1 JAVA集合概述
Java集合封装了一系列数据结构比如链表、二叉树、栈、队列等,然后提供了针对这些数据结构的一系列算法比如查找、排序、替换,使编程难度大大降低。(这句话有可能是非法的,因为个人对算法目前不是太了解,并不了解Java有没有实现哪些数据结构。但是说在这里想给那些畏难算法与数据结构这门课程的人一丝信心,嫑以为非要懂算法和数据结构才能编程,不懂这门课程编也能编程,并不是所有的问题都要自己来实现一个数据结构。如果因为觉得编程一定要懂算法和数据结构,进而对编程产生一种心理阴影,没有信心,那是很错误的!你总需要先用一门语言来练练手,然后才能去学习算法和数据结构。"懂算法和数据结构=会编程",完全是那些所谓的专家来吓唬那些新手入门者的,找一本语言介绍书好好练练,编程并不是你想的那么难!)这样的话,只需要利用提供的数据结构存储需要用的数据,然后利用数据结构上提供的算法就可以对数据进行简单的处理。链表、二叉树、栈、队列在JAVA里面统称为集合,就是把数据统统塞进这些集合里面,这些集合的结构可能是不同的。Java集合将这些数据结构分成如下几类。
注意: 这些集合类里面存储的数据都是指向堆内存对象的对象栈内存变量
区别:
Java的集合类分为四种:Set,List、Map和Queue四种体系,即MSQL设计者可以根据需要使用这四种体系里面的数据结构,然后处理数据。
Map:代表有映射关系的集合,也就是key-value这样的数据集合,比如{001——张三,002——李四}
Set:代表无序、不可重复的集合,比如{1,2,3}。注意:无序、不可重复
Queue:代表一种队列集合的实现
List:代表添加时候有序存储可重复的集合{1,1,2,3}
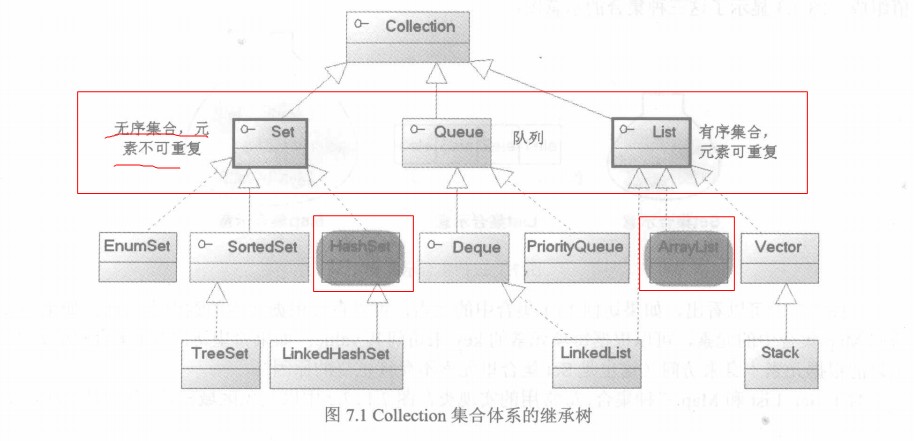
1.1 Java集合继承树
在处理数据时候经常处理到元素个数不确定(数组长度是固定的,初始化后就无法改变),有关联的数据{001——张三,002——李四},为了解决这些问题,Java提供了集合类,集合类负责保存、盛装这些数据,因此集合类也被称为容器类,所有的集合类都存放在java.util包中
集合类和数组的区别:
数组可以保存基本数据类型或者对象,但是集合类智能保存指向堆内存数据的栈内存对象变量(不过很多书上会直接说集合类里面装的都是对象,这样可能会好理解一些)。
MSQL接口类的继承拓扑图:
提供的四大接口类有如下继承结构的拓扑图,Collection和Map是两个根类,由这两个根类派生出一系列的接口类。
其中Collection派生SQL,Map派生其他的接口类。MSQL(记法M-SQL,像一种编程语言一样):Map,Set,Queue,List这四种集合类最常用的是SML(记法:AI领域的一种语言),也就是Set,Map,List,这三种接口类最常用实现是,Set的HashSet,Map的HashMap,List的ArrayList,也就是HHA(2HA,2哈——啊哈)如下图的颜色重的标注出来是常用的

1.2 Collection和Iterator接口
1.2.1 Collection 接口
下面如果没有特别说明,SQL并不指数据库语言SQL,而是代表Set,Queue,List三个Collection的子接口类。
Collection接口下面定义了若干方法,这些方法可以用于SQL三种集合接口类。注意:集合接口模板类里面存储的是栈对象变量
boolean add(Object o):该方法用于像一个集合接口类添加一个对象变量o指向的对象,如果添加成功,也就是集合类被改变成功,返回true,否则返回false
boolean addAll(Collection c):假设调用该接口的是集合接口类a,调用该接口后,会将集合接口类c的对象全部添加到集合接口类a中,元素间用逗号隔开
void clear():清空集合里面的所有元素,使元素个数size为0
boolean contains(Object o):检测集合里面是否含有对象元素o,有true,无false
boolean containsAll(Collection c):假定调用该接口的是集合a,那么调用该接口后会检测集合a里面是否包含集合c的全部元素,有true,无false
boolean isEmpty():返回集合是否为空,相当于int size()方法返回值为0和不为0的情况
boolean remove(Object o):删除集合里面指定元素o,删除成功返回true,失败false
boolean removeAll(Collection c):假设调用该接口的是集合a,调用该接口后,会从集合a里面找出集合c里面没有的元素,也就是找出差集,如果删除了一个或一个以上的元素,该方法返回true
boolean retainAll(Collection c):假设调用该接口的是集合a,调用该接口后,删除a中c没有的元素,也就是把a编程a和c的交集,如果操作成功,返回true
int size():返回集合里面元素个数
Object[] toArray():把集合转换成一个数组,所有的集合元素变成对应的数组元素,这样就可以用数组的方法来访问元素
Iterator iterator():返回一个Iterator对象用于遍历集合里面的所有元素,也就是一个迭代器,这个迭代器可以用于查询集合类元素,利用System.out的println查询同样可以打印出集合的所有数据,但是这样的查询是不可控制的,也就是说要么查询出所有,要么不查询,使用迭代器可以根据需要进行查询。
1.2.2 Iterator接口
Iterator接口隐藏了Collection集合类的底层实现,提供了若干方法对Collection集合类进行处理。
方法:
boolean hasNext():如果被迭代的集合仍然有元素没有被遍历(迭代),则返回true,就是说如果集合里面迭代一次后剩余的元素不止一个,则返回true。
Object next():返回集合里下一个元素,注意迭代器每次只返回一个,不像println那样一次返回所有
void remove():删除集合里上一次next方法返回的元素,比如说如果等于某个值,就可以删除这个元素,这样就可以控制集合返回结果
看一段代码:
1 //创建一个集合 2 Collection books = new HashSet(); 3 books.add("轻量级J2EE企业应用实战"); 4 books.add("Struts2权威指南"); 5 books.add("基于J2EE的Ajax宝典"); 6 //获取books集合对应的迭代器 7 Iterator it = books.iterator(); 8 while(it.hasNext()){ 9 //it.next()方法返回的数据类型是Object类型,需要强制类型转换 10 String book = (String)it.next();//book代表的是每次返回的一个元素 11 // it.remove();//remove删除每次next方法返回的元素,按照此循环,如果每次返回后都进行删除,那么最后就不返回任何一个结果,因为返回一个删掉一个 12 //如果next方法返回的元素与Struts2权威指南一样,则删除 13 // if(book.equals("Struts2权威指南")){ 14 // 15 // it.remove(); 16 // } 17 //对book变量赋值,不会改变改变集合本身 18 // System.out.println(book); 19 //book = "测试字符串"; 20 } 21 System.out.println(books);
强烈注意
Iterator接口类仅用于遍历集合,Iterator本身并不提供盛装对象的能力,如果需要创建Iterator对象,则必须与有一个可以被它迭代的集合,没有集合的迭代器没有存在价值。也就是说Iterator必须依附于Collection对象,有一个Iterator对象,则必然有一个与之关联的Collection对象供其迭代。
