描述一个FIFO的队列。我们再结合前面提到的节点(Node)数据结构。我们就发现Node.nextWaiter就派上用场了!nextWaiter就是将一系列的Condition.await*串联起来组成一个FIFO的队列。
signal/signalAll 操作
await*()清楚了,现在再来看signal/signalAll就容易多了。按照signal/signalAll的需求,就是要将Condition.await*()中FIFO队列中第一个Node唤醒(或者全部Node)唤醒。尽管所有Node可能都被唤醒,但是要知道的是仍然只有一个线程能够拿到锁,其它没有拿到锁的线程仍然需要自旋等待,就上上面提到的第4步(acquireQueued)。
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
上面的代码很容易看出来,signal就是唤醒Condition队列中的第一个非CANCELLED节点线程,而signalAll就是唤醒所有非CANCELLED节点线程。当然了遇到CANCELLED线程就需要将其从FIFO队列中剔除。
final boolean transferForSignal(Node node) {
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;Node p = enq(node);
int c = p.waitStatus;
if (c > 0 || !compareAndSetWaitStatus(p, c, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
上面就是唤醒一个await*()线程的过程,根据前面的小节介绍的,如果要unpark线程,并使线程拿到锁,那么就需要线程节点进入AQS的队列。所以可以看到在LockSupport.unpark之前调用了enq(node)操作,将当前节点加入到AQS队列。
整个锁机制的原理就介绍完了,从下一节开始就进入了锁机制的应用了。
五、闭锁
闭锁(Latch):一种同步方法,可以延迟线程的进度直到线程到达某个终点状态。通俗的讲就是,一个闭锁相当于一扇大门,在大门打开之前所有线程都被阻断,一旦大门打开所有线程都将通过,但是一旦大门打开,所有线程都通过了,那么这个闭锁的状态就失效了,门的状态也就不能变了,只能是打开状态。也就是说闭锁的状态是一次性的,它确保在闭锁打开之前所有特定的活动都需要在闭锁打开之后才能完成。
CountDownLatch是JDK 5+里面闭锁的一个实现,允许一个或者多个线程等待某个事件的发生。CountDownLatch有一个正数计数器,countDown方法对计数器做减操作,await方法等待计数器达到0。所有await的线程都会阻塞直到计数器为0或者等待线程中断或者超时。
CountDownLatch的API如下。
- public void await() throws InterruptedException
- public boolean await(long timeout, TimeUnit unit) throws InterruptedException
- public void countDown()
- public long getCount()
其中getCount()描述的是当前计数,通常用于调试目的。
下面的例子中描述了闭锁的两种常见的用法。
package xylz.study.concurrency.lock;
import java.util.concurrent.CountDownLatch;
public class PerformanceTestTool {
public long timecost(final int times, final Runnable task) throws InterruptedException {
if (times <= 0) throw new IllegalArgumentException();
final CountDownLatch startLatch = new CountDownLatch(1);
final CountDownLatch overLatch = new CountDownLatch(times);
for (int i = 0; i < times; i++) {
new Thread(new Runnable() {
public void run() {
try {
startLatch.await();
//
task.run();
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
} finally {
overLatch.countDown();
}
}
}).start();
}
//
long start = System.nanoTime();// 准备工作完成,调用下面的方法,打开闭锁
startLatch.countDown();// 主线程在此等候,所有其他线程完成后,主线程开始工作
overLatch.await();
return System.nanoTime() - start;
}}
在上面的例子中使用了两个闭锁,第一个闭锁确保在所有线程开始执行任务前,所有准备工作都已经完成,一旦准备工作完成了就调用startLatch.countDown()打开闭锁,所有线程开始执行。第二个闭锁在于确保所有任务执行完成后主线程才能继续进行,这样保证了主线程等待所有任务线程执行完成后才能得到需要的结果。在第二个闭锁当中,初始化了一个N次的计数器,每个任务执行完成后都会将计数器减一,所有任务完成后计数器就变为了0,这样主线程闭锁overLatch拿到此信号后就可以继续往下执行了。
根据前面的happend-before法则可以知道闭锁有以下特性:
内存一致性效果:线程中调用
countDown()之前的操作 happen-before 紧跟在从另一个线程中对应await()成功返回的操作。
在上面的例子中第二个闭锁相当于把一个任务拆分成N份,每一份独立完成任务,主线程等待所有任务完成后才能继续执行。这个特性在后面的线程池框架中会用到,其实FutureTask就可以看成一个闭锁。后面的章节还会具体分析FutureTask的。
同样基于探索精神,仍然需要“窥探”下CountDownLatch里面到底是如何实现await*和countDown的。
首先,研究下await()方法。内部直接调用了AQS的acquireSharedInterruptibly(1)。
public final void acquireSharedInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
前面一直提到的都是独占锁(排它锁、互斥锁),现在就用到了另外一种锁,共享锁。
所谓共享锁是说所有共享锁的线程共享同一个资源,一旦任意一个线程拿到共享资源,那么所有线程就都拥有的同一份资源。也就是通常情况下共享锁只是一个标志,所有线程都等待这个标识是否满足,一旦满足所有线程都被激活(相当于所有线程都拿到锁一样)。这里的闭锁CountDownLatch就是基于共享锁的实现。
闭锁中关于AQS的tryAcquireShared的实现是如下代码(java.util.concurrent.CountDownLatch.Sync.tryAcquireShared):
public int tryAcquireShared(int acquires) {
return getState() == 0? 1 : -1;
}
在这份逻辑中,对于闭锁而言第一次await时tryAcquireShared应该总是-1,因为对于闭锁CountDownLatch而言state的值就是初始化的count值。这也就解释了为什么在countDown调用之前闭锁的count总是>0。
