🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
目录* 16.1 本篇概述
+ 16.1.1 本篇内容
+ 16.1.2 设备驱动概述
+ 16.1.3 图形驱动概述
- 16.2 图形驱动基础
- 16.2.1 硬件概览
- 16.2.2 总线类型
- 16.2.3 显存架构
- 16.2.4 虚拟和物理内存
- 16.2.5 PFIFO
- 16.2.6 图形卡剖析
- 16.2.7 图形卡编程
- 16.2.8 图形硬件案例
- 16.3 操作系统图形驱动
- 16.3.1 Windows图形驱动
- 16.3.1.1 WDDM概述
- 16.3.1.2 WDDM架构
- 16.3.1.3 WDDM接口
- 16.3.2 Linux图形驱动
- 16.3.2.1 X11基础架构
- 16.3.2.2 DRI/DRM基础架构
- 16.3.2.3 Framebuffer驱动
- 16.3.2.4 直接渲染管理器
- 16.3.2.5 Mesa
- 16.3.2.6 Wayland
- 16.3.3 调度机制
- 16.3.3.1 OS And GPU abstraction
- 16.3.3.2 Halide Pipeline
- 16.3.3.3 Hardware Accelerated GPU Scheduling
- 16.3.3.4 TimeGraph
- 16.3.3.5 GPU Scheduling
- 16.3.1 Windows图形驱动
- 16.4 GPU驱动
- 16.4.1 NVIDIA
- 16.4.1.1 Turing架构
- 16.4.1.2 Ampere架构
- 16.4.1.3 Nouveau
- 16.4.2 AMD
- 16.4.3 Intel
- 16.4.4 Qualcomm
- 16.4.5 其它
- 16.4.1 NVIDIA
- 16.5 图形驱动应用
- 16.5.1 视频与合成
- 16.5.2 Rocksolid
- 16.5.3 I/O驱动
- 16.5.4 UE图形驱动
- 16.6 本篇总结
- 特别说明
- 参考文献
16.1 本篇概述
16.1.1 本篇内容
迄今为止,博主在博客中阐述的内容包含图形API、GPU、游戏引擎、Shader、渲染技术、性能优化等等技术范畴内容,但似乎还未涉及图形驱动的内幕。本篇将站在应用层开发者的视角,去阐述图形驱动的相关技术内幕(如果是驱动开发者,则博主不认为是目标读者),主要包含但不限于以下内容:
- 图形驱动的架构。
- 图形驱动的技术内幕。
- 图形驱动的常见实现。
- 相关的硬件基础。
16.1.2 设备驱动概述
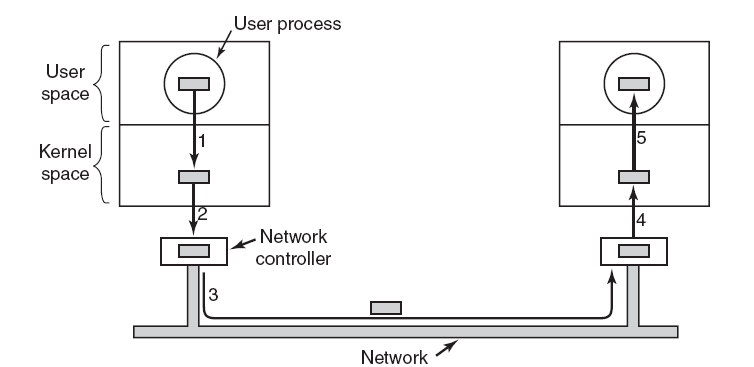
要给“驱动”一词下一个准确的定义是一个挑战。从最基本的意义上讲,驱动程序是一个软件组件,它允许操作系统和设备相互通信。例如,假设应用程序需要从设备读取一些数据,应用程序调用操作系统实现的函数,操作系统调用驱动程序实现的函数。该驱动程序由设计和制造该设备的同一家公司编写,他们知道如何与设备硬件通信以获取数据。驱动程序从设备获取数据后,将数据返回给操作系统,操作系统将数据返回给应用程序。
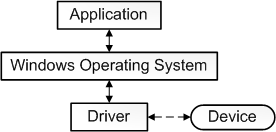
在计算机中,设备驱动程序是一种计算机程序,用于操作或控制连接到计算机或自动机的特定类型的设备。驱动程序为硬件设备提供软件接口,使操作系统和其他计算机程序能够访问硬件功能,而无需知道所使用硬件的确切细节。
驱动程序通过硬件连接的计算机总线或通信子系统与设备通信。当调用程序调用驱动程序中的例程时,驱动程序向设备发出命令(驱动设备)。一旦设备将数据发送回驱动程序,驱动程序就可以调用原始调用程序中的例程。驱动程序依赖于硬件且特定于操作系统,通常提供任何必要的异步时间相关硬件接口所需的中断处理。
设备驱动程序,特别是在现代Microsoft Windows平台上,可以在内核模式(x86 CPU上的ring 0)或用户模式(x86 CPU上的ring 3)下运行。在用户模式下运行驱动程序的主要好处是提高了稳定性,因为写得不好的用户模式设备驱动程序不会通过覆盖内核内存而导致系统崩溃。另一方面,用户/内核模式转换通常会带来相当大的性能开销,从而使内核模式驱动程序成为低延迟网络的首选。
用户模块只能通过使用系统调用来访问内核空间,最终用户程序(如UNIX shell或其他基于GUI的应用程序)是用户空间的一部分,这些应用程序通过内核支持的函数与硬件交互。
常见的设备驱动包含但不限于:
- 打印机。
- 视频适配器。
- 网卡。
- 声卡。
- 各种类型的本地总线,特别是用于在现代系统上控制总线。
- 各种低带宽输入/输出总线(用于鼠标、键盘等定点设备)。
- 计算机存储设备,如硬盘、CD-ROM和软盘总线(ATA、SATA、SCSI、SAS)。
- 实现对不同文件系统的支持。
- 图像扫描仪。
- 数码相机。
- 数字地面电视调谐器。
- 用于无线个人局域网的射频通信收发器适配器,用于家庭自动化中的短距离低速无线通信(例如蓝牙低能量(BLE)、线程、ZigBee和Z-Wave)。
- IrDA适配器。
以上的解释在以下几个方面过于简单:
- 并非所有驱动程序都必须由设计该设备的公司编写。在许多情况下,设备是根据已发布的硬件标准设计的,意味着驱动程序可以由Microsoft编写,并且设备设计器不必提供驱动程序。
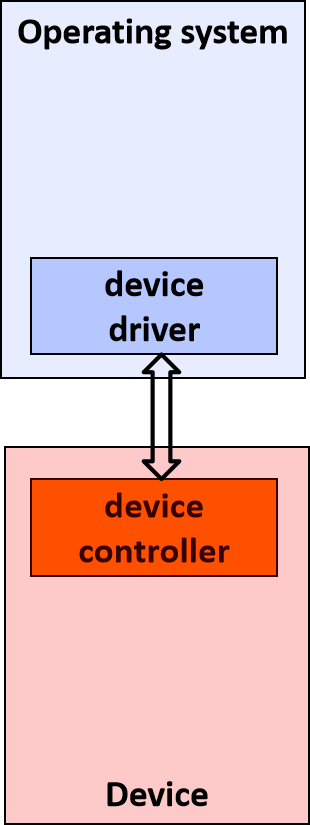
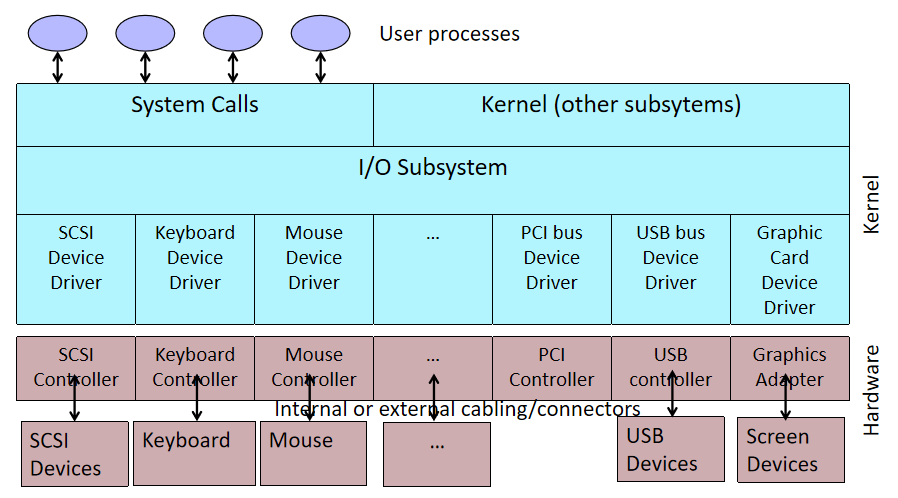
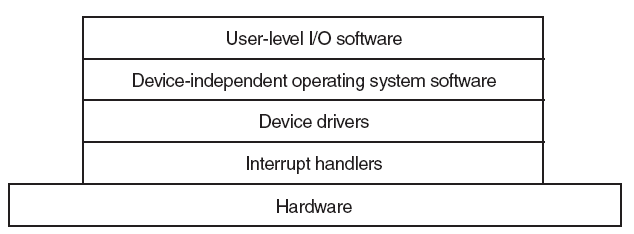
- 并非所有驱动程序都与设备直接通信。对于给定的I/O请求(如从设备读取数据),通常有多个驱动程序参与请求,这些驱动程序分层在驱动程序堆栈中。可视化堆栈的传统方法是,第一个参与者在顶部,最后一个参与者在底部,如下图所示。堆栈中的一些驱动程序可能通过将请求从一种格式转换为另一种格式来参与。这些驱动程序不直接与设备通信,他们只是操纵请求并将请求传递给堆栈中较低的驱动程序。
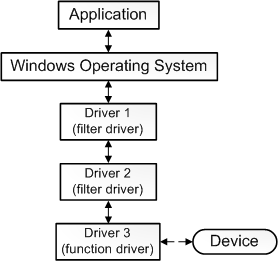
其中功能驱动程序是堆栈中直接与设备通信的一个驱动程序,过滤驱动程序是执行辅助处理的驱动程序。
- 一些过滤驱动程序观察并记录有关输入/输出请求的信息,但不主动参与这些请求。例如,某些过滤驱动程序充当验证器,以确保堆栈中的其他驱动程序正确处理I/O请求。
可以通过说驱动程序是观察或参与操作系统和设备之间通信的任何软件组件来扩展驱动程序的定义。
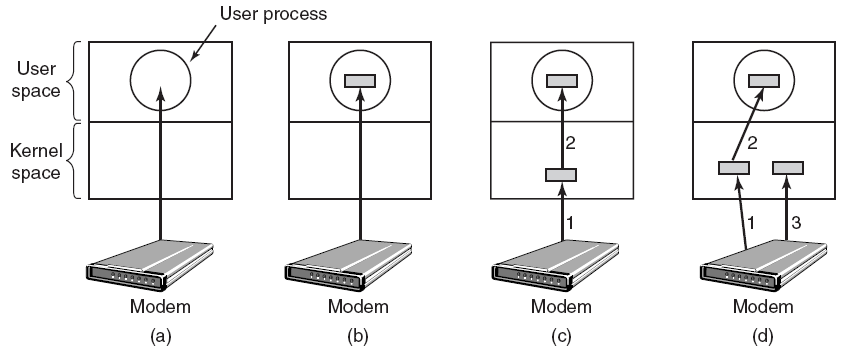
至此,扩展定义相当准确,但仍然不完整,因为一些驱动程序根本与任何硬件设备都没有关联。例如,假设需要编写一个能够访问核心操作系统数据结构的工具,而只有在内核模式下运行的代码才能访问核心操作系统数据结构。可以通过将该工具拆分为两个组件来实现这一点,第一个组件以用户模式运行并显示用户界面,第二个组件以内核模式运行,可以访问核心操作系统数据。在用户模式下运行的组件称为应用程序,在内核模式下运行的组件称为软件驱动程序,软件驱动程序与硬件设备不关联。下图说明了与内核模式软件驱动程序通信的用户模式应用程序。
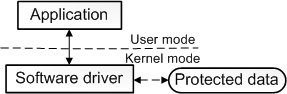
软件驱动程序总是在内核模式下运行,编写软件驱动程序的主要原因是为了访问仅在内核模式下可用的受保护数据。然而,设备驱动程序并不总是需要访问内核模式的数据和资源。因此,一些设备驱动程序以用户模式运行。
此外,还有总线驱动等更多功能性驱动(下图)。
16.1.3 图形驱动概述
显示驱动程序是允许操作系统与图形硬件一起工作的软件。图形硬件控制显示器,可以是计算机中的扩充卡,也可以内置在计算机的主电路板中(如笔记本电脑),也可以驻留在计算机外部(如Matrox remote graphics units)。每种型号的图形硬件都是不同的,需要一个显示驱动程序来与系统的其余部分连接。具有不同特性的较新图形硬件型号不断发布,每种新型号的控制方式往往不同。
驱动程序将操作系统函数调用(命令)转换为特定于该设备的调用。对于同一型号的图形硬件,使用不同函数调用的每个操作系统也需要不同的显示驱动程序。例如,Windows XP和Linux需要非常不同的显示驱动程序。但是,同一操作系统的不同版本有时可以使用相同的显示驱动程序。例如,Windows 2000和Windows XP的显示驱动程序通常是相同的。
如果未安装特定于计算机图形硬件的显示驱动程序,图形硬件将无法使用或功能有限。如果特定于型号的显示驱动程序不可用,操作系统通常可以使用具有基本功能的通用显示驱动程序。例如,Windows在“安全模式”下使用通用VGA或SVGA显示驱动程序。在这种情况下,大多数特定于模型的功能都不可用。
由于图形硬件非常复杂,并且显示驱动程序非常特定于该硬件,因此显示驱动程序通常由硬件制造商创建和维护,甚至操作系统中包含的显示驱动程序也通常最初由制造商提供。制造商可以完全访问有关硬件的信息,并在确保以最佳方式使用其硬件方面拥有既得利益。
显示驱动程序对系统资源具有低级(内核级)访问权限,因为显示驱动程序需要直接与图形硬件通信,这种低级别访问使得显示驱动程序的编码更加仔细和可靠。显示驱动程序中的错误比应用程序软件中的错误更有可能使整个操作系统暂时无法使用。
幸运的是,某些公司或组织(如Matrox)凭借其对专业用户的传统承诺以及其产品的长期产品生命周期,在制造可靠的显示器驱动程序方面享有盛誉。长生命周期意味着其显示器驱动程序的开发将持续更长的时间,使得悬而未决的问题更有可能得到解决,并且显示驱动程序能够适应不断变化的软件环境。新的操作系统和新的应用软件正在不断发布,每一种都可能需要新的驱动程序版本来保持兼容性或提供新的功能,可用的最新显示驱动程序经常解决此类问题。长的产品生命周期也使得显示驱动程序更有可能添加新的特性和功能,而不考虑操作系统和应用程序软件。
对于Linux等开源操作系统,非制造商有时会维护显示驱动程序,操作系统的开源特性使得为此类操作系统编写代码变得更容易(但并不容易)。虽然Matrox为特殊目的维护自己的Linux显示驱动程序,但Matrox Millennium G系列产品提供了基本的开源Linux显示驱动程序,Matrox合作伙伴Xi Graphics(一家在Linux/Unix开发方面有10多年经验的公司)为Matrox产品提供了全功能的Linux显示驱动程序。
即使对于相同的操作系统和图形硬件型号,有时也会同时提供不同的显示驱动程序,以满足不同的需求。以下是Matrox图形硬件某些型号可用的不同显示驱动程序的摘要:
- “HF”驱动程序:此类驱动程序具有丰富的界面,需要Microsoft .NET Framework软件,适用于喜欢此界面或者已有此界面的用户,微软NET软件包含在许多最近安装的Windows和许多其他需要它的应用程序中。“HF”软件仅适用于某些型号的Parhelia系列产品和Millennium P系列产品。
- Microsoft .NET Framework:是由Microsoft创建的一种编程基础架构,用于构建、部署和运行用户使用的应用程序和服务.NET技术,如我们的HF驱动程序。
- 统一驱动程序:此类驱动程序一次支持多个不同型号的Matrox产品。对于需要一次为许多不同的Matrox产品安装显示驱动程序并希望从一个软件包进行安装的系统管理员非常有用,对于不确定自己的图形硬件型号的用户也很有用。由于统一驱动程序的接口必须支持不同的硬件,Matrox统一驱动程序使用支持更广泛的“SE”接口。
- XDDM:Windows XP显示驱动程序模型,有时被称为XPDM或XPDDM。
- WDDM:Windows显示驱动程序模型(WDDM)是Windows Vista、Server 2008和Windows 7支持的显示驱动程序体系结构。
- “WDM”(Windows驱动程序型号)驱动程序包:此类驱动程序适用于需要视频捕获和实时播放功能的用户,有一个需要Microsoft的丰富界面.NET Framework软件和支持视频的额外功能,微软NET软件包含在许多最近安装的Windows和许多其他需要它的应用程序中。仅适用于某些型号的Parhelia系列产品。
- WHQL驱动程序:“Windows硬件质量实验室”驱动程序接受Microsoft开发的一系列标准测试,以提高驱动程序的可靠性。Matrox等硬件供应商执行这些测试,并将结果提交给Microsoft进行认证。如果用户安装的驱动程序未通过WHQL认证(即使驱动程序通过其他方式认证),则Windows操作系统的最新版本会向用户发出警告。为了避免此类警告和WHQL流程提供的额外测试,系统管理员通常更喜欢使用WHQL驱动程序。
- 认证驱动程序:Matrox通过领先的专业2D/3D软件认证显示驱动程序,包括用于AEC、MCAD、GIS和P&P(工厂和工艺设计)的软件,这种软件通常要求很高,并广泛使用图形硬件加速。Matrox单独认证此类应用程序,以确保额外的可靠性。该测试是对所有Matrox显示器驱动程序进行的常规测试的补充。
- ISV认证驱动程序:某些“独立软件供应商”对其应用软件有自己的认证流程,与Matrox认证的驱动程序相似,因为特定图形硬件的显示驱动程序会在特定应用程序中进行额外测试。但是,在这种情况下,Matrox将硬件和显示驱动程序提交给ISV,ISV执行测试。与Matrox认证相比,ISV认证的频率较低,涵盖的应用较少。
- 测试版驱动程序:有时,特殊支持或修复程序首先作为“测试版”驱动程序发布。这类驱动已经接受了一些测试,但不一定完成了整个测试周期,测试版驱动程序可供想要测试或预览重要新功能的用户使用。
- …
设备驱动程序是操作系统内核代码的最大贡献者,Linux内核中有超过500万行代码,并且会导致严重的复杂性、bug和开发成本。近年来,出现了一系列旨在提高可靠性和简化驱动开发的研究。然而,除了用于研究的一小部分驱动程序之外,人们对这一庞大的代码体的构成知之甚少。
有学者研究Linux驱动程序的源代码,以了解驱动程序的实际用途、当前的研究如何应用于这些驱动程序以及未来的研究机会,大体上,研究着眼于驱动程序代码的三个方面:
- 驱动程序代码功能的特征是什么,驱动程序研究如何适用于所有驱动程序。
- 驱动程序如何与内核、设备和总线交互。
- 是否存在可抽象为库以减少驱动程序大小和复杂性的相似性?
从驱动程序交互研究中,发现USB总线提供了一个高效的总线接口,具有重要的标准化代码和粗粒度访问,非常适合隔离执行驱动程序。此外,不同总线和级别的驱动程序的设备交互水平差异很大,这表明隔离成本将因级别而异。
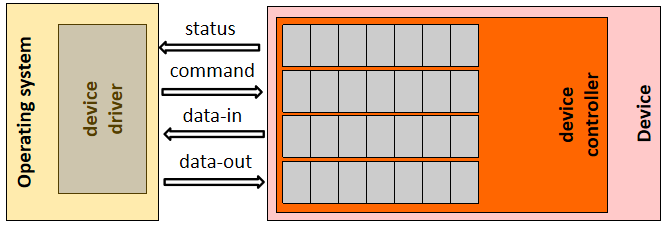
设备驱动程序是在操作系统和硬件设备之间提供接口的软件组件,驱动程序配置和管理设备,并将来自内核的请求转换为对硬件的请求。驱动程序依赖于三个接口:
- 驱动程序和内核之间的接口,用于通信请求和访问操作系统服务。
- 驱动器和设备之间的接口,用于执行操作。
- 驱动器和总线之间的接口,用于管理与设备的通信。
下图显示了Linux中驱动程序根据其接口的层次结构,从基本驱动程序类型开始,即char、block和net,可确定72个独特的驱动程序类别。大多数(52%)驱动程序代码是字符驱动程序,分布在41个类中。网络驱动程序占驱动程序代码的25%,但只有6个类。例如,视频和GPU驱动程序对驱动程序代码的贡献很大(近9%),这是因为复杂的设备具有每代都会改变的指令集,但这些设备由于其复杂性,在很大程度上被驱动程序研究所忽视。
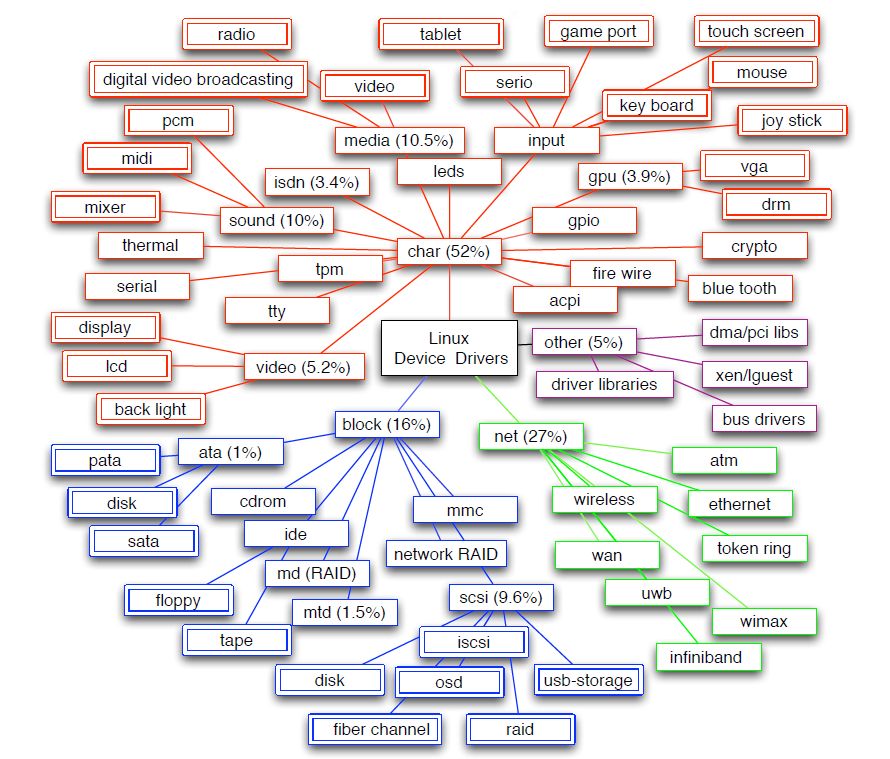
Linux驱动程序在基本驱动程序类方面的分类。其中提到了5个最大类的大小(以代码行的百分比表示)。
通常认为设备驱动程序主要执行输入/输出。标准本科操作系统教科书规定:设备驱动程序可以看作是转换器,其输入由高级命令组成,如“检索块123”其输出由硬件控制器使用的低级别、特定于硬件的指令组成,硬件控制器将输入/输出设备连接到系统的其余部分。
随着设备功能越来越强大,并拥有自己的处理器,人们通常认为驱动程序执行的处理很少,只是在操作系统和设备之间传输数据。然而,如果驱动程序需要大量的CPU处理,例如计算RAID奇偶校验、网络校验和或视频驱动程序显示数据,则必须保留处理能力。15%的驱动程序至少有一个执行处理的函数,而处理发生在所有驱动程序函数中的1%。
下表比较了PCI、USB和XenBus所有设备类别的复杂性指标。通过比较一个驱动程序支持的芯片组数量来考察支持多个设备的效率,表明了支持新设备的复杂性,以及驱动程序的抽象级别。支持来自不同供应商的许多芯片组的驱动程序表示具有高水平通用功能的标准化接口。相比之下,支持单个芯片组的驱动程序效率较低,因为每个设备都需要一个单独的驱动程序。

三种总线(bus)的驱动效率差别很大。PCI驱动程序支持每个驱动程序7.5个芯片组,几乎总是来自同一供应商。相比之下,USB驱动程序的平均值为13.2,通常来自许多供应商。其中很大一部分差异在于USB协议的标准化,而许多PCI设备都不存在这种标准化。例如,USB存储设备实现标准接口。因此,主USB存储驱动程序代码在很大程度上很常见,但包括对设备特定代码的调用。此代码包括特定于设备的初始化、挂起/恢复(未提供通过USB存储并作为附加功能要求保留)和其他需要设备特定代码的例程。虽然USB驱动程序有了更大的标准化工作,但仍不完整。
所有现代操作系统中驱动程序的另一个关键要求是需要多路访问设备。例如,一个磁盘控制器驱动程序必须允许多个应用程序同时读写数据,即使这些应用程序没有其他关联。这一要求会使驱动程序设计复杂化,因为它增加了对多个独立线程之间同步的需要。研究驱动程序如何跨长延迟操作多路访问:它们倾向于线程化代码、在堆栈上保存状态并阻止事件,还是倾向于事件驱动代码、将回调注册为USB驱动程序的完成例程或PCI设备的中断处理程序和计时器。如果驱动程序被移动到内核之外,驱动程序和内核将使用通信通道相互通信,支持事件驱动并发可能更自然。
下图中标记为事件友好型和线程化的条形图中显示的结果表明,线程化和事件友好型代码的划分在驱动程序类中差异很大。总的来说,驱动程序出于不同的目的广泛使用这两种同步方法。驱动程序使用线程原语来同步驱动程序和设备操作,同时初始化驱动程序并更新驱动程序全局数据结构,而事件友好型代码用于核心I/O请求。
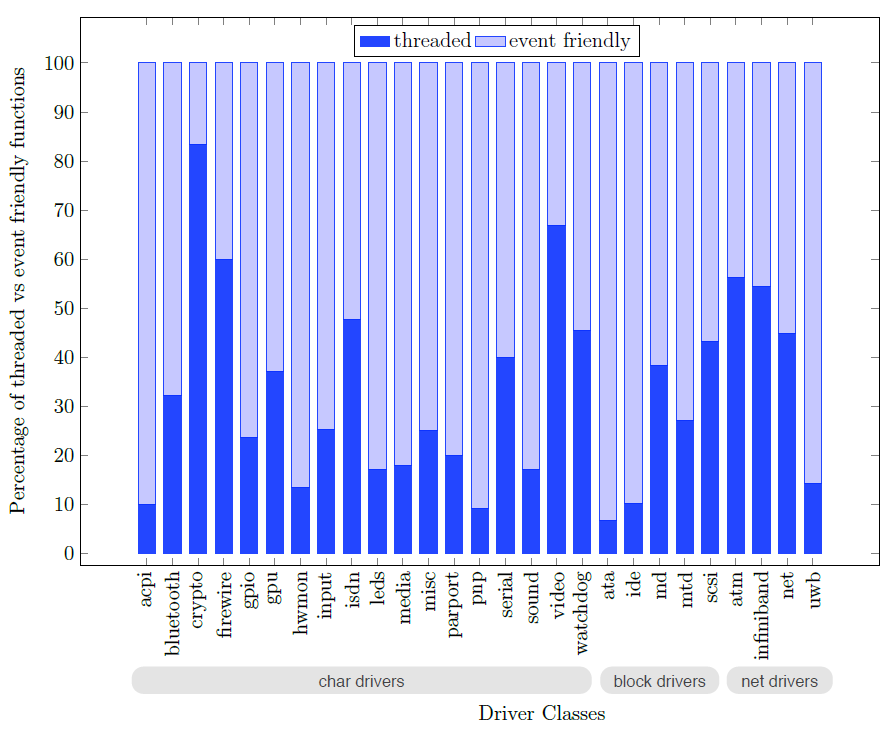
线程化和事件友好型同步原语覆盖范围内的驱动程序入口点的百分比。
随着GPU性能的提高,对图形驱动程序的要求也越来越高。良好的用户体验取决于稳定、可靠的软件栈。
16.2 图形驱动基础
16.2.1 硬件概览
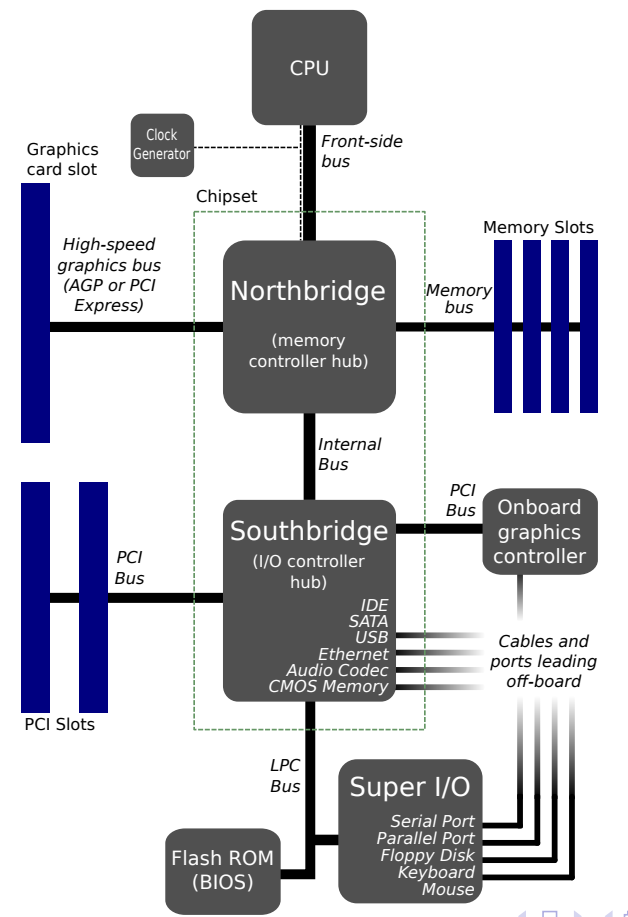
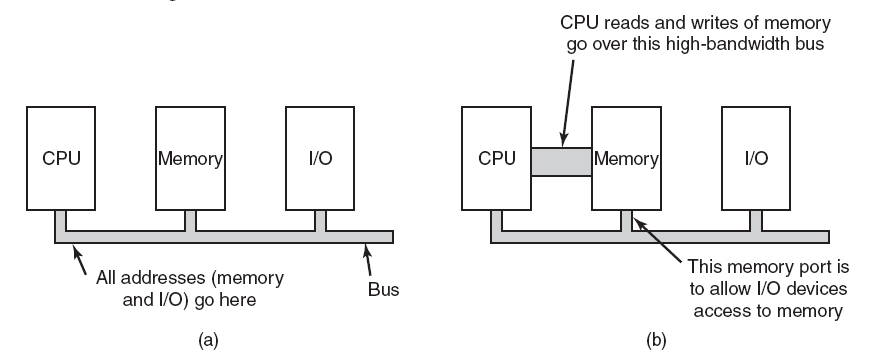
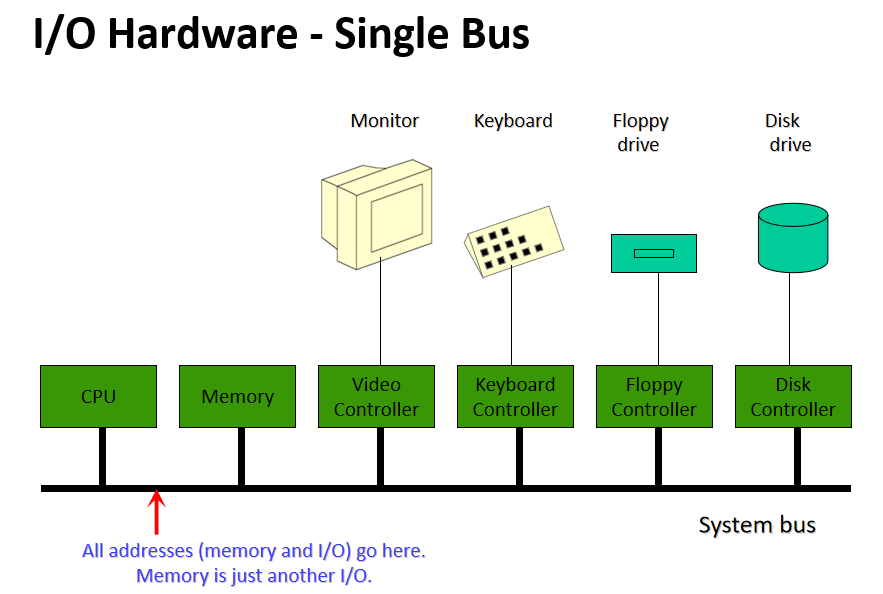
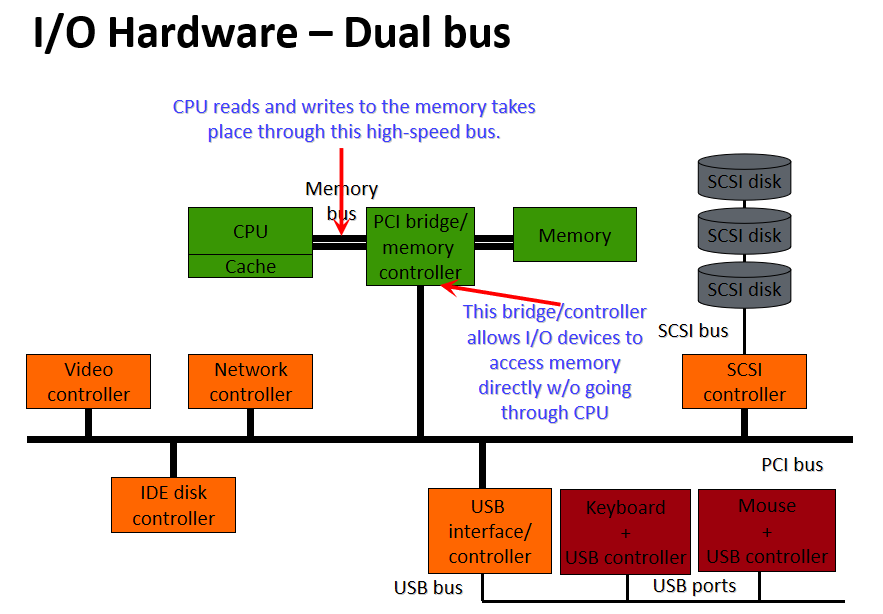
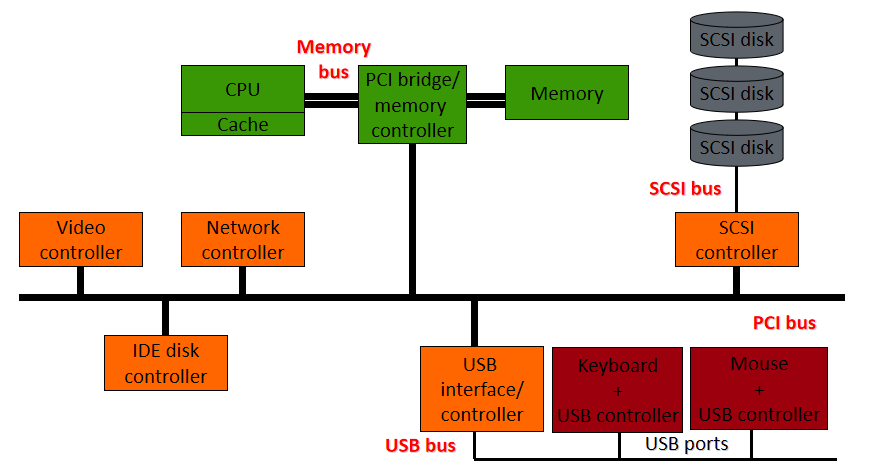
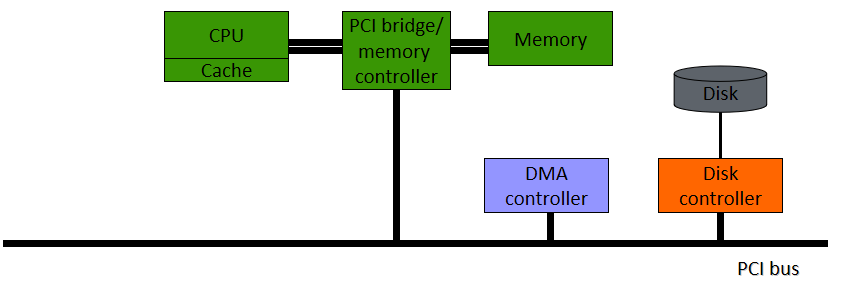
稍早期(如2012年)的计算机硬件架构大多可抽象成如下摸样:
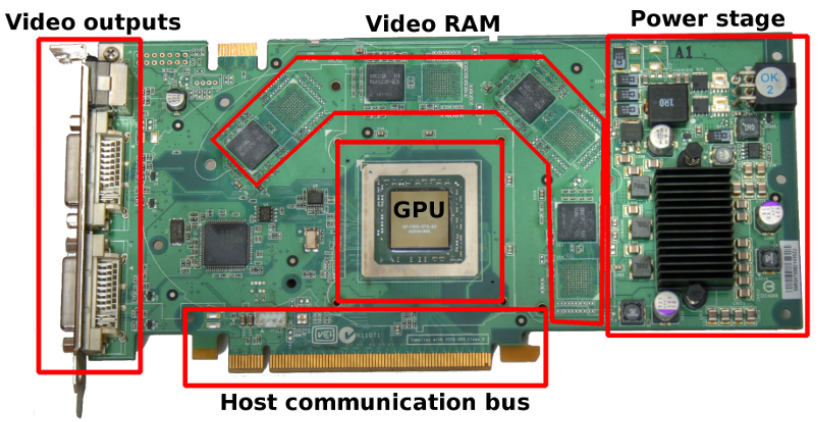
其中一款显卡的结构见下图,包含了GPU(执行所有计算)、视频输出(连接到屏幕)、显存(存储纹理或通用数据)、电源管理(降低电压,调节电流)、主机交互总线(与CPU的通信)等部件:
如今,所有计算机的结构都是类似的:一个中央处理器和许多外围设备。为了交换数据,这些外围设备通过总线互连,所有通信都通过总线进行。下图概述了标准计算机中外围设备的布局。
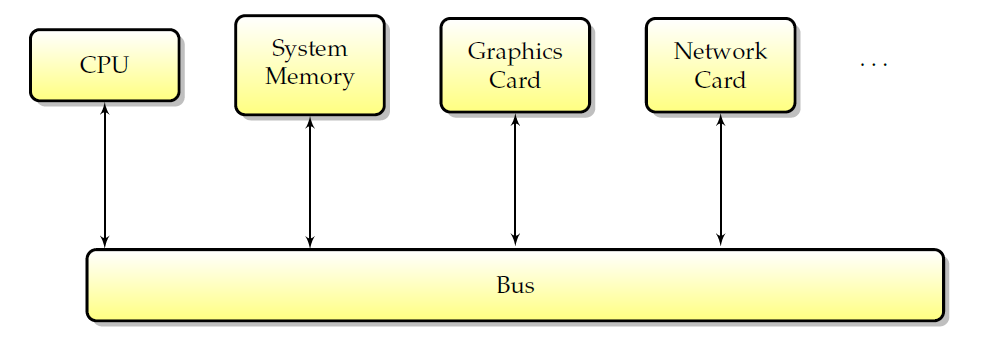
典型计算机中的外围互连。
总线的第一个用户是CPU。CPU使用总线访问系统内存和其他外围设备。然而,CPU并不是唯一能够向外围设备写入和读取数据的设备,外围设备本身也具有直接交换信息的能力。具体地说,能够在没有CPU干预的情况下读取和写入存储器的外围设备被称为具有**DMA(直接存储器访问)**能力,并且存储器事务通常被称为DMA。这种类型的事务很有趣,因为它允许驱动程序使用GPU而不是CPU来进行内存传输。由于CPU不再需要主动工作来实现这些传输,并且由于它允许CPU和GPU之间更好的异步性,因此可以获得更好的性能。**DMA的常见用途包括提高纹理上传或流视频的性能。**如今,所有图形处理器都具有这种能力(称为DMA总线主控),这种能力包括视频卡请求并随后控制总线几微秒。
如果外设能够在不连续的内存页列表中实现DMA(当数据在内存中不连续时非常方便),则称其具有DMA分散-收集(scatter-gather)功能(因为它可以将数据分散到不同的内存页,或从不同的内存页收集数据)。
**请注意,DMA功能在某些情况下可能是一个缺点。**例如,在实时系统上,意味着当DMA事务正在进行时,CPU无法访问总线,并且由于DMA事务是异步发生的,可能导致错过实时调度截止时间。另一个例子是小型DMA内存传输,其中设置DMA的CPU开销大于异步增益,导致传输速度变慢。因此,虽然DMA从性能角度来看有很多优势,但在某些情况下应该避免。
另外,GPU需要主机:
- 设置屏幕模式/分辨率(模式设置)。
- 配置引擎和通信总线。
- 处理电源管理。热量管理(风扇,对过热/功率作出反应),更改GPU的频率/电压以节省电源。
- 处理数据。分配处理上下文(GPU VM+上下文ID),上传纹理或场景数据,发送要在上下文中执行的命令。
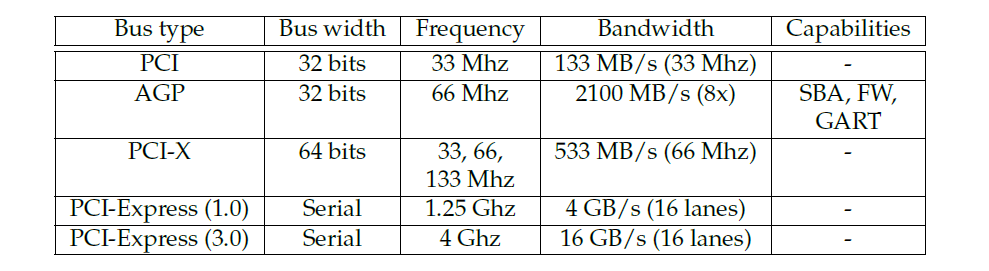
16.2.2 总线类型
总线将机器外围设备连接在一起,不同外设之间的每一次通信都通过(至少)一条总线进行。特别是,总线是大多数图形卡连接到计算机其余部分的方式(一个显著的例外是某些嵌入式系统,其中GPU直接连接到CPU)。如下表所示,有许多适用于图形的总线类型:PCI、AGP、PCI-X、PCI express等等。本小节将详细介绍的所有总线类型都是PCI总线类型的变体,但其中一些总线在原始PCI设计上有独特的改进。
-
PCI (Peripheral Component Interconnect,外设部件互连标准):PCI是目前允许连接图形外围设备的最基本的总线。它的一个关键特性叫做总线控制,此功能允许给定的外围设备在给定的周期数内占用总线并执行完整的事务(称为DMA,直接内存访问)。PCI总线是一致的,意味着无需显式刷新即可使内存在设备间保持一致。
-
AGP (Accelerated Graphics Port,图形加速端口):AGP本质上是一种经过改进的PCI总线,与它的祖先相比,具有许多额外的功能。最重要的是,它的速度更快,主要得益于更高的时钟速度以及在每个时钟tick中每个通道发送2、4或8位的能力(分别适用于AGP 2x、4x和8x)。AGP还有三个显著特点:
- 第1个特性是AGP GART(图形光圈重映射表),是IOMMU的一种简单形式。它允许从系统内存中取出一组(非连续的)物理内存页,并将其暴露给GPU作为连续区域使用,以很低的成本增加了GPU可用的内存量,并为CPU和GPU之间共享数据创建了一个方便的区域(AGP图形卡可以在该区域进行快速DMA,并且由于GART区域是一块系统RAM,因此CPU访问比VRAM快得多)。一个显著的缺点是,GART区域不一致,因此在另一方开始传输之前,需要刷新对GART的写入(无论是从GPU还是CPU)。另一个缺点是,硬件只处理一个GART区域,它必须由驱动程序分配。
- 第2个特性是AGP边带寻址(SBA)。边带寻址由用作地址总线的8个额外总线位组成,与多路复用地址和数据之间的总线带宽不同,标准AGP带宽只能用于数据。此功能对驱动程序开发人员是透明的。
- 第3个特性是AGP快速写入(FW)。快速写入允许直接向图形卡发送数据,而无需图形卡启动DMA。此功能对驱动程序开发人员也是透明的。注意,后两个功能在各种硬件上都不稳定,通常需要特定于芯片组的hack才能正常工作,因此建议不启用它们。事实上,它们是AGP卡上出现奇怪硬件错误的极为常见的原因。
-
PCI-X:PCI-X是为服务器板开发的一种更快的PCI,这种格式的图形外围设备很少(一些Matrox G550卡)。不要将其与PCI-Express混淆,后者的使用非常广泛。
-
PCI-Express (PCI-E):PCI Express是新一代PCI设备,比简单的改进PCI有更多的优点。最后,需要注意的是,根据体系结构,CPU-GPU通信并不总是依赖于总线,在GPU和CPU位于单个芯片上的嵌入式系统上尤其常见。在这种情况下,CPU可以直接访问GPU寄存器。
16.2.3 显存架构
虽然DRAM通常被视为一个扁平的字节数组,但其内部结构要复杂得多。对于像GPU这样的高性能应用程序,非常有必要深入地理解它。从下往上大致看,VRAM由以下部分组成:
- R行乘以C列的内存平面(memory plane),每个单元为一位。
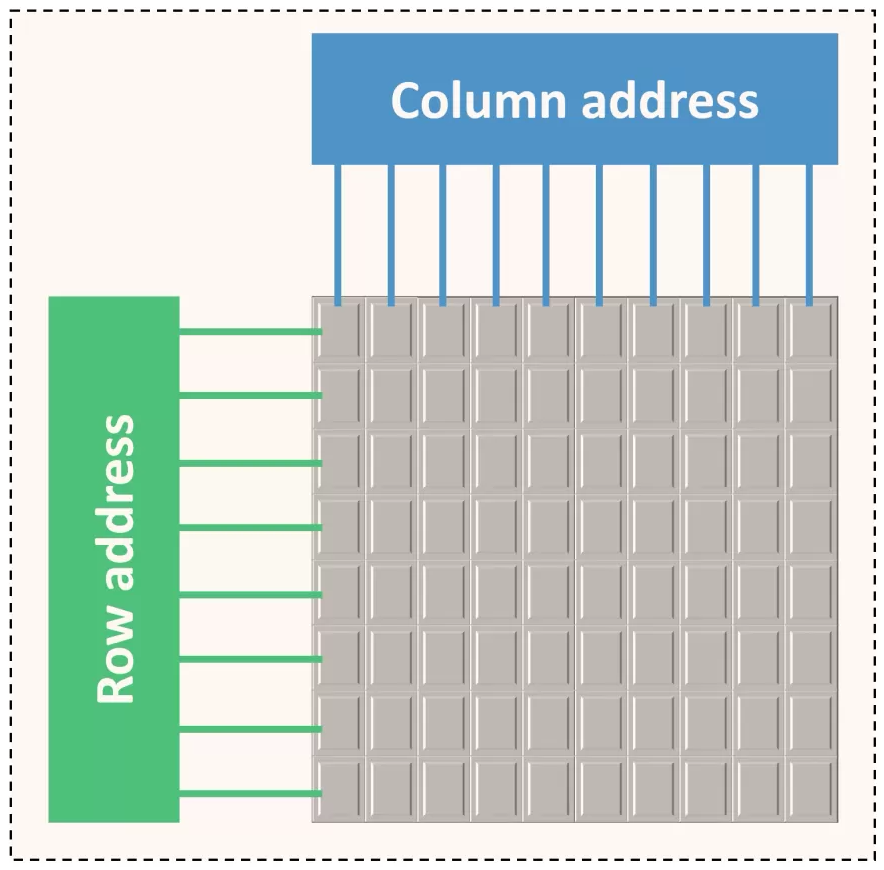
- 由32、64或128个并行使用的内存平面组成的内存组(memory bank)——这些平面通常分布在多个芯片上,其中一个芯片包含16或32个内存平面。bank中的所有页面都连接到行寻址系统(列也是如此),并且这些页面由命令信号和每行/列的地址控制。bank中的行和列越多,地址中需要使用的位就越多。

