文章目录
- MySQL基础
- 数据库的介绍
- 数据库概述
- 数据的存储方式
- 数据库的概念
- 常见数据库排行榜
- 数据库的安装与卸载
- 数据库的安装
- 数据库的卸载
- 数据库服务的启动与登录
- Windows 服务方式启动
- DOS 命令方式启动
- 控制台连接数据库
- SQLyog 图形化工具——客户端
- 使用 SQLyog 登录数据库
- 数据库管理系统
- 数据库管理系统、数据库和表的关系
- SQL 的概念
- 什么是 SQL
- SQL 作用
- SQL 语句分类
- MySQL 的语法
- DDL 操作数据库
- 创建数据库
- 创建数据库的几种方式
- 查看数据库
- 修改数据库
- 删除数据库
- 使用数据库
- DDL 操作表结构
- 创建表
- MySQL 数据类型
- 查看表
- 快速创建一个表结构相同的表
- 删除表
- 修改表结构
- DML 操作表中的数据
- 插入记录
- 蠕虫复制
- 什么是蠕虫复制
- 更新表记录
- 删除表记录
- DQL 查询表中的数据
- 简单查询
- 指定列的别名进行查询
- 清除重复值
- 查询结果参与运算
- 条件查询
- 运算符
- 逻辑运算符
- in 关键字
- 范围查询
- like 关键字
- MySQL 表的约束与数据库设计
- DQL 查询语句
- 排序
- 聚合函数
- 分组
- limit 语句
- 数据库备份和还原
- 备份的应用场景
- 备份与还原的语句
- 图形化界面备份与还原
- 数据库表的约束
- 数据库约束的概述
- 主键约束
- 唯一约束
- 非空约束
- 默认值
- 外键约束
- 表与表之间的关系
- 表关系的概念
- 一对多
- 多对多
- 一对一
- 数据库设计
- 数据规范化
- 1NF
- 2NF
- 3NF
- 三大范式小结
- MySQL 多表查询与事务的操作
- 表连接查询
- 什么是多表查询
- 内连接查询
- 外链接查询
- 子查询
- 事务
- 事务的基本介绍
- 事务的四大特征
- 事务的隔离级别
- DCL
- 管理用户
- 权限管理
MySQL基础
数据库的介绍
数据库概述
数据的存储方式
Java 中创建对象: Student s = new Student(1, “张三”) 存在内存中
学习了 Java IO 流:把数据保存到文件中。
| 存储位置 | 优点 | 缺点 |
|---|---|---|
| 内存 | 速度快 | 不能永久保存,数据是临时状态。 |
| 文件 | 数据可以永久保存 | 操作数据不方便,查询某个数据。 |
| 数据库 | (1)、 数据可以永久保存 (2)、 查询速度快 (3)、 对数据的管理方便 | 占用资源,需要购买。 |
数据库的概念
什么是数据库
- 存储数据的仓库
- 本质上是一个文件系统,还是以文件的方式存在服务器的电脑上的。
- 所有的关系型数据库都可以使用通用的 SQL
语句进行管理 DBMS DataBase Management System
常见数据库排行榜
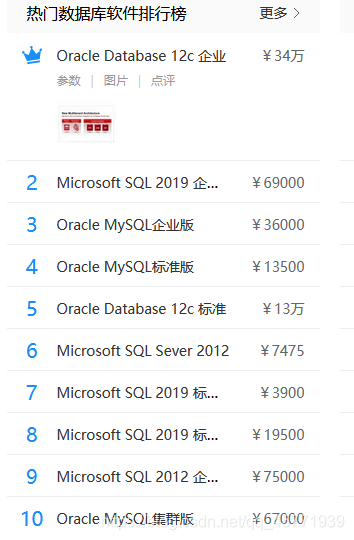
MySQL:开源免费的数据库,小型的数据库,已经被 Oracle 收购了。MySQL6.x 版本也开始收费。后来 Sun公司收购了 MySQL,而 Sun 公司又被 Oracle 收购。

Oracle:收费的大型数据库,Oracle 公司的产品。

DB2 :IBM 公司的数据库产品,收费的。常应用在银行系统中。
SQL Server:MicroSoft 公司收费的中型的数据库。C#、.net 等语言常使用。

SQLite: 嵌入式的小型数据库,应用在手机端,如:Android。
数据库的安装与卸载
安装过程分成两个部分:
- 文件解压和复制过程,默认的安装目录:
- 安装好以后必须对 MySQL 服务器进行配置
在 mysql 中管理员的名字。
下载地址:https://download.csdn.net/download/qq_45771939/21446730?spm=1001.2014.3001.5503
数据库的安装
-
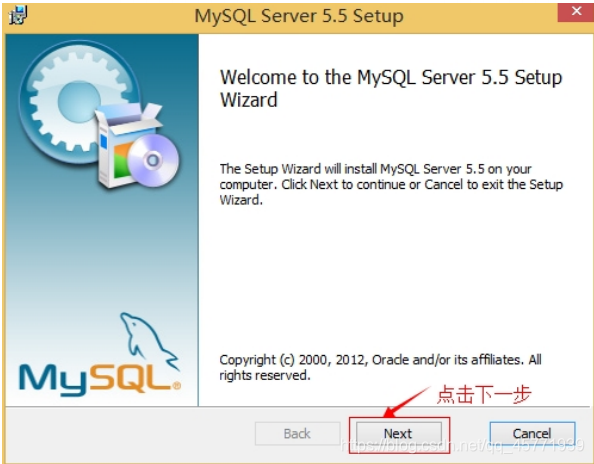
打开下载的 mysql 安装文件双击解压缩,运行“mysql-5.5.40-win64.msi”。
-
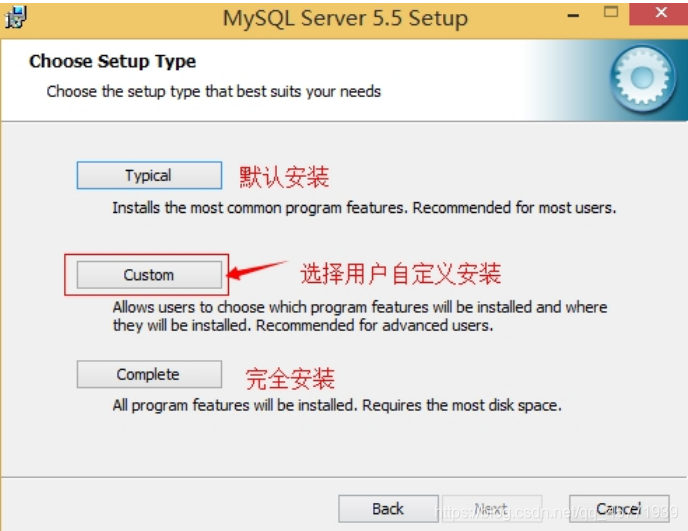
选择安装类型,有“Typical(默认)”、“Complete(完全)”、“Custom(用户自定义)”三个选项,选择“Custom”, 按“next”键继续。
-
点选“Browse”,手动指定安装目录。
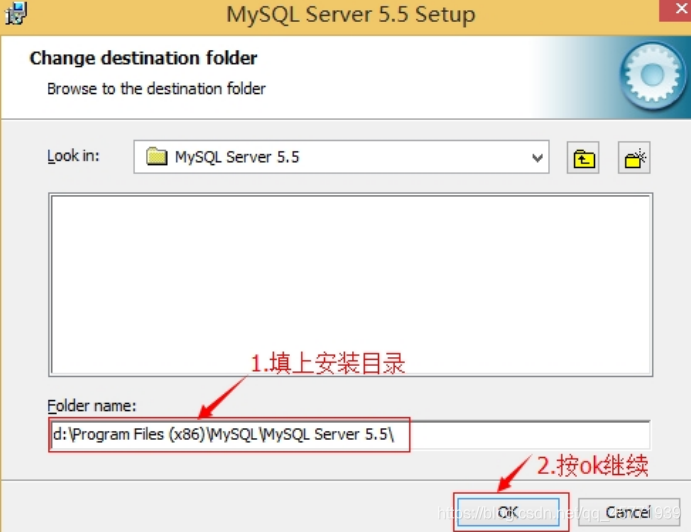
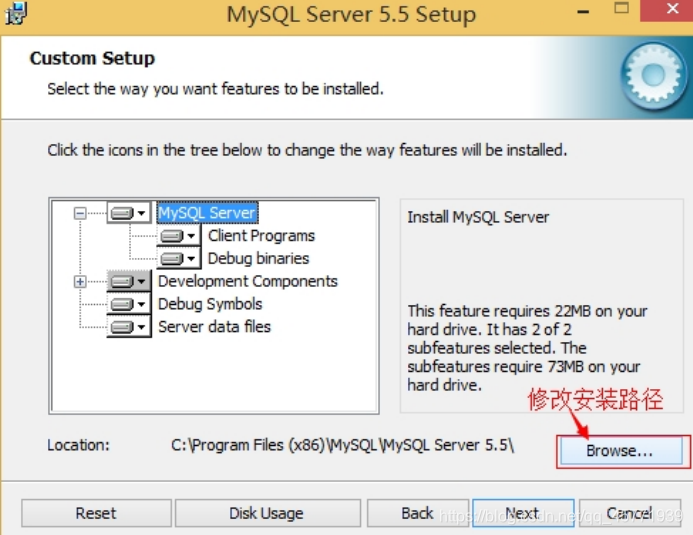 4. 填上安装目录,我的是“d:\Program Files (x86)\MySQL\MySQL Server 5.0”,按“OK”继续。
4. 填上安装目录,我的是“d:\Program Files (x86)\MySQL\MySQL Server 5.0”,按“OK”继续。
-
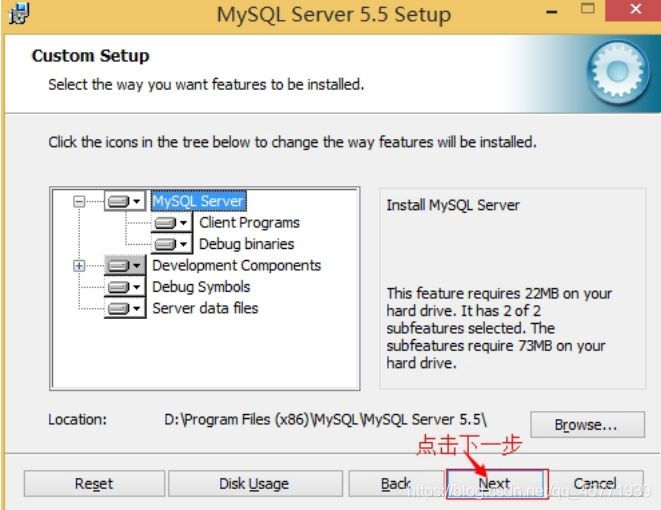
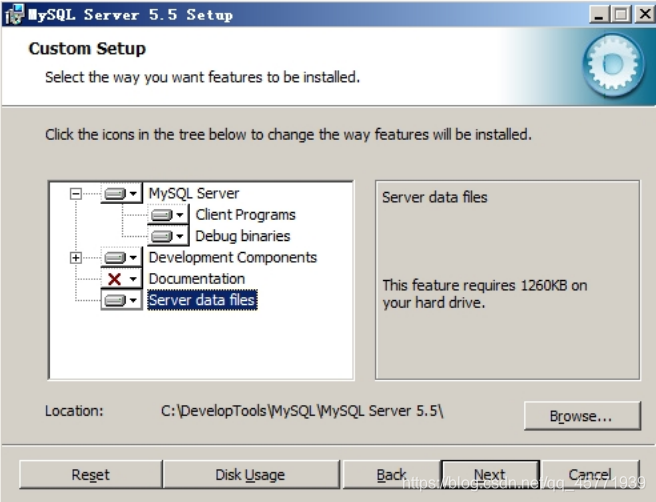
确认一下先前的设置,如果有误,按“Back”返回重做。按“Install”开始安装。
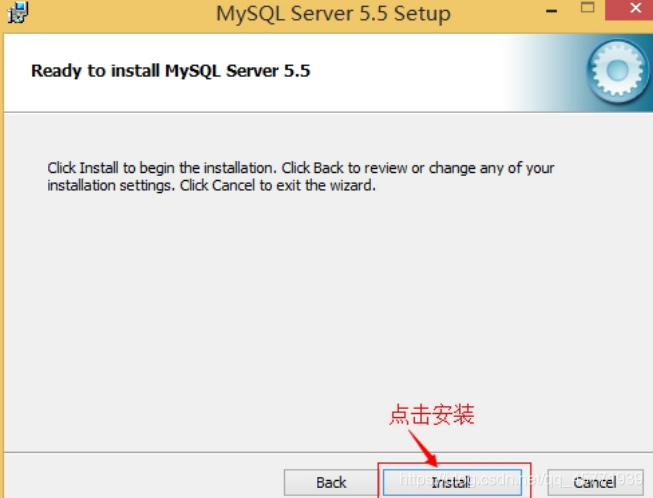

-
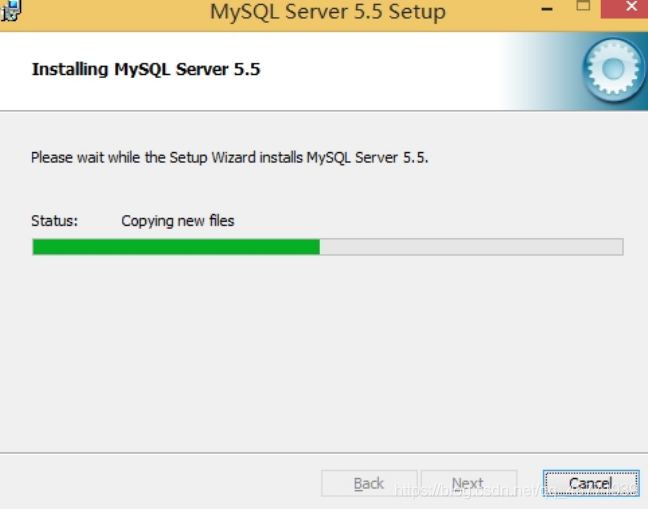
正在安装中,请稍候,直到出现下面的界面, 则完成 MYSQL 的安装。
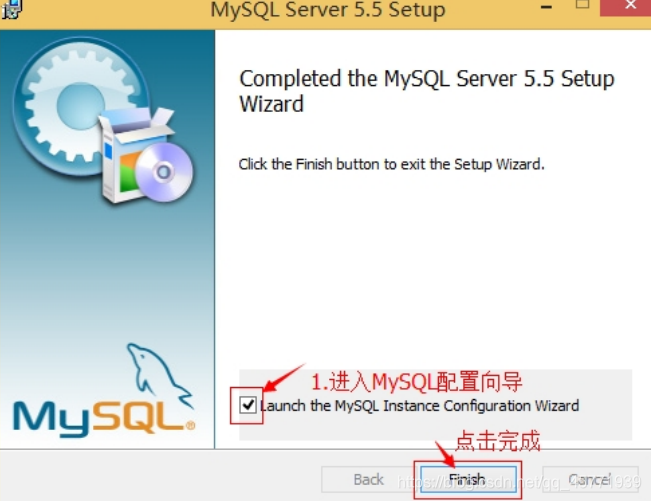
数据库安装好了还需要对数据库进行配置才能使用 MYSQL 的配置。 -
安装完成了,出现如下界面将进入 mysql 配置向导。
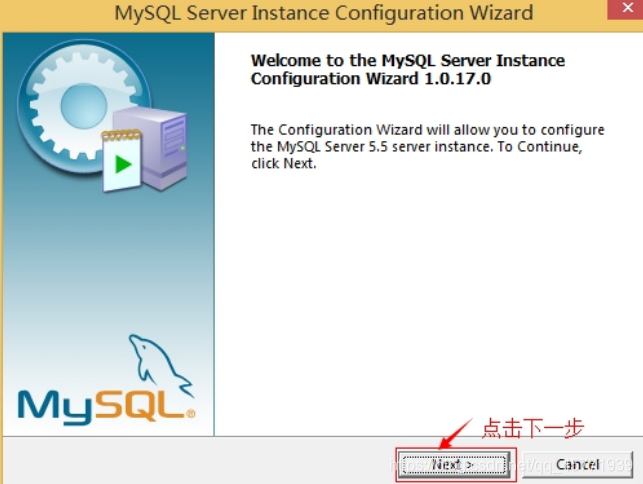
-
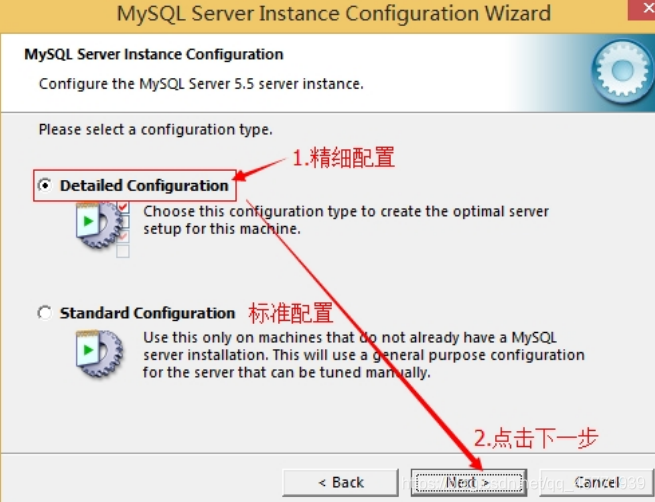
选择配置方式,“Detailed Configuration(手动精确配置)”、“Standard Configuration(标准配置)”,我们选择“Detailed Configuration”,方便熟悉配置过程。