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
break;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
// Arrive here only if interrupted
cancelAcquire(node);
throw new InterruptedException();
}
上面的逻辑展示了如何通过await将所有线程串联并挂起,直到被唤醒或者条件满足或者被中断。整个过程是这样的:
- 将当前线程节点以共享模式加入AQS的CLH队列中(相关概念参考这里和这里)。进行2。
- 检查当前节点的前任节点,如果是头结点并且当前闭锁计数为0就将当前节点设置为头结点,唤醒继任节点,返回(结束线程阻塞)。否则进行3。
- 检查线程是否该阻塞,如果应该就阻塞(park),直到被唤醒(unpark)。重复2。
- 如果2、3有异常就抛出异常(结束线程阻塞)。
这里有一点值得说明下,设置头结点并唤醒继任节点setHeadAndPropagate。由于前面tryAcquireShared总是返回1或者-1,而进入setHeadAndPropagate时总是propagate>=0,所以这里propagate==1。后面唤醒继任节点操作就非常熟悉了。
private void setHeadAndPropagate(Node node, int propagate) {
setHead(node);
if (propagate > 0 && node.waitStatus != 0) {
Node s = node.next;
if (s == null || s.isShared())
unparkSuccessor(node);
}
}
从上面的所有逻辑可以看出countDown应该就是在条件满足(计数为0)时唤醒头结点(时间最长的一个节点),然后头结点就会根据FIFO队列唤醒整个节点列表(如果有的话)。
从CountDownLatch的countDown代码中看到,直接调用的是AQS的releaseShared(1),参考前面的知识,这就印证了上面的说法。
tryReleaseShared中正是采用CAS操作减少计数(每次减-1)。
public boolean tryReleaseShared(int releases) {
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
整个CountDownLatch就是这个样子的。其实有了前面原子操作和AQS的原理及实现,分析CountDownLatch还是比较容易的。
六、CyclicBarrier
如果说CountDownLatch是一次性的,那么CyclicBarrier正好可以循环使用。它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。所谓屏障点就是一组任务执行完毕的时刻。
清单1 一个使用CyclicBarrier的例子
package xylz.study.concurrency.lock;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;public class CyclicBarrierDemo {
final CyclicBarrier barrier;
final int MAX_TASK;
public CyclicBarrierDemo(int cnt) {
barrier = new CyclicBarrier(cnt + 1);
MAX_TASK = cnt;
}public void doWork(final Runnable work) {
new Thread() {public void run() {
work.run();
try {
int index = barrier.await();
doWithIndex(index);
} catch (InterruptedException e) {
return;
} catch (BrokenBarrierException e) {
return;
}
}
}.start();
}private void doWithIndex(int index) {
if (index == MAX_TASK / 3) {
System.out.println("Left 30%.");
} else if (index == MAX_TASK / 2) {
System.out.println("Left 50%");
} else if (index == 0) {
System.out.println("run over");
}
}public void waitForNext() {
try {
doWithIndex(barrier.await());
} catch (InterruptedException e) {
return;
} catch (BrokenBarrierException e) {
return;
}
}public static void main(String[] args) {
final int count = 10;
CyclicBarrierDemo demo = new CyclicBarrierDemo(count);
for (int i = 0; i < 100; i++) {
demo.doWork(new Runnable() {public void run() {
//do something
try {
Thread.sleep(1000L);
} catch (Exception e) {
return;
}
}
});
if ((i + 1) % count == 0) {
demo.waitForNext();
}
}
}}
清单1描述的是一个周期性处理任务的例子,在这个例子中有一对的任务(100个),希望每10个为一组进行处理,当前仅当上一组任务处理完成后才能进行下一组,另外在每一组任务中,当任务剩下50%,30%以及所有任务执行完成时向观察者发出通知。
在这个例子中,CyclicBarrierDemo 构建了一个count+1的任务组(其中一个任务时为了外界方便挂起主线程)。每一个子任务里,人物本身执行完毕后都需要等待同组内其它任务执行完成后才能继续。同时在剩下任务50%、30%已经0时执行特殊的其他任务(发通知)。
很显然CyclicBarrier有以下几个特点:
- await()方法将挂起线程,直到同组的其它线程执行完毕才能继续
- await()方法返回线程执行完毕的索引,注意,索引时从任务数-1开始的,也就是第一个执行完成的任务索引为parties-1,最后一个为0,这个parties为总任务数,清单中是cnt+1
- CyclicBarrier 是可循环的,显然名称说明了这点。在清单1中,每一组任务执行完毕就能够执行下一组任务。
另外除了CyclicBarrier除了以上特点外,还有以下几个特点:
- 如果屏障操作不依赖于挂起的线程,那么任何线程都可以执行屏障操作。在清单1中可以看到并没有指定那个线程执行50%、30%、0%的操作,而是一组线程(cnt+1)个中任何一个线程只要到达了屏障点都可以执行相应的操作
- CyclicBarrier 的构造函数允许携带一个任务,这个任务将在0%屏障点执行,它将在await()==0后执行。
- CyclicBarrier 如果在await时因为中断、失败、超时等原因提前离开了屏障点,那么任务组中的其他任务将立即被中断,以InterruptedException异常离开线程。
- 所有await()之前的操作都将在屏障点之前运行,也就是CyclicBarrier 的内存一致性效果
CyclicBarrier 的所有API如下:
- public CyclicBarrier(int parties) 创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动 barrier 时执行预定义的操作。
- public CyclicBarrier(int parties, Runnable barrierAction) 创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,并在启动 barrier 时执行给定的屏障操作,该操作由最后一个进入 barrier 的线程执行。
- public int await() throws InterruptedException, BrokenBarrierException 在所有参与者都已经在此 barrier 上调用 await 方法之前,将一直等待。
- public int await(long timeout,TimeUnit unit) throws InterruptedException, BrokenBarrierException,TimeoutException 在所有参与者都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。
- public int getNumberWaiting() 返回当前在屏障处等待的参与者数目。此方法主要用于调试和断言。
- public int getParties() 返回要求启动此 barrier 的参与者数目。
- public boolean isBroken() 查询此屏障是否处于损坏状态。
- public void reset() 将屏障重置为其初始状态。
针对以上API,下面来探讨下CyclicBarrier 的实现原理,以及为什么有这样的API。
清单2 CyclicBarrier.await*()的实现片段
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}int index = --count;
if (index == 0) { // tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}// loop until tripped, broken, interrupted, or timed out
for (;;) {
try {
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}if (g.broken)
throw new BrokenBarrierException();if (g != generation)
return index;if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
清单2有点复杂,这里一点一点的剖析,并且还原到最原始的状态。
利用前面学到的知识,我们知道要想让线程等待其他线程执行完毕,那么已经执行完毕的线程(进入await*()方法)就需要park(),直到超时或者被中断,或者被其它线程唤醒。
前面说过CyclicBarrier 的特点是要么大家都正常执行完毕,要么大家都异常被中断,不会其中有一个被中断而其它正常执行完毕的现象存在。这种特点叫all-or-none。类似的概念是原子操作中的要么大家都执行完,要么一个操作都不执行完。当前这其实是两个概念了。要完成这样的特点就必须有一个状态来描述曾经是否有过线程被中断(broken)了,这样后面执行完的线程就该知道是否需要继续等待了。而在CyclicBarrier 中Generation 就是为了完成这件事情的。Generation的定义非常简单,整个结构就只有一个变量boolean broken = false;,定义是否发生了broken操作。
由于有竞争资源的存在(broken/index),所以毫无疑问需要一把锁lock。拿到锁后整个过程是这样的:
- 检查是否存在中断位(broken),如果存在就立即以BrokenBarrierException异常返回。此异常描述的是线程进入屏障被破坏的等待状态。否则进行2。
- 检查当前线程是否被中断,如果是那么就设置中断位(使其它将要进入等待的线程知道),另外唤醒已经等待的线程,同时以InterruptedException异常返回,表示线程要处理中断。否则进行3。
- 将剩余任务数减1,如果此时剩下的任务数为0,也就是达到了公共屏障点,那么就执行屏障点任务(如果有的话),同时创建新的Generation(在这个过程中会唤醒其它所有线程,因此当前线程是屏障点线程,那么其它线程就都应该在等待状态)。否则进行4。
- 到这里说明还没有到达屏障点,那么此时线程就应该park()。很显然在下面的for循环中就是要park线程。这里park线程采用的是Condition.await()方法。也就是trip.await*()。为什么需要Condition?因为所有的await*()其实等待的都是一个条件,一旦条件满足就应该都被唤醒,所以Condition整好满足这个特点。所以到这里就会明白为什么在步骤3中到达屏障点时创建新的Generation的时候是一定要唤醒其它线程的原因了。
上面4个步骤其实只是描述主体结构,事实上整个过程中有非常多的逻辑来处理异常引发的问题,比如执行屏障点任务引发的异常,park线程超时引发的中断异常和超时异常等等。所以对于await()而言,异常的处理比业务逻辑的处理更复杂,这就解释了为什么await()的时候可能引发InterruptedException,BrokenBarrierException,TimeoutException 三种异常。
清单3 生成下一个循环周期并唤醒其它线程
private void nextGeneration() {
trip.signalAll();
count = parties;
generation = new Generation();
}
清单3 描述了如何生成下一个循环周期的过程,在这个过程中当然需要使用Condition.signalAll()唤醒所有已经执行完成并且正在等待的线程。另外这里count描述的是还有多少线程需要执行,是为了线程执行完毕索引计数。
isBroken() 方法描述的就是generation.broken,也即线程组是否发生了异常。这里再一次解释下为什么要有这个状态的存在。
如果一个将要位于屏障点或者已经位于屏障点的而执行屏障点任务的线程发生了异常,那么即使唤醒了其它等待的线程,其它等待的线程也会因为循环等待而“死去”,因为再也没有一个线程来唤醒这些第二次进行park的线程了。还有一个意图是,如果屏障点都已经损坏了,那么其它将要等待屏障点的再线程挂起就没有意义了。
写到这里的时候非常不幸,用了4年多了台灯终于“寿终正寝了”。
其实CyclicBarrier 还有一个reset方法,描述的是手动立即将所有线程中断,恢复屏障点,进行下一组任务的执行。也就是与重新创建一个新的屏障点相比,可能维护的代价要小一些(减少同步,减少上一个CyclicBarrier 的管理等等)。
本来是想和Semaphore 一起将的,最后发现铺开后就有点长了,而且也不利于理解和吸收,所以放到下一篇吧。
七、信号量(Semaphore)
Semaphore 是一个计数信号量。从概念上讲,信号量维护了一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。
说白了,Semaphore是一个计数器,在计数器不为0的时候对线程就放行,一旦达到0,那么所有请求资源的新线程都会被阻塞,包括增加请求到许可的线程,也就是说Semaphore不是可重入的。每一次请求一个许可都会导致计数器减少1,同样每次释放一个许可都会导致计数器增加1,一旦达到了0,新的许可请求线程将被挂起。
