🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
作为目前数据库引擎的两种主要数据结构,LSM-tree和B±tree在业界已经有非常广泛的研究。相比B±tree,LSM-tree牺牲一定的读性能以换取更小的写放大以及更低的存储成本,但这必须建立在已有的HDD和SSD的基础上。
探索前沿研究,聚焦技术创新,本期DB·洞见由腾讯云数据库高级工程师王宏博进行分享,主要介绍一篇2022年FAST的论文,主题为“基于硬件透明压缩的B+树优化”。本次分享的论文针对可计算存储SSD(支持硬件透明压缩)提出了三种有趣的设计方法,从而极大地减少了B±tree的写放大(10X)以使其接近甚至超越LSM-tree。以下为分享实录:
完整视频:https://v.qq.com/x/page/p3342om19py.html
一、论文简介
本期分享的是2022年FAST的一篇论文,主题是基于硬件透明压缩的B+树优化,该论文在内容上主要分为三个部分:
第一部分是背景介绍,作者分别介绍了现有的B+树及其软件压缩、存储硬件透明压缩、B+树和LSM-tree的简要对比以及B+树写放大的构成分析。
第二部分是算法部分,作者针对性地提出了三种设计来优化B+树的写放大:
确定性的page shadowing来解决页面原子写引入的写放大。
通过页面本地增量日志来减少刷脏页引入的写放大。
通过稀疏日志来减少redo日志引入的写放大。
第三部分是实验部分,作者通过前面所述的三个方法实现了一个新的B+树(我们称之为B−-tree为以示区别),并详细比较了多种条件下的测试结果。

二、背景部分
2.1 现有的B+树及其软件压缩
我们熟悉的开源数据库有很多都使用B+树作为存储引擎,比如MySQL、MongoDB、PostgreSQL等,腾讯云数据库TDSQL-PG也是基于B+树来实现的。B+树的结构如下方的左图所示,它通过一个个的数据页面构成一个树状结构以提供索引加速数据查找。常见的数据页面大小有8k和16k,通过数据页面压缩可以减少B+树的空间占用以降低成本,此外还可以减少B+树的写放大。
在前面所提到的基于B+树实现的数据库中,MySQL、MongoDB都实现了B+树的软件压缩特性,TDSQL-PG的商业化版本也有实现。软件压缩具有不依赖于特定硬件、灵活性高的优点,但美中不足的是,受限于现有的IO 4K对齐的约束会产生一些额外的空间浪费。比如下方右图,一个16K的数据库页面经过压缩后产生了5K的数据。受限于IO 4K对齐的要求,当落盘时这5K的数据实际上要占用8K的空间,产生了额外的3K的空间浪费。
常见的B+树压缩算法有Lz4、zlib、ZSTD,后面所提的LBA则是指logical block adressing,即逻辑上的磁盘块大小。

2.2 存储硬件透明压缩
我们先简单回顾下闪存的特性。如下图所示,闪存支持三种基本操作:读、写、擦除。闪存的读、写都以page为单位,一般是4K,擦除则是以block为单位,一个block一般包含多个page,比如包含64个page。之所以闪存需要支持擦除,是由于闪存的写比较特殊,一个page只能在擦除之后一次写入,而不能更新。但从用户的角度来看,SSD需要支持更新,因此我们在SSD里会有一个FTL层来实现该逻辑,即下图中间蓝色部分所示。
CSD,顾名思义是一种带有计算能力的存储。如下图所示,一个通用的CSD在存储层可以支持API调用来进行计算下推。硬件透明压缩存储作为CSD的一种,支持在其内部对数据进行压缩和解压,后续我们提到的CSD主要是指带有硬件透明压缩的CSD。
对比最下方的两张图,左边是普通的SSD,右边是CSD。可以看到普通SSD的LBA和闪存都是以页面为基础,且都是4K大小,可以由FTL直接进行映射。CSD和SSD类似,都对外提供了4K的LBA接口,但4K的数据经过压缩后长度不一定,所以在CSD内部,FTL的闪存管理需要支持对变长数据的管理,这也使得CSD的FTL变得更加复杂。如此一来CSD能带来什么好处呢?