8. 选择服务器类型,“Developer Machine(开发测试类,mysql 占用很少资源)”、“Server Machine(服务器类型,mysql 占用较多资源)”、“Dedicated MySQL Server Machine(专门的数据库服务器,mysql 占用所有可用资源)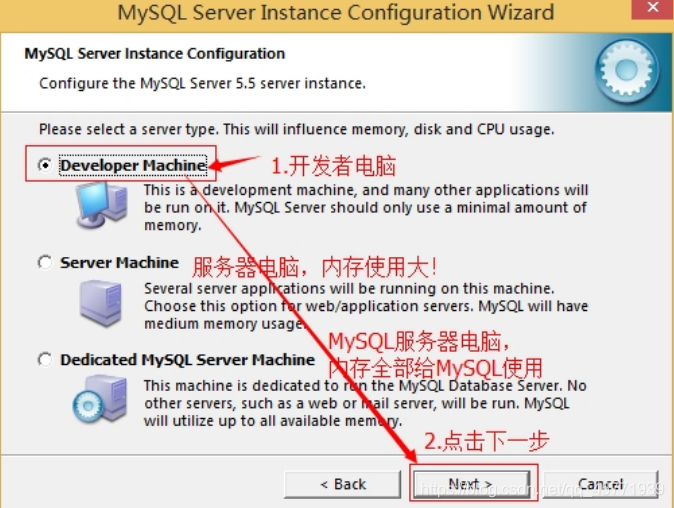
9. 选择mysql数据库的大致用途,“Multifunctional Database(通用多功能型,好)”、“Transactional Database Only(服务器类型,专注于事务处理,一般)”、“Non-Transactional Database Only(非事务处理型,较简单,主要做一些监控、记数用,对 MyISAM 数据类型的支持仅限于 non-transactional),按“Next”继续。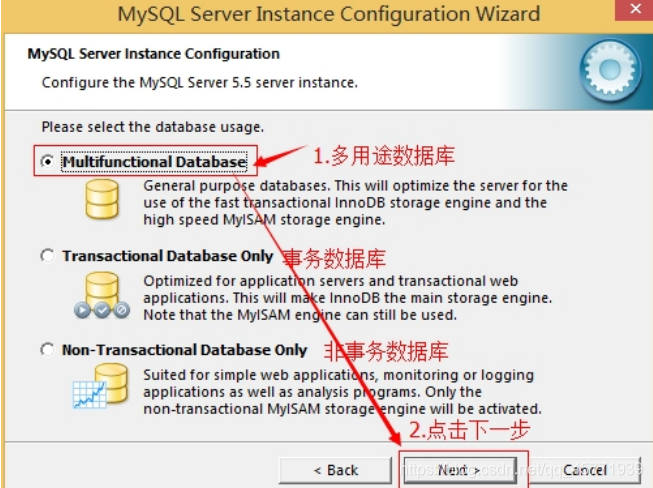
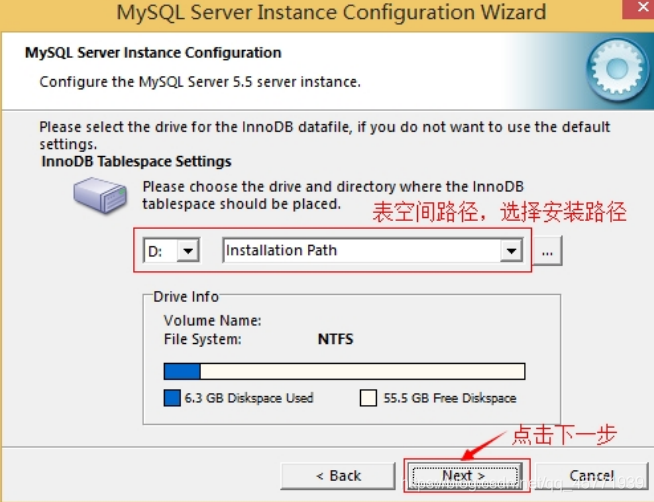 11. 选择网站并发连接数,同时连接的数目Decision Supportt(DSS)/OLAP(20个左右)”、“Online Transaction
11. 选择网站并发连接数,同时连接的数目Decision Supportt(DSS)/OLAP(20个左右)”、“Online Transaction
Processing(OLTP)(500 个左右)”、“Manual Setting(手动设置,自己输一个数)”。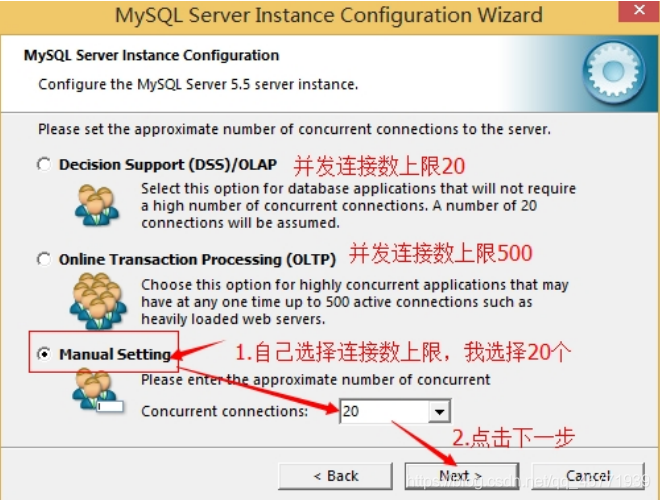
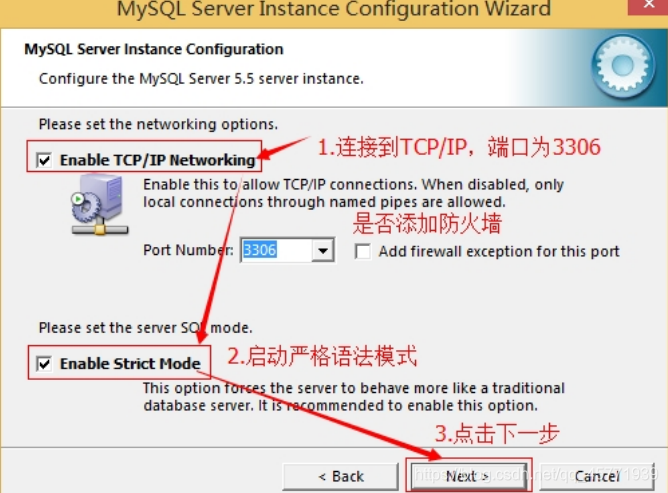
- 是否启用 TCP/IP 连接,设定端口,如果不启用,就只能在自己的机器上访问 mysql 数据库了,在这个页面上,您还可以选择“启用标准模式”(Enable Strict Mode),这样 MySQL 就不会允许细小的语法错误。如果是新手,建议您取消标准模式以减少麻烦。但熟悉 MySQL 以后,尽量使用标准模式,因为它可以降低有害数据进入数据库的可能性。按“Next”继续。
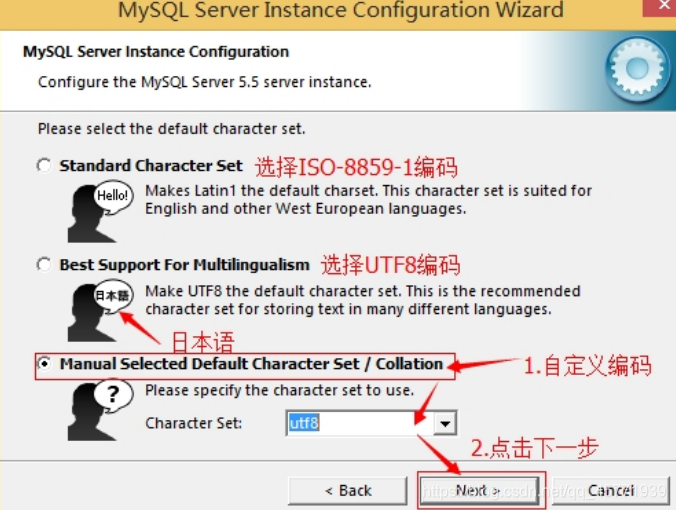
- 就是对 mysql 默认数据库语言编码进行设置(重要),一般选 UTF-8,按 “Next”继续。
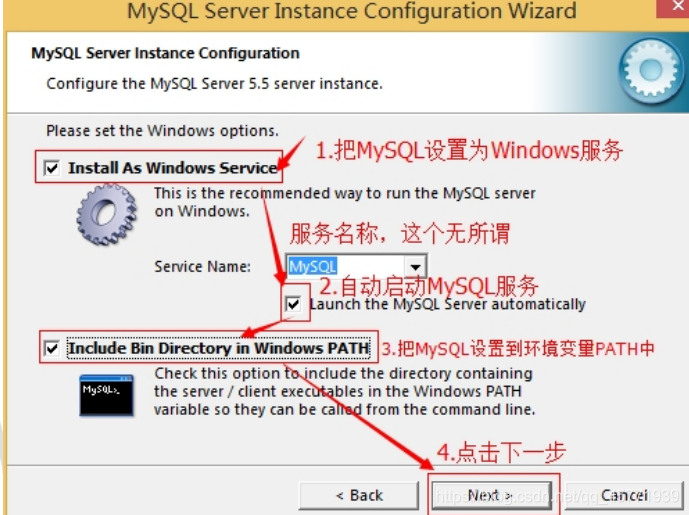
- 选择是否将 mysql 安装为 windows 服务,还可以指定 Service Name(服务标识名称),是否将 mysql 的 bin目录加入到 Windows PATH(加入后,就可以直接使用 bin 下的文件,而不用指出目录名,比如连接,“mysql.exe -uusername -ppassword;”就可以了,不用指出 mysql.exe 的完整地址,很方便),我这里全部打上了勾,Service Name 不变。按“Next”继续。
- 询问是否要修改默认 root 用户(超级管理)的密码。“Enable root access from remote machines(是否允许 root 用户在其它的机器上登陆,如果要安全,就不要勾上,如果要方便,就勾上它)”。最后“CreateAn Anonymous Account(新建一个匿名用户,匿名用户可以连接数据库,不能操作数据,包括查询)”,一般就不用勾了,设置完毕,按“Next”继续。
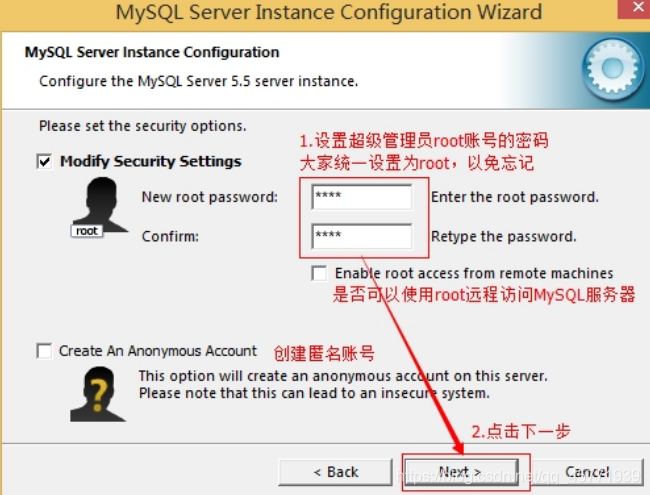
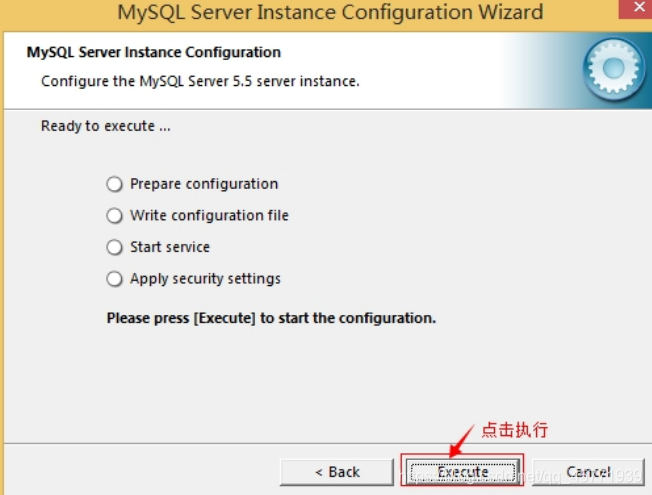
- 确认设置无误,按“Execute”使设置生效,即完成 MYSQL 的安装和配置。
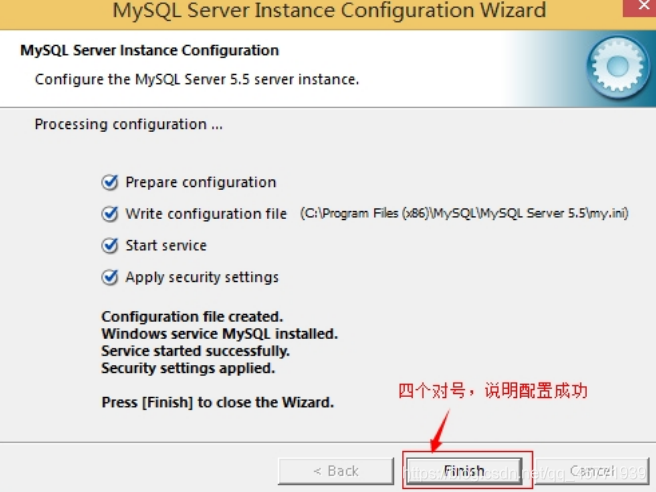
注意:设置完毕,按“Finish”后有一个比较常见的错误,就是不能“Start service”,一般出现在以前有安装 mysql的服务器上,解决的办法,先保证以前安装的 mysql 服务器彻底卸载掉了;不行的话,检查是否按上面一步所说,之前的密码是否有修改,照上面的操作;如果依然不行,将 mysql 安装目录下的 data 文件夹备份,然后删除,在安装完成后,将安装生成的 data 文件夹删除,备份的 data 文件夹移回来,再重启 mysql 服务就可以了,这种情况下,可能需要将数据库检查一下,然后修复一次,防止数据出错。
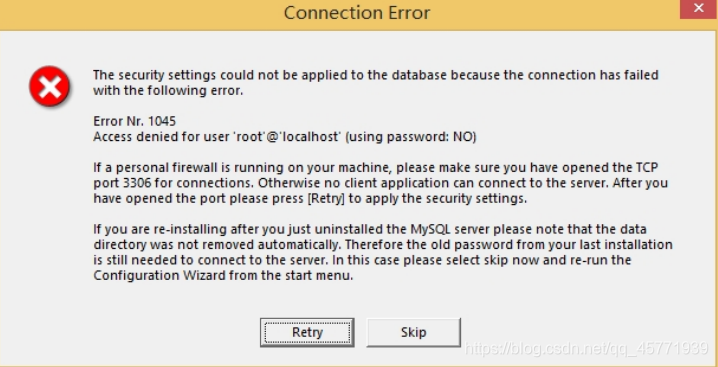
数据库的卸载
- 停止 window 的 MySQL 服务。 找到“此电脑”-> “管理”-> “服务”,停止 MySQL 后台服务。
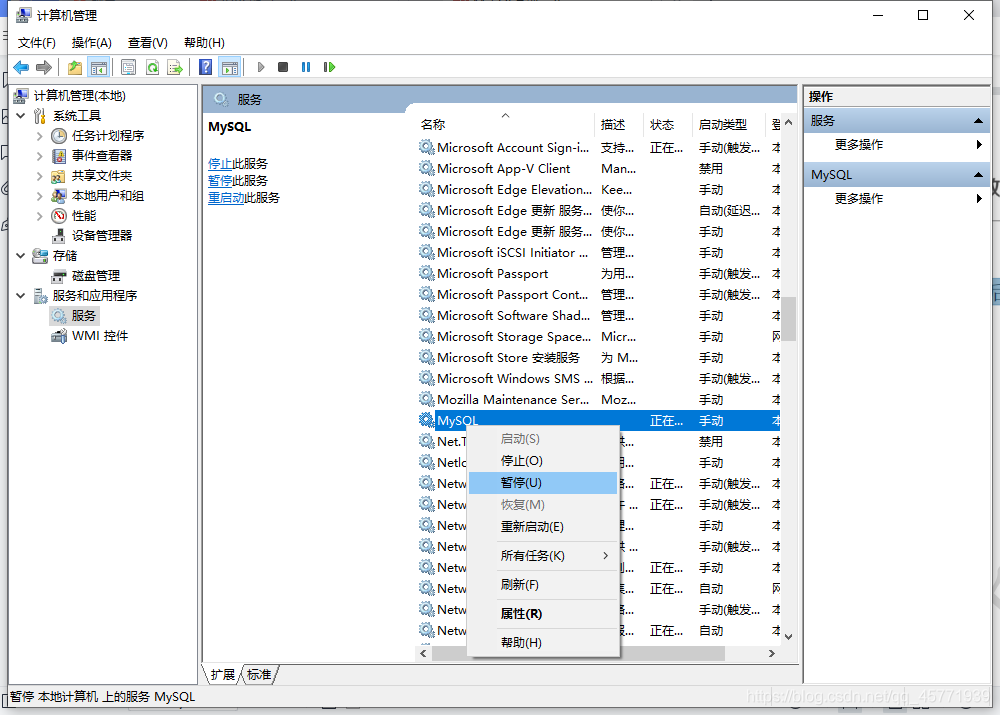
- 卸载 MySQL 安装程序。找到“控制面板”-> “程序和功能”,卸载 MySQL 程序。
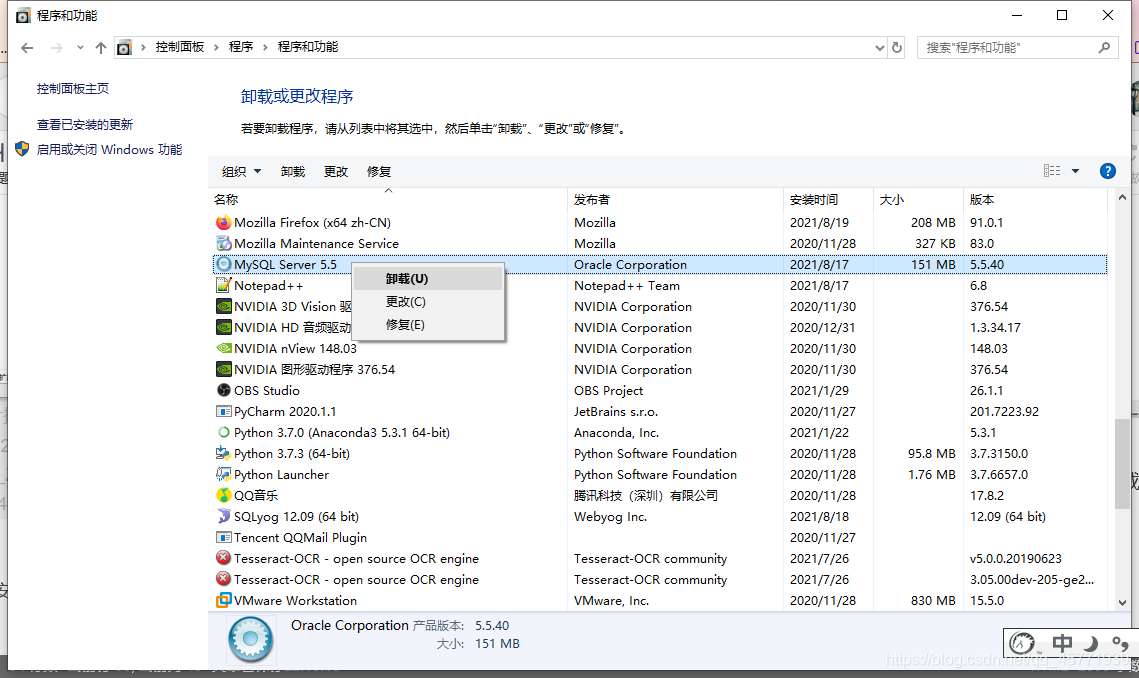
- 删除 MySQL 安装目录下的所有文件。
-
- 删除 c 盘 ProgramDate 目录中关于 MySQL 的目录。路径为:C:\ProgramData\MySQL(是隐藏文件,需要显示
出来)。
- 删除 c 盘 ProgramDate 目录中关于 MySQL 的目录。路径为:C:\ProgramData\MySQL(是隐藏文件,需要显示
数据库服务的启动与登录
MySQL 服务器启动方式有两种:
- 通过服务的方式自动启动
- 手动启动的方式
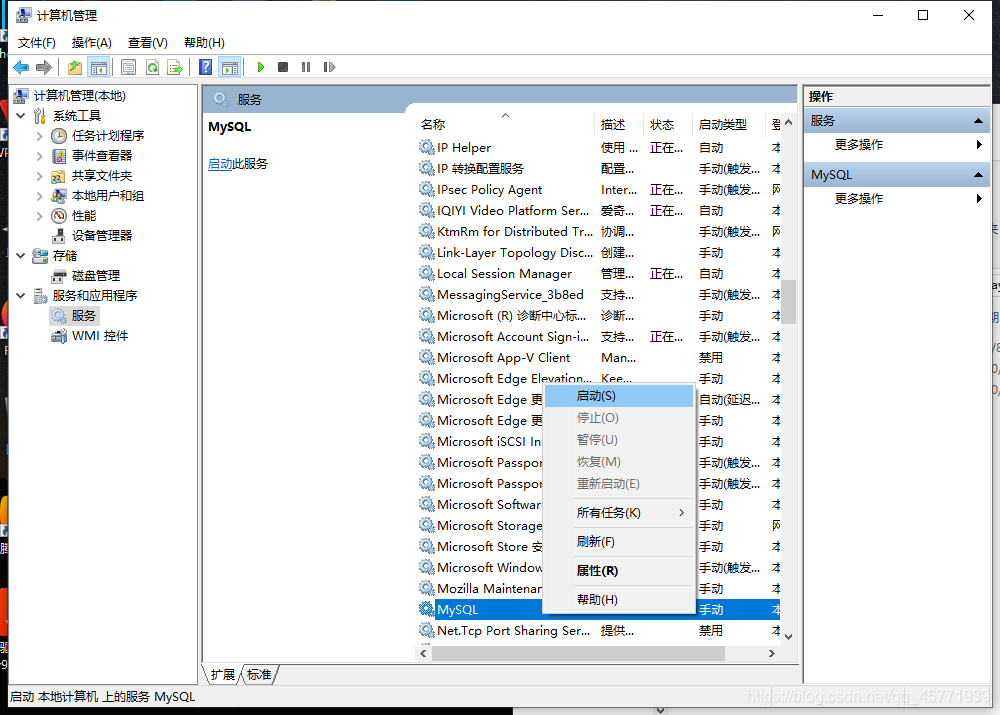
Windows 服务方式启动
找到“此电脑”-> “管理”-> “服务”,点击启动。
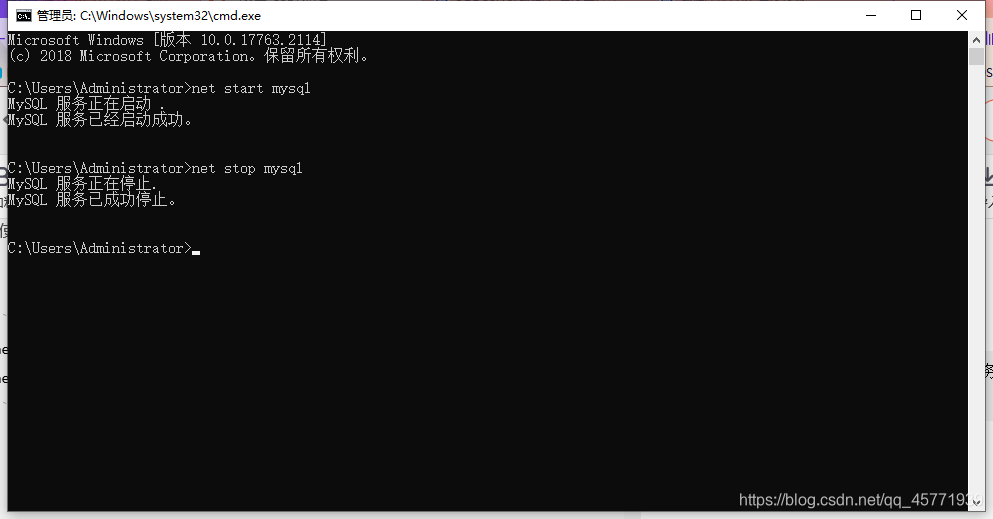
DOS 命令方式启动
使用管理员打开cmd
net start mysql : 启动mysql的服务
net stop mysql:关闭mysql服务
- 1
- 2
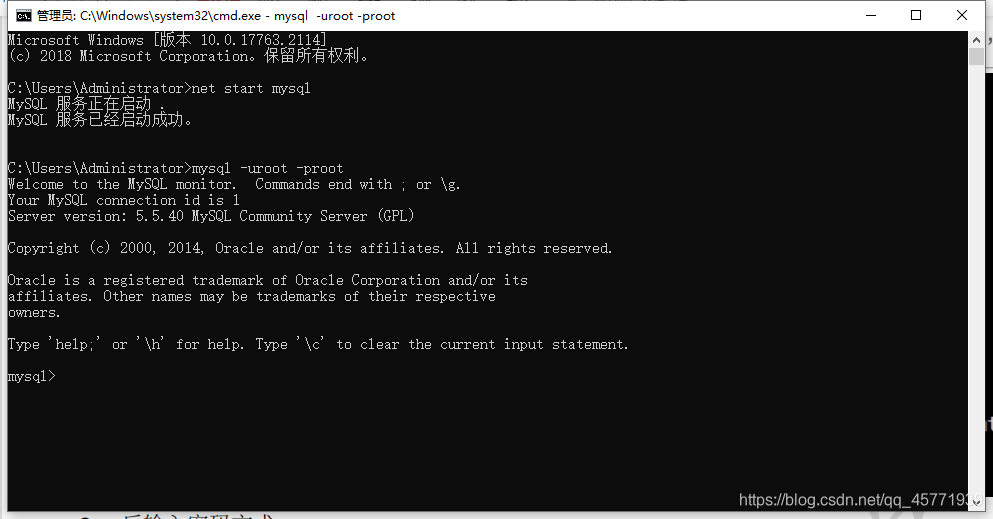
控制台连接数据库
MySQL 是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的 root 账号,使用安装时设置的密码即可登录
4.3.1 登录格式
// 方式一
mysql -u 用户名 -p 密码
// 方式二
mysql -hip 地址 -u 用户名 -p 密码
// 方式三
mysql --host=ip 地址 --user=用户名 --password=密码
- 1