缓存池整好使用此思想来实现的,比如链接池、对象池等。
清单1 对象池
package xylz.study.concurrency.lock;
import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class ObjectCache<T> {
public interface ObjectFactory<T> {
T makeObject();
}class Node {
T obj;
Node next;
}final int capacity;
final ObjectFactory<T> factory;
final Lock lock = new ReentrantLock();
final Semaphore semaphore;
private Node head;
private Node tail;
public ObjectCache(int capacity, ObjectFactory<T> factory) {
this.capacity = capacity;
this.factory = factory;
this.semaphore = new Semaphore(this.capacity);
this.head = null;
this.tail = null;
}public T getObject() throws InterruptedException {
//获取一个信号量
semaphore.acquire();
return getNextObject();
}private T getNextObject() {
lock.lock();
try {
if (head == null) {
return factory.makeObject();
} else {
Node ret = head;
head = head.next;
if (head == null) tail = null;
ret.next = null;//help GC
return ret.obj;
}
} finally {
lock.unlock();
}
}private void returnObjectToPool(T t) {
lock.lock();
try {
Node node = new Node();
node.obj = t;
if (tail == null) {
head = tail = node;
} else {
tail.next = node;
tail = node;
}} finally {
lock.unlock();
}
}public void returnObject(T t) {
returnObjectToPool(t);//返回一个信号量
semaphore.release();
}}
清单1描述了一个基于信号量Semaphore的对象池实现。此对象池最多支持capacity个对象,这在构造函数中传入。对象池有一个基于FIFO的队列,每次从对象池的头结点开始取对象,如果头结点为空就直接构造一个新的对象返回。否则将头结点对象取出,并且头结点往后移动。特别要说明的如果对象的个数用完了,那么新的线程将被阻塞,直到有对象被返回回来。返还对象时将对象加入FIFO的尾节点并且释放一个空闲的信号量,表示对象池中增加一个可用对象。
实际上对象池、线程池的原理大致上就是这样的,只不过真正的对象池、线程池要处理比较复杂的逻辑,所以实现起来还需要做很多的工作,例如超时机制,自动回收机制,对象的有效期等等问题。
这里特别说明的是信号量只是在信号不够的时候挂起线程,但是并不能保证信号量足够的时候获取对象和返还对象是线程安全的,所以在清单1中仍然需要锁Lock来保证并发的正确性。
将信号量初始化为 1,使得它在使用时最多只有一个可用的许可,从而可用作一个相互排斥的锁。这通常也称为二进制信号量,因为它只能有两种状态:一个可用的许可,或零个可用的许可。按此方式使用时,二进制信号量具有某种属性(与很多 Lock 实现不同),即可以由线程释放“锁”,而不是由所有者(因为信号量没有所有权的概念)。在某些专门的上下文(如死锁恢复)中这会很有用。
上面这段话的意思是说当某个线程A持有信号量数为1的信号量时,其它线程只能等待此线程释放资源才能继续,这时候持有信号量的线程A就相当于持有了“锁”,其它线程的继续就需要这把锁,于是线程A的释放才能决定其它线程的运行,相当于扮演了“锁”的角色。
另外同公平锁非公平锁一样,信号量也有公平性。如果一个信号量是公平的表示线程在获取信号量时按FIFO的顺序得到许可,也就是按照请求的顺序得到释放。这里特别说明的是:所谓请求的顺序是指在请求信号量而进入FIFO队列的顺序,有可能某个线程先请求信号而后进去请求队列,那么次线程获取信号量的顺序就会晚于其后请求但是先进入请求队列的线程。这个在公平锁和非公平锁中谈过很多。
除了acquire以外,Semaphore还有几种类似的acquire方法,这些方法可以更好的处理中断和超时或者异步等特性,可以参考JDK API。
按照同样的学习原则,下面对主要的实现进行分析。Semaphore的acquire方法实际上访问的是AQS的acquireSharedInterruptibly(arg)方法。这个可以参考CountDownLatch一节或者AQS一节。
所以Semaphore的await实现也是比较简单的。与CountDownLatch不同的是,Semaphore区分公平信号和非公平信号。
清单2 公平信号获取方法
protected int tryAcquireShared(int acquires) {
Thread current = Thread.currentThread();
for (;;) {
Thread first = getFirstQueuedThread();
if (first != null && first != current)
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
清单3 非公平信号获取方法
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
对比清单2和清单3可以看到,公平信号和非公平信号在于第一次尝试能否获取信号时,公平信号量总是将当前线程进入AQS的CLH队列进行排队(因为第一次尝试时队列的头结点线程很有可能不是当前线程,当然不排除同一个线程第二次进入信号量),从而根据AQS的CLH队列的顺序FIFO依次获取信号量;而对于非公平信号量,第一次立即尝试能否拿到信号量,一旦信号量的剩余数available大于请求数(acquires通常为1),那么线程就立即得到了释放,而不需要进行AQS队列进行排队。只有remaining<0的时候(也就是信号量不够的时候)才会进入AQS队列。
所以非公平信号量的吞吐量总是要比公平信号量的吞吐量要大,但是需要强调的是非公平信号量和非公平锁一样存在“饥渴死”的现象,也就是说活跃线程可能总是拿到信号量,而非活跃线程可能难以拿到信号量。而对于公平信号量由于总是靠请求的线程的顺序来获取信号量,所以不存在此问题。
八、读写锁
从这一节开始介绍锁里面的最后一个工具:读写锁(ReadWriteLock)。
ReentrantLock 实现了标准的互斥操作,也就是一次只能有一个线程持有锁,也即所谓独占锁的概念。前面的章节中一直在强调这个特点。显然这个特点在一定程度上面减低了吞吐量,实际上独占锁是一种保守的锁策略,在这种情况下任何“读/读”,“写/读”,“写/写”操作都不能同时发生。但是同样需要强调的一个概念是,锁是有一定的开销的,当并发比较大的时候,锁的开销就比较客观了。所以如果可能的话就尽量少用锁,非要用锁的话就尝试看能否改造为读写锁。
