本文总结了图的几种最短路径算法的实现:深度或广度优先搜索算法,弗洛伊德算法,迪杰斯特拉算法,Bellman-Ford算法
1),深度或广度优先搜索算法(解决单源最短路径)
从起始结点开始访问所有的深度遍历路径或广度优先路径,则到达终点结点的路径有多条,取其中路径权值最短的一条则为最短路径。
下面是核心代码:
[cpp] view plain copy
- void dfs(int cur, int dst){
- /***operation***/
- /***operation***/
- if(minPath < dst) return;//当前走过路径大于之前最短路径,没必要再走下去
- if(cur == n){//临界条件
- if(minPath > dst) minPath = dst;
- return;
- }
- else{
- int i;
- for(i = 1; i <= n; i++){
- if(edge[cur][i] != inf && edge[cur][i] != 0 && mark[i] == 0){
- mark[i] = 1;
- dfs(i, dst+edge[cur][i]);
- mark[i] = 0; //需要在深度遍历返回时将访问标志置0
- }
- }
- return;
- }
- }
例1:下面是城市的地图,注意是单向图,求城市1到城市5的最短距离。(引用的是上次总结的图论(一)中1)的例2)

[cpp] view plain copy
- /***先输入n个结点,m条边,之后输入有向图的m条边,边的前两元素表示起始结点,第三个值表权值,输出1号城市到n号城市的最短距离***/
- /***算法的思路是访问所有的深度遍历路径,需要在深度遍历返回时将访问标志置0***/
- #include <iostream>
- #include <iomanip>
- #define nmax 110
- #define inf 999999999
- using namespace std;
- int n, m, minPath, edge[nmax][nmax], mark[nmax];//结点数,边数,最小路径,邻接矩阵,结点访问标记
- void dfs(int cur, int dst){
- /***operation***/
- /***operation***/
- if(minPath < dst) return;//当前走过路径大于之前最短路径,没必要再走下去
- if(cur == n){//临界条件
- if(minPath > dst) minPath = dst;
- return;
- }
- else{
- int i;
- for(i = 1; i <= n; i++){
- if(edge[cur][i] != inf && edge[cur][i] != 0 && mark[i] == 0){
- mark[i] = 1;
- dfs(i, dst+edge[cur][i]);
- mark[i] = 0;
- }
- }
- return;
- }
- }
- int main(){
- while(cin >> n >> m && n != 0){
- //初始化邻接矩阵
- int i, j;
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- edge[i][j] = inf;
- }
- edge[i][i] = 0;
- }
- int a, b;
- while(m--){
- cin >> a >> b;
- cin >> edge[a][b];
- }
- //以dnf(1)为起点开始递归遍历
- memset(mark, 0, sizeof(mark));
- minPath = inf;
- mark[1] = 1;
- dfs(1, 0);
- cout << minPath << endl;
- }
- return 0;
- }
程序运行结果如下:

2),弗洛伊德算法(解决多源最短路径):时间复杂度O(n^3),空间复杂度O(n^2)
基本思想:最开始只允许经过1号顶点进行中转,接下来只允许经过1号和2号顶点进行中转......允许经过1~n号所有顶点进行中转,来不断动态更新任意两点之间的最短路程。即求从i号顶点到j号顶点只经过前k号点的最短路程。
分析如下:1,首先构建邻接矩阵Floyd[n+1][n+1],假如现在只允许经过1号结点,求任意两点间的最短路程,很显然Floyd[i][j] = min{Floyd[i][j], Floyd[i][1]+Floyd[1][j]},代码如下:
[cpp] view plain copy
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- if(Floyd[i][j] > Floyd[i][1] + Floyd[1][j])
- Floyd[i][j] = Floyd[i][1] + Floyd[1][j];
- }
- }
2,接下来继续求在只允许经过1和2号两个顶点的情况下任意两点之间的最短距离,在已经实现了从i号顶点到j号顶点只经过前1号点的最短路程的前提下,现在再插入第2号结点,来看看能不能更新更短路径,故只需在步骤1求得的Floyd[n+1][n+1]基础上,进行Floyd[i][j] = min{Floyd[i][j], Floyd[i][2]+Floyd[2][j]};......
3,很显然,需要n次这样的更新,表示依次插入了1号,2号......n号结点,最后求得的Floyd[n+1][n+1]是从i号顶点到j号顶点只经过前n号点的最短路程。故核心代码如下:
[cpp] view plain copy
- #define inf 99999999
- for(k = 1; k <= n; k++){
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- if(Floyd[i][k] < inf && Floyd[k][j] < inf && Floyd[i][j] > Floyd[i][k] + Floyd[k][j])
- Floyd[i][j] = Floyd[i][k] + Floyd[k][j];
- }
- }
- }
例1:寻找最短的从商店到赛场的路线。其中商店在1号结点处,赛场在n号结点处,1~n结点中有m条线路双向连接。
[cpp] view plain copy
- /***先输入n,m,再输入m个三元组,n为路口数,m表示有几条路其中1为商店,n为赛场,三元组分别表起点,终点,该路径长,输出1到n的最短路径***/
- #include <iostream>
- using namespace std;
- #define inf 99999999
- #define nmax 110
- int edge[nmax][nmax], n, m;
- int main(){
- while(cin >> n >> m && n!= 0){
- //构建邻接矩阵
- int i, j;
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- edge[i][j] = inf;
- }
- edge[i][i] = 0;
- }
- while(m--){
- cin >> i >> j;
- cin >> edge[i][j];
- edge[j][i] = edge[i][j];
- }
- //使用弗洛伊德算法
- int k;
- for(k = 1; k <= n; k++){
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- if(edge[i][k] < inf && edge[k][j] < inf && edge[i][j] > edge[i][k] + edge[k][j])
- edge[i][j] = edge[i][k] + edge[k][j];
- }
- }
- }
- cout << edge[1][n] << endl;
- }
- return 0;
- }
程序运行结果如下:

3),迪杰斯特拉算法(解决单源最短路径)
基本思想:每次找到离源点(如1号结点)最近的一个顶点,然后以该顶点为中心进行扩展,最终得到源点到其余所有点的最短路径。
基本步骤:1,设置标记数组book[]:将所有的顶点分为两部分,已知最短路径的顶点集合P和未知最短路径的顶点集合Q,很显然最开始集合P只有源点一个顶点。book[i]为1表示在集合P中;
2,设置最短路径数组dst[]并不断更新:初始状态下,令dst[i] = edge[s][i](s为源点,edge为邻接矩阵),很显然此时dst[s]=0,book[s]=1。此时,在集合Q中可选择一个离源点s最近的顶点u加入到P中。并依据以u为新的中心点,对每一条边进行松弛操作(松弛是指由结点s-->j的途中可以经过点u,并令dst[j]=min{dst[j], dst[u]+edge[u][j]}),并令book[u]=1;
3,在集合Q中再次选择一个离源点s最近的顶点v加入到P中。并依据v为新的中心点,对每一条边进行松弛操作(即dst[j]=min{dst[j], dst[v]+edge[v][j]}),并令book[v]=1;
4,重复3,直至集合Q为空。
以下是图示:

核心代码如下所示:
[cpp] view plain copy
- #define inf 99999999
- /***构建邻接矩阵edge[][],且1为源点***/
- for(i = 1; i <= n; i++) dst[i] = edge[1][s];
- for(i = 1; i <= n; i++) book[i] = 0;
- book[1] = 1;
- for(i = 1; i <= n-1; i++){
- //找到离源点最近的顶点u,称它为新中心点
- min = inf;
- for(j = 1; j <= n; j++){
- if(book[j] == 0 && dst[j] < min){
- min = dst[j];
- u = j;
- }
- }
- book[u] = 1;
- //更新最短路径数组
- for(k = 1; k <= n; k++){
- if(edge[u][k] < inf && book[k] == 0){
- if(dst[k] > dst[u] + edge[u][k])
- dst[k] = dst[u] + edge[u][k];
- }
- }
- }
例1:给你n个点,m条无向边,每条边都有长度d和花费p,给你起点s,终点t,要求输出起点到终点的最短距离及其花费,如果最短距离有多条路线,则输出花费最少的。
输入:输入n,m,点的编号是1~n,然后是m行,每行4个数 a,b,d,p,表示a和b之间有一条边,且其长度为d,花费为p。最后一行是两个数s,t;起点s,终点 t。n和m为 0 时输入结束。(1<n<=1000, 0<m<100000, s != t)
输出:输出一行,有两个数, 最短距离及其花费。
分析:由于每条边有长度d和花费p,最好构建边结构体存放,此外可以使用邻接链表,使用邻接链表时需要将上面的核心代码修改几个地方:
1,初始化dst[]时使用结点1的邻接链表;
2,更新最短路径数组时,k的范围由1~n变为1~edge[u].size()。先采用邻接矩阵解决此题,再使用邻接表解决此题,两种方法的思路都一样:初始化邻接矩阵或邻接链表,并
初始化最短路径数组dst ----> n-1轮边的松弛中,先找到离新源点最近的中心点u,之后根据中心点u为转折点来更新路径数组。
使用邻接矩阵求解:
[cpp] view plain copy
- /***对于无向图,输入n,m,点的编号是1~n,然后是m行,每行4个数 a,b,d,p,表示a和b之间有一条边,且其长度为d,花费为p。最后一行是两个数s,t;起点s,终点 t。***/
- /***n和m为 0 时输入结束。(1<n<=1000, 0<m<100000, s != t) 输出:输出一行,有两个数, 最短距离及其花费。***/
- #include <iostream>
- #include <iomanip>
- using namespace std;
- #define nmax 1001
- #define inf 99999999
- struct Edge{
- int len;
- int cost;
- };
- Edge edge[nmax][nmax];
- int dst[nmax], spend[nmax], book[nmax], n, m, stNode, enNode;
- int main(){
- while(cin >> n >> m && n != 0 && m != 0){
- int a, b, i, j;
- //构建邻接矩阵和最短路径数组
- for(i = 1; i <= n; i++){
- for(j = 1; j <= n; j++){
- edge[i][j].cost = 0;
- edge[i][j].len = inf;
- }
- edge[i][i].len = 0;
- }
- while(m--){
- cin >> a >> b;
- cin >> edge[a][b].len >> edge[a][b].cost;
- edge[b][a].len = edge[a][b].len;
- edge[b][a].cost = edge[a][b].cost;
- }
- cin >> stNode >> enNode;
- for(i = 1; i <= n; i++){
- dst[i] = edge[stNode][i].len;
- spend[i] = edge[stNode][i].cost;
- }
- memset(book, 0, sizeof(book));
- book[stNode] = 1;
- //开始迪杰斯特拉算法,进行剩余n-1次松弛
- int k;
- for(k = 1; k <= n-1; k++){
- //找离源点最近的顶点u
- int minNode, min = inf;
- for(i = 1; i <= n; i++){
- if(book[i] == 0 && min > dst[i] /* || min == dst[i]&& edge[stNode][min].cost > edge[stNode][i].cost*/){
- min = dst[i];
- minNode = i;
- }
- }
- //cout << setw(2) << minNode;
- book[minNode] = 1;//易错点1,错写成book[i]=1
- //以中心点u为转折点来更新路径数组和花费数组
- for(i = 1; i <= n; i++){
- if(book[i] == 0 && dst[i] > dst[minNode] + edge[minNode][i].len || dst[i] == dst[minNode] + edge[minNode][i].len && spend[i] > spend[minNode] + edge[minNode][i].cost){
- dst[i] = dst[minNode] + edge[minNode][i].len;//易错点2,错写成dst[i]+
- spend[i] = spend[minNode] + edge[minNode][i].cost;
- }
- }
- }
- cout << dst[enNode] << setw(3) << spend[enNode] << endl;
- }
- return 0;
- }
程序运行结果如下:
使用邻接链表求解:

[cpp] view plain copy
- /***对于无向图,输入n,m,点的编号是1~n,然后是m行,每行4个数 a,b,d,p,表示a和b之间有一条边,且其长度为d,花费为p。最后一行是两个数s,t;起点s,终点 t。***/
- /***n和m为 0 时输入结束。(1<n<=1000, 0<m<100000, s != t) 输出:输出一行,有两个数, 最短距离及其花费。***/
- #include <iostream>
- #include <iomanip>
- #include <vector>
- using namespace std;
- #define nmax 1001
- #define inf 99999999
- struct Edge{
- int len;
- int cost;
- int next;
- };
- vector<Edge> edge[nmax];
- int dst[nmax], spend[nmax], book[nmax], n, m, stNode, enNode;
- int main(){
- while(cin >> n >> m && n != 0 && m != 0){
- int a, b, i, j;
- //构建邻接表和最短路径数组
- for(i = 1; i <= n; i++) edge[i].clear();
- while(m--){
- Edge tmp;
- cin >> a >> b;
- tmp.next = b;
- cin >> tmp.len >> tmp.cost;
- edge[a].push_back(tmp);
- tmp.next = a;
- edge[b].push_back(tmp);
- }
- cin >> stNode >> enNode;
- for(i = 1; i <= n; i++) dst[i] = inf; //注意2,别忘记写此句来初始化dst[]
- for(i = 0; i < edge[stNode].size(); i++){//注意1,从下标0开始存元素,误写成i <= edge[stNode].size()
- dst[edge[stNode][i].next] = edge[stNode][i].len;
- //cout << dst[2] << endl;
- spend[edge[stNode][i].next] = edge[stNode][i].cost;
- }
- memset(book, 0, sizeof(book));
- book[stNode] = 1;
- //开始迪杰斯特拉算法,进行剩余n-1次松弛
- int k;
- for(k = 1; k <= n-1; k++){
- //找离源点最近的顶点u
- int minnode, min = inf;
- for(i = 1; i <= n; i++){
- if(book[i] == 0 && min > dst[i] /* || min == dst[i]&& edge[stnode][min].cost > edge[stnode][i].cost*/){
- min = dst[i];
- minnode = i;
- }
- }
- //cout << setw(2) << minnode;
- book[minnode] = 1;//易错点1,错写成book[i]=1
- //以中心点u为转折点来更新路径数组和花费数组
- for(i = 0; i < edge[minnode].size(); i++){
- int t = edge[minnode][i].next;//别忘了加此句,表示与结点minnode相邻的点
- if(book[t] == 0 && dst[t] > dst[minnode] + edge[minnode][i].len || dst[t] == dst[minnode] + edge[minnode][i].len && spend[t] > spend[minnode] + edge[minnode][i].cost){
- dst[t] = dst[minnode] + edge[minnode][i].len;
- spend[t] = spend[minnode] + edge[minnode][i].cost;
- }
- }
- }
- cout << dst[enNode] << setw(3) << spend[enNode] << endl;
- }
- return 0;
- }
程序运行结果如下:
使用邻接表时,注意更新dst[],book[]时要使用邻接表元素对应下标中的next成员,而涉及到权值加减时时需要使用邻接表中的对应下标来取得权值;而使用邻接矩阵就没这么多顾虑了,因为这时候邻接矩阵对应下标和dst[]要更新元素的下标正好一致,都是从1开始编号。

