
全文共3360字,预计学习时长9分钟

大多数数据科学在线课程都把Jupyter Notebook作为教学媒介,这是因为初学者在Jupyter Notebook的单元格中编写代码,比编写包含类和函数的脚本更容易。
另一个原因在于它使浏览和绘制数据变得容易。键入"Shift + Enter"时,你可以立即看到代码的结果,这使我们能够轻松地确定代码是否有效。
然而,当处理更多数据科学项目时,Jupyter Notebook也存在几个缺点:
· 缺乏条理性:随着代码变大,我们所编写的东西越来越难以跟踪。无论使用多少标记将Notebook分隔成不同的部分,断开连接的单元格都使用户难以专注于代码功能。
· 难以试验:你需要使用不同的数据处理方法进行测试,为机器学习算法选择不同的参数,查看准确性是否提高。但每次试验新方法时,都需要查找和重新运行相关单元格,这耗神耗时,尤其是处理或培训过程需要很长时间才能运行时。
· 可重复性低:如果你想要使用结构略有不同的新数据,识别其中的错误源很难。
· 难以调试:当你在代码中收到错误时,无法准确判断出错的原因,是代码还是数据更改?如果是代码出错,具体是哪个部分?
· 不适合生产:Jupyter Notebook与其他工具配合使用效果不佳。使用其他工具时,从Jupyter Notebook运行代码并不容易。

一定有更好的方法来处理代码,所以我决定尝试一下脚本。为了减少混淆,引用.py文件时,在本文中使用单词"脚本"。
组织
Jupyter Notebook中的单元格很难将代码组织成不同的部分。使用脚本可以创建几个小函数,每个函数指定代码的功能。
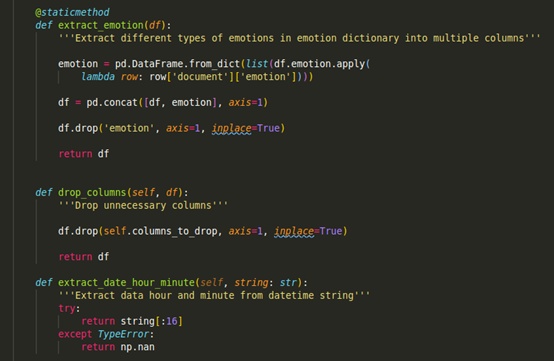
更妙的是,如果这些函数可以分类在同类别,如处理数据的函数时,可以将它们放在同一个类中。
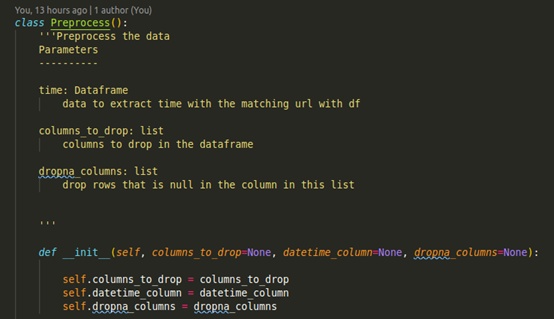
每当我们想要处理数据时,就可以利用类预处理中的函数。
鼓励实验
当我们想要尝试对预处理数据的不同方法时,只需添加或删除函数,这样注释不用害怕破坏代码。即使碰巧破坏了代码,也能确切地知道在哪里修复。
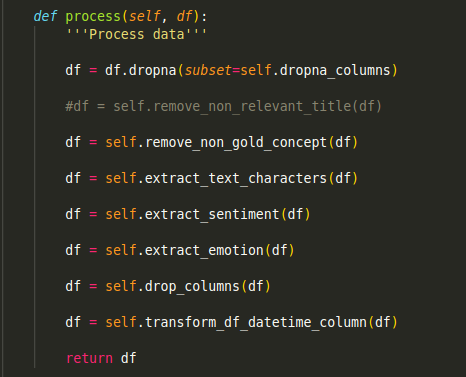
提高重复性
使用类和函数,可以使代码足够通用,以便能够和其他数据一起使用。例如,如果我们想在新数据中删除不同的列,只需将columns_to_drop更改为列的列表,若是删除,代码也将顺利运行。
columns_to_drop =config.columns.to_dropdatetime_column =config.columns.datetime.sentimentdropna_columns =config.columns.drop_naprocessor =Preprocess(columns_to_drop,datetime_column, dropna_columns)还可以创建一个管道来指定处理和训练数据的步骤。一旦拥有管道,我们所需要做的就是使用它对列车和测试数据应用相同的处理。
pipline.fit_transform(data)易于调试
使用函数可以更容易地测试该函数是否产生期望的输出,我们可以快速地指出代码中的哪些地方需要更改以生成想要的输出。
defextract_date_hour_minute(string: str):'''Extract datahour and minute from datetime string'''try:return string[:16]exceptTypeError: return np.nandeftest_extract_date_hour_minute(): '''Test whether the function extractdate, hour, and minute '''string ='2020-07-30T23:25:31.036+03:00'assertextract_date_hour_minute(string) =='2020-07-30T23:25'如果所有测试都通过了,但是在运行代码时仍然存在错误,那么我们就知道接下来应该查看这些数据。例如,在通过上面的测试后,在运行脚本时仍然有一个类型错误,这使数据中有空值。那就只需要处理这个问题,就可以平稳运行代码。
适于生产
在多个脚本中使用不同的函数:
from preprocess import preprocessfrom model import run_modelfrom predict import predictdefmain(config): df =preprocess(config) df =run_model(config) df, df_scale, min_day, max_day, accuracy =predict(df, config)或者添加配置文件来控制变量的值。这可以让我们不必浪费时间去跟踪代码中的特定变量来更改其值。
columns:to_drop:#- keywords #- entities - code - error - warnings binary_columns:- sentiment - Diff datetime:time: Datesentiment: crawleddrop_na:- sentiment - usage - crawled - emotion to_predict: sentiment你还可以轻松地添加工具来跟踪实验,比如MLFlow,或者添加工具来处理配置,比如http://Hydra.cc。