- 2
- 3
- 4
- 5
- 6
退出 MySQL:
quit 或 exit
- 1
SQLyog 图形化工具——客户端
SQLyog 是业界著名的 Webyog 公司出品的一款简洁高效、功能强大的图形化 MySQL 数据库管理工具。使用SQLyog 可以快速直观地让您从世界的任何角落通过网络来维护远端的 MySQL 数据库。

使用 SQLyog 登录数据库
数据库管理系统
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据。
数据库管理系统、数据库和表的关系
数据库管理程序(DBMS)可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。为保存应用中实体的数据,一般会在数据库创建多个表,以保存程序中实体 User 的数据。
数据库管理系统、数据库和表的关系如图所示: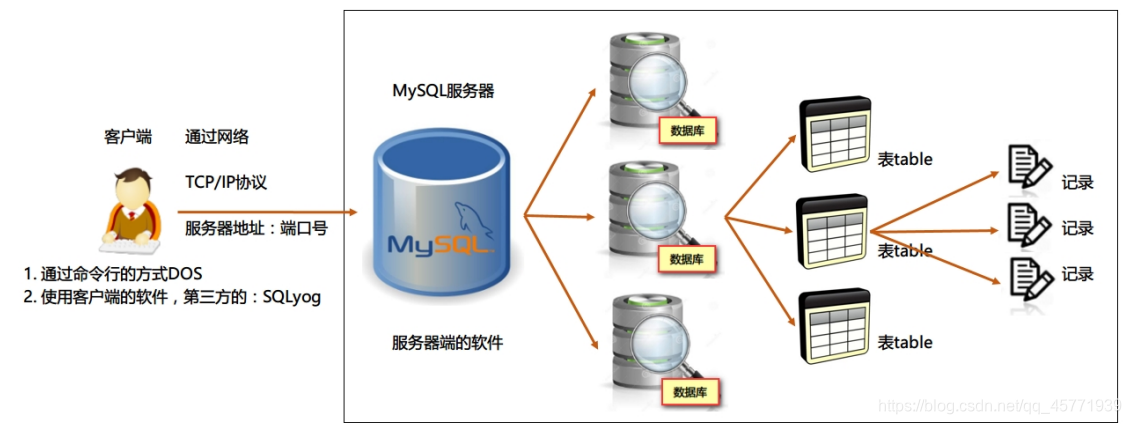
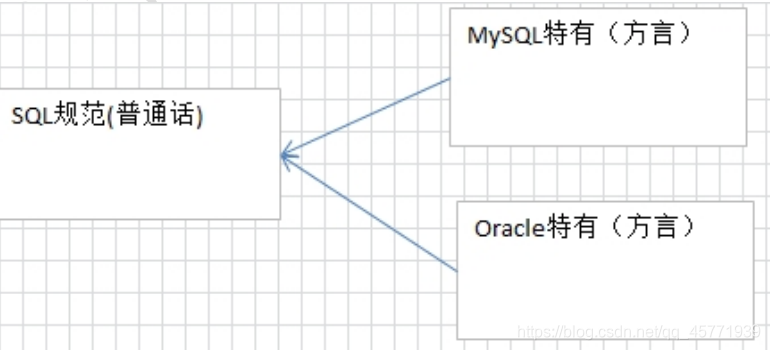
SQL 的概念
什么是 SQL
Structured Query Language 结构化查询语言
SQL 作用
1、是一种所有关系型数据库的查询规范,不同的数据库都支持。
2、 通用的数据库操作语言,可以用在不同的数据库中。
3、不同的数据库 SQL 语句有一些区别
SQL 语句分类
1、Data Definition Language (DDL 数据定义语言) 如:建库,建表
2、Data Manipulation Language(DML 数据操纵语言),如:对表中的记录操作增删改
3、Data Query Language(DQL 数据查询语言),如:对表中的查询操作
4、Data Control Language(DCL 数据控制语言),如:对用户权限的设置
MySQL 的语法
1、每条语句以分号结尾,如果在 SQLyog 中不是必须加的。
2、SQL 中不区分大小写,关键字中认为大写和小写是一样的
3、3 种注释:
| 注释的语法 | 说明 |
|---|---|
| –空格 | 单行注释 |
| /* */ | 多行注释 |
| # | 这是 mysql 特有的注释方式 |
DDL 操作数据库
创建数据库
创建数据库的几种方式
创建数据库
CREATE DATABASE 数据库名;
- 1
判断数据库是否已经存在,不存在则创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;
- 1
创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- 1
案例:
-- 直接创建数据库 db1
create database db1;
-- 判断是否存在,如果不存在则创建数据库 db2
create database if not exists db2;
-- 创建数据库并指定字符集为 gbk
create database db3 character set gbk;
- 1
- 2
- 3
- 4
- 5
- 6
查看数据库
查看所有的数据库
show databases;
- 1
查看某个数据库的定义信息
show create database db3;
show create database db1;
- 1
- 2
修改数据库
修改数据库默认的字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集;
- 1
将 db3 数据库的字符集改成 utf8
alter database db3 character set utf8;
- 1
删除数据库
删除数据库的语法
DROP DATABASE 数据库名;
- 1
使用数据库
查看正在使用的数据库
SELECT DATABASE(); --使用的一个 mysql 中的全局函数
- 1
使用/切换数据库
USE 数据库名;
- 1
DDL 操作表结构
创建表
创建表的格式
CREATE TABLE 表名 (
字段名 1 字段类型 1,
字段名 2 字段类型 2
);
- 1
- 2
- 3
- 4
关键字说明:
| 创建表的关键字 | 说明 |
|---|---|
| CREATE | 创建 |
| TABLE | 表 |
MySQL 数据类型
常使用的数据类型如下:
| 类型 | 描述 |
|---|---|
| int | 整型 |
| double | 浮点型 |
| varchar | 字符串型 |
| date | 日期类型 |
创建 student 表包含 id,name,birthday 字段
create table student (
id int, -- 整数
name varchar(20), -- 字符串
birthday date -- 生日,最后没有逗号
);
- 1
- 2
- 3
- 4
- 5
查看表
SHOW TABLES;
- 1
查看表结构
DESC 表名;
- 1
查看创建表的 SQL 语句
SHOW CREATE TABLE 表名;
- 1
查看 db1 数据库中的所有表
use db1;
show tables;
- 1
- 2
查看 student 的创建表 SQL 语句
show create table student;
- 1
快速创建一个表结构相同的表
语法
CREATE TABLE 新表名 LIKE 旧表名;
- 1
创建 s1 表,s1 表结构和 student 表结构相同
-- 创建一个 s1 的表与 student 结构相同
create table s1 like student;
desc s1;
- 1
- 2
- 3
删除表
直接删除表
DROP TABLE 表名;
- 1
判断表是否存在,如果存在则删除表
DROP TABLE IF EXISTS 表名;
- 1
案例:
-- 直接删除表 s1 表
drop table s1;
-- 判断表是否存在并删除 s1 表
drop table if exists `create`;
- 1
- 2
- 3
- 4
修改表结构
添加表列 ADD
ALTER TABLE 表名 ADD 列名 类型;
- 1
修改列类型 MODIFY
ALTER TABLE 表名 MODIFY 列名 新的类型;
- 1
修改列名 CHANGE
ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
- 1
删除列 DROP
ALTER TABLE 表名 DROP 列名;