- 由若干个[2、4或8]个memory bank连接在一起并由地址位选择的内存排(memory rank)——给定内存平面的所有memory bank位于同一芯片中。
- 由一个或两个连接在一起并由芯片选择线选择的memory rank组成的内存子分区(memory subpartition)——rank的行为类似于bank,但不必具有统一的几何结构,而是在单独的芯片中。
- 由一个或两个稍微独立的memory subpartition组成了内存分区(memory partition)。
- 整个VRAM由几个[1-8]个memory partition组成。
以上数量会因不同的GPU架构和家族而不同。
DRAM最基本的单元是内存平面,它是按所谓的列和行组织的二维位数组:
column
row 0 1 2 3 4 5 6 7
0 X X X X X X X X
1 X X X X X X X X
2 X X X X X X X X
3 X X X X X X X X
4 X X X X X X X X
5 X X X X X X X X
6 X X X X X X X X
7 X X X X X X X Xbuf X X X X X X X X内存平面包含一个缓冲区,该缓冲区可容纳整个行。在内部,DRAM通过缓冲区以行为单位进行读/写。因此有几个后果:
- 在对某个位进行操作之前,必须将其行加载到缓冲区中,会很慢。
- 处理完一行后,需要将其写回内存数组,也很慢。
- 因此,访问新行的速度很慢,如果已经有一个活动行,访问速度甚至更慢。
- 在一段不活动时间后,抢先关闭一行通常很有用——这种操作称为precharging(预充电?)一个bank。
- 但是,可以快速访问同一行中的不同列。
由于加载列地址本身比实际访问活动缓冲区中的位花费更多的时间,所以DRAM是以突发方式访问的,即对活动行中1-8个相邻位的一系列访问。通常,突发中的所有位都必须位于单个对齐的8位组中。内存平面中的行和列的数量始终是2的幂,并通过行选择和列选择位的计数来衡量[即行/列计数的log2],通常有8-10列位和10-14行位。内存平面被组织在bank中,bank由两个内存平面的幂组成。内存平面是并行连接的,共享地址和控制线,只有数据/数据启用线是分开的。这有效地使内存bank类似于由32位/64位/128位内存单元组成的内存平面,而不是单个位——适用于平面的所有规则仍然适用于bank,但操作的单元比位大。单个存储芯片通常包含16或32个存储平面,用于单个bank,因此多个芯片通常连接在一起以形成更宽的bank。
一个内存芯片包含多个[2、4或8]个bank,使用相同的数据线,并通过bank选择线进行多路复用。虽然在bank之间切换比在一行中的列之间切换要慢一些,但要比在同一bank中的行之间切换快得多。因此,一个内存bank由(MEMORY_CELL_SIZE / MEMORY_CELL_SIZE_PER_CHIP)存储器芯片组成。一个或两个通过公共线(包括数据)连接的内存列,芯片选择线除外,构成内存子分区。在rank之间切换与在bank中的列组之间切换具有基本相同的性能后果,唯一的区别是物理实现和为每个rank使用不同数量行选择位的可能性(尽管列计数和列计数必须匹配)。存在多个bank/rank的后果:
- 确保一起访问的数据要么属于同一行,要么属于不同的bank,这一点很重要(以避免行切换)。
- 分块内存布局的设计使分块大致对应于一行,相邻的分块从不共享一个bank。
内存子分区在GPU上有自己的DRAM控制器。1或2个子分区构成一个内存分区,它是一个相当独立的实体,具有自己的内存访问队列、自己的ZROP和CROP单元,以及更高版本卡上的二级缓存。所有内存分区与crossbar逻辑一起构成了GPU的整个VRAM逻辑,分区中的所有子分区必须进行相同的配置,GPU中的分区通常配置相同,但在较新的卡上则不是必需的。子分区/分区存在的后果:
- 与bank一样,可以使用不同的分区来避免相关数据的行冲突。
- 与bank不同,如果(子)分区没有得到同等利用,带宽就会受到影响。因此,负载平衡非常重要。
虽然内存寻址高度依赖于GPU系列,但这里概述了基本方法。内存地址的位按顺序分配给:
- 识别内存单元中的字节,因为无论如何都必须访问整个单元。
- 多个列选择位,以允许突发(burst)。
- 分区/子分区选择-以低位进行,以确保良好的负载平衡,但不能太低,以便在单个分区中保留相对较大的tile,以利于ROP。
- 剩余列选择位。
- 所有/大部分bank选择位,有时是排名选择位,以便相邻地址不会导致行冲突。
- 行位。
- 剩余的bank位或rank位,有效地允许将VRAM拆分为两个区域,在其中一个区域放置颜色缓冲区,在另一个区域放置zeta缓冲区,这样它们之间就不会有行冲突。
此外,可以不同倍数的数据速率同步动态随机存取内存,正是我们所熟知的DDR-SDRAM或DDR:

单ank和双rank对比。

单速率、双速率、四速率对比图。
下图是CPU和GPU内存请求路线:
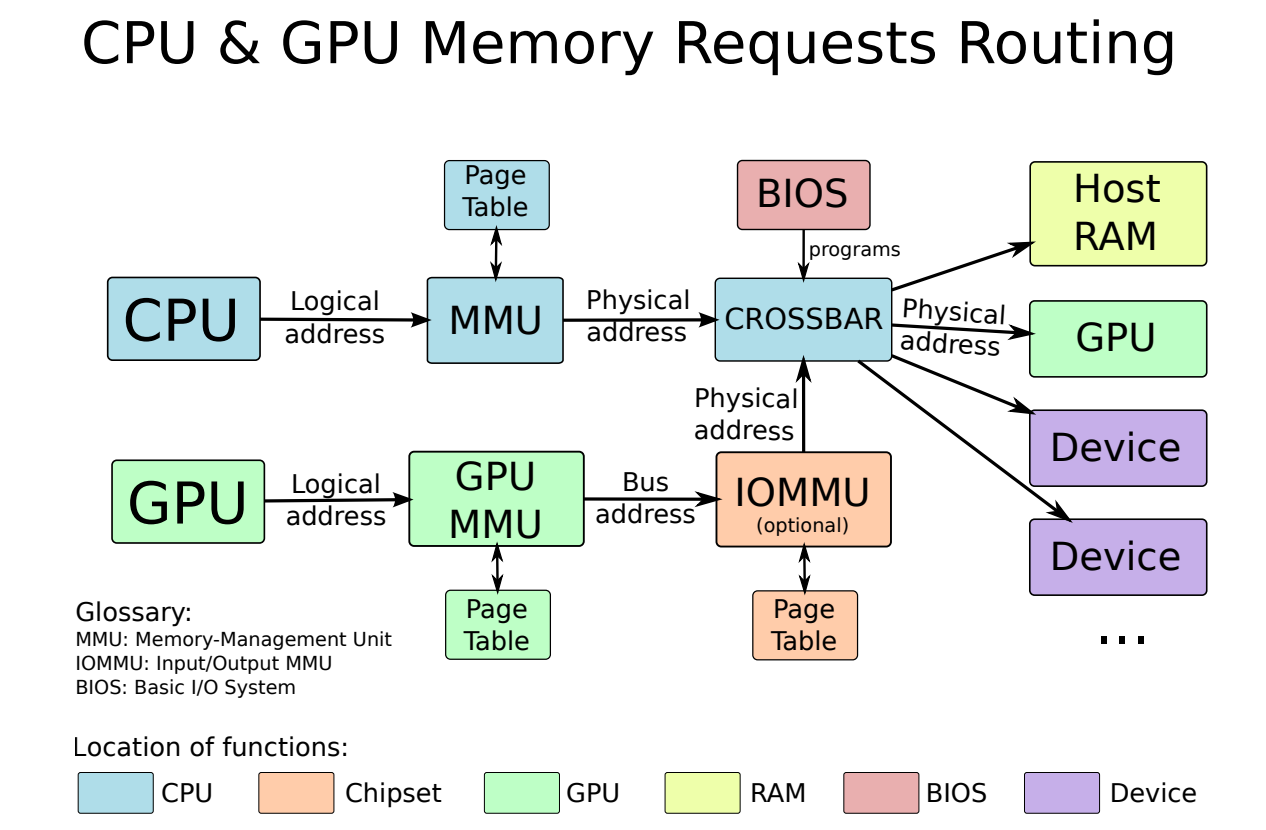
GTT/GART作为CPU-GPU共享缓冲区用于通信:
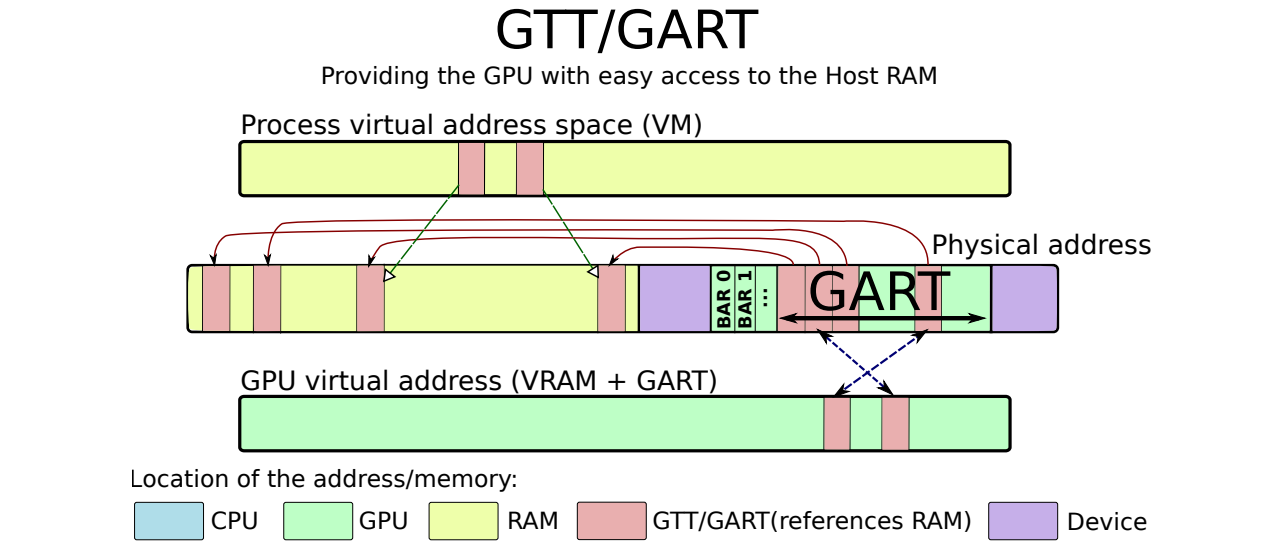
16.2.4 虚拟和物理内存
内存有两种主要的不同含义:
- 物理内存。物理内存是真实的硬件内存,存储在内存芯片中。
- 虚拟内存。虚拟内存是物理内存地址的转换,允许用户空间应用程序查看其分配的块,就好像它们是连续的,而它们在芯片上是碎片化和分散的。
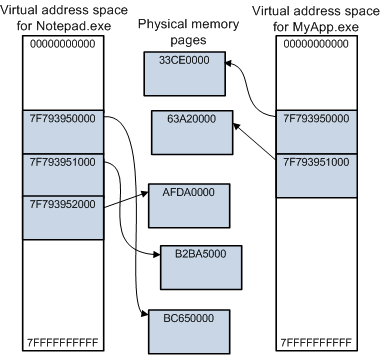
虚拟地址空间的一些关键功能,以及虚拟内存和物理内存的关系。
一些操作系统(如Windows)还存在**分页缓冲池(paged pool)和非分页缓冲池(nonpaged pool)**的机制。在用户空间中,所有物理内存页面都可以根据需要调出到磁盘文件。 在系统空间中,某些物理页面可以调出,而其他物理页面则不能。 系统空间具有用于动态分配内存的两个区域:分页缓冲池和非分页缓冲池。分页缓冲池中分配的内存可以根据需要调出到磁盘文件,非分页缓冲池中分配的内存永远无法调出到磁盘文件。
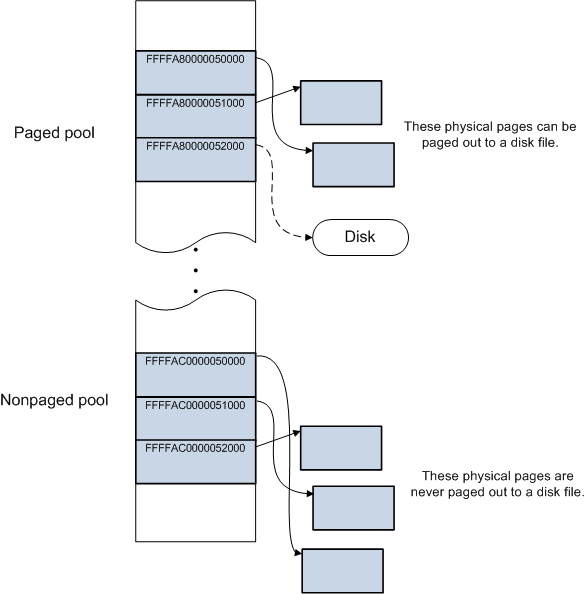
为了简化编程,更容易处理连续的内存区域。分配一个小的连续区域很容易,但分配一个更大的内存块将需要同样多的连续物理内存,在启动后由于内存碎片化导致难以实现。因此,需要一种机制来保持应用程序的连续内存块外观,同时使用分散的内存块。
为了实现这一点,内存被拆分为多个页。就本文的范围而言,可以说内存页是物理内存中连续字节的集合,以便使分散的物理页列表在虚拟空间中看起来是连续的,一个称为**MMU(内存映射单元)**的硬件使用页表将虚拟地址(用于应用程序)转换为物理地址(用于实际访问内存),如下图所示。如果页面不存在于虚拟空间中(因此不在MMU表中),MMU可以向其发送信号,为报告对不存在内存区域的访问提供了基本机制。反过来又被系统用来实现高级内存编程,如交换或动态页面实例化。由于MMU仅对CPU访问内存有效,虚拟地址与硬件无关,因为无法将它们与物理地址匹配。
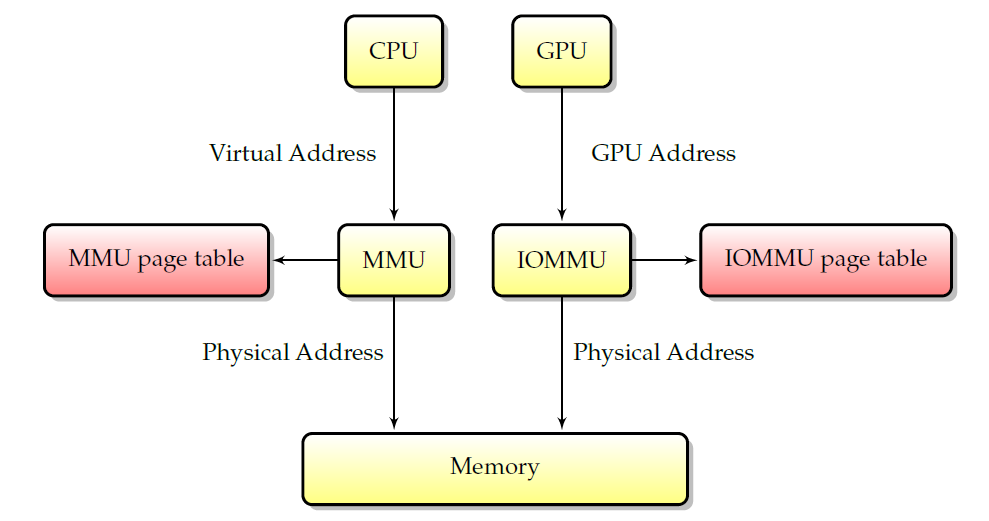
MMU和IOMMU。
虽然MMU只适用于CPU访问,但它对外围设备有一个等价物:IOMMU。如上图所示,IOMMU与MMU相同,只是它虚拟化了外围设备的地址空间。IOMMU可以在主板芯片组(在这种情况下,它在所有外围设备之间共享)或图形卡本身(在图形卡本身上,它将被称为AGP GART、PCI GART)上看到各种化身。IOMMU的工作是将外围设备的内存地址转换为物理地址。特别是,它允许“欺骗”设备将其DMA限制在给定的内存范围内,是更好的安全性和硬件虚拟化所必需的。
IOMMU的一个特例是Linux swiotlb,它在引导时分配一段连续的物理内存(使得有一个大的连续物理分配是可行的,因为还没有碎片),并将其用于DMA。由于内存在物理上是连续的,不需要页转换,因此可以在该内存范围内进行DMA。但是,意味着该内存(默认为64MB)是预先分配的,不会用于其他任何用途。
AGP GART是IOMMU的另一个特例,它与AGP图形卡一起使用,向图形卡显示一个线性区域。在这种情况下,IOMMU被嵌入主板上的AGP芯片组中。AGP GART区域作为虚拟内存的线性区域向系统公开。
IOMMU的另一个特例是某些GPU上的PCI GART,它允许向卡公开一块系统内存。在这种情况下,IOMMU表嵌入到图形卡中,通常使用的物理内存不需要是连续的。
显然,有这么多不同的内存类型,性能是不均匀的,并非所有的访问组合都是快速的,主要取决于它们是否涉及CPU、GPU或总线传输。另一个问题是内存一致性:如何确保跨设备的内存一致,尤其是CPU写入的数据可供GPU使用(或相反)。这两个问题是相关的,因为较高的性能通常意味着较低水平的内存连贯性,反之亦然。
就设置内存缓存参数而言,有两种方法可以在内存范围上设置缓存属性:
- MTRR。MTRR(内存类型范围寄存器)是描述给定物理内存范围属性的寄存器。每个MTRR包含一个起始物理地址、一个大小和一个缓存类型。MTRR的数量取决于系统,但非常有限。虽然适用于物理内存范围,但效果会作用于相应的虚拟内存页。例如,可以使用特定的缓存类型映射页面。
- PAT(页面属性表)允许设置每页内存属性。与MTRR一样依赖有限数量的内存范围不同,可以在每页的基础上指定缓存属性。但是,它是仅在最新x86处理器上可用的扩展。
除此之外,可以在某些体系结构上使用显式缓存指令,例如在x86上,movntq是一条未缓存的mov指令,clflush可以选择性地刷新缓存行。
有三种缓存模式,可通过MTRR和PAT系统内存使用:
- UC(UnCached)内存未缓存。CPU对此区域的读/写是未缓存的,每个内存写入指令都会触发实际的即时内存写入。有助于确保信息已实际写入,以避免CPU/GPU争用的情况。
- WC(Write Combine)内存未缓存,但CPU写入被组合在一起以提高性能。在需要未缓存内存但将写操作组合在一起不会产生不利影响的情况下,非常有利于提高性能。
- WB(Write Back)内存已被缓存。是默认模式,可以获得CPU访问的最佳性能。然而,并不能确保内存写入在有限时间后传播到中央内存。
请注意,以上缓存模式仅适用于CPU,GPU访问不受当前缓存模式的直接影响。然而,当GPU必须访问之前由CPU填充的内存区域时,未缓存模式可确保实际完成内存写入,并且不会挂起在CPU缓存中。实现相同效果的另一种方法是使用某些x86处理器(如cflush)上的缓存刷新指令,但比使用缓存模式的可移植性差。另一种(可移植的)方法是使用内存屏障,它可以确保在继续之前将挂起的内存写入提交到主内存。
显然,有这么多不同的缓存模式,并非所有访问都具有相同的性能:
- 在CPU访问系统内存时,未缓存模式提供最差的性能,回写提供最好的性能,写入组合介于两者之间。
- 当CPU从离散卡访问视频内存时,所有访问都非常慢,无论是读还是写,因为每次访问都需要总线上的一个周期。因此,不建议使用CPU访问大面积的VRAM。此外,在某些GPU上需要同步,否则可能会导致GPU挂起。
- 显然,GPU访问VRAM的速度非常快。
- GPU对系统RAM的访问不受缓存模式的影响,但仍须通过总线,DMA事务就是这种情况。由于都是异步发生的,从CPU的角度来看,它们可以被视为“免费”,但是每个DMA事务都涉及到不可忽略的设置成本。这就是为什么在传输少量内存时,DMA事务并不总是优于直接CPU访问。
最后,关于内存的最后一个重要观点是内存屏障和写入账本(write posting)的概念。对于缓存(写合并或写回)内存区域,内存屏障可确保挂起的写操作实际上已提交到内存。例如,在要求GPU读取给定的内存区域之前,会使用此选项。对于I/O区域,存在一种类似的称为写入账本的技术:包括在I/O区域内进行虚拟读取,作为一种副作用,它会等到挂起的写入生效后再完成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lNEQw0ro-1656218692594)(https://img2022.cnblogs.com/blog/1617944/202206/1617944-20220623135955177-1742403431.svg)]
经典的桌面计算机体系结构,在PCI Express上具有独特的图形卡。给定内存技术的典型带宽缺少内存延迟,GPU和CPU之间不可能实现零拷贝,因为两者都有各自不同的物理内存,数据必须从一个复制到另一个才能共享。
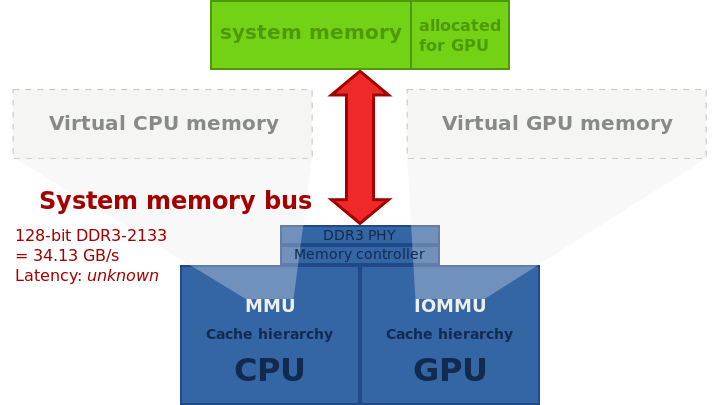
带分区主内存的集成图形:系统内存的一部分专门分配给GPU,零拷贝不可能实现,数据必须通过系统内存总线从一个分区复制到另一个分区。
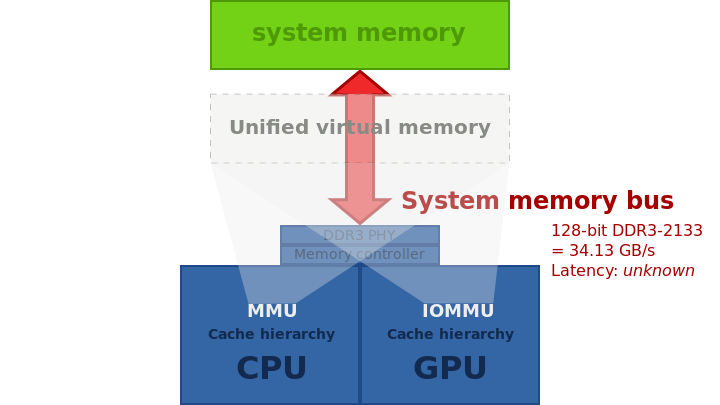
具有统一主存储器的集成图形,可在AMD Kaveri或PlayStation 4(HSA)中找到。
16.2.5 PFIFO
大多数引擎的命令都是通过一个名为PFIFO的特殊引擎发送的,PFIFO维护多个完全独立的命令队列,称为通道(channel)或FIFO,每个通道通过“通道控制区”进行控制,该区域是MMIO[GF100之前]或VRAM[GF100+]的区域,PFIFO拦截所有进入该区域的通道并对其采取行动。
PFIFO内部在通道之间进行分时(time-sharing),但对应用程序是透明的,PFIFO控制的引擎也知道通道,并为每个通道维护单独的上下文。
PFIFO的上下文切换能力取决于卡的次代。在NV40,PFIFO基本上可以随时在通道之间切换。在旧卡上,由于缺少缓存的后备存储,只有在缓存为空时才能切换。然而,PFIFO控制的引擎在切换方面要差得多:它们只能在命令之间切换。虽然这种方式在旧卡上不是一个大问题(因为命令保证在有限的时间内执行),但引入具有循环功能的可编程着色器,可以通过启动长时间运行的着色器来有效地挂起整个GPU。
PFIFO大致可分为4个部分:
- PFIFO pusher:收集用户命令并将其注入。
- PFIFO cache:等待执行的大量命令。
- PFIFO puller:执行命令,将其传递给适当的引擎或驱动。
- PFIFO switcher:标出通道的时间片,并在PFIFO寄存器和RAMFC内存之间保存/恢复通道的状态。
通道由以下部分组成:
- 通道模式:PIO[NV1:GF100]、DMA[NV4:GF100]或IB[G80-]。
- PFIFO DMA pusher状态[仅限DMA和IB通道]。
- PFIFO缓存状态:已接受但尚未执行的命令。
- PFIFO puller状态。
- RAMFC:当PFIFO上的通道当前未激活时,存储上述信息的VRAM区域[用户不可见]。
- RAMHT[仅限GF100之前版本]:通道可以使用的“对象”表,对象由任意32位句柄标识,可以是DMA对象[参见NV3 DMA对象、NV4:G80 DMA对象、DMA对象]或引擎对象。在G80之前的卡上,可以在通道之间共享单个对象。
- vspace(仅G80+):页表的层次结构,描述引擎在执行通道命令时可见的虚拟内存空间,多个通道可以共享一个vspace。
- 引擎特定状态。
通道模式决定向通道提交命令的方式。在GF100之前的卡上可以使用PIO模式,并且需要将这些方法直接插入通道控制区域。它的速度慢且脆弱——当多个通道同时使用时,很容易发生故障,故而不推荐使用。在NV1:NV40上,所有通道都支持PIO模式。在NV40:G80上,只有前32个通道支持PIO模式。在G80上:GF100仅通道0支持PIO模式。
16.2.6 图形卡剖析
如今,图形卡基本上是计算机中的计算机。它是一个复杂的野兽,在一个单独的卡上有一个专用处理器,具有自己的计算单元、总线和内存。本节概述图形卡,包括以下元素。
- Graphics Memory(图形内存)
GPU的内存(视频内存),可以是真实的、专用的、卡上内存(对于离散卡),也可以是与CPU共享的内存(对于集成卡,也称为“被盗内存”或“雕刻内存”)。请注意,共享内存的情况有着有趣的含义,因为如果实现得当,系统到视频内存的拷贝实际上是免费的。在专用内存的情况下,意味着需要进行来回传输,并且它们将受到总线速度的限制。
现代GPU也有一种形式的虚拟内存,允许将不同的资源(系统内存的真实视频内存)映射到GPU地址空间,与CPU的虚拟内存非常相似,但使用完全独立的硬件实现。例如,较旧的Radeon卡(实际上是Rage 128)具有许多表面(Surface),我们可以将这些表面映射到GPU地址空间,每个表面都是连续的内存资源(视频ram、AGP、PCI)。旧的Nvidia卡(NV40之前的所有卡)有一个类似的概念,它基于描述内存区域的对象,然后可以绑定到给定的用途。稍后的图形卡(从NV50和R800开始)可以让我们逐页构建地址空间,还可以随意选择系统和专用视频内存页。这些与CPU虚拟地址空间的相似性非常惊人,事实上,未映射的页面访问可以通过中断向系统发出信号,并在视频内存页面错误处理程序中执行。然而,小心处理这些问题,因为驱动程序开发人员必须处理来自CPU和GPU的多个地址空间,它们具有本质性的不同点。
- Surface(表面)
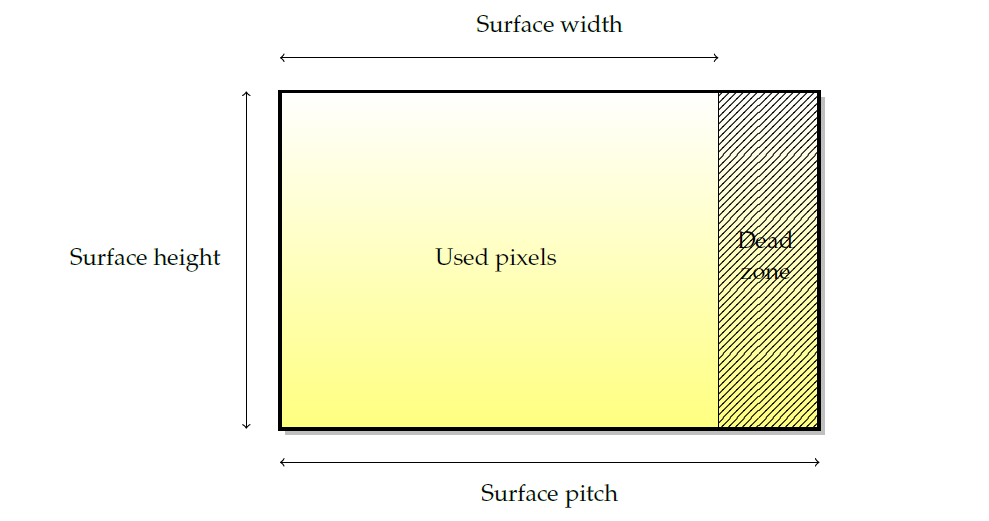
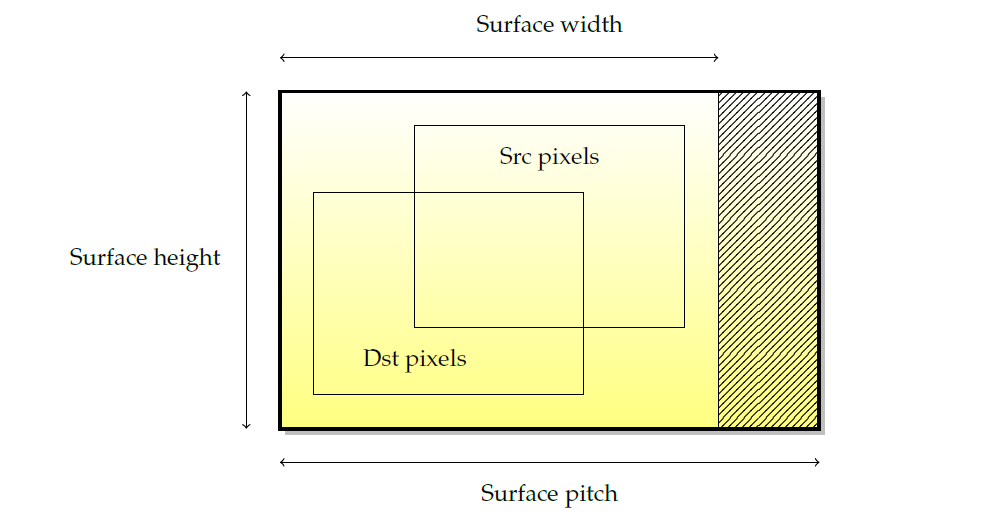
表面是所有渲染的基本源和目标。尽管它们的叫法有所差异(纹理、渲染目标、缓冲区…)基本思想总是一样的。下图描述了图形表面的布局。由于硬件限制(通常是某些2次方的下一个倍数),表面宽度被四舍五入到我们所称的间距,因此存在一个未使用的像素死区。
图形表面具有许多特征:
- 表面的像素格式。像素颜色由其红色、绿色和蓝色分量以及用作混合不透明度的alpha分量表示。整个像素的位数通常与硬件大小相匹配(8、16或32位),但四个组件之间的位数重新分配不必与硬件大小相匹配。用于每个像素的位数被称为每像素位数或bpp。常见的像素格式包括888 RGBX、8888 RGBA、565 RGB、5551 RGBA、4444 RGBA。请注意,现在大多数图形卡都是在8888中原生工作的。
- 宽度和高度是最明显的特征,以像素为单位。
- 间距是以字节为单位的宽度(不是以像素为单位!)表面的,包括空白区域(dead zone)像素。pitch便于计算内存使用量,例如,表面的大小应通过
高度 x pitch而不是高度 x 宽度 x bpp来计算,以便包括dead zone。
请注意,表面并非总是线性存储在视频内存中,事实上,出于性能原因,表面通常不是以线性存储,因为这样可以改善渲染时内存访问的位置。此类表面称为分块表面(tiled surface),分块表面的精确布局高度依赖于硬件,但通常是一种空间填充曲线,如Z曲线(又叫Z-order曲线、Morton曲线,下图)或Hilbert曲线(下下图)。

另外,Morton和Hilbert曲线还支持3D空间的遍历:
- 2D Engine(2D引擎)
2D引擎或blitter是用于2D加速的硬件,Blitter是最早的图形加速形式之一,今天仍然非常普遍。通常,2D引擎能够执行以下操作:
- Blits。BLIT是GPU将内存矩形从一个位置复制到另一个位置的副本,源和目标可以是视频或系统内存。
- 实心填充。实心填充包括用颜色填充矩形内存区域,也可以包括alpha通道。
- Alpha blits。Alpha Blit使用来自表面的像素的Alpha分量来实现透明度。
- 拉伸拷贝。
下图显示了在两个不同表面之间拼接矩形的示例。此操作由以下参数定义:源和目标坐标、源和目标节距以及blit宽度和高度。然而,仅限于2D坐标,通常不能使用blitting引擎进行透视或变换。
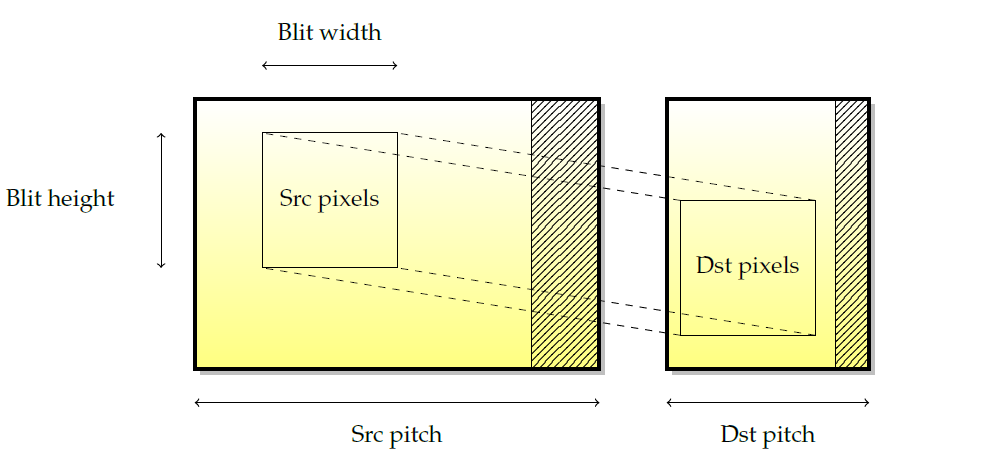
当blit发生在两个重叠的源表面和目标表面之间时,副本的语义并不是简单定义的,尤其是当人们认为blit发生的不是简单的矩形移动,而是在核心逐像素移动时。如下图所示,如果一行一行地从上到下复制,一些源像素将被修改为副作用。因此,拷贝方向的概念被引入到blitter中。在这种情况下,要获得正确的副本,需要从下到上的副本。一些卡将根据表面重叠自动确定拷贝方向(例如nvidia GPU),而其他卡则不会,在这种情况下,必须由驱动处理。这就是为什么有些GPU实际上支持负的pitch,以便告诉2D引擎后退。
最后,请记住,并非所有当前的图形加速器都具有2D引擎。由于3D加速在技术上是2D加速的超集,因此可以使用3D引擎实现2D加速。事实上,一些驱动程序使用3D引擎来实现2D,使得GPU制造商可以完全放弃专用于2D的晶体管。然而,其他一些卡并不专用于晶体管,而是在GPU内部的3D操作之上对2D操作进行微程序化(nv10之后的nVidia卡和nv50之前的nVidia卡都是这种情况,对于Radeon R600系列,它们具有在3D之上实现2D的可选固件)。有时会影响2D和3D操作的混合,因为它们现在共享硬件单元。
- 3D Engine(3D引擎)
3D引擎也称为光栅化引擎。它包含一系列以管线(单向)方式交换数据的阶段,如顶点->几何->片元、图形FIFO、DMA等。为了获得更好的缓存位置,纹理和表面通常会分块。分块意味着纹理不是线性存储在GPU内存中,而是存储在内存中,以便使纹理空间中接近的像素也在内存空间中接近,例如Z阶曲线和希尔伯特曲线。
- 覆盖层和硬件精灵(Overlays and hardware sprites)。
扫描输出:图形显示的最后一个阶段是将信息显示在显示设备或屏幕上,显示设备是图形链的最后一环,负责向用户展示图片。
此外,还有数字与模拟信号、hsync、vsync、绿同步、连接器和编码器(CRTC、TMD、LVDS、DVI-I、DVI-A、DVI-D、VGA)等技术,此文忽略之。
16.2.7 图形卡编程
每个PCI卡公开多个PCI资源,lspci-v列出了这些资源,包含但不限于BIOSS、MMIO范围、视频存储器(或仅部分)。由于PCI总资源大小有限,通常一张卡只能将其部分视频内存作为资源公开,访问剩余内存的唯一方法是通过其他可访问区域的DMA(以类似于跳转页面的方式)。随着视频内存大小不断增长,而PCI资源空间仍然有限,这种情况越来越普遍。
- MMIO
MMIO是卡的最直接访问方式。一系列地址暴露给CPU,每个写操作都直接进入GPU,使得从CPU到GPU的命令通信最简单。这种编程是同步的;写操作由CPU完成,并在GPU上以锁步方式执行,会导致低于标准的性能,因为每次访问都会在总线上变成一个数据包,而且CPU在提交后续命令之前必须等待以前的GPU命令完成。因此,MMIO仅用于当今驱动程序的非性能关键路径。
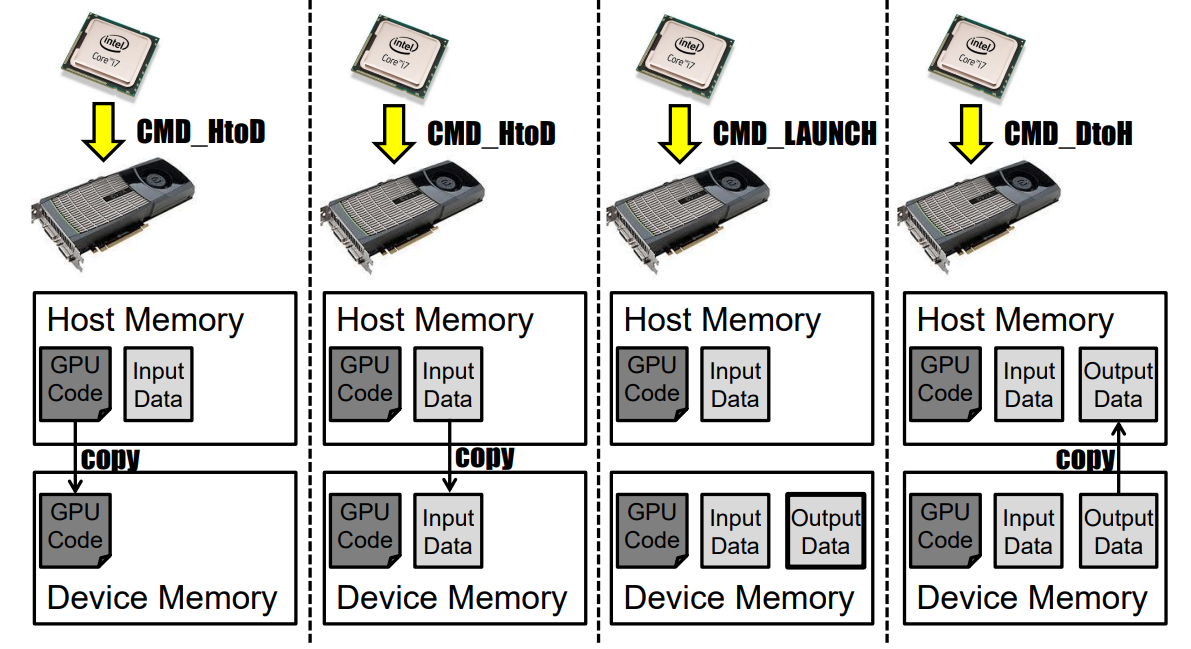
- DMA
直接内存访问(DMA)是指外围设备使用总线的总线主控功能,允许一个外设直接与另一个外设对话,而无需CPU的干预。在图形卡的情况下,DMA最常见的两种用途是:
1、GPU与系统内存之间的传输(用于读取纹理和写入缓冲区)。允许在AGP或PCI上实现纹理,以及硬件加速的纹理传输。
2、执行命令FIFO。由于CPU和GPU之间的MMIO是同步的,并且图形驱动程序本身使用大量的I/O,因此需要更快的方式与卡通信。命令FIFO是图形卡和CPU之间共享的一块内存(系统内存或更罕见的视频内存),CPU在其中放置命令供GPU稍后执行,然后GPU使用DMA异步读取FIFO并执行命令。此模型允许异步执行CPU和GPU命令流,从而提高性能。
- Interrupt(中断)
中断通常是硬件外围设备,尤其是GPU向CPU发送事件信号的一种方式。中断的使用示例包括发出图形命令完成的信号、发出垂直消隐事件的信号、报告GPU错误等等。
当外围设备引发中断时,CPU会执行一个称为中断处理程序的小例程(routine),该例程会抢占其他当前执行。中断处理程序有一个最长的执行时间,因此驱动程序必须保持较短的时间(不超过几微秒)。为了执行更多的代码,常见的解决方案是从中断处理程序调度一个小任务(tasklet)。
16.2.8 图形硬件案例
- 前向渲染
前向渲染器(即经典渲染器)是渲染三维图元最直接的方法,将向GPU逐个提交图形API以绘制几何体,并重复这个过程,是大多数移动GPU中使用的方法。
与其他体系结构相比,NVidia硬件具有多种特殊性。第一个是多个上下文的可用性,它使用多个命令FIFO(类似于某些高端infiniband网卡的功能)和上下文切换机制来实现这些FIFO之间的转换。一个小型固件用于上下文之间的上下文切换,负责将图形卡状态保存到内存的一部分并恢复另一个上下文。使用循环算法的调度系统处理上下文的选择,并且时间片是可编程的。
第二个特性是图形对象的概念。Nvidia硬件具有两个GPU访问级别:第一个是原始级别,用于上下文切换;第二个是图形对象,对原始级别进行微编程以实现高级功能(例如2D或3D加速)。
- 延迟渲染
延迟渲染器是GPU的不同设计。驱动程序将其存储在内存中,而不是在渲染API提交时渲染每个3D图元,当它注意到帧结束时,它会发出单个硬件调用来渲染整个场景。与经典体系结构相比,延迟渲染有许多优点:
1、通过将屏幕拆分为分块(通常在16 x 16到32 x 32像素范围内),可以实现更好的渲染位置。然后,GPU可以迭代这些分块,对于其中的每个分块,可以在内部(迷你)zbuffer中解析每像素深度。渲染完整个分块后,可以将其写回视频内存,从而节省宝贵的带宽。类似地,由于可见性是在获取纹理数据之前确定的,因此仅读取有用的纹理数据(再次节省带宽),并且仅对可见片元执行片元着色器(节省了计算能力)。
2、如果不需要深度缓冲区值,则无需将其写入内存。深度缓冲区分辨率可以在GPU内的每个分块上实现,并且永远不会写回视频内存,因此可以节省视频内存带宽和空间。
当然,分块渲染需要在开始绘制之前将整个场景存储在内存中,并且还将增加延迟,因为我们甚至需要在开始绘制之前等待帧结束。当驱动程序已经允许应用程序提交下一帧的数据时,通过在GPU上绘制给定帧可以部分隐藏延迟问题。然而,在某些情况下(回读、跨进程同步),并不总是能够避免它。
延迟渲染器对于带宽通常非常稀缺的嵌入式平台特别有用,并且应用程序非常简单,因此额外的延迟和方法的限制无关紧要。SGX是延迟渲染GPU的一个示例。它使用分块结构。SGX着色器结合了混合和深度测试。延迟渲染器的另一个示例是Mali系列GPU。
总之,计算机中有多个内存域,它们不一致。GPU是一台完全独立的计算机,有自己的总线、地址空间和计算单元。CPU和GPU之间的通信是通过总线实现的,对性能有着非常重要的影响。GPU可以使用两种模式进行编程:MMIO和命令FIFO。显示设备没有标准的输出方法。
16.3 操作系统图形驱动
16.3.1 Windows图形驱动
16.3.1.1 WDDM概述
Windows图形驱动程序由IHV(英特尔、NVIDIA、AMD、高通、PowerVR、VIA、Matrox等)实现并维护,是非常丰富的驱动程序。支持基本回退(基本渲染、基本显示),实现最低限度的驱动功能,还支持虚拟化(VMware、Virtual Box、Parallels驱动程序)、远程桌面方案(XenDesktop、RDP等)、虚拟显示(intelligraphics、extramon等)。
WDDM(Windows Display Driver Model)分为用户模式和内核模式,移动到用户模式是为了稳定性和可靠性。
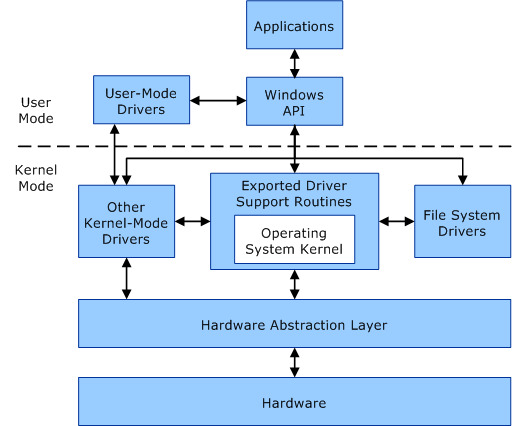
用户模式和内核模式组件之间的通信。
vista之前的大部分蓝屏都是由图形驱动程序(来自MSDN):“在Windows XP中,大型复杂的显示驱动程序可能是系统不稳定的主要原因。这些驱动程序完全在内核模式下执行(即深入系统代码),因此,驱动程序中的一个问题通常会迫使整个系统重新启动。根据在Windows XP时间段内收集的故障分析数据,显示驱动程序占所有蓝屏的20%。”
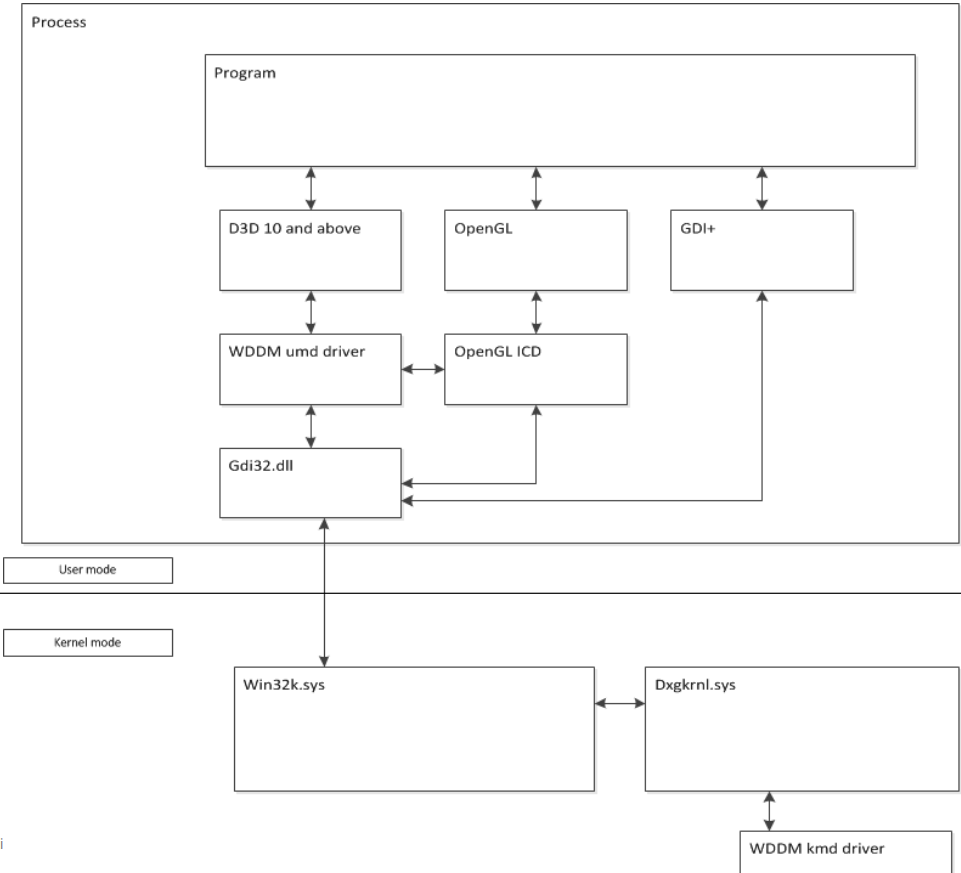
在大多数进程中,用户模式部分作为dll的一部分运行,仍然可以访问表面(编码器/解码器、二进制植入、某些API可能部分(或间接)暴露于远程访问表面(例如WebGL)。下图显示了支持WDDM所需的体系结构。
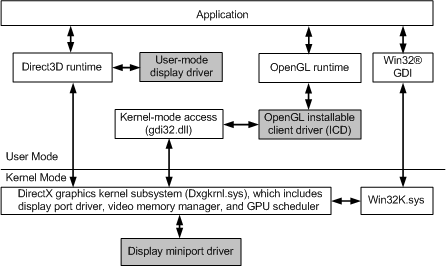
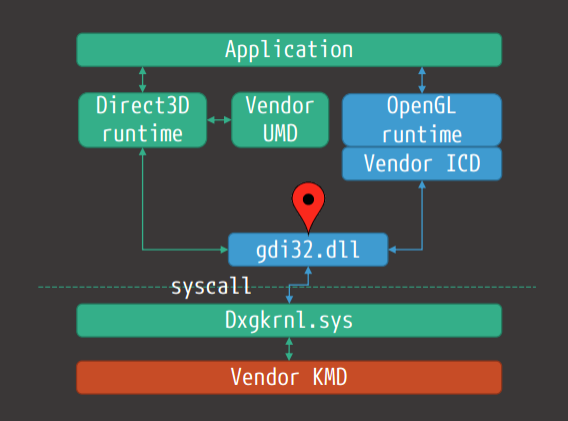
Windows的驱动模型演变历史如下:
- Windows XP:XPDM。
- Windows Vista:WDDM 1.0、DWM和Aero。
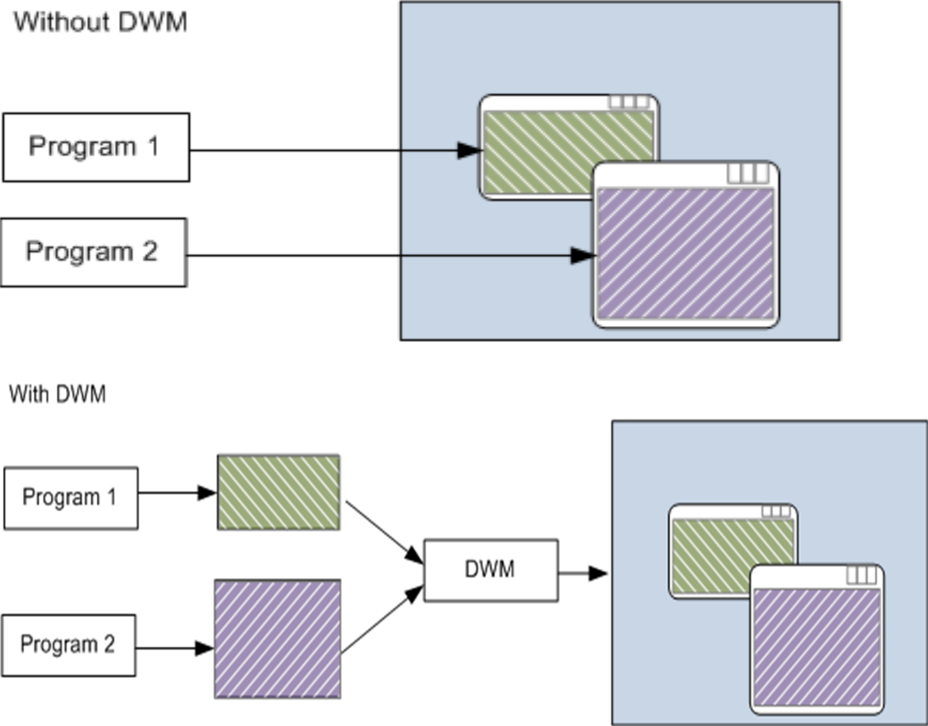
没有DWM和有dWM的对比。因为DWM处理桌面的合成,所以当每个程序都必须跟踪自己的显示时,新功能就不可用了,任务栏中的Aero Peek,Aero Glass可在最上面的窗口后查看应用程序,能够轻松改变方向,许多新的Windows动画都依赖于DWM,包括“收缩到任务栏”效果。
- Windows 7:WDDM 1.1,扩展DWM。
- Windows 8:WDDM 1.2,删除XPDM支持。
- Windows 8.1:WDDM 1.3。
- Windows 10:WDDM 2.0。
16.3.1.2 WDDM架构
早期的Windows版本(如Vista),图形/游戏/多媒体/呈现堆栈架构如下:
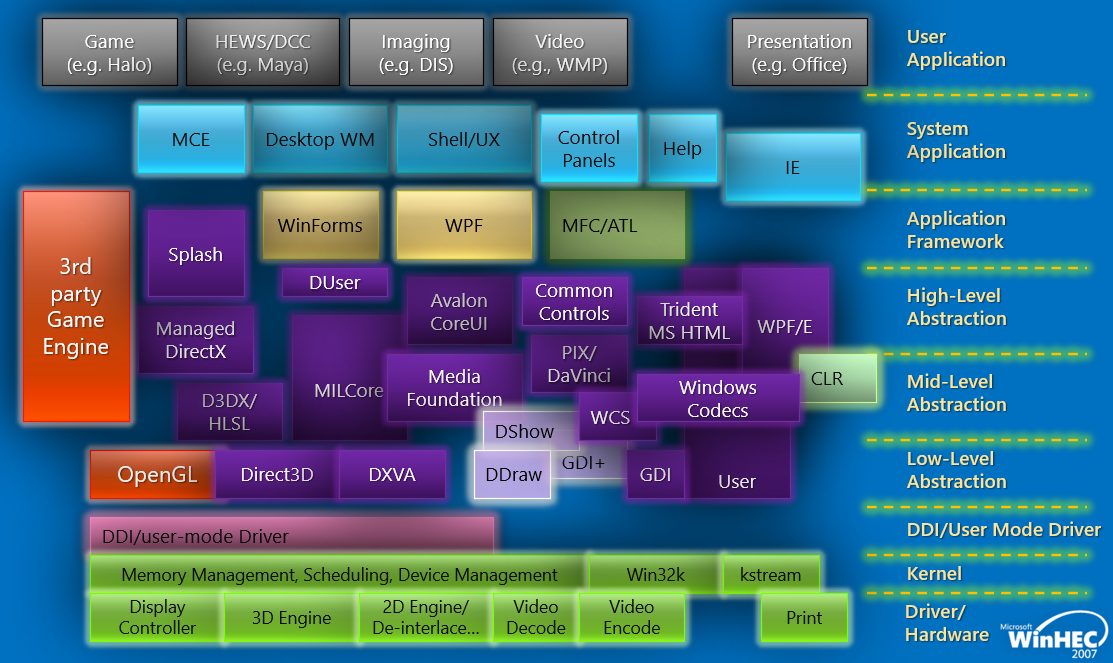
简化后的架构图如下:
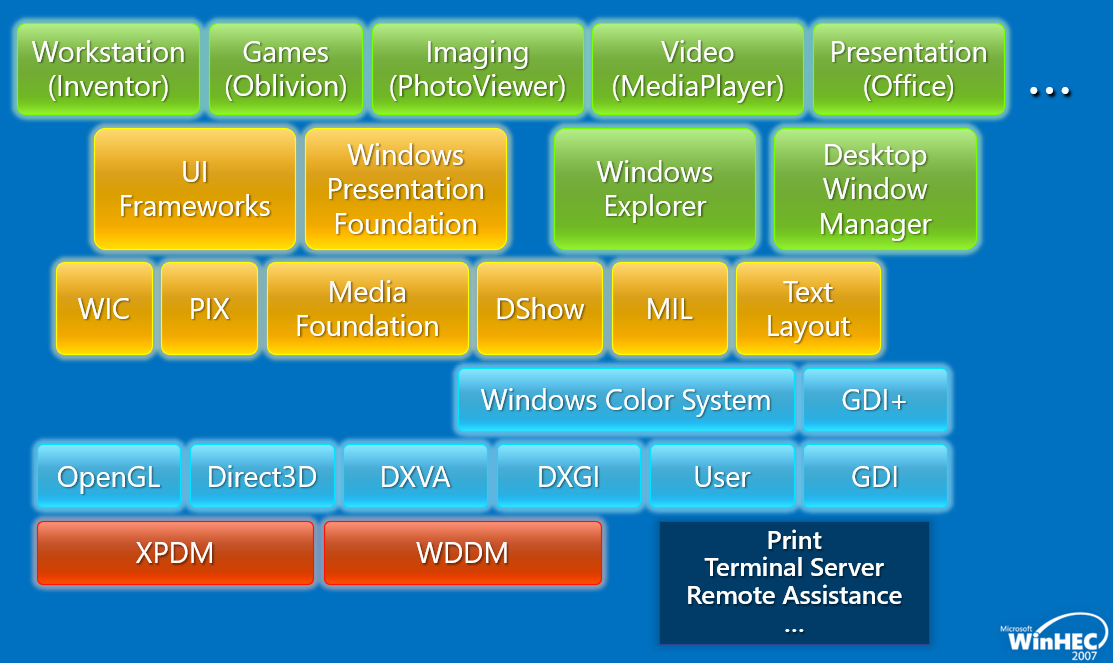
Windows Vista中的图形核心如下:
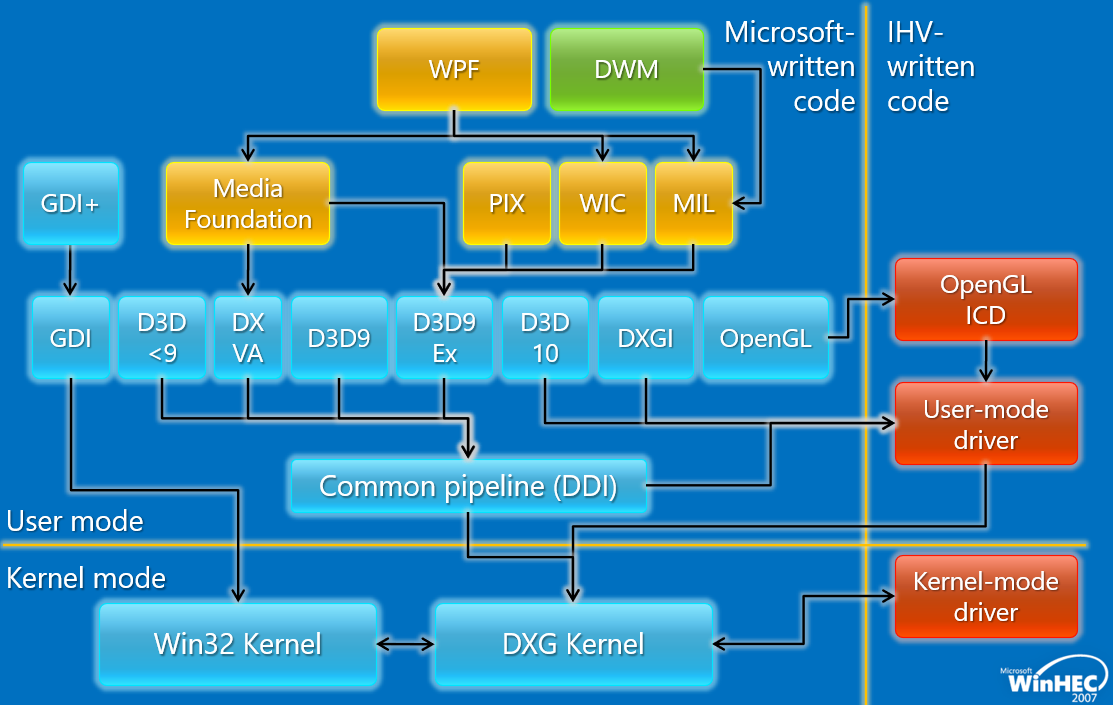
其中Windows Display Driver Model(WDDM,Windows显示驱动模型)相关的模块如下:

WDDM是构建所有图形的基石,基本原则是图形功能正常,重新架构整个驱动程序堆栈,巩固10年的发展,新的驱动程序模型,考量稳定性、安全、可用性(应用程序虚拟化)、性能。
对于图形API,早期的WDDM存在几个版本,分别如下:
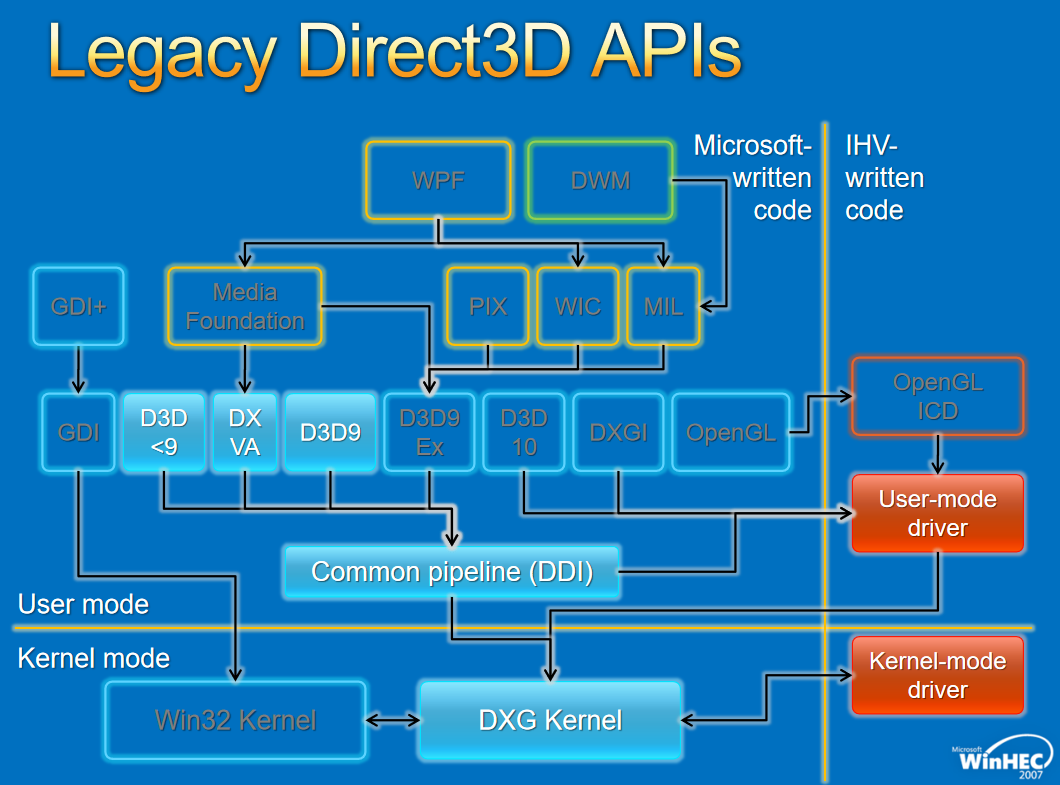
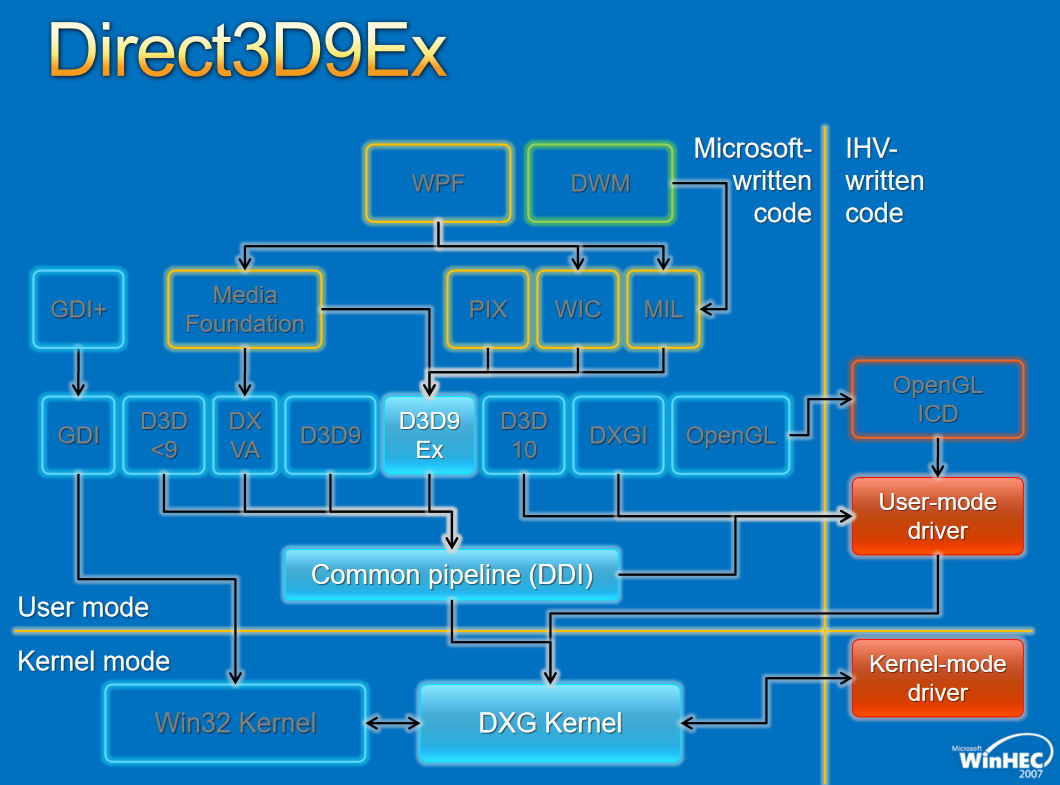
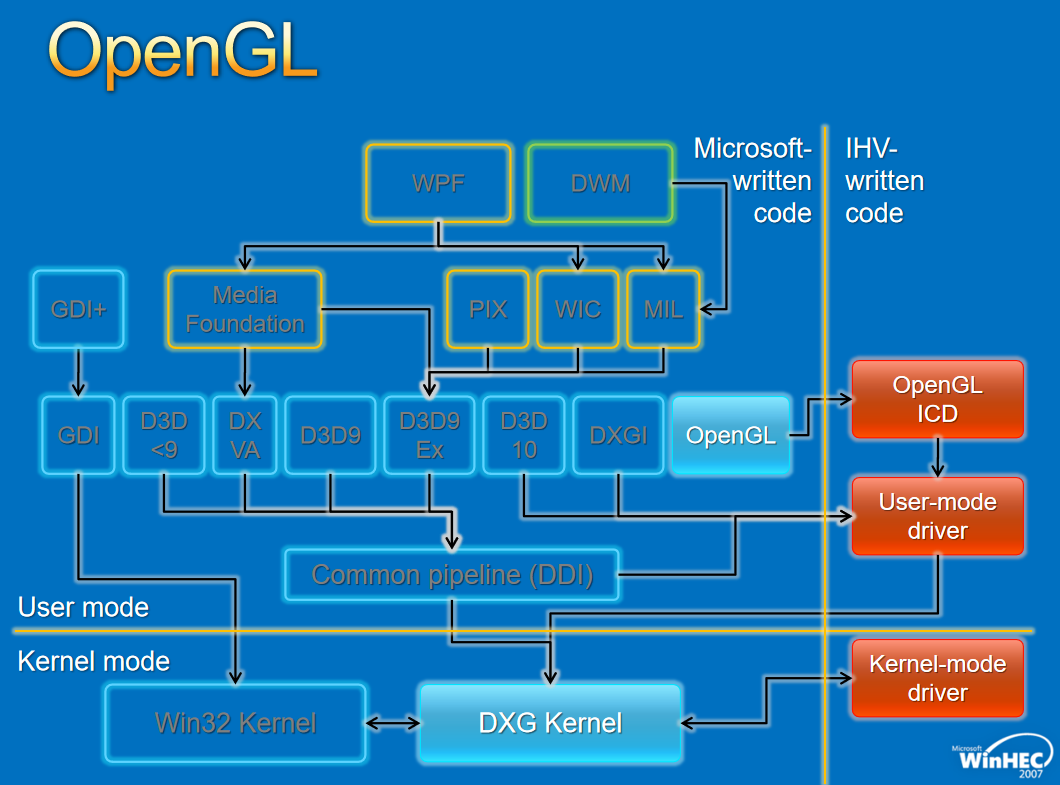
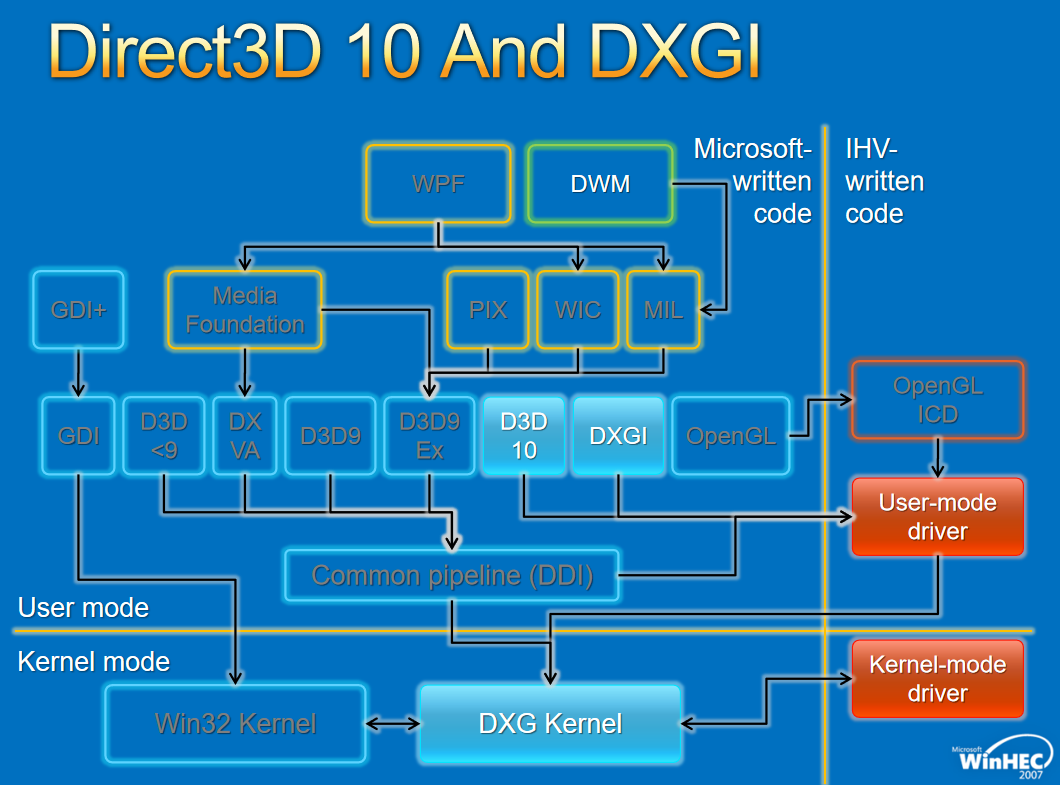
对于Window窗口管理,架构如下:
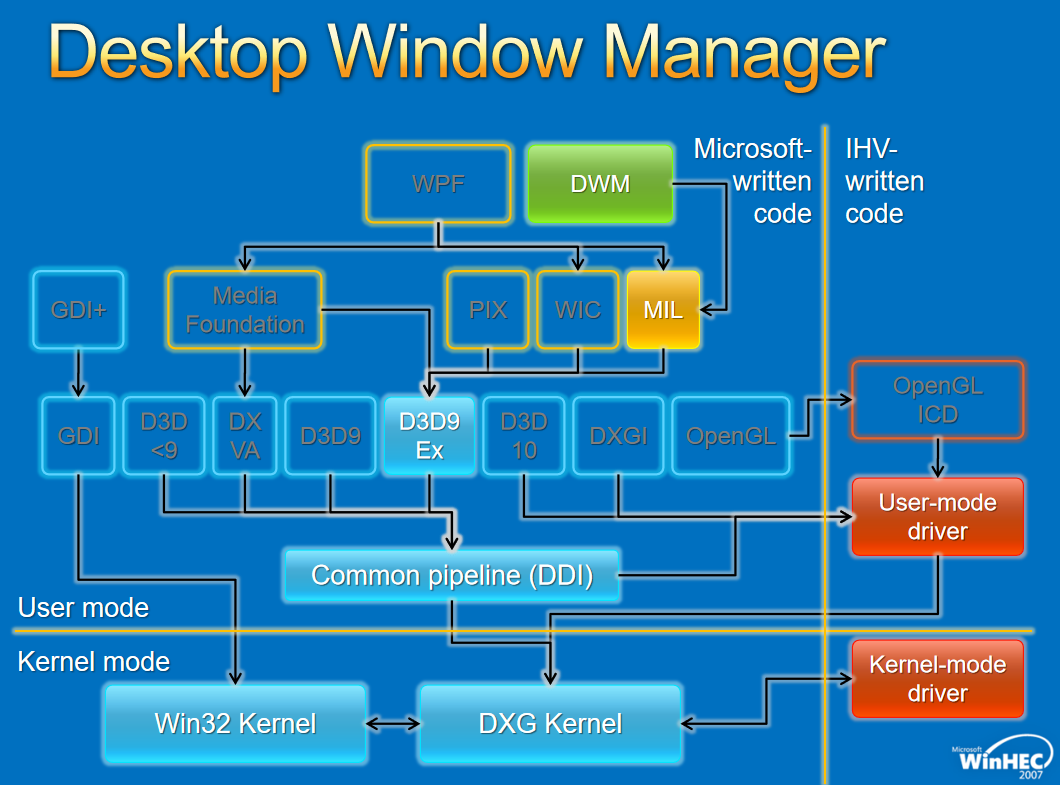
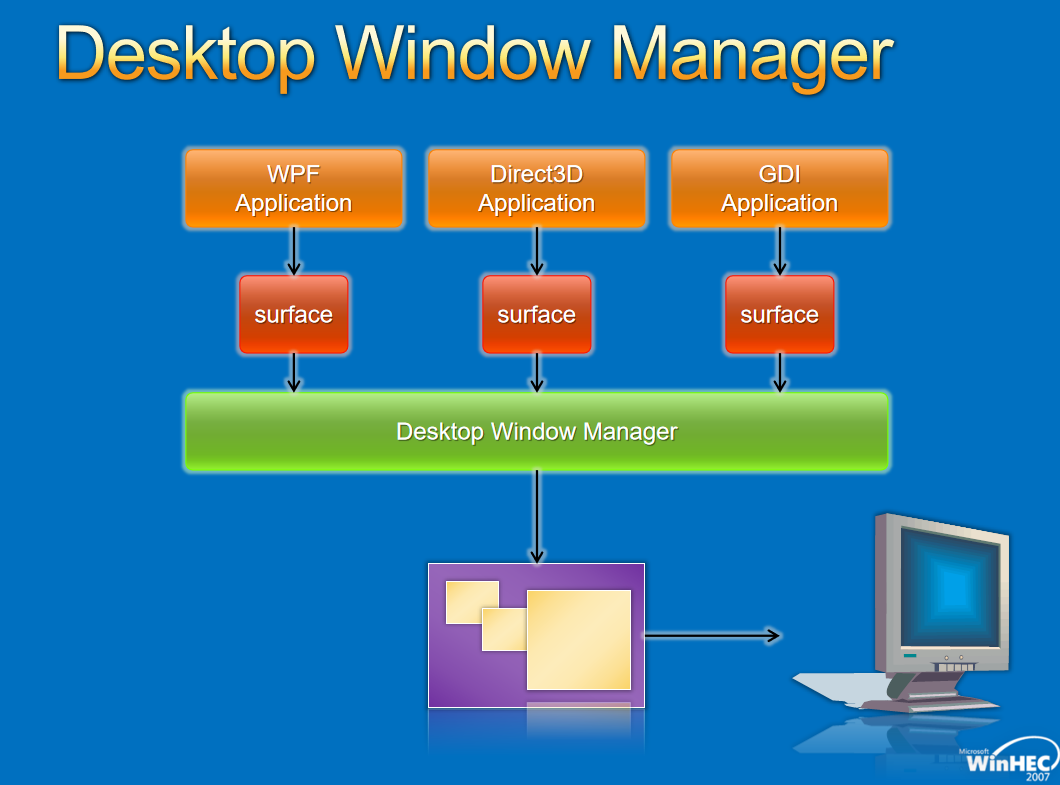
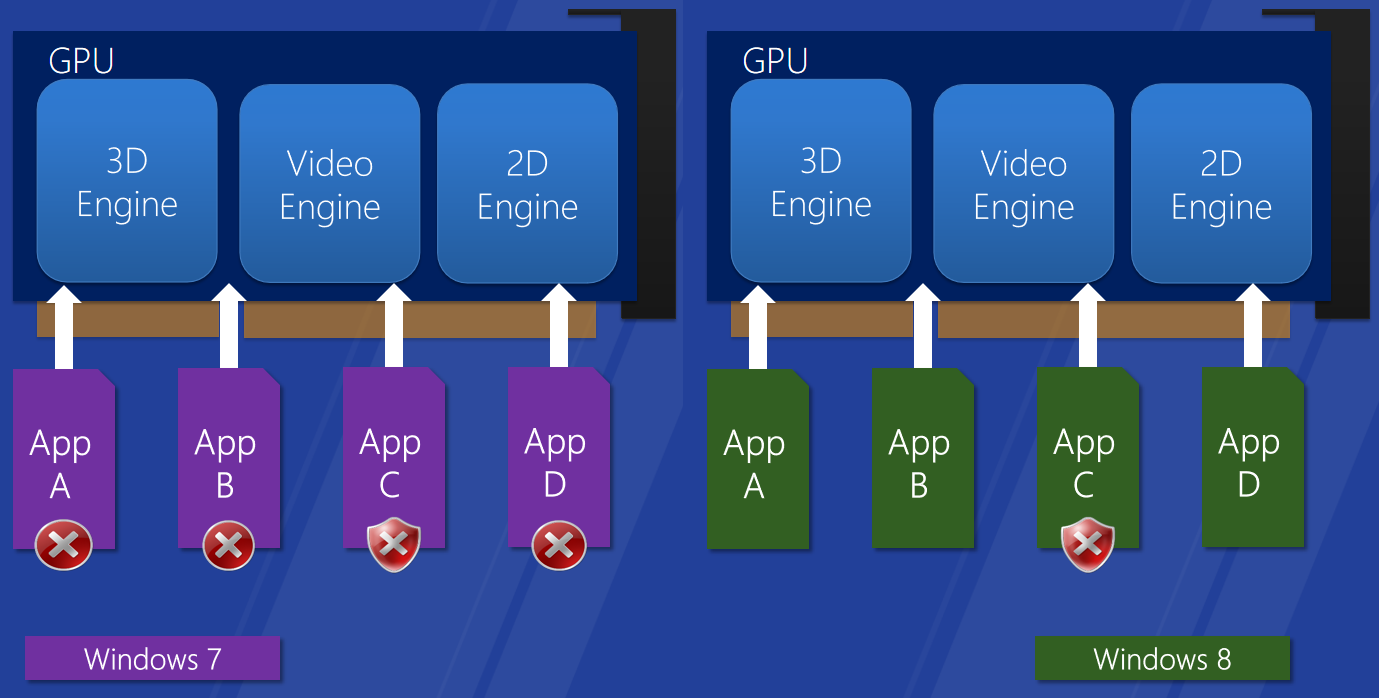
Windows图形驱动程序模型适用于所有Windows用户的单一图形驱动程序模型,图形驱动模型增强用户体验,创新实现了新的视觉和计算场景,性能和可靠性的改进使Windows能够跨一系列形状因素进行扩展。下面两图分布展示了Windows 7和8的对比:

WDDM 1.2功能集:
- 增强用户体验:立体3D体验,平滑屏幕旋转,无缝启动和恢复,显示“容器ID”支持。
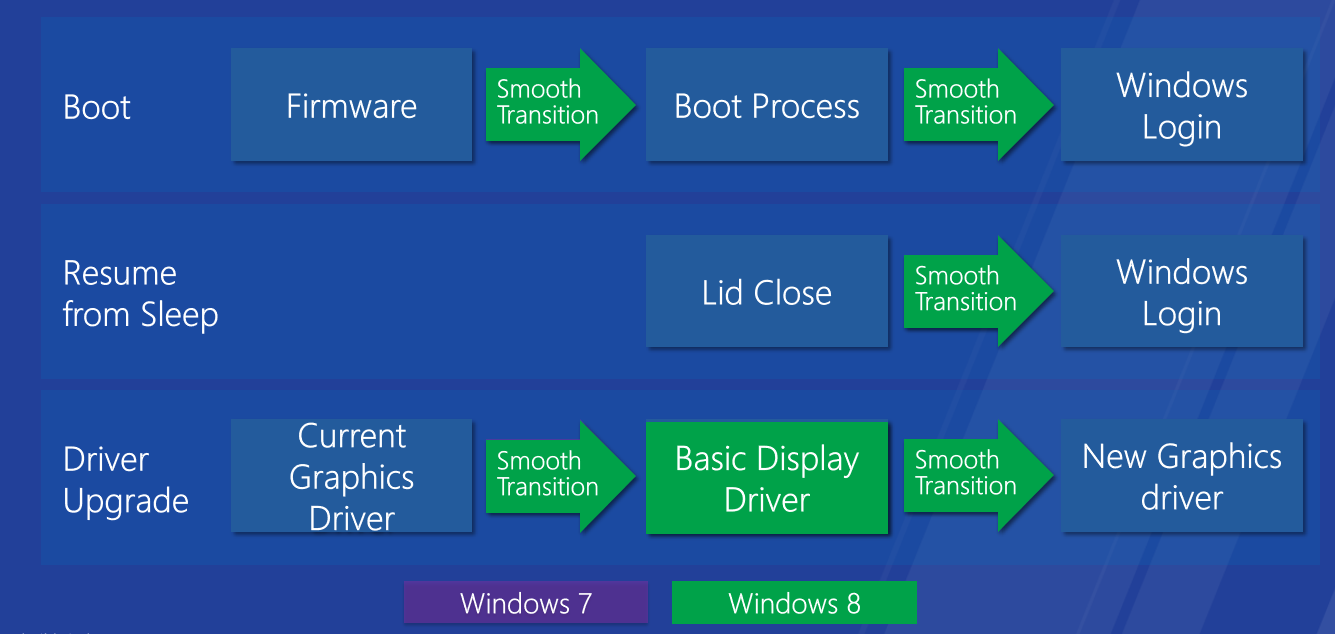
无缝引导、恢复和驱动程序升级。
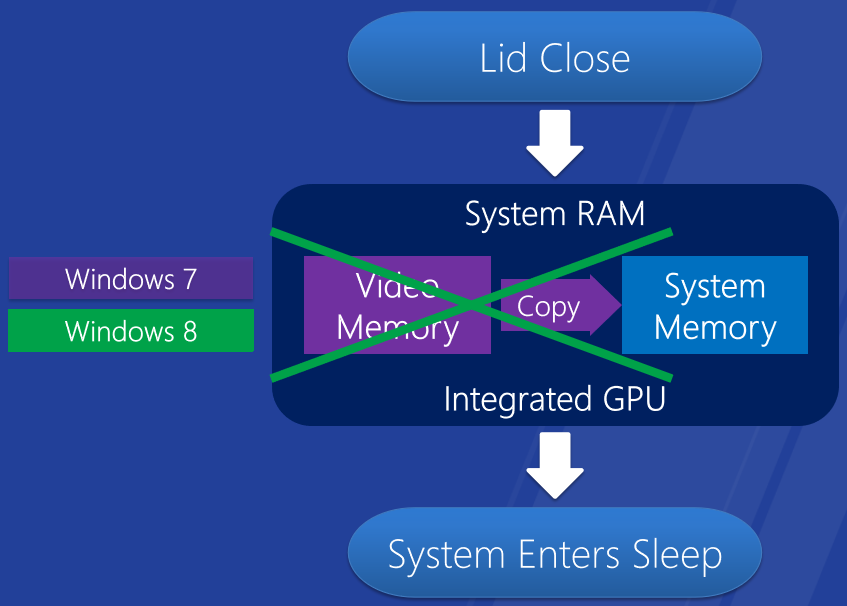
Windows 8上更快的睡眠和恢复-集成GPU。
- 更好的性能:GPU优先权,睡眠和恢复优化,视频内存提供和回收API、DDI,细粒度设备电源管理,SoC优化,基于分块的渲染优化。
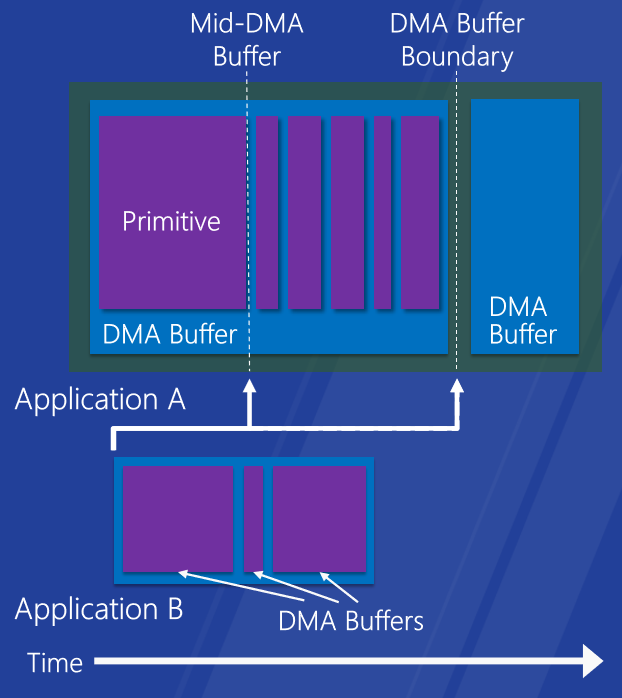
改进的桌面和触摸响应能力。快速流畅的地铁风格和触控体验,支持细粒度GPU抢占,抢占越精细,响应速度越快。
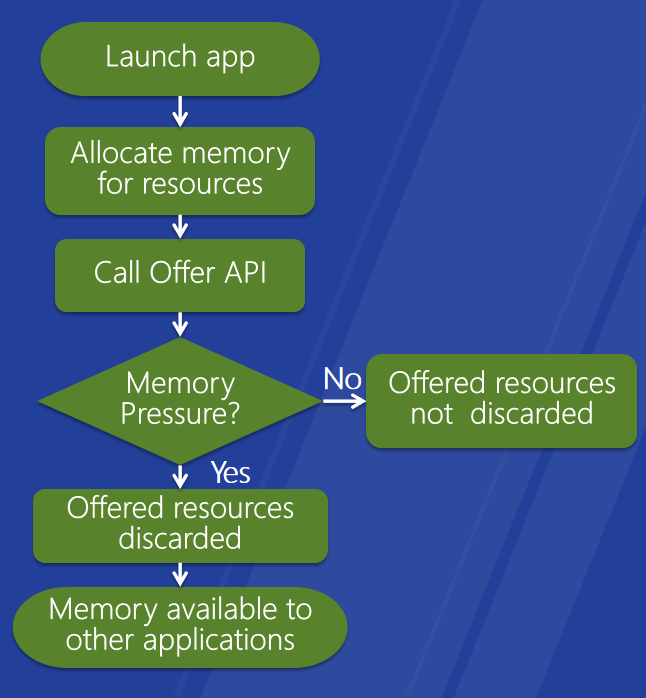
视频内存提供和回收API。改进的视频内存分配方案,优点:提高应用程序的视频内存可用性,新D3D API和WDDM DDI
:D3D应用程序、WDDM 1.2驱动程序。
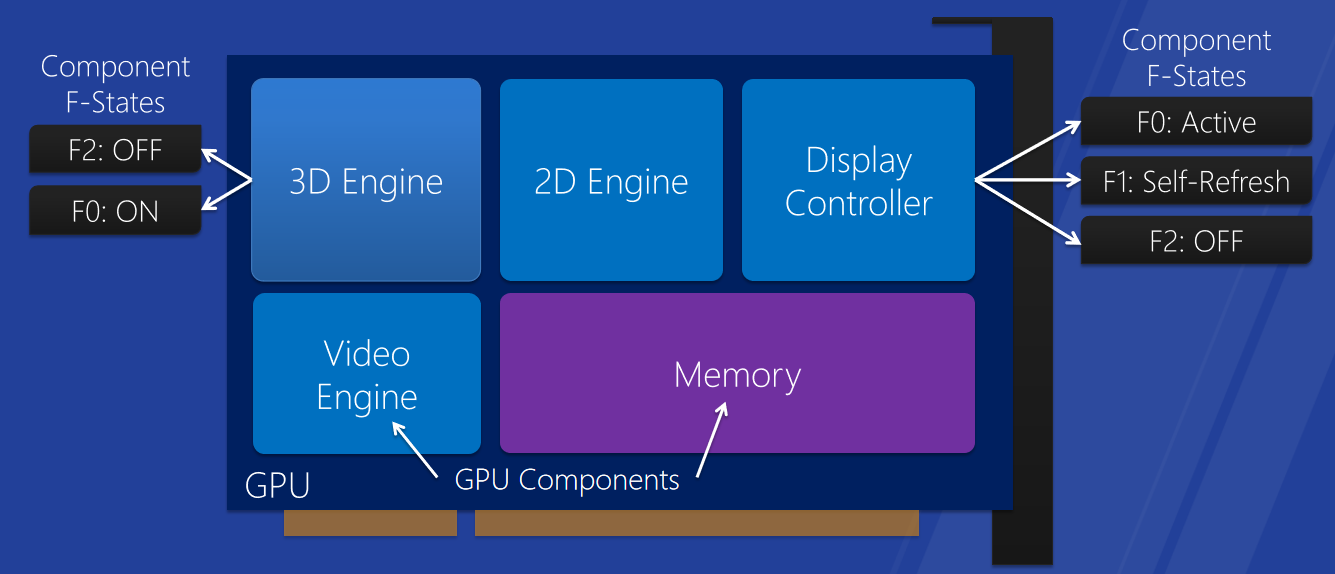
组件电源管理。
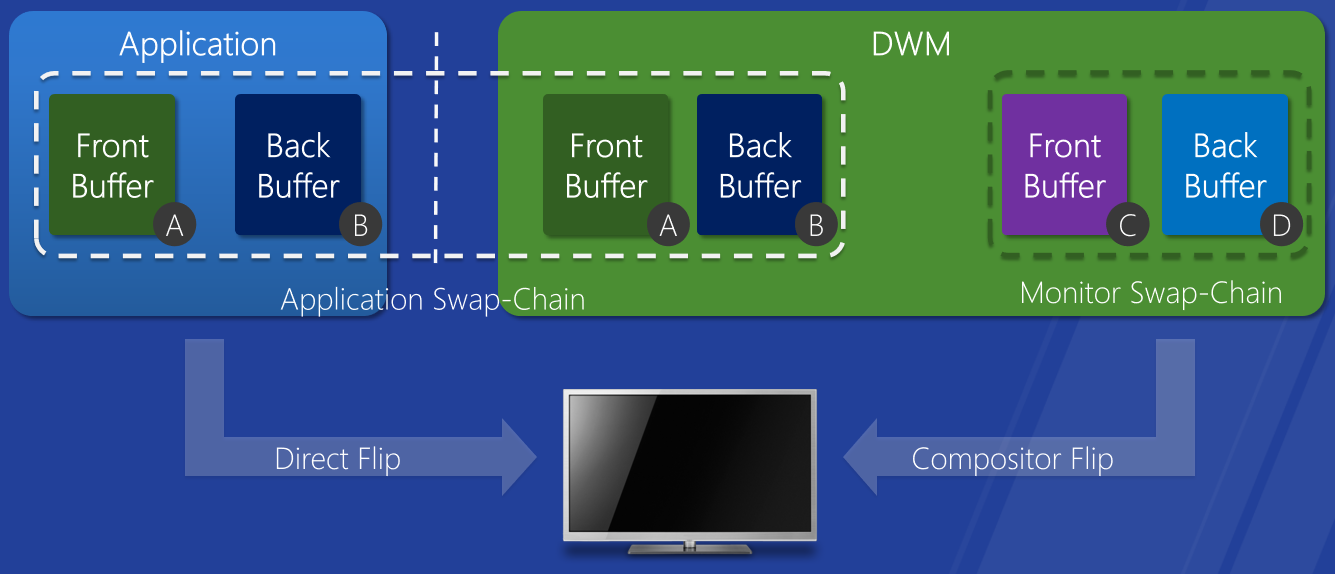
直接翻转。优化桌面组合以提高能效,在视频帧播放期间节省内存拷贝。
基于平铺的渲染优化。TBR GPU的日益普及,针对TBR优化的图形堆栈,节省电力,最小化内存带宽使用率,分块减少。
- 改善可靠性:改进的GPU容错能力,为开发人员和系统制造商提供更好的诊断,无需重新启动服务器的驱动程序升级。
改进的GPU容错能力。左:windows 7的超时检测和恢复改进,以前的操作系统,全局TDR,所有图形应用程序重置并重新启动。右:Windows 8的GPU挂起检测,抢占超时,能够执行长时间运行的任务,逐引擎的TDR。
总之,Windows 8的WDDM实现视觉上丰富、快速和流畅的最终用户体验,通过各种形式因素带来全新体验,优化性能,同时节省电源,利用性能工具调整图形驱动程序。
如今,WDDM的驱动架构如下:
以下是来自D3D的渲染操作流示例图:
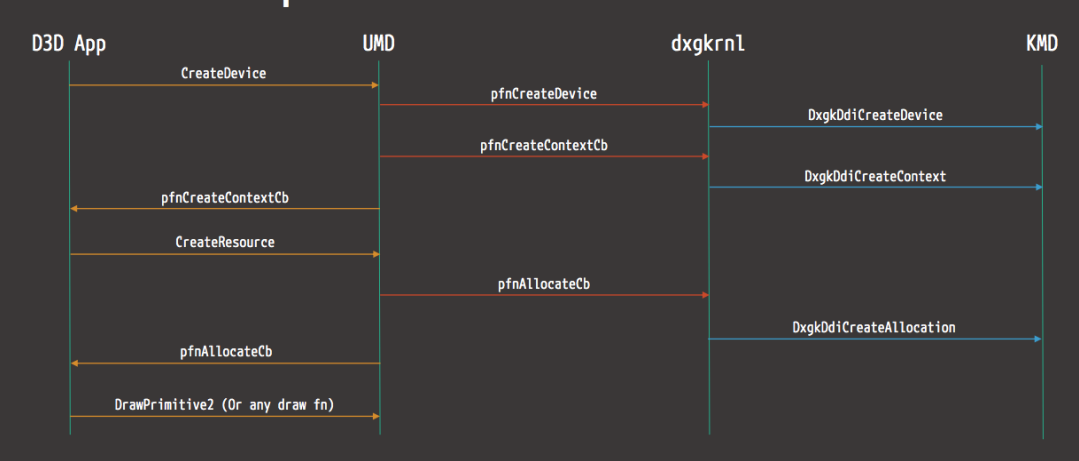
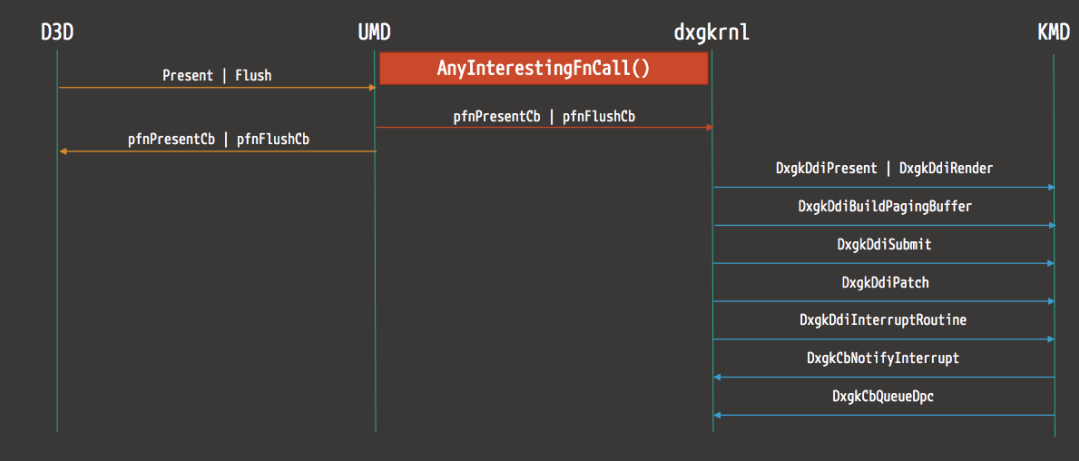
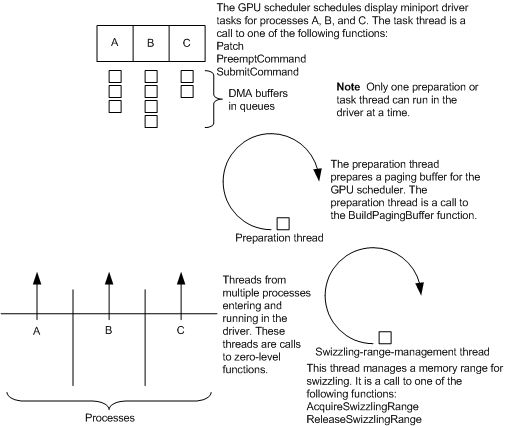
下图显示了WDDM中显示微型端口驱动程序的线程同步工作方式:
16.3.1.3 WDDM接口
kmd驱动是WDDM的内核模式的其中一个模块,它看起来如下所示:
NTSTATUS DriverEntry(IN PDRIVER\_OBJECT DriverObject, IN PUNICODE\_STRING RegistryPath)
{(...)DRIVER_INITIALIZATION_DATA DriverInitializationData;(...)DriverInitializationData.DxgkDdiEscape = DDIEscape;(...)Status = DxgkInitialize(DriverObject, RegistryPath, &DriverInitializationData);(...)
}WDDM kmd驱动程序在同步时,为这些回调提供了一个线程模型,该模型基本上由四个级别组成(其中每个回调属于其中一个级别):
3:只有一个线程可以进入,GPU必须处于空闲状态,没有正在处理的DMA缓冲区,视频内存被逐出到主机CPU内存。
2:与3相同,但视频内存移出除外。
1:调用被分类为类,每个类只允许一个线程同时调用回调。
0:完全可重入。
如果允许并发,则两个并发线程不能属于同一进程,在寻找潜在的竞争条件场景时,需要谨记这一点。
对于WDDM kmd驱动程序入口点,相当少的回调从userland获得了重要的输入:退出、渲染、分配、QueryAdapter,在找到它们之前,我们需要执行正确的驱动程序初始化,然后查看回调。涉及的结构体或接口:
// Escape
NTSTATUS D3DKMTEscape(\_In\_ const D3DKMT\_ESCAPE *pData );
typedef struct \_D3DKMT\_ESCAPE
{D3DKMT_HANDLE hAdapter;D3DKMT_HANDLE hDevice;D3DKMT_ESCAPETYPE Type;D3DDDI_ESCAPEFLAGS Flags;VOID *pPrivateDriverData;UINT PrivateDriverDataSize; D3DKMT_HANDLE hContext;
} D3DKMT_ESCAPE;// Render
NTSTATUS APIENTRY DxgkDdiRender(\_In\_ const HANDLE hContext, \_Inout\_ DXGKARG\_RENDER *pRender){ ... }
typedef struct \_DXGKARG\_RENDER
{const VOID CONST *pCommand;const UINT CommandLength;VOID *pDmaBuffer;UINT DmaSize;VOID *pDmaBufferPrivateData;UINT DmaBufferPrivateDataSize;DXGK_ALLOCATIONLIST *pAllocationList;UINT AllocationListSize;D3DDDI_PATCHLOCATIONLIST *pPatchLocationListIn;UINT PatchLocationListInSize;D3DDDI_PATCHLOCATIONLIST *pPatchLocationListOut;UINT PatchLocationListOutSize;UINT MultipassOffset;UINT DmaBufferSegmentId;PHYSICAL_ADDRESS DmaBufferPhysicalAddress;
} DXGKARG_RENDER;// Allocation
NTSTATUS APIENTRY DxgkDdiCreateAllocation(const HANDLE hAdapter, DXGKARG\_CREATEALLOCATION *pCreateAllocation){ ... }
typedef struct
\_DXGKARG\_CREATEALLOCATION
{const VOID *pPrivateDriverData;UINT PrivateDriverDataSize;UINT NumAllocations;DXGK_ALLOCATIONINFO *pAllocationInfo;HANDLE hResource;DXGK_CREATEALLOCATIONFLAGS Flags;
} DXGKARG_CREATEALLOCATION;// queryadapter
NTSTATUS APIENTRY DxgkDdiQueryAdapterInfo(HANDLE hAdapter, DXGKARG\_QUERYADAPTERINFO *pQueryAdapterInfo ){ ... }
typedef struct \_DXGKARG\_QUERYADAPTERINFO
{DXGK_QUERYADAPTERINFOTYPE Type; VOID *pInputData;UINT InputDataSize;VOID *pOutputData;UINT OutputDataSize;
} DXGKARG_QUERYADAPTERINFO;16.3.2 Linux图形驱动
Linux图形堆栈在过去几年中经历了许多演变。本节的目的是详细说明这段历史,并给出多年来所做更改背后的理由。今天,设计仍然深深植根于这段历史,本节将解释这段历史,以更好地推动Linux图形堆栈的当前设计。下面简述Linux图形驱动架构涉及的各个模块或概念:
-
PCI (Peripheral Component Interconnect):用户需要将图形卡插入主板上的PCI插槽。PCI规范不能免费向公众提供,此计算机总线的编程入口点是PCI配置空间,是通过x86体系结构I/O端口地址空间中的0xCF8和0xCFC I/O端口访问的。更具体地说,0xCF8是地址端口,0xCFC是数据端口。每个PCI实体(总线上的最小可寻址单元,如内存中的字节)有自己的配置空间。实体的配置空间中将有3种类型的资源:
-
输入/输出内存。这是实体解码的物理内存块。签出/proc/iomem的内容。
-
输入/输出端口。将由实体解码的I/O端口空间中的数据。签出/proc/ioports文件的内容。
-
IRQ(中断请求)。签出/proc/irq目录的内容。此类资源的配置使用2个系统完成:
-
PCI PNP(即插即用)已过时。
-
ACPI(高级配置和电源接口),目前实现的方法,是一项由OS(操作系统)内核完成的任务。
-
-
AGP (Accelerated Graphic Port)、PCI Express card:系统将看到插入AGP插槽或PCI Express插槽的图形卡,就像PCI设备一样。
-
ACPI (Advanced Configuration and Power Interface):如今的计算机通常具有ACPI功能,ACPI取代PCI PNP用于实体配置,并为该批次添加电源管理、多处理器sweet和其他内容。与PCI不同,ACPI规范是免费提供的。ACPI基于内存表:在计算机启动时,操作系统必须在物理内存中找到RSDP(根系统描述指针)。在x86体系结构上,需要在特定的物理内存区域中查找“RSD PTR”字符串。
-
XORG、DDX (Device Dependent X)和DIX (Device Independent X):XORG是X Window系统客户端libs和服务器的一部分、整个项目的参考实现,需要了解X Window核心协议。请记住,XORG有多个服务器,如DMX(分布式多头X)服务器、kdrive服务器或著名的XGL服务器。DIX是XORG的一部分,负责处理客户端、网络透明度和软件渲染。DDX是XORG处理硬件(以及在一定程度上处理操作系统)的一部分。
-
EXA:EXA是XORG加速的API,xfree86 DDX是唯一实现它的DDX。每次初始化屏幕时(例如,在新服务器生成开始时),都会初始化EXA加速(如果启用)。
-
DRI (Direct Rendering Infrastructure) 和DRM (Direct Rendering Manager):DRI和DRM是图形卡硬件编程的管道,主要由mesa(即“libre”opengl实现)使用,但由于对硬件的访问必须在所有图形卡硬件客户端之间同步,xfree86 DDX视频驱动模块必须处理它,因为它本身就是这样的客户端。然后,EXA当想要执行加速操作时,必须与硬件进行DRI对话。有一个用于xfree86 DDX代码的DRI xfree86 DDX模块,希望通过DRI方式进行硬件访问。此模块和相关的xfree86 DDX代码将使用DRM用户级接口库libdrm。理论上,未来的DRM演进将允许我们摆脱XORG服务器的PCI编程代码。
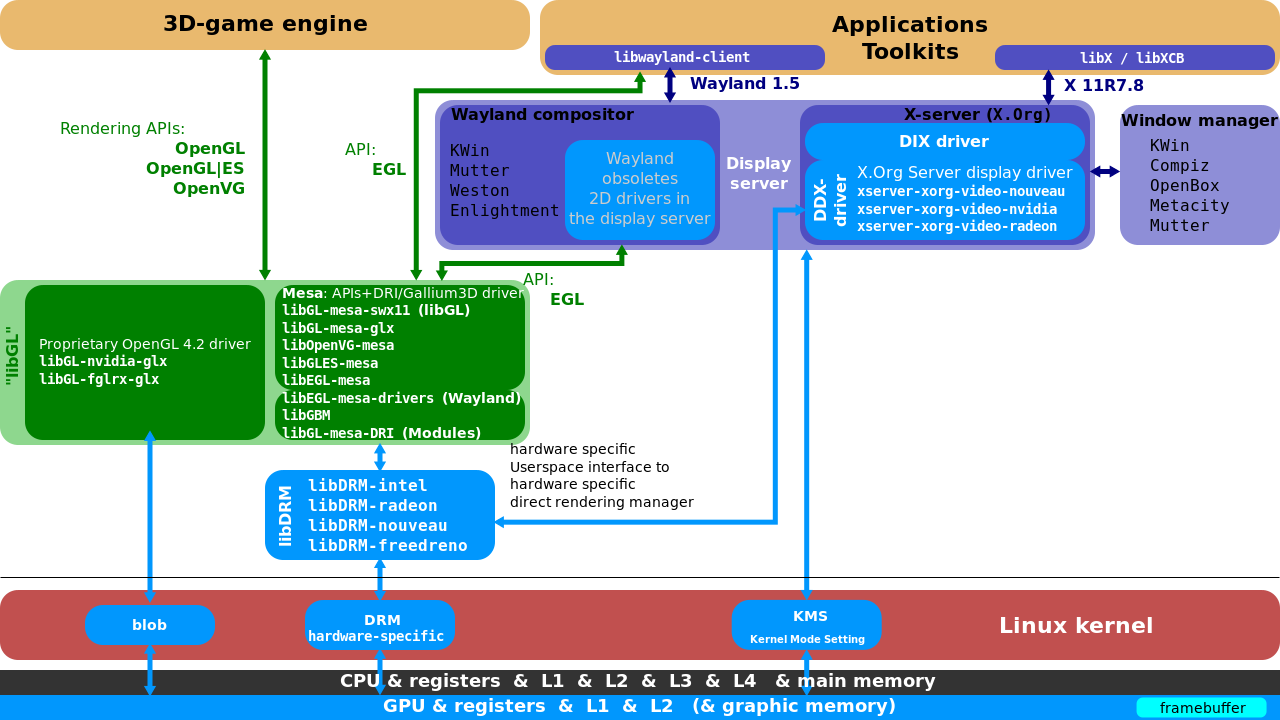
16.3.2.1 X11基础架构
X11架构图如下,包含DIX(设备无关X)、DDX(设备相关X)、Xlib、套接字、X协议、X扩展,shm->用于传输的共享内存,XCB->异步等。
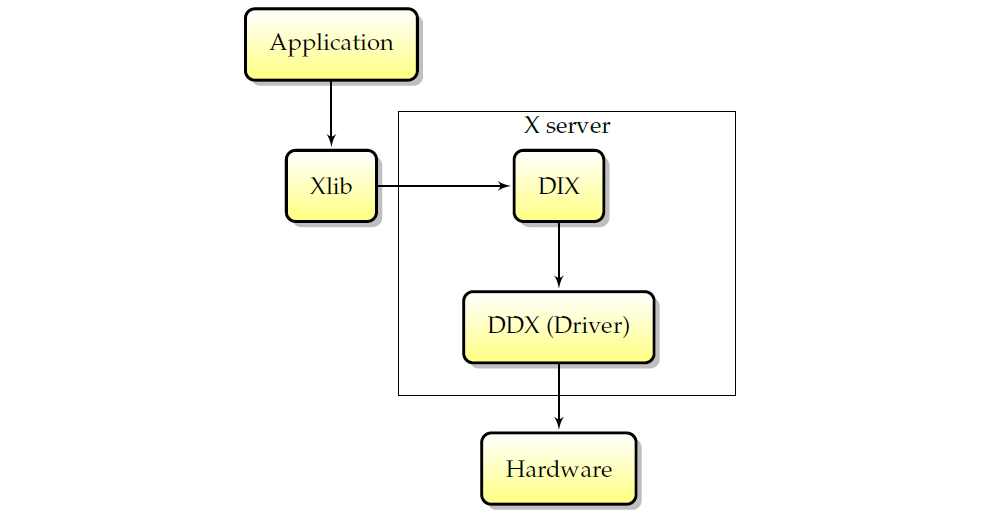
X服务的内部交互图如下:
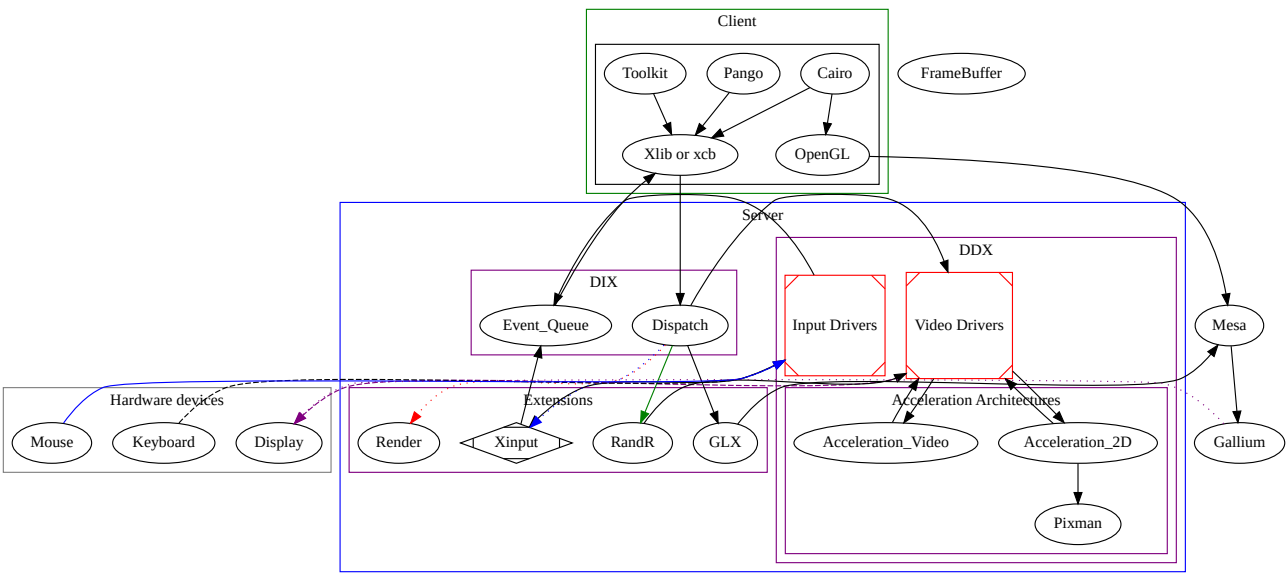
16.3.2.2 DRI/DRM基础架构
直接渲染管理器(DRM)是Linux内核的一个子系统,负责与现代视频卡的GPU接口。DRM公开了一个API,用户空间程序可以使用该API向GPU发送命令和数据,并执行诸如配置显示器的模式设置等操作。DRM最初是作为X Server直接渲染基础设施的核心空间组件开发的,但从那时起,它已被其他图形堆栈替代品(如Wayland)使用。
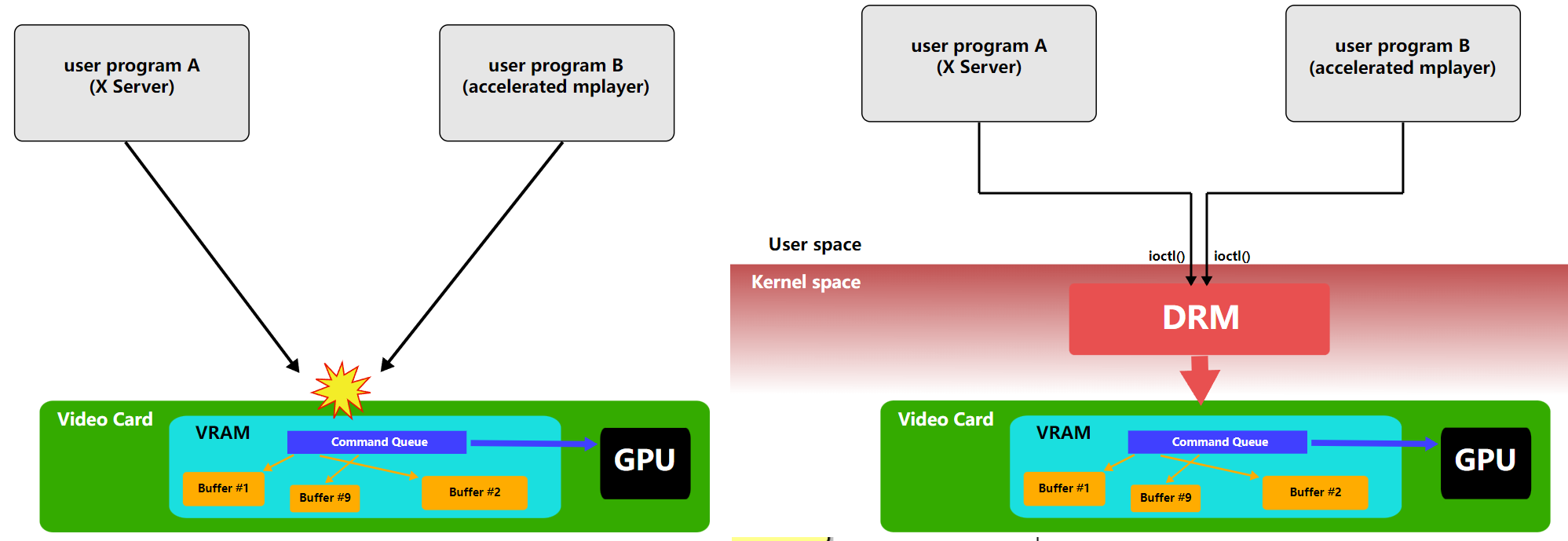
DRM允许多个程序同时访问3D视频卡,避免冲突。
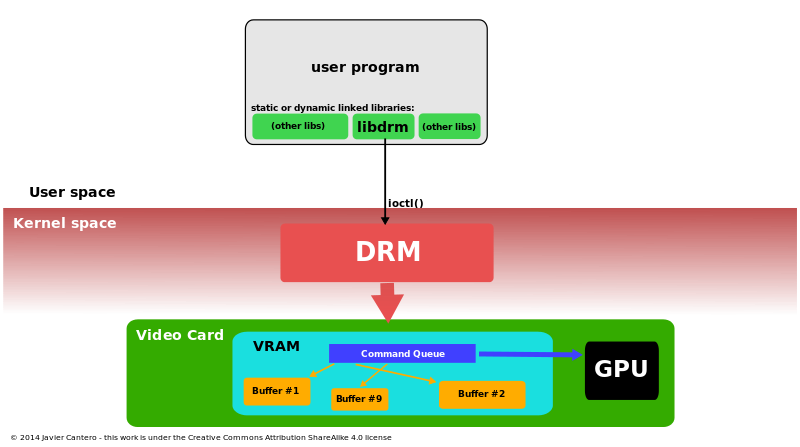
使用Linux内核的直接渲染管理器访问3D加速图形卡的过程。
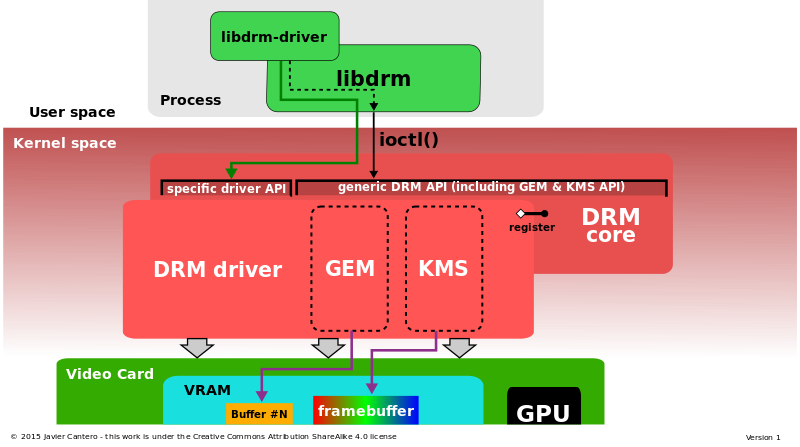
直接渲染管理器体系结构详细信息:DRM核心和DRM驱动程序(包括GEM和KMS),由libdrm接口。
最初(当Linux首次支持图形硬件加速时),只有一段代码可以直接访问图形卡:XFree86服务器。设计如下:通过以超级用户权限运行,XFree86服务器可以从用户空间访问卡,并且不需要内核支持来实现2D加速。这种设计的优点是简单,而且XFree86服务器可以很容易地从一个操作系统移植到另一个操作系统,因为它不需要内核组件。多年来,这是最广泛的X服务器设计(尽管也有明显的例外,比如XSun,它在内核中为一些驱动程序实现了modesetting)。
后来,第一个独立于硬件的3D加速设计Utah-GLX出现在Linux上,Utah-GLX基本上包含一个实现GLX的附加用户空间3D驱动程序,并以类似于2D驱动程序的方式从用户空间直接访问图形硬件。在3D硬件与2D明显分离的时代(因为2D和3D使用的功能完全不同,或者因为3D卡是一个完全独立的卡,即3Dfx),拥有一个完全独立的驱动程序是有意义的。此外,从用户空间直接访问硬件是在Linux下实现3D加速的最简单方法和最短途径。
与此同时,帧缓冲区驱动程序越来越广泛,它代表了可以同时直接访问图形硬件的另一个组件。为了避免帧缓冲区和XFree86驱动程序之间的潜在冲突,决定在VT交换机上,内核将向X服务器发出信号,告诉其保存图形硬件状态。要求每个驱动程序在VT交换机上保存其完整的GPU状态使驱动程序更加脆弱,对于突然面临不同驱动程序之间容易出现错误的交互的开发人员来说,生活变得更加困难。请记住,XFree86驱动程序至少有两种可能(xf86视频vesa和本机XFree86驱动程序)和两种内核帧缓冲区驱动程序(vesafb和本机帧缓冲区驱动程序),因此每个GPU至少有四种共存驱动程序的组合。
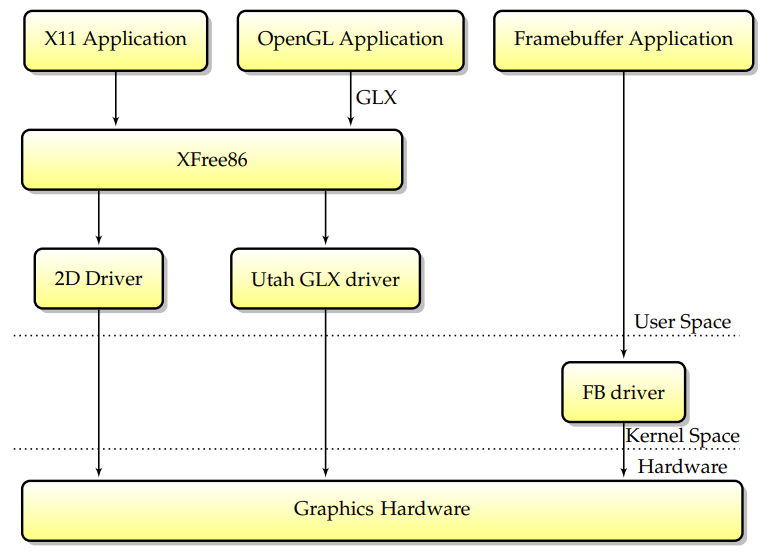
显然,这种模式有缺点。首先,它要求允许未经授权的用户空间应用程序访问3D图形硬件。其次,如上图所示,所有GL加速都必须通过X协议间接进行,将显著降低其速度,尤其是对于纹理上传等数据密集型功能。由于人们越来越担心Linux的安全性和性能缺陷,需要另一种模型。
为了解决Utah-GLX模型的可靠性和安全性问题,将DRI模型放在一起;XFree86及其后续版本X.Org都使用了它。该模型依赖于一个额外的内核组件,其职责是从安全角度检查3D命令流的正确性。现在的主要变化是,没有权限的OpenGL应用程序将向内核提交命令缓冲区,内核将检查它们的安全性,然后将它们传递给硬件执行,而不是直接访问卡。这种模型的优点是不再需要信任用户空间,但XFree86的2D命令流仍然没有通过DRM,因此X服务器仍然需要超级用户权限才能直接映射GPU寄存器。
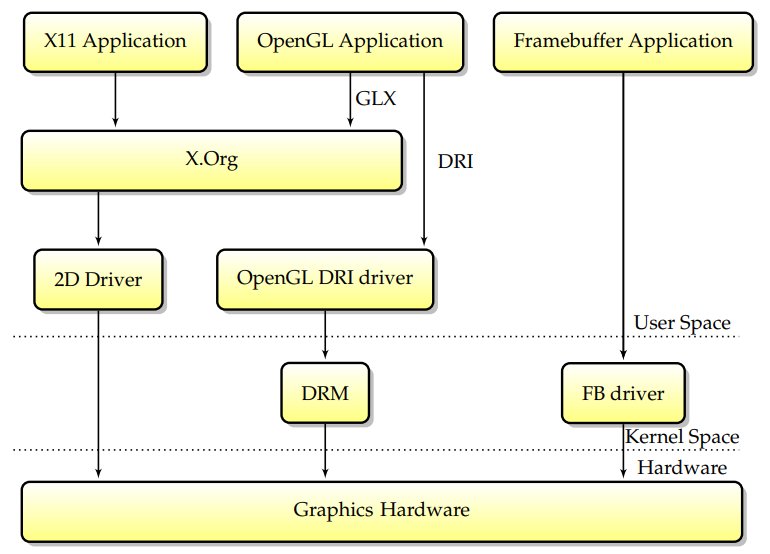
当前堆栈是从一组新的需求演变而来的。首先,要求X服务器具有超级用户权限总是会带来严重的安全隐患。其次,在以前的设计中,不同的驱动程序接触单个硬件,通常会导致问题。为了解决这个问题,关键有两个方面:第一,将内核帧缓冲区功能合并到DRM模块中,第二,让X.Org通过DRM模块访问图形卡并无权限运行。这种模型被称为内核模式设置(KMS),在这个模型中,DRM模块现在负责作为帧缓冲区驱动程序和X.Org提供模式设置服务。
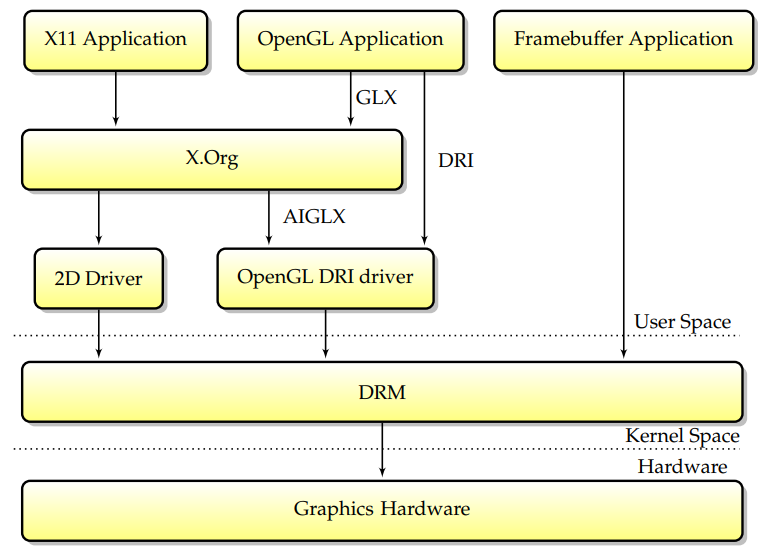
总之,应用程序通过封装绘图调用的特定库与X.Org通信,当前的DRI设计随着时间的推移在许多重要步骤中不断发展,在现代堆栈中,所有图形硬件活动都由内核模块DRM控制。Linux总的模块交互图如下:
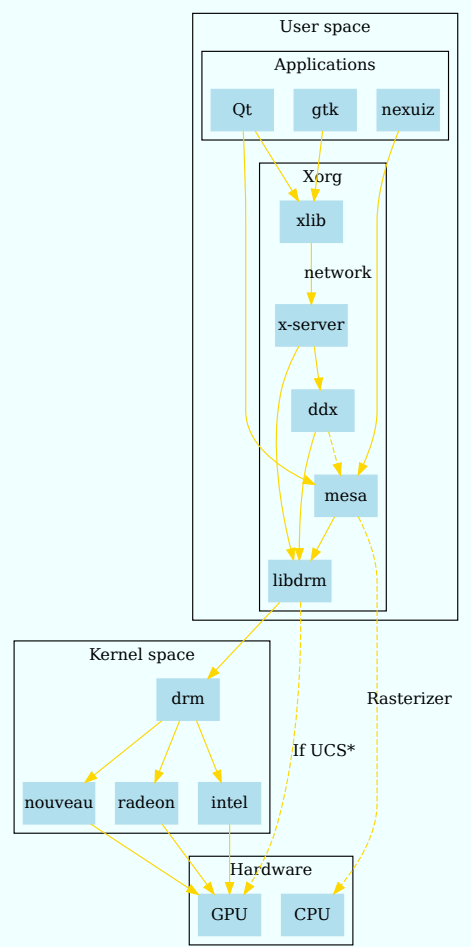
更详细的交互和分层架构如下:
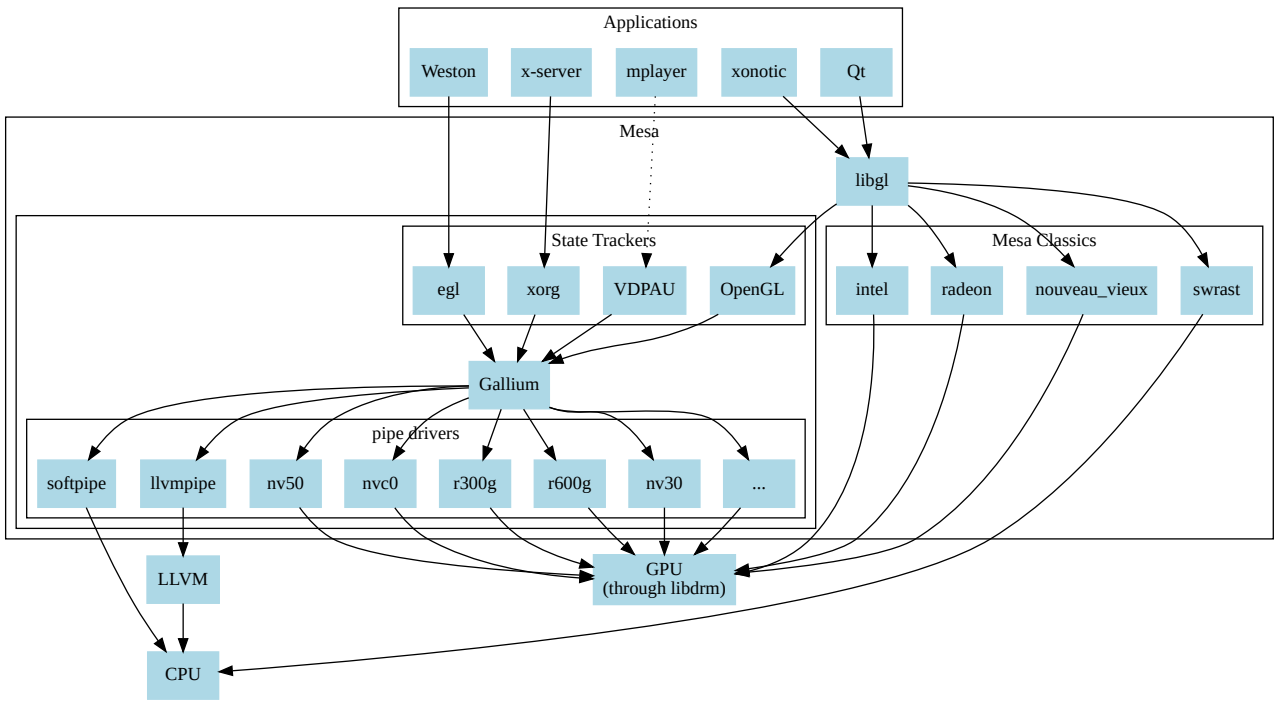
16.3.2.3 Framebuffer驱动
在核心,帧缓冲区驱动程序实现以下功能:
- 模式设置。模式设置包括配置视频模式以在屏幕上获取图片,包括选择视频分辨率和刷新率。
- 可选2d加速。帧缓冲区驱动程序可以提供用于加速linux控制台的基本2D加速,包括视频内存中的拷贝和实体填充。加速有时通过挂钩提供给用户空间(然后用户空间必须对特定于卡的MMIO寄存器进行编程,需要root权限)。
通过只实现这两部分,帧缓冲区驱动程序仍然是最简单、最合适的linux图形驱动程序形式。帧缓冲区驱动程序并不总是依赖于特定的卡型号(如nvidia或ATI)。存在vesa、EFI或Openfirmware之上的驱动程序,这些驱动程序不是直接访问图形硬件,而是调用固件功能来实现模式设置和2D加速。
帧缓冲区驱动程序是linux图形驱动程序的最简单形式。只需很少的实现工作,帧缓冲区驱动程序提供了较低的内存占用,因此对嵌入式设备很有用。实现加速是可选的,因为存在软件回退功能。
16.3.2.4 直接渲染管理器
在复杂的世界中,使用内核模块是一项要求。此内核模块称为直接渲染管理器(DRM),可用于多种用途:
- 将图形卡的关键初始化放在内核中,例如上载固件或设置DMA区域。
- 在多个用户空间组件之间共享渲染硬件,并处理访问。
- 通过防止应用程序对任意内存区域执行DMA,以及更一般地防止以任何可能导致安全漏洞的方式对卡进行编程来加强安全性。
- 通过向用户空间提供视频内存分配功能来管理卡的内存。
- DRM得到了改进,以实现模式设置,简化了以前DRM和帧缓冲区驱动程序争用同一GPU的情况。相反,将删除帧缓冲区驱动程序,并在DRM中实现帧缓冲区支持。
**内核模块(DRM)**是全局DRI/DRM用户空间/内核方案(下图包含libdrm-DRM-入口点-多个用户空间应用程序):
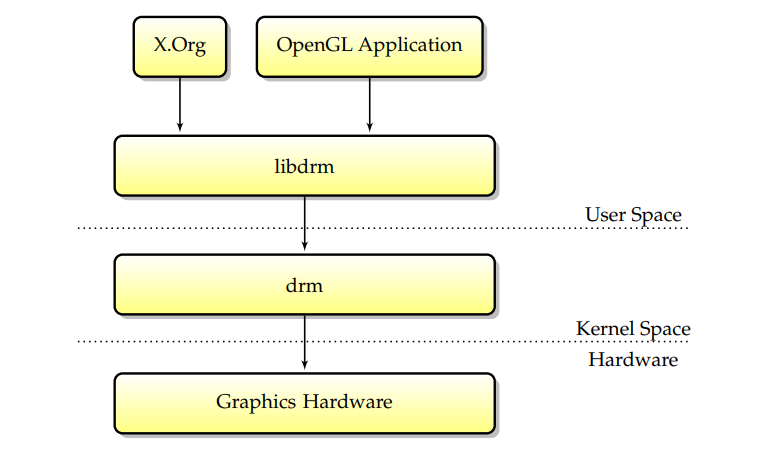
当设计一个Linux图形驱动程序以实现不仅仅是简单的帧缓冲区支持时,首先要做的是一个DRM组件,应该派生出一种既高效又能加强安全性的设计。DRI/DRM方案可以以不同的方式实现,并且接口确实完全是特定于卡的。
DRM批量缓冲区提交模型:DRM设计的核心是DRM_GEM_EXECBUFFER ioctl,允许用户空间应用程序向内核提交一个批处理缓冲区,然后内核将其放在GPU上。此ioctl允许许多事情,如共享硬件、管理内存和强制执行内存保护。
DRM的职责之一是在多个用户空间进程之间复用GPU本身。如果GPU保持图形状态,那么当多个应用程序使用同一GPU时,就会出现一个问题:如果什么都不做,应用程序就会破坏彼此的状态。根据当前的硬件,主要有两种情况:
1、当GPU具有硬件状态跟踪功能时,硬件共享会更简单,因为每个应用程序都可以发送到单独的上下文,GPU会跟踪每个应用程序本身的状态。此种方法就是新驱动的工作方式。
2、当GPU没有多个硬件上下文时,复用硬件的常见方法是在每个批处理缓冲区的请求时重新提交状态,是intel和radeon驱动程序多路复用GPU的方式。请注意,重新提交状态的职责完全依赖于用户空间。如果用户空间没有在每个批处理缓冲区开始时重新提交状态,那么来自其他DRM进程的状态将泄漏到它身上。DRM还防止同时访问同一硬件。
内核能够移动内存区域来处理内存压力大的情况。根据硬件的不同,有两种实现方法:
1、如果硬件具有完整的内存保护和虚拟化,则可以在分配内存资源时将其分页到GPU中,并隔离每个进程。因此,支持GPU内存的内存保护不需要太多。
2、当硬件没有内存保护时,仍然可以完全在内核中实现,用户空间完全不受其影响。为了允许重新定位对用户空间进程起作用,而用户空间进程在其他方面并不知道它们,命令提交ioctl将通过将所有硬件偏移量替换到当前位置来重写内核中的命令缓冲区。由于内核知道所有内存缓冲区的当前位置,使得前述方法成为可能。为了防止访问任意GPU内存,命令提交ioctl还可以检查这些偏移量中的每一个是否为调用进程所有,如果不是,则拒绝批处理缓冲区。这样,当硬件不提供该功能时,就可以实现内存保护。
DRM管理现代linux图形堆栈中的所有图形活动,是堆栈中唯一受信任的部分,负责安全,因此,不应信任其他组件。它提供基本的图形功能:模式设置、帧缓冲区驱动程序、内存管理。
16.3.2.5 Mesa
Mesa也称为Mesa3D和Mesa3D图形库,是OpenGL、Vulkan和其他图形API规范的开源软件实现。Mesa将这些规范转换为特定于供应商的图形硬件驱动程序。其最重要的用户是两个图形驱动程序,它们主要由Intel和AMD为各自的硬件开发和资助(AMD在不推荐的AMD Catalyst上推广其Mesa驱动程序Radeon和RadeonSI,Intel只支持Mesa驱动程序)。专有图形驱动程序(如Nvidia GeForce驱动程序和Catalyst)取代了所有Mesa,提供了自己的图形API实现,开发名为Nouveau的Mesa Nvidia驱动程序的开源工作主要由社区开发。
除了游戏等3D应用程序外,现代显示服务(X.org的Glamer或Wayland的Weston)也使用OpenGL/EGL;因此,所有图形通常都要使用Mesa。Mesa由freedesktop托管,该项目于1993年8月由布莱恩·保罗发起。Mesa随后被广泛采用,现在包含了世界各地各种个人和公司的众多贡献,包括管理OpenGL规范的Khronos集团图形硬件制造商的贡献。
Mesa有两个主要用途:
1、Mesa是OpenGL的软件实现,被认为是参考实现,在检查一致性时很有用,因为官方的OpenGL一致性测试并不公开。
2、Mesa为linux下的开源图形驱动程序提供了OpenGL入口点。
Mesa是Linux下的参考OpenGL实现,所有开源图形驱动程序都使用Mesa for 3D。
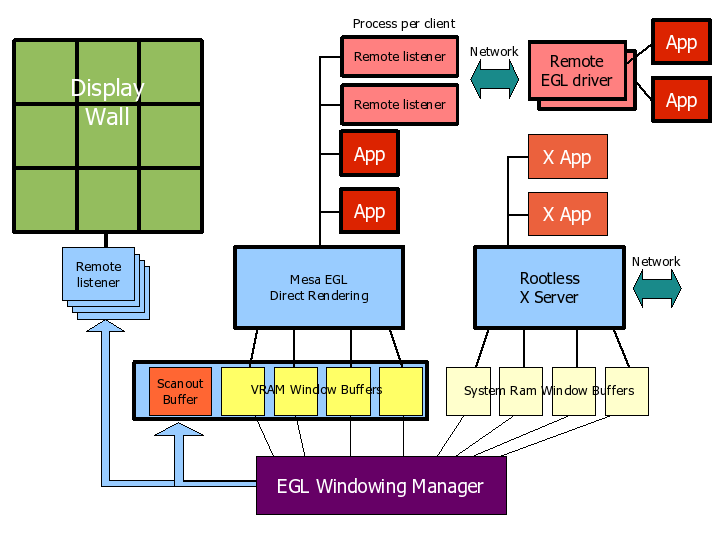
视频游戏通过OpenGL将渲染计算实时外包给GPU,着色器使用OpenGL着色语言或SPIR-V编写,并在CPU上编译,编译后的程序在GPU上执行。(下图)
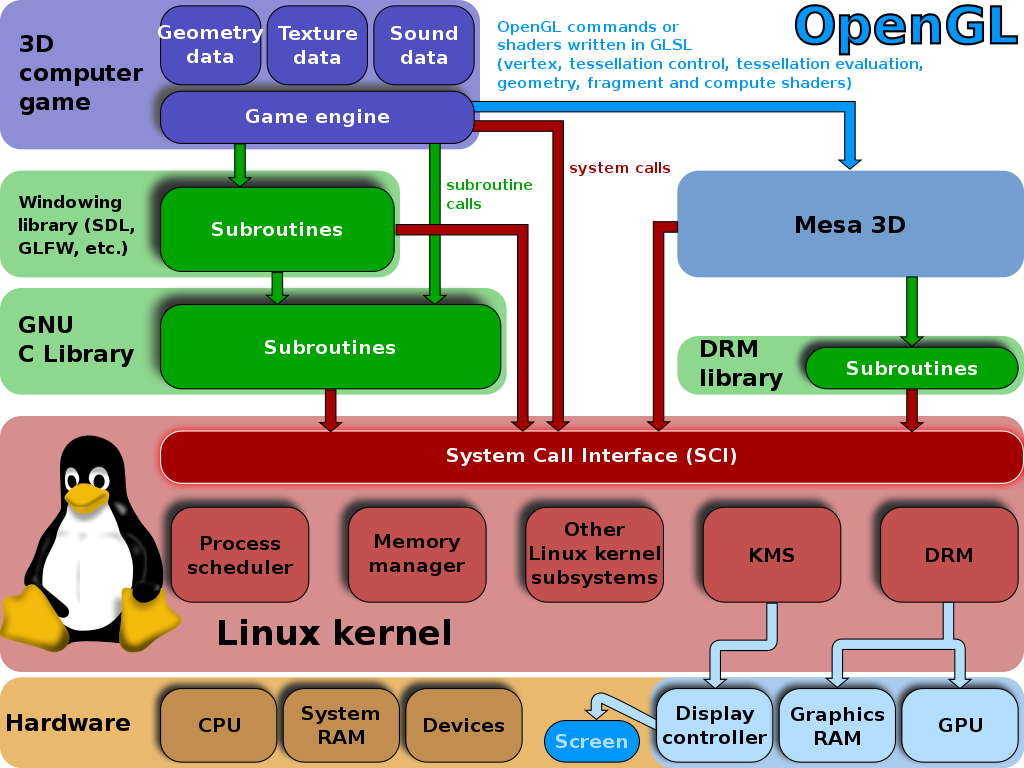
Linux图形堆栈见下图:DRM&libDRM,Mesa 3D,其中显示服务属于窗口系统,只用于游戏等上层应用。
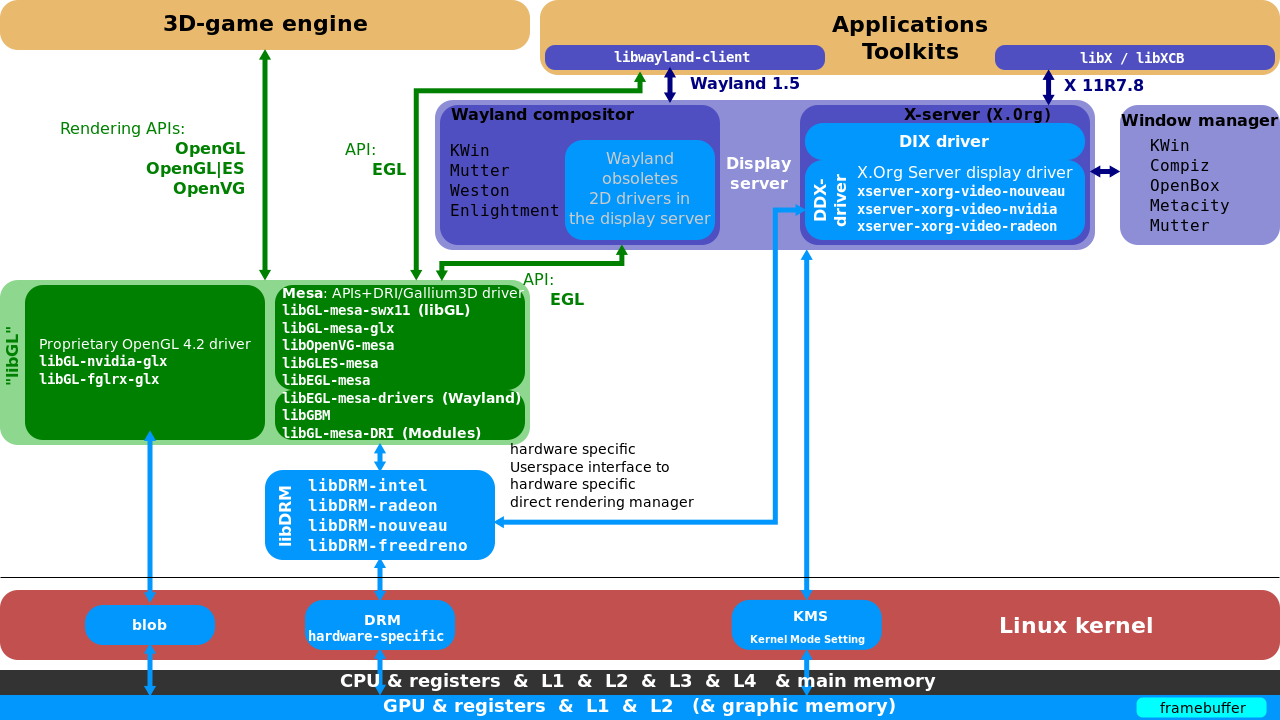
Wayland的免费实现依赖于EGL的Mesa实现,名为libwayland EGL的特殊库是为支持对帧缓冲区的访问而编写的,EGL 1.5版本已过时。在GDC 2014上,AMD正在探索使用DRM而不是其内核内blob的战略变化。
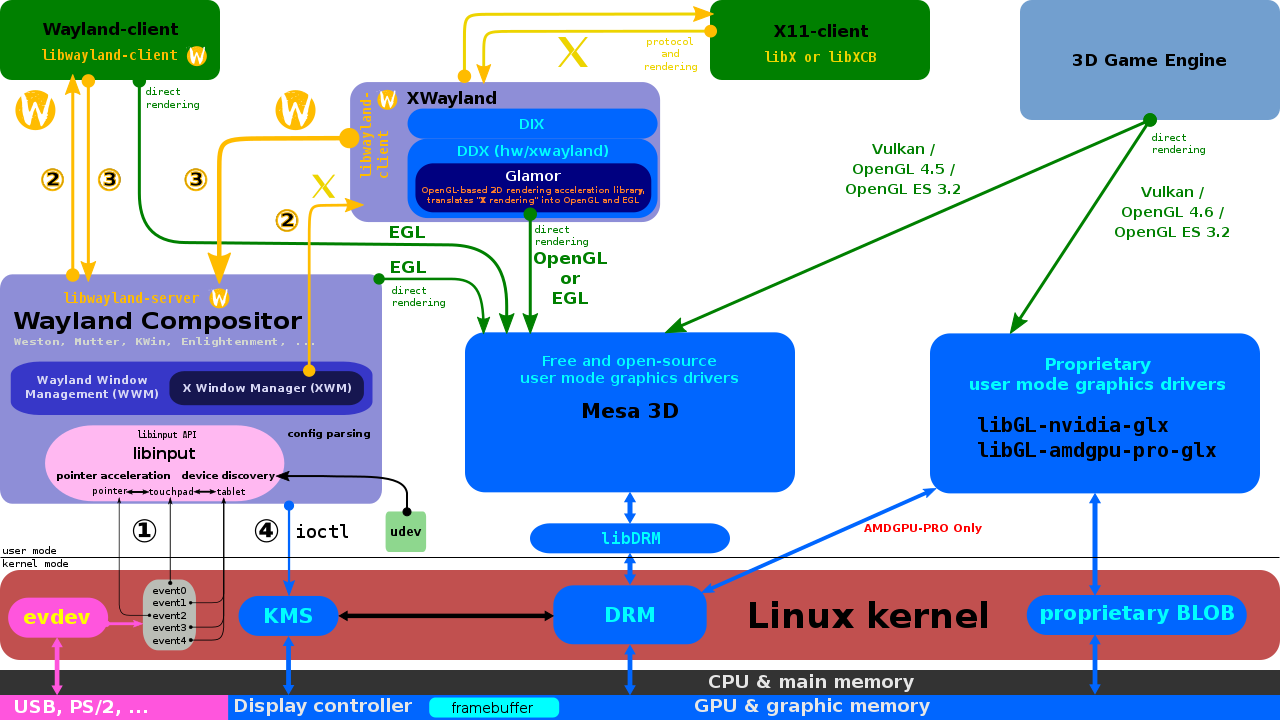
16.3.2.6 Wayland
Wayland旨在更简单地替代X,更易于开发和维护。Wayland是一种用于合成器与其客户机对话的协议,也是该协议的C库实现。合成器可以是在Linux内核模式设置和evdev输入设备上运行的独立显示服务器、X应用程序或wayland客户端本身。客户端可以是传统应用程序、X服务器(无根或全屏)或其他显示服务器。Wayland项目的一部分也是Wayland合成器的Weston参考实现,Weston可以作为X客户端或Linux KMS运行,Weston合成器是一种最小且快速的合成器,适用于许多嵌入式和移动用例。
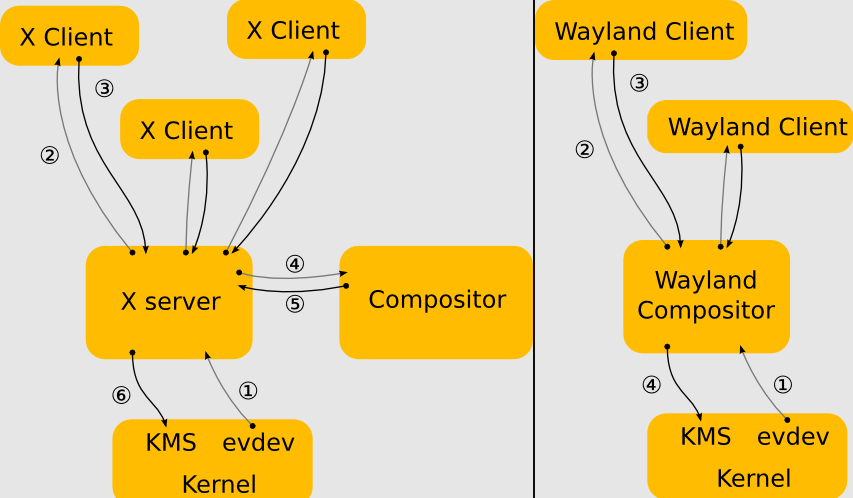
使用X(左)和Wayland(右)的驱动架构对比。
16.3.3 调度机制
16.3.3.1 OS And GPU abstraction
早在10年前,微软联合大学的科研人员在Operating Systems must support GPU abstractions中指出,缺乏对GPU抽象的操作系统支持从根本上限制了GPU在许多应用领域的可用性。操作系统为最常见的资源(如CPU、输入设备和文件系统)提供抽象。相比之下,操作系统目前将GPU隐藏在笨拙的ioctl 接口后面,将抽象的负担转移到用户库和运行时上。因此,操作系统无法为GPU提供系统范围的保证,例如公平性和隔离性,开发人员在构建集成GPU和其他操作系统管理资源的系统时,必须牺牲模块化和性能。他们提出了新的内核抽象,以支持GPU和其他加速器设备作为一流的计算资源。
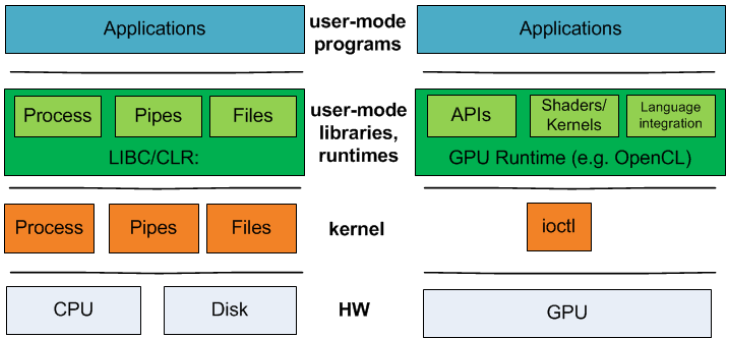
CPU与GPU程序的技术堆栈。对于GPU程序,CPU程序的操作系统级别和用户模式运行时抽象之间没有1对1的对应关系。
不存在对GPU抽象的直接操作系统支持,因此利用GPU完成此工作负载必然需要一个用户级GPU编程框架和运行时,如CUDA或OpenCL。在这些框架中实现xform和detect会大大提高隔离运行的组件的速度,但组合系统(catusb | xform | detect | hidinput)会因跨用户内核边界和跨PCI-e总线的硬件的过度数据移动而受损。
现代操作系统目前无法保证GPU的公平性和性能隔离,主要是因为GPU不是作为共享计算资源(如CPU)管理的,而是作为I/O设备管理的,其接口仅限于一小部分已知操作(如init_module、read、write、ioctl)。当操作系统需要使用GPU来实现其功能时,这种设计就成为了一个严重的限制。实际上,NVIDIA GPU Direct实现了这样一个功能,但需要在所涉及的任何I/O设备的驱动程序中提供专门的支持。自己计算(例如,Windows 7与Aero用户界面一样)。在当前的制度下,时间分割和超时可以确保屏幕刷新率保持不变,但在执行公平性和系统负载平衡时,操作系统在很大程度上取决于GPU驱动程序。
新的体系结构可能会改变跨GPU和CPU内存域管理数据的相对难度,但软件将继续发挥重要作用,在可预见的未来,优化数据移动仍然很重要。AMD的Fusion将CPU和GPU集成到一个芯片上,然而,它将CPU和GPU内存分区。Intel的Sandy Bridge(另一种CPU/GPU组合)表明,未来几年将出现各种形式的集成CPU/GPU硬件上市。新的混合系统,例如NVIDIA Optimus,在芯片和高性能离散图形卡上都具有能效,即使使用组合的CPU/GPU芯片,数据管理也更加明确。但即使是一个完全集成的虚拟内存系统,也需要系统支持来最小化数据拷贝。
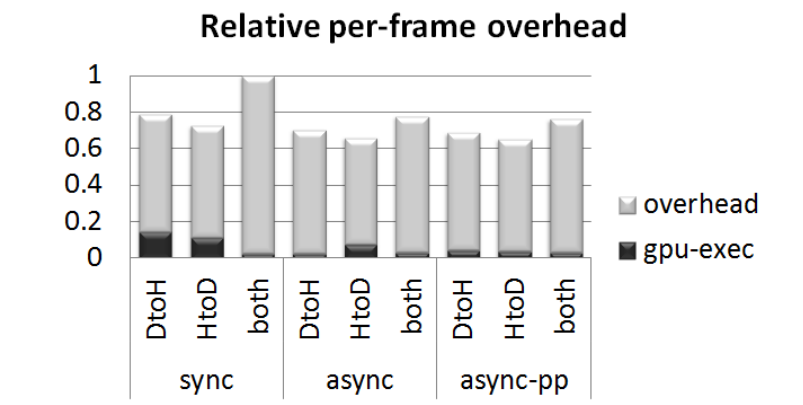
原型系统中基于CUDA的xform程序实现的相对GPU执行时间和开销(越低越好)。sync使用CPU和GPU之间的缓冲区同步通信,async使用异步通信,async pp同时使用异步和乒乓缓冲区来进一步隐藏延迟。条形图分为在GPU上执行的时间和系统开销。DtoH表示设备和主机之间在每个帧上进行通信的实现,反之亦然,并且两者都表示每个帧的双向通信。报告的执行时间与同步、双向情况(同步两者)相关。
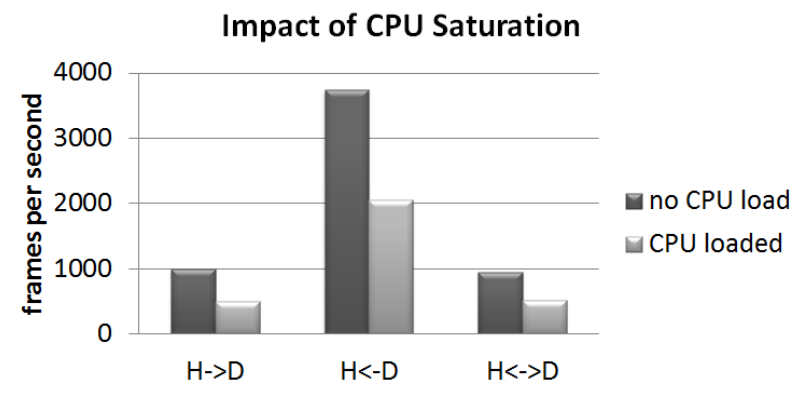
CPU密集工作对GPU密集任务的影响。当系统中存在并行GPU和CPU工作时,当前的操作系统抽象限制了操作系统提供性能隔离的能力。H→D是一个CUDA工作负载,它具有从主机到GPU设备的通信,而H←D具有从GPU到主机的通信,H↔D具有双向通信。
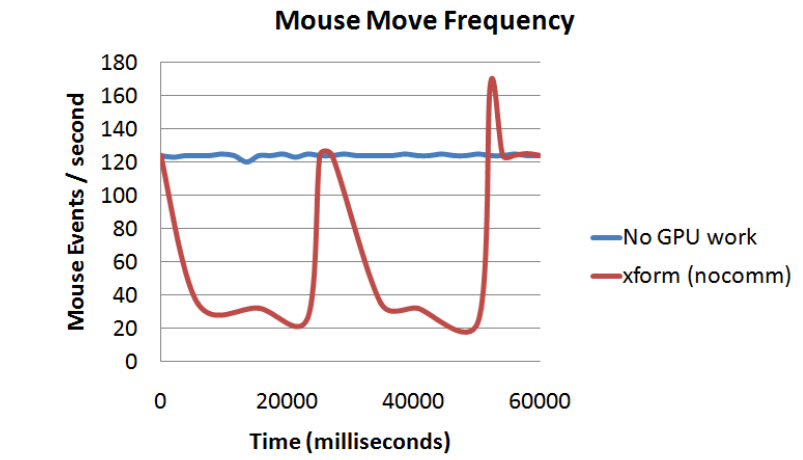 g)
g)
GPU密集工作对CPU密集任务的影响。这些图显示了操作系统能够在程序大量使用GPU的60秒内传递鼠标移动事件的频率(以Hz为单位)。在此期间的平均CPU利用率低于25%。
他们提出了以下新的操作系统抽象,可以使GPU适用于更广泛的应用程序域。这些抽象允许将计算表示为有向图,从而实现高效的数据移动和高效、公平的调度。
- PTask。PTask类似于传统的OS进程抽象,但PTask基本上在GPU上运行。PTask需要来自OS的一些编排来协调其执行,但不需要用户模式主机进程。PTask有一个可以绑定到端口的输入和输出资源列表(类似于POSIX stdin、stdout、stderr文件描述符)。
- Port。Port是内核命名空间中的一个对象,可以绑定到PTask输入和输出资源。一个Port是一个数据源或接收器,提供了一种方法来公开GPU代码中的数据和参数,这些数据和参数必须动态绑定,并且可以由GPU或CPU内存中的缓冲区填充。
- Channel。Channel类似于POSIX管道:它将端口连接到其他端口,或连接到系统中的其他数据源和接收器,如I/O总线、文件等。Channel具有子类型GraphInputChannel、GraphOutChannel和GraphInternalChannel。
- Graph。Graph是PTask节点的集合,其输入和输出端口通过通道连接。可以独立创建和执行多个图,PTask运行时负责公平地调度它们。
在操作系统接口上支持这些新的抽象需要新的系统调用来创建和管理ptask、端口和通道,额外的系统调用类似于POSIX中的进程API、进程间通信API和调度器提示API。
与GPU协调操作系统调度的两个主要好处是:
- 效率性。是指ptask准备就绪和在GPU上调度之间的低延迟,以及在GPU上调度足够的ptask工作以充分利用其计算带宽。
- **公平性。**是指操作系统调度器在GPU利用率和用户界面响应性之间取得平衡。此外,与GPU竞争的PTAK都能获得其计算带宽的合理份额。并非所有PTASK都有所有这些调度要求,如典型的CUDA程序不关心低延迟调度。
总之,他们主张对内核抽象进行根本性的重组,以管理交互式、大规模并行设备。内核必须根据需要只公开足够的硬件细节,以使程序员能够实现良好的性能和低延迟,同时提供根据机器拓扑进行封装和专门化的通信抽象。GPU是一种通用的共享计算资源,必须由操作系统进行管理,以提供公平性和隔离性。
16.3.3.2 Halide Pipeline
Schedule Synthesis for Halide Pipelines on GPUs揭示了Halide DSL和编译器通过分离算法描述和优化调度,实现了针对异构体系结构的图像处理管道的高性能代码生成。然而,自动调度生成目前仅适用于多核CPU体系结构。因此,在为具有GPU功能的平台进行优化时,仍然需要专家级知识。他们使用新的优化过程扩展了当前的Halide自动调度程序,以高效地生成基于CUDA的GPU体系结构的调度。实验结果表明,该调度平均比手动调度快10%,比以前的自动调度快2倍以上。
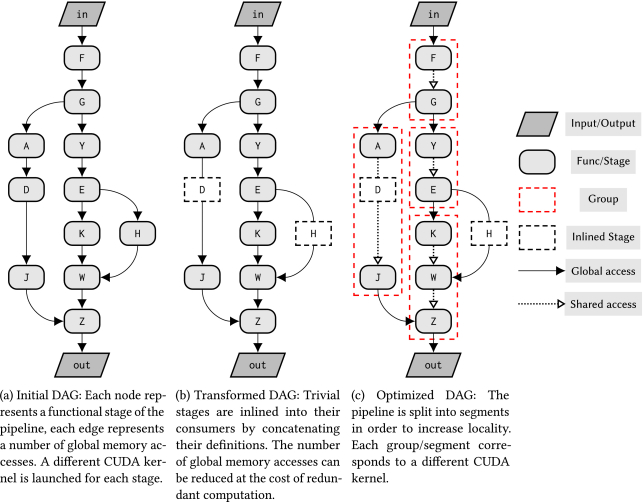
通用管道示例:在将管道拆分为分配了优化计划的较小阶段组之前,将普通阶段内联到其使用者中。

