朴素贝叶斯分类器 文本分类
背景 (Background)
Following a disaster, typically you will get millions and millions of communications, either direct or via social media, right at the time when disaster response organizations have the least capacity to filter and pull out the messages which are the most important. And often it really is only one in every thousand messages that might be relevant to disaster response professionals.
灾难发生后,通常在灾难响应组织过滤和提取最重要消息的能力最差的时候,您将直接或通过社交媒体获得数以百万计的通信。 通常,实际上只有十分之几的消息可能与灾难响应专业人员相关。
So the way that disasters are typically responded to is that different organizations will take care of different parts of the problem. One organization will care about water, another one will care about blocked roads, and another will care about medical supplies.
因此,灾难通常的应对方式是不同的组织将处理问题的不同部分。 一个组织将关心水,另一个组织将关心道路阻塞,另一个组织将关心医疗用品。
— Robert Munro, former CTO of Figure Eight (acquired by Appen)
-图8的前CTO Robert Munro(被Appen收购)
Robert Munro summed up the problem quite well. With so many messages being received during disasters, there needs to be a way of directing these messages to the appropriate organization so that they can respond to the problem accordingly.
Robert Munro很好地总结了这个问题。 灾难期间收到了如此多的消息,因此需要一种将这些消息定向到适当组织的方法,以便它们可以相应地对问题做出响应。
Using data from Figure Eight (now Appen), we will be building a web application to classify disaster messages so that an emergency professional would know which organization to send the message to.
使用图八 (现在为Appen)中的数据,我们将构建一个Web应用程序以对灾难消息进行分类,以便紧急事件专业人员知道将消息发送到哪个组织。
This walkthrough assumes you have some knowledge of natural language processing and machine learning. We will go over the general process but you can see the full code at my Github.
本演练假定您具有一些自然语言处理和机器学习的知识。 我们将介绍整个过程,但是您可以在我的Github上查看完整的代码。
数据 (The Data)
The data contains 26,248 labeled messages that were sent during past disasters around the world. Each message is labeled as 1 or more of the following 36 categories:
数据包含在世界各地过去的灾难中发送的26,248条带标签的邮件。 每条消息被标记为以下36个类别中的1个或多个:
'related', 'request', 'offer', 'aid_related', 'medical_help', 'medical_products', 'search_and_rescue', 'security', 'military', 'child_alone', 'water', 'food', 'shelter', 'clothing', 'money', 'missing_people', 'refugees', 'death', 'other_aid', 'infrastructure_related', 'transport', 'buildings', 'electricity', 'tools', 'hospitals', 'shops', 'aid_centers', 'other_infrastructure', 'weather_related', 'floods', 'storm', 'fire', 'earthquake', 'cold', 'other_weather', 'direct_report'
“相关”,“请求”,“提供”,“援助相关”,“医疗帮助”,“医疗产品”,“搜索和救援”,“安全”,“军事”,“独身”,“水”,“食品”,“庇护所” ”,“衣服”,“钱”,“失民”,“难民”,“死亡”,“其他援助”,“基础设施相关”,“运输”,“建筑物”,“电力”,“工具”,“医院”, “商店”,“援助中心”,“其他基础设施”,“与天气相关”,“洪水”,“风暴”,“火灾”,“地震”,“寒冷”,“其他天气”,“直接报告”
Note: Messages don’t necessarily fall into only 1 category. A message can be labeled as multiple categories or even none.
注意:邮件不一定只属于1类。 一条消息可以标记为多个类别,甚至可以都不标记。

As seen in figure 1, the original data was split into 2 CSV files:
如图1所示 ,原始数据分为2个CSV文件:
- Messages dataset — the messages and the method in which they were receive 邮件数据集-邮件及其接收方法
- Categories dataset — The categories the messages were labeled as 类别数据集-邮件被标记为的类别
And the categories dataset (figure 1B) was formatted in a way that is unusable. All 36 categories and their corresponding values (0 for no or 1 for yes) are stuffed into a single column. To be able to use this dataset as labels for our supervised learning model, we’ll need to transform that single column into 36 separate columns (1 for each category) with binary numeric values, shown in figure 2 below.
而且类别数据集( 图1B)的格式无法使用。 所有36个类别及其对应的值(0表示“否”或1表示“是”)被填充到一列中。 为了能够将此数据集用作监督学习模型的标签,我们需要将该单列转换为具有二进制数值的36个单独的列(每个类别1个),如下图2所示。