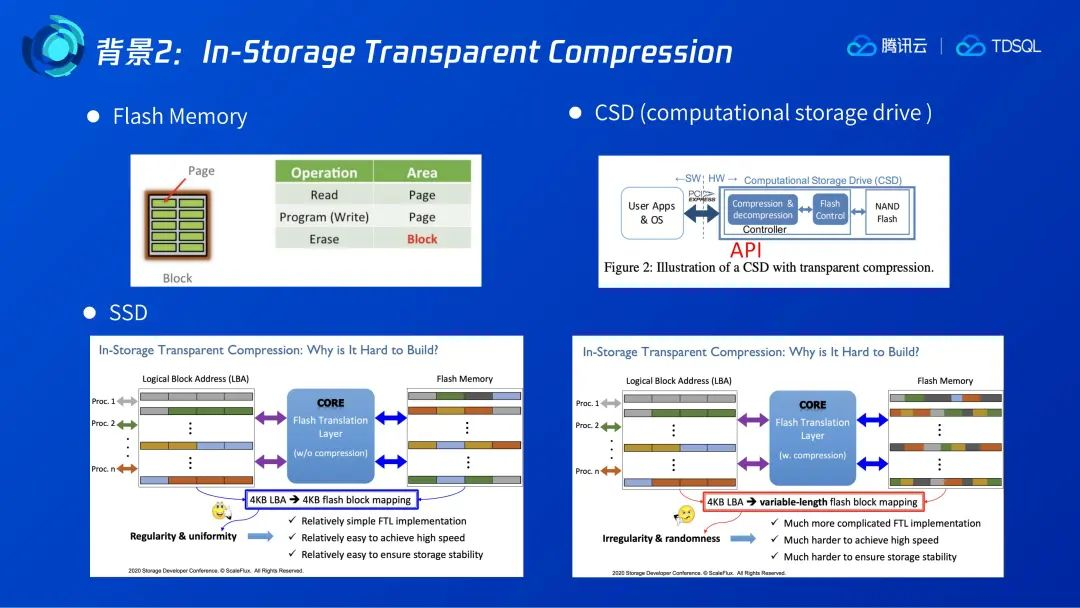
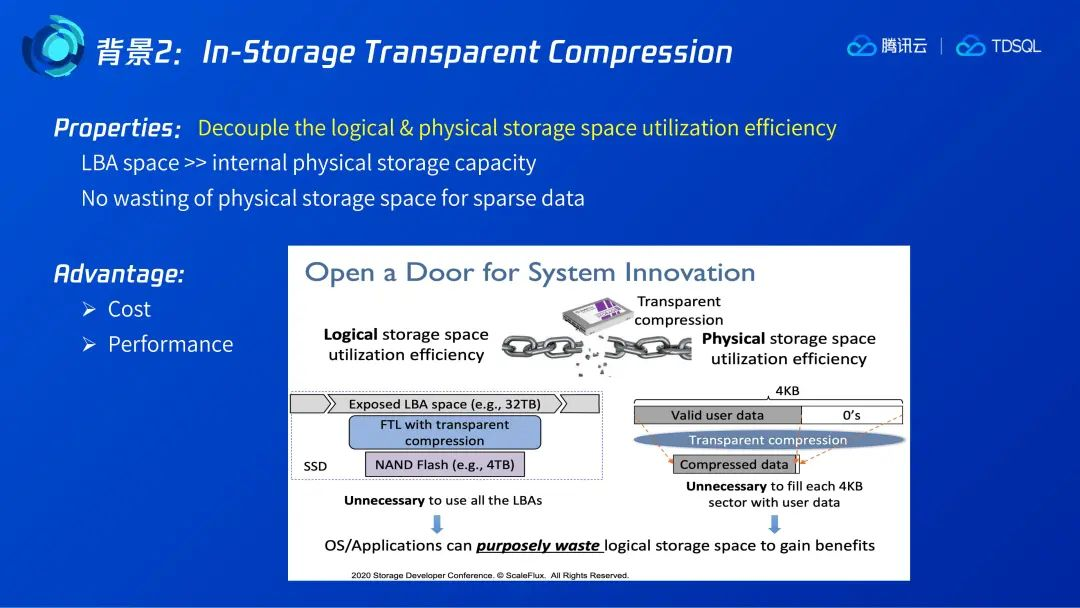
总体来看,CSD的好处体现在它有更优的成本、更好的性能,但在此不做详细讨论,我们主要关注CSD的技术特点。CSD可以实现逻辑地址和物理地址的解耦。如下方左图所示,对一个实际闪存大小只有4T的CSD来说,它可以对外提供远大于闪存大小的LBA。另外,如下方右图所示,对于稀疏数据的写入可以进行透明压缩而不产生空间浪费。基于CSD的这两个特性,我们在上层应用如数据库中,可以做一些针对性的设计,以进一步利用CSD的特性。
2.3 B+树和LSM-tree的简要对比
我们先回顾LSM-tree的写入流程。如右上图所示,一条数据记录的写入,会先写log,再进入memtbale,memtable写满之后会变成 immutable memtable, 再与L0的SSTable进行合并,上层的SSTbale也会在合适的时机与下层SSTable进行合并。
我们再简要回顾B+树的写入流程。一条记录的写入也是先写入log,再写入B+树的数据页面,当数据页面写满时就需要进行页面分裂,所以大部分时间B+树的页面其实是不满的。另外,由于B+树是直接操作目标页面,当内存不够时就会涉及到页面的淘汰问题,这时就需要刷脏页。极端场景是每写一条记录就需要刷一次脏页,如果一条记录是128字节,页面是8k,那么对应的写放大就是64倍。
B+树和LSM-tree在写方面的主要区别是:LSM-tree是一个紧密排布的结构,可以占用更小的写空间以及产生更小的写放大。B+树的写放大与数据集的大小成正相关,与单条记录的大小负相关。对于数据完全可以放入内存的场景,B+树可以产生比LSM-tree更小的写放大。因此这篇论文聚焦在大数据集以及小数据记录的场景,也就是说,B+树在该场景下写放大明显劣于LSM-tree。
