ai对话机器人实现方案
A couple of folks from Obviously.ai contacted me a few days back to introduce their service — a completely no-code machine learning automation tool. I was a bit skeptical at first, as I always am with supposedly fully-automated solutions, but I decided to give it a try. I’ll share my thoughts in this article, and discuss if service is worth the try.
几天前,来自Obviously.ai的几个人联系了我,介绍他们的服务-完全无代码的机器学习自动化工具。 一开始我有点怀疑,因为我一直都在使用所谓的全自动解决方案,但是我决定尝试一下。 我将在本文中分享我的想法,并讨论服务是否值得尝试。
I find it somewhat difficult to watch tools like this one automate machine learning, and decrease the need for machine learning engineers in small and medium-sized companies. The reasons are many, but the biggest is that the purpose of machine learning was to automate other professions, but we’ve managed to automate machine learning with machine learning. Good job.
我发现观看这种自动化机器学习的工具有点困难,并减少了中小型公司对机器学习工程师的需求。 原因有很多,但最大的原因是机器学习的目的是使其他专业自动化,但是我们已经设法通过机器学习使机器学习自动化。 做得好。
It’s not entirely a bad thing, as we can now focus on more important things, instead of fitting algorithm after algorithm, with the aim of squeezing that additional 0.15% accuracy.
这并不完全是一件坏事,因为我们现在可以专注于更重要的事情,而不是逐个算法进行拟合,以期提高0.15%的精度。
So, what is Obviously AI?
那么,什么是AI?
Hero section on their home page explains it pretty well:
他们主页上的“英雄”部分对此进行了很好的解释:
The total process of building ML algorithms, explaining results, and predicting outcomes in one single click.
一次单击即可构建ML算法,解释结果和预测结果的总过程。
After playing around with it for a bit, I must say that it delivers. So, what’s the catch? Good question. We are accustomed to quite pricy solutions in this day and age, and ObviouslyAI is not an exception. It has a more than decent free plan, limited to CSV files only with no more than 50,000 rows. That’s more than enough for basic exploration.
在玩了一段时间之后,我必须说它交付了。 那么,有什么收获呢? 好问题。 在当今时代,我们已经习惯了价格昂贵的解决方案, 显然AI也不例外。 它有一个不错的免费计划,只限于CSV文件(不超过50,000行)。 对于基础探索而言,这绰绰有余。
I’m on the Free plan currently, and it’s more than enough for my needs. We’ll now go through a concrete example of training a machine learning model with this service, and you’ll see how stupidly easy the entire thing is.
我目前处于“免费”计划中,已经足够满足我的需求。 现在,我们将通过使用此服务来训练机器学习模型的具体示例,您将看到整个过程多么简单。
Before we start, I want to make a quick disclaimer. Even though folks at ObviouslyAI asked me to review their service, I am in no way affiliated with them, nor will I try to convince you to switch to a paid account. Everything I say is based purely on the Free version.
在开始之前,我想快速声明一下。 即使ObviouslyAI的人员要求我审查他们的服务,但我绝不隶属于他们,也不会说服您切换到付费帐户。 我所说的一切完全基于免费版本。
注册和设置 (Registration and setup)
It was at this step that the first strange thing happened. I’ve gone ahead and opened the Signup page, and was prompted to enter an email. What was strange is that my personal Gmail account wasn’t eligible for registration.
正是在这一步,第一件事发生了。 我已经打开了“注册”页面,并被提示输入电子邮件。 奇怪的是我的个人Gmail帐户不符合注册条件。
A business email account is a must.
企业电子邮件帐户是必须的。
I have a business email account from my company, so that wasn’t an issue, but might be a dealbreaker for some of you. I can’t verify if the same thing happens for other email providers, but Gmail doesn’t work at this point in time. Strange.
