英伟达最近发布了一个新的GPUDirect Storage,暂且叫做GPU直连存储,让GPU直接连到NVMe存储设备上。这一方案用到了RDMA设备来把数据从闪存存储转移到GPU本地的内存里,无需经过CPU还有系统内存。
如果这一举措顺利的话,英伟达就能摆脱对于CPU的依赖开辟一片全新的领地,全新的市场,比如数据科学和机器学习市场,这一市场将造就每年200亿到250亿美金的服务器市场,跟HPC和深度学习市场加起来的市场规模差不多一样大。
英伟达在拼命的把要做的事情往GPU里放,去年十月份,英伟达发布了RAPIDS,这是一个开源的工具库,用于帮助人们用GPU做分析和机器学习。RAPIDS可以对Apache Arrow, Spark等数据科学类的工具提供GPU加速,将GPU放入大数据企业应用的生态,这一领域现如今仍旧是以基于CPU的Hadoopp和Mapreduce这种方案。
RAPIDS涵盖了机器学习的所有方面,包括监督式和无监督式的机器学习,还有各种数据处理方面的内容,但是,这一做法也遭到了一些怀疑。
GPU现在越做越大,连接性也越来越好,从应用的角度来看,GPU的通用也很好。与此同时,数据分析越来越负载,机器学习经常会集成到工作流程中,这样一来,对TB级数据进行千万亿次计算的应用程序也会越来越多。
想做好这点必须有很好的可扩展性,通过NVLink和NVSwitch等技术可以连接多个GPU,组成一个巨大的加速器,该技术最初是为DGX架构设计的,这一架构主要也是为了解决规模更大,更复杂的神经网络训练问题。英伟达想把GPU的计算能力用于大数据的想法是说的通的,但唯独就是缺少快速的数据存储路径。
通常,在GPU加速系统当中,所有的IO操作都会先经过主机端,也就是需要经过CPU指令把数据传到主机内存里,然后才会到达GPU,CPU通常会通过“bounce buffer”来实现数据传输,“bounce buffer”是系统内存中的一块区域,数据在传输到GPU之前会在这里保存一个副本。很明显,这种中转会引额外延迟和内存消耗,降低运行在GPU上的应用程序的性能,还会占用CPU资源,这就是GPUDirect Storage要解决的问题。
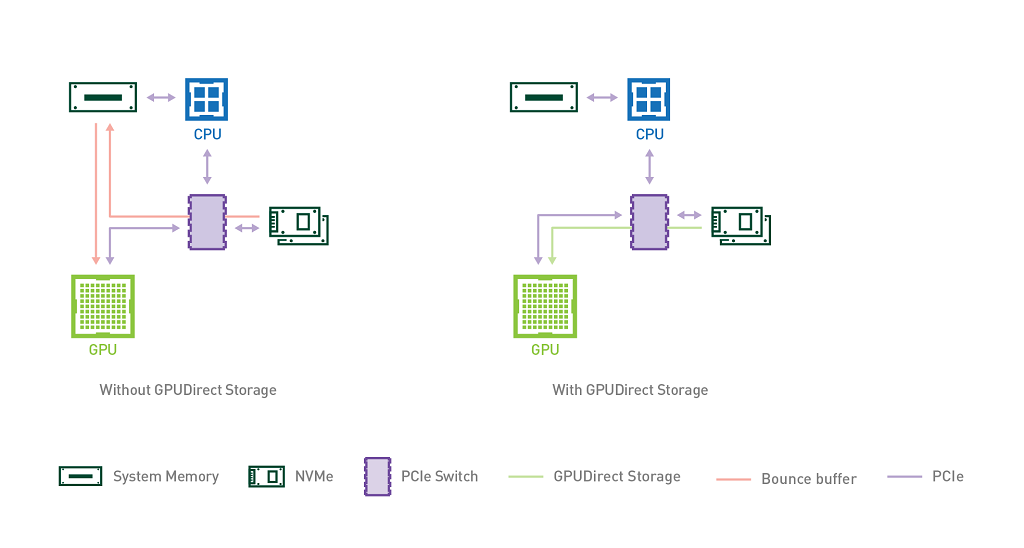
英伟达方面表示这一技术能提升50%的IO带宽,延迟能降低3.8倍。如果通过NVMeoF技术的话,GPU就能连上PB级别的存储资源池,更厉害的是,英伟达声称数据存取的效率比内存的页面缓存速度还要快。
英伟达表示,如果你的DGX-2系统里有16个GPU,主机端有1.5TB内存的话,GPUDirect Storage的吞吐带宽能提升8倍(跟原来不支持GPUDirect Storage的DGX-2系统相比)。这是因为,DGX-2的吞吐带宽能达到大约200GB/s,而原来依靠主机端内存的话,最多也就50GB/s。
多出来的这150GB/s传输速度对于数据分析型工作负载的提升将非常可观,对于像深度学习这种文件密集型应用程序,对于传统的HPC也将会带来很大改观。
英伟达的这一做法让GPU直连到存储,直接拿到原始数据,意味着GPU也可以对文件进行解压缩和解码操作,解放CPU。目前,GPUDirect Storage支持各种常见的文件格式进行操作。
GPUDirect Storage方案用到了两项高端技术,一个是RDMA,一个是NVMe(NVMe-oF),其中,RDMA被封装在GPUDirect的协议中,依靠各种网络适配器工作(比如Mellanox的NIC),既可以访问远程的存储也可以访问本地的存储设备。
目前,GPUDirect Storage只面向少数合作伙伴提供,预计今年十月份将推出beta版本。
在译者看来,这是英伟达跟英特尔竞争的又一大举措,可以看做是对英特尔再度进军GPU市场的一个回应。
绕开CPU,开辟一片新的生态,这在理论上是可行的,也确实有明显的需求场景,最后能否在市场上推行开来,还得看方案构建的水平,包括方案的易用性,稳定性,场景的优化水平,当然,最重要的还是不要对现有软件架构带来太多变化,控制用户的使用成本和购置成本。


—— hstack/column_stack,linalg.eig/linalg.eigh)













)