ReadWriteLock描述的是:一个资源能够被多个读线程访问,或者被一个写线程访问,但是不能同时存在读写线程。也就是说读写锁使用的场合是一个共享资源被大量读取操作,而只有少量的写操作(修改数据)。清单1描述了ReadWriteLock的API。
清单1 ReadWriteLock 接口
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
清单1描述的ReadWriteLock结构,这里需要说明的是ReadWriteLock并不是Lock的子接口,只不过ReadWriteLock借助Lock来实现读写两个视角。在ReadWriteLock中每次读取共享数据就需要读取锁,当需要修改共享数据时就需要写入锁。看起来好像是两个锁,但其实不尽然,在下一节中的分析中会解释这点奥秘。
在JDK 6里面ReadWriteLock的实现是ReentrantReadWriteLock。
清单2 SimpleConcurrentMap
package xylz.study.concurrency.lock;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;public class SimpleConcurrentMap<K, V> implements Map<K, V> {
final ReadWriteLock lock = new ReentrantReadWriteLock();
final Lock r = lock.readLock();
final Lock w = lock.writeLock();
final Map<K, V> map;
public SimpleConcurrentMap(Map<K, V> map) {
this.map = map;
if (map == null) throw new NullPointerException();
}public void clear() {
w.lock();
try {
map.clear();
} finally {
w.unlock();
}
}public boolean containsKey(Object key) {
r.lock();
try {
return map.containsKey(key);
} finally {
r.unlock();
}
}public boolean containsValue(Object value) {
r.lock();
try {
return map.containsValue(value);
} finally {
r.unlock();
}
}public Set<java.util.Map.Entry<K, V>> entrySet() {
throw new UnsupportedOperationException();
}public V get(Object key) {
r.lock();
try {
return map.get(key);
} finally {
r.unlock();
}
}public boolean isEmpty() {
r.lock();
try {
return map.isEmpty();
} finally {
r.unlock();
}
}public Set<K> keySet() {
r.lock();
try {
return new HashSet<K>(map.keySet());
} finally {
r.unlock();
}
}public V put(K key, V value) {
w.lock();
try {
return map.put(key, value);
} finally {
w.unlock();
}
}public void putAll(Map<? extends K, ? extends V> m) {
w.lock();
try {
map.putAll(m);
} finally {
w.unlock();
}
}public V remove(Object key) {
w.lock();
try {
return map.remove(key);
} finally {
w.unlock();
}
}public int size() {
r.lock();
try {
return map.size();
} finally {
r.unlock();
}
}public Collection<V> values() {
r.lock();
try {
return new ArrayList<V>(map.values());
} finally {
r.unlock();
}
}}
清单2描述的是用读写锁实现的一个线程安全的Map。其中需要特别说明的是并没有实现entrySet()方法,这是因为实现这个方法比较复杂,在后面章节中讲到ConcurrentHashMap的时候会具体谈这些细节。另外这里keySet()和values()也没有直接返回Map的视图,而是一个映射原有元素的新视图,其实这个entrySet()一样,是为了保护原始Map的数据逻辑,防止不正确的修改导致原始Map发生数据错误。特别说明的是在没有特别需求的情况下没有必要按照清单2写一个线程安全的Map实现,因为ConcurrentHashMap已经完成了此操作。
ReadWriteLock需要严格区分读写操作,如果读操作使用了写入锁,那么降低读操作的吞吐量,如果写操作使用了读取锁,那么就可能发生数据错误。
另外ReentrantReadWriteLock还有以下几个特性:
- 公平性
- 非公平锁(默认) 这个和独占锁的非公平性一样,由于读线程之间没有锁竞争,所以读操作没有公平性和非公平性,写操作时,由于写操作可能立即获取到锁,所以会推迟一个或多个读操作或者写操作。因此非公平锁的吞吐量要高于公平锁。
- 公平锁 利用AQS的CLH队列,释放当前保持的锁(读锁或者写锁)时,优先为等待时间最长的那个写线程分配写入锁,当前前提是写线程的等待时间要比所有读线程的等待时间要长。同样一个线程持有写入锁或者有一个写线程已经在等待了,那么试图获取公平锁的(非重入)所有线程(包括读写线程)都将被阻塞,直到最先的写线程释放锁。如果读线程的等待时间比写线程的等待时间还有长,那么一旦上一个写线程释放锁,这一组读线程将获取锁。
- 重入性
- 读写锁允许读线程和写线程按照请求锁的顺序重新获取读取锁或者写入锁。当然了只有写线程释放了锁,读线程才能获取重入锁。
- 写线程获取写入锁后可以再次获取读取锁,但是读线程获取读取锁后却不能获取写入锁。
- 另外读写锁最多支持65535个递归写入锁和65535个递归读取锁。
- 锁降级
- 写线程获取写入锁后可以获取读取锁,然后释放写入锁,这样就从写入锁变成了读取锁,从而实现锁降级的特性。
- 锁升级
- 读取锁是不能直接升级为写入锁的。因为获取一个写入锁需要释放所有读取锁,所以如果有两个读取锁视图获取写入锁而都不释放读取锁时就会发生死锁。
- 锁获取中断
- 读取锁和写入锁都支持获取锁期间被中断。这个和独占锁一致。
- 条件变量
- 写入锁提供了条件变量(Condition)的支持,这个和独占锁一致,但是读取锁却不允许获取条件变量,将得到一个
UnsupportedOperationException异常。
- 写入锁提供了条件变量(Condition)的支持,这个和独占锁一致,但是读取锁却不允许获取条件变量,将得到一个
- 重入数
- 读取锁和写入锁的数量最大分别只能是65535(包括重入数)。这在下节中有介绍。
上面几个特性对读写锁的理解很有帮助,而且也是必要的,另外在下一节中讲ReadWriteLock的实现会用到这些知识的。
九、读写锁的实现
这一节主要是谈谈读写锁的实现。
上一节中提到,ReadWriteLock看起来有两个锁:readLock/writeLock。如果真的是两个锁的话,它们之间又是如何相互影响的呢?