None of the messages in the dataset were labeled as child_alone so this category will be removed since it is not providing any information.
数据集中的所有消息均未标记为child_alone因此将删除该类别,因为它未提供任何信息。
To prepare the data, I wrote an ETL pipeline with the following steps:
为了准备数据,我编写了一个ETL管道,其步骤如下:
- Import the data from the 2 CSV files 从2个CSV文件导入数据
Transform the categories dataset from 1 string variable (figure 1B) into 36 numeric variables (figure 2)
将类别数据集从1个字符串变量( 图1B )转换为36个数字变量( 图2 )
Drop
child_alonefrom the categories dataset, leaving 35 categories left to classify从类别数据集中删除
child_alone,剩下35个类别以进行分类- Merge the 2 datasets into 1 将2个数据集合并为1个
- Load the merged dataset into a SQLite database 将合并的数据集加载到SQLite数据库中
分类器 (The Classifier)
With the data processed, we can use it to train a classification model. But wait! Machine learning models don’t know how to interpret text data directly, so we need to somehow convert the text into numeric features first. No worries though. This feature extraction can be done in conjunction with the classification model within a single pipeline.
处理完数据后,我们可以使用它来训练分类模型。 可是等等! 机器学习模型不知道如何直接解释文本数据,因此我们需要首先以某种方式将文本转换为数字特征。 不用担心。 可以与单个管道中的分类模型一起完成此特征提取。
The machine learning pipeline (code below) was built as follows:
机器学习管道(以下代码)的构建如下:
1. Tf-idf vectorizer — tokenizes an entire corpus of text data to build a vocabulary and converts individual documents into a numeric vector based on the vocabulary
1. Tf-idf矢量化器 -标记整个文本数据集以构建词汇表,并根据该词汇表将单个文档转换为数字矢量
Tokenizer steps: lowercase all characters > remove all punctuation > tokenize text into individual words > strip any white space surrounding words > remove stopwords (words that add no meaning to a sentence) > stem remaining words
标记生成器步骤:小写字母>除去所有标点>标记化文本为单个单词>剥去任何空白周围的单词>移除停止词(即没有意义添加到句子话)>干剩余字