代码倒数第二行有一个book赋值代码,但是输出集合books时候,输出结果没有任何改变,可以得到一个结论:当使用Iterator对集合进行迭代输出时候,Iterator并没有指向堆内存的集合,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素没有任何改变。
墙裂注意
1. 删除集合里面的元素只能通过迭代器的remove方法,也就是it.remove()才可以删除集合里面的元素,通过调用集合自身的方法来删除集合元素值也就是说books.remove(book)将会出错,引发的异常是java.util.ConcurrentModificationException异常,或者简单的说,迭代过程中,不能通过除了迭代器之外的方式来修改集合,也就是说在迭代过程中,只有迭代器有修改集合的权限,其他方式包括集合本身都没有修改集合自身元素的权限。(其实更本质的是集合类变量本身只是指向堆内存的数据,迭代时候,相当于堆内存的使用权交给了迭代器,集合类本身当然没有修改权限)迭代器采用的是快速失败机制,一旦在迭代过程中,检测到该集合已经被修改(通常是其他线程修改),程序立即引发ConcurrentModificationException异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
第二for循环遍历集合元素
前面已经介绍了for循环有两种方是,一种是标准的,另一种是被很多书称之为foreach循环(这种叫法很容易让人误解循环的关键字是foreach,但其实依然是for),这里我称之为第二for循环(表示第二种for循环),同样使用在用for循环迭代输出集合类“中”也不能修改集合元素。同样使用该种循环方式按照前面的语法
for(循环变量类型 循环变量:集合类)
代码如下:
1 //创建一个集合 2 Collection lan = new HashSet(); 3 //往集合里面装东西 4 lan.add("Englis"); 5 lan.add("Chinese"); 6 lan.add("Castellano"); 7 lan.add("Deutsch"); 8 //使用第二for循环输出集合里面的元素 9 for(Object lang:lan){ 10 String lgu = (String)lang;//集合里面存储的都是对象变量 11 System.out.print(lgu); 12 }
2 Set集合类
Set集合特点:Set集合接口类的元素特征是无序、不重复
Set集合与Collection基本完全一样,它没有提供任何额外的方法,实际上Set就是Collection,只是行为不同(Set不允许重复元素)。
Set不允许重复元素,如果相同元素加入同一个Set集合中则会添加失败,判断是否相同的标准是使用equals方法,而不是==方法,所以比较严格。
例如:
1 Set books = new HashSet(); 2 books.add(new String("English")); 3 //再次添加一个不同的对象 4 books.add(new String("English"));
由于Set是一个集合类,集合类里面应该装的是不同对象,上述代码里面明显装的是不同对象,但是Set集合判断是否是同一个对象的标准是equals方法,所以不能添加(有点怪怪的)
上面介绍的是Set集合的通用知识,因此完全适合后面介绍的HashSet、TreeSet、EnumSet三个实现类,只是三个实现类各有特色。
2.1 HashSet——LinkedHashSet类
2.1.1 HashSet接口
HashSet是Set接口的典型实现,大多数时候使用Set集合就是使用这个实现类,HashSet按Hash算法存储集合中的元素,因此具有很好的存取和查找性能。
HashSet特点
1. 不能保证元素的排列顺序,顺序有可能发送变化
2. HashSet不是同步的,如果多个线程同时访问一个Set集合或者一个HashSet,当2条或2条以上的线程同时修改了HashSet集合时,必须通过代码来保证同步。
3. 集合元素值可以是null
当向HashSet集合中存入一个元素,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值来决定该对象在HashSet中存储位置。如果有两个元素通过equals方法比较返回true,但他们的hashCode()方法返回值不相等,HashSet会把他们存储在不同位置,也就可以添加成功。
简单的说:HashSet集合通过两个条件来判断是否存储要插入的元素。一个是通过equals判断元素值是否相等,另一个是通过hashCode()方法判断Hash值是否相等。只有两个都相等了,才说明要插入的元素相等。
1 import java.util.*; 2 /** 3 * Description: 4 * <br/>Copyright (C), 2005-2008, Yeeku.H.Lee 5 * <br/>This program is protected by copyright laws. 6 * <br/>Program Name: 7 * <br/>Date: 8 * @author Yeeku.H.Lee kongyeeku@163.com 9 * @version 1.0 10 */ 11 12 //类A的equals方法总是返回true,但没有重写其hashCode()方法 13 class A{ 14 public boolean equals(Object obj){ 15 return true; 16 } 17 } 18 //类B的hashCode()方法总是返回1,但没有重写其equals()方法 19 class B{ 20 public int hashCode(){ 21 return 1; 22 } 23 } 24 //类C的hashCode()方法总是返回2,但没有重写其equals()方法 25 class C{ 26 public int hashCode(){ 27 return 2; 28 } 29 public boolean equals(Object obj){ 30 return true; 31 } 32 } 33 public class TestHashSet{ 34 public static void main(String[] args) { 35 HashSet books = new HashSet(); 36 //分别向books集合中添加2个A对象,2个B对象,2个C对象 37 books.add(new A()); 38 books.add(new A()); 39 books.add(new B()); 40 books.add(new B()); 41 books.add(new C()); 42 books.add(new C()); 43 System.out.println(books); 44 } 45 }
上面的程序中向books集合中添加了2个A对象、2个B对象、2个C对象,其中C类重写了equals()方法,总是返回true,hashCode()方法总是返回2,这将导致HashSet会把2个C对象当成同一个对象。运行上述可以得到
[B@1,B@1,C@2,A@343,A@kd33]
需要注意的是
如果需要把一个对象放入HashSet中时,如果重写该对象对应类的equals()方法,也应该重写起hashCode()方法,其规则是:如果2个对象通过equals方法比较返回true,这两个hashCode应该也相同,这样就不会添加两个同样的对象。
如果两个对象通过equals方法返回true,但是通过hashCode返回不同的,那么将会将两个对象保存在不同位置,从而都可以添加成功,这样会违反Set集合的特征(虽然可以添加成功)。