简单的实现会在不同的CUDA内核中完全计算每个阶段,并将所有数据存储到全局内存中。

重叠分块时间表计算一次分块内迭代(或线程块)所需的所有像素,并将其存储在共享内存中。
该文还介绍了在Halide master自动调度程序中实现的新优化过程,以生成针对基于CUDA的GPU架构的优化调度。其遵循一个类似于当前优化流程的过程,其中琐碎(逐点消耗)阶段首先被内联到其消费者中,然后使用Halide master中实现的贪心算法进行分组。下图显示了autoscheduler使用的优化流的概述。
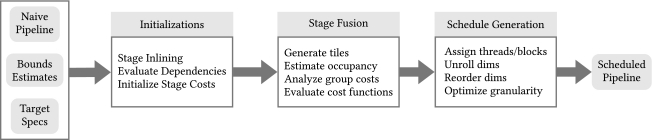
基本调度流程:调度器需要循环边界估计以及用户给定的目标规范描述,以生成给定管道的优化调度。编译流中的大多数步骤都已扩展,以支持自动GPU调度。
16.3.3.3 Hardware Accelerated GPU Scheduling
Hardware Accelerated GPU Scheduling阐述了WDDM在2020年5月引入的一种基于硬件加速的GPU调度机制。
自从Windows显示驱动程序Model 1.0(WDDM)的推出以及GPU调度在Windows中的引入,已经过去了将近14年。很少有人会记得WDDM之前的日子,在那里,应用程序只需向GPU提交他们想要的工作即可。他们提交到一个全局队列,在那里它以严格的“先提交,先执行”方式执行。在大多数GPU应用程序都是全屏游戏的时候,这些最基本的调度方案是可行的,一次运行一个。
随着向使用GPU实现更丰富图形和动画的广泛应用程序的过渡,该平台需要更好地确定GPU工作的优先级,以确保响应的用户体验。因此,WDDM GPU调度程序诞生了。
随着时间的推移,Windows显著增强了WDDM核心的GPU调度程序,支持每个新WDDM版本的其他功能和场景。然而,在整个发展过程中,调度器的一个方面没有改变。他们一直在CPU上运行一个高优先级线程,该线程负责协调、优先排序和安排各种应用程序提交的工作。
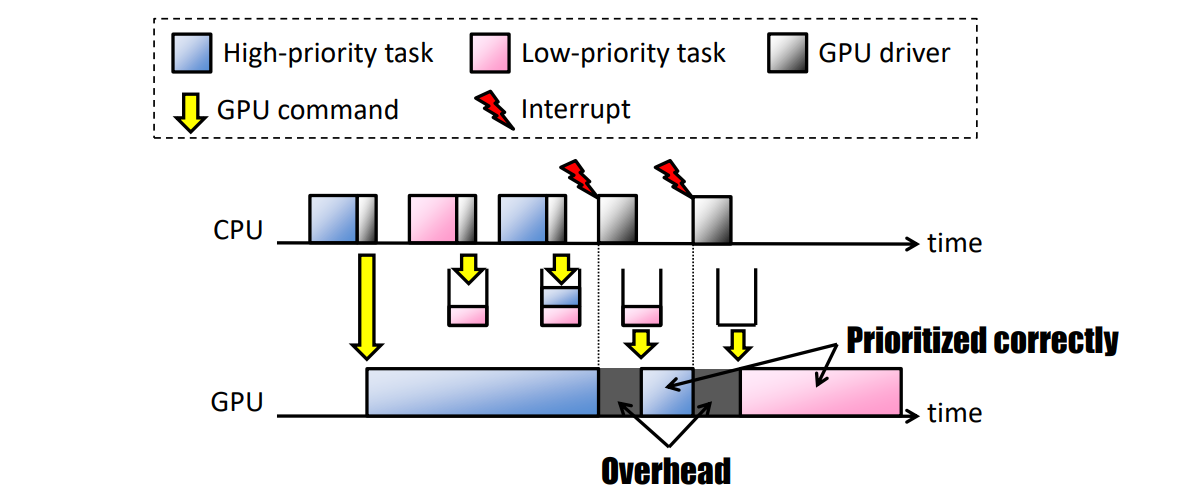
这种调度GPU的方法在提交开销以及工作到达GPU的延迟方面有一些基本的限制,这些开销大部分被传统的应用程序编写方式所掩盖。例如,应用程序通常会在第N帧上执行GPU工作,并让CPU提前运行,为第N+1帧准备GPU命令。这种GPU命令的批量缓冲允许应用程序每帧只提交几次,从而最大限度地降低调度成本,并确保良好的CPU-GPU执行并行性。
CPU和GPU之间缓冲的一个固有副作用是,用户体验到的延迟会增加。CPU在“第N+1帧”期间拾取用户输入,但GPU直到下一帧才渲染用户输入,延迟减少和提交/调度开销之间存在根本的紧张关系。应用程序可以更频繁地提交,以小批量方式提交以减少延迟,或者可以提交更大批量的工作以减少提交和调度开销。
随着Windows 2020年5月10日的更新,其引入一个新的GPU调度程序作为用户选择加入,但默认关闭选项。有了正确的硬件和驱动程序,Windows现在可以将大部分GPU调度卸载到基于GPU的专用调度处理器上。Windows系统可以通过Windows设置 -> 系统 -> 显示 -> 图形设置访问设置页面,以便开启或关闭硬件加速的GPU调度。

Windows继续控制优先级,并决定哪些应用程序在上下文中具有优先级。他们将高频任务卸载到GPU调度处理器,处理各种GPU引擎的量子管理和上下文切换。新的GPU调度程序是对驱动程序模型的重大和根本性更改,更改调度程序类似于在仍居住在房屋中的情况下重建房屋的基础。
虽然新的调度器减少了GPU调度的开销,但大多数应用程序都被设计为通过缓冲来隐藏调度成本。硬件加速GPU调度第一阶段的目标是使图形子系统的一个基本支柱现代化,并为将来的事情做好准备。
就目前而言,有评测文章发现,开启此项功能对部分3A游戏并无实际的帧率提升。
16.3.3.4 TimeGraph
GPU现在常用于图形和数据并行计算。随着越来越多的应用程序趋向于在多任务环境中的GPU上加速,其中多个任务同时访问GPU,操作系统必须在GPU资源管理中提供优先级和隔离功能,特别是在实时设置中。当前主流的GPU是命令驱动的:
多任务的常见问题是CPU常常会导致GPU阻塞:
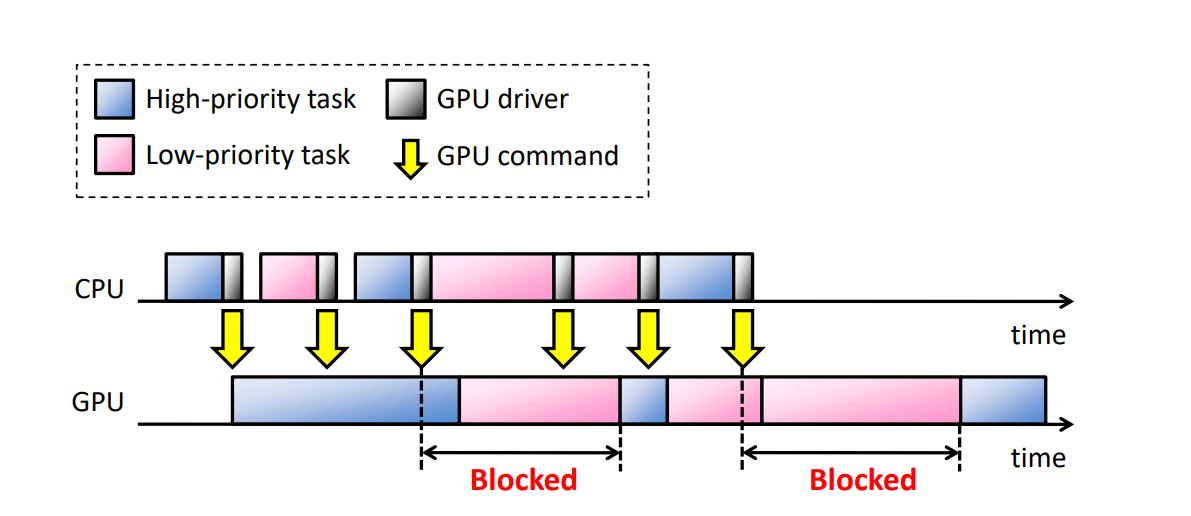
TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments介绍了TimeGraph——一种设备驱动程序级别的实时GPU调度器,用于保护重要的GPU工作负载免受性能干扰。
TimeGraph采用了一种新的事件驱动模型,该模型将GPU与CPU同步,以监控从用户空间发出的GPU命令,并以响应方式控制GPU资源的使用。TimeGraph支持两种基于优先级的调度策略,以解决GPU处理的异步性和非抢占性带来的响应时间和吞吐量之间的权衡问题。资源保留机制还用于说明和强制执行GPU资源使用,从而防止行为不端的任务耗尽GPU资源。进一步提供GPU命令执行成本的预测,以增强隔离。
他们使用OpenGL图形基准进行的实验表明,即使面对极端的GPU工作负载,TimeGraph也能将主要GPU任务的帧速率保持在所需的水平,而如果没有TimeGraph支持,这些任务几乎没有响应。此外还发现,施加在时间图上的性能开销可以限制在4-10%,其事件驱动调度器的吞吐量比现有的tick驱动调度器提高了约30倍。
该文假设系统由通用多核CPU和板载GPU组成,不操纵任何GPU内部单元,因此GPU命令在提交到GPU后不会被抢占。TimeGraph独立于库、编译器和运行时引擎,因此,时间图的原理适用于不同的GPU架构(如NVIDIA Fermi/Tesla和ATI Stream)和编程框架(如OpenGL、OpenCL、CUDA和HMPP)。目前,TimeGraph是为Gallium3D OpenGL软件栈中的Nouveau设计和实现的,该软件栈也计划支持OpenCL。此外,TimeGraph已移植到打包在PathScale ENZO套件中的PSCNV开源驱动程序,该套件支持CUDA和HMPP。然而,鉴于目前可用的一组开源解决方案:Nouveau和Gallium3D,该文主要关注OpenGL工作负载。
TimeGraph是设备驱动程序的一部分,它是用户空间程序向GPU提交GPU命令的接口。假设设备驱动程序是基于大多数类UNIX操作系统中采用的直接渲染基础设施(DRI)模型设计的,作为X Window系统的一部分。在DRI模式下,用户空间程序可以直接访问GPU来渲染帧,而无需使用窗口协议,同时仍可以使用窗口服务器将渲染帧blit到屏幕上。GPGPU框架不需要这样的窗口过程,因此它们的模型更加简化。
为了向GPU提交GPU命令,必须为用户空间程序分配GPU通道,这些通道在概念上表示GPU上的单独地址空间。例如,NVIDIA Fermi和Tesla架构支持128个通道,每个通道的GPU命令提交模型如下图所示。
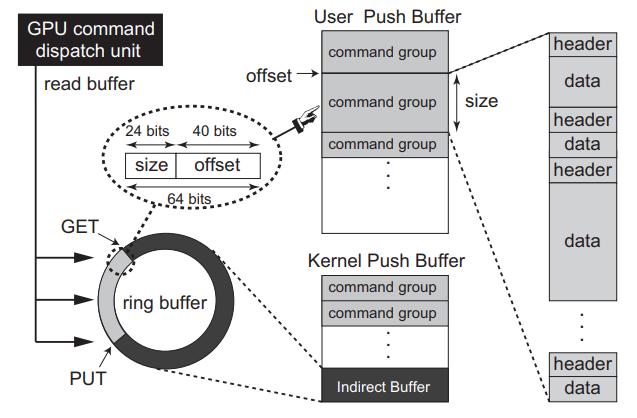
GPU命令提交模型。
每个通道使用两种类型的内核空间缓冲区:用户推送缓冲区和内核推送缓冲区。用户推送缓冲区映射到相应任务的地址空间,其中GPU命令从用户空间推送。GPU命令通常分组为非抢占区域,以匹配用户空间原子性假设。同时,内核推送缓冲区用于内核原语,如主机设备同步、GPU初始化和GPU模式设置。
当用户空间程序将GPU命令推送到用户推送缓冲区时,它们还将数据包写入内核推送缓冲区的特定环形缓冲区部分,称为间接缓冲区,每个数据包都是一个(大小和地址)元组,用于定位某个GPU命令组。驱动程序将GPU上的命令调度单元配置为读取用于命令提交的缓冲区,这个环形缓冲区由GET和PUT指针控制,指针从同一个地方开始。每次数据包写入缓冲区时,驱动程序都会将PUT指针移动到数据包的尾部,并向GPU命令调度单元发送信号,以下载位于GET和PUT指针之间的数据包所在的GPU命令组。然后,GET指针会自动更新到与PUT指针相同的位置。一旦这些GPU命令组提交到GPU,驱动程序将不再管理它们,并继续提交下一组GPU命令组(如果有)。因此,这个间接缓冲区扮演着命令队列的角色。
每个GPU命令组可以包括多个GPU命令,每个GPU命令都由标头(header)和数据组成,标头包含方法和数据大小,而数据包含传递给方法的值。方法表示GPU指令,其中一些指令在计算和图形之间共享,另一些则针对每种指令。我们假设,一旦GPU命令组卸载到GPU上,设备驱动程序不会抢占它们。在同一GPU通道中,GPU命令执行顺序错误。GPU通道由GPU引擎自动切换。
上述驱动程序模型基于直接渲染管理器(DRM),尤其针对NVIDIA Fermi和Tesla架构,但也可以用于其他架构,只需稍加修改。
TimeGraph的体系结构及其与软件堆栈其余部分的交互如下图所示。用户空间程序无需修改,GPU命令组可以通过现有软件框架生成。然而,TimeGraph需要与设备驱动程序空间中名为PushBuf的特定接口进行通信,PushBuf接口允许用户空间提交存储在用户推送缓冲区中的GPU命令组。TimeGraph使用此PushBuf接口将GPU命令组排队,它还使用为GPU到CPU中断准备的IRQ处理程序来调度下一个可用的GPU命令组。
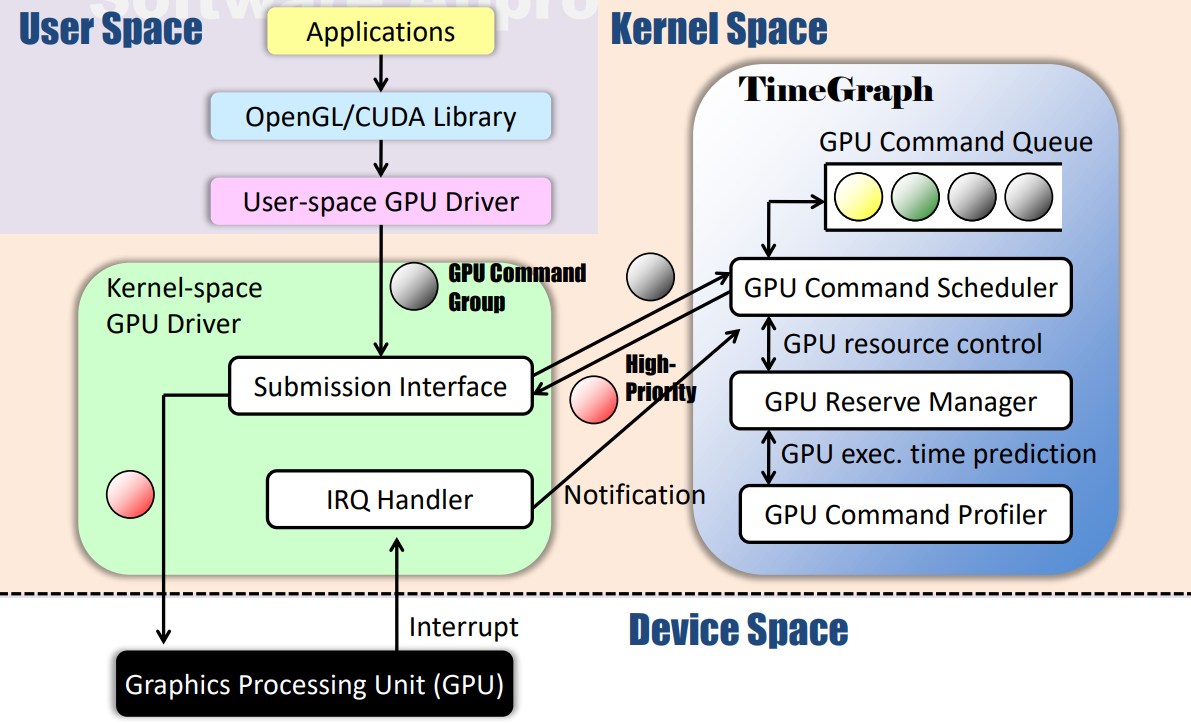
TimeGraph由GPU命令调度器、GPU保留管理器和GPU命令探查器组成。GPU命令调度器根据任务优先级对GPU命令组进行排队和调度,它还与GPU保留管理器协调,以计算和强制执行任务的GPU执行时间。GPU命令探查器支持预测GPU命令执行成本,以避免超出保留范围。支持两种调度策略来解决响应时间和吞吐量之间的权衡问题:
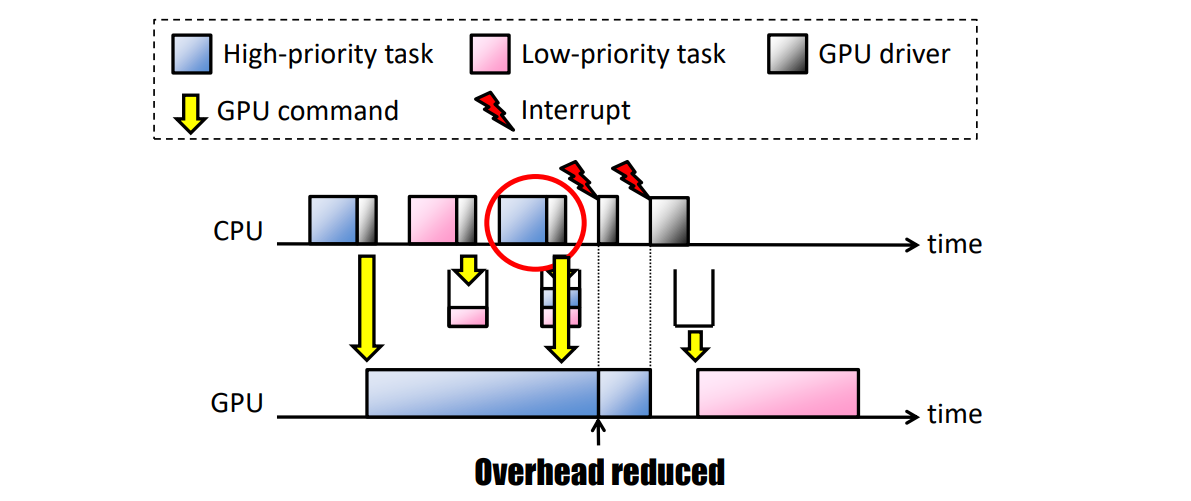
- 可预测响应时间(PRT):此策略最大限度地减少GPU上的优先级反转,以根据优先级提供可预测的响应时间。当GPU不空闲时,GPU命令排队;当GPU空闲时,GPU命令被调度:
- 高吞吐量(HT):此策略增加总吞吐量,允许额外的优先级反转。当GPU不空闲时,只有当优先级低于当前GPU上下文时,GPU命令才会排队;当GPU空闲时,会调度GPU命令:
 ng)
ng)
它还支持两种GPU保留策略,以解决隔离和吞吐量之间的权衡问题:
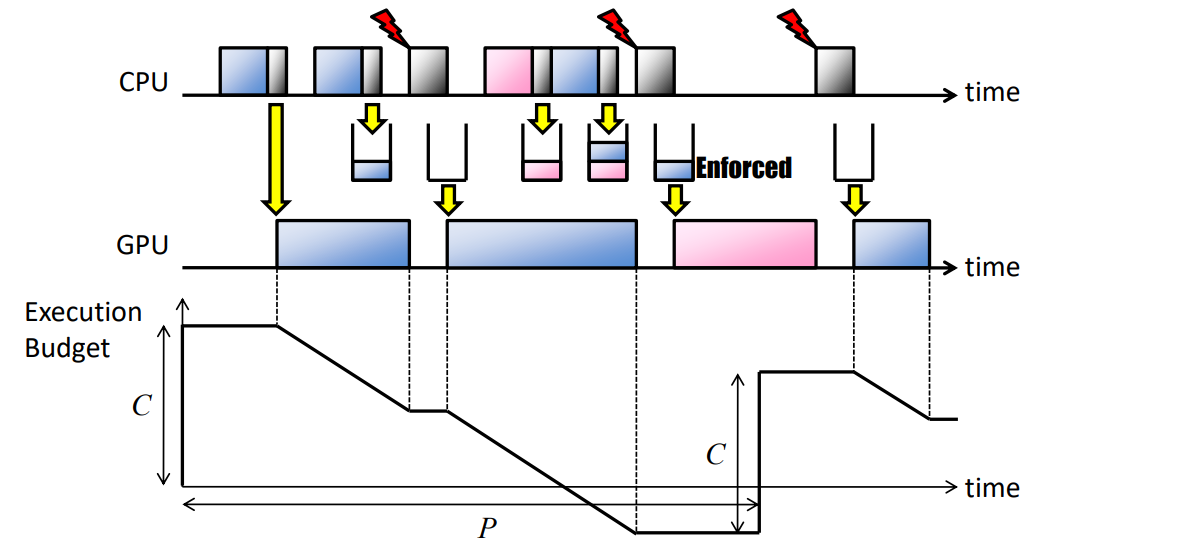
- 后验强制(PE):此策略在GPU命令组完成后强制GPU资源使用,而不牺牲吞吐量。优化GPU资源使用,指定每个任务的容量(C)和周期(P)(/proc/GPU/$任务):
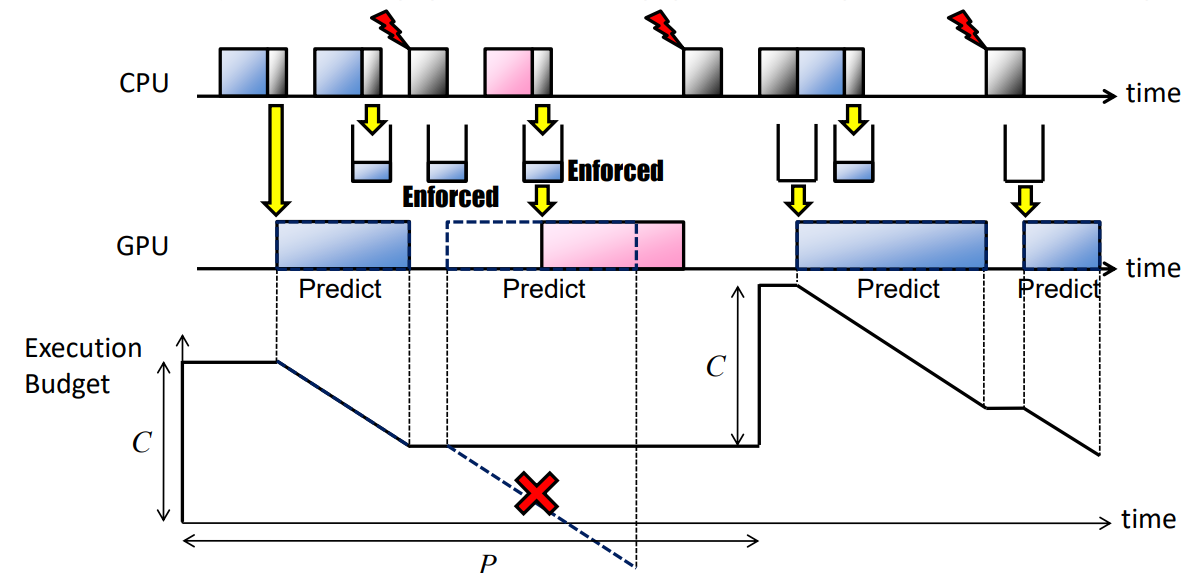
- 先验强制(AE):此策略在提交GPU命令组之前,使用GPU执行成本预测强制GPU资源使用,但会增加额外的开销。指定每个任务的容量(C)和周期(P)(/proc/GPU/$任务):
为了将多个任务统一到一个保留中,TimeGraph保留机制提供了共享保留模式。特别是,TimeGraph在加载时使用PE策略创建一个特殊的共享保留实例(称为Background,它为不属于任何特定保留的所有GPUAccessed任务提供服务)。下图显示了PushBuf接口和IRQ处理程序的高级图,其中TimeGraph引入的修改以粗体框架突出显示。此图基于Nouveau实现,但大多数GPU驱动程序应该具有类似的控制流。
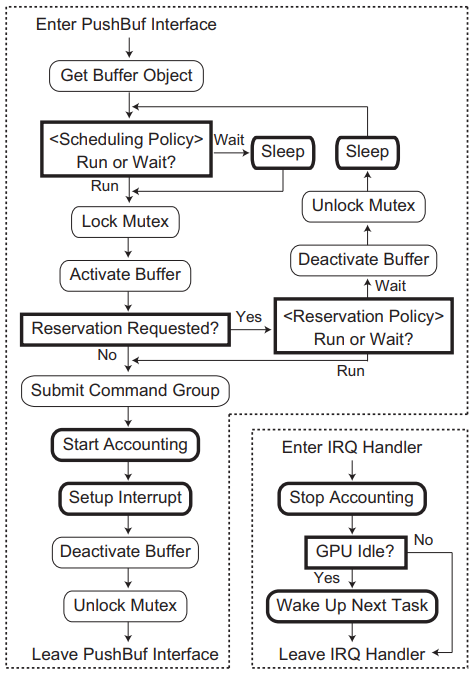
PushBuf接口和IRQ处理程序与时间图方案的关系图。
GPU命令调度器的目标是根据任务优先级对非抢占式GPU命令组进行排队和调度。为此,TimeGraph包含一个暂停任务的等待队列,它还管理GPU联机列表,即指向当前在GPU上执行的GPU命令组的指针列表。
当GPU命令组进入PushBuf界面时,GPU联机列表用于检查当前是否有正在执行的GPU命令组。如果列表为空,则将相应的任务插入其中,并将GPU命令组提交给GPU。否则,任务将插入到要调度的等待队列中。
GPU联机列表的管理需要有关GPU命令组何时完成的信息。TimeGraph采用事件驱动模型,该模型使用GPU到CPU中断来通知每个GPU命令组的完成,而不是以前工作中采用的tick驱动模型。每次中断时,相应的GPU命令组将从GPU联机列表中删除。
TimeGraph支持两种GPU调度策略。**可预测响应时间(PRT)**策略鼓励此类任务在不影响重要任务的情况下及时执行。此策略在某种意义上是可预测的,GPU命令组是基于任务优先级进行调度的,以使高优先级任务在GPU上响应。另一方面,**高吞吐量(HT)**策略适用于应该尽可能快地执行的任务。有一个权衡,即PRT策略以牺牲吞吐量为代价防止任务受到干扰,而HT策略实现了一个任务的高吞吐量,但可能会阻止其他任务。例如,桌面小部件、浏览器插件和视频播放器任务需要使用PRT策略,而三维游戏和交互式三维接口任务可以使用HT策略。
PRT策略强制任何GPU命令组等待前面的GPU命令组(如果有)完成。具体而言,如果GPU联机列表为空,则到达设备驱动程序的新GPU命令组可以立即提交给GPU。否则,相应的任务必须在等待队列中休眠。等待队列中的最高优先级任务(如果有)在GPU的每次中断时被唤醒。
下图(a)显示了在PRT策略下如何在GPU上调度具有不同优先级的三个任务,即高优先级、中优先级(MP)和低优先级(LP)。当MP任务到达时,其GPU命令组可以在GPU上执行,因为没有GPU命令组正在执行。如果GPU和CPU异步运行,则MP任务可以在其上一个GPU命令组执行时再次到达。但是,根据PRT策略,由于GPU没有空闲,MP任务这次将排队。由于同样的原因,甚至下一个HP任务也会排队,因为更高优先级的任务可能很快就会到达。TimeGraph附加在每个GPU命令组末尾的特定GPU命令集会向CPU生成一个中断,并相应地调用TimeGraph调度程序以唤醒等待队列中的最高优先级任务。因此,接下来选择在GPU上执行HP任务,而不是MP任务。这样,LP任务的下一个实例和HP任务的第二个实例将根据其优先级进行调度。
鉴于GPU命令组的到达时间未知,且每个GPU命令组都是非抢占的,我们认为PRT策略是提供可预测响应时间的最佳方法。然而,在每个GPU命令组边界进行调度决策不可避免地会带来开销,如下图(a)所示。
HT策略减少了这种调度开销,稍微减少了可预测的响应时间。如果(i)当前正在执行的GPU命令组是由同一任务提交的,并且(ii)等待队列中没有更高优先级的任务,则允许立即将GPU命令组提交给GPU。否则,它们必须以与PRT策略相同的方式暂停。在中断时,只有当GPU联机列表为空(GPU空闲)时,等待队列中优先级最高的任务才会被唤醒。
下图(b)描述了在HT策略下如何调度下图(a)中使用的同一组GPU命令组。与PRT策略不同,MP任务的第二个实例可以立即提交其GPU命令组,因为当前正在执行的GPU命令组是由其自身发出的。MP任务的这两个GPU命令组可以连续执行,而不会产生空闲时间,HP任务的两个GPU命令组也是如此。因此,HT策略更适用于面向吞吐量的任务,但HP任务被MP任务阻塞更长的时间。这是一种权衡,如果优先级反转至关重要,则PRT策略更合适。
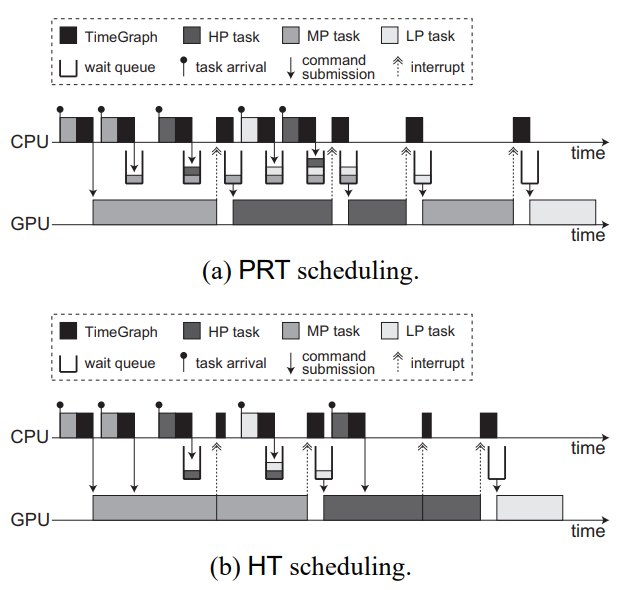
TimeGraph中GPU调度的示例。
TimeGraph支持GPU执行时间预测,使用基于历史的方法——搜索与传入GPU命令序列匹配的以前GPU命令序列的记录,适用于二维,但需要调查三维和计算。
TimeGraph开启后,在各方面的性能影响如下:
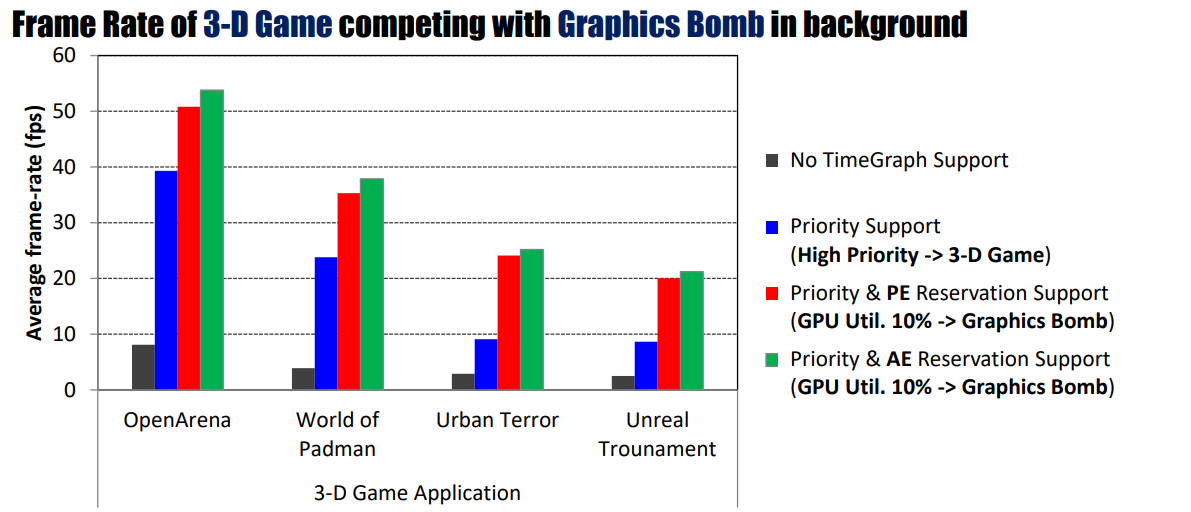
在后台中与图形Bomb竞争的三维游戏帧速率。
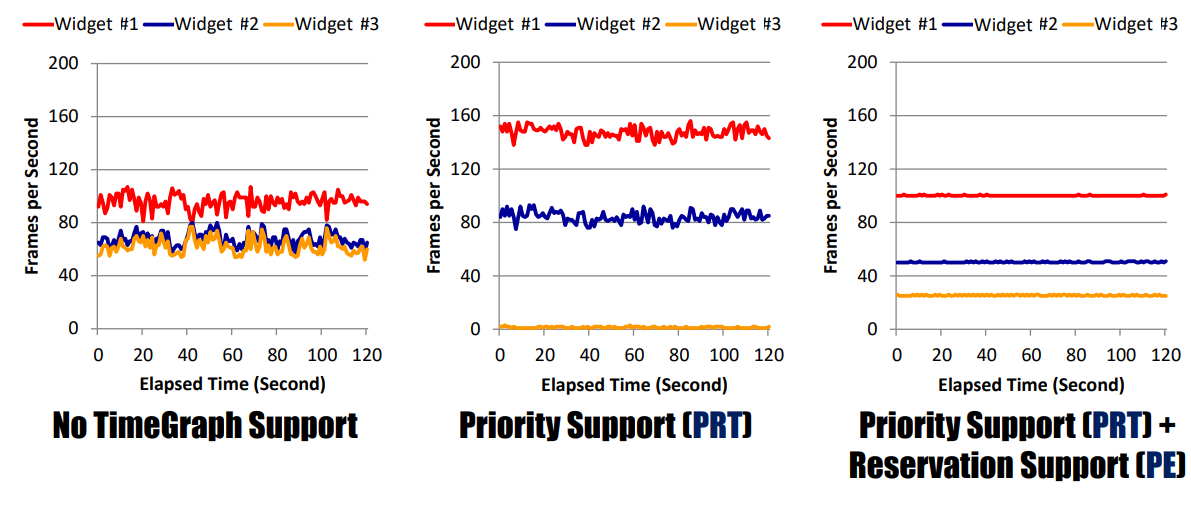
干扰时间。

