项目搭建
1、启动ES,和head-master,用head-master建立索引
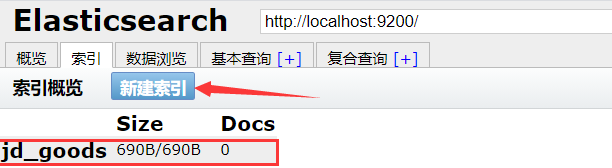
不建立也没事,添加数据的时候会自动创建
2、导入SpringBoot需要的依赖
注意:elasticsearch的版本要和自己本地的版本一致!所以还要在pom里面添加自定义版本

<!--解析网页需要的依赖Jsoup-->
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version>
</dependency>
<!--阿里的JSon转换依赖-->
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.73</version>
</dependency>
<!--ES启动依赖-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--thymeleaf模板依赖-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--lombok依赖-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
3、项目用到的静态资源(修改过的)
- 链接:https://pan.baidu.com/s/1X1kwMHsDvML-0rBEJnUOdA
- 提取码:qjqy
4、添加SpringBoot配置(application.yml)
#端口改为9090
server:port: 9090# 关闭 thymeleaf 的缓存
spring:thymeleaf:cache: false
5、项目的整体结构
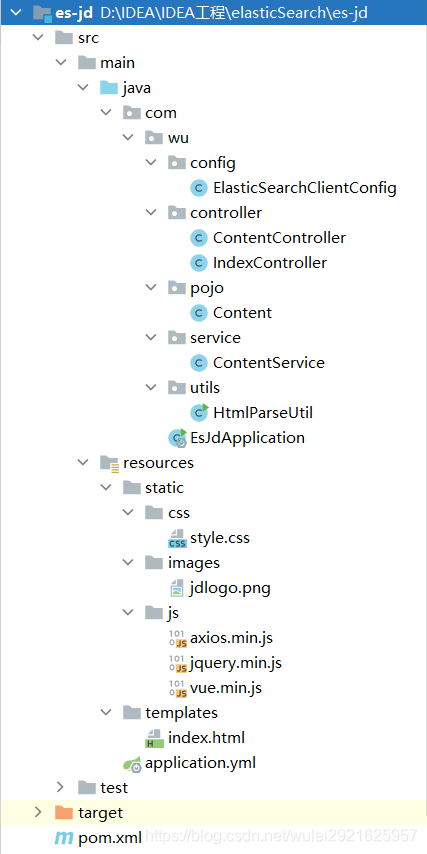
6、添加静态资源到项目中
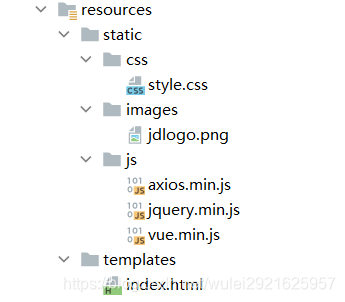
7、SpringBoot中添加ES客户端配置类
ElasticSearchClientConfig.java
package com.wu.config;@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient() {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));return client;}
}
Jsoup爬取京东数据