如果equals方法返回false,但hashCode值却是一样的,这样更加极品。因为hash值一样,HashSet试图把它们保存在同一个位置(但实际不能这样做,否认则将覆盖其中一个),所以处理比较复杂,而且HashSet访问元素根据hash值访问,如果HashSet中包含元素有相同的hashCode值,将导致性能下降。
HashSet的使用hashCode值去查询元素,hashCode就相当于数组索引,但为什么不使用数组呢?因为数组元素索引是连续的,并且长度固定,无法自由增加数组长度。而HashSet访问元素,可以先算出hashCode值,然后去对应位置取出元素。
重写hashCode方法原则:
当两个对象通过equals方法返回true时,对象的hashCode应该也要相等
对象中用作equals比较标准的熟悉,都应该用来计算hashCode值
重写hashCode()方式
第一步:
对象内每个有意义的熟悉f(即每个用作equals()比较标准的属性)计算出一个int类型的hashCode值,计算方法如下:
不同类型属性取得hashCode值方式
属性类型 计算方式
boolean hashCode=(f?0:1);
整数类型(byte,short,char,int) hashCode=(int)f;
long hashCode=(int)(f^(f>>>32))
float hashCode=Float.floatToIntBits(f)
double long l = Double.doubleTolongBits(f);
hashCode = (int)(l^(l>>>32));
普通引用类型 hashCode = f.hashCode();
第二步:
用第一步计算出来的对象的多个hashCode值组合计算出一个最终的hashCode,作为对象的hashCode值返回
return f2.hashCode() + (int)f2;
为了避免直接相加产生的偶然相等(两个对象的f1、f2不等,但他们的和刚好相等。例如6=2+4=3+3),可以通过为各属性乘以一个质数再相加:
return f1.hashCode()*17 + (int)f2*13;
当向HashSet中添加可变对象时,必须十分小心,如果修改HashSet集合中的对象,有可能导致该对象与集合中其他对象相等,从而导致HashSet无法准确访问对象。也就是说添加时候会做出检查,修改时候是不会检查元素之间是否相同的。所以如果修改导致了与其他对象相等,那么HashSet无法准确访问该对象。
2.1.2 LinkedHashSet接口
HashSet还有一个子类LinkedHashSet集合,LinkedHashSet集合也是根据元素hashCode值来决定元素的存储位置,但它同时使用链表维护元素次序,这样时元素看起来以插入的顺序保存的,也就是说,当遍历LinkedHashSet集合元素时,HashSet将会按元素添加顺序来访问集合里的元素。LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet性能,但迭代输出时候性能将会很好。
注意:LinkedHashSet集合特点是有序的,并且顺序和添加时候顺序一致。
2.2 SortedSet——TreeSet接口
TreeSet是SortedSet接口的唯一实现,正如SortedSet名字所述,TreeSet可以确保元素处于排序状态。TreeSet提供了如下方法
方法:
Comparator comparator():返回当前Set使用的Comparator,或者null(表示自然方式排序)
Object first():返回集合中的第一个元素
Object last():返回集合中的最后一个元素
Object lower(Object e):返回集合中与e相比的最大元素,e不一定是TreeSet里面的元素,也就是下确界
Object higher(Object e):返回集合中与e相比的最小元素,也就是上确界,e不一定是TreeSet里面的元素
SortedSet subSet(fromElement,toElement):返回此Set的子集合,范围从fromElement(包含)到toElement(不包含)
SortedSet headSet(toElement):返回此Set的子集,由小于toElement的元素组成
SortedSet tailSet(fromElement):返回此Set的子集,由大于等于fromElement的元素组成
总的来说:TreeSet提供了:访问第一个最后一个,上确界、下确界(前一个后一个),以及截取子TreeSet的方法
区别:
同样是提供了排序的存储,LinkedHashSet与TreeSet是有本质区别的。LinkedHashSet的顺序是插入元素时候的顺序,TreeSet提供的是元素值的顺序
TreeSet支持两种排序方法:自然排序和定制排序,默认是自然排序
2.2.1 自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间大小关系,然后集合元素按照升序排列,这种方式就是自然排序。
Java提供了一个Comparable接口,该接口定义一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。当一个对象调用该方法与另一个对象进行比较,例如obj1.compareTo(obj2),如果该方法返回0,则表示这两个对象相等;如果返回一个正整数,则表明obj1大于obj2,如果返回是一个负整数,则表示obj1小于obj2。
Java的一些常用类已经实现了Comparable接口,并提供了比较大小的标准。下面是实现了Comparable接口的常用类。
BigDecimal、BigInteger以及所有数值型对应的包装类:按它们对应的数值大小进行比较
Character:按字符的UNICODE值进行比较
Boolean:true对应的包装类实例大于false对应的包装类实例
String:按字符串字符的UNICODE值进行比较
Date、Time:后面的时间、日期比前面的时间、日期大。
如果试图把一个对象添加进TreeSet时,该对象的类必须实现Comparable接口,否则程序抛出异常。另外在实现compareTo(Object obj)方法时,需要将被比较对象obj强制类型转换成相同类型,因为只有相同类的实例才会比较大小。比如日期和字符串就不能直接比较。
对TreeSet集合而言:判断两个对象不相等的标准是:两个对象通过equals方法比较false,或通过compareTo(Object obj)比较没有返回0——即使两个对象是同一个对象。
类似地:当需要把一个对象放入TreeSet中时,重写该对象对应类的equals()方法时,应该保证该方法与compareTo(Object obj)方法有一致的结果,其规则是:如果两个对象通过equals方法比较返回true时,这两个对象通过compareTo(Object obj)方法比较返回0.
如果两个对象通过equals方法返回true,但是通过compareTo(Object obj)返回不同的,那么将会将两个对象保存在不同位置,从而都可以添加成功,这样会违反Set集合的特征(虽然可以添加成功)。
如果equals方法返回false,但compareTo(Object obj)值却是一样的,这样更加极品。因为比较相等,TreeSet试图把它们保存在同一个位置(但实际不能这样做,否认则将覆盖其中一个),所以处理比较复杂。
如果向TreeSet中添加一个可变对象后,并且后面程序修改了该可变 对象的属性,导致它与其他对象的大小顺序发生了改变,但TreeSet不会再次调整它们的顺序,甚至可能导致TreeSet中保存这两个对象,它们通过equals方法比较返回true,通过compareTo(Object obj)方法比较返回0.