Vectorizer steps: convert a text document into a term frequency vector (word counts) > normalize word counts by multiplying the inverse document frequency
矢量化器步骤:将文本文档转换为术语频率矢量(字数)>通过乘以逆文档频率将字数归一化
2. Multi-output classifier using a logistic regression model — predicts 35 binary labels (0 or 1 for each of the 35 categories)
2. 使用逻辑回归模型的多输出分类器 -预测35个二元标签(35个类别中的每个类别为0或1)
After importing the data from the database we just created, we split the data into a training and test set, and use the training set to train the classifier pipeline outlined above. A grid search was done to optimize the parameters for both steps in the pipeline and the final classifier was evaluated on the test set with the following results:
从刚刚创建的数据库中导入数据后,我们将数据分为训练和测试集,并使用训练集来训练上面概述的分类器管道。 进行了网格搜索以优化管道中两个步骤的参数,并在测试集中对最终分类器进行了评估,结果如下:
Average accuracy: 0.9483
平均准确度 :0.9483
Average precision: 0.9397
平均精度 :0.9397
Average recall: 0.9483
平均召回率 :0.9483
Average F-score: 0.9380
平均F值 :0.9380
As this was a multi-output classification problem, these metrics were averaged across all 35 outputs.
由于这是一个多输出分类问题,因此对所有35个输出进行平均。
I also tried Naive Bayes and random forest models, but they didn’t perform as well as the logistic regression model. The random forest model had slightly better metrics for a lot of the categories, but since it takes significantly longer to train, I opted for logistic regression.
我还尝试过朴素贝叶斯和随机森林模型,但它们的表现不如逻辑回归模型。 对于许多类别,随机森林模型的指标稍好一些,但是由于训练所需的时间明显更长,因此我选择了逻辑回归。
Finally, the trained classifier is saved in pickle format.
最后,训练有素的分类器以泡菜格式保存。
应用程序 (The Application)
Now that we have a trained classifier, we can build it into a web application that classifies disaster messages. Personally, I prefer Flask as it is a lightweight framework, perfect for smaller applications. The app’s interface is shown in figure 4 below.
现在,我们拥有训练有素的分类器,可以将其构建到对灾难消息进行分类的Web应用程序中。 就个人而言,我更喜欢Flask,因为它是轻量级的框架,非常适合较小的应用程序。 该应用程序的界面如下图4所示。