独立设备的性能。
总之,TimeGraph支持在多任务环境中对GPU应用程序进行优先级排序和隔离:
- 设备驱动程序解决方案:不修改用户空间。
- GPU命令的调度。
- 保留GPU资源使用。
16.3.3.5 GPU Scheduling
要开始理解在多个独立应用程序之间共享单个GPU的含义和困难,我们首先必须了解GPU通常如何处理单个应用程序的任务调度。调度是跨时间和空间维度考虑的,即决定任务应该在何时何地执行。时间调度由上述FCFS算法确定;当任务到达队列的头部时,它将得到服务(如果有足够的资源可用)。这种调度也是非抢占性的——一旦将一个块调度到设备,就不能为另一个块抢占执行。此外,这种非抢占也适用于任务级别。空间调度根据任务资源需求和SMX上的资源可用性的双重考虑,确定任务可以执行的SMX单元。
在硬件调度级别,最小的可调度单元是线程块,意味着设备上的某些SMX必须能够满足整个块的资源需求,以便将其分派执行。此外,一个内核的所有线程块都不必一次处理,这就引入了执行波的概念。如果我们将块调度视为一个瞬时过程,那么每个wave都会根据块需求和设备资源可用性来调度最大允许的块数。一旦安排了wave,所有剩余的块都将保留在执行队列中,直到设备上的其他执行完成,从而释放资源。
有许多因素决定了有多少块可以组成一个完整的执行wave。内核线程块的配置是一个重要因素,因为这决定了所需的每个资源的数量。另一个关键限制因素是对每个SMX允许的驻留线程块数量的内置约束。必须注意这种约束,因为在达到最大驻留块数之前,其他资源通常可能不会完全耗尽,在由具有不同配置和资源需求的内核组成的并发执行场景中尤其可能。下表列出了多代NVIDIA GPU上每个SMX的资源限制。
| Compute Capability | 3.5 | 5.2 | 6.0 | 7.0 |
|---|---|---|---|---|
| Maximum Threads / SMX | 2048 | 2048 | 2048 | 2048 |
| Maximum Thread Blocks / SMX | 16 | 32 | 32 | 32 |
| Maximum Threads per Block | 1024 | 1024 | 1024 | 1024 |
| Maximum Registers / SMX | 65536 | 65536 | 65536 | 65536 |
| Shared Memory per SMX | 48 KB | 96 KB | 64 KB | 96 KB |
首先,线程块在所有SMX单元中的分布确保了某些技术(例如功率选通)无法可靠地应用于提高功率效率。其次,空间调度方法会导致不确定性模式,从而消除了通过将某些块映射到特定SMX来提高利用率和/或效率的可能方法。最后,在并发场景下,独立内核的不同资源需求导致SMX单元集的利用率不对称。
将上述调度策略应用于多个独立应用程序共享GPU设备的场景,需要消除资源冲突并确保某些属性,例如公平性。在GPU计算中实现这一点的一种方法是通过构造流。
GPU流表示CPU和GPU之间的独立执行流,类似于CPU线程。在流中,操作按调用顺序(即FCF)顺序执行。在不同的流之间,根据资源的可用性,可以并行或交错执行操作。下图显示了多流场景的抽象表示,流中的操作被调度到单个工作队列中,只有当操作到达流队列的前端时,才会将其调度到下一级设备调度器。
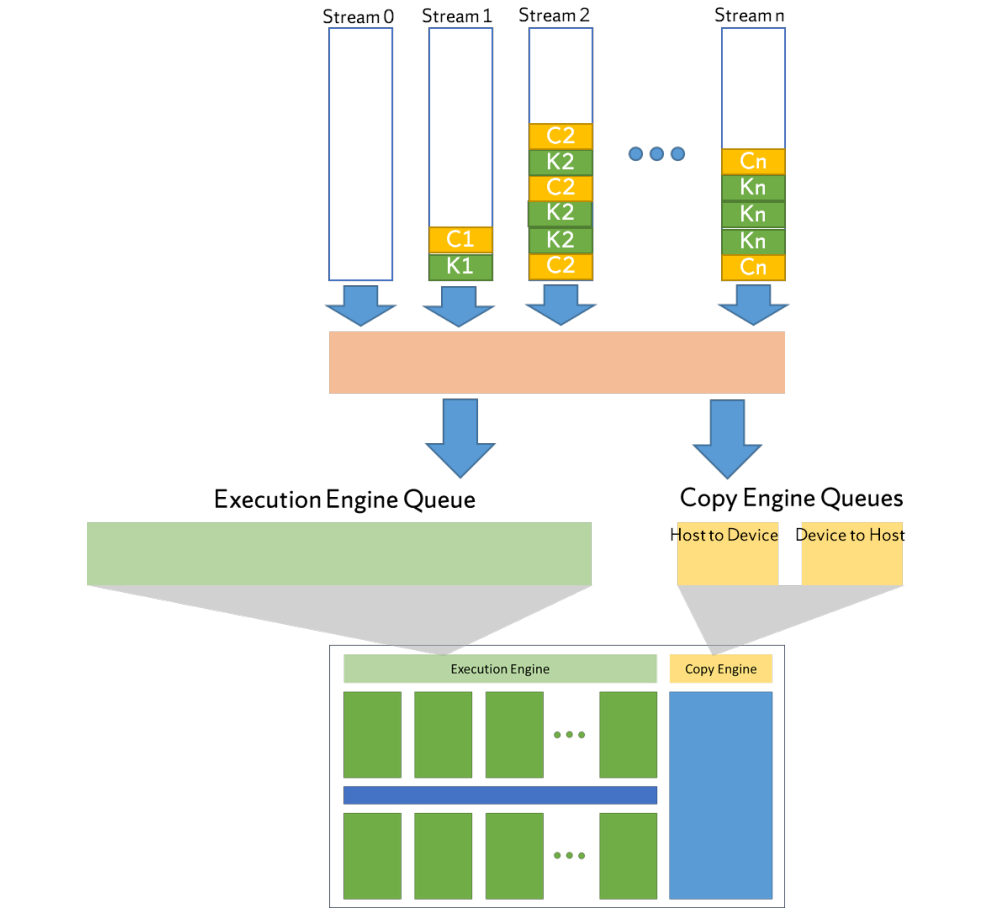
多内核调度层次结构。
下一级调度器表示执行队列(对于内核)或复制队列(对于内存传输)。同样,这些队列中的操作是以FCFS方式调度的,但由于某些设备状况,会出现一些警告。下表是一些GPU调度规则(是针对NVIDIA Jetson TX2体系结构根据经验得出的一组调度规则,并针对其他几种NVIDIA体系结构进行了验证)。
| 标识符 | 规则 |
|---|---|
| G1 | 当调用关联的CUDA API函数(内存传输或内核启动)时,复制操作或内核在其流的流队列中排队。 |
| G2 | 当内核到达其流队列的头部时,它将被排入EE队列。 |
| G3 | EE队列头部的内核一旦完全调度,就会从该队列中退出队列。 |
| G4 | 一旦内核的所有块完成执行,内核就会从其流队列中退出队列。 |
| X1 | 只有位于EE队列头部的内核块才有资格分配。 |
| R1 | 只有在满足资源约束的情况下,位于EE队列头部的内核块才有资格被分配。 |
| R2 | 只有在某些SM上有足够的可用线程资源时,位于EE队列头部的内核块才有资格被分配。 |
| R3 | 只有在某些SM上有足够的共享内存资源可用时,位于EE队列头部的内核块才有资格被分配。 |
| C1 | 复制操作到达其流队列的头部时,将在CE队列上排队。 |
| C2 | CE队列头部的复制操作有资格分配给CE。 |
| C3 | 一旦将拷贝分配给GPU上的CE,CE队列头部的拷贝操作将从CE队列中退出。 |
| C4 | CE完成复制后,复制操作将从其流队列中退出队列。 |
| N1 | 当对于每个其他流队列,要么队列为空,要么其头部的内核在Kk之后启动时,位于空流队列头部的内核Kk被排队到EE队列上。 |
| N2 | 非空流队列头部的内核Kk不能在EE队列上排队,除非空流队列为空或其头部的内核是在Kk之后启动的。 |
| A1 | 内核只能在与其流优先级匹配的EE队列上排队。 |
| A2 | 只有当所有高优先级EE队列(优先级高过优先级低)为空时,任何EE队列头部的内核块才有资格分配。 |
理解这些调度规则对于实现最大资源利用率和高系统吞吐量至关重要。这些规则共同说明,一旦内核的块开始调度到GPU(通过X1),在调度完第一个内核的所有块之前,无法调度其他内核(G3)。当第一个内核由于不满足其中一个资源规则(R1-R3)而在执行队列中暂停时,最有可能出现这种情况。然而,执行队列中后续内核的配置完全可能满足这些资源规则。因此,将错失提高设备利用率的机会,从而需要更精细的执行队列调度方法。在不进行类似解释的情况下,我们声称复制队列也存在这些考虑因素,因此需要对替代调度策略进行类似的检查。
先前的研究为进一步分析GPU资源的利用情况提供了动力,以实现高性能和能效。Hong和Kim在论文沿着两个主轴对应用程序进行了分类,即计算约束的应用程序和内存约束的应用程序,并表明性能、利用率和能效之间的关系与此特征相关。受计算限制的应用程序具有强伸缩性。对于固定的问题大小,如果给应用程序更多的处理内核,它将显示与内核数量成比例的加速(即在更短的时间内完成相同数量的工作)。另一方面,内存受限的应用程序具有弱伸缩性。在这种情况下,性能受到固定问题大小的限制,如果问题大小按比例增加(即在相同时间内完成更多工作),则添加更多处理器只能提高性能。
Hong和Kim展示了这些缩放特性与各种GPU内核的性能和功耗之间的关系,以得出在应用程序中使用的最佳内核数。这种方法声称的好处是,根据应用类型,在不同的利用率下可以实现最佳的能效。对于受计算限制的应用程序,最佳点是充分利用率,而对于受内存限制的应用程序,最佳点是低于此值。显而易见的结论是,许多应用程序不需要完全补充GPU资源来实现最佳性能。此外,该论文中方法的目标是开发一个模型,以确定单个内核的最佳内核数量,并成功证明了能量效率的提高。然而,该方法没有解决并发执行场景,也没有提出一种利用未充分利用的GPU资源潜力的方法。
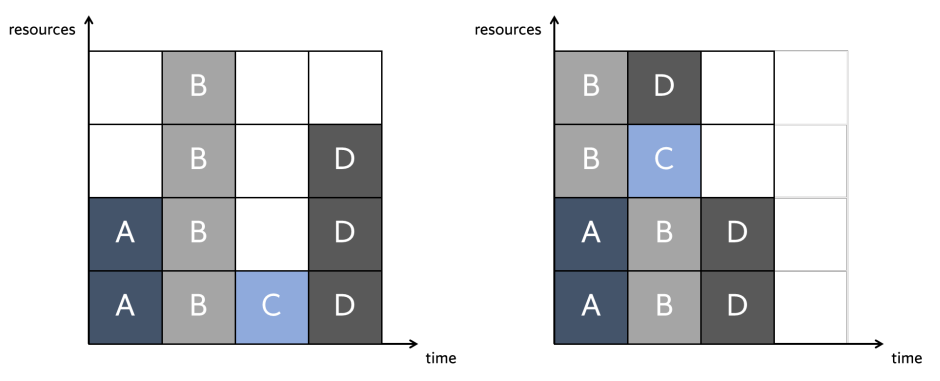
下图所示的简单场景,在左边,展示了单个内核执行的概念场景(即独立内核之间没有设备共享)以及由此产生的性能和利用率。特别是该设备的利用率仅为62.5%,计划内核的最大生成时间为4个时间单位。然而,当考虑并发执行时,如下图右所示,利用率增加到83.3%,最大完工时间减少到3个时间单位。虽然所示场景是对复杂调度问题的过度简化,特别是考虑到上面讨论的调度规则和约束,但它提供了分析和开发新技术以最大限度地利用GPU计算架构能力的最初动机。
串行(左)和并发(右)执行的性能和利用率比较。
在考虑典型GPU设备的功耗特性时,进一步验证了利用并发性和最大化设备利用率的好处。如上所述,工作以循环或半循环的方式分配给设备上的SMX单元。因此,整个设备在执行期间通电,功率选通等策略通常不适用。当然,有多种因素决定内核应用程序的峰值功耗,包括线程操作、内存访问等,但我们观察到,峰值通常与所利用的主设备资源的总体百分比无关。下图说明了这样一个示例。
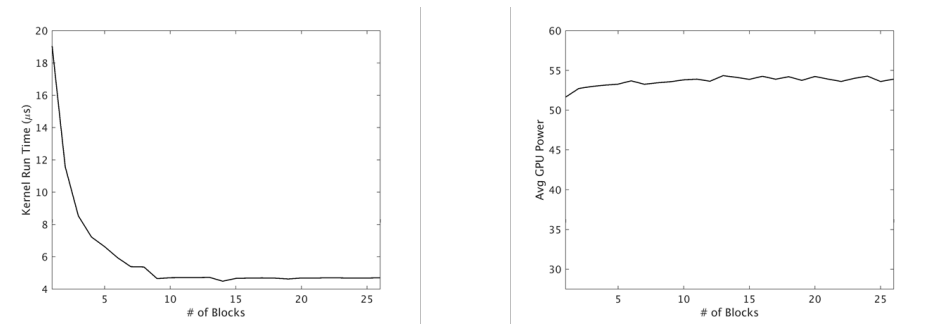
内核运行时间(左)和GPU功耗(右),用于增加块数和设备利用率。
在本例中,内核的最高性能是在GPU利用率不足的情况下实现的。类似地,峰值功耗从最低利用率水平到可能的最大利用率增长约5%,增幅可以忽略不计。这有助于从经验上验证中的观察结果,并允许我们提出这样的主张:提高系统吞吐量的方法,即在较短时间内完成更多任务,将对系统能效产生积极影响,而无需引入任何明确管理功耗的技术。鉴于这些机会,研究的主要重点是独立GPU任务的优化调度,以提高系统吞吐量和资源利用率。除了上述能效外,这种方法的好处还包括通过平均标准化周转时间来衡量改善各自的任务绩效。
OS的GPU调度可从用户空间和内核空间考量,它们各有4种调度方式。
首先考虑用户空间的GPU调度器的软件体系结构,下图描述了几种体系结构。
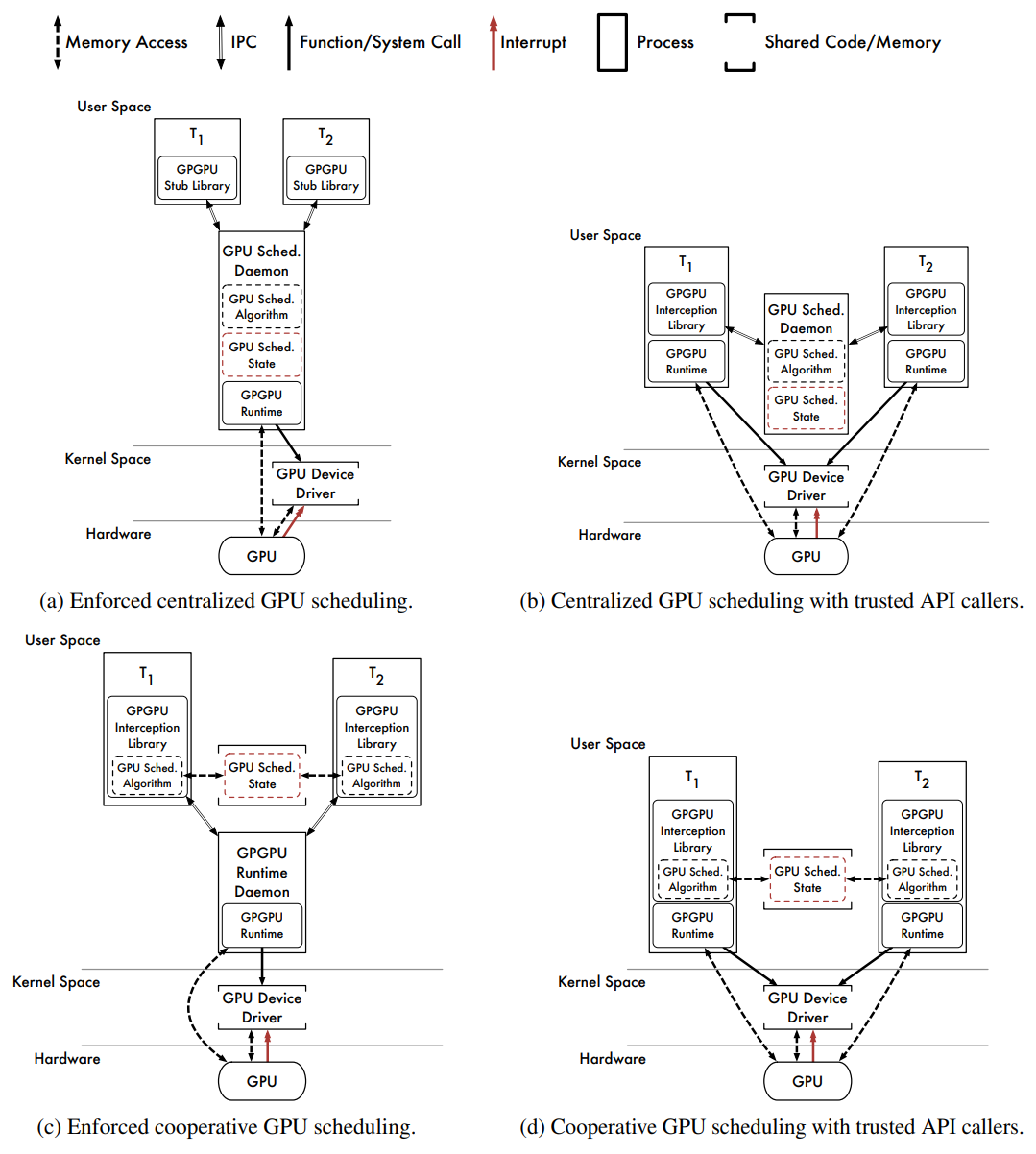
在用户空间中实现的API驱动的GPU调度程序的几种软件体系结构。
- Centralized Scheduling With Enforcement(集中调度与实施)
上图(a)描述了用户空间中GPU调度的通用软件体系结构。GPGPU API调用被发出到每个任务中的GPGPU存根库,存根库通过IPC通道(例如UNIX域套接字、TCP/IP套接字等)将API请求重定向到GPGPU调度守护程序,该守护程序根据集中式调度策略为请求提供服务。守护进程自行执行所有API调用,强制执行所有调度决策。
好处:
1、由于决策集中,调度策略易于实施。
2、由于计划的API调用由GPGPU调度守护程序本身执行,因此执行调度决策。
缺点:
1、守护进程必须包含或能够加载组成任务的GPU内核代码。这可以在编译守护程序时完成。GPU内核代码的动态加载也是可能的,但实现起来并不简单。
2、由于任务和守护进程之间的消息传递,IPC引入了开销。
3、除非使用任何内存重映射技术,GPU内核数据必须通过IPC通道传输。数据密集型GPGPU应用程序(例如,由摄像机提供数据的行人检测应用程序)的性能较差。
4、必须对守护进程本身进行调度。这会带来额外的调度程序开销。此外,除非RTOS提供一种机制,使守护进程可以从其组成部分继承优先级任务,可调度性分析不是直截了当的。可以通过提高守护程序的优先级(会影响可调度性分析)来绕过此限制,或者可以为守护程序专门保留一个CPU(会导致其他工作丢失一个CPU)。这两种方法都不可取。
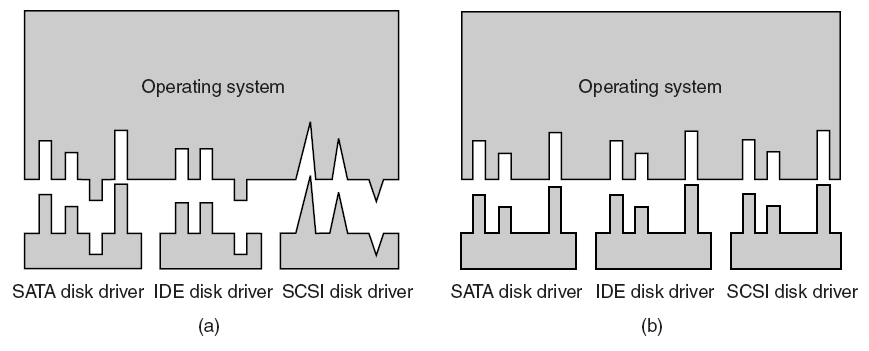
GViM、gVirtuS、vCUDA、rCUDA和MPS采用这种流行的体系结构。然而,这些都没有实现实时GPU调度策略。通过IPC通道传输GPU内核数据的开销可能会导致数据量大的应用程序无法接受的性能。
- Centralized Scheduling Without Enforcement(集中调度,无需强制执行)
上图(b)描述了另一个基于守护进程的调度器。GPGPU API调用被插入的库截获,对于每个调用,库都会通过IPC通道向GPU调度守护程序发出相应GPU引擎的请求。库等待每个请求被授予,守护程序根据集中式调度策略授予请求,一旦授予了必要的资源,插入的库就会将截获的API调用传递给原始GPGPU运行时。
好处:
1、易于实现,因为调度决策是集中的,GPU内核代码对于每个组成任务都是本地的。
2、GPU内核数据不会通过IPC通道复制。数据密集型GPGPU应用程序性能良好。
缺点:
1、无法执行GPU调度决策。行为不当或恶意的任务可能会绕过插入库并直接访问GPGPU运行时。
2、IPC引入了消息传递开销。
3、必须安排守护程序本身。
由于GPU内核输入和输出数据不穿过IPC通道,这种体系结构牺牲了调度决策的执行,以实现数据密集型应用程序的性能优势。此外,这是8种GPU调度体系结构中最容易实现的,是基于Windows 7的PTask原型所采用的体系结构,PTask是一种非实时GPU调度程序。RGEM也是一种实时GPU调度器,它也采用了这种体系结构。
- Cooperative Scheduling With Enforcement(带执行的协作调度)
上图(c)描述了协作GPU调度器和GPGPU运行时守护程序的软件体系结构。插入的库拦截API调用,每个任务中库的每个实例调用相同的GPU调度算法,该算法嵌入在插入的库中。GPU调度程序状态的单个实例存储在共享内存中,插入的库将API调用传递给守护程序以实际执行。
好处:
1、GPU调度是高效的,因为每个任务都可以直接访问GPU调度程序状态。
2、调度决策执行力弱。尽管GPGPU运行时守护程序集中了对GPU的所有访问,但行为不当或恶意的任务可能会绕过协作GPU调度程序直接向守护程序发出工作。
缺点:
1、对共享GPU调度程序状态的访问必须在任务之间进行协调(或同步)。根据使用的同步机制,任务可能需要在执行调度算法时非抢占地执行(以避免死锁)。这需要RTO的支持或访问临时禁用抢占的特权CPU指令。
2、行为不当或恶意的任务可能会损坏GPU调度程序状态,因为它可能会覆盖共享内存中的任何数据。从此类故障中恢复可能很困难。
3、行为不当或恶意的任务可能绕过GPU调度程序,直接向GPGPU运行时守护程序发出工作,除非守护程序具有验证请求的机制。
4、IPC引入了消息传递开销。
5、GPU内核数据必须通过IPC通道传输。
6、必须安排守护程序本身。
该体系结构中与IPC相关的开销消除了协作调度的任何潜在好处。此外,由于可以绕过GPU调度器,执行调度决策的能力被削弱。这种体系结构与集中式调度(上图a)相比没有明显的优势。
- Cooperative Scheduling Without Enforcement(无强制的协同调度)
上图(d)描述了协作GPU调度程序的软件体系结构,无需使用守护程序。插入的库拦截API调用,与之前一样,任务协同执行相同的GPU调度算法,并在相同的共享调度程序状态下运行。截获的API调用在计划时传递给原始GPGPU运行时。
好处:
1、没有IPC管理费用。数据密集型GPGPU应用程序性能良好。
2、没有要调度的守护程序。这简化了实时分析,并减少了对RTO的支持。
3、高效的GPU调度。
坏处:
1、必须协调对GPU调度程序状态的访问。
2、GPU调度程序状态容易损坏。
3、无法执行GPU调度决策。
这是研究的最有效的用户空间体系结构。它避免了所有IPC开销,避免了守护进程带来的所有开销和分析难题。然而,它也是所有8种体系结构中最脆弱的,必须信任任务:不要绕过GPU调度程序和不损坏GPU调度程序状态。
接下来探索内核空间的GPU调度。
用户空间中的GPU调度有几个弱点。一个缺点是,我们可能无法充分保护GPU调度程序数据结构。协作调度方法就是这种情况,其中GPU调度程序状态可能会被行为错误或恶意任务破坏。然而,用户空间调度的最大弱点是我们无法与底层RTO紧密集成,可能会妨碍我们以任何程度的信心实现正确的实时系统。RTOS可以提供一些机制,允许实时任务通过用户空间操作影响其他任务的调度优先级(例如,具有优先级修改进度机制的实时锁定协议,以及直接操纵优先级的系统调用)。可以利用这些为用户空间GPU调度器添加一些实时确定性。然而,这些机制可能不足以最小化,更重要的是,限制GPU相关的优先级反转。
我们解决很多问题的能力受到用户空间的严重限制。通过将GPU调度器与CPU调度器和RTOS内核中的其他操作系统组件(如中断处理服务)紧密集成,可以最好地解决这些问题。这些问题促使我们考虑内核空间GPU调度器。下图描述了内核空间GPU调度器的几种高级软件体系结构。假设所有方法都受益于与RTO紧密集成的能力。
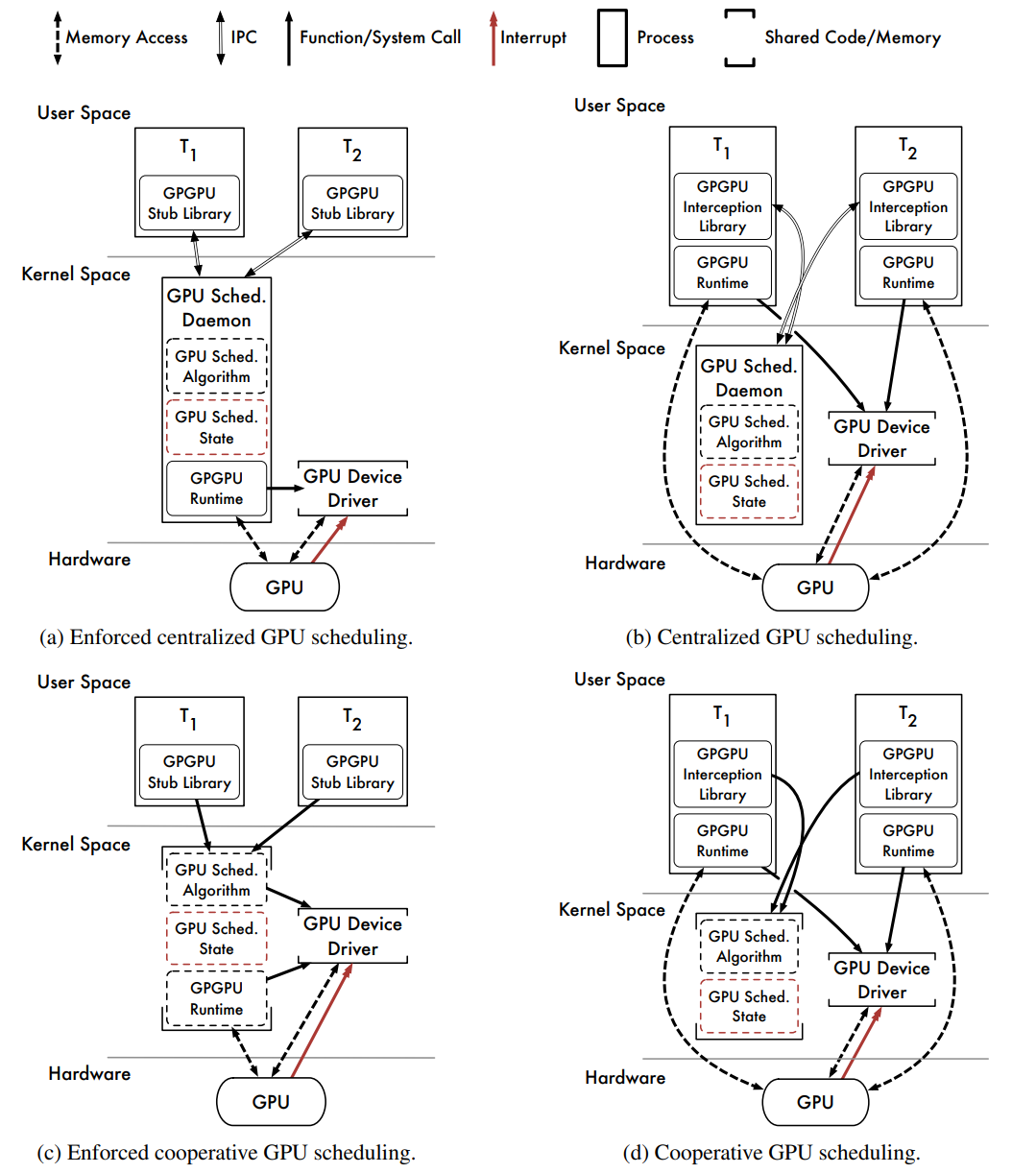
- Centralized Scheduling With Enforcement(集中调度与实施)
上图(a)描述了具有集中式调度程序守护程序的软件体系结构。该体系结构与图3.1(a)中所示的体系结构非常相似,其功能大致相同。然而,GPU调度守护程序现在从内核空间运行。
好处:
1、GPU内核数据不会通过IPC通道复制。这是可能的,因为GPU调度守护程序可以直接访问其组成任务的用户空间内存。数据密集型GPGPU应用程序性能良好。
2、调度策略是集中的。
3、执行计划决策。
缺点:
1、内核空间GPGPU运行时可能不可用。所有制造商提供的GPGPU运行时仅在用户空间中运行。
2、必须对守护进程本身进行调度。会带来额外的系统开销,然而,从内核空间来看,可以更灵活地对守护进程进行适当的优先级排序,以确保实时确定性。
3、守护进程必须包括或能够加载组成任务的GPU内核代码。
4、IPC引入了消息传递开销。
这种体系结构得益于强制的集中式调度,无需在IPC通道上穿梭GPU内核输入和输出数据。由于消息传递,这种方法仍然会遇到一些IPC通道开销。然而,这种方法最大的缺点是实用性:内核空间GPGPU运行时通常不可用。正如Gdev(采用上图a和d的混合架构)所示,虽不是一个无法克服的挑战,但很困难。
- Centralized Scheduling Without Enforcement(集中调度,无需强制执行)
上图(b)描述了另一个带有GPU调度守护程序的软件体系结构,其架构与用户空间的(b)中的架构相匹配,只是守护进程现在在内核空间中运行。
好处:
1、使用通用用户空间GPGPU运行时。
2、调度策略是集中的。
3、GPU内核数据未通过IPC通道复制。
好处:
1、无法执行GPU调度决策。
2、IPC引入了消息传递开销。
3、必须调度守护程序本身。
该体系结构在内核空间集中式调度和实际约束之间达成了妥协。调度决策是在内核空间内做出的,但由具有用户空间GPGPU运行时的单个任务执行。因此,体系结构无法强制执行其调度决策,是基于Linux的PTask原型所采用的体系结构,PTask是一个非实时GPU调度器。
- Cooperative Scheduling With Enforcement(带执行的协作调度)
上图(c)描述了协作GPU调度器的软件体系结构。GPGPU API调用被路由到存根库,存根库通过OS系统调用调用内核空间GPU调度程序。GPU调度程序状态由所有任务共享,但存储在内核空间数据结构中。计划的API调用由内核空间GPGPU运行时使用调用任务的程序线程执行。
好处:
1、GPU调度程序状态受保护。与协作用户空间调度器不同,GPU调度器状态在内核空间内受到保护,不会因行为不当或恶意的用户空间任务而损坏。
2、在内核空间中,对GPU调度程序状态的同步访问是微不足道的。在更新GPU调度程序数据结构时,无需升级权限以非抢占方式执行。
3、GPU调度是有效的。
4、执行计划决策。
好处:
1、需要内核空间GPGPU运行时。
这是从性能角度研究的8种体系结构中最强的一种,协作调度决策是高效的,由RTO执行。GPGPU运行时是使用调用任务的程序堆栈在内核空间中执行的,而不是单独调度的守护进程,没有IPC开销,唯一限制是对内核空间GPGPU运行时的依赖。
- Cooperative Scheduling Without Enforcement(无强制的协同调度)
上图(d)描述了协作GPU调度器的另一种软件体系结构。插入的库拦截API调用,并通过系统调用调用内核空间GPU调度器。与之前一样,GPU调度程序状态由所有任务共享,并保护其不受行为不当和恶意任务的影响。要计划API调用,GPU调度程序将控制权返回到插入的库。插入的库使用用户空间GPGPU运行时执行计划的API调用。
好处:
1、使用通用用户空间GPGPU运行时。
2、GPU调度程序状态受保护。
3、访问GPU调度程序状态很容易同步。
4、GPU调度是有效的。
坏处:
1、无法执行GPU调度决策。
为了支持用户空间GPGPU运行时,此体系结构牺牲了强制功能,通过直接访问GPGPU运行时,信任任务不会绕过插入的库。尽管有此限制,但从性能角度来看,它仍然是一个强大的体系结构。与前面的方法一样,调度决策是有效的。此外,没有与IPC或守护进程相关的开销。对于愿意实现操作系统级代码的研究人员或开发人员来说,这种体系结构是最实用的高性能选项。
再聊聊其它GPU调度相关的杂项技术。
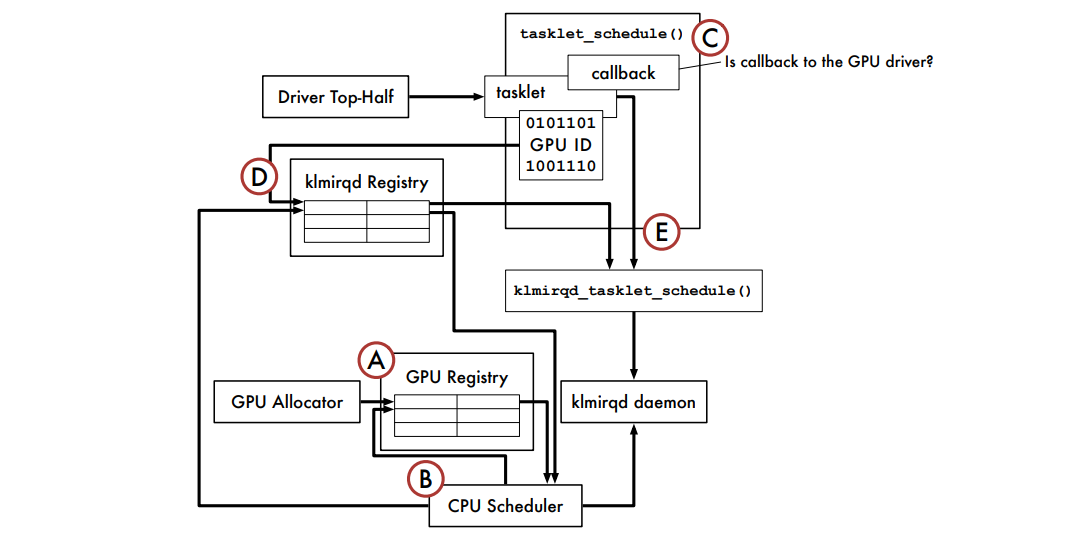
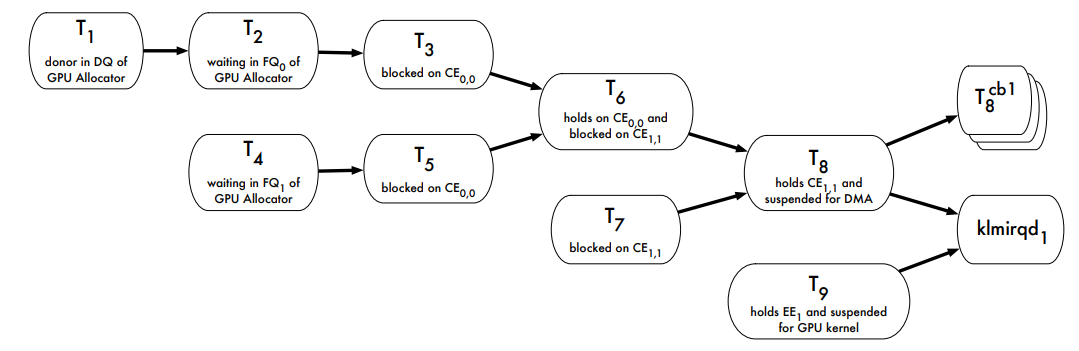
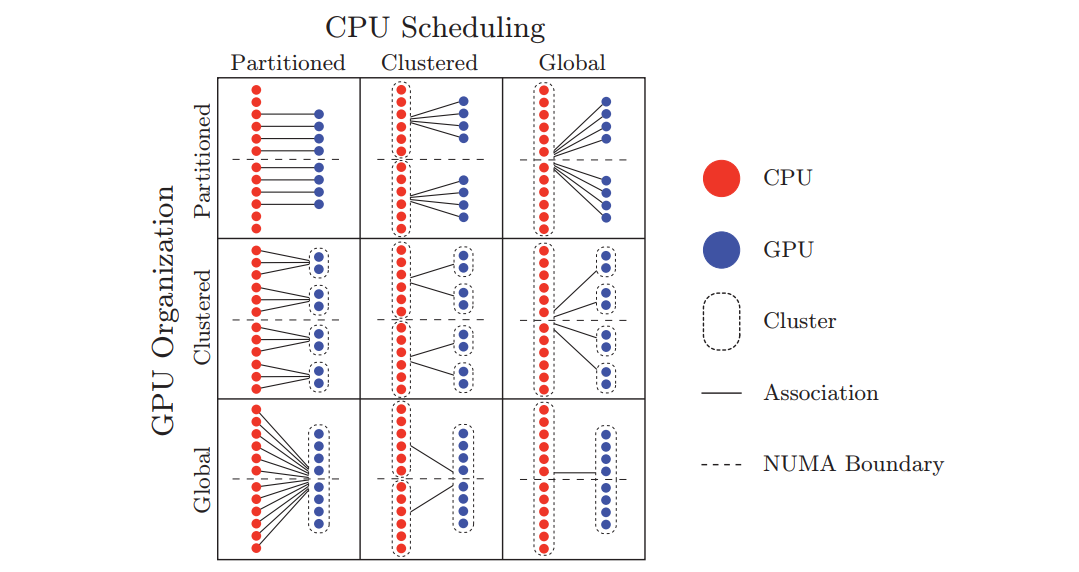
下图是名为vHybrid的CPU-GPU调度架构:
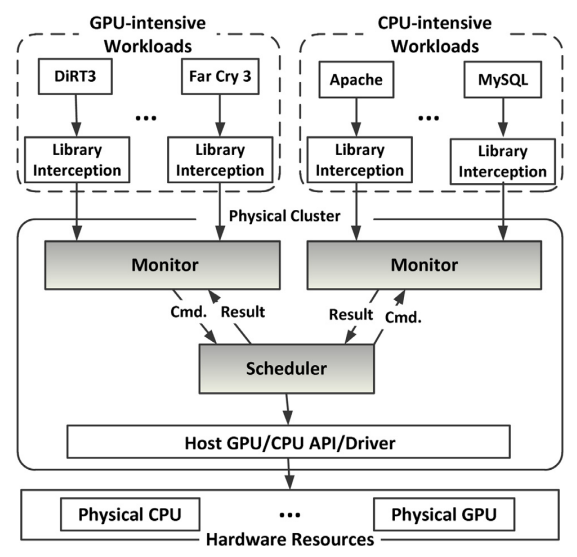
下图是使用klmirqd的GPU微线程调度基础架构:
使用GPUSync的任务的复杂执行依赖链示例:
混合平台配置:
下半部分开销处理的高级视图:
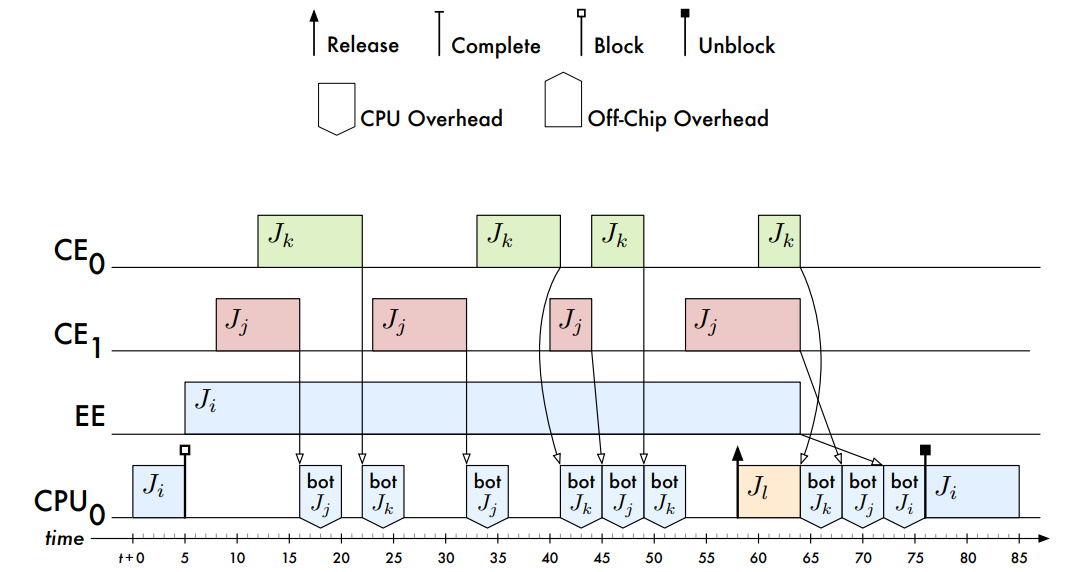
间接开销增加引擎临界区长度的情况:
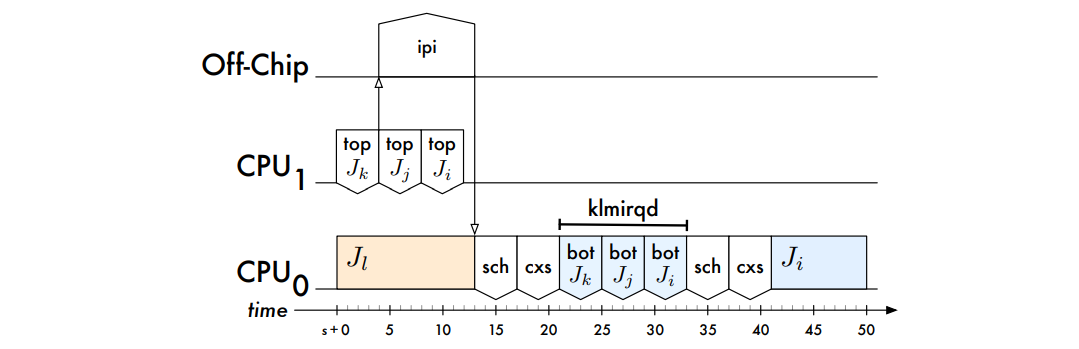
描述回调开销的调度:
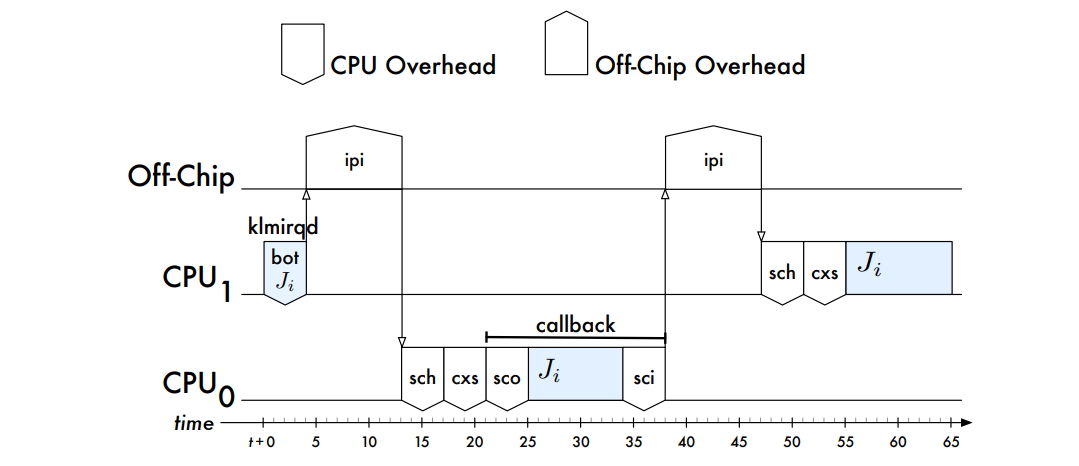
更多详情看参阅:
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
16.4 GPU驱动
16.4.1 NVIDIA
16.4.1.1 Turing架构
Turing代表了十多年来最大的架构飞跃,它提供了一种新的核心GPU架构,使PC游戏、专业图形应用程序和深度学习推断在效率和性能方面取得了重大进步。
使用新的基于硬件的加速器和混合渲染方法,Turing融合了光栅化、实时光线跟踪、AI和模拟,以实现PC游戏中难以置信的真实感、神经网络支持的惊人新效果、电影质量的交互体验,以及创建或导航复杂3D模型时的流体交互。
在核心体系结构中,Turing显著提升图形性能的关键促成因素是具有改进着色器执行效率的新GPU处理器(流式多处理器SM)体系结构,以及包括支持最新GDDR6内存技术的新内存系统体系结构。
图像处理应用程序(如ImageNet Challenge)是深度学习的首批成功案例之一,因此AI有潜力解决许多重要的图形问题也就不足为奇了。Turing的Tensor Cores为一套新的基于深度学习的神经服务提供动力,除了为基于云的系统提供快速AI推断外,还为游戏和专业图形提供惊人的图形效果。

Turing的革命性新特性。
NVIDIA Turing是世界上最先进的GPU体系结构,高端TU102 GPU包括在台积电12纳米FFN(FinFET NVIDIA)高性能制造工艺上制造的186亿个晶体管。GeForce RTX 2080 Ti Founders Edition GPU具有以下优异的计算性能:
- 14.2峰值单精度(FP32)性能的TFLOPS。
- 28.5峰值半精度(FP16)性能的TFLOPS。
- 14.2 TIPS1通过独立的整数执行单元与FP并发。
- 113.8 Tensor TFLOPS。
- 10 Giga射线/秒。
- 78 Tera RTX-OPS。
Quadro RTX 6000提供了专为专业工作流设计的卓越计算性能:
- 16.3峰值单精度(FP32)性能的TFLOPS。
- 32.6峰值半精度(FP16)性能的TFLOPS。
- 16.3 TIPS通过独立的整数执行单元与FP并发。
- 130.5张量TFLOPS。
- 10 Giga射线/秒。
- 84 Tera RTX-OPS。
此外,新的特性还有新的Streaming Multiprocessor (SM)、Turing Tensor Core、实时光追加速、新的着色改进(Mesh Shading、Variable Rate Shading、Texture-Space Shading 、Multi-View Rendering)、Deep Learning、GDDR6等等。

Turing架构的TU102 GPU。
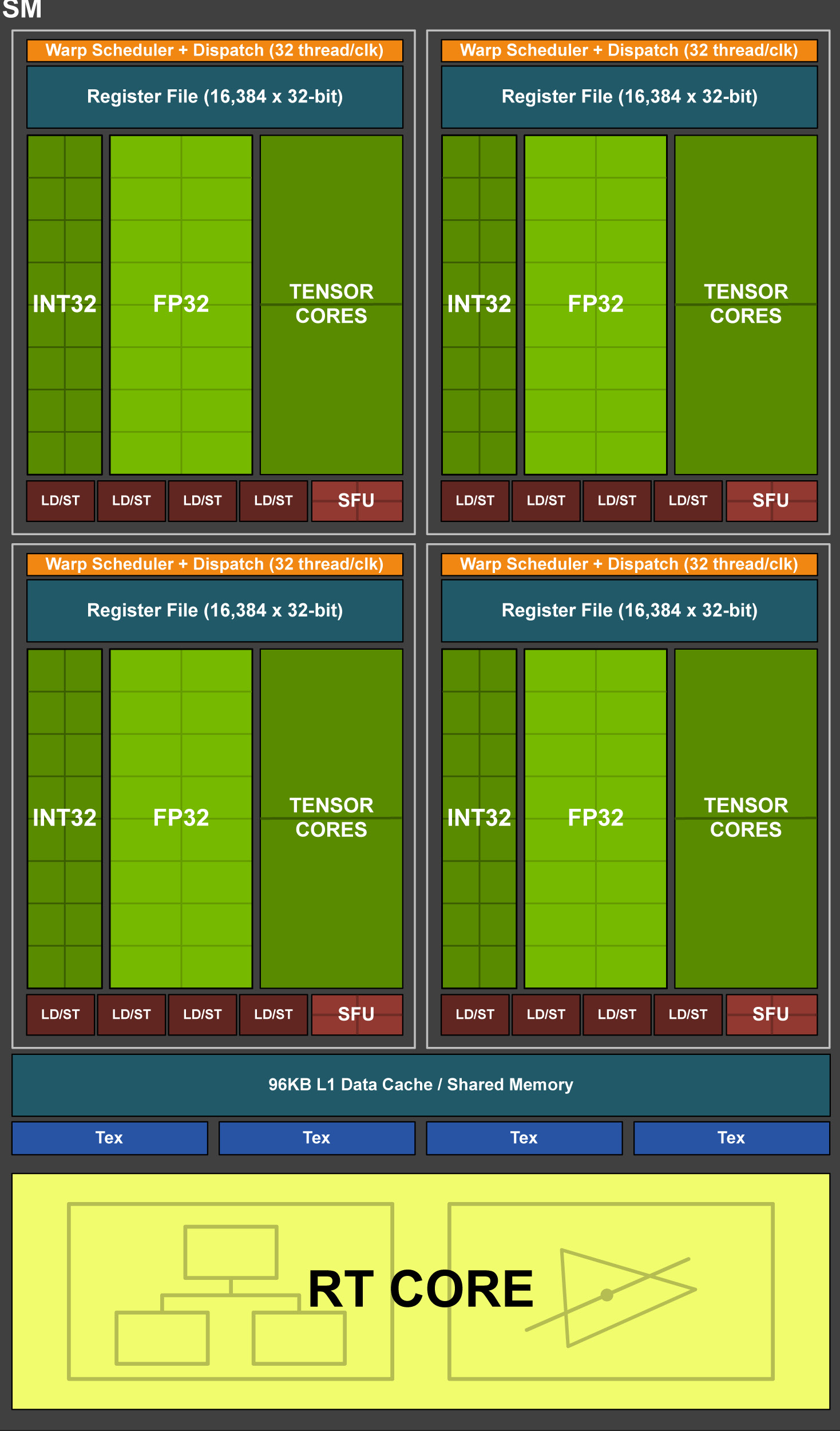
Turing TU102/TU104/TU106 Streaming Multiprocessor (SM)。
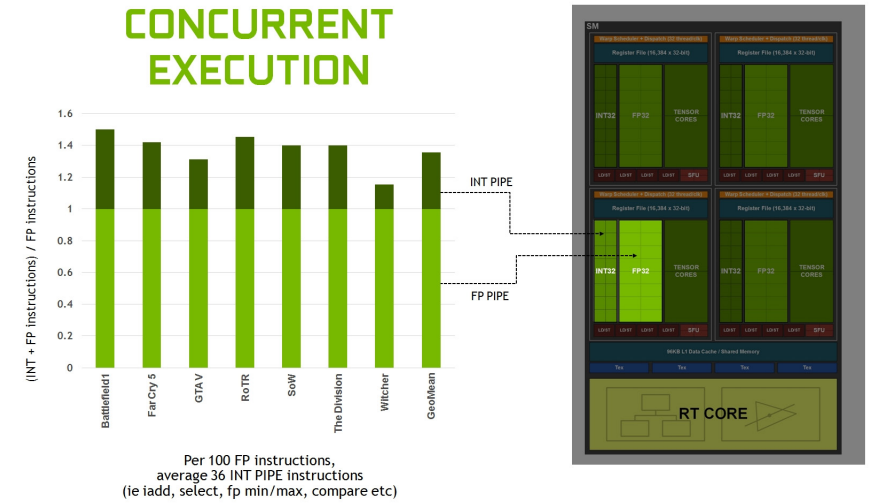
分析许多工作负载显示,平均每100个浮点操作有36个整数操作。
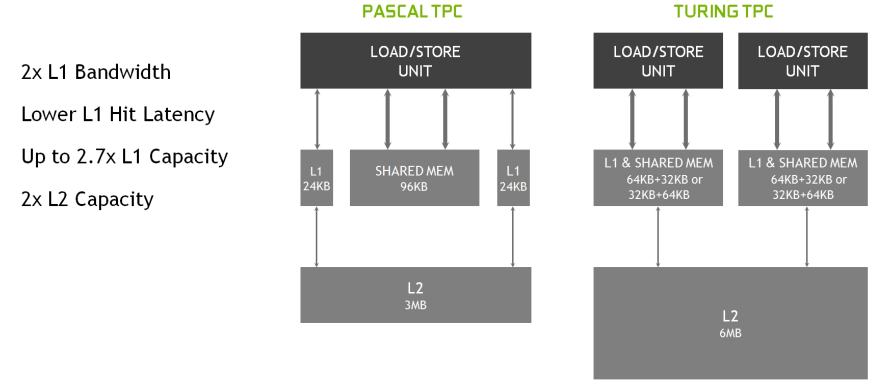
新的共享内存体系结构。
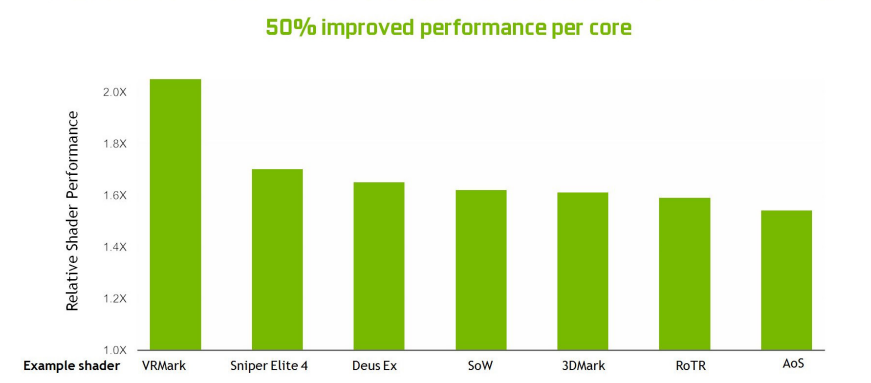
与Pascal相比,Turing Shading在许多不同工作负载下的性能加速比。
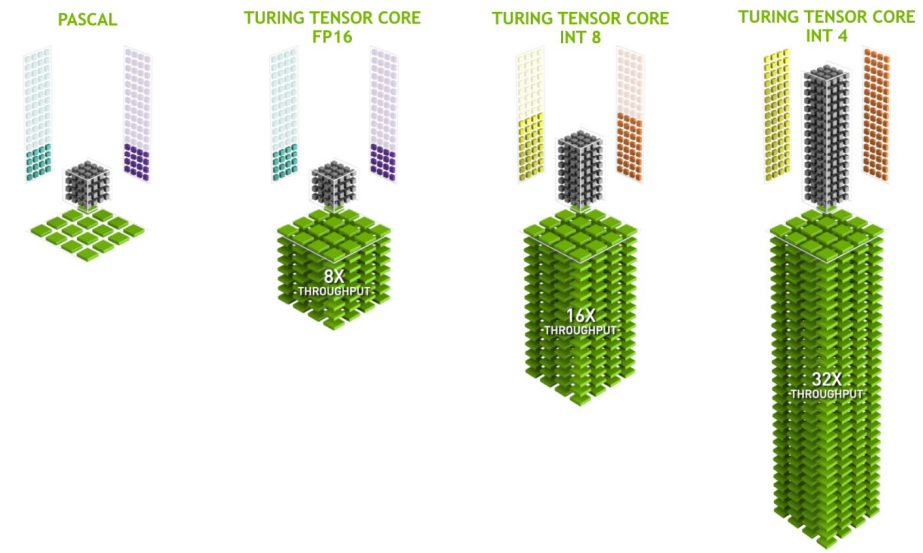
新的Turing Tensor Core为人工智能推理提供了多精度。
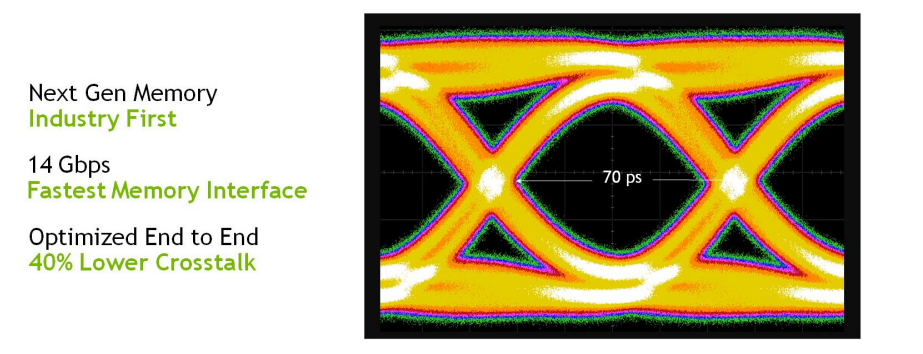
Turing GDDR6。
图灵GPU除了新的GDDR6内存子系统之外,还添加了更大、更快的二级缓存。TU102 GPU附带6 MB二级缓存,是TITAN Xp中使用的上一代GP102 GPU提供的3 MB二级缓存的两倍。TU102还提供了比GP102高得多的二级缓存带宽。与上一代NVIDIA GPU一样,图灵中的每个ROP分区包含八个ROP单元,每个单元可以处理一个颜色样本。完整的TU102芯片包含12个ROP分区,总共96个ROP。
NVIDIA GPU利用几种无损内存压缩技术来减少数据写入帧缓冲存储器时的内存带宽需求。GPU的压缩引擎有各种不同的算法,这些算法根据数据的特性确定压缩数据的最有效方式,减少了写入内存和从内存传输到二级缓存的数据量,并减少了客户端(如纹理单元)和帧缓冲区之间传输的数据量。图灵进一步改进了Pascal最先进的内存压缩算法,在GDDR6原始数据传输速率增加的基础上,进一步提升了有效带宽。如下图所示,原始带宽的增加和通信量的减少意味着与Pascal相比,Turing上的有效带宽增加了50%,对于保持体系结构平衡和支持新Turing SM体系结构提供的性能至关重要。
与基于Pascal GP102的1080 Ti相比,基于Turing TU102的RTX 2080 Ti的内存子系统和压缩(流量减少)改进提供了大约50%的有效带宽改进。
此外,Turing还开创性地增加了实时光线追踪的支持,引入了混合管线:

Turing GPU可以加速以下许多渲染和非渲染操作中使用的光线跟踪技术:
- 反射和折射。
- 阴影和环境光遮挡。
- 全局照明。
- 即时离线光照贴图烘焙。
- 美丽的照片和高质量的预览。
- 用于注视点VR渲染的主光线。
- 遮挡剔除。
- 物理、碰撞检测、粒子模拟。
- 音频模拟(例如,NVIDIA VRWorks音频构建在OptiX API之上)。
- AI可见性查询。
- 引擎内路径跟踪(非实时)生成参考屏幕截图,用于调整实时渲染技术和去噪器、材质合成和场景照明。
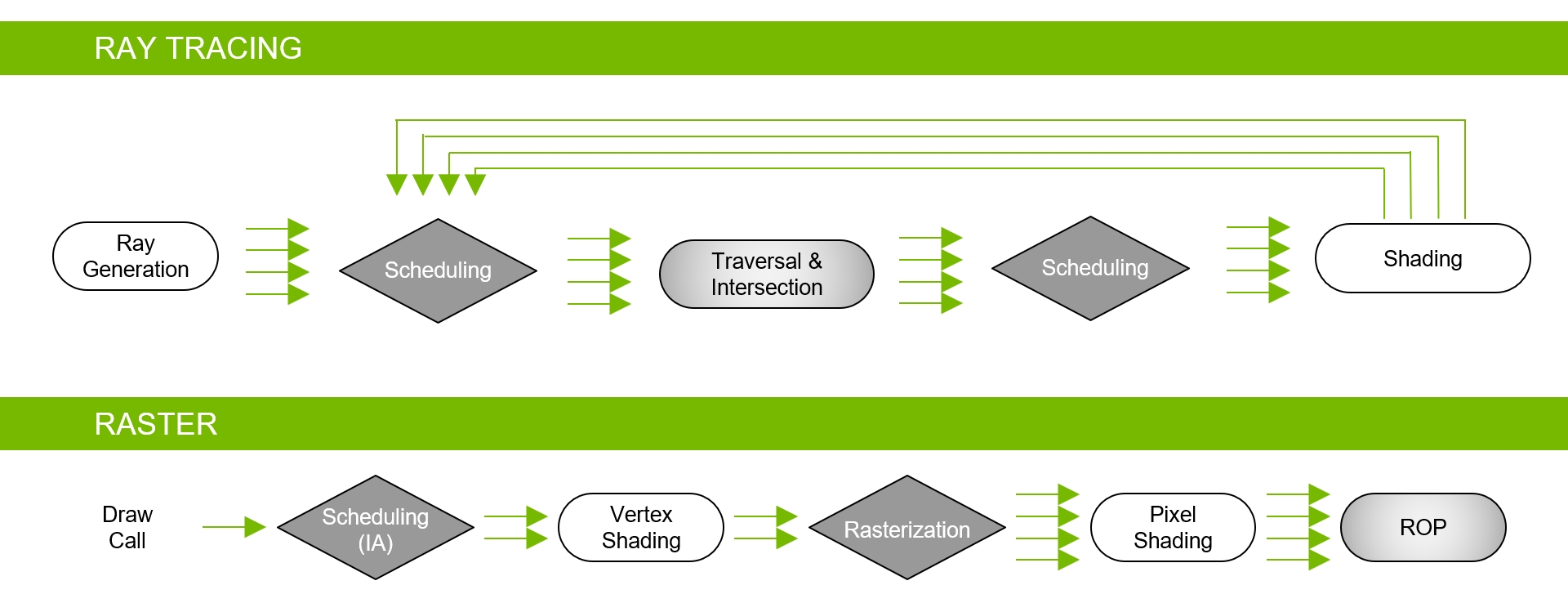
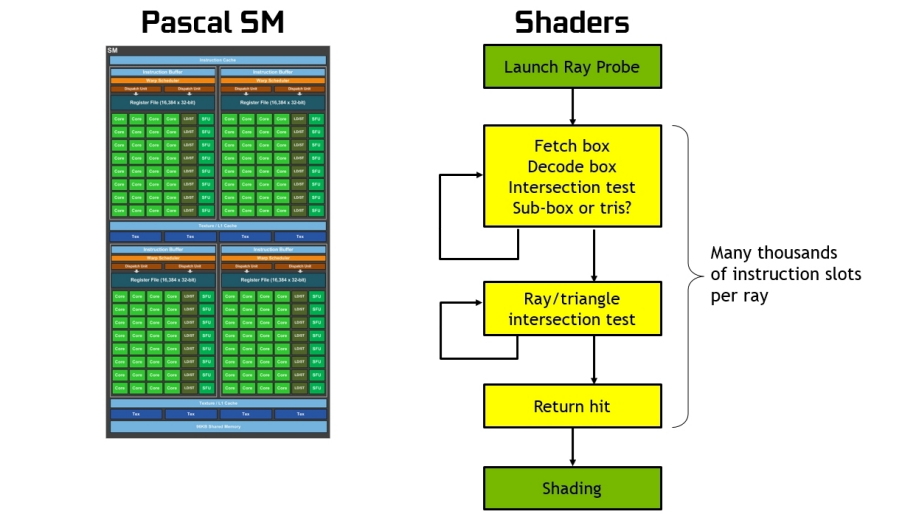
在没有硬件加速的情况下,光线跟踪需要每条光线上千个软件指令槽,以便在BVH结构中连续测试较小的包围盒,直到可能碰到三角形为止。这是一个计算密集型的过程,如果没有基于硬件的光线跟踪加速,就不可能在GPU上实时完成(见下图)。
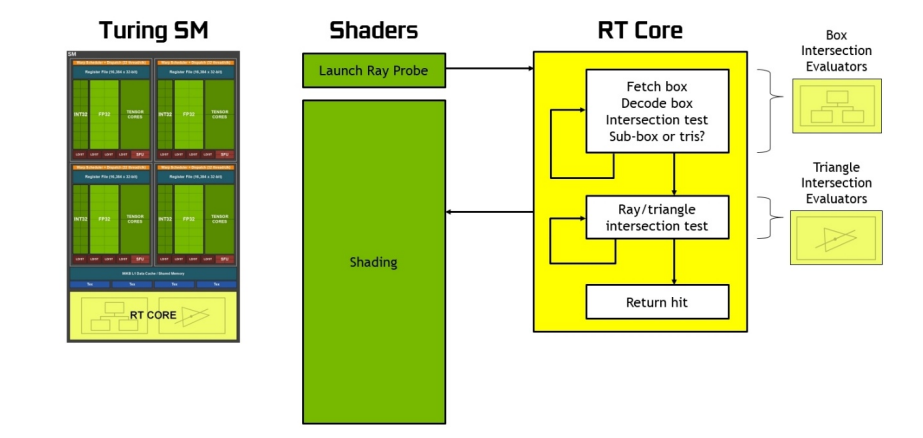
下图说明了传统的光栅化和着色过程,3D场景被光栅化并转换为屏幕空间中的像素,对像素进行可见性测试、外观着色测试和深度测试。所有操作都发生在相同的屏幕空间像素网格上,在相同的像素上。
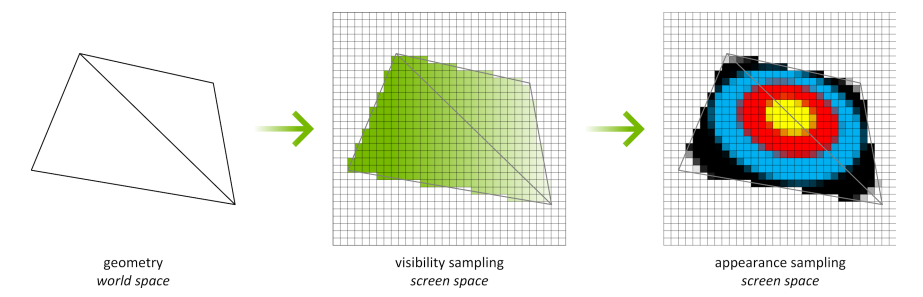
使用纹理空间着色(Texture Space Shading,TSS),可见性采样(光栅化和z测试)和外观采样(着色)这两个主要操作可以解耦,并以不同的速率、在不同的采样网格上、甚至在不同的时间轴上执行。着色过程不再直接绑定到屏幕空间像素,而是发生在纹理空间中。在下图中,几何体仍被光栅化以生成屏幕空间像素,可见性测试仍在屏幕空间中进行。然而,不是在屏幕空间中着色,而是发现需要覆盖输出像素的纹理。换句话说,屏幕空间像素的足迹映射到单独的纹理空间中,并在纹理空间中对关联的texel进行着色。映射到纹理空间是一种标准的纹理映射操作,对LOD和各向异性过滤等具有相同的控制。为了生成最终的屏幕空间像素,我们从着色纹理中采样。纹理是根据示例请求按需创建的,仅为引用的纹理生成值。
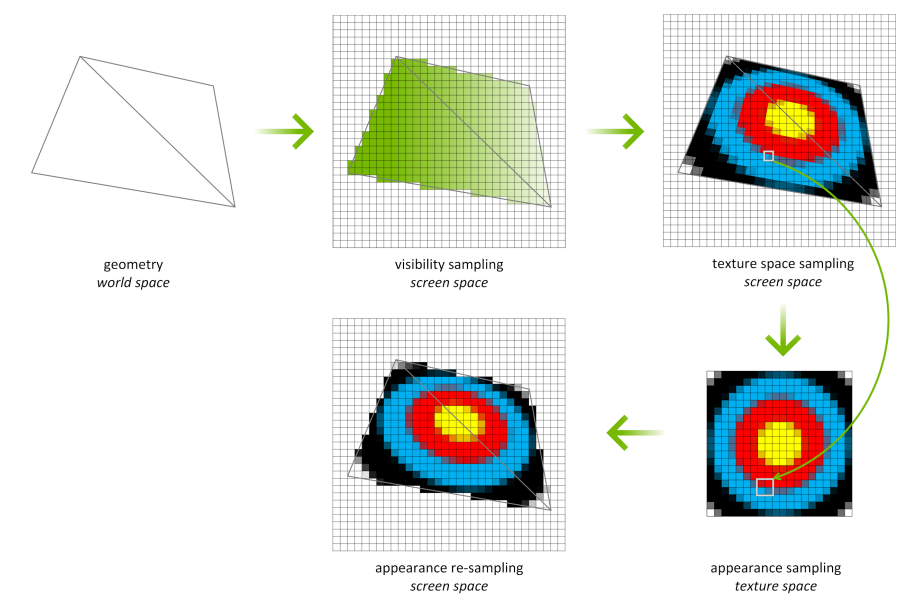
TSS的一个示例用例是提高VR渲染的效率,下图显示了VR渲染中TSS的一个示例用例。在VR中,渲染一对立体图像,左眼可见的几乎所有元素也显示在右眼视图中。使用TSS,我们可以对整个左眼视图进行着色,然后通过从完成的左眼视图采样来渲染右眼视图。右眼视图只需在未找到有效样本的情况下对新纹理进行着色(例如,从左眼角度看,背景对象在视图中被遮挡,但右眼可见)。

**多视图渲染(MVR)**允许开发人员从多个视点高效地绘制场景,甚至以不同姿势绘制角色的多个实例,所有这些都在一个通道中完成。Turing硬件每个过程最多支持四个视图,在API级别最多支持32个视图。通过只提取一次几何体并对其着色,Turing可以在渲染多个版本时以最佳方式处理三角形及其关联的顶点属性。当通过D3D12视图实例化API访问时,开发人员只需使用变量SV_ViewID来索引不同的变换矩阵、引用不同的混合权重或控制他们喜欢的任何着色器行为,这些行为取决于他们正在处理的视图。
下图显示了200° FOV HMD的配置,其中使用了两个倾斜面板,需要MVR更大的表现力。MVR的灵活性也有利于支持标准立体VR显示器的更精确校准,以与单个用户的面部对齐。在立体渲染中,眼睛只是在X方向上相互偏移的简单假设并不完全正确,实际上还有一些额外的不对称,需要独立投影才能获得最高的保真度对齐。

200°FOV HMD,其中使用两个倾斜面板,并受益于MVR。

MVR单通道级联阴影贴图渲染。
16.4.1.2 Ampere架构
NVIDIA Ampere体系架构GPU系列的最新成员GA102和GA104,GA102和GA104是新英伟达“GA10x”级Ampere架构GPU的一部分,GA10x GPU基于革命性的NVIDIA Turing GPU架构。
GeForce RTX 3090是GeForce RTX系列中性能最高的GPU,专为8K HDR游戏设计。凭借10496个CUDA内核、24GB GDDR6X内存和新的DLSS 8K模式,它可以在8K@60fps。GeForce RTX 3080的性能是GeForce RTX 2080的两倍,实现了GPU有史以来最大的一代飞跃,GeForce RTX 3070的性能可与NVIDIA上一代旗舰GPU GeForce RTX 2080 Ti相媲美,GA10x GPU中新增的HDMI 2.1和AV1解码功能允许用户使用HDR以8K的速度传输内容。
NVIDIA A40 GPU是数据中心在性能和多工作负载能力方面的一次革命性飞跃,它将一流的专业图形与强大的计算和AI加速相结合,以应对当今的设计、创意和科学挑战。A40具有与RTX A6000相同的内核数量和内存大小,将为下一代虚拟工作站和基于服务器的工作负载提供动力。NVIDIA A40的能效比上一代高出2倍,它为专业人士带来了光线跟踪渲染、模拟、虚拟制作等最先进的功能。

Ampere GA10x体系结构具有巨大的飞跃。
GA102的关键特性有2倍FP32处理、第二代RT Core、第三代Tensor Core、GDDR6X和GDDR6内存、PCIe Gen 4等。
与之前的NVIDIA GPU一样,GA102由图形处理集群(Graphics Processing Cluster,GPC)、纹理处理集群(Texture Processing Cluster,TPC)、流式多处理器(Streaming Multiprocessor,SM)、光栅操作器(Raster Operator,ROP)和内存控制器组成。完整的GA102 GPU包含7个GPC、42个TPC和84个SM。
GPC是主要的高级硬件块,所有关键图形处理单元都位于GPC内部。每个GPC都包括一个专用的光栅引擎,现在还包括两个ROP分区(每个分区包含八个ROP单元),是NVIDIA Ampere Architecture GA10x GPU的一个新功能。GPC包括六个TPC,每个TPC包括两个SM和一个PolyMorph引擎。
GA102 GPU还具有168个FP64单元(每个SM两个),FP64 TFLOP速率是FP32操作TFLOP速率的1/64。包括少量的FP64硬件单元,以确保任何带有FP64代码的程序都能正确运行,包括FP64 Tensor Core代码。
GA10x GPU中的每个SM包含128个CUDA核、四个第三代Tensor核、一个256 KB的寄存器文件、四个纹理单元、一个第二代光线跟踪核和128 KB的L1/共享内存,这些内存可以根据计算或图形工作负载的需要配置为不同的容量。GA102的内存子系统由12个32位内存控制器组成(共384位),512 KB的二级缓存与每个32位内存控制器配对,在完整的GA102 GPU上总容量为6144 KB。
Ampere架构还对ROP执行了优化。在以前的NVIDIA GPU中,ROP绑定到内存控制器和二级缓存。从GA10x GPU开始,ROP是GPC的一部分,通过增加ROP的总数和消除扫描转换前端和光栅操作后端之间的吞吐量不匹配来提高光栅操作的性能。每个GPC有7个GPC和16个ROP单元,完整的GA102 GPU由112个ROP组成,而不是先前在384位内存接口GPU(如前一代TU102)中可用的96个ROP。此方法可改进多采样抗锯齿、像素填充率和混合性能。
在SM架构方面,图灵SM是NVIDIA的第一个SM体系结构,包括用于光线跟踪操作的专用内核。Volta GPU引入了张量核,Turing包括增强的第二代张量核。Turing和Volta SMs支持的另一项创新是并行执行FP32和INT32操作。GA10x SM改进了上述所有功能,同时还添加了许多强大的新功能。与以前的GPU一样,GA10x SM被划分为四个处理块(或分区),每个处理块都有一个64 KB的寄存器文件、一个L0指令缓存、一个warp调度程序、一个调度单元以及一组数学和其他单元。这四个分区共享一个128 KB的一级数据缓存/共享内存子系统。与每个分区包含两个第二代张量核、总共八个张量核的TU102 SM不同,新的GA10x SM每个分区包含一个第三代张量核,总共四个张量核,每个GA10x张量核的功能是图灵张量核的两倍。与Turing相比,GA10x SM的一级数据缓存和共享内存的组合容量要大33%。对于图形工作负载,缓存分区容量是图灵的两倍,从32KB增加到64KB。

GA10x Streaming Multiprocessor (SM) 。
GA10x SM继续支持图灵支持的双速FP16(HFMA)操作。与TU102、TU104和TU106图灵GPU类似,标准FP16操作由GA10x GPU中的张量核处理。FP32吞吐量的比较X因子如下表:
| Turing | GA10x | |
|---|---|---|
| FP32 | 1X | 2X |
| FP16 | 2X | 2X |
如前所述,与前一代图灵体系结构一样,GA10x具有用于共享内存、一级数据缓存和纹理缓存的统一体系结构。这种统一设计可以根据工作负载进行重新配置,以便根据需要为L1或共享内存分配更多内存。一级数据缓存容量已增加到每个SM 128 KB。在计算模式下,GA10x SM将支持以下配置:
- 128 KB L1 + 0 KB Shared Memory
- 120 KB L1 + 8 KB Shared Memory
- 112 KB L1 + 16 KB Shared Memory
- 96 KB L1 + 32 KB Shared Memory
- 64 KB L1 + 64 KB Shared Memory
- 28 KB L1 + 100 KB Shared Memory
Ampere架构的RT Core比Turing的RT Core的射线/三角形相交测试速度提高了一倍:
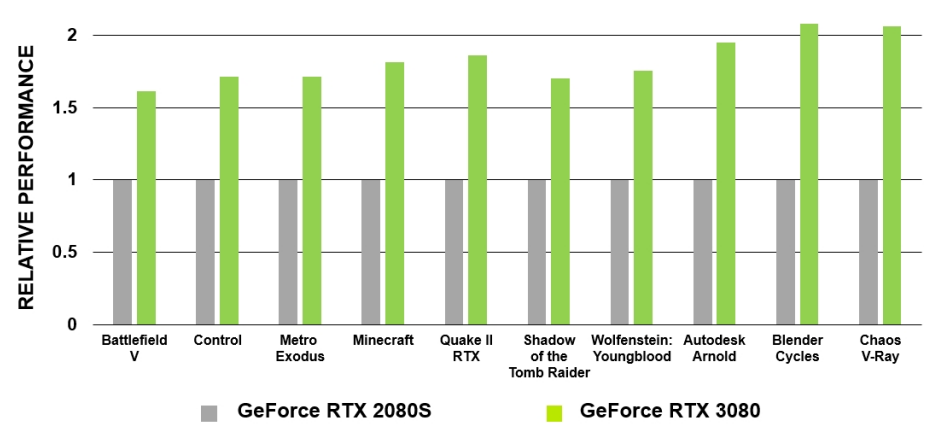
GA10x GPU通过一种新功能增强了先前NVIDIA GPU的异步计算功能,该功能允许在每个GA10x GPU SM中同时处理RT Core和图形或RT Core和计算工作负载。GA10x SM可以同时处理两个计算工作负载,并且不像以前的GPU代那样仅限于同时计算和图形,允许基于计算的降噪算法等场景与基于RT Core的光线跟踪工作同时运行。

相比Turing架构,NVIDIA Ampere体系结构在渲染同一游戏中的同一帧时,可大大提高性能:
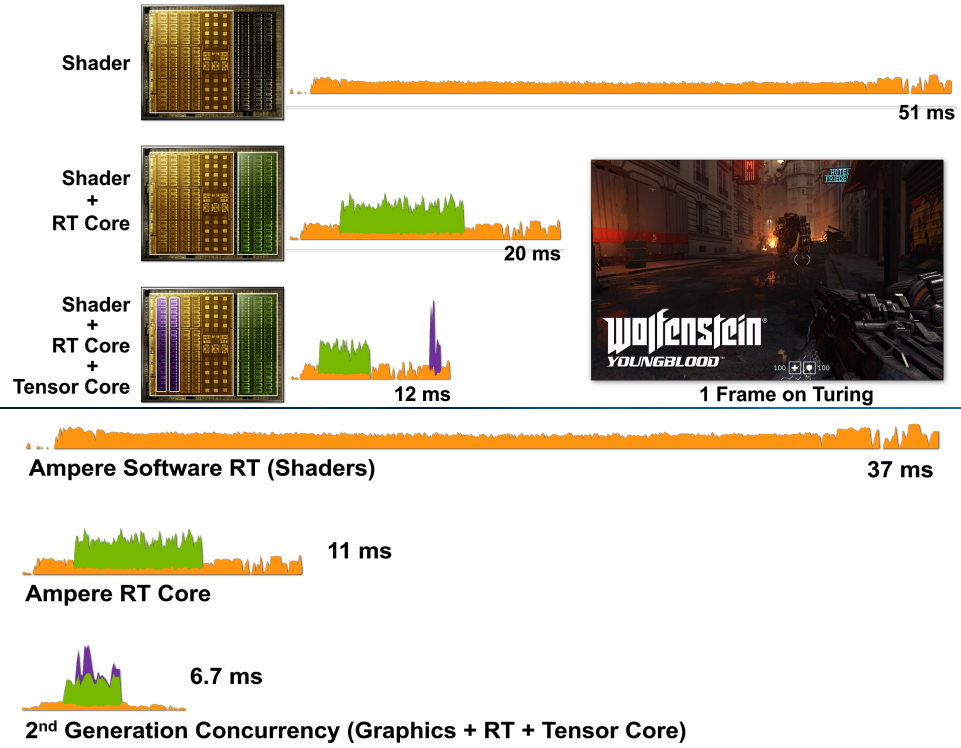
上:基于图灵的RTX 2080超级GPU渲染Wolfenstein的一帧:仅使用着色器核心(CUDA核心)、着色器核心+RT核心和着色器核心+RT核心+张量核心的Youngblood。请注意,在添加不同的RTX处理内核时,帧时间逐渐减少。
下:基于安培体系结构的RTX 3080 GPU渲染一帧Wolfenstein:Youngblood仅使用着色器核心(CUDA核心)、着色器核心+RT核心和着色器核心+RT核心+张量核心。
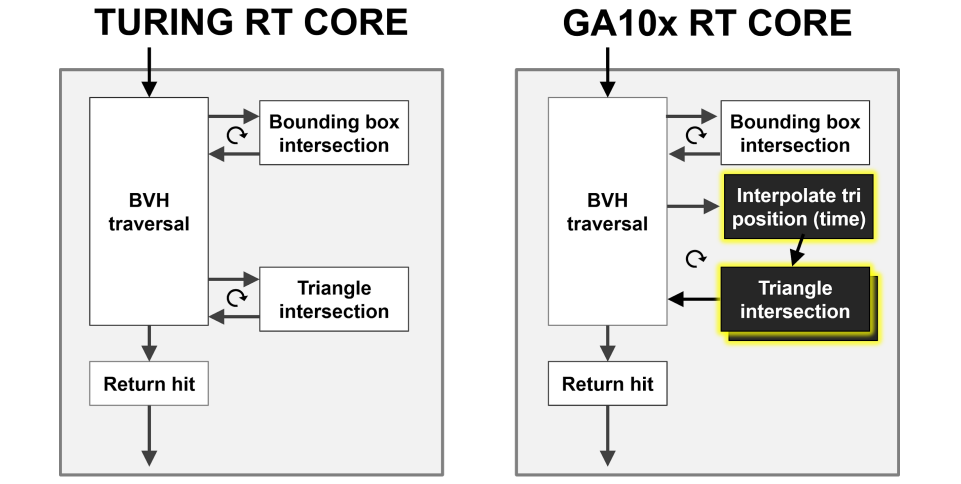
GA10x RT Core使光线/三角形相交测试速率比Turing RT Core提高了一倍,还添加了一个新的插值三角形位置加速单元,以协助光线跟踪运动模糊操作。
在启用稀疏性的情况下,GeForce RTX 3080提供的FP16 Tensor堆芯操作峰值吞吐量是GeForce RTX 2080 Super的2.7倍,后者具有密集的Tensor堆芯操作:
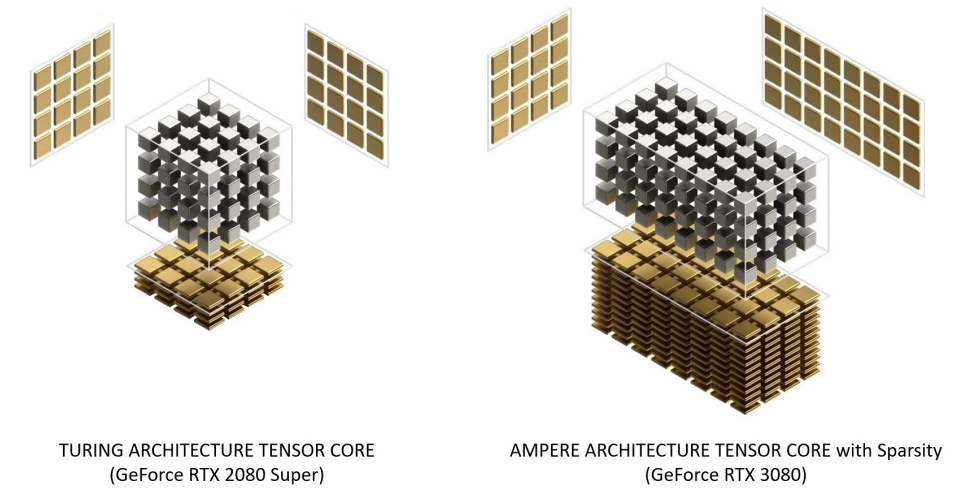
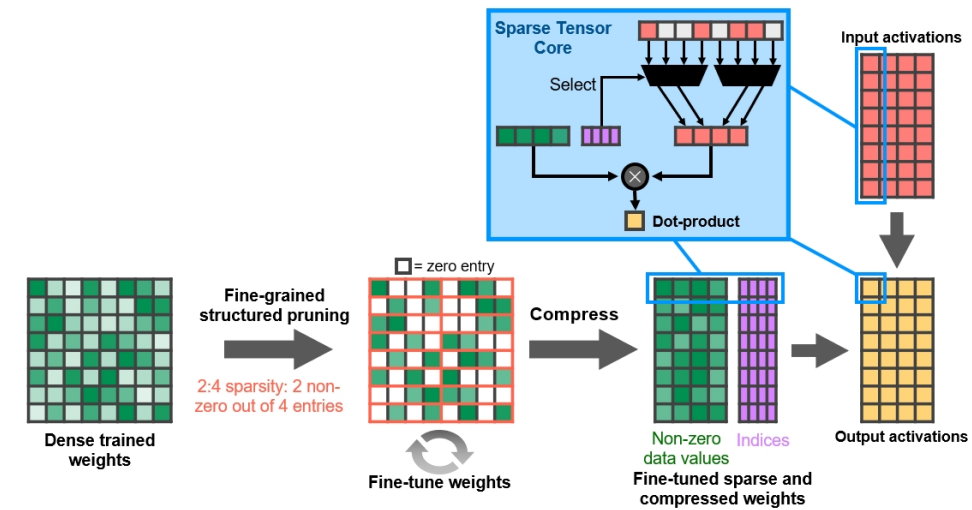
细粒度结构化稀疏性使用四取二非零模式修剪训练权重,然后是微调非零权重的简单通用方法。对权重进行压缩,使数据占用和带宽减少2倍,稀疏张量核心操作通过跳过零使数学吞吐量加倍。(下图)
下图显示了GDDR6(左)和GDDR6X(右)之间的数据眼(data eye)比较,通过GDDR6X接口可以以GDDR6的一半频率传输相同数量的数据,或者,在给定的工作频率下,GDDR6X可以使有效带宽比GDDR6增加一倍。
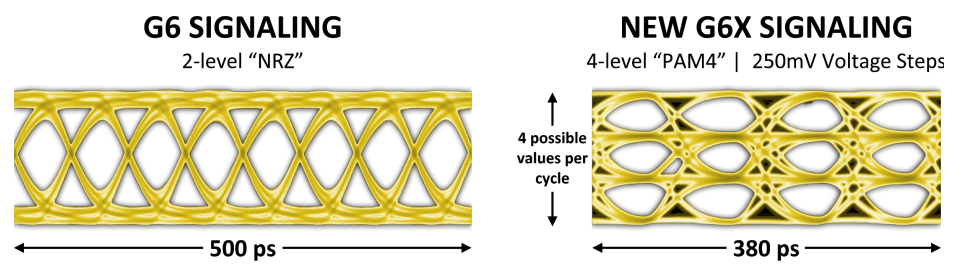
GDDR6X使用PAM4信令提高了性能和效率。
为了解决PAM4信令带来的信噪比挑战,开发了一种名为MTA(最大传输消除,见下图)的新编码方案,以限制高速信号的转移。MTA可防止信号从最高电平转换到最低电平,反之亦然,从而提高接口信噪比。它是通过在编码管脚上传输的字节中为每个管脚分配一部分数据突发(时间交错),然后使用明智选择的码字将数据突发的剩余部分映射到没有最大转换的序列来实现的。此外,还引入了新的接口培训、自适应和均衡方案。最后,封装和PCB设计需要仔细规划和全面的信号和电源完整性分析,以实现更高的数据速率。

