一、说明
大语言模型(维基:LLM- large language model)是以大尺寸为特征的语言模型。它们的规模是由人工智能加速器实现的,人工智能加速器能够处理大量文本数据,这些数据大部分是从互联网上抓取的。 [1]所构建的人工神经网络可以包含数千万到数十亿的权重,并使用自监督学习和半监督学习进行(预)训练。 Transformer 架构有助于加快训练速度。[2]替代架构包括专家混合(MoE),它是由 Google 提出的,从 2017 年的稀疏门控架构开始,[3] 2021 年的 Gshard[4] 到 2022 年的 GLaM。
作为语言模型,它们的工作原理是获取输入文本并重复预测下一个标记或单词。[6]到 2020 年,微调是模型能够完成特定任务的唯一方法。然而,较大尺寸的模型,例如 GPT-3,可以通过快速设计来实现类似的结果。 [7]他们被认为获得了人类语言语料库中固有的语法、语义和“本体论”的具体知识,但也获得了语料库中存在的不准确和偏见。 [8]
二、度量尺度演进史
在17世纪初,一位名叫埃德蒙·冈特(Edmund Gunter)的数学家和天文学家面临着前所未有的天文学挑战。计算行星的复杂运动和预测日食需要的不仅仅是直觉——它需要掌握复杂的对数和三角方程。因此,就像任何精明的创新者一样,冈瑟决定从头开始构建它!他创造了一种模拟计算设备,最终成为所谓的计算尺。
计算尺是一个长30厘米的矩形木块,由两部分组成:固定框架和滑动部分。固定框架容纳固定对数刻度,而滑动部分容纳可移动刻度。要使用计算尺,您需要了解对数的基本原理以及如何对齐乘法、除法和其他数学运算的刻度。您必须滑动可移动部分以对齐设置数字,读取结果并考虑小数点放置。哎呀,这真的很复杂!

大约300年后,贝尔潘奇公司于1961年推出了第一台电子桌面计算器“ANITA Mk VII”。在接下来的几十年里,电子计算器变得更加复杂,具有附加功能。以前需要大量手动计算的工作大大减少了工时,使员工能够专注于工作中更具分析和创造性的方面。因此,现代电子计算器不仅重塑了工作角色,还为提高解决问题的能力铺平了道路。
计算器是数学完成方式的一步变化。语言呢?
三、语言度量才刚刚开始
想想你是如何生成句子的。你首先需要有一个想法。接下来,你需要知道一堆单词(词汇)。然后,您需要能够将它们放在适当的句子(语法)中。啧,又是相当复杂的!

我们生成语言单词的方式可以追溯到50万年前,也就是现代智人首次创造语言的时候。
公平地说,我们仍然处于冈瑟在生成句子时使用计算尺的时代!
如果你考虑一下,使用适当的词汇和语法基本上只是遵守规则。语言规则。
这类似于数学。它充满了规则。因此,为什么我可以确定 1+1=2 以及为什么计算器有效!
我们需要的是一个计算器,但对于文字!
是的,不同的语言遵循不同的规则,但需要遵循一些规则才能理解。语言和数学之间的一个明显区别是,数学有固定的答案,而一个句子中可以容纳的合理单词的数量可能很大。
尝试完成以下句子:我吃了一个________。想象一下接下来可能出现的单词。英文大约有1万个单词。其中很多都可以在这里使用,但绝对不是全部。
回答“黑洞”相当于说2+2=5。此外,回答“苹果”也不准确。为什么?因为语法!

在过去的几个月里,大型语言模型(LLM)风靡全球。一些人称其为自然语言处理的突破,而另一些人则将其视为人工智能(AI)新时代的曙光。
LLM已被证明非常擅长生成类似人类的文本,提高了基于语言的AI应用程序的标准。凭借庞大的知识库和上下文理解,LLM可以应用于各个领域,从语言翻译和内容生成到虚拟助手和客户支持聊天机器人。
问题是:我们目前是否处于LLM的拐点,就像我们在1960年代使用电子计算器一样?