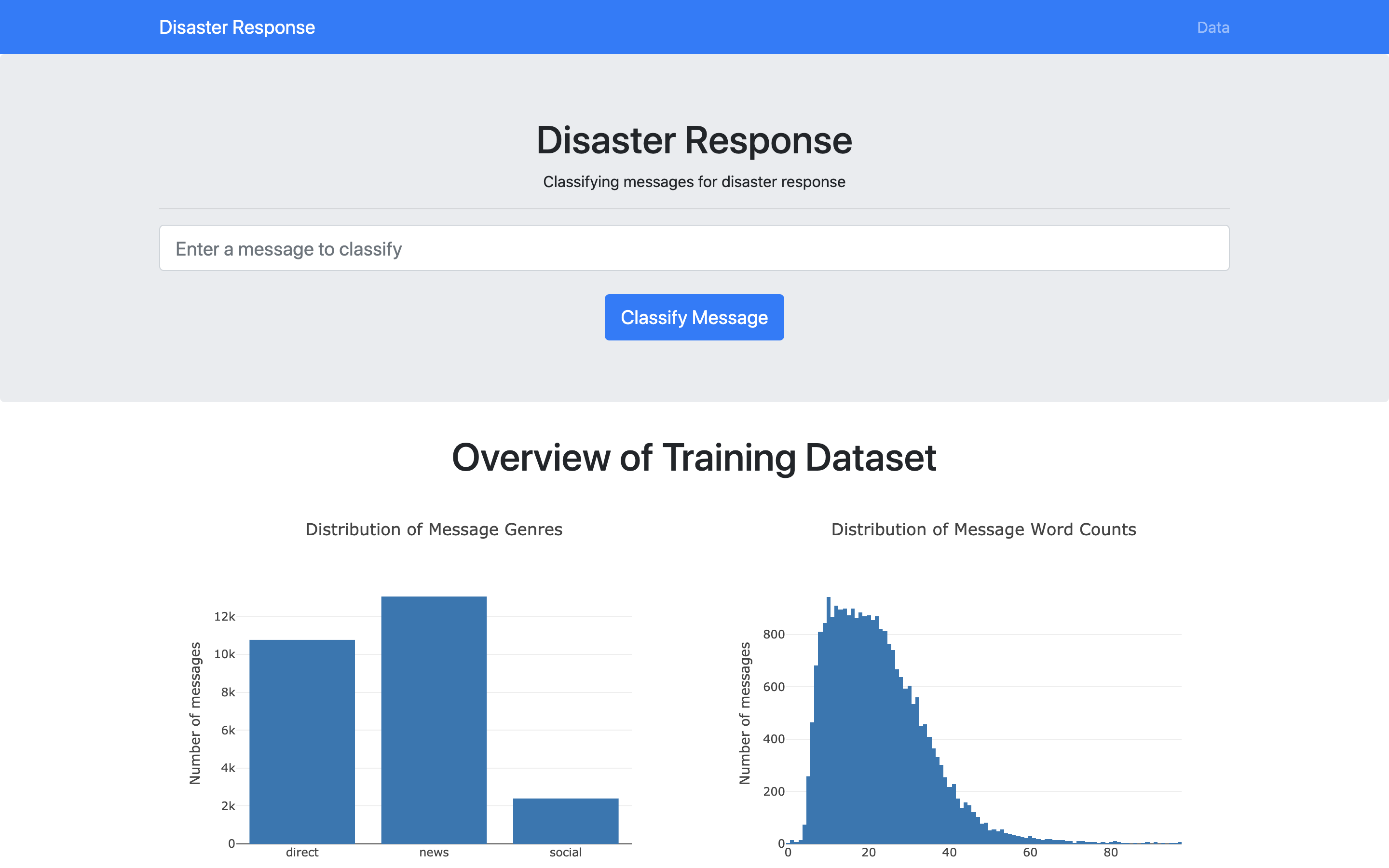
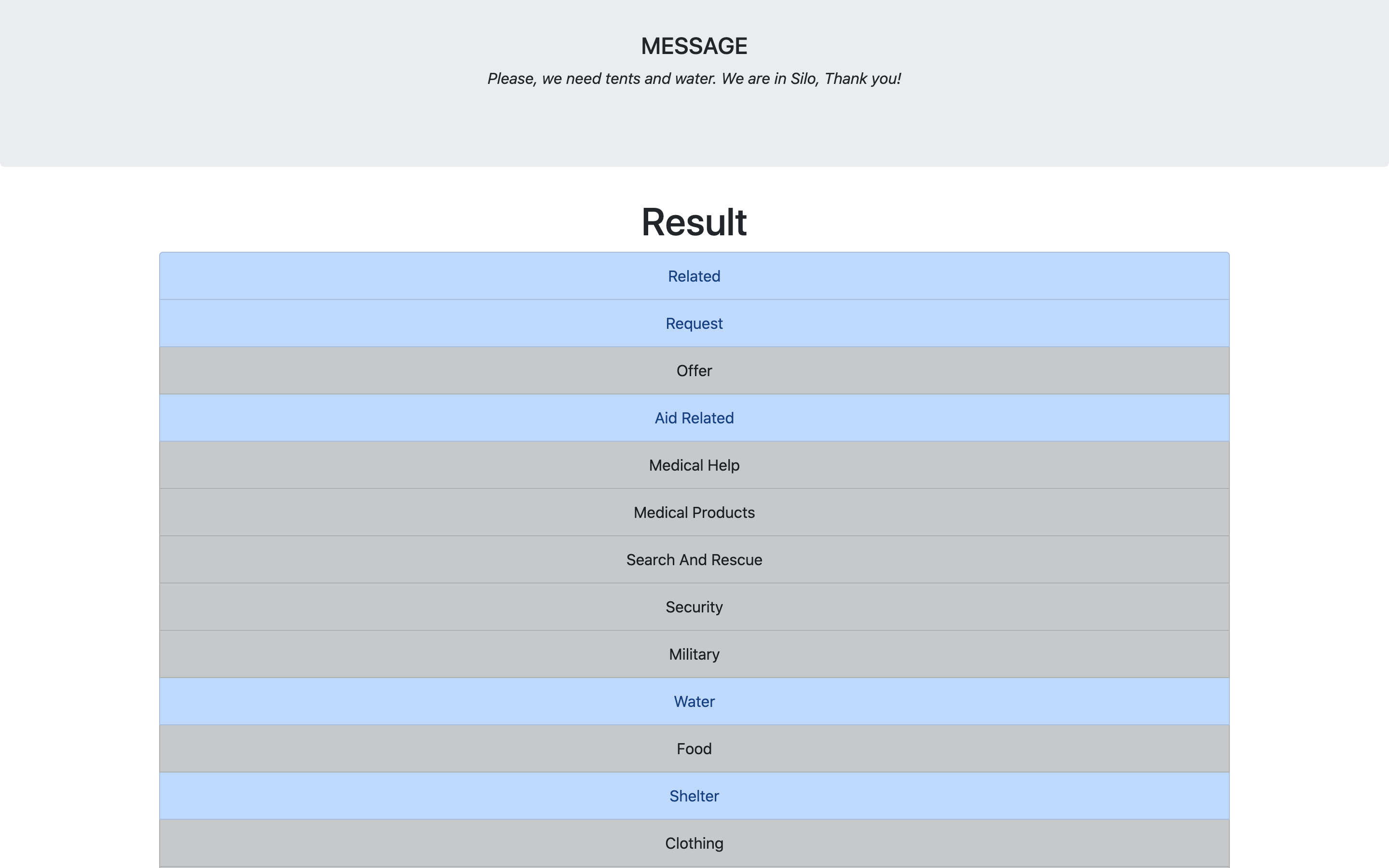
As shown in Figure 4, the web application has 2 pages:
如图4所示,Web应用程序有2个页面:
Home page: This page contains an input field to enter a message to classify and a dashboard of interactive visualizations that summarizes the data. The dashboard (created with Plotly) shows the (1) distribution of message genres, (2) the distribution of message word counts, (3) top message categories, and (4) the most common words in messages.
主页 :此页面包含一个输入字段,用于输入要分类的消息以及用于汇总数据的交互式可视化仪表板。 仪表板(使用Plotly创建)显示(1)消息类型的分布,(2)消息字数的分布,(3)顶部消息类别,以及(4)消息中最常见的单词。
Result page: This page displays the message that was entered into the input field and the 35 classification results for that message. The categories highlighted blue are the categories that the message was classified as.
结果页面 :此页面显示输入到输入字段中的消息以及该消息的35个分类结果。 蓝色突出显示的类别是邮件被分类为的类别。
Both pages were written in HTML and Bootstrap (a CSS library) and are rendered by the Flask app. To build the app, we first load in the data and the trained model.
这两个页面都是用HTML和Bootstrap(一个CSS库)编写的,并由Flask应用程序呈现。 要构建该应用程序,我们首先要加载数据和经过训练的模型。
We use the data to set up the home-page visualizations in the back-end with Plotly’s Python library and render these visualizations in the front-end with Plotly’s Javascript library.
我们使用这些数据在Plotly的Python库中在后端设置主页可视化效果,并在Plotly的Javascript库中在前端渲染这些可视化效果。
When text is entered into the input field and submitted, it is fetched by Flask to the back-end where the model will classify it, and the result page will then be rendered with the classification results.
将文本输入输入字段并提交后,Flask会将其提取到模型将对其进行分类的后端,然后将使用分类结果来呈现结果页面。
As shown in figure 4B, I tested an example message:
如图4B 所示 ,我测试了一个示例消息:
“Please, we need tents and water. We are in Silo, Thank you!”