事实上在ReentrantReadWriteLock里锁的实现是靠java.util.concurrent.locks.ReentrantReadWriteLock.Sync完成的。这个类看起来比较眼熟,实际上它是AQS的一个子类,这中类似的结构在CountDownLatch、ReentrantLock、Semaphore里面都存在。同样它也有两种实现:公平锁和非公平锁,也就是java.util.concurrent.locks.ReentrantReadWriteLock.FairSync和java.util.concurrent.locks.ReentrantReadWriteLock.NonfairSync。这里暂且不提。
在ReentrantReadWriteLock里面的锁主体就是一个Sync,也就是上面提到的FairSync或者NonfairSync,所以说实际上只有一个锁,只是在获取读取锁和写入锁的方式上不一样,所以前面才有读写锁是独占锁的两个不同视图一说。
ReentrantReadWriteLock里面有两个类:ReadLock/WriteLock,这两个类都是Lock的实现。
清单1 ReadLock 片段
public static class ReadLock implements Lock, java.io.Serializable {
private final Sync sync;protected ReadLock(ReentrantReadWriteLock lock) {
sync = lock.sync;
}public void lock() {
sync.acquireShared(1);
}public void lockInterruptibly() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}public boolean tryLock() {
return sync.tryReadLock();
}public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}public void unlock() {
sync.releaseShared(1);
}public Condition newCondition() {
throw new UnsupportedOperationException();
}}
清单2 WriteLock 片段
public static class WriteLock implements Lock, java.io.Serializable {
private final Sync sync;
protected WriteLock(ReentrantReadWriteLock lock) {
sync = lock.sync;
}
public void lock() {
sync.acquire(1);
}public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}public boolean tryLock( ) {
return sync.tryWriteLock();
}public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}public void unlock() {
sync.release(1);
}public Condition newCondition() {
return sync.newCondition();
}public boolean isHeldByCurrentThread() {
return sync.isHeldExclusively();
}public int getHoldCount() {
return sync.getWriteHoldCount();
}
}
清单1描述的是读锁的实现,清单2描述的是写锁的实现。显然WriteLock就是一个独占锁,这和ReentrantLock里面的实现几乎相同,都是使用了AQS的acquire/release操作。当然了在内部处理方式上与ReentrantLock还是有一点不同的。对比清单1和清单2可以看到,ReadLock获取的是共享锁,WriteLock获取的是独占锁。
在AQS章节中介绍到AQS中有一个state字段(int类型,32位)用来描述有多少线程获持有锁。在独占锁的时代这个值通常是0或者1(如果是重入的就是重入的次数),在共享锁的时代就是持有锁的数量。在上一节中谈到,ReadWriteLock的读、写锁是相关但是又不一致的,所以需要两个数来描述读锁(共享锁)和写锁(独占锁)的数量。显然现在一个state就不够用了。于是在ReentrantReadWrilteLock里面将这个字段一分为二,高位16位表示共享锁的数量,低位16位表示独占锁的数量(或者重入数量)。2^16-1=65536,这就是上节中提到的为什么共享锁和独占锁的数量最大只能是65535的原因了。
有了上面的知识后再来分析读写锁的获取和释放就容易多了。
清单3 写入锁获取片段
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
}
if ((w == 0 && writerShouldBlock(current)) ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
清单3 是写入锁获取的逻辑片段,整个工作流程是这样的:
- 持有锁线程数非0(c=getState()不为0),如果写线程数(w)为0(那么读线程数就不为0)或者独占锁线程(持有锁的线程)不是当前线程就返回失败,或者写入锁的数量(其实是重入数)大于65535就抛出一个Error异常。否则进行2。
- 如果当且写线程数位0(那么读线程也应该为0,因为步骤1已经处理c!=0的情况),并且当前线程需要阻塞那么就返回失败;如果增加写线程数失败也返回失败。否则进行3。
- 设置独占线程(写线程)为当前线程,返回true。
清单3 中 exclusiveCount(c)就是获取写线程数(包括重入数),也就是state的低16位值。另外这里有一段逻辑是当前写线程是否需要阻塞writerShouldBlock(current)。清单4 和清单5 就是公平锁和非公平锁中是否需要阻塞的片段。很显然对于非公平锁而言总是不阻塞当前线程,而对于公平锁而言如果AQS队列不为空或者当前线程不是在AQS的队列头那么就阻塞线程,直到队列前面的线程处理完锁逻辑。
清单4 公平读写锁写线程是否阻塞
final boolean writerShouldBlock(Thread current) {
return !isFirst(current);
}
清单5 非公平读写锁写线程是否阻塞
final boolean writerShouldBlock(Thread current) {
return false;
}
写入锁的获取逻辑清楚后,释放锁就比较简单了。清单6 描述的写入锁释放逻辑片段,其实就是检测下剩下的写入锁数量,如果是0就将独占锁线程清空(意味着没有线程获取锁),否则就是说当前是重入锁的一次释放,所以不能将独占锁线程清空。然后将剩余线程状态数写回AQS。
清单6 写入锁释放逻辑片段
protected final boolean tryRelease(int releases) {
int nextc = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