我有一个来自公司的企业电子邮件帐户,所以这不是问题,但对于某些人来说可能是一个大问题。 我无法验证其他电子邮件提供商是否也发生了同样的事情,但是Gmail目前无法正常工作。 奇怪。
Nevertheless, I’ve completed the registration process and verified the email address, and then I was presented with a nice-looking dashboard:
不过,我已经完成了注册过程并验证了电子邮件地址,然后看到一个漂亮的仪表板:
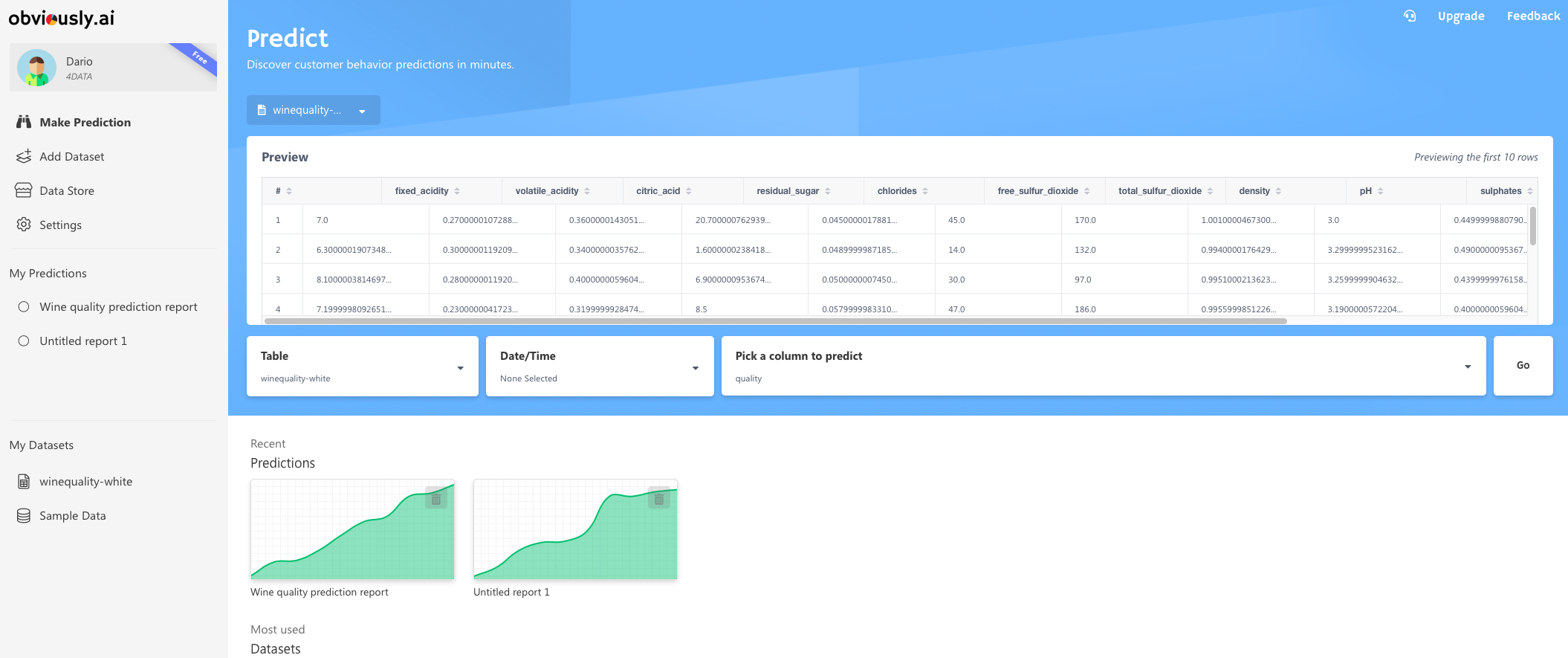
There are some sample datasets built-in, but I guess those work flawlessly. We won’t be using those for our machine learning tasks, and will instead be using a well-known Wine dataset. Let’s build a model in the next section.