2.2.2 定制排序
可以对TreeSet集合类进行自定义排序,比如降序。可以使用Comparator接口帮助,该接口里面有一个int compare(T o1,T o2)方法用于比较o1和o2大小,比较原理痛compareTo()一样。
如果实现定制排序,需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。
2.3 EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中所有值都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。EnumSet集合元素也是有序的,EnumSet以枚举值在Enum类定义顺序来决定集合元素的顺序。也就是不以元素值大小决定,根据添加顺序决定。
EnumSet在内部以为向量的形式存储,这种存储形式紧凑、高效,占用内存小。
EnumSet集合不允许加入null元素,如果插入null元素将抛出空指针异常。如果只是测试是否出现null元素或删除null元素都不会抛出异常,只是删除操作将返回false,因为没有任何null元素被删除。
EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的static方法来创建EnumSet对象。它提供了如下常用static方法来创建EnumSet对象。
2.3.1 EnumSet创建方法
static EnumSet allOf(Class elementType):创建一个包含指定枚举类里所有枚举值的EnumSet集合
static EnumSet complementOf(EnumSet s):假设调用该方法的是EnumSet a,调用后的新EnumSet的集合元素是a+s,结果放在a中
static EnumSet copyOf(Collection c):使用一个普通集合来创建EnumSet集合
static EnumSet copyOf(EnumSet s):创建一个与指定EnumSet具有相同元素类型、相同集合元素的EnumSet
static EnumSet noneOf(Class elementType):创建一个元素类型为指定枚举类型的空EnumSet
static EnumSet of(E first,E...rest):创建一个包含一个或多个枚举值的EnumSet,传入的多个枚举值必须属于同一个枚举类。
static EnumSet range(E from ,E to):创建包含从from枚举值,到to枚举值范围内所有枚举值的EnumSet集合
注意:
EnumSet复制另一个EnumSet集合中所有元素创建新的EnumSet,或复制另一个Collection集合中所有元素来创建新的EnumSet,当复制Collection集合中所有元素创建新的EnumSet时,要求Collection集合中所有元素必须是同一个枚举类型的枚举值
HashSet和TreeSet是Set的两个典型实现,那如何选择HashSet和TreeSet呢?HashSet的性能总是比TreeSet好(特别是最常用的添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合元素的次序。只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该使用HashSet
HashSet还有一个子类:LinkedHashSet,对于普通插入、删除操作,LinkedHashSet比HashSet要略慢一点:这是有维护链表所带来的额外开销,不过有了链表,遍历LinkedHashSet会更快
EnumSet是所有Set实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
必须指出的是,Set的三个实现类HashSet、TreeSet和EnumSet都是线程不安全的,如果有多条线程同时访问一个Set集合,并且有超过一条线程修改了该Set集合,则必须手动保证该Set集合的同步性。通常可以通过Collections工具类synchronizedSortedSet方法来包装该Set集合。次操作最好在创建时进行,以防止对Set集合的意外非同步访问。
3.Queue集合类
3.1概述
Queue用于模拟了队列这种数据结构,队列是指"先进先出"(FIFO)的容器。队列的头部保存在队列中时间最长的元素,队列的尾部保存在队列中时间最短的元素。
3.2队列
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
在队列这种数据结构中,最先插入的元素将是最先被删除的元素;反之最后插入的元素将是最后被删除的元素,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。
队列空的条件:front=rear
队列满的条件: rear = MAXSIZE
队列不允许随机访问队列中的元素。
3.3 Queue接口定义的方法
void add(Object e):将制定元素加入此队列的尾部。
Object element():获取队列头部的元素,但是不删除该元素。
boolean offer(Object e):将指定元素加入此队列的尾部。当使用有容量限制的队列时,此方法通常比add(Object e)方法更好。
Object peek():获取队列头部的元素,但是不删除该元素,如果此队列为空,则返回null
Object poll():获取队列头部的元素,并删除该元素,如果队列为空,则返回为null
Object remove():获取队列头部的元素,并删除该元素。
3.4 Queue的实现类
Queue有两个常用的实现类:LinkedList和PriorityQueue,下面介绍着两个类。
3.4.1 LinkedList实现类
LinkedList类是一个奇怪的类,它是List接口的实现类——这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,Deque接口是Queue接口的子接口,它代表一个双向队列,Deque有如下方法。
void addFirst(Object e):将制定元素插入该双向队列的开头
void addLast(Object e):将制定元素插入该双向队列的末尾
Iterator descendingIterator():返回以该双向队列对应的迭代器,该迭代器将以逆向顺序来迭代队列中的元素。
Object getFirst():获取、但不删除双向队列的第一个元素
Object getLast():获取、但不删除双向队列的最后一个元素
boolean offerFirst(Object e):将指定的元素插入该双向队列的开头
boolean offerLast(Object e):将指定的元素插入该双向队列的末尾
Object poolFirst():获取、并删除该双向队列的第一个元素;如果此双向队列为空,则返回null
Object poolLast():获取、并删除该双向队列的最后一个元素;如果此双向队列为空,则返回null
Object peekFirst():获取、但不删除该双向队列的第一个元素;如果此双向队列为空,则返回null
Object peekLast():获取、但不删除该双向队列的最后一个元素;如果此双向队列为空,则返回null
Object pop():pop出该双向队列所表示的栈中第一个元素
void push(Object e):将一个元素push进该双向队列所表示的栈中(即该双向队列的头部)
Object removeFirst():获取并删除该双向队列的第一个元素
Object removeFirstOccurrence(Object o):删除该双向队列的第一次出现元素o
removeLast():获取并删除该双向队列的最后一个元素
removeLastOccurrence(Object o):删除该双向队列的最后一次出现的元素o
LinkedList不仅可以当成双向队列使用,也可以当成"栈"(但其实不是栈)使用,因为该类里面有pop和push两个方法,除此之外,LinkedList实现了List接口,所以被当成List使用。
LinkedList有上述方法让它可以当做双向队列、栈和List集合用。LinkedList是个相当强大的集合类。
LinkedList与ArrayList、Vector的实现机制完全不同,ArrayList、Vector内部以数组形式保存集合中的元素,因此随机访问集合元素上性能较好,而LinkedList以链表形式保存集合,所以随机访问集合元素较差,但插入、删除元素时性能出色。
通常编程时候无需理会ArrayList和LinkedList性能差异,只需要知道LinkedList集合不仅提供了List功能,还有双向队列及栈功能,在一些性能比较敏感的地方,可能需要慎重选择哪个List实现。下面是三者性能差异:
类别 实现机制 随机访问排名 迭代排名 插入排名 删除排名
数组 连续内存区保存元素 1 不支持 不支持 不支持
ArrayList 内部以数组保存元素 2 2 2 2
Vector 内部以数组保存元素 3 3 3 3
LinkedList 内部以链表保存元素 4 1 1 1
从上表看出:因为数组以一块连续内存区保存所有数组元素,所以数组在随机访问时性能最好。所有内部数组作为底层实现的集合在随机访问时也有较好的性能;而内部以链表作为底层实现的集合在插入、删除操作时有很好的性能,以链表作为底层实现的集合也比数组作为底层实现的集合性能好。
