NoSQL数据库发展迅猛,据说现在已经有上百种NoSQL数据库了,下面来了解下常见的一些NoSQL数据库
先来看张表,了解下典型的NoSQL数据库的分类
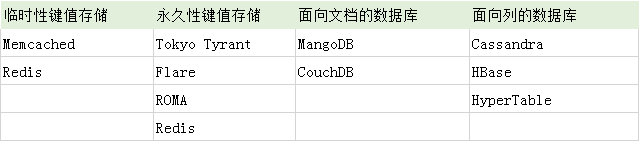
NoSQL一般特征:
- 临时性键值存储
- 一般作为关系型数据库的缓存来使用
- 由于存在数据丢失的可能,所以一般用来处理不需要持久保存的数据
- 具有非常快的处理速度
- 用于需要使用expires时(需要定期清除数据)
- 使用一致性散列(Consistent Hashing)算法来分散数据
1、CouchDB
- 所用语言: Erlang
- 特点:DB一致性,易于使用
- 使用许可: Apache
- 协议: HTTP/REST
- 双向数据复制,
- 持续进行或临时处理,
- 处理时带冲突检查,
- 采用的是master-master复制(见编注2)
- MVCC – 写操作不阻塞读操作
- 可保存文件之前的版本
- Crash-only(可靠的)设计
- 需要不时地进行数据压缩
- 视图:嵌入式 映射/减少
- 格式化视图:列表显示
- 支持进行服务器端文档验证
- 支持认证
- 根据变化实时更新
- 支持附件处理
- CouchApps(独立的 js应用程序)
- 需要 jQuery程序库
最佳应用场景:适用于数据变化较少,执行预定义查询,进行数据统计的应用程序。适用于需要提供数据版本支持的应用程序。
例如: CRM、CMS系统。 master-master复制对于多站点部署是非常有用的。
2、Neo4j
所用语言: Java
特点:基于关系的图形数据库
使用许可: GPL,其中一些特性使用 AGPL/商业许可
协议: HTTP/REST(或嵌入在 Java中)
可独立使用或嵌入到 Java应用程序
图形的节点和边都可以带有元数据
很好的自带web管理功能
使用多种算法支持路径搜索
使用键值和关系进行索引
为读操作进行优化
支持事务(用 Java api)
使用 Gremlin图形遍历语言
支持 Groovy脚本
支持在线备份,高级监控及高可靠性支持使用 AGPL/商业许可
最佳应用场景:适用于图形一类数据。这是 Neo4j与其他nosql数据库的最显著区别
例如:社会关系,公共交通网络,地图及网络拓谱
最佳应用场景:适用于数据变化较少,执行预定义查询,进行数据统计的应用程序。适用于需要提供数据版本支持的应用程序。
例如: CRM、CMS系统。 master-master复制对于多站点部署是非常有用的。
(编注2:master-master复制:是一种数据库同步方法,允许数据在一组计算机之间共享数据,并且可以通过小组中任意成员在组内进行数据更新。)
3、 Cassandra
所用语言: Java
特点:对大型表格和 Dynamo支持得最好
使用许可: Apache
协议: Custom, binary (节约型)
可调节的分发及复制(N, R, W)
支持以某个范围的键值通过列查询
类似大表格的功能:列,某个特性的列集合
写操作比读操作更快
基于 Apache分布式平台尽可能地 Map/reduce
我承认对 Cassandra有偏见,一部分是因为它本身的臃肿和复杂性,也因为 Java的问题(配置,出现异常,等等)
最佳应用场景:当使用写操作多过读操作(记录日志)如果每个系统组建都必须用 Java编写(没有人因为选用 Apache的软件被解雇)
例如:银行业,金融业(虽然对于金融交易不是必须的,但这些产业对数据库的要求会比它们更大)写比读更快,所以一个自然的特性就是实时数据分析
4、HBase
(配合 ghshephard使用)
所用语言: Java
特点:支持数十亿行X上百万列
使用许可: Apache
协议:HTTP/REST (支持 Thrift,见编注4)
在 BigTable之后建模
采用分布式架构 Map/reduce
对实时查询进行优化
高性能 Thrift网关
通过在server端扫描及过滤实现对查询操作预判
支持 XML, Protobuf, 和binary的HTTP
Cascading, hive, and pig source and sink modules
基于 Jruby( JIRB)的shell
对配置改变和较小的升级都会重新回滚
不会出现单点故障
堪比MySQL的随机访问性能
最佳应用场景:适用于偏好BigTable:)并且需要对大数据进行随机、实时访问的场合。
例如: Facebook消息数据库(更多通用的用例即将出现)
编注4:Thrift 是一种接口定义语言,为多种其他语言提供定义和创建服务,由Facebook开发并开源。
5、Tokyo Tyrant
- 持久性的键值存储
- 用来处理需要持久保存,高速处理的数据
- 具有非常快的处理速度
- 用于不需要定期清除的数据
- 使用一致性散列(Consistent Hashing)算法来分散数据
6、redis
优点:
- 支持多种数据结构,如 string(字符串)、 list(双向链表)、dict(hash表)、set(集合)、zset(排序set)、hyperloglog(基数估算)
- 支持持久化操作,可以进行aof及rdb数据持久化到磁盘,从而进行数据备份或数据恢复等操作,较好的防止数据丢失的手段。