4),Bellman-Ford算法(解决负权边,解决单源最短路径,前几种方法不能求含负权边的图)::时间复杂度O(nm),空间复杂度O(m)
主要思想:对所有的边进行n-1轮松弛操作,因为在一个含有n个顶点的图中,任意两点之间的最短路径最多包含n-1边。换句话说,第1轮在对所有的边进行松弛后,得到的是从1号顶点只能经过一条边到达其余各定点的最短路径长度。第2轮在对所有的边进行松弛后,得到的是从1号顶点只能经过两条边到达其余各定点的最短路径长度,......
以下是图示:
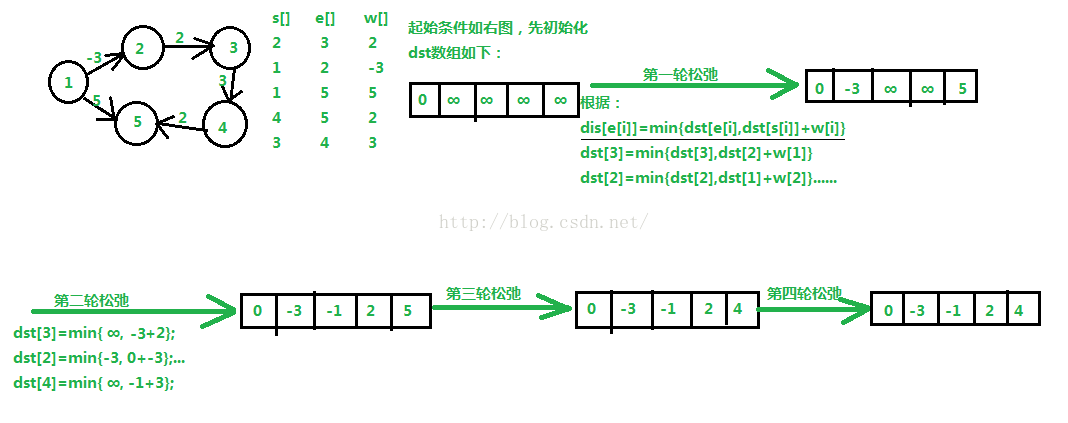
此外,Bellman_Ford还可以检测一个图是否含有负权回路:如果在进行n-1轮松弛后仍然存在dst[e[i]] > dst[s[i]]+w[i]。算法核心代码如下:
[cpp] view plain copy
- #define inf 999999999
- for(i = 1; i <= n; i++) dst[i] = inf;
- dst[1] = 0;
- for(k = 1; k <= n-1; k++){
- for(i = 1; i <= m; i++){
- if(dst[e[i]] > dst[s[i]] + w[i])
- dst[e[i]] = dst[s[i]] + w[i];
- }
- }
- //检测负权回路
- flag = 0;
- for(i = 1; i <= m; i++){
- if(dst[e[i]] > dst[s[i]] + w[i])
- flag = 1;
- }
- if(flag) cout << "此图含有负权回路";
例1:对图示中含负权的有向图,输出从结点1到各结点的最短路径,并判断有无负权回路。
[cpp] view plain copy
- /***先输入n,m,分别表结点数和边数,之后输入m个三元组,各表起点,终点,边权,输出1号结点到各结点的最短路径****/
- #include <iostream>
- #include <iomanip>
- using namespace std;
- #define nmax 1001
- #define inf 99999999
- int n, m, s[nmax], e[nmax], w[nmax], dst[nmax];
- int main(){
- while(cin >> n >> m && n != 0 && m != 0){
- int i, j;
- //初始化三个数组:起点数组s[],终点数组e[],权值数组w[],最短路径数组dst[]
- for(i = 1; i <= m; i++)
- cin >> s[i] >> e[i] >> w[i];
- for(i = 1; i <= n; i++)
- dst[i] = inf;
- dst[1] = 0;
- //使用Bellman_Ford算法
- for(j = 1; j <= n-1; j++){
- for(i = 1; i <= m; i++){
- if(dst[e[i]] > dst[s[i]] + w[i])
- dst[e[i]] = dst[s[i]] + w[i];
- }
- }
- //测试是否有负权回路并输出
- int flag = 0;
- for(i = 1; i <= m; i++)
- if(dst[e[i]] > dst[s[i]] + w[i])
- flag = 1;
- if(flag) cout << "此图含有负权回路\n";
- else{
- for(i = 1; i <= n; i++){
- if(i == 1)
- cout << dst[i];
- else
- cout << setw(3) << dst[i];
- }
- cout << endl;
- }
- }
- return 0;
- }
程序运行结果如下:







How to take a picture of a black hole)

)

)





)
)