作者通过在CSD上执行一个随机写入的测试,初步展示了B+树和LSM-tree的差异。结果如右下图所示,可以看到LSM-tree占用的逻辑空间更小,这与LSM-tree的数据紧密排列有关,经过CSD压缩之后,B+树的物理空间占用也大幅度减小。此外,通过对比发现,LSM-tree的写放大显著小于B+树,因此本论文的目标就是需要通过改进B+树的实现来大幅度减小B+树的写放大。

2.4 B+树写放大的构成分析
B+树的写放大构成主要包含三个部分:
为了保证事务原子性采用redo log引入的写放大 ;
由于lru buffer淘汰或者checkpoint 刷脏页而引入的写放大;
为了保证页面写的原子性而引入的写放大,如MySQL的 double write。
当考虑CSD的压缩特性时,公式1所列的写放大会引入表示压缩比的系数α ,其含义为 压缩后的数据大小比压缩前的数据大小,其位于0-1之间,也就是说,CSD会降低写放大。

三、算法部分
3.1 Deterministic Page Shadowing
算法1是通过确定性的page Shadowing来减少page原子写引入的写放大,其本质上是copy on write,一次页面刷盘写只需要写一次即可。具体实现如右图所示,1个数据页面在磁盘上会有2倍的连续LBA空间与之对应,这个LBA被划分为两个slot,两个slot轮流写入以实现copy on write,从而保证每次写入不管是否成功,页面的前镜像总是保持稳定。在页面写入成功后,可以通过trim 操作清理前一个slot的物理空间占用。在页面的写失败时,我们可以通过 checksum进行检测,并通过页面前镜像+redo恢复出最新的页面。对于写成功后crash保留两个完整页面的场景,则可以通过比较页面的LSN找到最新的页面,并trim掉旧的页面。