1 package chapter3excercise; 2 3 import java.util.*; 4 5 public class TestPerformance { 6 public static void main(String[] args){ 7 //创建一个字符串数组 8 String[] test1 = new String[200000]; 9 //动态初始化数组 10 for(int i = 0;i < test1.length;i++){ 11 test1[i] = String.valueOf(i); 12 } 13 ArrayList al = new ArrayList(); 14 for(int i = 0;i < test1.length;i++){ 15 al.add(test1[i]); 16 } 17 LinkedList ll = new LinkedList(); 18 for(int i = 0;i < test1.length;i++){ 19 ll.add(test1[i]); 20 } 21 long start = System.currentTimeMillis(); 22 for(Iterator it = al.iterator();it.hasNext();){ 23 it.next(); 24 } 25 System.out.println("迭代ArrayList元素所需要的时间:" + 26 (System.currentTimeMillis() - start)); 27 start = System.currentTimeMillis(); 28 for(Iterator it = ll.iterator();it.hasNext();){ 29 it.next(); 30 } 31 System.out.println("迭代LinkedList元素所需要的时间:" + 32 (System.currentTimeMillis() - start)); 33 } 34 }
多次运行上面程序会发现,迭代ArrayList集合的时间略大于迭代LinkedList集合的时间。因此,关于使用List集合有如下建议:
如果需要遍历List集合元素,对于ArrayList、Vector集合,则应该使用随机访问方法(get)来遍历集合元素,这样性能更好。对于LinkedList集合,则应该采用迭代器来遍历集合元素
如果需要经常执行插入、删除操作来改变List集合的大小,则应该使用LinkedList集合,而不是ArrayList。使用ArrayList、Vector集合将需要经常重新分配内部数组的大小,其时间开销常常是使用LinkedList时时间开销的几十倍,效果很差。
如果有多条线程需要同时访问List集合中元素,可以考虑使用Vector这个同步实现。
3.4.2 PriorityQueue实现类
PriorityQueue是一个比较标准的队列实现类,之所以说它是比较标准的队列实现,而不是绝对标准的队列实现是因为:PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此因此当调用peek方法或者poll方法来取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列最小的元素。从这个意义上看,PriorityQueue已经违反了队列的最基本的规则:先进先出。
PriorityQueue不允许插入null元素,它还需要对队列元素进行排序,队列元素有两种排序方式:
自然排序:采用自然顺序的PriorityQueue集合中的元素必须实现了Comparable接口,而且应该是同一类的多个实例,否则可能导致ClassCastException异常
定制排序:创建PriorityQueue队列时,传入一个Comparator对象,该对象负责对队列中所有元素排序,采用定制排序时不要求队列元素实现Comparable接口
PriorityQueue队列对元素的要求与前面TreeSet对元素的要求基本一致,可以参考TreeSet处理
4.List接口和ListIterator接口
List作为Collection接口的子接口,可以使用Collection接口里的全部方法,而且List是有序集合,因此List集合里面增加了一些根据索引来操作集合元素的方法:
void add(int index,Object element):将元素element插入在List集合index处
boolean addAll(int index,Collection c):将集合c的所有元素都插入在List集合index处
Object get(int index):返回集合index索引处的元素
int indexOf(Object o):返回对象o在List集合中出现的位置索引
int lastIndexOf(Object o):返回对象o在List集合中最后一次出现的位置索引
Object remove(int index):删除并返回index索引处的元素
Object set(int index ,Object element):将index索引处的元素替换成element对象,返回新元素
List subList(int fromIndex,int toIndex):返回从索引fromIndex(包含)到索引toIndex(不包含)处所有集合元素的子集合。
所有List实现类都可以调用这些方法实现对集合元素的操作,相对于Set集合,List可以根据索引来插入、替换和删除集合元素。
与Set只提供了一个iterator()方法不同,List还额外提供了一个listIterator()方法,该方法返回一个ListIterator对象,ListIterator接口继承了Iterator接口,提供了专门操作List的方法。
ListIterator接口在Iterator接口基础上增加了如下方法:
boolean hasPrevious():返回该迭代器关联的集合是否还有上一个元素
Object previous():返回该迭代器的上一个元素
void add():在指定位置插入一个元素
拿ListIterator与普通Iterator进行对比,容易发现ListIterator增加了向前迭代的功能(Iterator只能向后迭代),而且ListIterator还可以通过add方法向List集合添加元素(Iterator只能删除元素)。
正向迭代是从正向迭代输出元素,反向迭代是从反向迭代输出元素。
4.1 ArrayList和Vector实现类
ArrayList和Vector是List的两个典型实现类,完全支持List接口的全部功能。
ArrayList和Vector类是基于数组实现的List类,所以ArrayList和Vector类封装了一个动态再分配的Object[]数组。每个ArrayList或Vector对象有一个capacity属性,这个capacity表示它们所封装的Object[]数组长度。当想ArrayList或Vector中添加元素时,其capacity会自动增加。
通常无需关心ArrayList或Vector的capacity属性,但如果想ArrayList集合或Vector集合中添加大量元素时,可以使用ensureCapacity方法一次性增加capacity,可以减少增加分配次数,提高性能。
如果开始就知道ArrayList集合或Vector集合需要保存多少个元素,可以创建时候就指定capacity大小。如果不指定,则capacity属性默认值为10
此外,ArrayList和Vector集合提供了两个方法操作capacity属性。
void ensureCapacity(int minCapacity):将ArrayList或Vector集合中的capacity增加minCapacity
void trimToSize():调整ArrayList或Vector集合的capacity为列表当前大小。程序可调用该方法来减少ArrayList或Vector集合对象存储空间
ArrayList或Vector在用法上几乎完全相同,但Vector是一个古老的集合最开始Java没有提供系统的集合框架,所以Vector提供了一些方法名很长的方法。 ArrayList开始就作为List的主要实现类,因此没有那些方法名很长的方法,实际上Vector有很多缺点,通常尽量少用Vector实现类。
ArrayList和Vector的显著区别是ArrayList是线程不安全的,当多线程访问同一个ArrayList集合时,如果超过一条修改了ArrayList集合,则需要手动保证集合的同步性,而Vector集合是线程安全的,无需保证集合的同步性。Vector性能低于ArrayList性能。
Vector还提供了Stack子类,用于模拟"栈"这种数据结构,栈通常是后进先出进栈出栈的都是Object,所以取出栈里的元素需要做类型转换。
Object peek():返回"栈"的第一个元素,但并不将该元素pop出栈
Object pop():返回栈的第一个元素,并将该元素pop出栈
void push(Object item):将一个元素push进栈,最后一个进栈的元素总是位于栈顶。
数组的工具类Arrays里面提供了asList(Object...a)方法,该方法可以把一个数组或指定个数的对象转换成一个List集合,这个List集合既不是ArrayList实现类,也不是Vector实现类的实例,而是Arrays的内部类ArrayList的实例
Arrays.ArrayList是一个固定长度的List集合,程序只能遍历访问该集合里的元素,不可增加、删除集合里的元素。
5.Map集合
5.1 Map集合特点
Map用于保存具有映射关系的数据,因此Map集合保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false。key和value之间存在单向一对一关系,即通过指定的key,总能找到唯一的、确定的value。从Map中取出数据时,只要给出指定的key,就可以取出对应的value。也就是说Map保存的元素是键值对。如果把Map里的key放在一起看,它们就组成了一个Set集合(key是没有顺序,key与key之间不能重复),事实上Map确实包含了一个keySet()方法,用于返回Map所有key组成的Set集合。
不仅如此Map里key集合和Set集合里元素的存储形式也很像,Map子类和Set子类在名字上也几乎相似。Set接口下有HashSet、LinkedHashSet、SortedSet(接口)、TreeSet、EnumSet等实现类和子接口,而Map接口下则有HashMap、LinkedHashMap、SortedMap(接口)、TreeMap、EnumMap等实现类和子接口。正如名字暗示,Map的实现类和子接口中key集存储形式和对应的Set集合存储形式完全相同。如果把Map所有的value放在一起看,它们非常类似于一个List:元素与元素之间可以重复,每个元素通过索引来查找,只是Map中的索引不再使用整数值,而是另一个对象来作为索引。如果需要从List集合取出元素,需要提供该元素的数字索引,如果需要从Map中取出元素,需要提供该元素的key索引,因此Map也被称为字典或关联数组。