爬取数据
1、进入京东官网搜索java
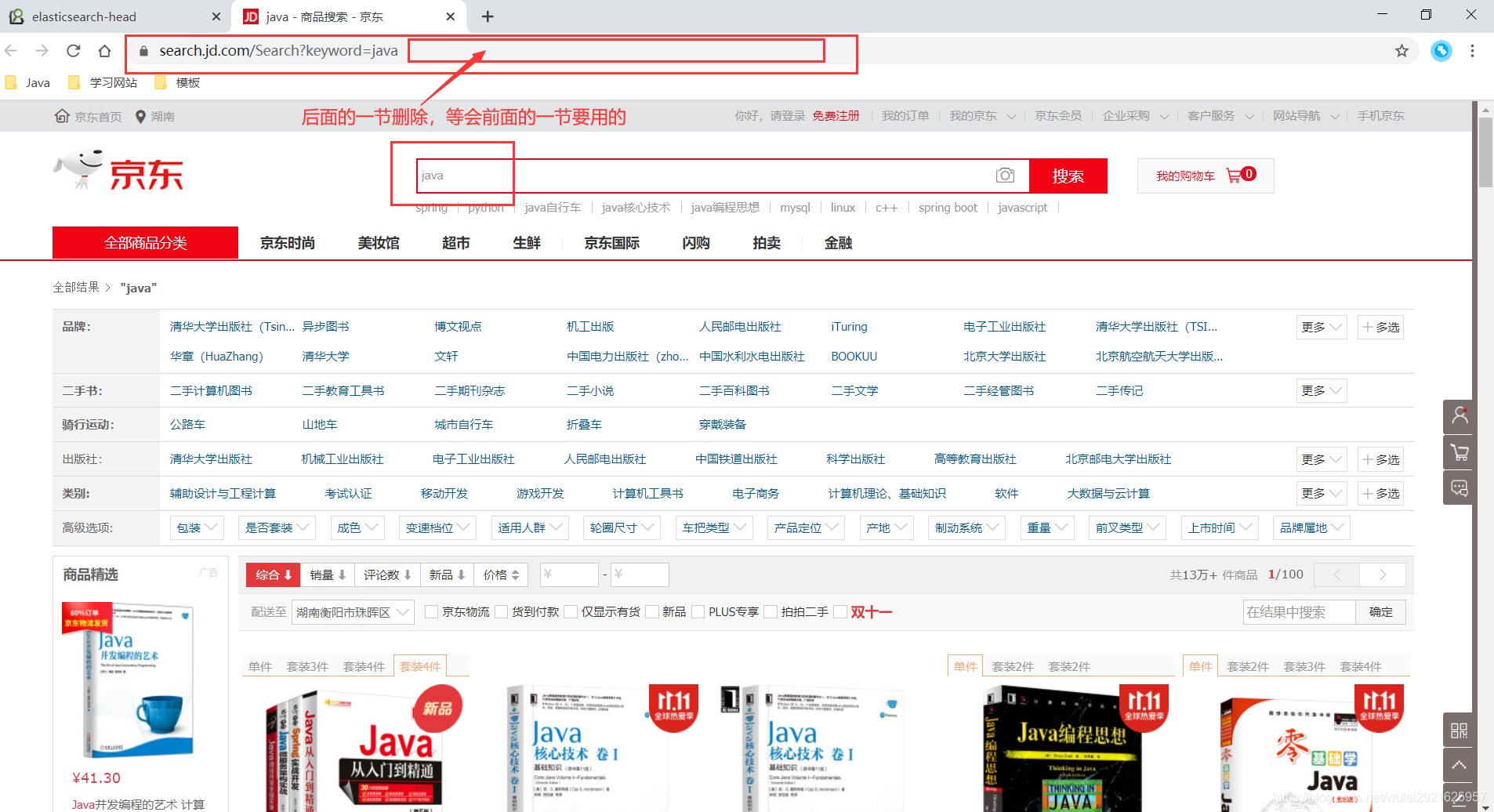
2、按F12审查元素,找到书籍所在位置
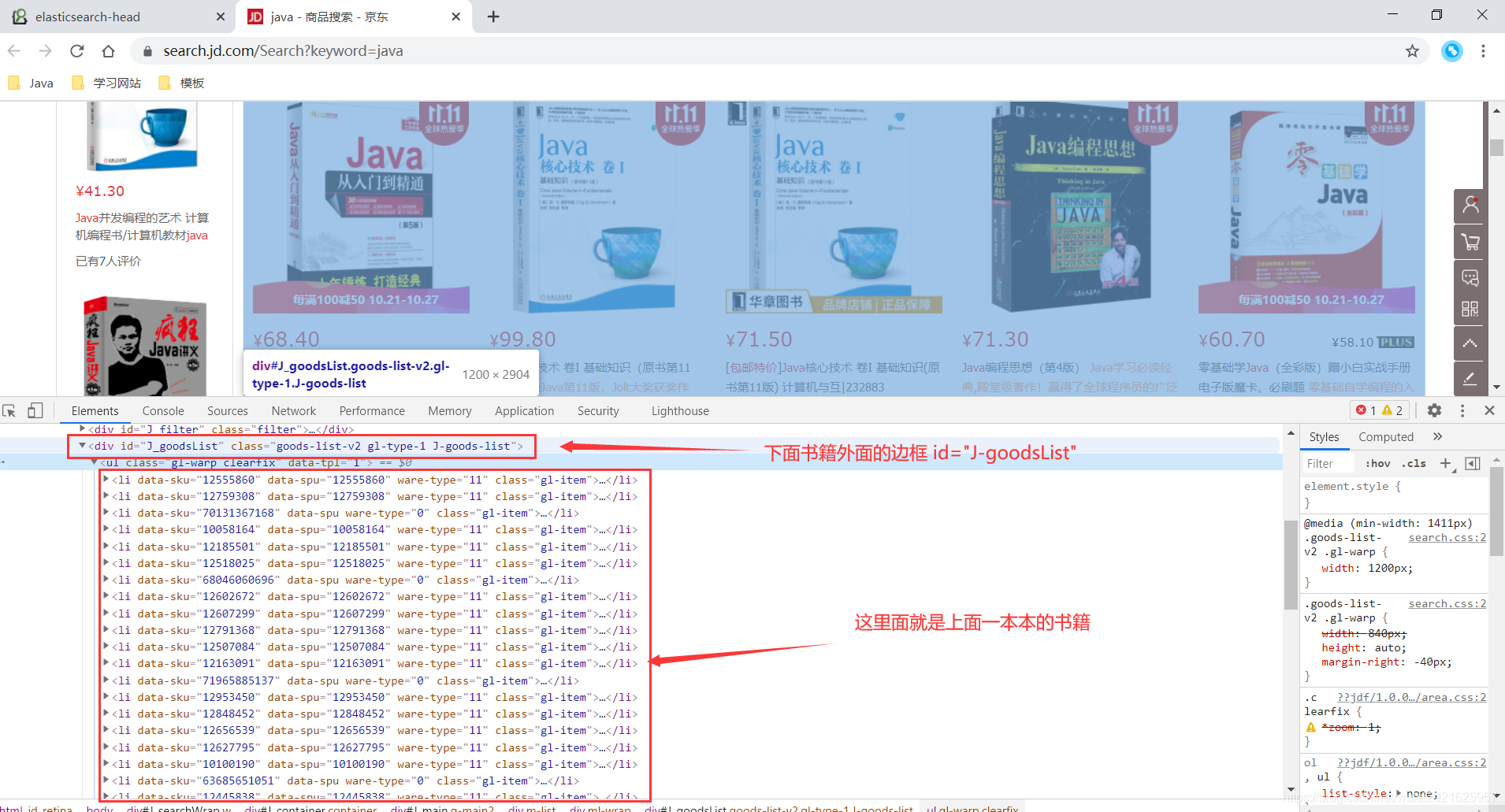
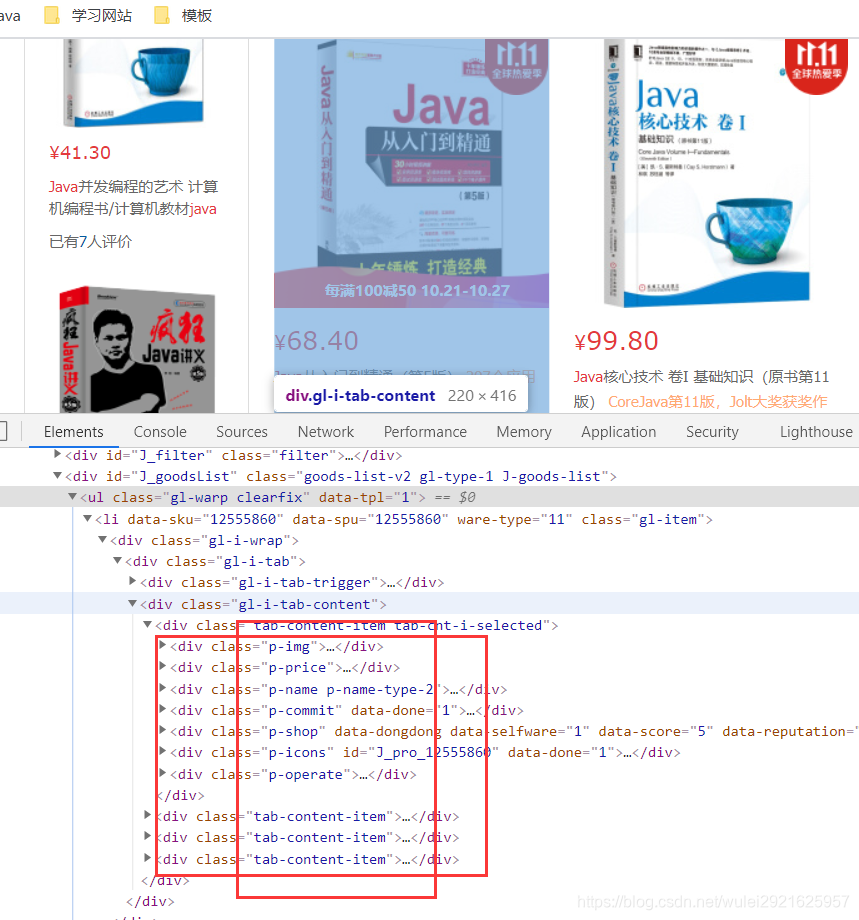
3、在utils包下建立HtmlParseUtil.java爬取测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hz6j9by4-1610955508957)(C:\Users\王东梁\AppData\Roaming\Typora\typora-user-images\image-20210118112732209.png)]
//测试数据
public static void main(String[] args) throws IOException, InterruptedException {//获取请求String url = "https://search.jd.com/Search?keyword=java";// 解析网页 (Jsou返回的Document就是浏览器的Docuement对象)Document document = Jsoup.parse(new URL(url), 30000);//获取id,所有在js里面使用的方法在这里都可以使用Element element = document.getElementById("J_goodsList");//获取所有的li元素Elements elements = element.getElementsByTag("li");//用来计数int c = 0;//获取元素中的内容 ,这里的el就是每一个li标签for (Element el : elements) {c++;//这里有一点要注意,直接attr使用src是爬不出来的,因为京东使用了img懒加载String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");//获取商品的价格,并且只获取第一个text文本内容String price = el.getElementsByClass("p-price").eq(0).text();String title = el.getElementsByClass("p-name").eq(0).text();String