- 支持通过Replication进行数据复制,通过master-slave机制,可以实时进行数据的同步复制,支持多级复制和增量复制,master-slave机制是Redis进行HA的重要手段。
- 单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
- 支持pub/sub消息订阅机制,可以用来进行消息订阅与通知。
- 支持简单的事务需求,但业界使用场景很少,并不成熟。
缺点:
- Redis只能使用单线程,性能受限于CPU性能,故单实例CPU最高才可能达到5-6wQPS每秒(取决于数据结构,数据大小以及服务器硬件性能,日常环境中QPS高峰大约在1-2w左右)。
- 支持简单的事务需求,但业界使用场景很少,并不成熟,既是优点也是缺点。
- Redis在string类型上会消耗较多内存,可以使用dict(hash表)压缩存储以降低内存
耗用。
7、Memcache
优点:
- Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key、value的字节大小以及服务器硬件性能,日常环境中QPS高峰大约在4-6w左右)。适用于最大程度扛量。
- 支持直接配置为session handle。
缺点:
- 只支持简单的key/value数据结构,不像Redis可以支持丰富的数据类型。
- 无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失。
- 无法进行数据同步,不能将MC中的数据迁移到其他MC实例中。
- Memcached内存分配采用Slab Allocation机制管理内存,value大小分布差异较大时会造成内存利用率降低,并引发低利用率时依然出现踢出等问题。需要用户注重value设计。
8、MongoDB
优点:
- 更高的写负载,MongoDB拥有更高的插入速度。
- 处理很大的规模的单表,当数据表太大的时候可以很容易的分割表。
- 高可用性,设置M-S不仅方便而且很快,MongoDB还可以快速、安全及自动化的实现节点(数据中心)故障转移。
- 快速的查询,MongoDB支持二维空间索引,比如管道,因此可以快速及精确的从指定位置获取数据。MongoDB在启动后会将数据库中的数据以文件映射的方式加载到内存中。如果内存资源相当丰富的话,这将极大地提高数据库的查询速度。
- 非结构化数据的爆发增长,增加列在有些情况下可能锁定整个数据库,或者增加负载从而
导致性能下降,由于MongoDB的弱数据结构模式,添加1个新字段不会对旧表格有任何影响,
整个过程会非常快速。
缺点:
- 不支持事务。
- MongoDB占用空间过大 。
- MongoDB没有成熟的维护工具。
9、Redis、Memcache和MongoDB的区别
9.1 性能
三者的性能都比较高,总的来讲:Memcache和Redis差不多,要高于MongoDB。
9.2 便利性
memcache数据结构单一。
redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数。
mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富。
9.3 存储空间
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;可以对key value设置过期时间(类似memcache)。
memcache可以修改最大可用内存,采用LRU算法。
mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起。
9.4 可用性
redis,依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,所以单点问题比较复杂;不支持自动sharding,需要依赖程序设定一致hash 机制。一种替代方案是,不用redis本身的复制机制,采用自己做主动复制(多份存储),或者改成增量复制的方式(需要自己实现),一致性问题和性能的权衡。
Memcache本身没有数据冗余机制,也没必要;对于故障预防,采用依赖成熟的hash或者环状的算法,解决单点故障引起的抖动问题。
mongoDB支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制。
9.5 可靠性
redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响。
memcache不支持,通常用在做缓存,提升性能。
MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性。
9.6 一致性
Memcache 在并发场景下,用cas保证一致性。
redis事务支持比较弱,只能保证事务中的每个操作连续执行。
mongoDB不支持事务。
9.7 数据分析
mongoDB内置了数据分析的功能(mapreduce),其他两者不支持。
9.8 应用场景
redis:数据量较小的性能操作和运算上。
memcache:用于在动态系统中减少数据库负载,提升性能;做缓存,提高性能(适合读多写
少,对于数据量比较大,可以采用sharding)。
MongoDB:主要解决海量数据的访问效率问题。








的原理与实现)
 - 入门与工具简介)







)

 - 使用官方推荐方式)