5.2 Map接口方法
Map中包括一个内部实现类:Entry。该类封装了一个key-value对,Entry包含三个方法:
Object getKey():返回该Entry里包含的key值
Object getValue():返回Entry里面包含的value值
Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值
可以把Map理解成一个特殊的Set,只是该Set里包含的集合元素是Entry类对象,而不是普通对象
5.3Map接口的内部实现类
Map中包括一个内部实现类:Entry。该类封装了一个key-value对,Entry包含三个方法: Object getKey():返回该Entry里包含的key值 Object getValue():返回Entry里面包含的value值 Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值 可以把Map理解成一个特殊的Set,只是该Set里包含的集合元素是Entry类对象,而不是普通对象
5.4 HashMap和Hashtable
HashMap和Hashtable是Map接口的典型实现类,它们之间的关系类似于ArrayList和Vector关系:Hashtable是个古老的Map实现类,它有两个繁琐的方法elements()和keys(),现在基本不用了。
Hashtable和HashMap的区别
Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable性能好,但多线程访问Map对象时,Hashtable实现类更好 Hashtable不允许使用null作为key和table,如果把null值放进Hashtable中,将会引发NullPointerException异常,但HashMap可以使用null作为key或value,但由于key不能重复,所以HashMap里最多只有一项key-value对的key为null,但可以有无数多项key-value对的value为null。key类似Set集合的,所以无序、禁止重复key,而value类似List所以可以重复,顺序和key是对应的。 代码:
1 package chapter7; 2 3 import java.util.HashMap; 4 5 public class NullInHashMapTest { 6 public static void main(String[] args){ 7 HashMap hm = new HashMap(); 8 //将两个key值为null的放在key-value键值对中 9 hm.put(null, null); 10 hm.put(null, null); 11 //将一个value值为null的放入key-value键值对中 12 hm.put('a', null); 13 System.out.println(hm); 14 } 15 } 16 17 输出结果:{null=null, a=null}
根据输出结果可以看出HashMap重写了toString()方法,实际所有Map实现类都重写了toString()方法,调用Map对象的toString()方法总是返回如下格式字符串 {key1=value1,key2=value2}
Hashtable从类名上就可以看出是一个古老的类,命名甚至都没有遵守Java的命名规范:每个类的单词首字母大写。后来也没有改成HashTable,否则将有大量程序需要改写。尽量少用Hashtable类,即使需要创建线程安全的Map实现类,可以通过Collections工具类,把HashMap变成线程安全的,无须使用Hashtable实现类。
为了成功在HashMap、Hashtable中存储、获取对象,用作key的对象必须实现hashCode方法和equals方法。HashMap、Hashtable判断两个key相等的标准也是key通过equals方法返回true,两个key的hashCode相等。判断value相等的标准是equals返回true即可,不需要hashCode判断。
1 package chapter7; 2 3 import java.util.Hashtable; 4 5 //定义类A,该类根据A对象的count属性来判断两个对象是否相等,计算hashCode值 6 //只要两个A对象的count相等,则它们通过equals比较也相等,其hashCode值也相等 7 8 class AA{ 9 int count; 10 public AA(int count){ 11 this.count = count; 12 } 13 public boolean equals(Object obj){ 14 if (obj == this){ 15 return true; 16 } 17 if(obj!=null && obj.getClass() == AA.class){ 18 AA a = (AA)obj; 19 if(this.count == a.count){ 20 return true; 21 } 22 23 } 24 return false; 25 } 26 public int hashCode(){ 27 return this.count; 28 } 29 } 30 //定义类B,B对象与任何对象通过equals方法比较都相等 31 class BB{ 32 public boolean equals(Object obj){ 33 return true; 34 } 35 } 36 public class HashtableTest { 37 public static void main(String[] args){ 38 Hashtable ht = new Hashtable(); 39 ht.put(new AA(60000),"English"); 40 ht.put(new AA(87653),"Castellano"); 41 ht.put(new AA(1232),new B()); 42 System.out.println(ht); 43 //只要两个对象通过equals比较返回true,Hashtable就认为它们是相等的value。 44 //因为Hashtable中有一个B对象,它与任何对象通过equals比较都相等,所以下面输出true。 45 System.out.println(ht.containsValue("测试字符串")); 46 //只要两个A对象的count属性相等,它们通过equals比较返回true,且hashCode相等 47 //Hashtable即认为它们是相同的key,所以下面输出true。 48 System.out.println(ht.containsKey(new AA(87653))); 49 //下面语句可以删除最后一个key-value对 50 ht.remove(new AA(1232)); 51 for(Object key:ht.keySet()){ 52 System.out.print(key + "---->"); 53 System.out.print(ht.get(key) + "\n"); 54 } 55 } 56 }
程序最后展示了如何遍历Map中的全部key-value对:调用Map对象的keySet方法返回全部key组成的Set对象,通过遍历Set的元素(就是Map的全部key)就可以遍历Map中的所有键值对。
与HashSet类似的是,尽量不要使用可变对象作为HashMap、Hashtable的key,如果确实需要使用可变对象作为HashMap、Hashtable的key,则尽量不要在程序中修改作为key的可变对象。
HashSet有一个子类是LinkedHashSet,HashMap则有一个子类:LinkedHashMap;LinkedHashMap也使用双向链表来维护key-value对的次序,该链表定义了迭代次序,迭代顺序与插入顺序时候保持一致。
LinkedHashMap可以避免需要对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可)。同时可以避免使用TreeMap所增加的成本。LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。下面程序示范了LinkedHashMap的功能:迭代输出LinkedHashMap的元素时,将会按添加key-value对相同顺序输出。
Properties类
Properties类是Hashtable类的子类,该文件处理属性文件(ini文件就是一种属性文件)。Properties类可以把Map对象和属性文件关联起来,从而把Map对象中的key-value对写入属性文件,也可以把属性文件中的属性名=属性值加载到Map对象中。由于属性文件里的属性名、属性值只能是字符串类型,所以Properties里的key、value都是字符串类型,该类提供了如下三个方法来修改Properties里的key、value值。
方法:
String getProperty(String key):获取Properties中指定属性名对应的属性值,类似于Map的get(Object key)方法
String getProperty(String key,String defaultValue):该方法与前一个方法基本类似,该方法多一个功能,如果Properties中不存在指定key时,该方法返回默认值
Object setProperty(String key,String value):设置属性值,类似Hashtable的put方法 除此之外,它还提供了两个读、写属性文件的方法
void load(InputStream inStream):从属性文件(以输入流表示)中加载属性名=属性值,把加载到的属性名=属性值对追加到Properties里(由于Properties是Hashtable的子类,它不保证key-value对之间的次序)。