shopName = el.getElementsByClass("p-shop").eq(0).text();System.out.println("========================================");System.out.println(img);System.out.println(price);System.out.println(title);System.out.println(shopName);}System.out.println(c);
}
测试结果
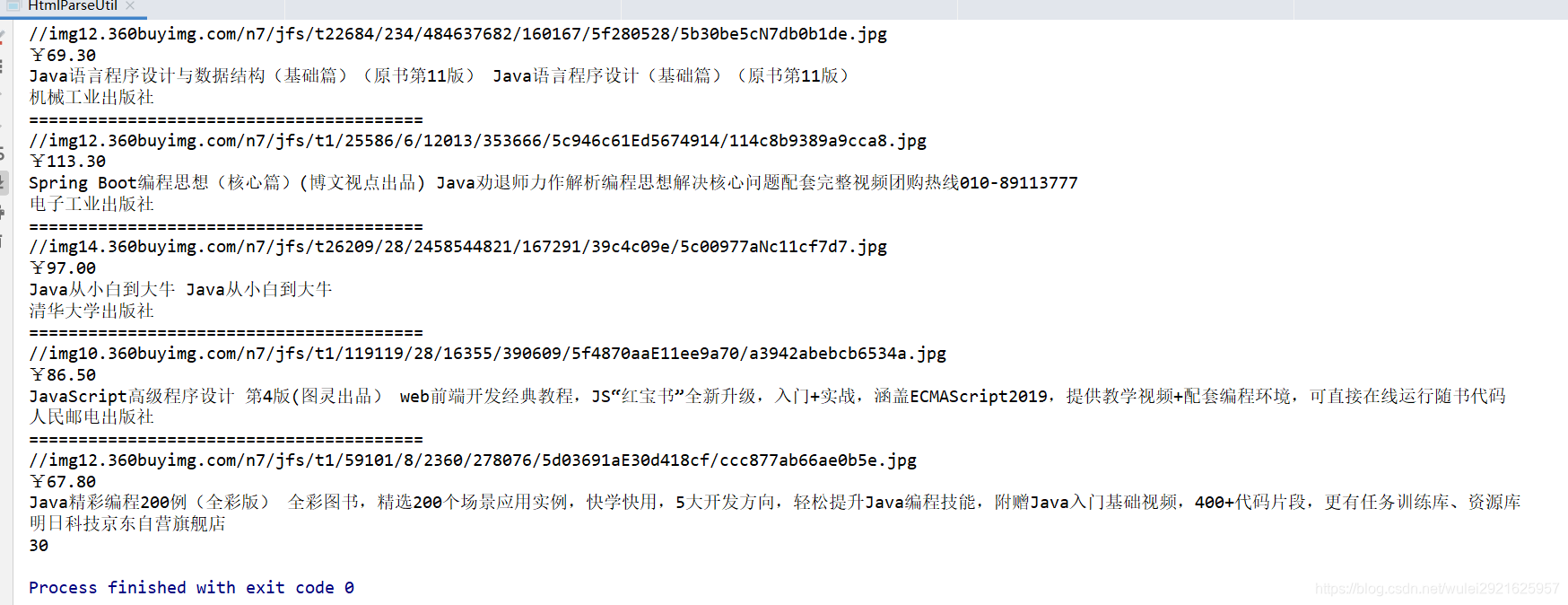
获取结果没问题,下面就把它封装成一个工具类
4、建立一个pojo实体类
实体类Content.java
package com.wu.pojo;@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {private String img;private String price;private String title;private String shopName;//可以自己扩展属性
}
工具类HtmlParseUtil.java
package com.wu.utils;@Component
public class HtmlParseUtil {public List<Content> parseJD(String keyword) throws IOException {List<Content> list = new ArrayList<>();String url = "https://search.jd.com/Search?keyword=" + keyword;Document document = Jsoup.parse(new URL(url), 30000);Element element = document.getElementById("J_goodsList");Elements elements = element.getElementsByTag("li");for (Element el : elements) {String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");String price = el.getElementsByClass("p-price").eq(0).text();String