本方法带来的一个负面影响就是每次读需要产生额外的数据传输,但是作者认为pcie的传输能力远大于flash的速度,因此不成问题。此外,对于支持计算下推的CSD,我们可以将该逻辑下推,也可以避免掉额外的数据传输。

3.2 Localized Page Modification Logging
算法2是通过本地修改日志来减少刷脏页引起的写放大。如右图所示,一个数据页面在存储层对应一个数据页面+一个4K增量log页面,两者的逻辑地址连续。在内存中数据页面被分为k个segment,每个segment大小是Ds,每次页面修改所涉及到的segment会在bitmap f里面记录。当需要刷脏页时,我们可以通过bitmap f找到所有的修改增量,并把它记为δ,再把δ、bitmap f、补零后的数据一起写入盘中。以一个16K的数据页面为例,对应的写放大会减少75%。经过CSD透明压缩后,写放大可进一步减小。
在该方法中,由于额外引入了增量日志,会造成一定的物理空间的放大,我们可以通过参数T来控制物理空间的放大。当增量日志大于T时直接刷脏页并重置增量日志,T越大写放大越小,但是对应的物理空间放大就越大。读取页面时我们需要读原始数据页面+增量日志部分,再构造最新的数据页面。由于读页面需要额外读所以会造成一定的读放大,但由于数据页面的地址和增量日志LBA是连续的,因此一次读请求即可解决。另外,增量日志相对较小,所以可以认为这部分的读放大影响较小。

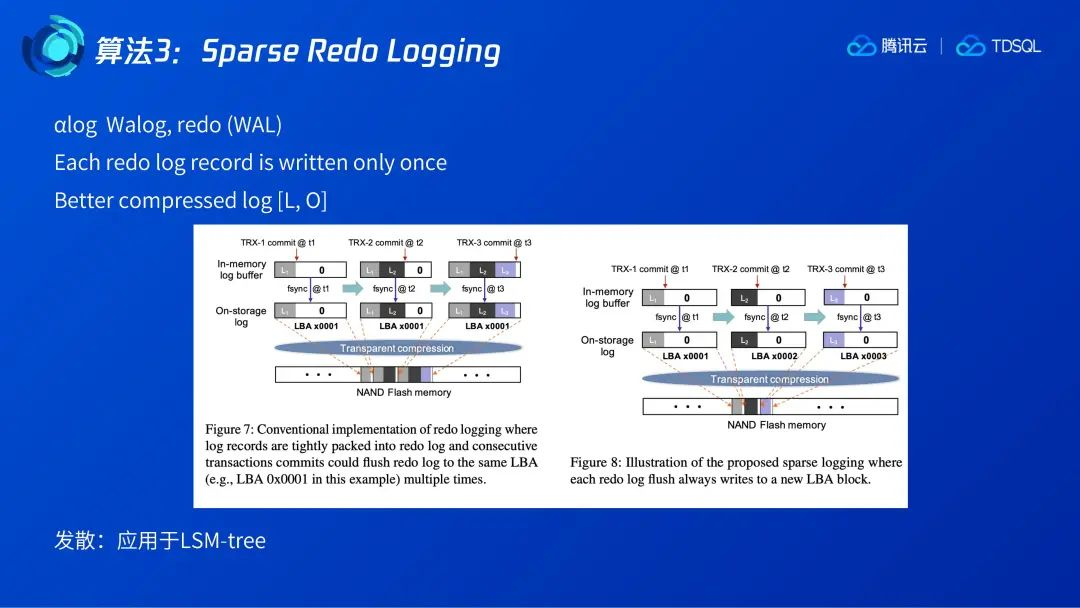
3.3 Sparse Redo Logging
