全世界只有3.14 % 的人关注了
数据与算法之美
卢sir在回顾2018年的时候,发现居然遗漏了一个“知识点”——在2018年的最后一个月, AlphaGo Zero登上了世界顶级学术期刊《科学》杂志的封面。

Google设计了AlphaGo(围棋机器人)的事早已经家喻户晓了,都9102年了,它怎么又出现了?
说到这,卢sir就先带大伙回顾一下AlphaGo的发展历程吧。迄今为止,AlphaGo一共有四个版本:AlphaGo Fan、AlphaGo Lee、AlphaGo Master和AlphaGo Zero。
2016年,AlphaGo Fan以5比0的战绩战胜了欧洲围棋冠军樊麾后,登上了国际学术期刊《自然》的封面,成功引起了人类的注意。

紧接着AlphaGo Lee又以4比1的比分战胜了围棋世界冠军、职业九段棋手李世石,成为了世界上第一个战胜围棋世界冠军的人工智能机器人。
愈战愈勇的AlphaGo又以“AlphaGo Master”的身份与中日韩数十位围棋高手进行快棋对决,创造了连续60局全胜的战绩,甚至连人类排名第一的棋手柯洁也被打成3比0。
不得不说,AlphaGo的势头的确挺猛的,仅一年的时间,就战胜了大量的世界顶尖的围棋高手,甚至还引发了“机器人打败人类开始占领地球”的言论。
不过机智的卢sir早已看破其中的奥秘,“Fan、Lee和Master”看起来是人工智能,实际上却是“人工智障”。
因为它们在比赛前就会从对手的棋局里进行全方位的学习,比如说:在任意一步时,它们就会把下一步所有可能性都罗列出来,然后一步步往后推,然后选取胜率最高的方法。
说来也搞笑,谁能想到一群围棋精英会输给一个连围棋规则都不懂的机器人呢?所以说,AlphaGo只能打有准备的仗,让它临场发挥的话,可能它连我卢sir都下不赢,更别提它能“占领地球”了。
直到2017年10月19,Deepmind(谷歌下属公司)在国际学术期刊《自然》上发表的一篇研究论文中就提到了AlphaGo的全新版本——AlphaGo Zero。