有一些内置的示例数据集,但我想它们可以完美地工作。 我们不会将这些用于机器学习任务,而是将使用众所周知的Wine数据集 。 让我们在下一部分中构建模型。
建立模型 (Building a model)
This step is stupidly simple, as stated earlier. The first to do is to upload the dataset. We’ll use the Add Dataset button on the sidebar to do so:
如前所述,这一步骤非常简单。 首先要做的是上传数据集。 我们将使用边栏上的“ 添加数据集”按钮执行此操作:

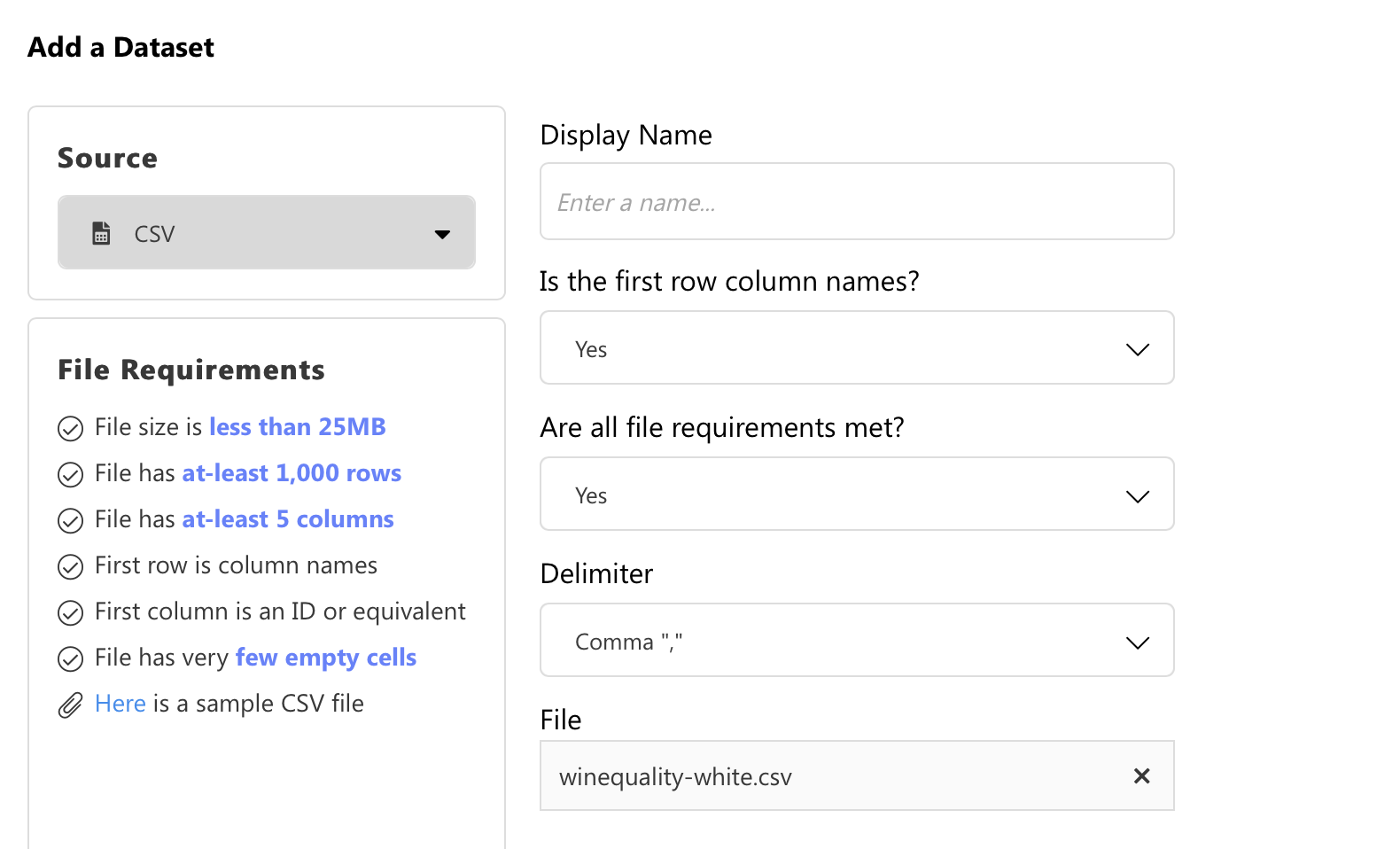
Once clicked, a modal should appear on which we can drag and drop (or click to upload) our dataset. Keep in mind these constraints (free version):
单击后,将出现一个模态,我们可以在其上拖放(或单击以上传)我们的数据集。 请记住以下限制 (免费版本):
- File size must be less than 25MB 档案大小必须小于25MB
- There must be at least 1000 rows 必须至少有1000行
- There must be at least 5 columns 必须至少有5列