- 1
修改表名
RENAME TABLE 表名 TO 新表名;
- 1
修改字符集 character set
ALTER TABLE 表名 character set 字符集;
- 1
DML 操作表中的数据
用于对表中的记录进行增删改操作
插入记录
INSERT [INTO] 表名 [字段名] VALUES (字段值)
- 1
插入全部字段:
所有的字段名都写出来
INSERT INTO 表名 (字段名 1, 字段名 2, 字段名 3…) VALUES (值 1, 值 2, 值 3);
- 1
不写字段名
INSERT INTO 表名 VALUES (值 1, 值 2, 值 3…);
- 1
插入部分数据
INSERT INTO 表名 (字段名 1, 字段名 2, ...) VALUES (值 1, 值 2, ...);
- 1
案例:
-- 插入所有的列,向学生表中
insert into student (id,name,age,sex) values (1, '孙悟空', 34, '男');
insert into student (id,name,age,sex) values (2, '孙悟饭', 16, '男');
- 1
- 2
- 3
insert 的注意事项:
- 插入的数据应与字段的数据类型相同
- 数据的大小应在列的规定范围内,例如:不能将一个长度为 80 的字符串加入到长度为 40 的列中。
- 在 values 中列出的数据位置必须与被加入的列的排列位置相对应。在 mysql 中可以使用 value,但不建议使
用,功能与 values 相同。 - 字符和日期型数据应包含在单引号中。MySQL 中也可以使用双引号做为分隔符。
- 不指定列或使用 null,表示插入空值。
蠕虫复制
什么是蠕虫复制
将一张已经存在的表中的数据复制到另一张表中。
语法格式
将表名 2 中的所有的列复制到表名 1 中
INSERT INTO 表名 1 SELECT * FROM 表名 2;
- 1
只复制部分列
INSERT INTO 表名 1(列 1, 列 2) SELECT 列 1, 列 2 FROM student;
- 1
更新表记录
语法格式:
UPDATE 表名 SET 列名=值 [WHERE 条件表达式]
- 1
不带条件修改数据
UPDATE 表名 SET 字段名=值; --修改所有的行
- 1
带条件修改数据
UPDATE 表名 SET 字段名=值 WHERE 字段名=值;
- 1
案例:
-- 不带条件修改数据,将所有的性别改成女
update student set sex = '女';
-- 带条件修改数据,将 id 号为 2 的学生性别改成男
update student set sex='男' where id=2;
-- 一次修改多个列,把 id 为 3 的学生,年龄改成 26 岁,address 改成北京
update student set age=26, address='北京' where id=3;
- 1
- 2
- 3
- 4
- 5
- 6
删除表记录
语法格式:
DELETE FROM 表名 [WHERE 条件表达式]
- 1
不带条件删除数据
DELETE FROM 表名;
- 1
带条件删除数据
带条件删除数据
- 1
使用 truncate 删除表中所有记录
TRUNCATE TABLE 表名;
- 1
truncate 和 delete 的区别:
truncate 相当于删除表的结构,再创建一张表。
案例:
-- 带条件删除数据,删除 id 为 1 的记录
delete from student where id=1;
-- 不带条件删除数据,删除表中的所有数据
delete from student;
- 1
- 2
- 3
- 4
DQL 查询表中的数据
查询不会对数据库中的数据进行修改.只是一种显示数据的方式。
语法:
SELECT 列名 FROM 表名 [WHERE 条件表达式]
- 1
简单查询
使用*表示所有列
SELECT * FROM 表名;
- 1
查询所有的学生:
select * from student;
- 1
查询指定列的数据,多个列之间以逗号分隔
SELECT 字段名 1, 字段名 2, 字段名 3, ... FROM 表名;
- 1
查询 student 表中的 name 和 age 列
select name,age from student;
- 1
指定列的别名进行查询
使用别名的好处: 显示的时候使用新的名字,并不修改表的结构。
语法:
1、对列指定别名
SELECT 字段名1 AS 别名, 字段名 2 AS 别名... FROM 表名;
- 1
2、对列和表同时指定别名
SELECT 字段名1 AS 别名, 字段名2 AS 别名... FROM 表名 AS 表别名;
- 1
案例:
-- 使用别名
select name as 姓名,age as 年龄 from student;
-- 表使用别名
select st.name as 姓名,age as 年龄 from student as st
- 1
- 2
- 3
- 4
清除重复值
查询指定列并且结果不出现重复数据
SELECT DISTINCT 字段名 FROM 表名;
- 1
案例:
-- 查询学生来至于哪些地方
select address from student;
-- 去掉重复的记录
select distinct address from student;
- 1
- 2
- 3
- 4
查询结果参与运算
某列数据和固定值运算:
SELECT 列名1 + 固定值 FROM 表名;
- 1
某列数据和其他列数据参与运算:
SELECT 列名1 + 列名2 FROM 表名;
- 1
案例:
--添加数学,英语成绩列,给每条记录添加对应的数学和英语成绩,查询的时候将数学和英语的成绩相加
select from student;
– 给所有的数学加 5 分
select math+5 from student;
– 查询 math + english 的和
select from student;
select ,(math+english) as 总成绩 from student;
– as 可以省略
select ,(math+english) 总成绩 from student;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
条件查询
为什么要条件查询:
如果没有查询条件,则每次查询所有的行。实际应用中,一般要指定查询的条件。对记录进行过滤。
