一、说明
随着HBase在重要的商业系统中应用的大量增加,许多企业需要通过对它们的HBase集群建立健壮的备份和故障恢复机制来保证它们的企业(数据)资产。备份Hbase时的难点是其待备份的数据集可能非常巨大,因此备份方案必须有很高的效率。Hbase备份方案必须既能够伸缩至对数百TB的存储容量进行备份,又能够在一个合理的时间内完成数据恢复的工作。HBase和Apache Hadoop系统提供了许多内置的机制,可以快速而轻松的完成PB级数据的备份和恢复工作。
二、方法
HBase是一个基于LSM树(log-structured merge-tree)的分布式数据存储系统,它使用复杂的内部机制确保数据准确性、一致性、多版本等。因此,你如何获取数十个region server在HDFS和内存中的存储的众多HFile文件、WALs(Write-Ahead-Logs)的一致的数据备份?
让我们从最小的破坏性,最小的数据占用空间,最小的性能要求机制和工作方式到最具破坏性的逐一讲述:
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
- Offline backup of HDFS data
下面的表格提供了一个关于这些方法的快速比较,具体的细节在下面再详细描述。

Snapshots(快照)
HBase快照功能丰富,有很多特征,并且创建时不需要关闭集群。关于snapshot在文章《apache hbase snapshot介绍》中有更详细的介绍。
快照能通过在HDFS中创建一个和unix硬链接相同的存储文件,简单捕捉你的hbase表的某一时刻的信息(如下图)。这些快照在几秒内就可以完成,几乎对整个集群没有任何性能影响。并且,它只占用一个微不足道的空间。除了在metadata文件中存储的极少目录数据,你的数据不会冗余,快照允许你的系统回滚到(创建快照)那个时刻,当然,你需要恢复快照。

通过在HBase shell中运行如下命令来创建一个表的快照:
hbase(main):013:0> snapshot 'yy', 'MySnapShot' 在执行这条命令之后,你将发现在hdfs中有一些小的数据文件。在/hbase/.hbase-snapshots里 ,这些文件中存储着快照信息。想要恢复数据只需要执行在shell中执行如下命令:
hbase(main):022:0> disable 'yy'
hbase(main):023:0> restore_snapshot 'MySnapShot'
hbase(main):024:0> enable 'yy'正如你看到的,恢复快照需要对表进行离线操作。一旦恢复快照,那任何在快照时刻之后做的增加/更新数据都会丢失。如果你的业务需求是这样的:你必须有数据的异地备份,你可以用exportSnapshot命令赋值一个表的数据到你的本地HDFS或者你选择的远程HDFS中。
HBase复制(HBase Relication)
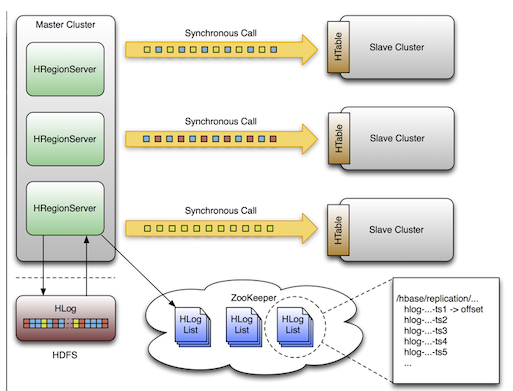
HBase复制是另外一个负载较轻的备份工具。文章《HBase复制概述》有对它的详细描述。总的来说,复制被定义为列簇级别,可以工作在后台并且保证所有的编辑操作在集群复制链之间的同步。
复制有三种模式:主->从(master->slave),主<->主(master<->master)和循环(cyclic)。这种方法给你灵活的从任意数据中心获取数据并且确保它能获得在其他数据中心的所有副本。在一个数据中心发生灾难性故障的情况下,客户端应用程序可以利用DNS工具,重定向到另外一个备用位置。
复制是一个强大的,容错的过程。它提供了“最终一致性”,意味着在任何时刻,最近对一个表的编辑可能无法应用到该表的所有副本,但是最终能够确保一致。
注:对于一个存在的表,你需要通过本文描述的其他方法,手工的拷贝源表到目的表。复制仅仅在你启动它之后才对新的写/编辑操作有效。
导出导入(Export/Import)
HBase的导出工具是一个内置的实用功能,它使数据很容易从hbase表导入HDFS目录下的SequenceFiles文件。它创造了一个map reduce任务,通过一系列HBase API来调用集群,获取指定表格的每一行数据,并且将数据写入指定的HDFS目录中。这个工具对集群来讲是性能密集的,因为它使用了mapreduce和HBase 客户端API。但是它的功能丰富,支持制定版本或日期范围,支持数据的筛选,从而使增量备份可用。
下面是一个导出命令的简单例子:
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> 一旦你的表导出了,你就可以复制生成的数据文件到你想存储的任何地方(比如异地/离线集群存储)。你可以执行一个远程的HDFS集群/目录作为命令的输出目录参数,这样数据将会直接被导出到远程集群。使用这个方法需要网络,所以你应该确保到远程集群的网络连接是否可靠以及快速。
导入命令:
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir> 拷贝表(CopyTable)
拷贝表功能在文章《使用CopyTable在线备份HBase》中有详细描述,但是这里做了基本的总结。和导出功能类似,拷贝表也使用HBase API创建了一个mapreduce任务,以便从源表读取数据。不同的地方是拷贝表的输出是hbase中的另一张表,这张表可以在本地集群,也可以在远程集群。
一个简单的例子如下:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test 这个命令将会拷贝名为test的表到集群中的另外一个表testCopy。
请注意,这里有一个明显的性能开销,它使用独立的“puts”操作来逐行的写入数据到目的表。如果你的表非常大,拷贝表将会导致目标region server上的memstore被填满,会引起flush操作并最终导致合并操作的产生,会有垃圾收集操作等等。
此外,你必须考虑到在HBase上运行mapreduce任务所带来的性能影响。对于大型的数据集,这种方法的效果可能不太理想。
HBase API
由于总是这样使用hadoop,你可以使用公用的api写自己定制的客户端应用程序来直接查询表格。你也可以通过mapreduce任务的批量处理优势,或者自己设计的其他手段。然而,这个方法需要对hadoop开发以及因此对生产集群带来的影响有深入的理解。
离线备份原生的HDFS数据(Offline Backup of Raw HDFS Data)
最强力的备份机制,也是破坏性最大的一个。涉及到最大的数据占用空间。你可以干净的关闭你的HBase集群并且手工的在HDFS上拷贝数据(distcp)。因为HBase已经关闭,所以能确保所有的数据已经被持久化到HDFS上的HFile文件中,你也将能获得一个最准确的数据副本。但是,增量的数据几乎不能再获得,你将无法确定哪些数据发生了变化。
同时也需要注意,恢复你的数据将需要一个离线的元数据因为.META.表将包含在修复时可能无效的信息。这种方法需要一个快速的,可信赖的网络来传输异地的数据,如果需要在稍后恢复它的话。
由于这些原因,Cloudera非常不鼓励在HBase中这种备份方法。
故障恢复(Disaster Recory)
HBase被设计为一个非常能容忍错误的分布式系统,假设硬件失败很频繁。在HBase中的故障恢复通常有以下几种形式:
- 在数据中心级别的灾难性故障,需要切换到备份位置;
- 需要恢复由于用户错误或者意外删除的数据的之前一个拷贝;
- 出于审计目的,恢复实时点数据拷贝的能力
正如其他的故障恢复计划,业务需要驱动这你如何架构并且投入多少金钱。一旦你确定了你将要选择的备份方案,恢复将有以下几种类型:
- 故障转移到备份集群
- 导入表/恢复快照
- 指向HBase在备份位置的根目录
如果你的备份策略是这样的,你复制你的HBase数据在不同数据中心的备份集群,故障转移将变得简单,仅需要使用DNS技术,转移你的应用程序。
请记住,如果你打算允许数据在停运时写入你的备份集群,那你需要确保在停运结束后,数据可以回到主机群。主<->主或循环的复制架构能自动处理这个过程,但对于一个主从结构来讲,你就需要手动进行干预了。
你也可以在故障时通过简单的修改hbase-site.xml的 hbase.root.dir属性来更改hbase根目录,但是这是最不理想的还原选项,因为你复制完数据返回生产集群时,正如之前提到的,可能会发现.META是不同步的。
总结
综上所述,从某种损失或中断中恢复数据需要一个精心设计的BDR计划。强烈建议你彻底明白你的业务需求,然后明白数据精确度/可用性以及故障恢复的最大时间。有了这些知识,你才能更好的选择满足这些需求的工具。
选择工具仅仅是个开始,你应该对你的BDR策略进行大规模测试,以确保它的在你的基础设施下的功能。并且,你应该是非常熟悉所有的故障恢复步骤。
参考
http://blog.cloudera.com/blog/2013/11/approaches-to-backup-and-disaster-recovery-in-hbase/
http://blog.csdn.net/iam333/article/details/38232215