void store(OutputStream out,String comments):将Properties中的key-value对写入指定属性文件(以输出流表示)。
5.5 SortedMap和TreeMap
正如Set接口派生出了SortedSet子接口,SortedSet接口有一个TreeSet实现类,Map接口也派生了一个SortedMap子接口,SortedMap也有一个TreeMap实现类。 与TreeSet类似的是,TreeMap也是基于红黑树对TreeMap中所有key进行排序,从而保证TreeMap中的键值对处于有序状态。类似也有两种排序方式。
排序方式
自然排序:TreeMap的所有key必须实现Comparable接口,而且所有key应该是同一个类对象,否则抛出ClassCastException异常 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中所有key进行排序,采用定制排序时不要求Map的key实现Comparable接口 类似地,TreeSet中判断两个元素相等的标准,TreeMap中判断两个key相等的标准也是两个key通过equals比较返回true,而通过compareTo方法返回0,TreeMap即认为这两个key是相等的。 如果想使用自定义的类作为TreeMap的key,且想让TreeMap工作良好,重写该类的equals方法和compareTo方法时应该有一致的返回结果:即两个key通过equals方法比较返回true时,通过compareTo方法返回0,否则处理会有性能问题,具体可以参考TreeSet。
TreeMap方法
与TreeSet类似的是,TreeMap提供了系列根据key顺序访问Map中key-value对方法。
Map.Entry firstEntry():返回该Map中最小key所对应的键值对,如果该Map为空,则返回null
Object firstKey():返回该Map中的最小key值,如果Map为空,则返回null
Map.Entry lastEntry():返回该Map中最大key所对应的key-value对,如果该Map为空,或不存在这样的key-value则返回null
Object lastKey():返回该Map中的最大key值,如果Map为空,或不存在这样的key都返回null
Map.Entry higherEntry(Object key):返回该Map中key的上确界对应的键值对
Object higherKey(Object key):返回key的上确界
Map.Entry lowerEntry(Object key):返回该Map中key的下确界对应的键值对
Object lowerKey(Object key):返回key的下确界
NavigableMap subMap(Object fromKey,boolean fromInclusive,Object toKey,boolean toInclusive):返回该Map的子Map,其key的范围从fromKey(是否包括取决于第二个参数) 到toKey(是否包括取决于第四个参数)
NavigableMap tailMap(Object fromKey,boolean inclusive):返回该Map的子Map,其key的范围从fromKey(是否包括取决于第二个参数)
NavigableMap headMap(Object toKey,boolean inclusive):返回该Map的子Map,其key的范围小于toKey(是否包括取决于第二个参数)
SortedMap subMap(Object fromKey,Object toKey):返回该Map的子Map,其key的范围从fromKey(包括)到toKey(不包括)
SortedMap tailMap(Object fromKey):返回该Map的子Map,其key的范围从fromKey(不包括)
SortedMap headMap(Object toKey):返回该Map的子Map,其key的范围小于toKey(不包括)
上面的看起来方法挺多:也就是第一个、前一个、后一个、最后一个键值对方法,并提供了截取子TreeMap的方法
5.6 WeakHashMap实现类
WeakHashMap与HashMap用法基本类似,但与HashMap区别在于,HashMap的key保留对实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap对象所有key所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的key-value对象;但WeakHashMap的key只保留对实际对象的弱引用,这意味着如果该HashMap对象所有key所引用的对象没有被其他强引用变量所引用,key所引用的对象可能被垃圾回收,HashMap有可能自动删除这些key所对应的key-value对象 WeakHashMap中的每个key对象保存了实际对象的弱引用,因此,当垃圾回收了该key所对应的实际对象之后,WeakHashMap会自动删除key-value对。
1 package chapter7; 2 3 import java.util.*; 4 5 public class TestWeakHashMap { 6 public static void main(String[] args){ 7 //添加一个集合,并添加匿名对象(无变量引用) 8 WeakHashMap whm = new WeakHashMap(); 9 whm.put(new String("English"), "80"); 10 whm.put(new String("Chemistry"), "80"); 11 whm.put(new String("Java"), "80"); 12 System.out.println(whm); 13 //添加一个有变量引用的对象 14 whm.put("Deutsch", "99"); 15 System.out.println("垃圾回收前:" + whm); 16 //通知系统进行垃圾回收 17 System.gc(); 18 //输出垃圾回收后的结果 19 System.out.println("垃圾回收后:" + whm); 20 //对比HashMap垃圾处理机制 21 HashMap hm = new HashMap(); 22 hm.put(new String("English"), "80"); 23 hm.put(new String("Chemistry"), "80"); 24 hm.put(new String("Java"), "80"); 25 System.out.println(hm); 26 //添加一个有变量引用的对象 27 hm.put("Deutsch", "99"); 28 System.out.println("垃圾回收前:" + hm); 29 //通知系统进行垃圾回收 30 System.gc(); 31 //输出垃圾回收后的结果 32 System.out.println("垃圾回收后:" + hm); 33 34 } 35 } 36 执行结果如下: 37 {Java=80, English=80, Chemistry=80} 38 垃圾回收前:{Java=80, English=80, Deutsch=99, Chemistry=80} 39 垃圾回收后:{Deutsch=99} 40 {Chemistry=80, Java=80, English=80} 41 垃圾回收前:{Chemistry=80, Deutsch=99, Java=80, English=80} 42 垃圾回收后:{Chemistry=80, Deutsch=99, Java=80, English=80}
5.7 IdentityHashMap实现类
这个Map实现类的实现机制与HashMap基本相似,但它在处理两个key相等时比较独特:在IdentityHashMap中,当且仅当两个key严格相等(key1==key2)时,IdentityHashMap才认为两个key相等,对于普通HashMap而言,只要key1和key2通过equals方法比较返回true,且hashCode值相同即可。 IdentityHashMap是一个特殊的Map实现,它有意违反Map的通常规范:在IdentityHashMap中,当且仅当两个key严格相等(key1==key2)时,IdentityHashMap才认为两个key相等 IndetityHashMap提供了与HashMap基本类似的方法,null作为key和value,不保证键值对之间的顺序。
1 package chapter7; 2 3 import java.util.*; 4 /** 5 * Description: 6 * <br/>Copyright (C), 2005-2008, Yeeku.H.Lee 7 * <br/>This program is protected by copyright laws. 8 * <br/>Program Name: 9 * <br/>Date: 10 * @author Yeeku.H.Lee kongyeeku@163.com 11 * @version 1.0 12 */ 13 public class TestIdentityHashMap{ 14 public static void main(String[] args){ 15 IdentityHashMap ihm = new IdentityHashMap(); 16 //下面两行代码将会向IdentityHashMap对象中添加2个key-value对 17 ihm.put(new String("语文") , 89); 18 ihm.put(new String("语文") , 78); 19 ihm.put("java" , 93); 20 ihm.put("java" , 98); 21 System.out.println(ihm); 22 } 23 }
注意:最后添加的两个key为java的键值对是一样的,因为java采用的缓存机制,对于同一个字符串,不新建新的对象来浪费内存
5.8 EnumMap集合类
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。