条件查询的语法:
SELECT 字段名 FROM 表名 WHERE 条件;
--流程:取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回
- 1
- 2
运算符
| 比较运算符 | 说明 |
|---|---|
| >、<、<=、>=、=、<> | <>在 SQL 中表示不等于,在 mysql 中也可以使用!= 没有== |
| BETWEEN…AND | 在一个范围之内,如:between 100 and 200相当于条件在 100 到 200 之间,包头又包尾 |
| IN(集合) | 集合表示多个值,使用逗号分隔 |
| LIKE ’ %’ | 模糊查询 |
| IS NULL | 查询某一列为 NULL 的值,注:不能写=NULL |
案例:
- 创建表示表
- CREATE TABLE student3 (id int, -- 编号name varchar(20), -- 姓名age int, -- 年龄sex varchar(5), -- 性别address varchar(100), -- 地址math int, -- 数学english int -- 英语
);
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES
(1,'孙悟空',55,'男','杭州',66,78),
(2,'琪琪',55,'女','深圳',98,87),
(3,'孙悟饭',35,'男','香港',56,77),
(4,'布尔玛',30,'女','成都',76,65),
(5,'孙悟天',28,'男','北京',86,NULL),
(6,'弗利萨',572,'男','香港',85,97),
(7,'小芳',21,'女','香港',99,99),
(8,'贝吉塔',62,'男','郑州',56,65),
(9,'魔人布欧',432,'男','武汉',83,75),
(10,'贝比',12,'男','广州',95,63)
);
– 查询 math 分数大于 80 分的学生
select from student3 where math>80;
– 查询 english 分数小于或等于 80 分的学生
select from student3 where english <=80;
– 查询 age 等于 20 岁的学生
select from student3 where age = 20;
– 查询 age 不等于 20 岁的学生,注:不等于有两种写法
select from student3 where age <> 20;
select * from student3 where age != 20;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
逻辑运算符
| 逻辑运算符 | 说明 |
|---|---|
| and | 或 && 与,SQL 中建议使用前者,后者并不通用。 |
| or | 或|| |
| not | 或 ! 非 |
案例:
-- 查询 age 大于 35 且性别为男的学生(两个条件同时满足)
select * from student3 where age>35 and sex='男';
-- 查询 age 大于 35 或性别为男的学生(两个条件其中一个满足)
select * from student3 where age>35 or sex='男';
-- 查询 id 是 1 或 3 或 5 的学生
select * from student3 where id=1 or id=3 or id=5;
- 1
- 2
- 3
- 4
- 5
- 6
in 关键字
语法:
SELECT 字段名 FROM 表名 WHERE 字段 in (数据 1, 数据 2...);
- 1
案例:
-- 查询 id 是 1 或 3 或 5 的学生
select * from student3 where id in(1,3,5);
-- 查询 id 不是 1 或 3 或 5 的学生
select * from student3 where id not in(1,3,5);
- 1
- 2
- 3
- 4
范围查询
语法:
BETWEEN 值1 AND 值2
- 1
查询 english 成绩大于等于 75,且小于等于 90 的学生
select * from student3 where english between 75 and 90;
- 1
like 关键字
语法:
SELECT * FROM 表名 WHERE 字段名 LIKE '通配符字符串';
- 1
MySQL 通配符:
| 通配符 | 说明 |
|---|---|
| % | 匹配任意多个字符串 |
| _ | 匹配一个字符 |
-- 查询姓孙的学生
select * from student3 where name like '孙%';
select * from student3 where name like '孙';
-- 查询姓名中包含'布'字的学生
select * from student3 where name like '%布%';
-- 查询姓贝,且姓名有两个字的学生
select * from student3 where name like '贝_';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
MySQL 表的约束与数据库设计
DQL 查询语句
排序
通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名 [ASC|DESC];
ASC: 升序,默认值
DESC: 降序
- 1
- 2
- 3
- 4
单列排序:只按某一个字段进行排序。
-- 查询所有数据,使用年龄降序排序
select * from student order by age desc;
- 1
- 2
组合排序:同时对多个字段进行排序,如果第 1 个字段相等,则按第 2 个字段排序,依次类推。
组合排序语法:
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名 1 [ASC|DESC], 字段名 2 [ASC|DESC];
- 1
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩升序排序
select * from student order by age desc, math asc;