AlphaGo Zero与前三代的最大不同是,它能从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋。
也就是说,这次AlphaGo Zero是真的自己学会了围棋规则,系统学会渐渐从输、赢以及平局里面调整参数,让自己更懂得选择那些有利于赢下比赛的走法,而不再去分析对手的特征了。
都说新官上任三把火,AlphaGo Zero仅经过了3天的训练(自学),就以100比0的绝对优势战胜了AlphaGo Lee;经过40天训练后又把AlphaGo Master给秒杀了。
高呼着“抛弃人类经验”和“自我训练”问世的AlphaGo Zero的本领当然不只是欺负“老人家”啦,它强大的reinforcement learning(强化学习的算法)可以让它轻松的掌握国际象棋、日本将棋和中国围棋,而且每项都能当世界第一。
训练2个小时,AlphaZero就碾压了日本将棋世界冠军程序Elmo;
训练4个小时,AlphaZero就战胜了国际象棋世界冠军程序Stockfish。
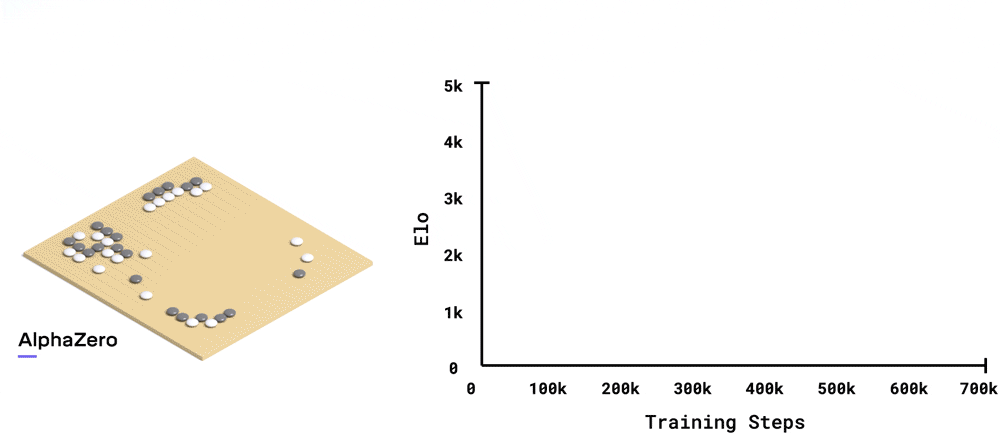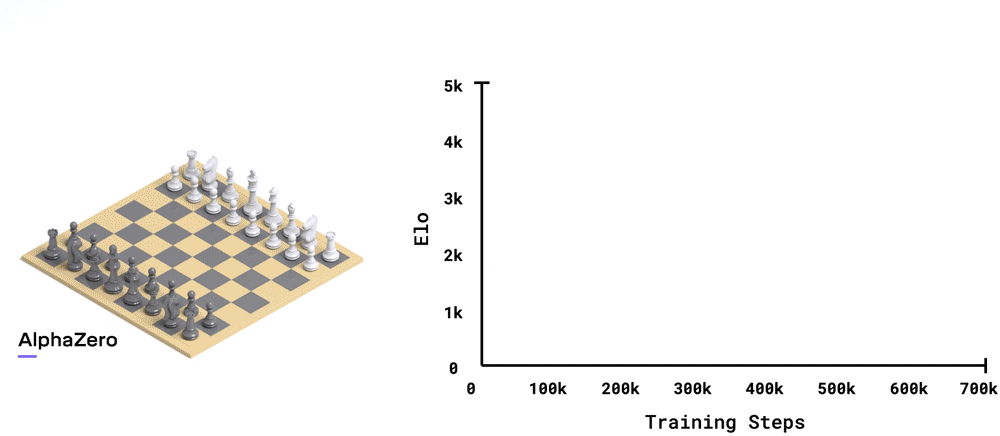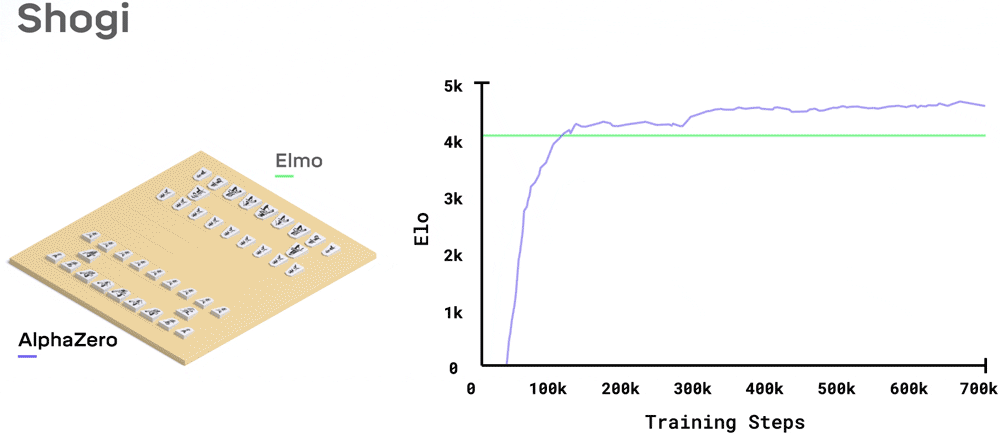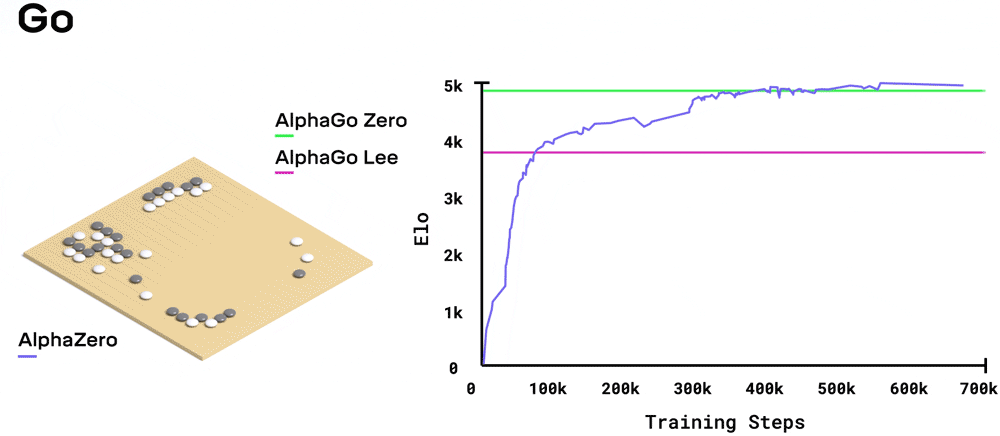
其中,卢sir就发现了一个细节,由于AlphaGo Zero的机制从“知己知彼”变成了“百战百胜”,它下棋能力也出现相应的成长式变化,而不是一味的获胜。话不多说,直接看一组数据:
AlphaGo Zero在挑战国际象棋世界冠军Stockfish时,1000场输了155场;
在挑战日本将棋世界冠军Elmo时,胜率为91.2%;
在挑战AlphaGo的前三代时,胜率仅有61%。
那为什么AlphaGo Zero不选择和人类一较高下,而是和机器人打起了内战?
因为早在AlphaGo把人类精英棋手虐一遍之后,就宣布不再参与任何人机之间的下棋比赛,典型的装完逼就跑。
其实机器人也是不忍心了,因为早在1997年5月,人类棋手就已经被机器人血虐了——超级计算机“深蓝”打败了国际象棋棋王,世界冠军卡斯帕罗夫,这件事轰动了整个世界。

