用PYTHON探索数据 (EXPLORING DATA WITH PYTHON)
Between data blends, joins, and wrestling with the resulting levels of detail in Tableau, managing relationships between data can be tricky.
在数据混合,联接以及在Tableau中产生的详细程度之间进行搏斗之间,管理数据之间的关系可能很棘手。
Stepping into your shiny new Python shoes, the world opens up a bit. Instead of trying to squeeze everything into a single data source to rule them all, you can choose your battles.
踏入您闪亮的新Python鞋子,世界将会打开一点。 您可以选择自己的战斗,而不是试图将所有内容压缩到单个数据源中以对其全部进行统治。
In our previous articles, we already saw:
在之前的文章中,我们已经看到:
Pandas groupby expressions and basic visualizations
熊猫groupby表达式和基本可视化
Calculations and coloring sales by profitability
按获利能力计算和着色销售
Data exploration with advanced visuals
具有高级视觉效果的数据探索
搭建舞台 (Setting the stage)
In this article, we’ll focus on one of the most important aspects of working with data in any ecosystem: joins.
在本文中,我们将重点介绍在任何生态系统中处理数据的最重要方面之一:联接。
Lucky for us, the Tableau data we have been playing around with comes with batteries included! Within the context of the fictitious store we have been analyzing, we have a bit of data detailing various items that were returned.
幸运的是,我们一直在使用的Tableau数据随附电池! 在我们一直在分析的虚拟商店的背景下,我们有一些数据详细说明了退回的各种商品。
Let’s use this data on orders and returns to get comfortable joining data in Python using the Pandas library. Along the way, we’ll see how different types of joins can help us accomplish different goals.
让我们按订单和退货使用此数据,以使用Pandas库轻松地在Python中加入数据。 一路上,我们将看到不同类型的联接如何帮助我们实现不同的目标。
第1步:快速查看我们要加入的数据 (Step 1: taking a quick look at the data we’d like to join)
Remember that orders data we’ve been working with? Let’s get a good look at it real quick.
还记得我们一直在处理的订单数据吗? 让我们快速地真正了解它。
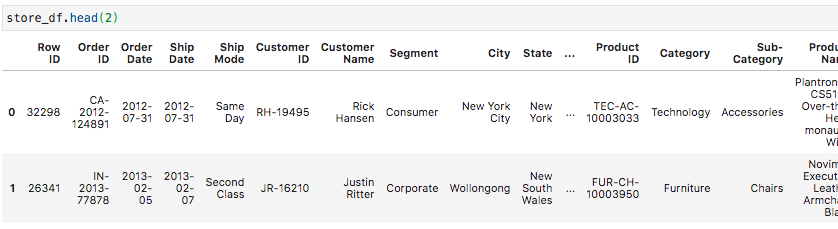
Ah, that’s familiar. Now let’s see what’s behind door #2. But first, in the spirit of getting a feel for how Pandas works, let’s highlight how we are getting our hands on this data.
嗯,很熟悉。 现在,让我们看看2号门的背后。 但是首先,本着了解熊猫工作方式的精神,让我们重点介绍一下如何获取这些数据。
In the first article, we used Pandas read_excel() function to get our orders data from an Excel file. It turns out this file has multiple sheets:
在第一篇文章中,我们使用了Pandas的read_excel()函数从一个Excel文件中获取订单数据。 事实证明,此文件有多个工作表:
- Orders 命令
- Returns 退货
- People 人
Let’s ignore the ‘People’ sheet for now (nobody likes them anyway), and simply acknowledge the fact that when we used the read_excel() function without specifying a sheet name, the function grabbed the first sheet available in the Excel workbook.
现在让我们忽略“人员”工作表(无论如何都没人喜欢),并简单地承认一个事实,当我们使用read_excel()函数但未指定工作表名称时,该函数将获取Excel工作簿中可用的第一张工作表。
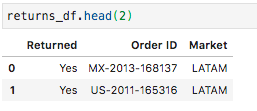
Here’s how we can specify that we want to fetch data from the ‘Returns’ sheet:
这是我们可以指定要从“退货”表中获取数据的方式:
returns_df = pd.read_excel('Global Superstore.xls', sheet_name='Returns')And here’s what that data looks like:
数据如下所示:
步骤2:避免相亲数据 (Step 2: avoid blind dates for your data)
In the data joining world, an arranged marriage is better than a blind date. That is, we want to be the overbearing parents who inspect the columns we are about to join our data on, looking for any inconsistencies that would make for a poor match. Blindly joining our data together just because we assume the columns match up could lead to some undesired results.
在数据连接世界中,包办婚姻比相亲更好。 就是说,我们希望成为一个顽强的父母,他们将检查将要加入我们数据的列,以寻找可能导致匹配不良的任何不一致之处。 仅仅因为我们假设各列匹配会导致盲目地将我们的数据连接在一起,可能会导致一些不良结果。
To prove that point, let’s take a stroll into a blind date and see what happens.
为了证明这一点,让我们走进相亲,看看会发生什么。
For starters, let’s observe which columns our two data sets have in common.
首先,让我们观察一下我们的两个数据集共有哪些列。
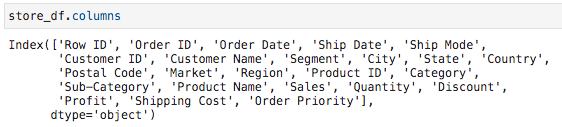