if (exclusiveCount(nextc) == 0) {
setExclusiveOwnerThread(null);
setState(nextc);
return true;
} else {
setState(nextc);
return false;
}
}
清单3~6 描述的写入锁的获取释放过程。读取锁的获取和释放过程要稍微复杂些。 清单7描述的是读取锁的获取过程。
清单7 读取锁获取过程片段
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
if (!readerShouldBlock(current) &&
compareAndSetState(c, c + SHARED_UNIT)) {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != current.getId())
cachedHoldCounter = rh = readHolds.get();
rh.count++;
return 1;
}
return fullTryAcquireShared(current);
}final int fullTryAcquireShared(Thread current) {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != current.getId())
rh = readHolds.get();
for (;;) {
int c = getState();
int w = exclusiveCount(c);
if ((w != 0 && getExclusiveOwnerThread() != current) ||
((rh.count | w) == 0 && readerShouldBlock(current)))
return -1;
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) {
cachedHoldCounter = rh; // cache for release
rh.count++;
return 1;
}
}
}
读取锁获取的过程是这样的:
- 如果写线程持有锁(也就是独占锁数量不为0),并且独占线程不是当前线程,那么就返回失败。因为允许写入线程获取锁的同时获取读取锁。否则进行2。
- 如果读线程请求锁数量达到了65535(包括重入锁),那么就跑出一个错误Error,否则进行3。
- 如果读线程不用等待(实际上是是否需要公平锁),并且增加读取锁状态数成功,那么就返回成功,否则进行4。
- 步骤3失败的原因是CAS操作修改状态数失败,那么就需要循环不断尝试去修改状态直到成功或者锁被写入线程占有。实际上是过程3的不断尝试直到CAS计数成功或者被写入线程占有锁。
在清单7 中有一个对象HoldCounter,这里暂且不提这是什么结构和为什么存在这样一个结构。
接下来根据清单8 我们来看如何释放一个读取锁。同样先不理HoldCounter,关键的在于for循环里面,其实就是一个不断尝试的CAS操作,直到修改状态成功。前面说过state的高16位描述的共享锁(读取锁)的数量,所以每次都需要减去2^16,这样就相当于读取锁数量减1。实际上SHARED_UNIT=1<<16。
清单8 读取锁释放过程
protected final boolean tryReleaseShared(int unused) {
HoldCounter rh = cachedHoldCounter;
Thread current = Thread.currentThread();
if (rh == null || rh.tid != current.getId())
rh = readHolds.get();
if (rh.tryDecrement() <= 0)
throw new IllegalMonitorStateException();
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
好了,现在回头看HoldCounter到底是一个什么东西。首先我们可以看到只有在获取共享锁(读取锁)的时候加1,也只有在释放共享锁的时候减1有作用,并且在释放锁的时候抛出了一个IllegalMonitorStateException异常。而我们知道IllegalMonitorStateException通常描述的是一个线程操作一个不属于自己的监视器对象的引发的异常。也就是说这里的意思是一个线程释放了一个不属于自己或者不存在的共享锁。
前面的章节中一再强调,对于共享锁,其实并不是锁的概念,更像是计数器的概念。一个共享锁就相对于一次计数器操作,一次获取共享锁相当于计数器加1,释放一个共享锁就相当于计数器减1。显然只有线程持有了共享锁(也就是当前线程携带一个计数器,描述自己持有多少个共享锁或者多重共享锁),才能释放一个共享锁。否则一个没有获取共享锁的线程调用一次释放操作就会导致读写锁的state(持有锁的线程数,包括重入数)错误。
明白了HoldCounter的作用后我们就可以猜到它的作用其实就是当前线程持有共享锁(读取锁)的数量,包括重入的数量。那么这个数量就必须和线程绑定在一起。
在Java里面将一个对象和线程绑定在一起,就只有ThreadLocal才能实现了。所以毫无疑问HoldCounter就应该是绑定到线程上的一个计数器。
清单9 线程持有读取锁数量的计数器
static final class HoldCounter {
int count;
final long tid = Thread.currentThread().getId();
int tryDecrement() {
int c = count;
if (c > 0)
count = c - 1;
return c;
}
}static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
清单9 描述的是线程持有读取锁数量的计数器。可以看到这里使用ThreadLocal将HoldCounter绑定到当前线程上,同时HoldCounter也持有线程Id,这样在释放锁的时候才能知道ReadWriteLock里面缓存的上一个读取线程(cachedHoldCounter)是否是当前线程。这样做的好处是可以减少ThreadLocal.get()的次数,因为这也是一个耗时操作。需要说明的是这样HoldCounter绑定线程id而不绑定线程对象的原因是避免HoldCounter和ThreadLocal互相绑定而GC难以释放它们(尽管GC能够智能的发现这种引用而回收它们,但是这需要一定的代价),所以其实这样做只是为了帮助GC快速回收对象而已。
除了readLock()和writeLock()外,Lock对象还允许tryLock(),那么ReadLock和WriteLock的tryLock()不一样。清单10 和清单11 分别描述了读取锁的tryLock()和写入锁的tryLock()。
读取锁tryLock()也就是tryReadLock()成功的条件是:没有写入锁或者写入锁是当前线程,并且读线程共享锁数量没有超过65535个。
写入锁tryLock()也就是tryWriteLock()成功的条件是: 没有写入锁或者写入锁是当前线程,并且尝试一次修改state成功。
清单10 读取锁的tryLock()
final boolean tryReadLock() {
Thread current = Thread.currentThread();
for (;;) {