title = el.getElementsByClass("p-name").eq(0).text();String shopName = el.getElementsByClass("p-shopnum").eq(0).text();list.add(new Content(img, price, title, shopName));}return list;}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jpthiq6i-1610955508959)(C:\Users\王东梁\AppData\Roaming\Typora\typora-user-images\image-20210118115802010.png)]
5、业务层,这里就不写接口了
ContentService.java
先写一个方法让爬取的数据添加到ES中
package com.wu.service;//业务编写
@Service
public class ContentService {//将客户端注入@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;//1、解析数据放到 es 中public boolean parseContent(String keyword) throws IOException {List<Content> contents = new HtmlParseUtil().parseJD(keyword);//把查询的数据放入 es 中BulkRequest request = new BulkRequest();request.timeout("2m");for (int i = 0; i < contents.size(); i++) {request.add(new IndexRequest("jd_goods").source(JSON.toJSONString(contents.get(i)), XContentType.JSON));}BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);return !bulk.hasFailures();}
}
6、在Controller包下建立
ContentController.java
package com.wu.controller;//请求编写
@RestController
public class ContentController {@Autowiredprivate ContentService contentService;@GetMapping("/parse/{keyword}")public Boolean parse(@PathVariable("keyword") String keyword) throws IOException {return contentService.parseContent(keyword);}
}
7、启动SpringBoot项目,访问它爬取数据添加到ES中
http://127.0.0.1:9090/parse/java
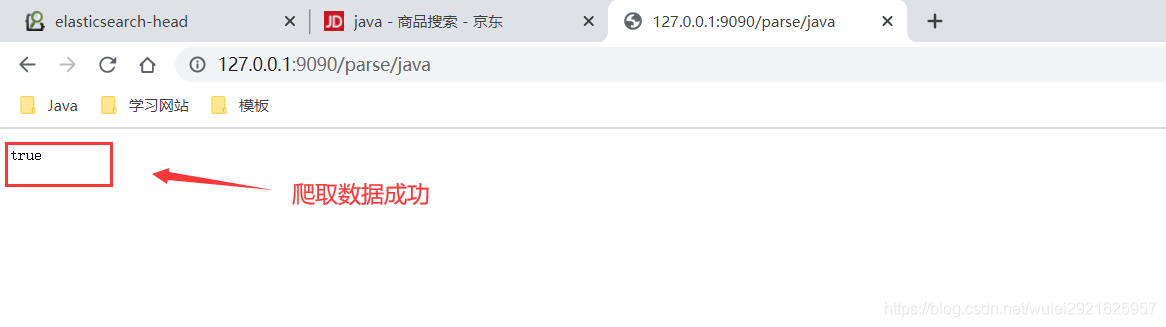
实现搜索功能
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xZLCRWps-1610955508961)(C:\Users\王东梁\AppData\Roaming\Typora\typora-user-images\image-20210118131856663.png)]
1、在ContentService.java添加
//2、获取这些数据实现基本的搜索功能
public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {if (pageNo <= 1) {pageNo = 1;}if (pageSize <= 1) {pageSize = 1;}//条件搜索SearchRequest searchRequest = new SearchRequest("jd_goods");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//分页sourceBuilder.from(pageNo).size(pageSize);//精准匹配TermQueryBuilder termQuery = QueryBuilders.termQuery("title", keyword);sourceBuilder.query(termQuery);sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));//执行搜索SearchRequest source = searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//解析结果List<Map<String, Object>> list = new ArrayList<>();for (SearchHit documentFields : searchResponse.getHits().getHits()) {list.add(documentFields.getSourceAsMap());}return list;
}
2、在ContentController添加搜索请求
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(@PathVariable("keyword") String keyword,@PathVariable("pageNo") int pageNo,@PathVariable("pageSize") int pageSize) throws IOException {List<Map<String, Object>> list = contentService.searchPage(keyword, pageNo, pageSize);return list;
}
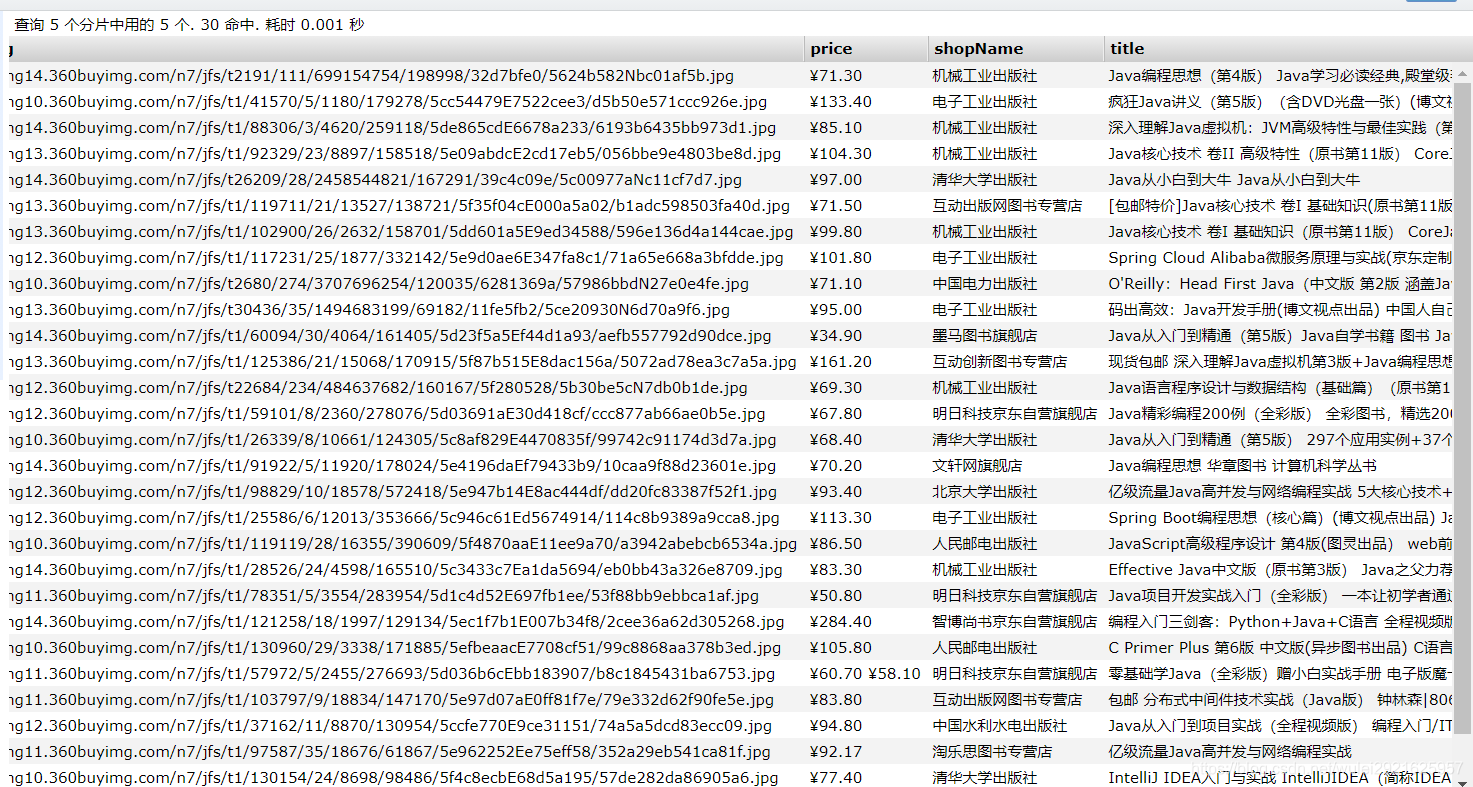
3、访问http://127.0.0.1:9090/search/java/1/10
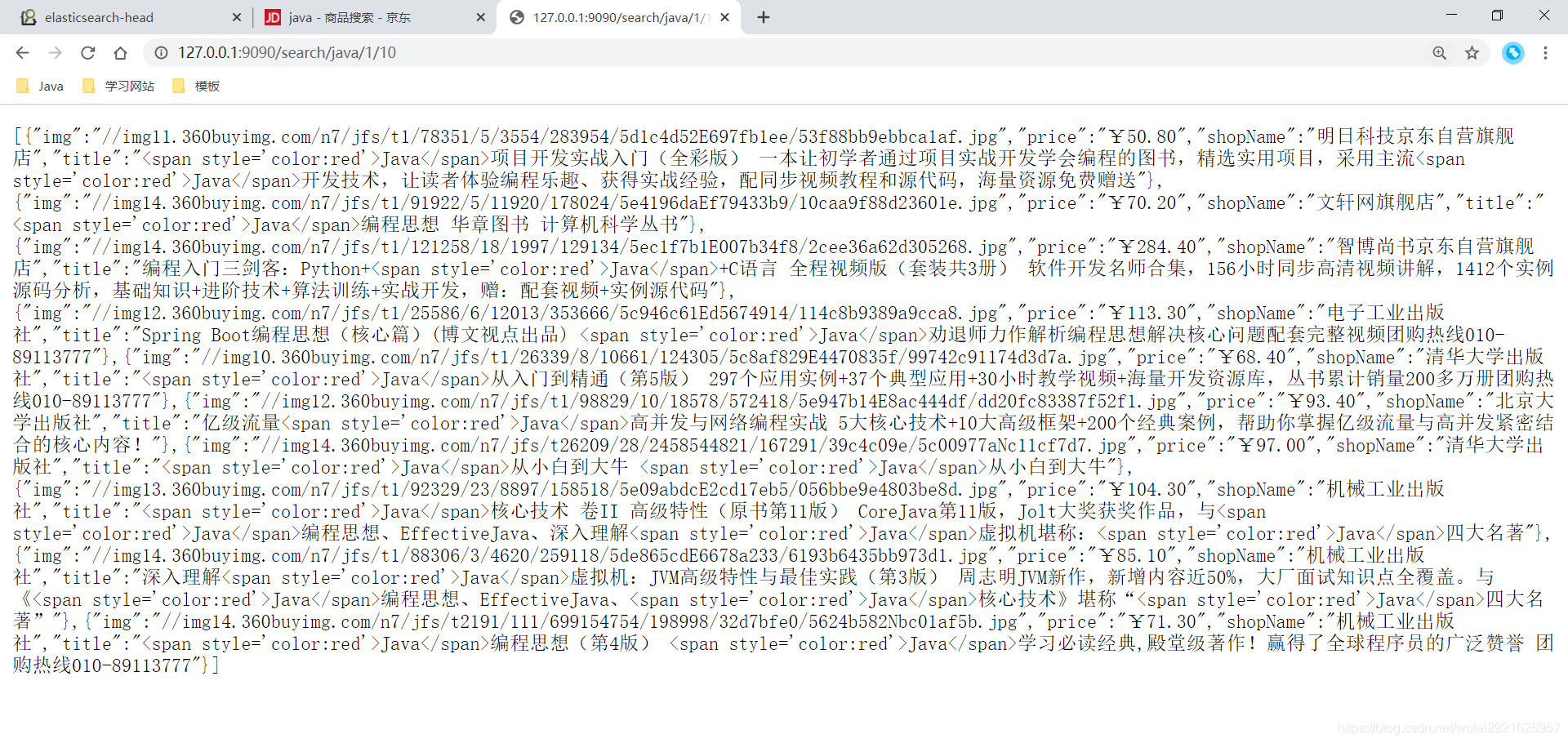
欧克,爬取和搜索都没问题,下面要做的就是和前端交互了
和前端交互
1、前端接收数据
index.html
1、用vue接收数据
<script>new Vue({el: '#app',data: {keyword: '', //搜索的关键字results: [] //搜索的结果},methods: {searchKey() {var keyword = this.keywordaxios.get('search/' + keyword + '/1/210').then(response => {this.results = response.data;//绑定数据!})}}})
</script>
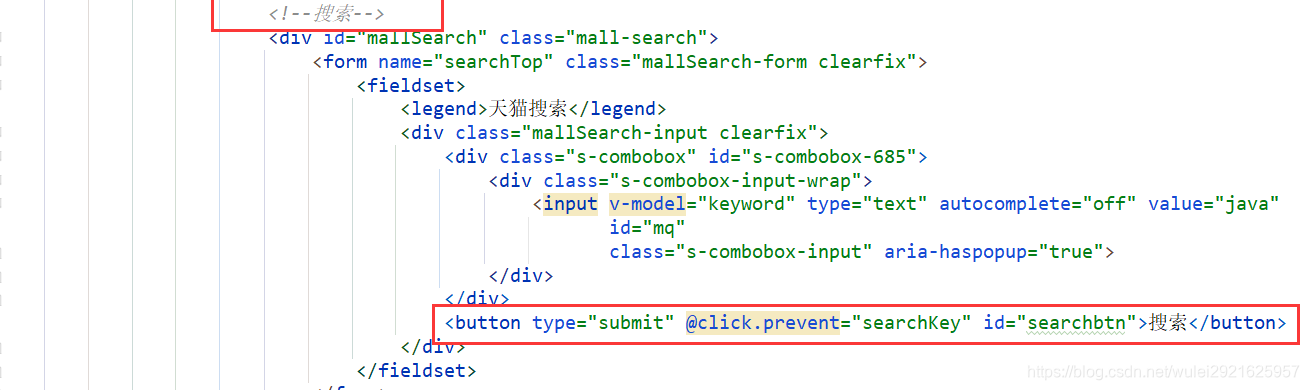
2、用vue给前端传递数据
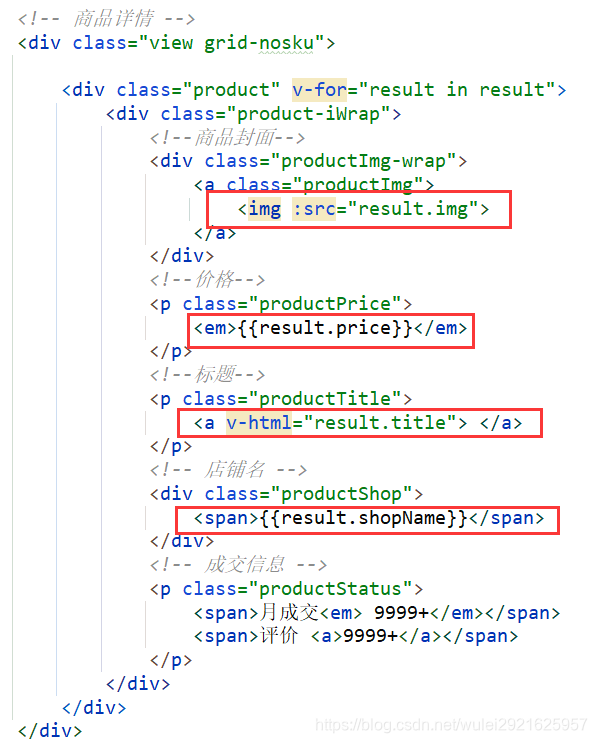
2、访问 127.0.0.1:9090 并且搜索java
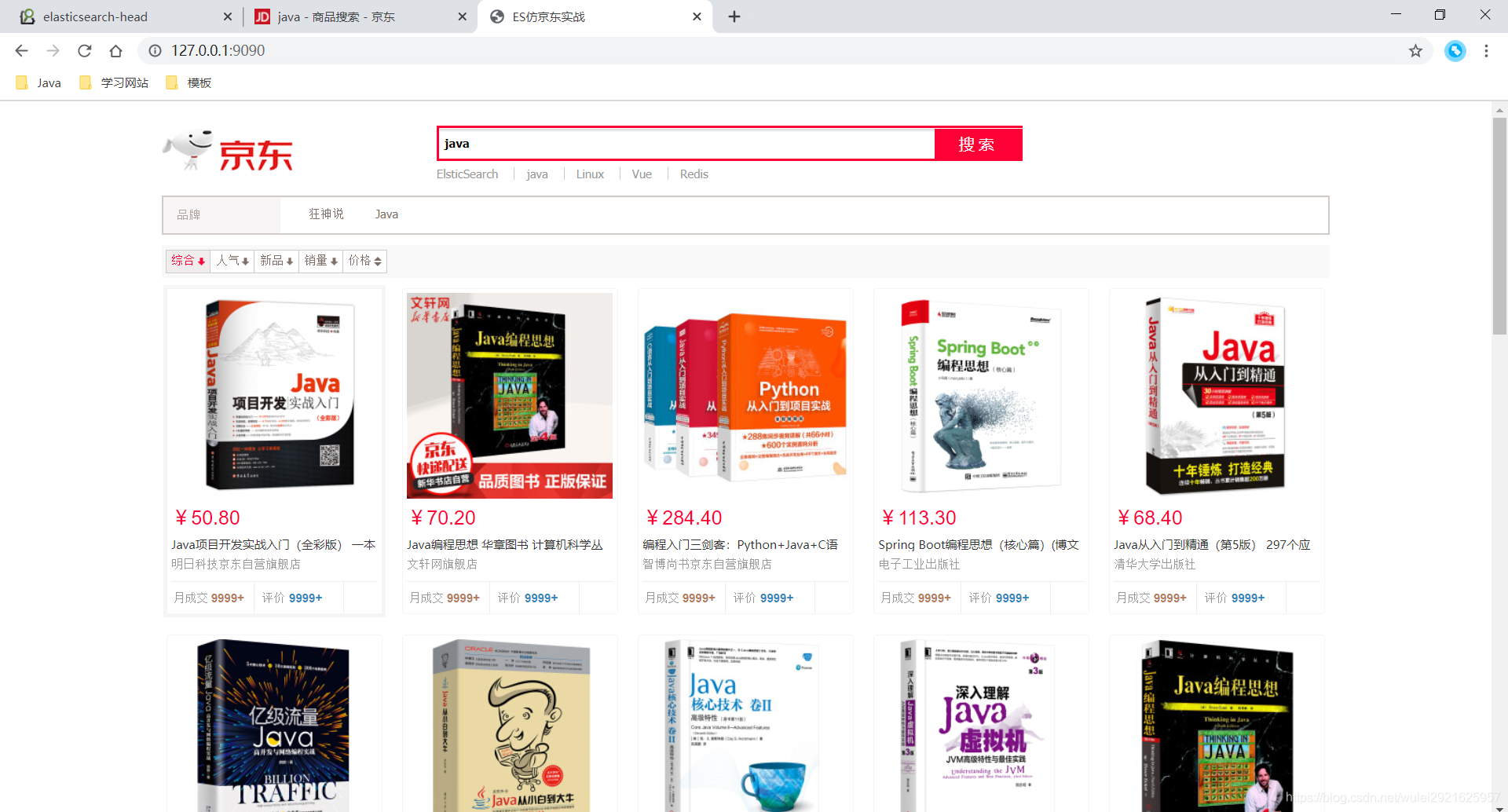
