
目录
- Kafka的基本介绍
- Kafka的设计原理分析
- Kafka数据传输的事务特点
- Kafka消息存储格式
- 副本(replication)策略
- Kafka消息分组,消息消费原理
- Kafak顺序写入与数据读取
- 消费者(读取数据)
Kafka的基本介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
Kafka的设计原理分析
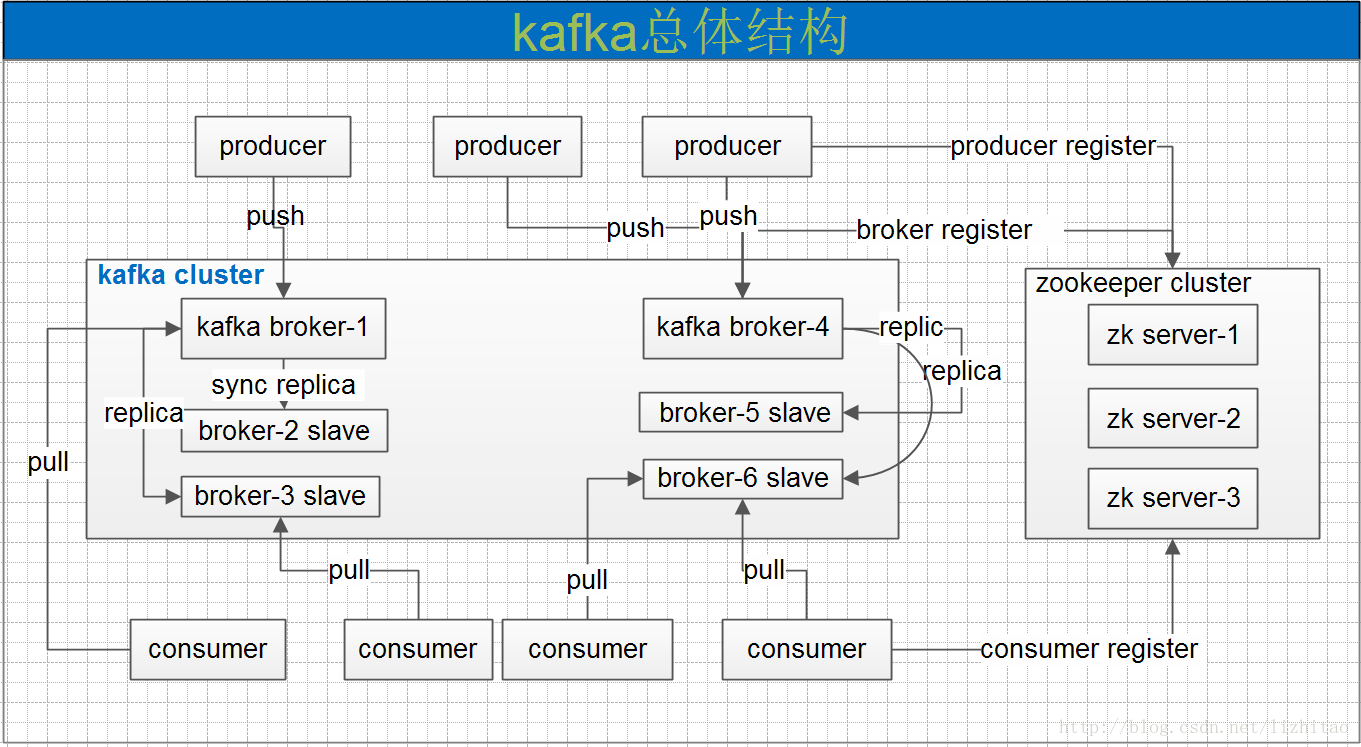
一个典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
Kafka专用术语:
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
- Producer:负责发布消息到Kafka broker。
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer Group。
Kafka数据传输的事务特点
- at most once:最多一次,这个和JMS中"非持久化"消息类似,发送一次,无论成败,将不会重发。消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后"未处理"的消息将不能被fetch到,这就是"at most once"。
- at least once:消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
- exactly once:消息只会发送一次。kafka中并没有严格的去实现(基于2阶段提交),我们认为这种策略在kafka中是没有必要的。
通常情况下"at-least-once"是我们首选。
Kafka消息存储格式
Topic & Partition
一个topic可以认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。
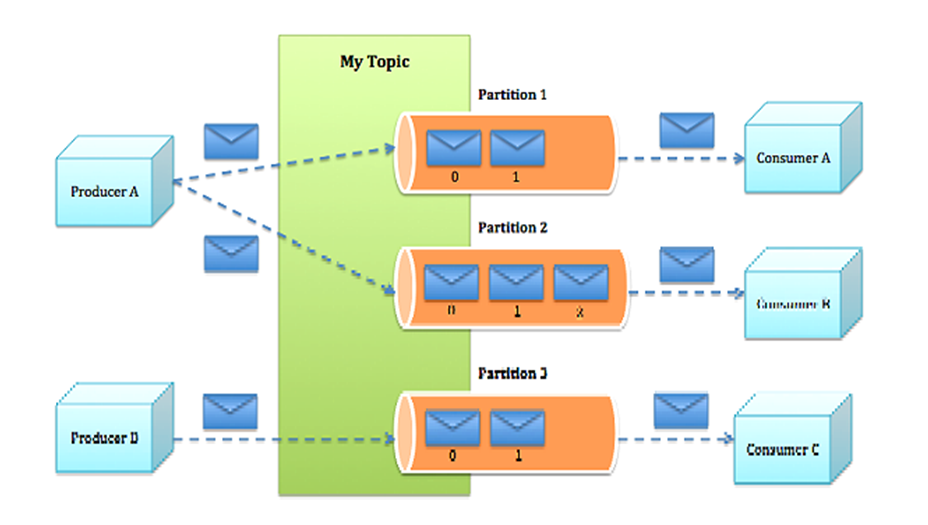
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
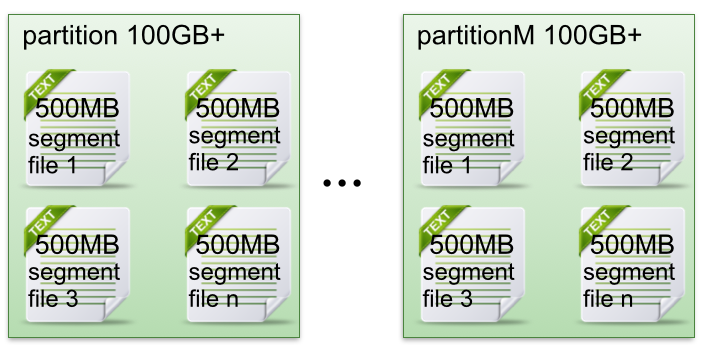
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
最后分享一波我的面试宝典——一线互联网大厂Java核心面试题库
以下是我个人的一些做法,希望可以给各位提供一些帮助:
点击《一线互联网大厂Java核心面试题库》即可免费领取,整理了很长一段时间,拿来复习面试刷题非常合适,其中包括了Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且还会持续的更新…可star一下!
283页的Java进阶核心pdf文档
Java部分:Java基础,集合,并发,多线程,JVM,设计模式
数据结构算法:Java算法,数据结构
开源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架构设计,Redis缓存,Zookeeper,kafka,RabbitMQ,负载均衡等
微服务部分:SpringBoot,SpringCloud,Dubbo,Docker
还有源码相关的阅读学习
…(img-PWPB8R6G-1626257210895)]
还有源码相关的阅读学习
[外链图片转存中…(img-OvpzyqGf-1626257210896)]

)
















)