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return false;
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != current.getId())
cachedHoldCounter = rh = readHolds.get();
rh.count++;
return true;
}
}
}
清单11 写入锁的tryLock()
final boolean tryWriteLock() {
Thread current = Thread.currentThread();
int c = getState();
if (c != 0) {
int w = exclusiveCount(c);
if (w == 0 ||current != getExclusiveOwnerThread())
return false;
if (w == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
}
if (!compareAndSetState(c, c + 1))
return false;
setExclusiveOwnerThread(current);
return true;
}
整个读写锁的逻辑大概就这么多,其实真正研究起来也不是很复杂,真正复杂的东西都在AQS里面。
十、锁的一些其他问题
主要谈谈锁的性能以及其它一些理论知识,内容主要的出处是《Java Concurrency in Practice》,结合自己的理解和实际应用对锁机制进行一个小小的总结。
首先需要强调的一点是:所有锁(包括内置锁和高级锁)都是有性能消耗的,也就是说在高并发的情况下,由于锁机制带来的上下文切换、资源同步等消耗是非常可观的。在某些极端情况下,线程在锁上的消耗可能比线程本身的消耗还要多。所以如果可能的话,在任何情况下都尽量少用锁,如果不可避免那么采用非阻塞算法是一个不错的解决方案,但是却也不是绝对的。
内部锁
Java语言通过synchronized关键字来保证原子性。这是因为每一个Object都有一个隐含的锁,这个也称作监视器对象。在进入synchronized之前自动获取此内部锁,而一旦离开此方式(不管通过和中方式离开此方法)都会自动释放锁。显然这是一个独占锁,每个锁请求之间是互斥的。相对于前面介绍的众多高级锁(Lock/ReadWriteLock等),synchronized的代价都比后者要高。但是synchronized的语法比较简单,而且也比较容易使用和理解,不容易写法上的错误。而我们知道Lock一旦调用了lock()方法获取到锁而未正确释放的话很有可能就死锁了。所以Lock的释放操作总是跟在finally代码块里面,这在代码结构上也是一次调整和冗余。另外前面介绍中说过Lock的实现已经将硬件资源用到了极致,所以未来可优化的空间不大,除非硬件有了更高的性能。但是synchronized只是规范的一种实现,这在不同的平台不同的硬件还有很高的提升空间,未来Java在锁上的优化也会主要在这上面。
性能
由于锁总是带了性能影响,所以是否使用锁和使用锁的场合就变得尤为重要。如果在一个高并发的Web请求中使用了强制的独占锁,那么就可以发现Web的吞吐量将急剧下降。
为了利用并发来提高性能,出发点就是:更有效的利用现有的资源,同时让程序尽可能的开拓更多可用的资源。这意味着机器尽可能的处于忙碌的状态,通常意义是说CPU忙于计算,而不是等待。当然CPU要做有用的事情,而不是进行无谓的循环。当然在实践中通常会预留一些资源出来以便应急特殊情况,这在以后的线程池并发中可以看到很多例子。
线程阻塞
锁机制的实现通常需要操作系统提供支持,显然这会增加开销。当锁竞争的时候,失败的线程必然会发生阻塞。JVM既能自旋等待(不断尝试,知道成功,很多CAS就是这样实现的),也能够在操作系统中挂起阻塞的线程,直到超时或者被唤醒。通常情况下这取决于上下文切换的开销以及与获取锁需要等待的时间二者之间的关系。自旋等待适合于比较短的等待,而挂起线程比较适合那些比较耗时的等待。
挂起一个线程可能是因为无法获取到锁,或者需要某个特定的条件,或者耗时的I/O操作。挂起一个线程需要两次额外的上下文切换以及操作系统、缓存等多资源的配合:如果线程被提前换出,那么一旦拿到锁或者条件满足,那么又需要将线程换回执行队列,这对线程而言,两次上下文切换可能比较耗时。
锁竞争
影响锁竞争性的条件有两个:锁被请求的频率和每次持有锁的时间。显然当而这二者都很小的时候,锁竞争不会成为主要的瓶颈。但是如果锁使用不当,导致二者都比较大,那么很有可能CPU不能有效的处理任务,任务被大量堆积。
所以减少锁竞争的方式有下面三种:
- 减少锁持有的时间
- 减少锁请求的频率
- 采用共享锁取代独占锁
死锁
如果一个线程永远不释放另外一个线程需要的资源那么就会导致死锁。这有两种情况:一种情况是线程A永远不释放锁,结果B一直拿不到锁,所以线程B就“死掉”了;第二种情况下,线程A拥有线程B需要的锁Y,同时线程B拥有线程A需要的锁X,那么这时候线程A/B互相依赖对方释放锁,于是二者都“死掉”了。
还有一种情况为发生死锁,如果一个线程总是不能被调度,那么等待此线程结果的线程可能就死锁了。这种情况叫做线程饥饿死锁。比如说在前面介绍的非公平锁中,如果某些线程非常活跃,在高并发情况下这类线程可能总是拿到锁,那么那些活跃度低的线程可能就一直拿不到锁,这样就发生了“饥饿死”。
避免死锁的解决方案是:尽可能的按照锁的使用规范请求锁,另外锁的请求粒度要小(不要在不需要锁的地方占用锁,锁不用了尽快释放);在高级锁里面总是使用tryLock或者定时机制(这个以后会讲,就是指定获取锁超时的时间,如果时间到了还没有获取到锁那么就放弃)。高级锁(Lock)里面的这两种方式可以有效的避免死锁。
活锁
活锁描述的是线程总是尝试某项操作却总是失败的情况。这种情况下尽管线程没有被阻塞,但是人物却总是不能被执行。比如在一个死循环里面总是尝试做某件事,结果却总是失败,现在线程将永远不能跳出这个循环。另外一种情况是在一个队列中每次从队列头取出一个任务来执行,每次都失败,然后将任务放入队列头,接下来再一次从队列头取出任务执行,仍然失败。
还有一种活锁方式发生在“碰撞协让”情况下:两个人过独木桥,如果在半路相撞,双方礼貌退出去然后再试一次。如果总是失败,那么这两个任务将一直无法得到执行。
总之解决锁问题的关键就是:从简单的开始,先保证正确,然后再开始优化。

![[js] 微信的JSSDK都有哪些内容?如何接入?](http://pic.xiahunao.cn/[js] 微信的JSSDK都有哪些内容?如何接入?)


![[js] document.domain的作用是什么?它有什么限制?](http://pic.xiahunao.cn/[js] document.domain的作用是什么?它有什么限制?)

![[js] axios为什么可以使用对象和函数两种方式调用?是如何实现的?](http://pic.xiahunao.cn/[js] axios为什么可以使用对象和函数两种方式调用?是如何实现的?)


![[js] 在不支持js的浏览器中如何隐藏JavaScript代码?](http://pic.xiahunao.cn/[js] 在不支持js的浏览器中如何隐藏JavaScript代码?)








![[vue-element] ElementUI是怎么做表单验证的?在循环里对每个input验证怎么做呢?](http://pic.xiahunao.cn/[vue-element] ElementUI是怎么做表单验证的?在循环里对每个input验证怎么做呢?)