Our wine dataset passes all of those conditions, so we can upload it:
我们的葡萄酒数据集通过了所有这些条件,因此我们可以上传它:
Once the upload is finished, we’ll get to this well-presented exploration modal:
上传完成后,我们将进入这个精心呈现的探索模式:
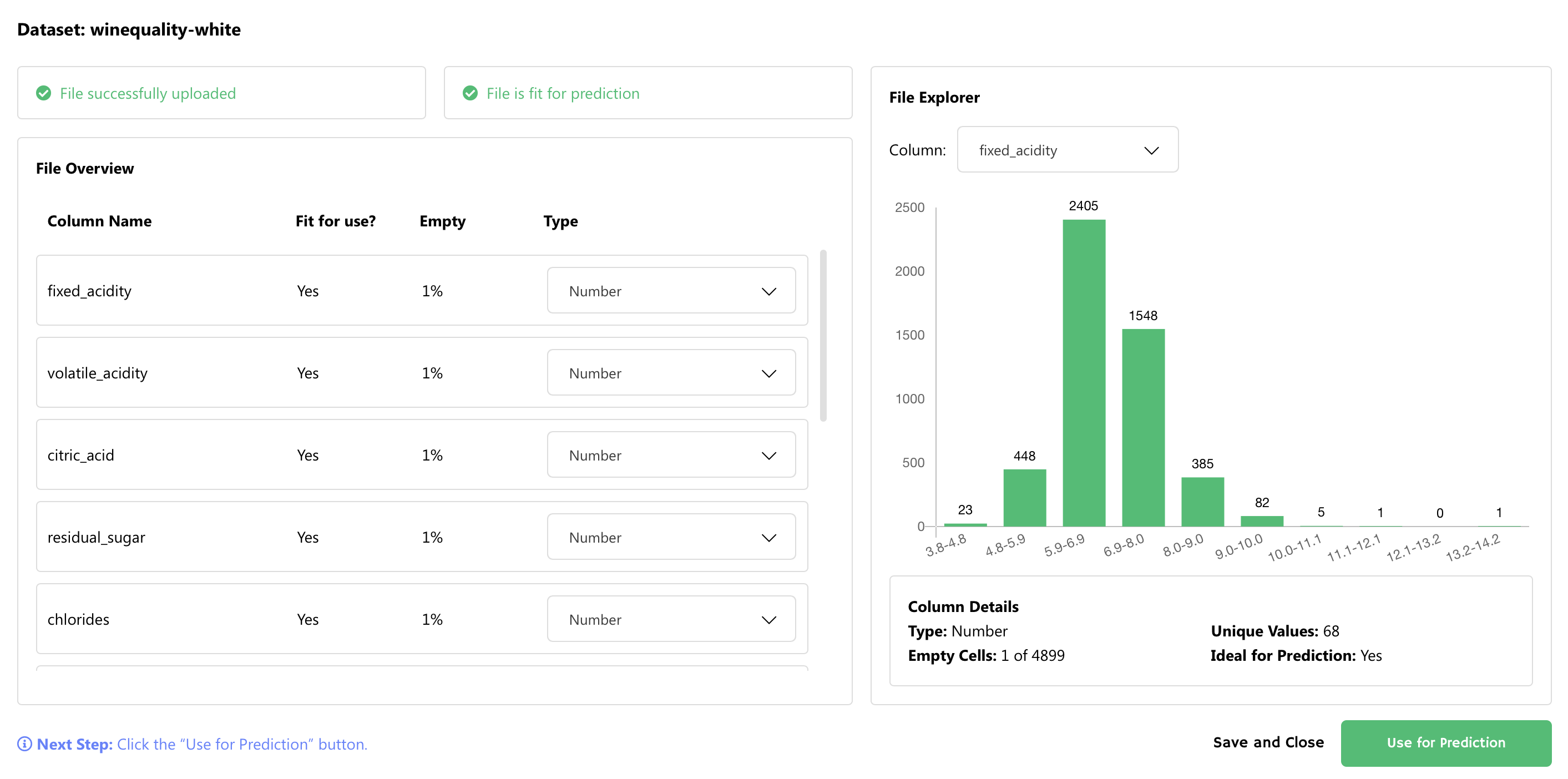
From here, we just need to follow the instructions. Let's click on the Use for Prediction button. We’re almost finished with the preparation. In the next modal window we just need to choose the target variable:
从这里开始,我们只需要按照说明进行操作即可。 让我们单击“ 用于预测”按钮。 准备工作差不多完成了。 在下一个模态窗口中,我们只需要选择目标变量:
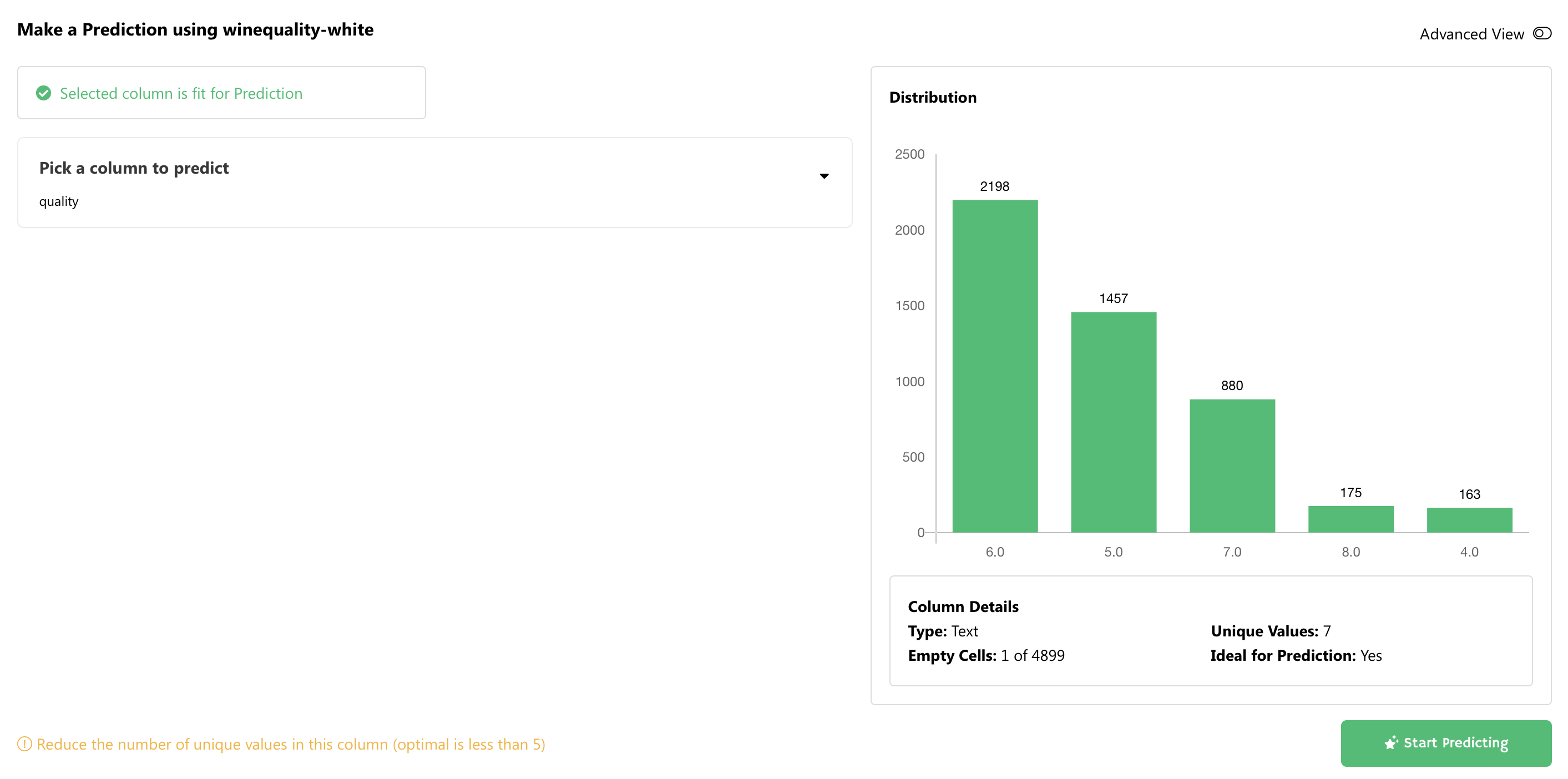
And that’s it! The service complains that we should reduce the number of unique values in the target variables, but we can ignore that. To finish, just click on the Start Predicting button. That’s all you have to do.
就是这样! 服务抱怨说我们应该减少目标变量中唯一值的数量,但是我们可以忽略它。 要完成操作,只需单击“ 开始预测”按钮。 那就是你要做的。
The model is trained. Done. It’s that easy.
模型经过训练。 做完了 就这么简单。
That doesn’t mean that model is any good, so we’ll explore how it performed in the next section.
这并不意味着该模型有什么用,所以我们将在下一部分中探讨其性能。
模型评估 (Model evaluation)
Once the model is trained, we’re presented with the report dashboard. It consists of a few areas:
训练好模型后,我们将看到报告仪表板。 它包含以下几个方面:
- Drivers 车手
- Personas 角色
- Export Predictions 出口预测
- Advanced Analytics 进阶分析
- Tech Specs 技术规格
We’ll explore a couple of those here, the first being the Drivers area.