在我们回答这个问题之前,LLM是如何工作的?LLM基于转换器神经网络,用于计算和预测接下来最适合的单词。要构建一个强大的转换器神经网络,您需要在大量的文本数据上对其进行训练。这就是为什么“预测下一个单词/标记”方法如此有效的原因:有很多容易获得的训练数据。LLM将整个单词序列作为输入,并预测下一个最有可能出现的单词。为了了解接下来最有可能发生的事情,他们吞下了所有的维基百科作为热身练习,然后转向成堆的书籍,最后是整个互联网。
我们之前已经确定语言包含规则和模式。该模型通过遍历所有这些句子隐式学习这些规则,它将使用这些句子来完成预测下一个单词的任务。
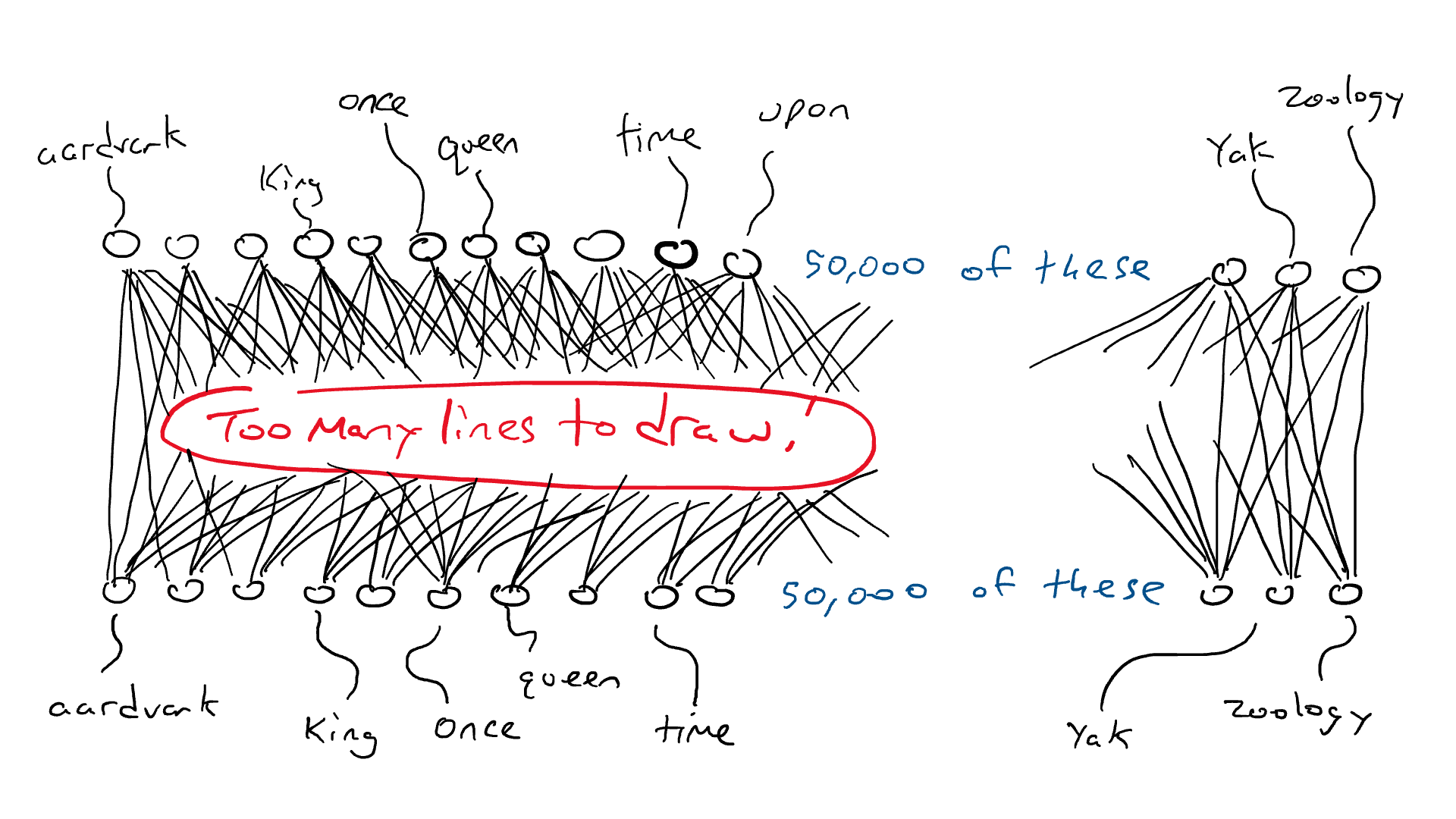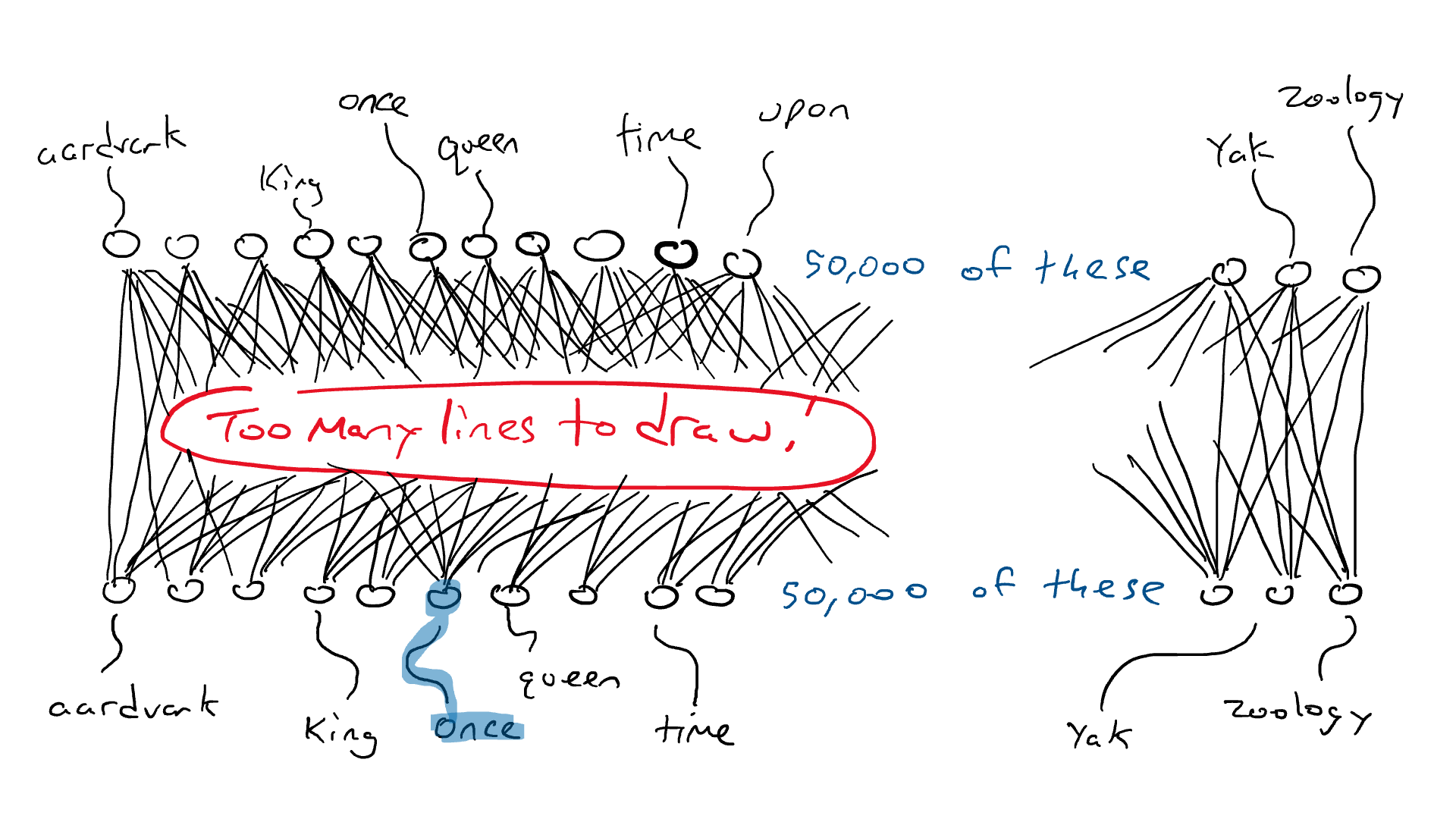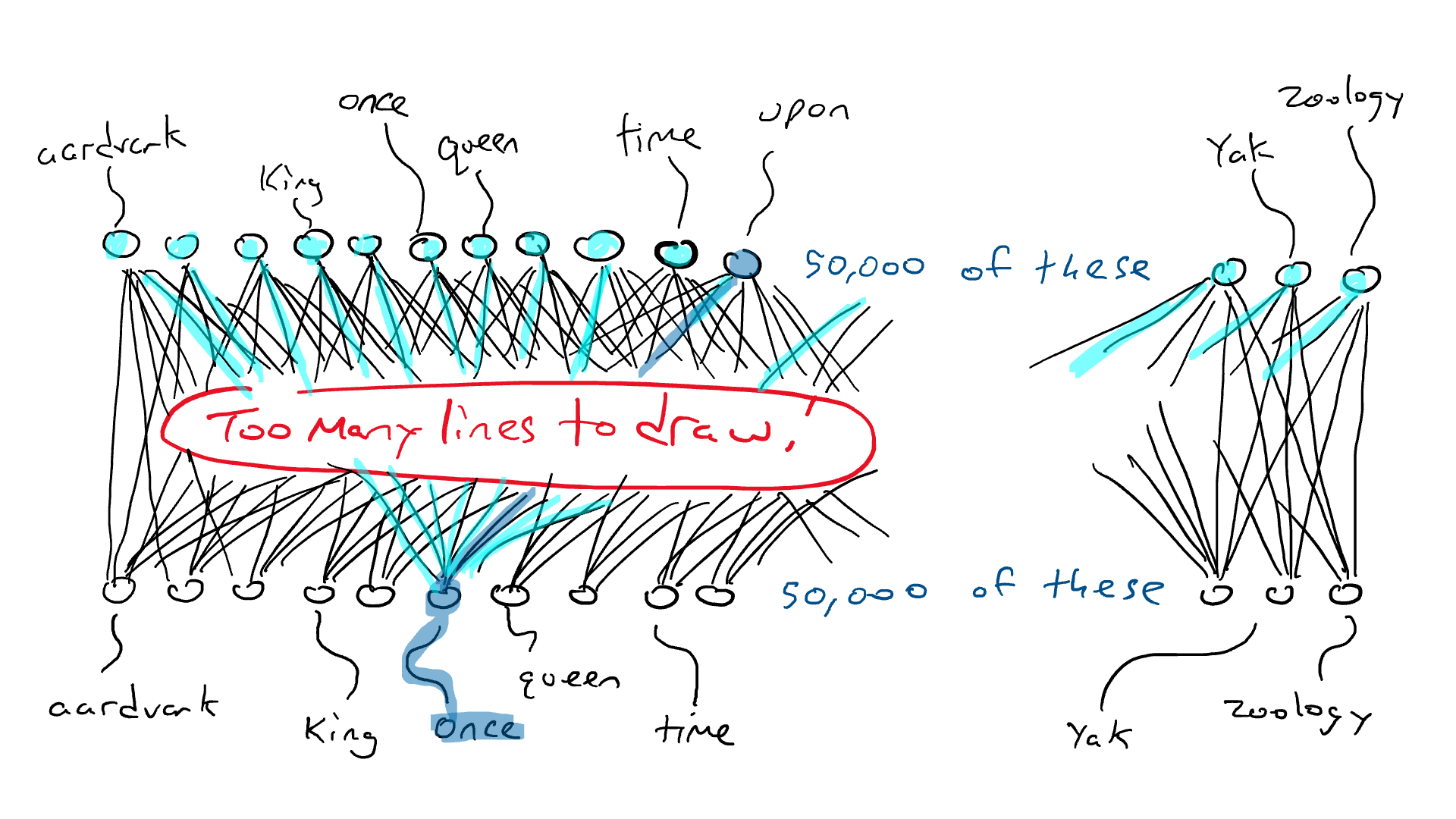