算法3是稀疏日志,用于减少Redo log造成的写放大。目前常见的Redo log的实现如左图所示,日志采用连续紧密排列,事务1提交时日志L1落盘,事务2提交时由于日志buffer未满,因此会在L1的buffer中追加L2,L1和L2一起落盘,事务3提交时,L1、 L2 需要连同L3再落盘一次,直到当前日志buffer页面被写满,才会开启新的页面。在该例子中,从flash的角度看,L1被写了3次,后两次都是额外的写放大。当采用右图所示的稀疏日志时,每次日志写入都是用一个新的页面,页面经过透明压缩后落盘,则完全可以避免写放大的问题,另外由于透明压缩的存在也不会产生额外的空间占用。此外稀疏日志也是可以用于LSM-tree的。
四、实验部分
在实验部分,作者通过前述的三个优化方法实现了一个新的B+树(命名为B-树以示区别),同时还实现了一个Baseline的B+树,并且与Rocksdb、WiredTiger做了比较全面的实验对比。
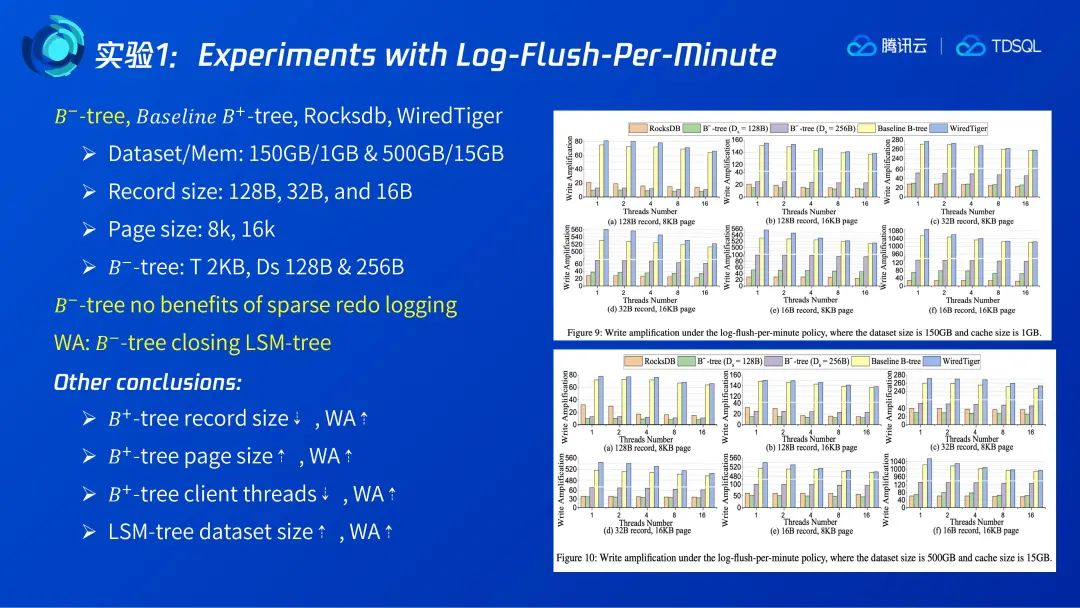
4.1 Experiments with Log-Flush-Per-Minute
在实验1中,Redolog的刷盘频率被设置为每分钟1次,以屏蔽掉Redo log写放大的影响。通过不同的数据集大小、单条记录的大小以及B+树页面大小设置,作者比较全面地评估了B-树的特性,得出初步的结论:B-树的写放大已经比较接近于LSM-tree,即右图中所有的橙色、绿色和紫色的部分比较接近。而Baseline B+tree和WiredTiger这两种标准的B+Tree,它们的写放大都比较大。
通过实验数据的对比,我们还可以发现:
B+树的写放大与Record size负相关,即Record size越小其写放大越大。以前面提到的极端例子为例,每条Record都会引起一次刷脏页,这时的写放大是Page size比Record size。如果Page size固定,当Record size越小,其写放大会越大。