虽然卢sir觉得AlphaGo Zero已经有了质的突变,但还是有不少人怀疑它的真实性和可行性。
直到2018年12月,AlphaGo Zero登上世界顶级学术期刊《科学》杂志封面后,《科学》杂志官方为其正名:“能够解决多个复杂问题的单一算法,是创建通用机器学习系统,解决实际问题的重要一步。”
那AlphaGo Zero到底是凭什么用短短一年时间从“知己知彼”变成“百战百胜”的呢?
首先,AlphaGo Zero做了一个全新的定位:重在学习,而不是急于求胜。
Deepmind采用了5000个TPU(可以简单的理解为电脑的CPU),再结合深度神经网络、通用强化学习算法和通用树搜索算法来打造了一个全能棋手。
AlphaGo Zero的学习能力也是一个动态成长的过程,每次学习一种新的棋类或者游戏都会根据难易程度来展开一段自我博弈,产生的超参数再通过贝叶斯优化进行调整。
与此同时,AlphaGo Zero的“自学”过程还有一项特别重要的任务——对自身进行神经网络训练。
训练好的神经网络,可以精准地指引一个搜索算法,就是蒙特卡洛树搜索 (MCTS) ,为每一步棋选出最有利的落子位置。每下一步之前,AlphaGo Zero的搜索对象不是所有可能性,而只是最合适当下“战况”的一小部分可能性,这就大大提升了精确性和效率性。
关于神经网络的优势,Deepmind在论文中也例举了例子。
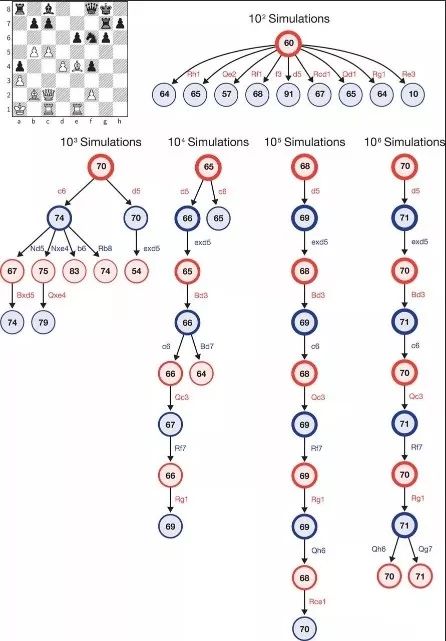
上图展示的是在AlphaGo Zero执白、Stockfish执黑的一局国际象棋里,经过100次、1000次……直到100万次模拟之后,AlphaZero蒙特卡洛树的内部状态。每个树状图解都展示了10个最常访问的状态。
不怕机器人会下棋,就怕机器人产生意识和情感。
其实对于AlphaGo Zero的人工智能性质,棋手们最大的感受就是:这个家伙不按套路出牌。因为AlphaGo Zero自己学习了每种棋类,所以它并不受人类现有套路的影响,产生了独特的、且富有创造力和动态的棋风。
国际象棋世界冠军卡斯帕罗夫也在《科学》上撰文表示:“AlphaGo Zero的棋风跟我一样,具备动态、开放的风格。”
卢sir:但这样并不能掩盖你战败的事实。
 精品课程推荐:
精品课程推荐:


选购数学科普正版读物
严选“数学思维好物”
送给孩子的益智礼物 | 办公室神器
算法工程师成长阅读 | 居家高科技
理工科男女实用型礼物精选





---- 点击头像关注----
点击头像关注----

超级数学建模

数据与算法之美

少年数学家

数锐学堂

惊喜酱(个人号)

玩酷屋COOL


中用颜色显示不同类型文件)



)













)