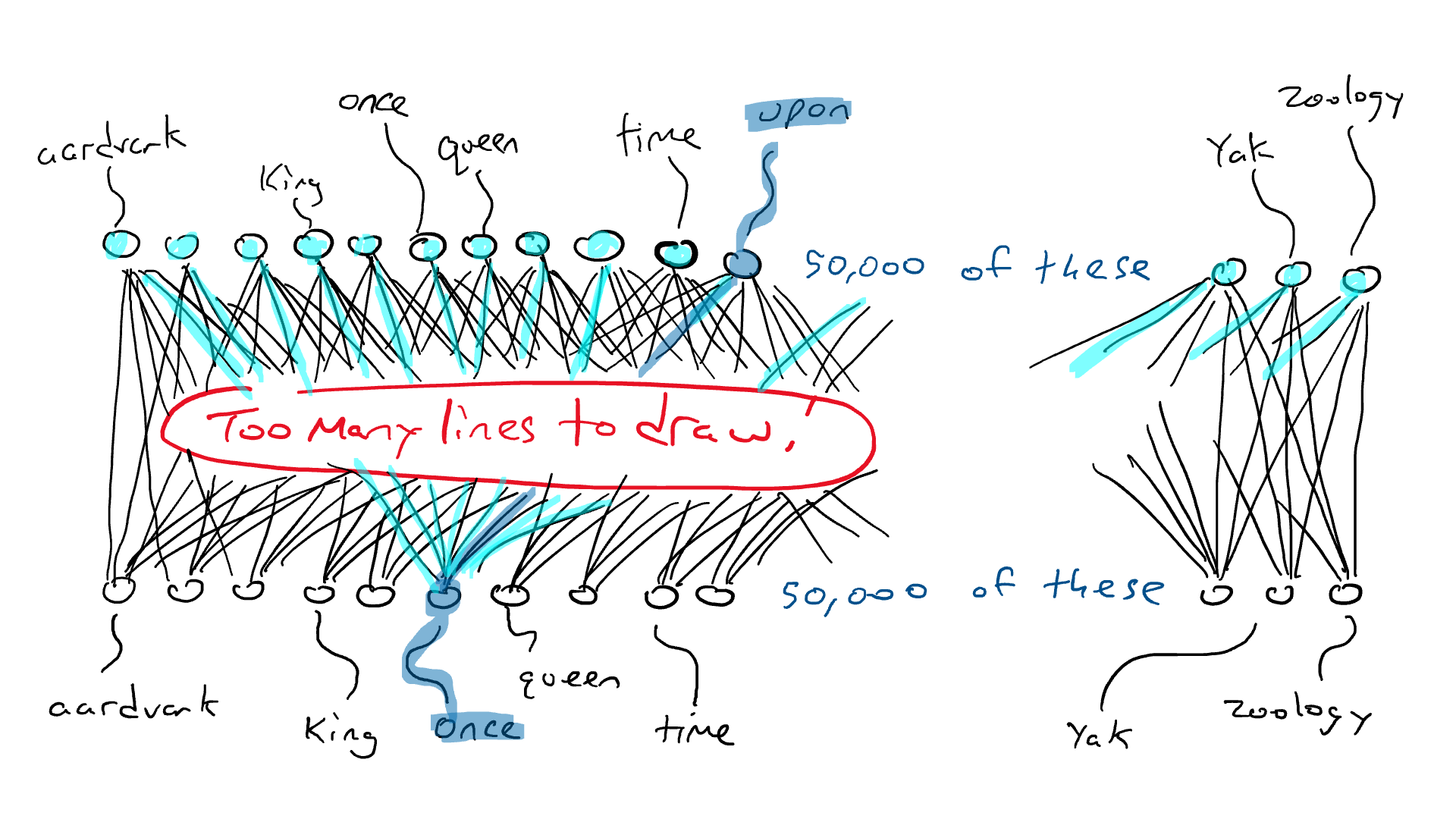
在单数名词之后,下一个单词是以“s”结尾的动词的可能性增加。同样,在阅读莎士比亚时,看到“doth”和“wherefore”等词的机会也会增加。
在训练过程中,模型用语言学习这些模式,最终成为专家!