B+树的写放大与并发数负相关,即并发数越大其写放大越小。我们可以理解为,当并发数比较高时,一个页面里可能会产生更多的更新,一次刷脏页就会有更多的Record进来。
LSM-Tree的写放大与数据集正相关。当数据集比较大时,做不同层之间的merge,它的写放大会变大。
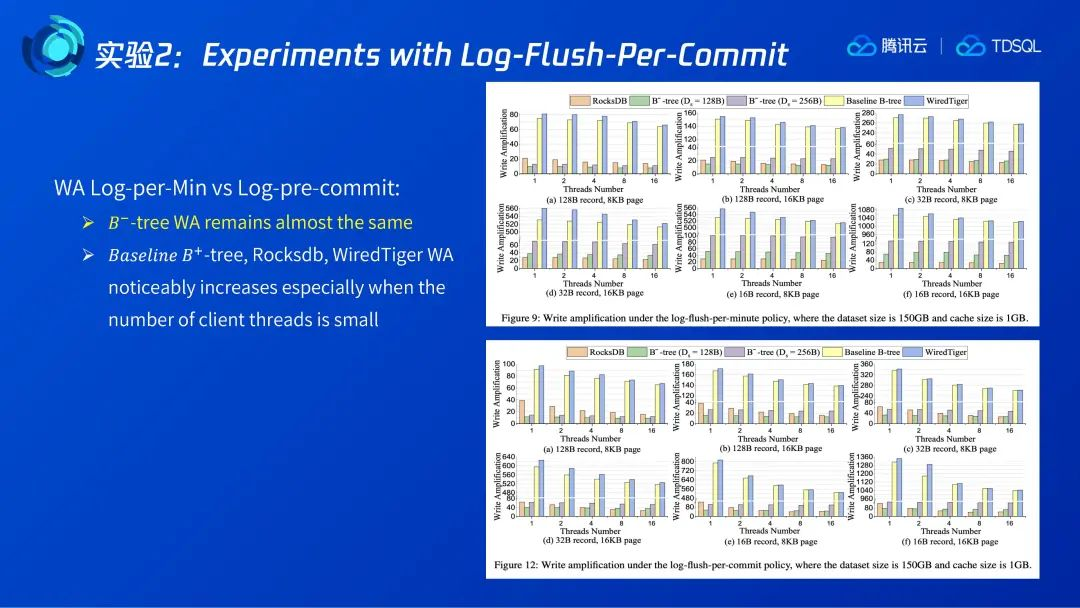
4.2 Experiments with Log-Flush-Per-Commit
在实验2中,Redo log的刷盘频率被设置为每次事务提交,这也是我们在实际生产中为保证不丢数据而常用的方法。作者用一个单独的图来展示log部分的写放大,我们可以看到LSM-tree和B+树的Redo log的写放大都跟Record size相关,Record size越小,写放大越大,同时与并发数负相关,随着并发数的上升写放大会减小。这是由于并发数的上升实际上会产生更多日志的合并,即每次写盘时会有更多的事务的提交日志一起写入,因此写放大减少了。对B-树而言,由于采用了稀疏日志,所以其在不同Record size大小和不同并发数下都保持很小的日志写放大。
图12展示了一个考虑日志写放大后的整体写放大。我们可以看到,B-树相对LSM-tree而言,它的写放大进一步降低,除了图中红框部分外,其他场景都比LSM-tree更优。

如果把两个不同的日志刷盘方式放在一起对比,我们可以发现,Redo log的写放大对B-树而言总体保持稳定,因为它使用了稀疏Redo log。当其他B+树和LSM-tree采用每事务提交时,两者的写放大显著提高,尤其是在并发数比较小的情况下,Redo log日志所引起的写放大占比较高。
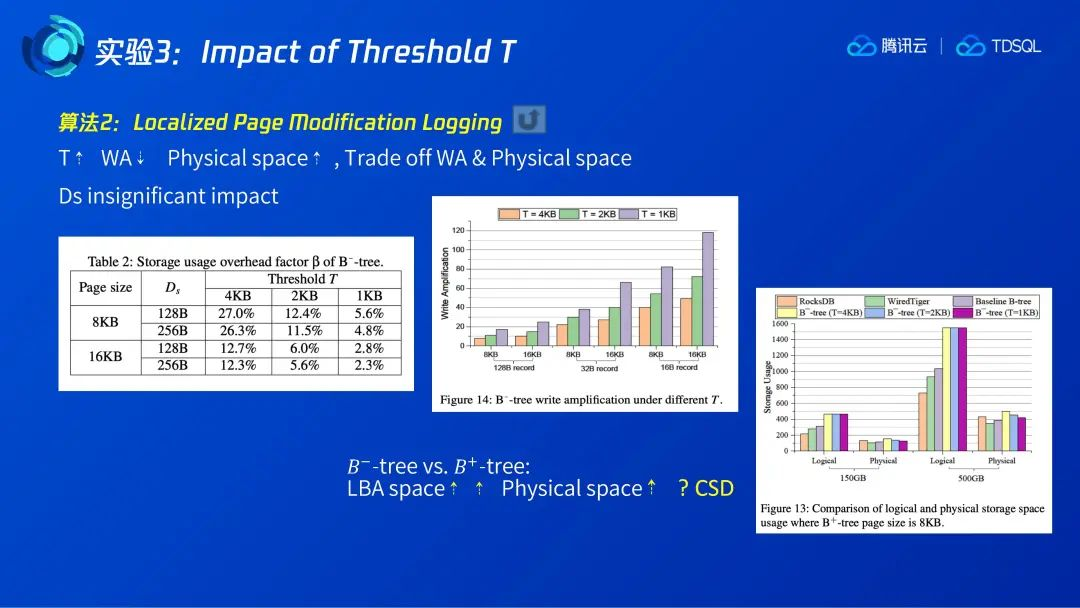
4.3 Impact of Threshold T