欧克,完美
实现关键字高亮
1、改ContentService.java里面的搜索功能就行
//3、获取这些数据实现基本的搜索高亮功能
public List<Map<String, Object>> searchPagehighlighter(String keyword, int pageNo, int pageSize) throws IOException {if (pageNo <= 1) {pageNo = 1;}if (pageSize <= 1) {pageSize = 1;}//条件搜索SearchRequest searchRequest = new SearchRequest("jd_goods");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//分页sourceBuilder.from(pageNo).size(pageSize);//精准匹配TermQueryBuilder termQuery = QueryBuilders.termQuery("title", keyword);//==================================== 高 亮 ==========================================HighlightBuilder highlightBuilder = new HighlightBuilder(); //获取高亮构造器highlightBuilder.field("title"); //需要高亮的字段highlightBuilder.requireFieldMatch(false);//不需要多个字段高亮highlightBuilder.preTags("<span style='color:red'>"); //前缀highlightBuilder.postTags("</span>"); //后缀sourceBuilder.highlighter(highlightBuilder); //把高亮构造器放入sourceBuilder中sourceBuilder.query(termQuery);sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));//执行搜索SearchRequest source = searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//解析结果List<Map<String, Object>> list = new ArrayList<>();for (SearchHit hit : searchResponse.getHits().getHits()) {Map<String, HighlightField> highlightFields = hit.getHighlightFields();//获取高亮字段HighlightField title = highlightFields.get("title"); //得到我们需要高亮的字段Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的返回的结果//解析高亮的字段if (title != null) {Text[] fragments = title.fragments();String new_title = "";for (Text text : fragments) {new_title += text;}sourceAsMap.put("title", new_title); //高亮字段替换掉原来的内容即可}list.add(sourceAsMap);}return list;
}
2、改变Controller里面的搜索请求
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(@PathVariable("keyword") String keyword,@PathVariable("pageNo") int pageNo,@PathVariable("pageSize") int pageSize) throws IOException {List<Map<String, Object>> list = contentService.searchPagehighlighter(keyword, pageNo, pageSize);return list;
}
3、发现问题
需要高亮的字段前缀和后缀都有了,但是这不是我们想要的结果
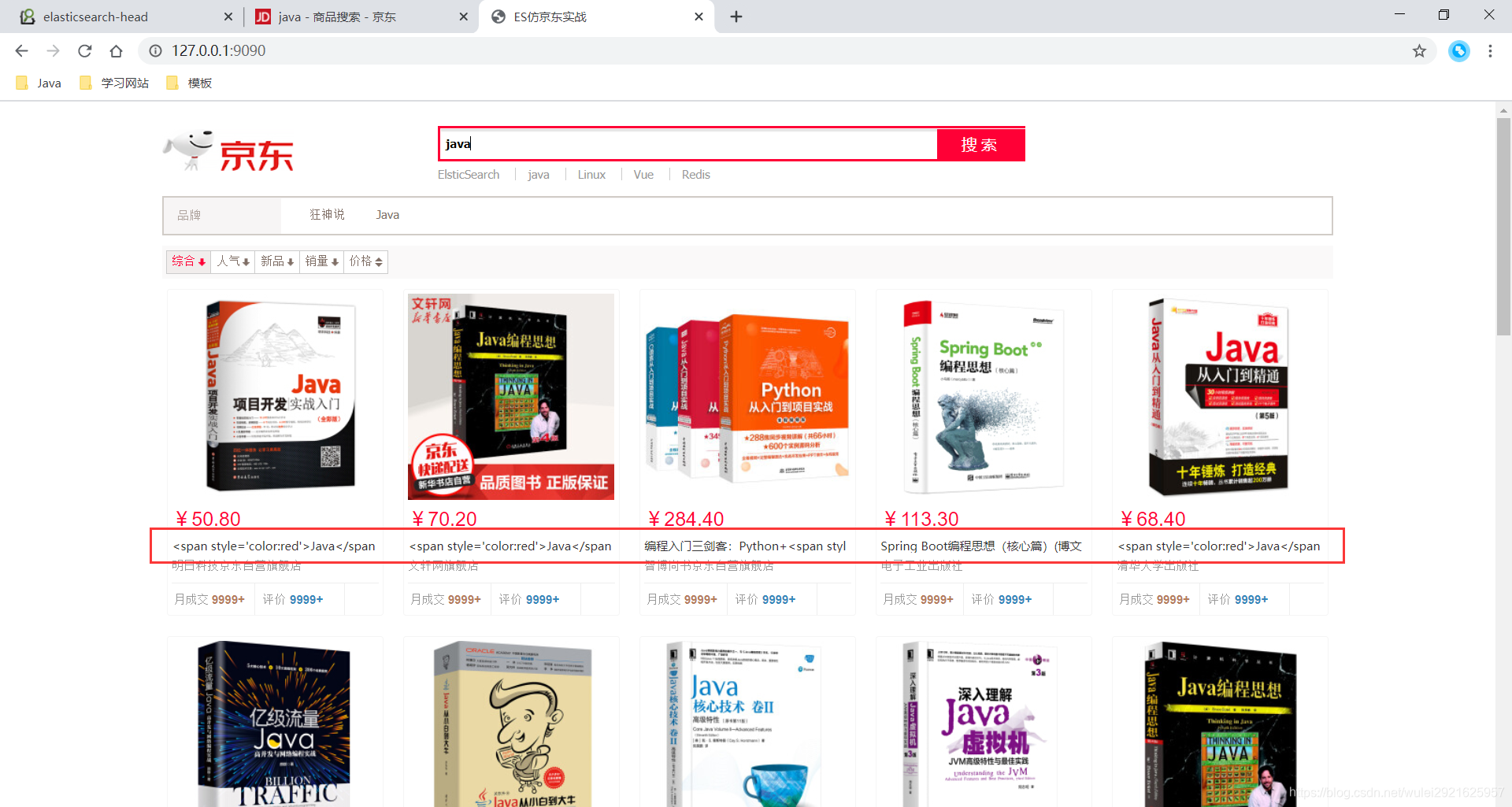
4、解决问题
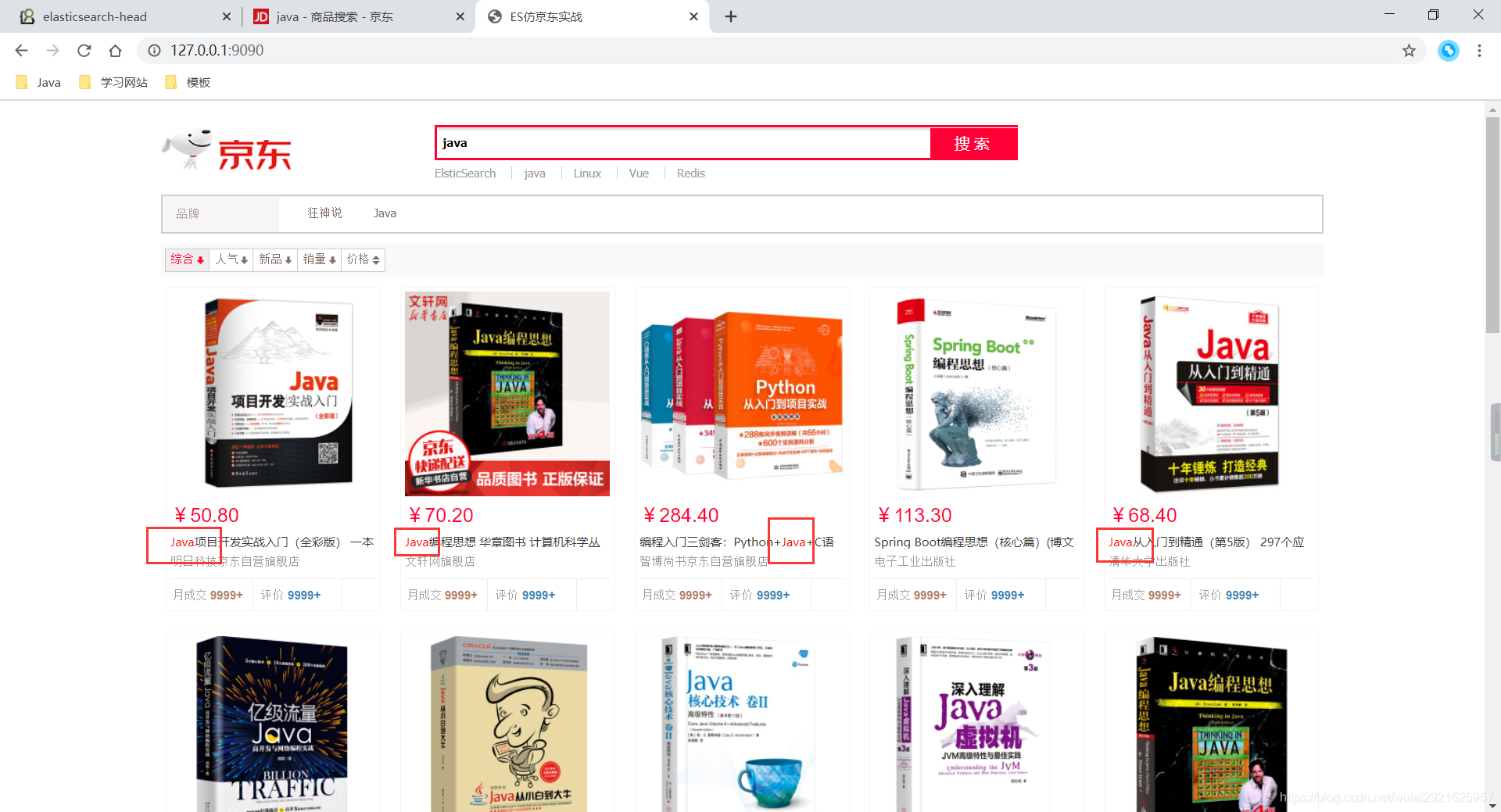
这里Vue给了我们很方便的解决办法

5、完美













 ——applicationContext.xml)



 ——测试)
)