“请,我们需要帐篷和水。 我们在筒仓,谢谢!”
And it was classified as “related”, “request”, “aid related”, “water” and “shelter”.
它分为“相关”,“请求”,“与援助有关”,“水”和“庇护所”。
摘要 (Summary)
The main components of this project are (1) the data processing pipeline, which transforms the data into a usable format and prepares it for the classifier, (2) the machine learning pipeline, which includes a tf-idf vectorizer and a logistic regression classifier, and (3) the web application, which serves the trained classifier and a data dashboard.
该项目的主要组件是(1)数据处理管道,它将数据转换为可用格式并为分类器做准备;(2)机器学习管道,其中包括tf-idf矢量化器和逻辑回归分类器,以及(3)Web应用程序,该服务为训练有素的分类器和数据仪表板提供服务。
Here are some ideas for improving this project you may want to try:
以下是一些改进您可能想尝试的项目的想法:
- Different or additional text processing steps, like lemmatization instead of stemming 不同的或附加的文本处理步骤,例如词法化而不是词干化
- Extract more features from the text, like message word count 从文本中提取更多功能,例如消息字数
- A different classification algorithm, like convolutional neural networks 不同的分类算法,例如卷积神经网络
The web application is available on my Github. Clone the repository and follow the instructions in the readme to try it yourself!
该Web应用程序可在我的Github上找到 。 克隆存储库,并按照自述文件中的说明进行操作!
翻译自: https://medium.com/analytics-vidhya/building-a-text-classifier-for-disaster-response-caf83137e08d
朴素贝叶斯分类器 文本分类
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/388995.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

第二轮冲次会议第六次

markdown 链接跳转到标题_我是如何使用 Vim 高效率写 Markdown 的



Seaborn:Python


Springboot集成BeanValidation扩展一:错误提示信息加公共模板
)
福大软工 · 第十次作业 - 项目测评(团队)

销货清单数据_2020年8月数据科学阅读清单

c++运行不出结果_fastjson 不出网利用总结
)
FocusBI:租房分析可视化(PowerBI网址体验)

米其林餐厅 盐之花_在世界范围内探索《米其林指南》

require_once的用法

差值平方和匹配_纯前端实现图片的模板匹配

蓝牙耳机音量大解决办法_长时间使用蓝牙耳机的危害这么大?我们到底该选什么蓝牙耳机呢?...

JVM基础系列第10讲:垃圾回收的几种类型


spotify 数据分析_我的Spotify流历史分析

idea 搜索不到gsonformat_Idea中GsonFormat插件安装