EnumMap根据key的定义时顺序来维护键值对的次序,当使用keySet()、entrySet()、values()等方法来遍历EnumMap时即可看到这种顺序与插入时候顺序是一致的。
EnumMap不允许使用null昨晚key值,但允许使用null作为value,如果试图使用null作为key将抛出NullPointerException异常,如果只是查询是否包含值为null的key,或者删除使用删除值为null的key都不会抛出异常。
与创建普通Map有区别的是,创建EnumMap时必须指定一个枚举类,从将该EnumMap和指定枚举类关联起来。
对于Map的常用实现类而言,HashMap和Hashtable的效率大致相同,因为实现机制几乎完全一样,但通常HashMap通常比Hashtable快一点,因为Hashtable额外实现同步操作。 TreeMap通常比HashMap、Hashtable要慢(尤其是插入、删除键值对时候更慢),因为TreeMap需要额外的红黑树操作来维护key之间的次序,但是用TreeMap有一个好处:TreeMap中的键值对总是有序的,无序专门进行排序操作。当TreeMap被填充后,可以调用keySet(),取得key组成的Set,然后是用toArray()生成key的数组,接下来是用Arrays的binarySearch()方法在已排序的数组中快速地查询对象。当然,通常只有在某些情况下无法使用HashMap的时候才这么做,因为HashMap正是为快速查询而设计的,通常使用Map时候首选HashMap,除非需要一个总是排好序的Map时才使用TreeMap。 LinkedHashMap比HashMap慢一点,因为它需要维护链表来保持Map中key的顺序。IndentityHashMap性能没有特别出色之处,EnumMap性能最好,但它只能使用同一个枚举类的枚举值作为key。
5.9 HashSet和HashMap的性能选择
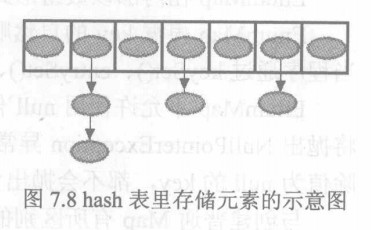
对于HashSet及其子类而言,它们采用hash算法来决定集合中元素的存储位置,并通过hash算法来增加集合容积的大小;对于HashMap、Hashtable及其子类而言,它们采用hash算法来决定Map中key的存储,并通过hash算法来增加key Set容积的大小Hash表里可以存储元素的位置被称为"桶(bucket)",通常情况下,单个"桶"里存储一个元素,此时有最好的性能:hash算法可以根据hashCode值计算出"桶"的存储位置,接着从"桶"中取出元素,但hash表的状态为open:当发送hash冲突时候,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。如下图
因为HashSet、HashMap、Hashtable都是用hash算法来决定其元素(对HashMap则是key)的存储,因此HashSet、HashMap的hash表包含如下属性:
Hash表属性
容量(capacity):hash表中桶的数量
初始化容量(initial capacity):创建hash表时桶的数量。HashMap和HashSet都允许在构造器中指定初始化容量
尺寸(size):当前hash表中记录的数量
负载因子(load factor):负载因子等于size/capacity。负载因子为0,表示空的hash表,0.5 表示半满的hash表,以此类推,轻负载的hash表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时候会变慢)
除此之外,hash表里还有一个负载极限,负载极限在[0,1]的数值,负载极限决定了hash表中的最大填满程度。当hash表中的负载因子到达指定的负载极限时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,也被称为rehashing
HashSet与HashMap、Hashtable的构造器允许指定一个负载极限,HashSet与HashMap、Hashtable默认的负载极限为0.75, 表明当该hash表被填到3/4 时,hash表会发生rehashing
默认负载极限值0.75 是时间和空间成本上的一种折中:较高的负载极限可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作;较低的负载极限会增加查询数据性能,但会增加hash表所占用的内存空间。通常无须改变HashSet和HashMap的负载极限值。通常不需要将初始化容量设置太高。
5.10 操作集合工具类Collections
Java提供了一个操作Set、List和Map等集合的工具类:Collections,该工具类提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了将集合对象设置为不可变、对集合对象实现同步控制等方法。
5.10.1 排序操作
Collections提供了如下几个方法对List集合元素进行排序 static void reverse(List list):反转指定List集合中元素的顺序 static void shuffle(List list):对List集合元素进行随机排序(shuffle方法模拟了洗牌动作) static void sort(List list):根据元素的自然顺序对指定List集合的元素按升序进行排序 static void sort(List list,Comparator c):根据指定Comparator产生的顺序对List集合的元素进行排序 static void swap(List list,int i,int j):将指定List集合中i处元素和j处元素进行交换 static void rotate(List list,int distance):将指定集合中i处元素和list.length-i-1 处的元素进行交换
5.10.2查找,替换操作
Collections还提供了如下用于查找、替换集合元素的常用方法 static int binarySearch(List list,Object key):使用二分搜索法搜索指定List集合,以获得指定对象在List集合中的索引,如果要该方法可以正常工作,必须保证List中的元素已经处于有序状态
static Object max(Collection coll):根据元素的自然顺序,返回给定集合中的最大元素 static Object max(Collection coll,Comparator comp):根据指定Comparator产生的顺序,返回给定集合的最大元素 static Object min(Collection coll):根据元素的自然顺序,返回给定集合中的最小元素 static Object min(Collection coll,Comparator comp):根据指定Comparator产生的顺序,返回给定集合的最小元素 static void fill(List list,Object obj):使用指定元素obj替换指定List集合中的所有元素 static int frequency(Collection c,Object o):返回指定集合中等于指定对象的元素数量 static int indexOfSubList(List source,List target):返回子List对象在母List对象中第一次出现的位置索引;如果母List中没有这样的子List,则返回-1
static int lastIndexOfSubList(List source,List target):返回子List对象在母List对象中最后一次出现的位置索引;如果母List中没有这样的子List,则返回-1 static boolean replaceAll(List list,Object oldVal,Object newVal):使用一个新值newVal替换List对象所有的旧值oldVal
5.10.3 同步控制
Collections类中提供了多个synchronizedXxx方法(Xxx代表集合类名称),该方法返回指定集合对象对应的同步对象,从而可以解决多线程并发访问集合时的线程安全问题。 如前所述,Java常用的集合框架中推荐使用的三个实现类:HashSet、ArrayList和HashMap都是线程不安全的,如果有多条线程访问它们,而且有超过一条线程试图修改它们,则可能出现错误。Collections提供了多个静态方法用于创建同步集合。
5.10.4 设置不可变集合
Collections提供了如下三类方法来返回一个不可变的集合,Xxx代表集合类名称 emptyXxx():返回一个空的、不可变的集合对象,此处的集合可以是List、Set、Map singleonXxx():返回一个只包含指定对象(只有一个或一项元素)的、不可变的集合对象,此处的集合可以是List、Set、Map unmodifiableXxx:返回指定集合对象的不可变视图。此处的集合可以是List、Set、Map 通过这样的方法就可以创建"只读"版本的集合,对象不可修改
5.10.5 烦琐的:Enumeration
Enumeration接口是Iterator迭代器的古老版本,目前都使用Iterator,保留Enumeration主要是为了照顾那些古老的程序。
6.小结
本部分详细介绍了Java集合框架的相关知识。
本部分从Java集合框架体系开始讲起,概述了Java集合框架的三个主要体系:Set、List和Map,简述集合在编程中的重要性。详细讲述了Set、Queue、List、Map接口及各实现类的详细用法,深入分析了各实现类的机制差异,给出选择集合实现类的原则,最后给出了Collections工具类的基本用法。
)


)
方法与示例)





中的array :: fill())
![Opencv——批量处理同一文件夹下的图片(解决savedfilename = dest + filenames[i].substr(len)问题)](http://pic.xiahunao.cn/Opencv——批量处理同一文件夹下的图片(解决savedfilename = dest + filenames[i].substr(len)问题))





)