我们将在这里探索其中的两个,第一个是“ 驾驶员”区域。
司机区 (Drivers area)
Put simply, this area tells us which variables are most important for forecasting, ergo which variables have the greatest prediction power. In our case, variables density, alcohol, and free_sulfur_dioxide are the top 3:
简而言之,该区域告诉我们哪些变量对预测最重要,因此,哪些变量具有最大的预测能力。 在我们的案例中,变量density , alcohol和free_sulfur_dioxide是排名free_sulfur_dioxide变量:
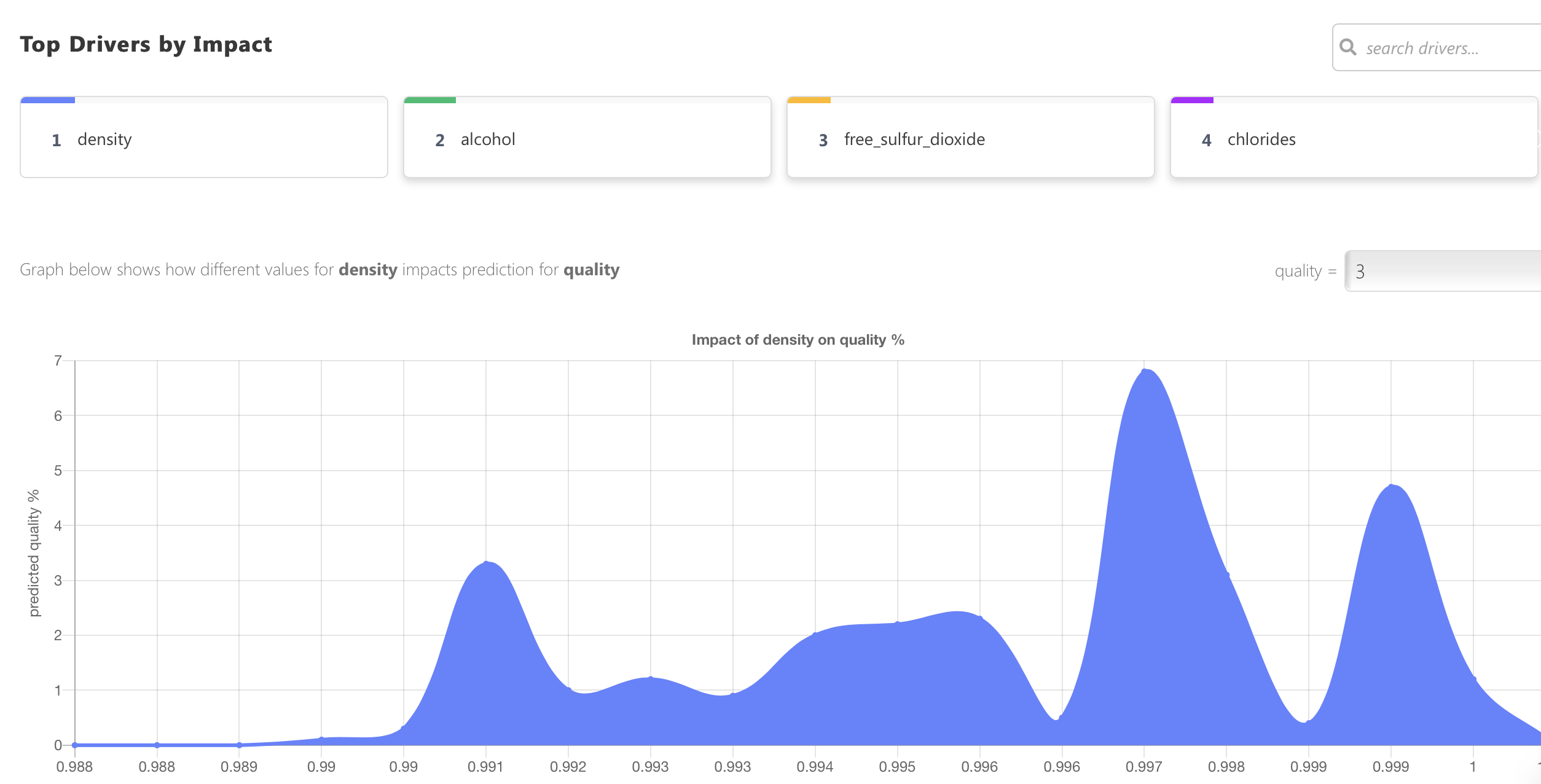
Nicely formatted and easy to understand. Let’s proceed.