It looks to me like we have ‘Order ID’ and ‘Market’ in common. Of course, in many real world scenarios the same information might be stored under different names, but this isn’t the real world. It’s an example!
在我看来,我们有共同的“订单ID”和“市场”。 当然,在许多现实世界中,相同的信息可能以不同的名称存储,但这不是现实世界。 这是一个例子!
By the way, here’s a shortcut you could use to find values that exist in both column lists:
顺便说一下,这是一个快捷方式,可用于查找两个列列表中都存在的值:
common_cols = [col for col in store_df.columns if col in returns_df.columns]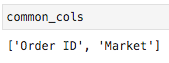
What you just saw is called a list comprehension. If you end up falling in love with Python, these will become like second nature to you. They’re very useful. In this case, our list comprehension provides us any value of list X whose values also appear in list Y.
您刚刚看到的被称为列表理解 。 如果您最终爱上了Python,那么对于您来说,这些将成为第二天性。 它们非常有用。 在这种情况下,我们的列表理解为我们提供了列表X的任何值,其值也出现在列表Y中。
Now that we know we have two columns in common, what are we waiting for!? Initiate the blind date!
现在我们知道我们有两个共同点,我们还在等什么! 开始相亲!
步骤3:好的,让我们尝试一下相亲… (Step 3: alright, let’s give the blind date a try…)
So we have ‘Order ID’ and ‘Market’ in common between our orders and our returns. Let’s join them.
因此,我们的订单和退货之间共有“订单ID”和“市场”。 让我们加入他们。
In Pandas, you can use the join() method and you can also use the merge() method. Different strokes for different folks. I prefer the merge() method in pretty much any scenario, so that’s what we’ll use here. Team merge, for life.
在Pandas中,您可以使用join()方法,也可以使用merge()方法。 物以类聚,人以群分。 在几乎所有情况下,我都更喜欢merge()方法,因此我们将在这里使用它。 团队合并,终生一生。
blind_date_df = store_df.merge(returns_df, on=['Order ID', 'Market'], how='left')And let’s see what the results look like:
让我们看看结果如何:
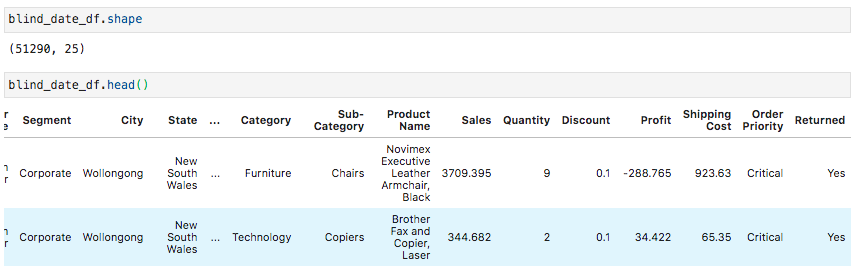
First of all, we ran .shape on the resulting dataframe to get values for the number of rows and columns (in that order). So our resulting dataframe has 51,290 rows and 25 columns, where the original orders dataframe has 51,290 rows and 24 columns.
首先,我们在结果数据帧上运行.shape以获取行数和列数的值(按该顺序)。 因此,我们得到的数据框具有51,290行和25列,而原始订单数据框具有51,290行和24列。
This join has effectively sprinkled in new data for each of our rows, providing one additional column named ‘Returned’, which takes on the value of ‘Yes’ if an order was returned.
此联接有效地为我们的每一行添加了新数据,并提供了一个名为“ Returned”的附加列,如果返回了订单,该列的值为“ Yes”。
Note that in our join we specified the columns to join on as well as how to perform the join. What is this ‘left’ join? It simply means that the table that was there first (in this example that is our store_df) will remain as-is, and the new table’s data will be sprinkled onto it wherever relevant.
请注意,在我们的联接中,我们指定了要联接的列以及执行联接的方式。 什么是“左”联接? 这只是意味着首先存在的表(在本例中为store_df )将保持原样,并且新表的数据将在任何相关的地方散布到该表上。
Let’s compare this to an inner join:
让我们将其与内部联接进行比较:

This inner join behaves differently from our left join in the sense that it only keeps the intersection between the two tables. This type of join would be useful if we only cared about analyzing orders that were returned, as it filters out any orders that were not returned.
此内部联接的行为与我们的左联接不同,因为它仅保持两个表之间的交集。 如果我们只关心分析已退回的订单,则这种类型的联接将很有用,因为它会过滤掉未退回的所有订单。
步骤4:相亲怎么了? (Step 4: so what’s wrong with the blind date?)
Sometimes you think you know everything, and that’s when it bites you the hardest. In this example, we think we know that we have two matching columns: ‘Order ID’ and ‘Market’. But do our two data sets agree on what a market is?
有时您认为自己知道所有事情,那是最难的时刻。 在此示例中,我们认为我们知道有两个匹配的列:“订单ID”和“市场”。 但是,我们的两个数据集是否就什么是市场达成共识?
Let’s stir up some drama. Orders, how do you define your markets?
让我们煽动一些戏剧。 订单,您如何定义市场?
store_df['Market'].unique()
This line of code takes a look at the entire ‘Market’ column and outputs the unique values found within it.
此行代码将查看整个“市场”列,并输出在其中找到的唯一值。
Okay. Returns, how do you define your markets?
好的。 退货,您如何定义市场?

It looks like our orders and returns teams both need to get on the same page in terms of whether they use acronyms for markets or spell them out.
看来我们的订单和退货团队都需要在同一个页面上使用首字母缩写词表示市场还是将其拼写清楚。
On the orders side, to avoid future issues we should probably switch ‘Canada’ to an acronym value like ‘CA’.
在订单方面,为避免将来出现问题,我们可能应该将“加拿大”更改为“ CA”等首字母缩写值。
On the returns side, to avoid future issues we should probably switch ‘United States’ to ‘US’
在收益方面,为了避免将来出现问题,我们可能应该将“美国”切换为“美国”
But wait, that only fixes the future issues… what kinds of problems is this causing right now?
但是,等等,这只能解决未来的问题……这现在会引起什么问题?
步骤5:盲目加入后清理 (Step 5: cleaning up after a blind join)
To see the mess we’re in, let’s look at how many returns we have per market (using the inner join from earlier):
为了弄清楚我们所处的混乱状况,让我们看一下每个市场有多少回报(使用前面的内部联接):

Hurray, it looks like our US market is perfect and has no returns! Or wait, is it the United States market… ah, oops.
华友世纪,看来我们的美国市场是完美的,没有任何回报! 还是等等,这是美国市场吗?
Because the data containing our orders calls the market ‘US’ and the data containing our returns calls the market ‘United States’, the join will never match the two.
因为包含我们的订单的数据将市场称为“美国”,而包含我们的退货的数据将市场称为“美国”,所以联接将永远不会匹配两者。
Luckily, it’s really easy to rename our markets. Here’s a quick way to do it in this situation, where there’s really just one mismatch that’s causing a problem. This introduces the concept of a lambda function, which you can simply ignore for now if it makes no sense to you.
幸运的是,重命名我们的市场真的很容易。 在这种情况下,这是一种快速的解决方法,实际上只有一个不匹配会导致问题。 这引入了lambda函数的概念,如果对您没有意义,您可以暂时忽略它。
returns_df['Market'] = returns_df['Market'].apply(lambda market: market.replace('United States', 'US'))Basically what this does is it creates a function on the fly that we use quickly to perform a useful action in a single line of code. The result of running the line of code above is that any occurrence of the ‘United States’ market has been renamed to ‘US’.
基本上,这是在运行中创建一个函数,我们可以快速使用它在一行代码中执行有用的操作。 运行上述代码行的结果是,所有出现的“美国”市场都已重命名为“美国”。
Now, if we run that inner join between store_df and returns_df, the results will look a bit different:
现在,如果我们在store_df和returns_df之间运行该内部联接 ,结果将看起来有些不同:

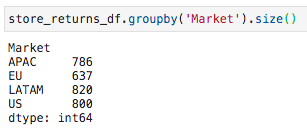
And if we check how many returns there are per market, we get this:
如果我们检查每个市场有多少回报,我们将得到:
第6步:对数据上瘾者的挑战 (Step 6: a little challenge for the data addicts out there)
Now that we know how to join our orders and our returns, can you figure out how to stitch together a table like the one shown below?
既然我们知道如何加入订单和退货,那么您能否弄清楚如何将一张表格拼接在一起,如下图所示?

Looks like the ‘Tables’ sub-category is crying out for attention again! We can’t escape it.
看起来“表格”子类别再次引起人们的注意! 我们无法逃脱。
Applying what we’ve learned so far in this series, can you recreate this table on your own? If you’re a real over-achiever, go ahead and build it in Tableau as well and compare the process. How do you handle the market mismatch in Tableau vs Python? There are multiple ways to crack the case — go try it out!
运用我们在本系列中到目前为止所学到的知识,您可以自己重新创建该表吗? 如果您是真正的成就者,请继续在Tableau中进行构建,并进行比较。 您如何处理Tableau vs Python中的市场不匹配问题? 有多种破解方法-试试吧!
结语 (Wrapping it up)
Joining data is an absolutely crucial skill if you’re working with data at scale. Understanding what you’re joining is as important as knowing the technical details of how to execute the joins, keep that in mind!
如果您要大规模处理数据,那么连接数据是绝对至关重要的技能。 了解您要加入的内容与了解如何执行连接的技术细节一样重要,请记住这一点!
If you send your data on a blind date to be joined with another table, be aware of the risks. Scrub your data sets clean before sending them on dates with other data. Dirty data tends to leave a mess, and you’ll be the one troubleshooting it.
如果您在相亲数据中发送数据以与另一个表结合使用,请注意风险。 在将数据集与其他数据一起发送之前,先清理数据集。 肮脏的数据容易造成混乱,您将成为对它进行故障排除的人。
Hope to see you next time as we dive into crafting reusable code using functions!
希望下次我们使用函数编写可重用代码时与您见面!
翻译自: https://towardsdatascience.com/a-gentle-introduction-to-python-for-tableau-developers-part-4-a6fd6b2f46b1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/391123.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
![bzoj 4552: [Tjoi2016Heoi2016]排序](http://pic.xiahunao.cn/bzoj 4552: [Tjoi2016Heoi2016]排序)
bzoj 4552: [Tjoi2016Heoi2016]排序

oracle之 手动创建 emp 表 与 dept 表
—单表访问)
深入理解InnoDB(8)—单表访问

蝙蝠侠遥控器pcb_通过蝙蝠侠从Circle到ML:第二部分
)
camera驱动框架分析(上)

工程项目管理需要注意哪些问题
)
leetcode 872. 叶子相似的树(dfs)

探索感染了COVID-19的动物的数据

Facebook哭晕在厕所,调查显示用VR体验社交的用户仅为19%


解决Javascript疲劳的方法-以及其他所有疲劳

Java 8 的List<V> 转成 Map<K, V>

已知两点坐标拾取怎么操作_已知的操作员学习-第4部分

北京供销大数据集团发布SinoBBD Cloud 一体化推动产业云发展

windows下有趣的小玩意

rxjs angular_Angular RxJS深度

HashMap, LinkedHashMap 和 TreeMap的区别

“陪护机器人”研报:距离真正“陪护”还差那么一点

neo-6m uno_Uno-统治所有人的平台