- 1
- 2
聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值 NULL。
五个聚合函数:
| SQL 中的聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值 |
| count(列名) | 统计这一列有多少条记录 |
| sum(列名) | 对这一列求总和 |
语法:
SELECT 聚合函数(列名) FROM 表名;
- 1
-- 查询学生总数
select count(id) as 总人数 from student;
select count(*) as 总人数 from student;
- 1
- 2
- 3
统计null:
-- 查询 id 字段,如果为 null,则使用 0 代替
select ifnull(id,0) from student;
select count(ifnull(id,0)) from student;
- 1
- 2
- 3
- 4
案例:
-- 查询年龄大于 20 的总数
select count(*) from student where age>20;
-- 查询数学成绩总分
select sum(math) 总分 from student;
-- 查询数学成绩平均分
select avg(math) 平均分 from student;
-- 查询数学成绩最高分
select max(math) 最高分 from student;
-- 查询数学成绩最低分
select min(math) 最低分 from student;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分组
分组查询是指使用 GROUP BY 语句对查询信息进行分组,相同数据作为一组
语法:
SELECT 字段 1,字段 2... FROM 表名 GROUP BY 分组字段 [HAVING 条件];
- 1
GROUP BY 将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
-- 按性别进行分组,求男生和女生数学的平均分
select sex, avg(math) from student3 group by sex;
- 1
- 2
使用having查询年龄大于 25 岁的人,按性别分组,统计每组的人数,并只显示性别人数大于 2 的数据:
-- 对分组查询的结果再进行过滤
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex having COUNT(*) >2;
- 1
- 2
| 子名 | 作用 |
|---|---|
| where 子句 | 1、对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤再分组。2、 where 后面不可以使用聚合函数 |
| having 子句 | 1、 having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2、 having 后面可以使用聚合函数 |
limit 语句
limit 的作用:
LIMIT 是限制的意思,所以 LIMIT 的作用就是限制查询记录的条数。
LIMIT 语法格式:
LIMIT offset,length
--offset:起始行数,从 0 开始计数,如果省略,默认就是 0
--length: 返回的行数
- 1
- 2
- 3
案例:
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES
(11,'唐僧',25,'男','长安',87,78),
(12,'孙悟空',18,'男','花果山',100,66),
(13,'猪八戒',22,'男','高老庄',58,78),
(14,'沙僧',50,'男','流沙河',77,88),
(15,'白骨精',22,'女','白虎岭',66,66),
(16,'蜘蛛精',23,'女','盘丝洞',88,88);
– 查询学生表中数据,从第 3 条开始显示,显示 6 条。
select * from student3 limit 2,6;
– 最后如果不够 5 条,有多少显示多少
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
数据库备份和还原
备份的应用场景
在服务器进行数据传输、数据存储和数据交换,就有可能产生数据故障。比如发生意外停机或存储介质损坏。这时,如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失,造成的损失是无法弥补与估量的。
备份与还原的语句
备份格式: DOS 下,未登录的时候。这是一个可执行文件 exe,在 bin 文件夹。
mysqldump -u 用户名 -p 密码 数据库 > 文件的路径
- 1
还原格式:mysql 中的命令,需要登录后才可以操作
USE 数据库;
SOURCE 导入文件的路径;
- 1
- 2
案例:
-- 备份 day21 数据库中的数据到 d:\a.sql 文件中
mysqldump -uroot -proot day21 > d://a.sql
–还原
use day21;
source d://a.sql;
- 1
- 2
- 3
- 4
- 5
- 6
图形化界面备份与还原
备份数据库中的数据
- 选中数据库,右键 ”备份/导出”
- 指定导出路径,保存成.sql 文件即可
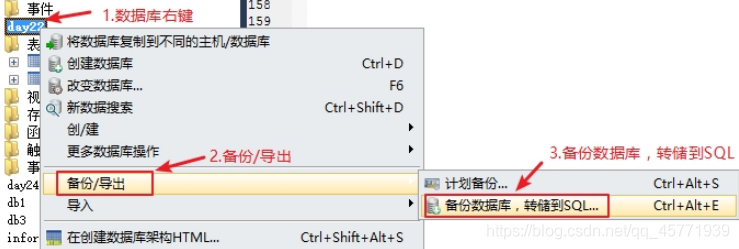
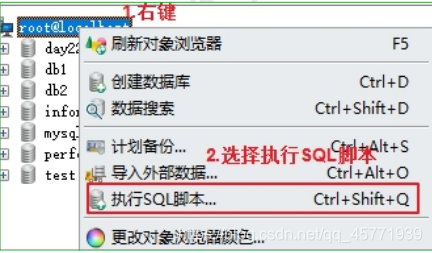
还原数据库中的数据
- 删除数据库
- 数据库列表区域右键“执行 SQL 脚本”, 指定要执行的 SQL 文件,执行即可
数据库表的约束
数据库约束的概述
约束的作用:
对表中的数据进行限制,保证数据的正确性、有效性和完整性。一个表如果添加了约束,不正确的数据将无法插入到表中。约束在创建表的时候添加比较合适。
约束种类:
| 约束名 | 约束关键字 |
|---|---|
| 主键 | primary key |
| 唯一 | unique |
| 非空 | not null |
| 外键 | foreign key |
| 检查约束 | check ( 注:mysql 不支持) |
主键约束
主键的作用:
用来唯一标识数据库中的每一条记录
哪个字段应该作为表的主键?