在传统的存储模型中,游戏数据从硬盘读取,然后从系统内存和CPU传输,然后再传输到GPU,使得IO常常成为游戏的性能瓶颈:
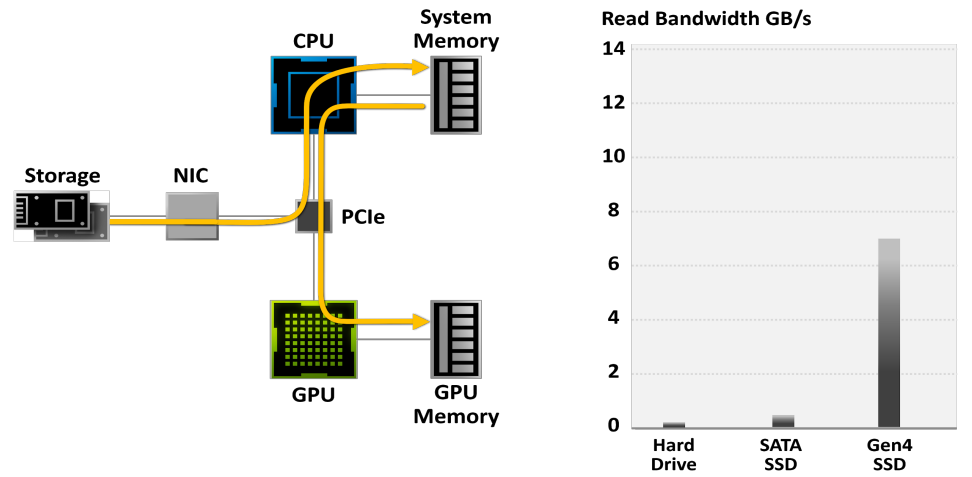
使用传统的存储模型,游戏解压缩可以消耗Threadripper CPU上的所有24个内核。现代游戏引擎已经超过了传统存储API的能力。需要新一代的输入/输出体系结构。数据传输速率为灰色条,所需CPU内核为黑色/蓝色块。需要压缩数据,但CPU无法跟上:
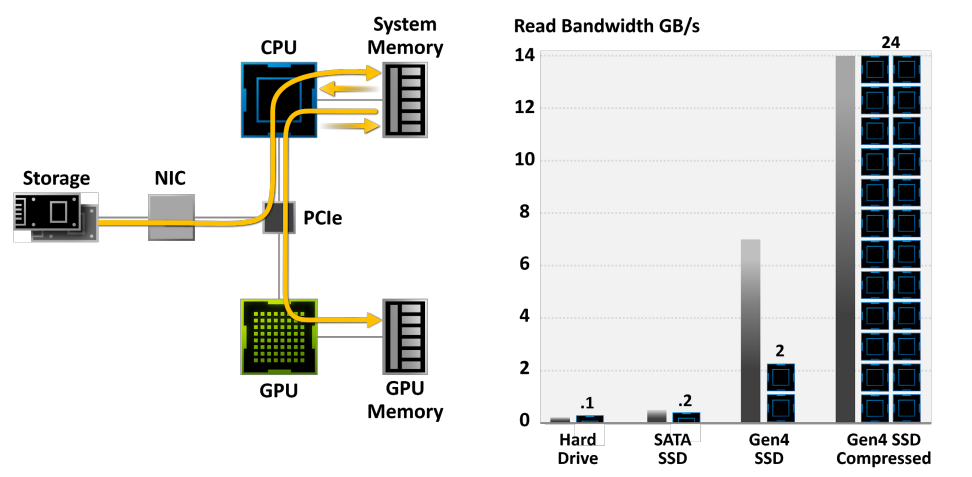
NVIDIA RTX IO插入Microsoft即将推出的DirectStorage API,这是一种新一代存储体系结构,专为配备最先进NVMe SSD的游戏PC和现代游戏所需的复杂工作负载而设计。总之,专门为游戏定制的流线型和并行化API可以显著减少IO开销,并最大限度地提高从NVMe SSD到支持RTX IO的GPU的性能/带宽。具体而言,NVIDIA RTX IO带来了基于GPU的无损解压缩,允许通过DirectStorage进行的读取保持压缩,并传送到GPU进行解压缩。此技术可消除CPU的负载,以更高效、更压缩的形式将数据从存储器移动到GPU,并将I/O性能提高了两倍。
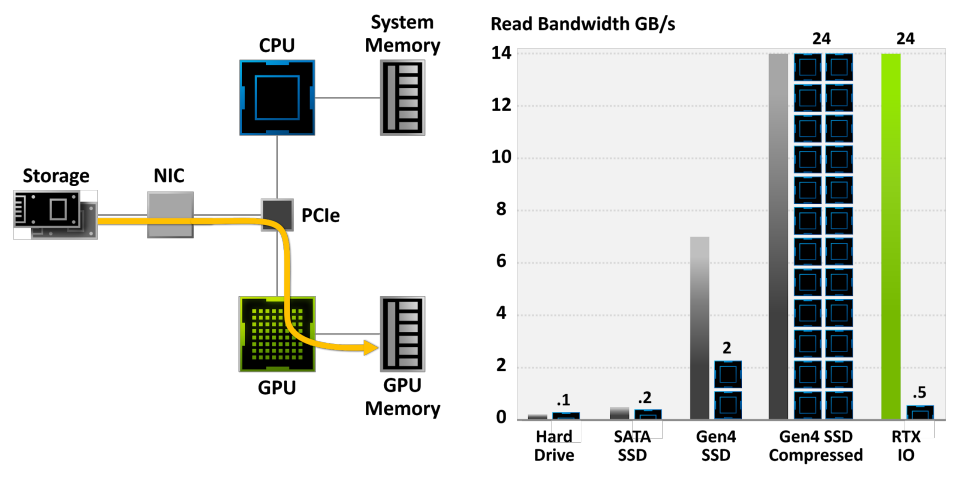
RTX IO提供100倍的吞吐量,20倍的CPU利用率。数据传输速率为灰色和绿色条,所需CPU内核为黑色/蓝色块。
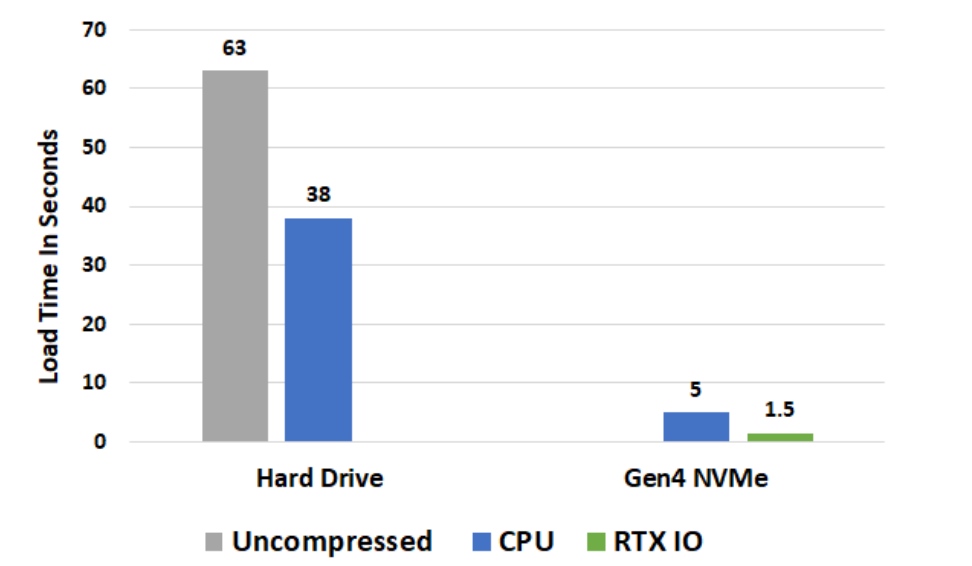
关卡加载时间比较。负载测试在24核Threadripper 3960x平台上运行,原型Gen4 NVMe m.2 SSD,alpha软件。
16.4.1.3 Nouveau
“Nouveau”是法语中“new”的意思。Nouveau项目旨在为nVidia卡构建高质量、免费/自由的软件驱动程序,Nouveau由Linux内核KMS驱动程序(Nouveau)、Mesa中的Gallium3D驱动程序和Xorg DDX(xf86 video Nouveau)组成,内核组件也已移植到NetBSD。官网是https://nouveau.freedesktop.org/index.html。
所有GPU均支持2D/3D加速(GA10x除外),大多数pre-Maxwell卡支持视频解码加速,在GM10x Maxwell、Kepler和Tesla G94-GT218 GPU上支持手动性能级别选择。GM20x和更新的GPU重新锁定的希望渺茫,因为如今固件需要NVIDIA签署才能获得必要的访问权限。最近的更新是2021年1月:Linux 5.11中合并了GA10x内核模式设置支持。
Nouveau最初使用Mesa 3D的直接渲染基础设施(DRI)渲染3D计算机图形,允许直接从3D应用程序使用图形处理单元(GPU)加速3D绘制;但在2008年2月,DRI支持方面的工作停止了,并转移到了新的Gallium3D。2013年9月23日Nvidia公开宣布,他们将发布一些关于其GPU的文档,旨在解决影响Nvidia GPU与nouveau的现成可用性的领域。2016年7月9日,Red Hat员工Ben Skeggs提交了一个补丁,该补丁将对GeForce GTX 1070和GeForce GTX 1080品牌图形卡上基于Pascal的GP104芯片的支持添加到Linux内核中。XDC2016介绍了2016年的现状和未来的工作,FOSDEM上显示了OpenCL的新工作状态。2019年,NVidia提供了一些有关开普勒、麦克斯韦、帕斯卡和沃尔塔芯片组的文档。
除了Nouveau,支持NVIDIA显卡的驱动还有pscnv、DirectFB nVidia driver、BeOS/Haiku nVidia driver、Utah-GLX、xfree 3.3.3 nvidia driver等。2022年5月,NVIDIA释放了支持最新NV GPU的Linux内核驱动模块,源码在:NVIDIA Linux Open GPU Kernel Module Source。
16.4.2 AMD
AMD Radeon软件是一种用于高级Micro Devices图形卡和APU的设备驱动程序和实用软件包。其图形用户界面由Electron构建,并与64位Windows和Linux发行版兼容。
该软件以前称为AMD Radeon Settings、AMD Catalyst和ATI Catalyst。AMD Radeon软件旨在支持GPU或APU芯片上的所有功能块,除了用于渲染的指令代码外,还包括显示控制器及其用于视频解码(统一视频解码器(UVD))和视频编码(视频编码引擎(VCE))的SIP块。设备驱动程序还支持AMD TrueAudio,是一个用于执行声音相关计算的SIP块。
Radeon软件包括的功能:游戏配置文件管理、超频和降频、性能监控、录制和流媒体、捕获的视频和屏幕截图管理、软件更新通知、升级advisor等。另外还支持多显示器、视频加速、音频加速、电量节省、GPGPU、等功能,还支持D3D、Mantle、OpenGL、Vulkan、OpenCL等图形API。
GCN通过结合硬件和驱动程序支持,与缓存一致性一起引入了虚拟内存。虚拟内存消除了内存管理中最具挑战性的方面,并提供了新的功能。AMD在高性能图形和微处理器方面的独特专长尤其有益,因为GCN的虚拟内存模型已被仔细定义为与x86兼容。此举简化了初始产品中CPU和离散GPU之间的数据移动,更重要的是,它为CPU和GPU无缝共享的单个地址空间铺平了道路。共享而非复制数据对于性能和能效至关重要,也是AMD加速处理单元(APU)等异构系统中的关键元素。
GCN命令处理器负责从驱动程序接收高级API命令,并将其映射到不同的处理管道。GCN有两条主要管道。异步计算引擎(ACE)负责管理计算着色器,而图形命令处理器处理图形着色器和固定功能硬件。每个ACE都可以处理并行的命令流和图形命令处理器可以为每种着色器类型提供单独的命令流,从而创建大量的工作来利用GCN的多任务。
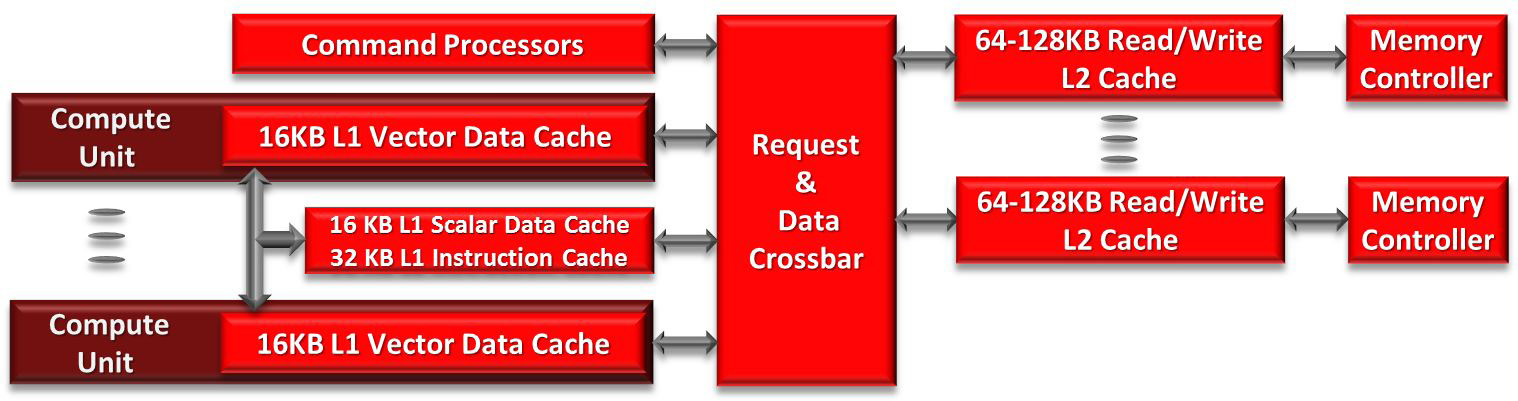
AMD GCN架构的缓存层次结构。
16.4.3 Intel
下图显示了Intel图形平台上完整的功能栈所需的成分,以及每个组件的简要说明。
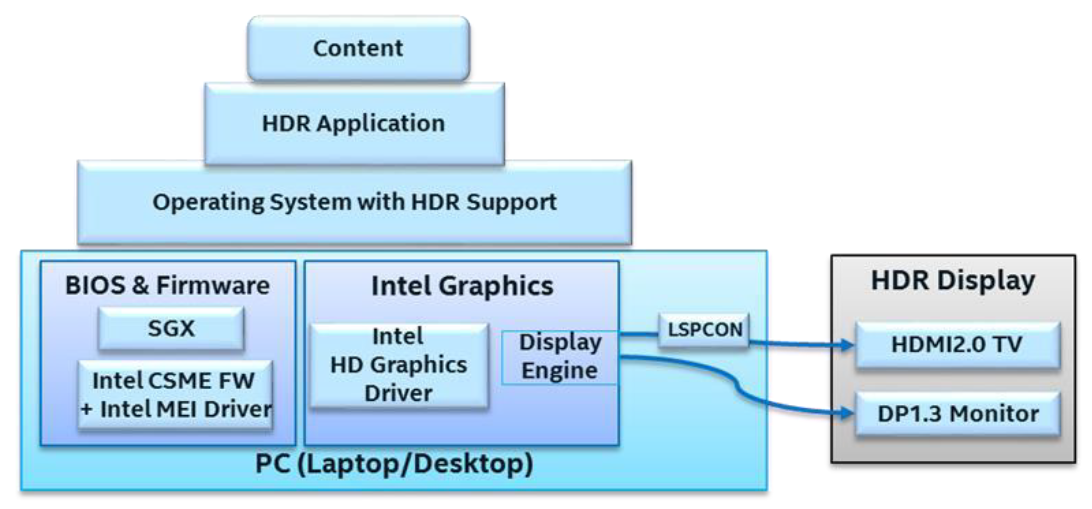
- Intel Graphics Controller:集成在第7代Intel Core处理器及更新版本中的图形引擎硬件,用于解码和呈现HDR内容。其显示引擎通过HDMI和DisplayPort电缆将HDR信号传输到HDR显示器。
- Intel Graphics Driver:除上述相应的硬件外,还需要特定的驱动程序版本,始终建议获取intel.com、PC OEM网站或通过Windows Update上发布的最新图形驱动程序。
- Operating System:Windows 10操作系统的适当版本,Windows 10 Fall Creators Update(RS3)是任何较新版本都适用的最低操作系统版本。
- LSPCON:要在第7代Intel Core处理器上通过HDMI实现HDR信令,主板上必须有一个称为LSPCON(电平移位器和协议转换器)的额外硬件组件,是一种必须由PC制造商安装的组件,最终用户无法添加。注意,LSPCON仅适用于HDMI,而不适用于DisplayPort。在使用第9代Intel Core处理器或更高版本HDMI2的较新平台中,原生支持2.0,因此不需要LSPCON支持。
- LSPCON FW:LSPCON上需要正确版本的FW。
- System BIOS:特别是对于超高清蓝光播放,系统BIOS必须正确配置以支持Intel Software Guard Extensions(SGX)。
- Intel CSME FW:需要Intel Management Engine(ME)固件版本才能实现必要的HW-DRM支持和HDCP2.2高级HDR视频内容需要链路保护,通常包含在系统制造商拥有的系统BIOS中。
- Intel MEI Driver:必须安装此驱动程序,以便软件可以与ME FW通信。
- Application:播放HDR内容需要特定的应用程序和internet浏览器(如Microsoft Edge)。
- Content:HDR视频文件来自不同的来源,要从某些流媒体提供商(如Netflix)接收HDR内容,必须具有适当的计划/帐户类型。
- HDR display:少数设备的内置显示器上提供了称为扩展动态范围(EDR)的部分HDR体验,但笔记本电脑和平板电脑的内置显示器尚无法实现真正的HDR播放。
- Display connector:电脑上连接到HDR显示器的物理显示接口(接口)可以是HDMI、DisplayPort、mini DisplayPort或USB Type-C。寻找HDCP2.2支持很重要,可将高级内容传输到显示器所需的。
- Cable/ dongle:对于支持本机HDMI或DP连接器的PC,可以直接使用适当的电缆连接到显示器。如果PC带有USB Type-C端口(支持Thunderbolt 3或DP Alt模式),则需要适配器或加密狗将USB Type-C转换为HDMI2.0或DisplayPort,以及支持HDCP2,miniDP连接器也需要类似的适配器,此类适配器可从第三方供应商处获得,如Club3D、BelkinUptab等。
另外,**Intel Graphics Media Accelerator(GMA)**是Intel于2004年推出的一系列集成图形处理器,取代了早期的Intel Extreme Graphics系列,并由Intel HD和Iris Graphics系列取代,本系列面向低成本图形解决方案市场。该系列产品集成在主板上,图形处理能力有限,并使用计算机的主内存而不是专用视频内存进行存储。它们通常出现在上网本、低价笔记本电脑和台式电脑上,以及不需要高水平图形功能的商务电脑上。在2007年初,大约90%的PC主板都有一个集成GPU。
16.4.4 Qualcomm
Freedreno是一个开源的逆向工程项目,为高通公司的Adreno图形硬件实现了一个完全开源的驱动程序。Freedreno由MSM DRM驱动程序、xf86视频Freedreno DDX和Mesa内部的Freedreno Gallium3D驱动程序组成。源码地址是https://github.com/freedreno/freedreno。
用户空间组件可以在两种模式下运行,要么使用msm drm/kms内核驱动程序,要么使用下游msm android树中的msm fbdev+kgsl驱动程序。这样做的主要目的是使在android设备上使用freedreno更加容易,特别是因为msm drm/kms驱动程序尚未对手机/平板电脑上的LCD显示器提供完整的DSI面板支持。(即使DSI支持在msm drm/kms中就位,仍然需要为每个不同型号的LCD面板编写面板驱动程序。)
使用drm/kms驱动程序时,图形堆栈看起来与任何其他开源桌面驱动程序(nouveau、radeon等)的图形堆栈一样:
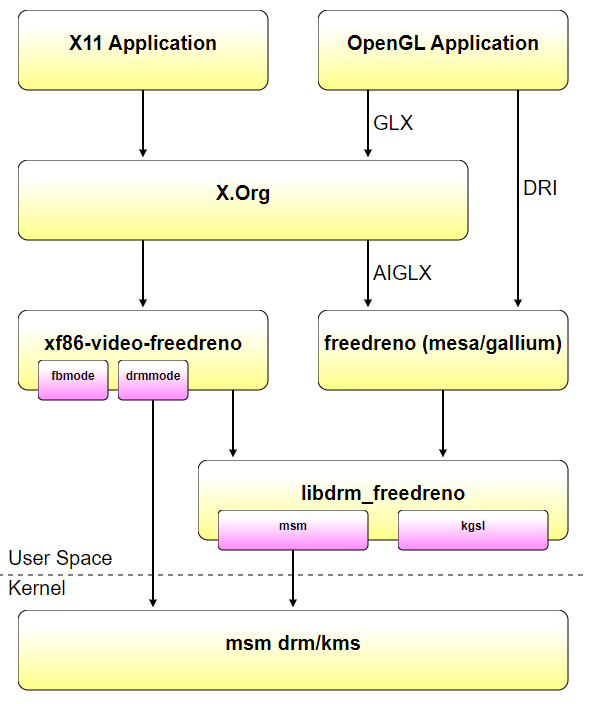
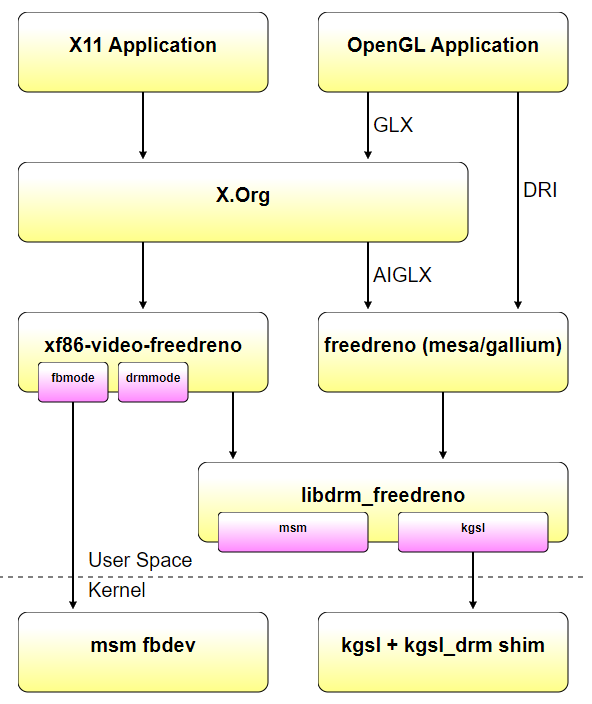
使用android fbdev/kgsl驱动程序时,堆栈几乎相同,只是xf86 video freedreno中的fbmode_display模式设置代码和libdrm_freedreno中的kgsl后端被用来代替drmmode_display和msm后端。无需重新编译任何用户空间组件,xf86 video freedreno和libdrm_freedreno可以确定在运行时使用什么。
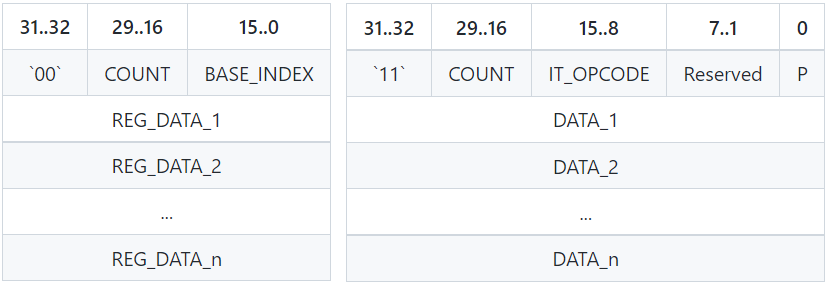
Command Processor (CP)是从ringbuffer(PM4命令流)读取一系列渲染命令的块,它可以设置一些寄存器值或触发一些渲染操作,主要由Type-0(PKT0)和Type-3(PKT3)命令组成。Type-0 (PKT0)从BASE_INDEX指定的寄存器开始,将N个连续(32位)DWORD写入N个寄存器(下图左),Type-3(PKT3)执行IT_OPCODE操作码指定的操作(下图右)。
与许多嵌入式/SoC GPU一样,Adreno是一种基于Tile的体系架构,然而,其实现方式要简单一些。大多数分块器渲染小(32x32和/或64x64)分块,硬件以某种方式对每个分块的几何体进行排序,通常忽略给定分块的不可见表面。另一方面,Adreno有一个(相对)大的内核(GMEM)或片上(OCMEM)分块缓冲区,大小从256KB到1MB不等。正在渲染的缓冲区分为“tile”或“bin”,颜色缓冲区和(如果启用)深度/模板缓冲区可以在分块缓冲区中容纳。驱动程序完全负责每个tile/bin的绘制,以及恢复(将数据从系统内存移动到GMEM)和解析(将数据从GMEM移动到系统内存)。请注意,解析步骤可以通过多个通道用于多样本解析。
最简单的方法是建立CMD以设置状态并执行清除/绘制,忽略tile,然后在顶级命令流缓冲区(提交给内核的内容)中,执行(可选)将每个tile设置、IB(分支)解析为清除/绘制命令,然后解析:
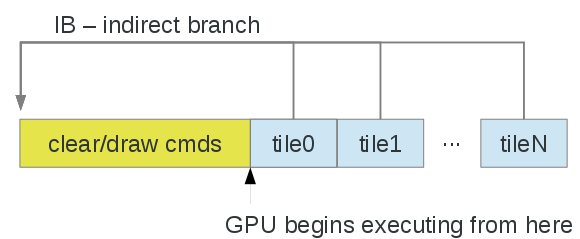
- 每个tile内的渲染效果与传统IMR类似。
- 逐tile命令:
- 恢复——可选将内容从系统内存传输到tile缓冲区。
- 设置窗口偏移和屏幕剪切。
- IB清除/绘制渲染命令。
- 解析——将tile缓冲区传输到系统内存。
- 注意:命令流构建的顺序与GPU执行的顺序不同,并且恢复/解析也在清除/绘制中使用的一些GPU状态寄存器,因此在驱动程序中需要注意在第一次清除/绘制之前将某些状态对象标记为脏。
以上是gallium3D驱动程序中实现的内容,当存在少量几何体和/或廉价的顶点着色器时,不一定是一个巨大的缺点。
上述的粗略的方法有一个缺点,即顶点着色器针对每个bin的每个顶点运行,但其实可以分为两个过程以减少开销。在第一个pass(“装箱”过程)中,顶点被拆分为每个分块箱,此信息在第二个pass中用于限制为每个箱子处理的顶点。不需要在两个过程上使用相同的顶点着色器,装箱过程可以使用简化的着色器,该着色器仅计算gl_Position / gl_PointSize。
注:以下注释适用于a3xx,但a2xx应大致相似。
blob驱动程序为每个tile分配一个VSC_PIPE,共有八个管线,可以为一个管线分配多个tile,即可以使用四个管线来排列4x4个tile,如下所示:
# X, Y = upper-left tile coord of group of tiles mapped to pipe
# W, H = size of group in tiles, so below each pipe is mapped to
# a 2x2 group of tiles
VSC_PIPE[0].CONFIG: { X = 0 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x1].CONFIG: { X = 0 | Y = 2 | W = 2 | H = 2 }
VSC_PIPE[0x2].CONFIG: { X = 2 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x3].CONFIG: { X = 2 | Y = 2 | W = 2 | H = 2 }对于每个管线,驱动程序配置管线缓冲区地址/大小( VSC_PIPE[p].DATA_ADDRESS和VSC_PIPE[p].DATA_LENGTH),为gpu提供了存储可见性流数据的位置。大小缓冲区(VSC_SIZE_ADDRESS),一个4字节 x 8个管线的缓冲区,GPU在其中存储写入每个管线缓冲区的数据量,在装箱过程中用于控制将哪些顶点存储到哪个管线。在渲染过程中,在每个tile的开始处,驱动程序将GPU配置为通过CP_SET_BIN_DATA数据包使用来自管线p的数据(即适当的缓冲区大小/地址):
OUT_PKT3(ring, CP_SET_BIN_DATA, 2);
OUT_RELOC(ring, pipe[p].bo, 0); /* same value as VSC\_PIPE[p].DATA\_ADDRESS */
OUT_RELOC(ring, size_addr_bo, (p * 4)); /* same value as VSC\_SIZE\_ADDRESS + (p * 4) */OUT_PKT0(ring, REG_A3XX_PC_VSTREAM_CONTROL, 1);
OUT_RING(ring, A3XX_PC_VSTREAM_CONTROL_SIZE(pipe[p].config.w * pipe[p].config.h) |A3XX_PC_VSTREAM_CONTROL_N(n)); /* N is 0..(SIZE-1) */OUT_PKT3(ring, CP_SET_BIN, 3);
OUT_RING(ring, 0x00000000);
OUT_RING(ring, CP_SET_BIN_1_X1(x1) | CP_SET_BIN_1_Y1(y1));
OUT_RING(ring, CP_SET_BIN_2_X2(x2) | CP_SET_BIN_2_Y2(y2));**与大多数/所有分块器一样,切换渲染目标代价高昂,会触发刷新。**此外,至少对于freedreno gallium3D驱动程序,如果只渲染缓冲区的一部分,建议剪去缓冲区中不会被touch(读或写)的部分。gallium驱动程序可以使用此信息调整tile边界/大小,避免不必要的恢复(将数据从系统内存拉入GMEM)或解析(从GMEM写回系统内存)。
对于指令集体系结构(Instruction Set Architecture,ISA),与a2xx着色器ISA不同,a3xx使用“简单”标量指令集,但有一些技巧。编译器需要更加了解调度和其他一些约束。每条指令为64位(qword),有7种基本指令编码或“类别”(在某些情况下有多个子编码)。与a2xx一样,没有单独的CF vs FETCH/ALU程序。但某些类别的指令是异步运行的,需要特殊的同步来处理先读后写(或先读后写)。与a2xx不同的是,现在有完整和半(16位)寄存器,它们都没有重叠。指令不仅针对浮点,还针对整数。7种指令编码描述如下:
-
类别0(cat0):通常采用零参数的流控制指令(有时带有嵌入常量),例如:
nop、jump、branch。 -
类别1(cat1):移动/转换的变体(单个源寄存器),此类指令没有操作码,尽管着色器助记符因src和目标类型而异。如果src和目标类型相同,则称为移动:
mov.f16f16 Rdst, Rsrc- 从同一类型src和dst移动。cov.f32u16 Rdst, Rsrc- 从f32 src移动/转换到u16 dst。mova- 是mov.f16f16寻址到寄存器(a0)。(在所有情况下,src寄存器都可以是const)
-
类别2(cat2):普通ALU指令,通常带有2个src寄存器,但在少数情况下,第2个src编码会被忽略:
add.f Rdst, Rsrc0, Rsrc1and.b Rdst, Rsrc0, Rsrc1floor.f Rdst, Rsrc0- an example of cat2 which ignores the 2nd src.
-
类别3(cat3):三个src寄存器操作,例如:
mad.f16- src0 * src1 + src2sel.f32- src1 ? src0 : src2
-
类别4(cat4):与cat1-cat3相比,复杂的单src操作需要更多的周期(可能无法预测的数量)和/或更异步:
rcp Rdst, Rsrclog2 Rdst, Rsrc从cat4指令写入的寄存器读取的其他非cat4指令必须将(ss)位设置为与复杂alu管线同步。
-
类别5(cat5):一般纹理样本相关说明:
sam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0samgq (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, Rsrc2
-
类别6(cat6):将指令加载/存储到专用/本地/全局内存、原子添加/订阅/交换等,以及其他杂项指令。对opencl最有用。
在**调度(Scheduling)**上,编译器负责在前一条指令的目标寄存器准备就绪之前考虑(指令调度)周期数。对于cat1-cat3指令,目标寄存器在三条指令之后可用,如果需要,编译器负责插入nop指令。对于由cat4或cat5指令写入的目标寄存器,(ss)或(sy)位可以设置为同步,因为与cat1-cat3不同,完成所需的周期数是不可预测的。特别是对于cat3指令,直到第二个周期才需要第三个src寄存器,因此,诸如DP4(点积)指令可以实现为:
; DP4 r0.x, r2.xyzw, r3.xyzw:
mul.f r0.x, r2.x, r3.x
nop
mad.f32 r0.x, r2.y, r3.y, r0.x
nop
mad.f32 r0.x, r2.z, r3.z, r0.x
nop
mad.f32 r0.x, r2.w, r3.w, r0.x而不是需要两个nop才能获得前一条指令的结果,如果可能,编译器当然可以在这些nop插槽中调度不相关的指令。写入寄存器的指令以前是纹理样本指令的src(WAR hazard),需要(ss)位集。
通常,简单的if/else构造将被展开,执行分支的所有分支,然后使用sel指令有条件地写回从流控制角度“获取”的分支的结果。amonst线程的发散流控制通常很昂贵(即,硬件最终必须在线程组中一次执行一个线程),因此编译器通常会尽量避免这种情况。(目前,if/else是用gallium驱动程序中的分支实现的,仅仅是因为编译器不够聪明,不知道如何将其展开。)当需要分支时,可以使用cat0指令来实现它们,例如,可以通过以下方式实现if/else:
cmps.f.eq p0.x, hr1.x, hc2.x
br p0.x, #6
mov.f16f16 hr1.x, hc2.x
mov.f16f16 hr1.y, hc2.y
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
jump #6
(jp)nop
mov.f16f16 hr1.x, hc2.y
mov.f16f16 hr1.y, hc2.x
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
(jp)nop请注意,分支目标指令上设置了(jp)(跳转目标)标志,可能有助于线程调度器找出潜在的聚合点,跳转目标不必是nop。分支可以是向前(正)或向后(负)立即偏移。
分组通道结束后,没有更多要插入或删除的指令。从深度通道创建的深度排序列表中最深的节点开始调度每个基本块,递归地尝试在每个指令的源指令加上延迟槽之后调度每个指令,根据需要插入NOP。
在指令中使用const src参数有一些限制,在某些情况下,编译器需要将const移动到GPR中。已知的限制包括:
- cat2最多可以使用一个常量src(但可以在任意位置)。
- cat3不能将常量src作为第二个参数(src1)。
- cat4不能接受常量src。
16.4.5 其它
此外,还有其它平台的驱动:
- Vidix:是一种适用于类Unix操作系统的便携式编程接口,它允许在用户空间中运行的视频卡驱动程序通过X Window系统的直接图形访问扩展直接访问帧缓冲区。
- MPLAB:MPLAB Harmony Graphics Suite是MPLAB生态系统的扩展,用于为32位微芯片设备创建嵌入式图形固件解决方案。
- MiniGLX:是一种应用程序编程接口规范,有助于在没有窗口系统的系统上进行OpenGL渲染,例如,没有X窗口系统的Linux或没有窗口系统的嵌入式系统。该接口是GLX接口的子集,加上一组最小的Xlib类函数。
16.5 图形驱动应用
16.5.1 视频与合成
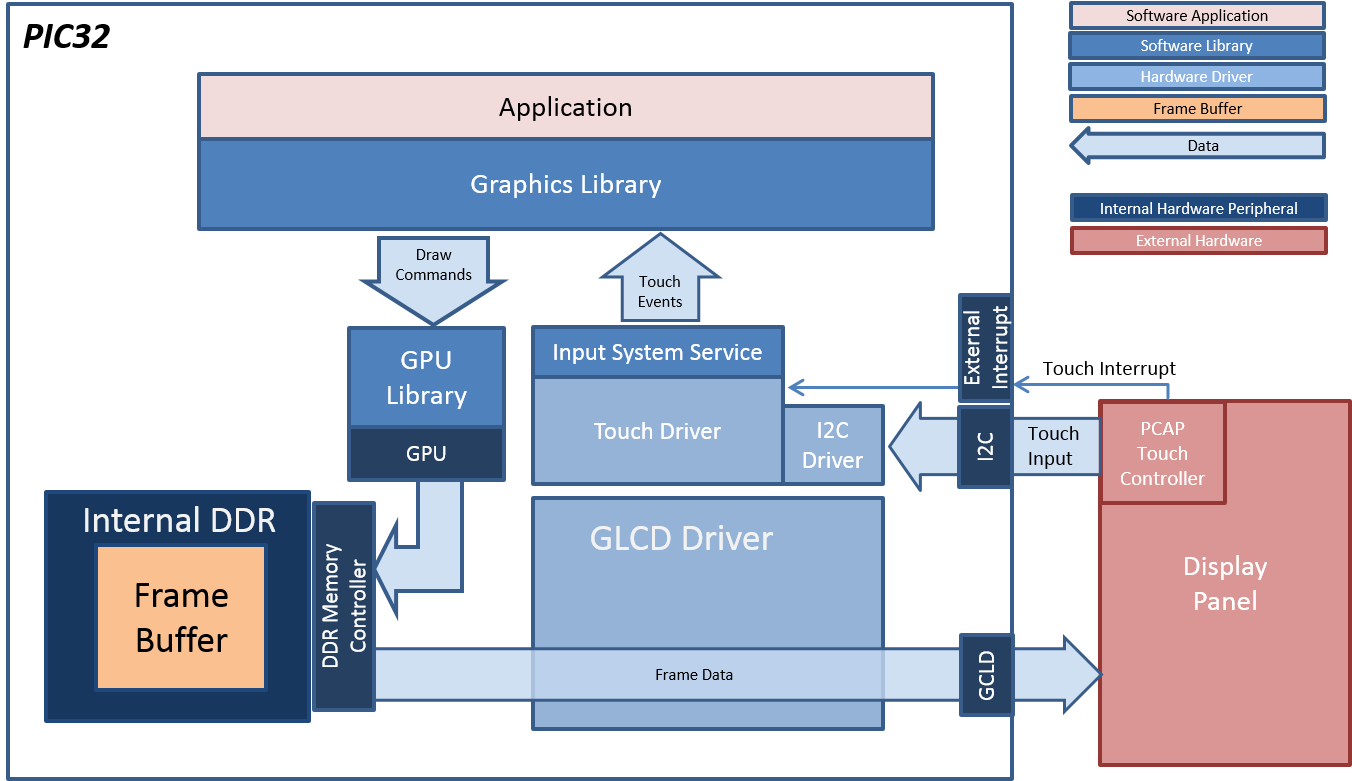
在运行GFX/视频播放用例(应用程序的视频流类型)时,查看影响英特尔体系结构下UI体验的特定稳定性问题,行为是冻结一个UI,然后是一个黑屏,然后是系统重新启动(当然是在一段随机的时间间隔之后)。
如果3D客户端应用程序“挂起”GPU,则GPU进程可能会被终止,然后GPU会完全重置。对于复杂的用例,如视频解码,许多帧/对象当前处于运行状态,因此终止GPU进程并重置GPU会导致不受欢迎的效果。
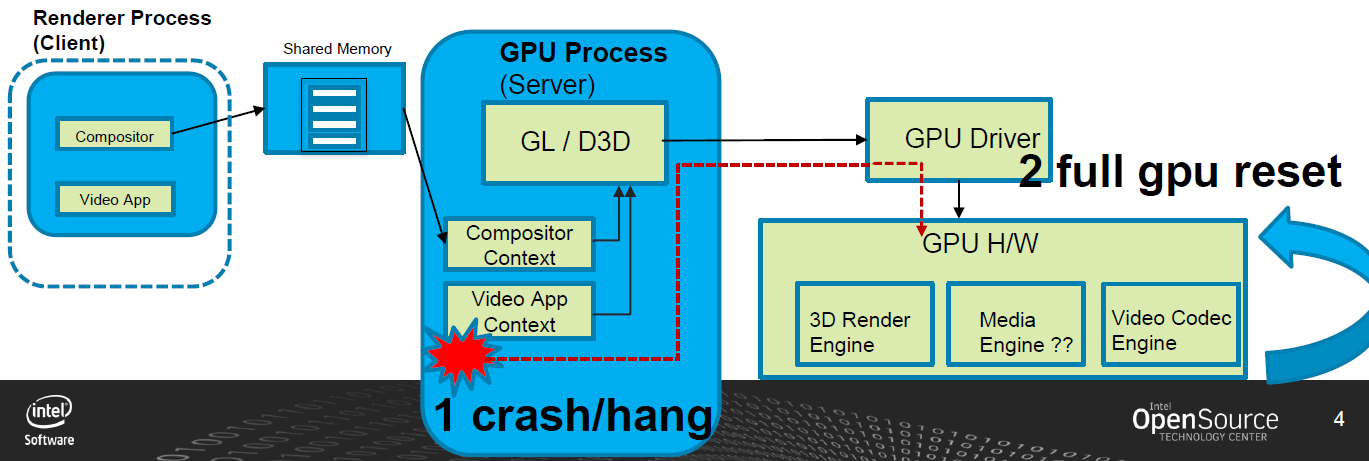
建议的解决方案:超时检测和恢复(Timeout Detection & Recovery,TDR)。Intel GPU的新功能(上游为wip),允许应用程序在单个批处理缓冲区上启用挂起检测,从而提高稳定性和鲁棒性。超时检测和恢复(TDR)允许独立重置GPU中的不同引擎(而不是完全重置GPU)。一般来说,这些实现在i915驱动程序中引入了一个新的IRQ处理程序,以及在gpu的环形缓冲区中发出的批处理缓冲区的启动指令之前和之后引入了两个新的gpu命令指令。TDR的步骤如下:
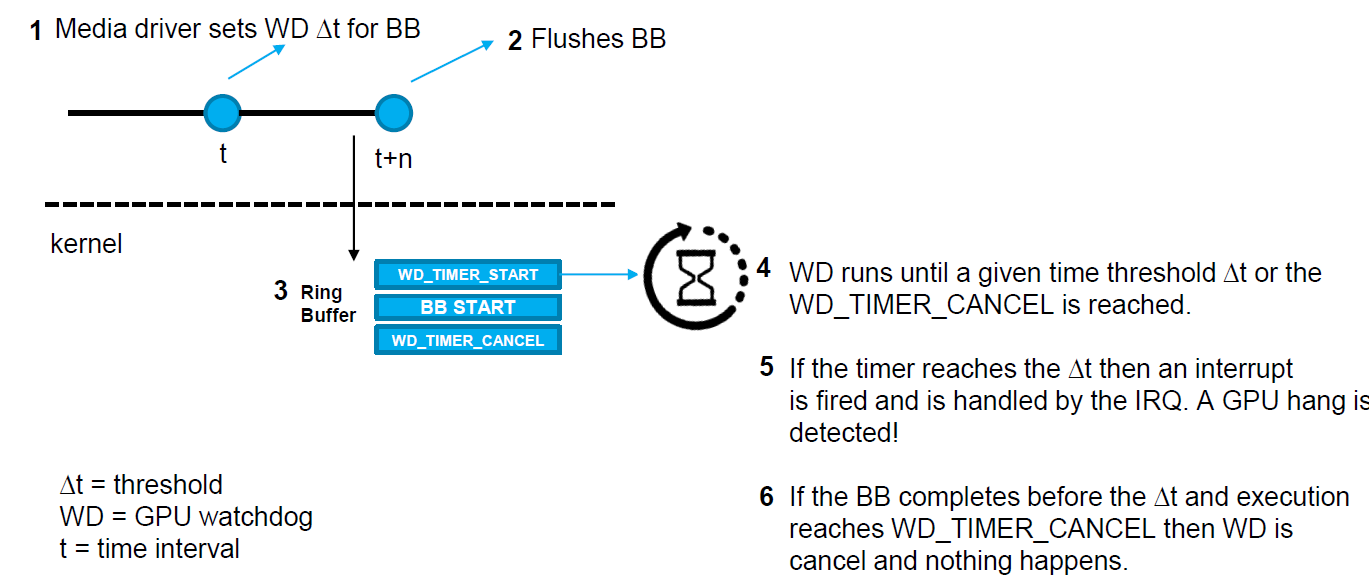
建议的解决方案:
1、UMD媒体驱动程序在发送批缓冲区后启动定时器。
2、计时器过期后,检测到媒体引擎处于挂起状态。
3、GPU驱动程序仅重置受影响的媒体引擎。
4、由于UMD媒体驱动程序知道提交错误批次的时间,因此可以在媒体驱动程序从重置中恢复的时间内采取措施。
整个机制通过任意阈值工作,该阈值可以通过ioctl从应用程序设置。但阈值不能太低,否则会产生太多误报。
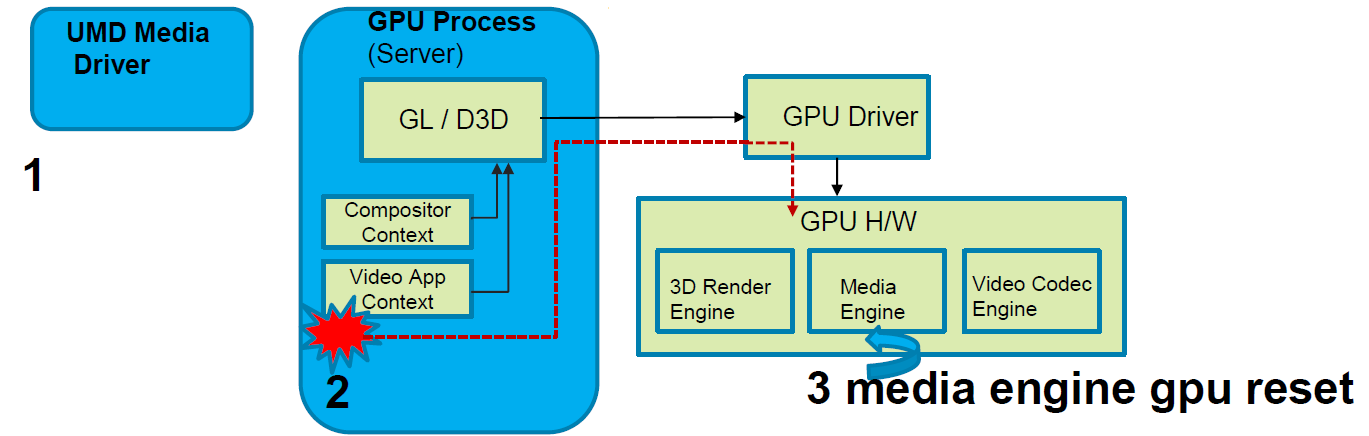
**合成器(compositor)**如何受益?结合下图加以回答:
1、合成器的基本任务是生成帧。
2、过去,当我们检测到GPU挂起时,合成器恢复(屏幕冻结、绿色或黑色屏幕或系统重新启动)为时已晚。
3、视频客户端应用程序现在可以早期确定“任务”是否导致媒体引擎崩溃,如果是,则向合成器标记以显示当前帧,同时媒体引擎从重置中返回。
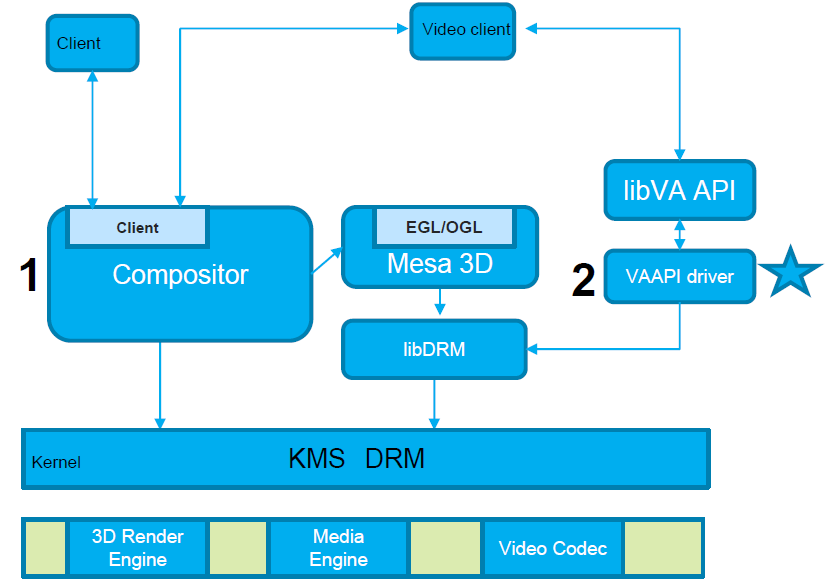
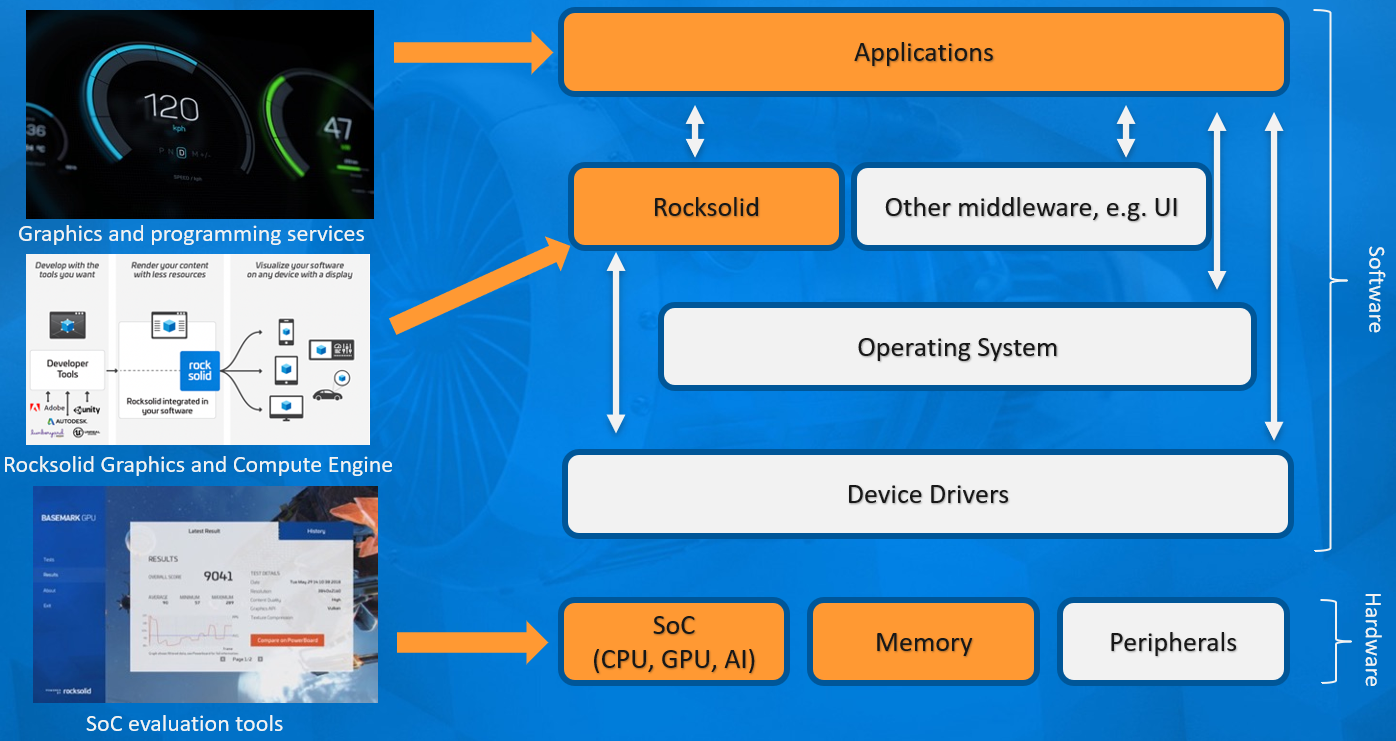
16.5.2 Rocksolid
Rocksolid最初是GPU基准产品的引擎,后来发展成为一个独立的产品。除了客户需求之外,该开发仍然与基准开发紧密相关。轻量级渲染/计算引擎主要针对非游戏用途,从小型嵌入式系统扩展到现代桌面级硬件。它不是一个成熟的游戏引擎,但它的开销比大型现代游戏引擎低得多,也更容易定制,更稳定,并且可以通过获得安全认证。下图是Rocksolid引擎的架构图,由此可知,它可以直接访问设备驱动,从而提升性能。
图形管线是一种非常好的运行方式,例如图像处理任务。在许多硬件中,如果问题自然映射到全屏光栅化过程,则将其作为图形管道而不是计算管道运行会更快。在一个工业客户案例中,Rocksolid被用于提供GPU加速的图像处理管道。与原始OpenCL版本相比,目标硬件的速度快了好几倍。
在OpenGL中,Rocksolid引擎只是在拓扑排序中运行记录的节点命令列表。在Vulkan中,每个使用的命令队列都有一个提交线程。目前,默认设置只是一个命令队列,所以只有一个提交线程。提交线程连续运行。当提交线程仍在推送命令时,程序的其余部分可以准备下一帧。Vulkan的CPU可见资源由简单的循环围栏系统保护。
16.5.3 I/O驱动
将应用程序的输入/输出请求转换为设备的低级命令,并将其发送给设备控制器,获取输入/输出设备的响应并将其发送到应用程序。
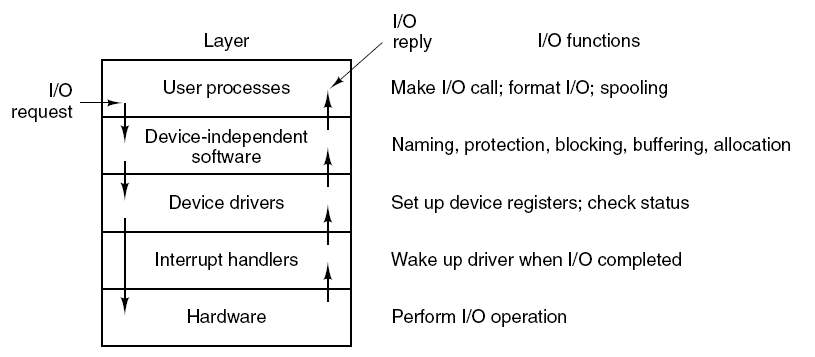
输入/输出系统的各层以及各层的主要功能。
如何在硬件中访问IO呢?步骤如下:
- 操作系统需要向设备控制器发送/接收命令和控制以完成输入/输出。
- 设备控制器有一个或多个用于控制和数据的寄存器。
- 处理器通过读/写这些寄存器与控制器通信。
- 如何寻址这些寄存器?
- 基于内存的I/O。
- 基于端口的输入/输出。
- 混合输入/输出。
内存映射/基于端口/混合的IO的方式如下图:
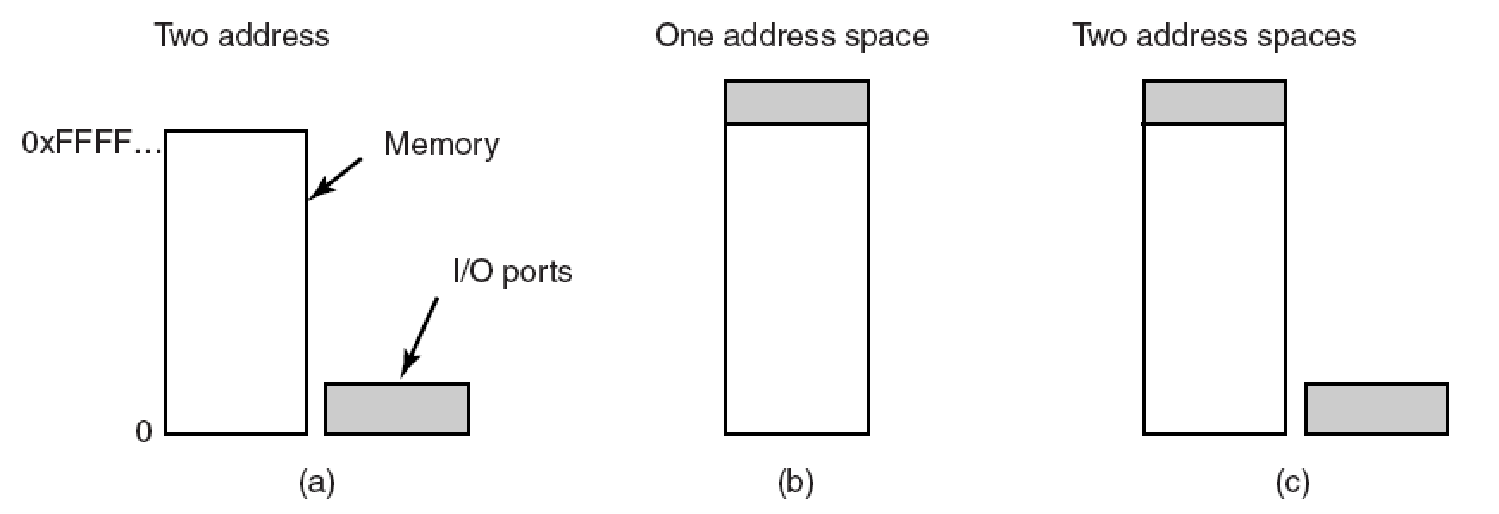
(a)特殊CPU指令(输入/输出)。(b)内存映射:为硬件输入/输出寄存器保留内存区域。标准内存指令会更新它们。(c)混合:一些控制器映射到内存,一些使用I/O指令。
单总线和双总线IO。(a)内存映射I/O只有一个地址空间,内存映射I/O更易于实现和使用。帧缓冲区或类似设备更适合于内存映射的I/O。(b)基于端口的I/O有两个地址空间:一个用于内存,一个用于端口。双总线允许并行读/写数据和设备。
单总线和双总线更详细的对比图如下:
总线:组件(包括CPU)之间的互连,可以连接多个设备:
端口:仅插入一个输入/输出设备的接口:
设备控制器:将物理设备连接到系统总线/端口:
每个设备都有一个设备控制器和一个设备驱动程序来与操作系统通信,设备驱动程序是可以插入操作系统以处理特定设备的软件模块,设备控制器用作设备和设备驱动程序之间的接口,设备控制器可以处理多个设备。作为一个接口,它的主要任务是将串行位流转换为字节块,并根据需要执行纠错。
IO端口寄存器有状态寄存器(由host读取)、命令寄存器(由host写入)、寄存器中的数据(由host读取以获取输入)、数据输出寄存器(由host写入以发送输出)。
直接内存访问(Direct Memory Access,DMA):对于进行大型传输的设备,如磁盘驱动器,使用昂贵的通用处理器来监视状态位并将数据一次输入1字节的控制器寄存器,似乎是一种浪费——这一过程称为编程输入/输出。基于中断的I/O不是一种补救方法,因为每个字节都会创建一个到中断处理程序例程的上下文开关。在基于轮询和基于中断的I/O中,所有字节都需要通过CPU,并且输入/输出设备<->CPU<->内存有很多开销。如果我们可以将这个平凡的任务卸载到一个特殊用途的处理器上,该处理器可以将数据从输入/输出设备直接移动到内存中,那就太好了!这就是直接内存访问(DMA)控制器。
要启动DMA传输,host将DMA命令块写入内存。指向传输源的指针,指向传输目标的指针,以及要传输的字节数的计数。CPU将此命令块的地址写入DMA控制器,然后继续其他工作。DMA控制器继续直接操作内存总线,在总线上放置地址以执行传输,而无需主CPU的帮助。简单的DMA控制器是PC中的标准组件,PC的总线主控输入/输出板通常包含自己的高速DMA硬件。使用DMA的IO示例:
/* Code executed when the print system call is made */
copyFromUser(buffer, p, count);
setupDMAController();
scheduler();/* Interrupt Service Routine Procedure for the printer */
acknowledgeInterrupt();
unblockUser();
returnFromInterrupt();请注意,中断是每个I/O任务生成一次,而不是每个字节生成一次(在基于中断的I/O情况下)。
IO硬件接口:设备驱动程序被告知将磁盘数据传输到地址X处的缓冲区,设备驱动程序告诉磁盘控制器将C字节从磁盘传输到地址X处的缓冲区,磁盘控制器启动DMA传输,磁盘控制器将每个字节发送到DMA控制器,DMA控制器将字节传输到缓冲区X,递增内存地址,递减C直到0,当C==0时,DMA中断CPU以完成信号传输。
应用程序IO接口如下图所示:
连接到计算机的每个输入/输出设备都需要一些特定于设备的代码来控制它。设备制造商编写,每个操作系统都需要自己的设备驱动程序,每个设备驱动程序都支持特定类型或类别的输入/输出设备。鼠标驱动程序可以支持不同类型的鼠标,但不能用于网络摄像头。操作系统定义了驱动程序的功能以及它如何与操作系统的其余部分交互。设备驱动程序具有多个功能,要接受来自其上方独立于设备的软件的抽象读写请求,并确保执行这些请求,设备初始化,管理is电源需求和日志事件。
Microsoft Windows使用文件系统上的设备快捷方式来寻址设备,设备访问API为应用程序程序员提供了一个接口,以检查设备并与之交互,Windows设备框架为设备驱动程序开发提供了用户和内核界面。输入/输出分类(操作系统视角)有:
- 字符流和块。
- 顺序访问与随机访问。设备驱动程序允许查找设备中的偏移量。
- 同步与异步。设备驱动程序上的I/O操作与设备控制器上的I/O完成同步,异步I/O更早返回,稍后报告成功/失败。
- 缓冲和直接。报告的操作结果在缓冲区或设备控制器上完成。
- 共享或专用。每个设备实例上的I/O是互斥的。(即打印机)
- 只读、只写、读写。
内核提供了许多与I/O相关的服务:调度、缓冲、缓存、池化、设备保留及错误处理,基于硬件和设备驱动程序基础架构构建。
IO调度用来调度一组I/O请求,意味着确定执行它们的良好顺序。操作系统开发人员通过维护每个设备的请求队列来实现调度,当应用程序发出阻塞I/O系统调用时,该请求将被置于该设备的队列中。I/O调度器重新排列队列的顺序,以提高总体系统效率和应用程序的平均响应时间。输入/输出通常很慢,一些设备的物理特性需要优化,例如硬盘——由磁头移动和旋转引起的机械装置和延迟。如果在FIFO策略中执行输入/输出,机械之字形运动可能会否决输入/输出操作。I/O调度获取设备上的一组I/O请求,并确定在设备上执行请求的最佳顺序和时间。当多个任务竞争要处理的I/O请求时,调度变得复杂。
块设备操作与虚拟内存和分页紧密耦合,一些帧用作页面缓存,并将块设备的数据保存在系统中。块设备中的输入/输出:搜索块是否已在页缓存中(物理内存中):如果找到现有帧的读/写缓冲区,否则,分配一个帧,将设备块读取到帧中,将帧标记为缓存设备块对从此帧读取/写入缓冲区。脏页定期写入块设备,显著加快I/O操作,尤其是文件系统元数据操作。
页面缓存思想还与内存映射的I/O相结合,mmap()文件采用类似的机制。进程的虚拟内存映射作为文件(而不是块设备)备份的页,更改会在内存上更新,缓存的帧会定期在磁盘上强制执行。VM系统跟踪页面和文件缓存以及其他(常驻和免费)页面的帧,VM系统根据系统的内存状态调整文件和设备缓存的大小。
缓冲区是在两个设备之间或设备与应用程序之间传输数据时存储数据的存储区域。进行缓冲有三个原因:
- 处理数据流的生产者和消费者之间的速度不匹配。通过适配器接收文件以存储在硬盘上。
(a) 无缓冲输入。(b) 用户空间中的缓冲。(c)在内核中进行缓冲,然后复制到用户空间。(d) 内核中的双缓冲。
- 在具有不同数据传输大小的设备之间进行调整。网络:消息通常在发送和接收过程中被分割。
联网可能涉及一个数据包的多个副本。
- 支持应用程序I/O的复制语义。应用程序调用write()系统调用,提供指向缓冲区的指针和指定要写入的字节数的整数。系统调用返回后,如果应用程序更改缓冲区的内容,会发生什么情况?在处理write()系统调用时,操作系统会将应用程序数据复制到内核缓冲区,然后再将控制权返回给应用程序。磁盘写入是从内核缓冲区执行的,因此对应用程序缓冲区的后续更改不会产生任何影响。
缓存在I/O级别完成,以提高I/O效率。缓冲区和缓存之间的区别在于,缓冲区可能只保存数据项的现有副本,而缓存根据定义,只保存位于其他位置的项的更快存储上的副本。缓存和缓冲是不同的功能,但有时一个内存区域可以用于这两个目的。例如,为了保留拷贝语义并实现磁盘I/O的高效调度,操作系统使用主存中的缓冲区来保存磁盘数据。
输入/输出软件通常分为四层,每个层都有一个定义良好的接口。
下面是有(右)无(左)标准驱动接口的对比图:
16.5.4 UE图形驱动
虽然原则上应用层不应该关心驱动层和GPU的细节,但往往事与愿违,众多的GPU、系统、图形API、版本造就了众多的驱动程序版本,它们之间可能存在一些奇奇怪怪的问题,而驱动程序有着很长的供应链路,修复问题的周期往往比较漫长。作为应用程序开发者,肯定不能坐以待毙,需主动解决或规避。UE提供了有限的接口和类型,为我们提供了一些信息,从而可以读取GPU或驱动的信息。相关的主要接口:
// GenericPlatformDriver.h// 视频驱动细节
struct FGPUDriverInfo
{uint32 VendorId; // DirectX供应商ID,0如果未设置,请使用以下函数设置/获取FString DeviceDescription; // e.g. "NVIDIA GeForce GTX 680" or "AMD Radeon R9 200 / HD 7900 Series"FString ProviderName; // e.g. "NVIDIA" or "Advanced Micro Devices, Inc."FString InternalDriverVersion; // e.g. "15.200.1062.1004"(AMD), "9.18.13.4788"(NVIDIA)FString UserDriverVersion; // e.g. "Catalyst 15.7.1"(AMD) or "Crimson 15.7.1"(AMD) or "347.88"(NVIDIA)FString DriverDate; // e.g. 3-13-2015FString RHIName; // e.g. D3D11, D3D12FGPUDriverInfo();bool IsValid() const;FString GetUnifiedDriverVersion() const;bool IsAMD() const { return VendorId == 0x1002; }bool IsIntel() const { return VendorId == 0x8086; }bool IsNVIDIA() const { return VendorId == 0x10DE; }(...)
};// GPU硬件信息
struct FGPUHardware
{// 驱动信息const FGPUDriverInfo DriverInfo;FGPUHardware(const FGPUDriverInfo InDriverInfo);FString GetSuggestedDriverVersion(const FString& InRHIName) const;FBlackListEntry FindDriverBlacklistEntry() const;bool IsLatestBlacklisted() const;const TCHAR* GetVendorSectionName() const;(...)
};// GenericPlatformMisc.hstruct CORE\_API FGenericPlatformMisc
{// 获取GPU驱动信息static struct FGPUDriverInfo GetGPUDriverInfo(const FString& DeviceDescription);(...)
};有了以上接口,就可以方便地在渲染层、游戏逻辑层获取驱动信息以执行针对性的操作。
除了GPU驱动,还可以访问图形API的驱动,常出现在各个图形API的RHI实现中,例如Android Vulkan:
// AndroidPlatformMisc.cppbool FAndroidMisc::HasVulkanDriverSupport()
{(...)// this version does not check for VulkanRHI or disabled by cvars!if (VulkanSupport == EDeviceVulkanSupportStatus::Uninitialized){// assume noVulkanSupport = EDeviceVulkanSupportStatus::NotSupported;VulkanVersionString = TEXT("0.0.0");// check for libvulkan.sovoid* VulkanLib = dlopen("libvulkan.so", RTLD_NOW | RTLD_LOCAL);if (VulkanLib != nullptr){UE_LOG(LogAndroid, Log, TEXT("Vulkan library detected, checking for available driver"));// if Nougat, we can check the Vulkan versionif (FAndroidMisc::GetAndroidBuildVersion() >= 24){extern int32 AndroidThunkCpp\_GetMetaDataInt(const FString& Key);int32 VulkanVersion = AndroidThunkCpp_GetMetaDataInt(TEXT("android.hardware.vulkan.version"));if (VulkanVersion >= UE_VK_API_VERSION){// final check, try initializing the instanceVulkanSupport = AttemptVulkanInit(VulkanLib);}}else{// otherwise, we need to try initializing the instanceVulkanSupport = AttemptVulkanInit(VulkanLib);}dlclose(VulkanLib);if (VulkanSupport == EDeviceVulkanSupportStatus::Supported){UE_LOG(LogAndroid, Log, TEXT("VulkanRHI is available, Vulkan capable device detected."));return true;}else{UE_LOG(LogAndroid, Log, TEXT("Vulkan driver NOT available."));}}else{UE_LOG(LogAndroid, Log, TEXT("Vulkan library NOT detected."));}}return VulkanSupport == EDeviceVulkanSupportStatus::Supported;
}16.6 本篇总结
本篇主要阐述了图形渲染体系的驱动部分,包含它的概念、技术、架构、机制和相关的硬件部件。
在PC上,开发者可以要求用户更新其驱动程序,这样做相对容易。在移动设备上,驱动需要在多个阶段获得认证,从硬件供应商到客户的链条很长,这样做既昂贵又缓慢,错误修复和新功能可能需要数月时间,意味着bug修复可能需要很长时间才能进入用户的手中。在较旧/低端设备上,它们可能永远不会到来。目前正在努力改进这一点,但如果看到驱动程序错误,行业从业者准备解决它。这一情况正在好转(但进程缓慢)。
说到驱动程序bug,在移动设备上研究Vulkan驱动程序的团队通常没有在PC上那么大,有很多GPU的嵌入式变体需要测试。意味着驱动的质量常常有点落后。再加上发布修复程序的延迟,看看它是否有效或引入其他问题,驱动程序质量成为一个问题就不足为奇了。随着一致性测试的改进,驱动程序的测试变得更好,Khronos的硬件供应商非常清楚这是一个高度优先事项。需要行业从业者齐心协力改善这一点(CTS)。
随着现代图形API的到来,驱动不再进行隐式的优化,可预测的性能是可预测的低!使用新API启动新项目的开发人员具有优势(下图),新的图形API给大型软件安装群带来了更多的问题。构建渲染流,以便以正确的顺序获得所需的信息,在开始时要比改装容易得多。最重要的是,可以根据旧的API执行的驱动程序优化来编写引擎,以获得良好的性能。现在,软件开发人员拥有了控制权,使得性能可以预测,并确保应用了正确的优化,但也确实意味着由开发人员来确保这些优化存在。
DirectX11驱动程序(上)和DirectX12应用程序(下)执行的工作对比图。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Understanding Modern Device Drivers
- AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE
- I/O systems
- A low latency GPU engine based reset mechanism for a more robust UI experience
- Graphics Driver Quality - AMD
- High Dynamic Range(HDR)on Intel Graphics
- Understanding the Windows 8 graphics driver model
- Linux Graphics Drivers: an Introduction
- Linux GPU Driver Developer’s Guide
- Matrox Display Driver Guide
- nouveau Development
- envytools
- Mobile Graphics 101 - Arm Community
- Understanding Citrix HDX Graphics
- Windows Kernel Graphics Driver Attack Surface
- Vulkan in Rocksolid
- Windows Graphics Architecture
- Anatomy of RAM
- Memory structure
- FIFO overview
- NVIDIA TURING GPU ARCHITECTURE
- NVIDIA AMPERE GA102 GPU ARCHITECTURE
- 深入GPU硬件架构及运行机制
- Graphic Stack Overview
- The State of Linux Graphics
- A deeper look into GPUs and the Linux Graphics Stack
- Device driver
- Free and open-source graphics device driver
- Mesa (computer graphics)
- nouveau (software)
- AMD Radeon Software
- Freedreno in freedesktop
- Freedreno Architecture Overview
- Freedreno in Mesa3d
- Freedreno in Phoronix
- Freedreno in GitHub
- Adreno tiling
- Vidix
- Graphics card
- NVIDIA Linux Open GPU Kernel Module Source
- MPLAB® Harmony Graphics Suite Applications
- What is a driver?
- WDDM Architecture
- Low-Level GPU Documentation
- MiniGLX
- Intel GMA
- Game Architecture and Game Engine
- Z-order curve
- Hilbert curve
- Direct Rendering Manager
- Direct X – Direct way to Microsoft Windows Kernel
- User mode and kernel mode
- Virtual address spaces
- Thread Synchronization and TDR
- Wayland
- Wayland Architecture
- Operating Systems must support GPU abstractions
- Schedule Synthesis for Halide Pipelines on GPUs
- Hardware Accelerated GPU Scheduling
- Windows 10 Hardware-Accelerated GPU Scheduling Benchmarks (Frametimes, FPS)
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
- An Integrated GPU Power and Performance Model
- A user mode CPU–GPU scheduling framework for hybrid workloads
- Balancing Energy Efficiency and Real-Time Performance in GPU Scheduling

的使用 十五分钟快速入门与完全掌握)

看门狗定时器 (WDT))



SFR 模块)



比较器B Comp_B)

)
导入工程模板)
不可用状态的解决办法)