在实验3中,作者对算法2中提到的本地页面修改增量日志的算法做了验证。参数T表示当增量日志达到多少量时直接刷数据页面并重置增量日志,参数Ds表示页面分割的segment的大小。如图14和表格2,我们可以看到当T越大时,B-树的写放大会越小,但物理空间占用则会越大,这与我们之前的理论分析一致,所以这两个参数在实际中需要trade off。
图13展示了压缩对于物理空间占用的影响。由于B-树需要额外的4k页面占用,所以B-树的逻辑空间占用显著高于其他B+树,但在经过CSD压缩后,实际物理空间的占用放大则缩小了,相比B+树已经不明显了。
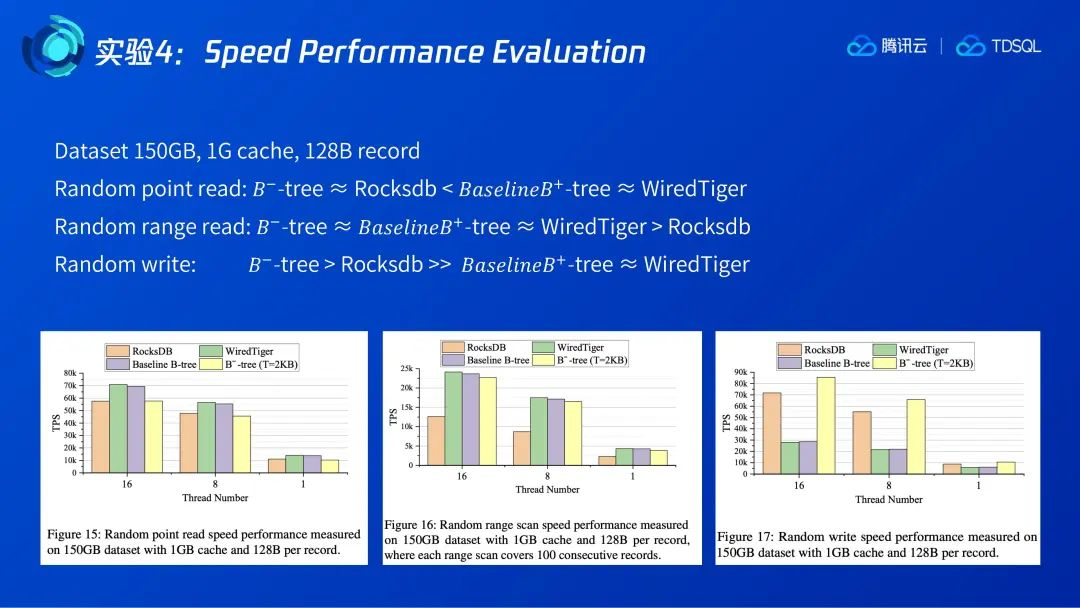
4.4 Speed Performance Evaluation
在实验4中,作者对比了三种场景下的B-树相对于其他几种树的性能。
在随机点查场景中, B- tree 和 LSM-tree 相当,但两者都小于B+树。这与B- tree采用本地页面的增量日志刷脏页有关,因为每次读取需要重新通过增量日志来构造最新的数据页面,这会引入额外的开销 。
对随机范围查询而言,B-树和B+tree的性能相当,优于LSM-tree。作者认为,由于一次查询多条记录,B-树引入的读开销占比变小了,所以其性能比较高。
在随机写场景中,B-树稍微优于LSM-tree,两者都显著优于B+树,这是由于前两者都拥有更小的写放大。但需要强调的是,由于B-树和B+树都涉及到buffer 淘汰问题,所以虽然是只写负载但实际的IO却是读写混合的,因为B-树需要读取额外的4k增量日志页面,因此读IO比B+tree有所放大,其相对B+树的性能提升也就没有像写放大减少得那么显著。
五、拓展与总结