通常不用业务字段作为主键,单独给每张表设计一个 id 的字段,把 id 作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
创建主键:
主键关键字: primary key
主键的特点:
- 非空 not null
- 唯一
创建主键方式:
- 在创建表的时候给字段添加主键
字段名 字段类型 PRIMARY KEY
- 1
- 在已有表中添加主键
ALTER TABLE 表名 ADD PRIMARY KEY(字段名)
- 1
案例:
-- 创建表学生表 st5, 包含字段(id, name, age)将 id 做为主键
create table st5 (id int primary key, -- id 为主键name varchar(20),age int
)
desc st5;
-- 插入重复的主键值
insert into st5 values (1, '关羽', 30);
-- 错误代码: 1062 Duplicate entry '1' for key 'PRIMARY'
insert into st5 values (1, '关云长', 20);
select * from st5;
-- 插入 NULL 的主键值, Column 'id' cannot be null
insert into st5 values (null, '关云长', 20);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-- 删除 st5 表的主键
alter table st5 drop primary key;
-- 添加主键
alter table st5 add primary key(id);
- 1
- 2
- 3
- 4
主键自增:
主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值。
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
- 1
-- 插入数据
insert into st6 (name,age) values ('孙权',17);
insert into st6 (name,age) values ('孙策',25);
-- 另一种写法
insert into st6 values(null,'孙坚',36);
select * from st6;
- 1
- 2
- 3
- 4
- 5
- 6
修改自增长的默认值起始值
默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下列 SQL 语法
CREATE TABLE 表名(
列名 int primary key AUTO_INCREMENT
) AUTO_INCREMENT=起始值;
- 1
- 2
- 3
案例:
-- 指定起始值为 1000
create table st4 (id int primary key auto_increment,name varchar(20)
) auto_increment = 1000;
insert into st4 values (null, '孔明');
select * from st4;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
唯一约束
什么是唯一约束: 表中某一列不能出现重复的值。
唯一约束的基本格式:
字段名 字段类型 UNIQUE
- 1
案例:
-- 创建学生表 st7, 包含字段(id, name),name 这一列设置唯一约束,不能出现同名的学生
create table st7 (id int,name varchar(20) unique
)
-- 添加一个同名的学生
insert into st7 values (1, '张三');
select * from st7;
-- Duplicate entry '张三' for key 'name'
insert into st7 values (2, '张三');
-- 重复插入多个 null
insert into st7 values (2, null);
insert into st7 values (3, null);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
非空约束
什么是非空约束:某一列不能为 null。
非空约束的基本语法格式:
字段名 字段类型 NOT NULL
- 1
-- 创建表学生表 st8, 包含字段(id,name,gender)其中 name 不能为 NULL
create table st8 (
id int,
name varchar(20) not null,
gender char(1)
)
-- 添加一条记录其中姓名不赋值
insert into st8 values (1,'张三疯','男');
select * from st8;
-- Column 'name' cannot be null
insert into st8 values (2,null,'男');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
默认值
语法:
字段名 字段类型 DEFAULT 默认值
- 1
案例:
-- 创建一个学生表 st9,包含字段(id,name,address), 地址默认值是广州
create table st9 (id int,name varchar(20),address varchar(20) default '广州' )
-- 添加一条记录,使用默认地址
insert into st9 values (1, '李四', default);
select * from st9;
insert into st9 (id,name) values (2, '李白');
-- 添加一条记录,不使用默认地址
insert into st9 values (3, '李四光', '深圳');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
外键约束
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(30),
age INT,
dep_name VARCHAR(30),
dep_location VARCHAR(30)
);
-- 添加数据
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('张三', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('李四', 21, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('王五', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('老王', 20, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('大王', 22, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('小王', 18, '销售部', '深圳');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以上数据表的缺点:
- 数据冗余
- 后期还会出现增删改的问题
解决方案:
-- 解决方案:分成 2 张表
-- 创建部门表(id,dep_name,dep_location)
-- 一方,主表
create table department(
id int primary key auto_increment,
dep_name varchar(20),
dep_location varchar(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int -- 外键对应主表的主键
)
-- 添加 2 个部门
insert into department values(null, '研发部','广州'),(null, '销售部', '深圳');
select * from department;
-- 添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
select * from employee;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
问题:当我们在 employee 的 dep_id
里面输入不存在的部门,数据依然可以添加.但是并没有对应的部门,实际应用中不能出现这种情况。employee 的 dep_id 中的数据只能是
department 表中存在的 id目标: 需要约束 dep_id 只能是 department 表中已经存在 id
解决方式: 使用外键约束
什么是外键约束:
什么是外键:在从表中与主表主键对应的那一列,如:员工表中的 dep_id
主表: 一方,用来约束别人的表
从表: 多方,被别人约束的表
创建约束的语法:
1、新建表时增加外键:
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
- 1
2、已有表增加外键:
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主键字段名);
- 1
案例:
-- 1) 删除副表/从表 employee
drop table employee;
-- 2) 创建从表 employee 并添加外键约束 emp_depid_fk
-- 多方,从表
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int, -- 外键对应主表的主键
-- 创建外键约束
constraint emp_depid_fk foreign key (dep_id) references department(id)
)
-- 3) 正常添加数据
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
select * from employee;
-- 4) 部门错误的数据添加失败
-- 插入不存在的部门
-- Cannot add or update a child row: a foreign key constraint fails
INSERT INTO employee (NAME, age, dep_id) VALUES ('老张', 18, 6);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
删除外键:
语法:
ALTER TABLE 从表 drop foreign key 外键名称;
- 1
案例:
-- 删除 employee 表的 emp_depid_fk 外键
alter table employee drop foreign key emp_depid_fk;
-- 在 employee 表情存在的情况下添加外键
alter table employee add constraint emp_depid_fk
foreign key (dep_id) references department(id);
- 1
- 2
- 3
- 4
- 5
外键的级联:
出现新的问题
select * from employee;
select * from department;
-- 要把部门表中的 id 值 2,改成 5,能不能直接更新呢?
-- Cannot delete or update a parent row: a foreign key constraint fails
update department set id=5 where id=2;
-- 要删除部门 id 等于 1 的部门, 能不能直接删除呢?
-- Cannot delete or update a parent row: a foreign key constraint fails
delete from department where id=1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
什么是级联操作:
在修改和删除主表的主键时,同时更新或删除副表的外键值,称为级联操作。
| 级联操作语法 | 描述 |
|---|---|
| ON UPDATE CASCADE | 级联更新,只能是创建表的时候创建级联关系。更新主表中的主键,从表中的外键列也自动同步更新 |
| ON DELETE CASCADE | 级联删除 |
-- 删除 employee 表,重新创建 employee 表,添加级联更新和级联删除
drop table employee;
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int, -- 外键对应主表的主键
-- 创建外键约束
constraint emp_depid_fk foreign key (dep_id) referencesdepartment(id) on update cascade on delete cascade
)
-- 再次添加数据到员工表和部门表
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
-- 删除部门表?能不能直接删除?
drop table department;
-- 把部门表中 id 等于 1 的部门改成 id 等于 10
update department set id=10 where id=1;
select * from employee;
select * from department;
-- 删除部门号是 2 的部门
delete from department where id=2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
数据约束小结:
| 约束名 | 关键字 | 说明 |
|---|---|---|
| 主键 | primary key | 1、唯一 2、非空 |
| 默认 | default | 如果一列没有值,使用默认值 |
| 非空 | not null | 这一列必须有值 |
| 唯一 | unique | 这一列不能有重复值 |
| 外键 | foreign key | 主表中主键列,在从表中外键列 |
表与表之间的关系
表关系的概念
现实生活中,实体与实体之间肯定是有关系的,比如:老公和老婆,部门和员工,老师和学生等。那么我们在设计表的时候,就应该体现出表与表之间的这种关系!
表与表之间的三种关系
- 一对多:最常用的关系 部门和员工
- 多对多:学生选课表 和 学生表, 一门课程可以有多个学生选择,一个学生选择多门课程
- 一对一:相对使用比较少。员工表 简历表, 公民表 护照表
一对多
一对多(1:n) 例如:班级和学生,部门和员工,客户和订单,分类和商品
一对多建表原则: 在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键.