格式正确,易于理解。 让我们继续。
出口预测区域 (Export Predictions area)
There’s no point in machine learning without making predictions on new, previously unseen data. That’s where the free version falls short, unfortunately. We can make predictions by uploading a CSV of previously unseen data — only attributes without the target variable.
如果不对以前看不见的新数据进行预测,则机器学习毫无意义。 不幸的是,这就是免费版本不足的地方。 我们可以通过上传以前看不见的数据的CSV做出预测-仅包含没有目标变量的属性。
That’s all the free version offers. It might be enough for you, but I was expecting to see more.
这就是所有免费版本所提供的。 对您来说可能就足够了,但是我希望看到更多。
What paid version gets you is deployed version of your model in the form of a REST API, which makes predictions that much easier to make from any programming language:
付费版本为您提供的是REST API形式的模型的已部署版本,这使得使用任何编程语言进行预测都变得更加容易:

This option isn’t supported in the free version, unfortunately, but can you blame them?
不幸的是,免费版本不支持此选项,但是您能怪他们吗?
技术规格区 (Tech Specs area)
This area displays some basic information about the model, such as which algorithm was used, what was the accuracy on the train, test, and validation subsets, etc:
此区域显示有关模型的一些基本信息,例如使用了哪种算法,训练,测试和验证子集的准确性如何,等等:
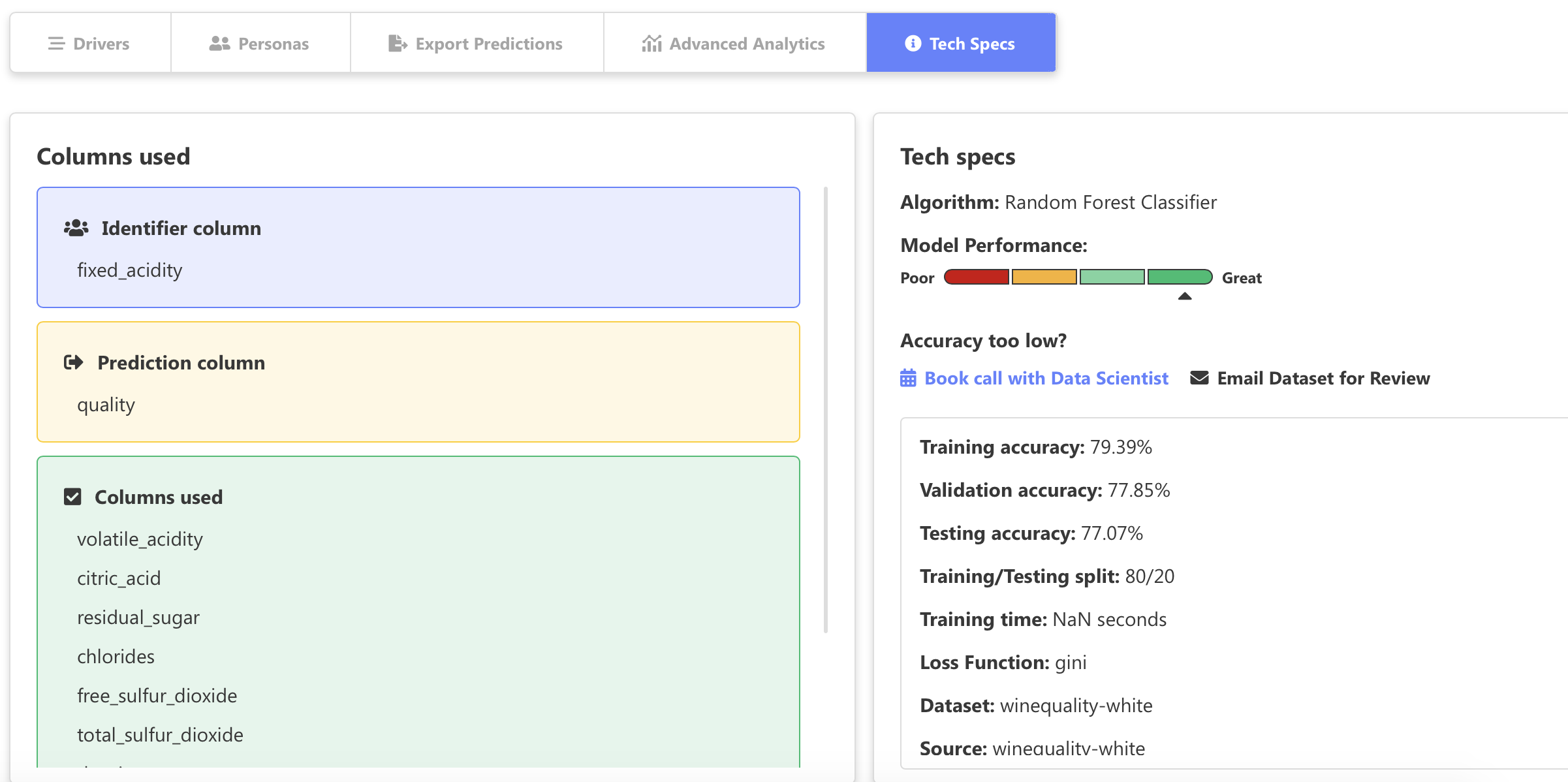
It’s a nice section to get a basic understanding of your model, but that’s it.