最后分享一个CSD和PG结合起来的有趣实验。PG中有个名为 heap only tuple update的机制,用于优化非索引列更新。如下图所示,当更新一个元组时,如果当前元组所在的heap表页面有空闲空间,就可以直接在当前页面插入一条新的元组,再把老元组的ctid指向新元组即可,这样可以避免去找新的数据页面写入以及在索引页面中写入新的记录。PG中还有一个fillfactor的参数来控制heap表的填充率,我们可以利用较小填充率来换取非索引列更新的性能。当引入CSD之后,还可以进一步避免造成物理空间占用的放大,比较完美地解决了以往需要进行物理空间占用和性能trade off的问题。

综上所述,这篇论文提供了一个不同的视角去比较B+树和LSM-tree,让我们更深入地理解B+树和LSM-tree。作者通过三种实现比较简单但却非常巧妙的方法来改进B+树,在CSD上也取得了很好的效果,为我们带来了很好的启发。
参考文献
[1] Closing the B±tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression
[2] The True Value of Storage Drives with Built-in Transparent Compression: Far Beyond Lower Storage Cost
[3] Understanding Flash: Blocks, Pages and Program / Erases
[4] B+Tree index structures in InnoDB
[5] PostgreSQL与透明压缩
[6] The Internals of PostgreSQL
[7] WiscKey: Separating Keys from Values in SSD-Conscious Storage




)


)








——透视Pivot开发指南)