但这够了吗?学习语言规则就够了吗?

因此,自我关注。简单来说,自我注意是LLM用来理解句子或一段文本中不同单词之间关系的一种技术。就像你关注故事的不同部分来理解它一样,自我关注允许LLM在处理信息时更加重视句子中的某些单词。这样,模型可以更好地理解文本的整体含义和上下文,而不是仅仅根据语言规则盲目地预测下一个单词。

如果LLM是单词的计算器,只是预测下一个单词,它如何回答我所有的问题?
当你要求一个大型语言模型做一些聪明的事情——而且它有效——你很有可能要求它做一些它已经看到数千个例子的事情。即使你想出了一些非常独特的东西,比如:
“给我写一首关于逆戟鲸吃鸡的诗”
在海浪中,一个看不见的景象,一只逆戟鲸捕猎,迅速而敏锐,在海洋领域,舞蹈开始,作为鸡的命运,逆戟鲸获胜。
它用强大的下颚撞击猎物,羽毛漂浮,漂流,以自然的方式,编织一个故事,生与死合而为一。
~ 聊天
很不错吧?得益于其自我注意机制,它可以有效地混合和匹配相关信息,以构建合理而连贯的响应。
在训练过程中,LLM学习识别他们所接触到的数据中单词和短语之间的模式,关联和关系。由于这种广泛的培训和微调,LLM可以表现出新兴属性,例如执行语言翻译,摘要,问答甚至创意写作的能力。这些功能通常超出了模型中显式编程的范围,并且可能非常出色!
大型语言模型是否智能?
电子计算器已经存在了六十多年。该工具本身已经有了突飞猛进的改进,但它从未被认为是智能的。为什么?
图灵测试 - 图灵测试是一种看似简单的方法,用于确定机器是否表现出类似人类的智能:如果机器能够以与人类无法区分的方式与人类进行对话,则认为它具有人类智能。
计算器从未接受过图灵测试,因为它不像人类那样用同样的语言进行交流,只有数学语言。另一方面,LLM产生人类语言。它的整个训练过程围绕着模仿人类语言。因此,它可以“以与人类无法区分的方式与人类进行对话”也就不足为奇了。
因此,用“智能”这个词来描述LLM有点棘手,因为对于智能的真正含义没有明确的共识。考虑某物是否智能的一种方法是,它是否做了有趣、有用且不是非常明显的事情。LLM确实属于这一类。不幸的是,我完全不同意这种解释。
我将智力定义为扩展知识前沿的能力。
在撰写本文时,经过训练来预测下一个标记/单词的机器仍然无法扩展知识的前沿。
但是,它可以对已训练的数据进行插值。没有明确理解单词背后的逻辑,也没有存在的知识树。因此,它将永远无法产生异常的想法并实现洞察力的飞跃。它将始终提供连贯的答案,在某种程度上是平均响应。

我们应该把LLM更像一个单词的计算器。永远不要把你的思维完全外包给语言模型。
与此同时,随着这些模型呈指数级增长,我们可能会感到越来越不知所措和微不足道。解决这个问题的方法是始终对看似无关的想法保持好奇。表面上看起来不连贯的想法,但基于我们与周围环境的互动而有意义。目标是生活在知识的边缘,创造和连接新的点。
如果你在这个层面上工作,所有形式的技术,无论是计算器还是大型语言模型,都会成为你可以使用的工具,而不是你需要担心的生存威胁。

)
)





![[RoarCTF 2019Online Proxy]sql巧妙盲注](http://pic.xiahunao.cn/[RoarCTF 2019Online Proxy]sql巧妙盲注)






![Vue [Day7]](http://pic.xiahunao.cn/Vue [Day7])