不喜欢Jupyter Notebook,直到迫使自己做出调整
我以前一直使用Jupyter Notebook。当一些数据科学家建议将Notebook笔记本换成脚本从而避免上述一些问题时,我不理解也不愿意这么做,因为我不喜欢运行单元格时无法看到这种不确定性。
但是,当我在新公司开始第一个真正的数据科学项目时,Jupyter Notebook的缺点越来越大,所以我决定踏出舒适区,用脚本进行实验。
起初,我很不习惯,但也注意到了使用脚本的好处。当代码被组织成不同的函数、类和等多个脚本(每个脚本都用于不同的目的,如预处理、培训和测试)时,我开始感到工作更有条理性。
我在建议读者不要用Jupyter Notebook?
并不是。如果代码比较小,且不打算将代码投入生产,仍然可以使用Jupyter Notebook。当想要分析、可视化数据时,也可以使用Jupyter Notebook。还可以用它来解释如何使用一些python库。例如,Khuyen Tran主要使用这个存储库中的Jupyter Notebook作为媒介来解释他所有文章中提到的代码。
如果你不习惯在脚本中编写所有内容,那么你可以将脚本和Jupyter Notebook用于不同的目的。例如,可以在脚本中创建类和函数,然后将它们导入到Notebook中,这样就不那么凌乱了。
另一种方法是在写完笔记本后把它变成脚本,但组织笔记本中的代码(比如把它们放到函数和类中以及编写测试函数)通常要花费更长的时间。你可以先写一个小的函数,再写一个小的测试函数,可以更快更安全。如果正好想用新的Python库加速代码,可以使用已经编写的测试函数来确保它如期望中那样工作。

除了本文中提到的方法,一定有更多的方法可以解决Jupyter Notebook的缺点。
每个人都有自己提高工作利率的方法。刚从Jupyter Notebook切换到脚本可能不太习惯,因为用脚本编写代码不太直观,但你最终会习惯的。你会开始意识到脚本在凌乱的Jupyter Notebook上有着许多好处,并且会希望用脚本编写大部分代码。
不积跬步无以至千里,从细微处开始改变自己吧。

留言点赞关注
我们一起分享AI学习与发展的干货
编译组:符馨元、何婧璇
相关链接:https://towardsdatascience.com/5-reasons-why-you-should-switch-from-jupyter-notebook-to-scripts-cb3535ba9c95
如转载,请私信小芯,遵守转载规范




)






 的一些了解)