多对多
多对多(m:n) 例如:老师和学生,学生和课程,用户和角色
多对多关系建表原则: 需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。
一对一
一对一(1:1) 在实际的开发中应用不多.因为一对一可以创建成一张表。
两种建表原则:
| 一对一的建表原则 | 说明 |
|---|---|
| 外键唯一 | 主表的主键和从表的外键(唯一),形成主外键关系,外键唯一 UNIQUE |
| 外键是主键 | 主表的主键和从表的主键,形成主外键关系 |
数据库设计
数据规范化
什么是范式:
好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则来优化数据的设计和存储,这些规则就称为范式。
三大范式:
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
1NF
概念:
数据库表的每一列都是不可分割的原子数据项,不能是集合、数组等非原子数据项。即表中的某个列有多个值时,必须拆分为不同的列。简而言之,第一范式每一列不可再拆分,称为原子性。
学生课程表:
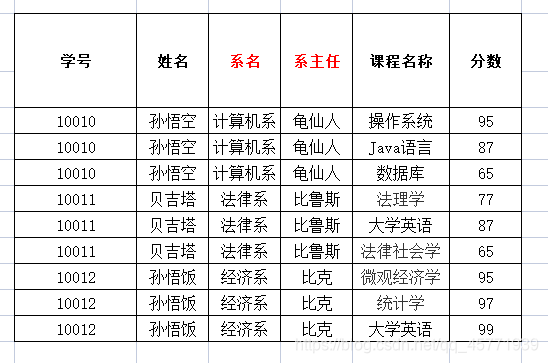
存在的问题:
1.存在非常严重的数据冗余(重复):姓名、系名、系主任
2.数据添加存在问题:添加新开设的系和系主任时,数据不合法
3.数据删除存在问题:张无忌同学毕业了,删除数据,会将系的数据一起删除。
2NF
概念:
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键。
所谓完全依赖是指不能存在仅依赖主键一部分的列。简而言之,第二范式就是在第一范式的基础上所有列完全依赖于主键列。当存在一个复合主键包含多个主键列的时候,才会发生不符合第二范式的情况。比如有一个主键有两个列,不能存在这样的属性,它只依赖于其中一个列,这就是不符合第二范式。
第二范式的特点:
- 一张表只描述一件事情。
- 表中的每一列都完全依赖于主键
学生课程表:
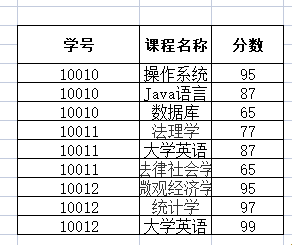
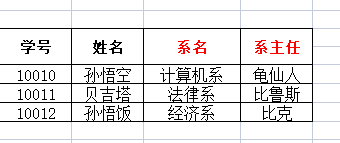
存在的问题:
1.(已经被解决)
2.数据添加存在问题:添加新开设的系和系主任时,数据不合法
3.数据删除存在问题:张无忌同学毕业了,删除数据,会将系的数据一起删除。
3NF
概念:
在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键。
简而言之,第三范式就是所有列不依赖于其它非主键列,也就是在满足 2NF 的基础上,任何非主列不得传递依赖于主键。所谓传递依赖,指的是如果存在"A → B → C"的决定关系,则 C 传递依赖于 A。因此,满足第三范
式的数据库表应该不存在如下依赖关系:主键列 → 非主键列 x → 非主键列 y
学生信息表:
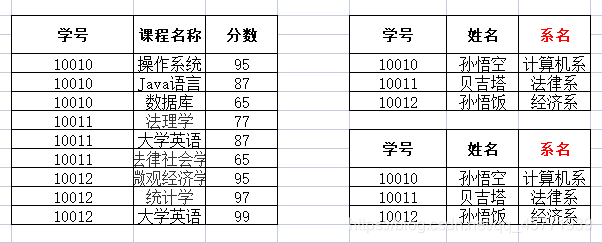
三大范式小结
| 范式 | 特点 |
|---|---|
| 1NF | 原子性:表中每列不可再拆分。 |
| 2NF | 不产生局部依赖,一张表只描述一件事情 |
| 3NF | 不产生传递依赖,表中每一列都直接依赖于主键。而不是通过其它列间接依赖于主键。 |
MySQL 多表查询与事务的操作
表连接查询
什么是多表查询
# 创建部门表
create table dept(id int primary key auto_increment,name varchar(20)
)
insert into dept (name) values ('开发部'),('市场部'),('财务部');
# 创建员工表
create table emp (id int primary key auto_increment,name varchar(10),gender char(1), -- 性别salary double, -- 工资join_date date, -- 入职日期dept_id int,foreign key (dept_id) references dept(id) -- 外键,关联部门表(部门表的主键) )
insert into emp(name,gender,salary,join_date,dept_id) values('孙悟空','男
',7200,'2013-02-24',1);
insert into emp(name,gender,salary,join_date,dept_id) values('猪八戒','男
',3600,'2010-12-02',2);
insert into emp(name,gender,salary,join_date,dept_id) values('唐僧','男',9000,'2008-
08-08',2);
insert into emp(name,gender,salary,join_date,dept_id) values('白骨精','女
',5000,'2015-10-07',3);
insert into emp(name,gender,salary,join_date,dept_id) values('蜘蛛精','女
',4500,'2011-03-14',1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
多表查询的作用:
比如:我们想查询孙悟空的名字和他所在的部门的名字,则需要使用多表查询。
如果一条 SQL 语句查询多张表,因为查询结果在多张不同的表中。每张表取 1 列或多列。
笛卡尔积:
- 有两个集合A,B .取这两个集合的所有组成情况。
- 要完成多表查询,需要消除无用的数据
多表查询的分类:
内连接查询
- 隐式内连接:使用where条件消除无用数据
例子:
-- 查询所有员工信息和对应的部门信息
SELECT * FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
SELECT
t1.name, – 员工表的姓名
t1.gender,– 员工表的性别
t2.name – 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.</span>dept_id<span class="token punctuation"> = t2.</span>id<span class="token punctuation">;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 显式内连接:
语法: select 字段列表 from 表名1 [inner] join 表名2 on 条件
例如:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`;
- 1
- 2
- 内连接查询:
1. 从哪些表中查询数据
2. 条件是什么
3. 查询哪些字段
外链接查询
- 左外连接:
语法:
select 字段列表 from 表1 left [outer] join 表2 on 条件;
- 1
查询的是左表所有数据以及其交集部分。
例子:
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.`name` FROM emp t1 LEFT JOIN dept t2 ON t1.`dept_id` = t2.`id`;
- 1
- 2
- 右外连接:
语法:select 字段列表 from 表1 right [outer] join 表2 on 条件;
查询的是右表所有数据以及其交集部分。
例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id` = t2.`id`;
- 1
子查询
概念:查询中嵌套查询,称嵌套查询为子查询。
-- 查询工资最高的员工信息
-- 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
– 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.</span>salary<span class="token punctuation"> = 9000;
– 一条sql就完成这个操作。子查询
SELECT * FROM emp WHERE emp.</span>salary<span class="token punctuation"> = (SELECT MAX(salary) FROM emp);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
子查询不同情况
1. 子查询的结果是单行单列的:
子查询可以作为条件,使用运算符去判断。 运算符: > >= < <= =
-- 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
- 1
- 2
- 子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断
-- 查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部';
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
-- 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部');
- 1
- 2
- 3
- 4
- 5
- 子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询
-- 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-- 子查询
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp.`join_date` > '2011-11-11') t2
WHERE t1.id = t2.dept_id;
– 普通内连接
SELECT * FROM emp t1,dept t2 WHERE t1.</span>dept_id<span class="token punctuation"> = t2.</span>id<span class="token punctuation"> AND t1.</span>join_date<span class="token punctuation"> > ‘2011-11-11’
- 1
- 2
- 3
- 4
- 5
- 6
- 7
事务
事务的基本介绍
-
概念:
如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。 -
操作:
- 开启事务: start transaction;
2. 回滚:rollback;
3. 提交:commit;
- 例子:
CREATE TABLE account (id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(10),balance DOUBLE
);
-- 添加数据
INSERT INTO account (NAME, balance) VALUES ('zhangsan', 1000), ('lisi', 1000);
SELECT * FROM account;
UPDATE account SET balance = 1000;
– 张三给李四转账 500 元
– 0. 开启事务
START TRANSACTION;
– 1. 张三账户 -500
UPDATE account SET balance = balance - 500 WHERE NAME = ‘zhangsan’;
– 2. 李四账户 +500
– 出错了…
UPDATE account SET balance = balance + 500 WHERE NAME = ‘lisi’;
– 发现执行没有问题,提交事务
COMMIT;
– 发现出问题了,回滚事务
ROLLBACK;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
MySQL数据库中事务默认自动提交
事务提交的两种方式:
1、自动提交:
mysql就是自动提交的
一条DML(增删改)语句会自动提交一次事务。
2、手动提交:
Oracle 数据库默认是手动提交事务
需要先开启事务,再提交
修改事务的默认提交方式:
1、查看事务的默认提交方式:
SELECT @@autocommit; -- 1 代表自动提交 0 代表手动提交
- 1
2、 修改默认提交方式:
set @@autocommit = 0;
- 1
事务的四大特征
1. 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。2. 持久性:当事务提交或回滚后,数据库会持久化的保存数据。3. 隔离性:多个事务之间。相互独立。4. 一致性:事务操作前后,数据总量不变
- 1
- 2
- 3
- 4
事务的隔离级别
概念:多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题。
存在问题:
1. 脏读:一个事务,读取到另一个事务中没有提交的数据
2. 不可重复读(虚读):在同一个事务中,两次读取到的数据不一样。
3. 幻读:一个事务操作(DML)数据表中所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改。
隔离级别:
1. read uncommitted:读未提交
产生的问题:脏读、不可重复读、幻读
2. read committed:读已提交 (Oracle)
产生的问题:不可重复读、幻读
3. repeatable read:可重复读 (MySQL默认)
产生的问题:幻读
4. serializable:串行化
可以解决所有的问题
注意:隔离级别从小到大安全性越来越高,但是效率越来越低
数据库查询隔离级别:
select @@tx_isolation;
数据库设置隔离级别:
set global transaction isolation level 级别字符串;
案例:
set global transaction isolation level read uncommitted;
start transaction;
-- 转账操作
update account set balance = balance - 500 where id = 1;
update account set balance = balance + 500 where id = 2;
- 1
- 2
- 3
- 4
- 5
DCL
DBA:数据库管理员
DCL:管理用户,授权
管理用户
1.添加用户:
语法:
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
- 1
2.删除用户:
语法:
DROP USER '用户名'@'主机名';
- 1
3.修改用户密码:
UPDATE USER SET PASSWORD = PASSWORD('新密码') WHERE USER = '用户名';
UPDATE USER SET PASSWORD = PASSWORD('abc') WHERE USER = 'lisi';
SET PASSWORD FOR '用户名'@'主机名' = PASSWORD('新密码');
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('123');
- 1
- 2
- 3
- 4
mysql中忘记了root用户的密码?
1. cmd -- > net stop mysql 停止mysql服务* 需要管理员运行该cmd2. 使用无验证方式启动mysql服务: mysqld --skip-grant-tables3. 打开新的cmd窗口,直接输入mysql命令,敲回车。就可以登录成功4. use mysql;5. update user set password = password('你的新密码') where user = 'root';6. 关闭两个窗口7. 打开任务管理器,手动结束mysqld.exe 的进程8. 启动mysql服务9. 使用新密码登录。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
查询用户:
– 1. 切换到mysql数据库
USE myql;
– 2. 查询user表
SELECT * FROM USER;* 通配符: % 表示可以在任意主机使用用户登录数据库- 1
权限管理
1. 查询权限:
- 1
-- 查询权限SHOW GRANTS FOR '用户名'@'主机名';SHOW GRANTS FOR 'lisi'@'%';
- 1
- 2
- 3
2.授予权限:
-- 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
-- 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON *.* TO 'zhangsan'@'localhost';
- 1
- 2
- 3
- 4
- 5
3.撤销权限:
-- 撤销权限:
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
REVOKE UPDATE ON db3.`account` FROM 'lisi'@'%';
- 1
- 2
- 3



...)





浅介 (转载))
)







)