这是一个很好的部分,可以基本了解您的模型,仅此而已。
And that’s pretty much it for this introductory article to ObviouslyAI. Let’s wrap things up in the next section.
这就是ObviouslyAI的介绍性文章。 让我们在下一节中总结一下。
你走之前 (Before you go)
In a nutshell, ObviouslyAI is obviously awesome, and such an easy service to recommend. For small to medium-sized businesses I can even see it as the only data science solution, maintained by one or more software developers that are training models with a couple of clicks and making predictions with API calls.
简而言之, 显然 AI很棒,而且推荐这种简单的服务。 对于中小型企业,我什至可以将其视为唯一的数据科学解决方案,由一个或多个软件开发人员维护,他们只需单击几次即可训练模型,并通过API调用进行预测。
Data science teams could deliver a better solution, sure, but that team would potentially cost tens of thousands USD per month, where this solution is somewhere below $200 per month for the most expensive option. You do the math.
数据科学团队当然可以提供更好的解决方案,但是该团队每月可能花费数万美元,而对于最昂贵的选择而言,该解决方案每月的费用不到200美元。 你做数学。
It was obvious right from the start that data science will become just another flavor of software engineering, but it is services like this one that change the minds of even the most stubborn individuals.
从一开始就显而易见,数据科学将成为软件工程的另一种形式,但正是这种服务改变了即使是最顽固的个人的想法。
What are your thoughts? Have you tried ObviouslyAI? Feel free to drop your thoughts in the comment section.
你觉得呢?你有没有什么想法? 您是否尝试过ObviouslyAI? 随时在评论部分中发表您的想法。
Join my private email list for more helpful insights.
加入我的私人电子邮件列表以获取更多有用的见解。
翻译自: https://towardsdatascience.com/introducing-obviouslyai-no-code-machine-learning-solution-da528c81071c
ai对话机器人实现方案
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389088.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章


透明状态栏导致windowSoftInputMode:adjustResize失效问题
![[TimLinux] JavaScript 元素动态显示](http://pic.xiahunao.cn/[TimLinux] JavaScript 元素动态显示)
[TimLinux] JavaScript 元素动态显示


图片中的暖色或冷色滤色片是否会带来更多点击? —机器学习A / B测试

3d制作中需要注意的问题_浅谈线路板制作时需要注意的问题

冷启动、热启动时间性能优化

python:lambda、filter、map、reduce


Myeclipes连接Mysql数据库配置
...)
cnn图像二分类 python_人工智能Keras图像分类器(CNN卷积神经网络的图片识别篇)...

图卷积 节点分类_在节点分类任务上训练图卷积网络
![[微信小程序] 当动画(animation)遇上延时执行函数(setTimeout)出现的问题](http://pic.xiahunao.cn/[微信小程序] 当动画(animation)遇上延时执行函数(setTimeout)出现的问题)
[微信小程序] 当动画(animation)遇上延时执行函数(setTimeout)出现的问题

关于使用pdf.js预览pdf的一些问题

SqlHelper改造版本

回归分析预测_使用回归分析预测心脏病。

)

UDP打洞程序包的源码
