阿里云离线数据仓库
- 第1章 数据仓库概念
- 第2章 项目需求及架构设计
- 2.1 项目需求分析
- 2.2 阿里云技术框架
- 2.2.1 技术选型
- 2.2.2 系统数据流程设计
- 第3章 数据生成模块
- 3.1 埋点数据基本格式
- 3.2 事件日志数据
- 3.2.1 商品列表页(loading)
- 3.2.2 商品曝光(display)
- 3.2.3 商品详情页(newsdetail)
- 3.2.4 购物车(cart)
- 3.2.5 广告(ad)
- 3.2.6 消息通知(notification)
- 3.2.7 评论(comment)
- 3.2.8 收藏(favorites)
- 3.2.8 点赞(praise)
- 3.2.10 错误日志(error)
- 3.3 启动日志数据(start)
- 第4章 数据采集模块
- 4.5 Flume安装及使用
- 4.6 DataHub安装及使用
- 4.6.1 DataHub 简介
- 4.8 DataWorks 和 MaxCompute
- 4.8.1 简介
- 第5章 用户数据行为数仓搭建
- 5.1 数仓分层概念
- 5.1.1 数仓分层
- 5.1.2 数仓分层优点
- 5.1.3 数仓命名规范
- 5.5 DataHub 推送数据到MaxCompute
- 5.6 明细数据层(DWD层)
- 5.6.1 日志格式分析
- 5.6.2 自定义UDTF(解析具体事件字段)
- 5.6.5 数据导入脚本
- 5.7.3 数据导入脚本
- 5.8 应用数据层(ADS层)
- 第6章 业务数仓理论
- 6.1 表的分类
- 6.1.1 实体表
- 6.1.2 维度表
- 6.1.3 事务型事实表
- 6.1.4 周期型事实表
- 6.2 同步策略
- 6.2.1 实体表同步策略
- 6.2.2 维度表同步策略
- 6.2.3 事务型事实表同步策略
- 6.2.4 周期型事实表同步策略
- 第7章 业务数仓搭建
- 7.1 业务数仓架构图
- 7.2 RDS 服务器准备
- 7.2.1 RDS 服务器购买
- 7.5.3 每日增量表同步
- 7.5.4 每日新增及变化表同步
- 7.6 DWD层
- 7.6.2 手动将数据导入 DWD 层
- 7.7 DWS层
- 7.8 ADS层
- 第8章 数据导出与作业调度
- 8.1 创建结果数据库
- 8.2 创建商品销售数据同步节点
- 第9章 数据可视化
第1章 数据仓库概念
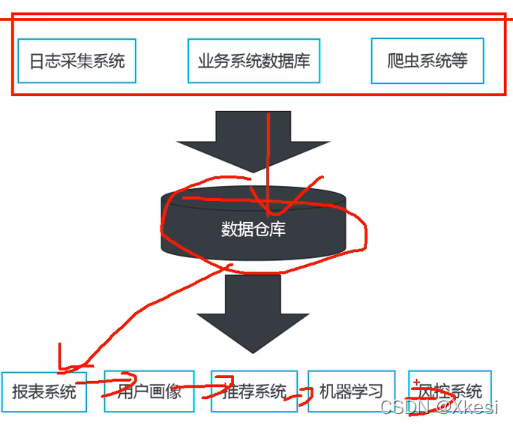
- 数据仓库定义(Data Warehouse),是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
- 数据仓库好处:可以帮助企业改进业务流程、控制成本、提高产品质量等。
- 数据仓库做什么:清洗、转义、分类、重组、合并、拆分,统计等。
- 数据仓库输出到哪:报表系统、用户画像、推荐系统、机器学习、风控系统等。
第2章 项目需求及架构设计
2.1 项目需求分析
- 采集埋点日志数据:用户行为数据仓库,用户来到网站/APP的行为(干了那些事),包括一些异常或故障。(以文件的形式存储)
- 采集业务数据库中数据:业务数仓,网站/APP中的各功能组件运行时所产生的数据。 (以MySQL数据库的形式存储)
- 数据仓库的搭建(用户行为数仓、业务数仓)
- 分析统计各种业务指标:比如日活跃用户、新增用户、交易额等。
- 对结果进行可视化展示
2.2 阿里云技术框架
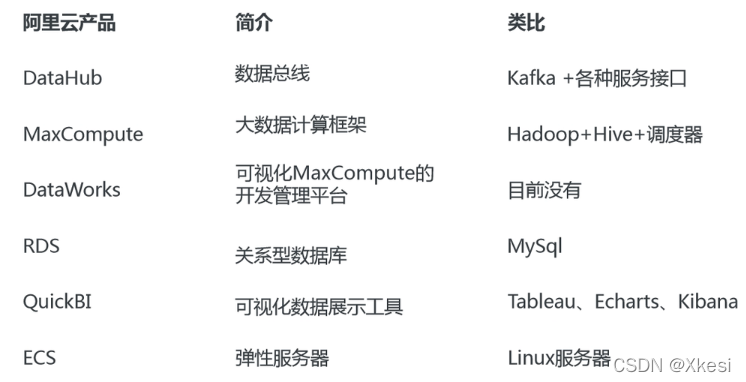
2.2.1 技术选型
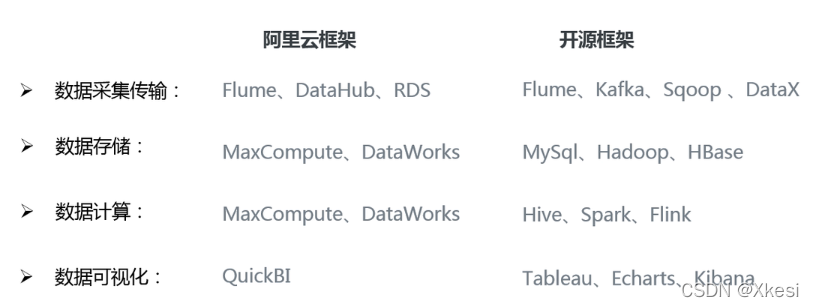
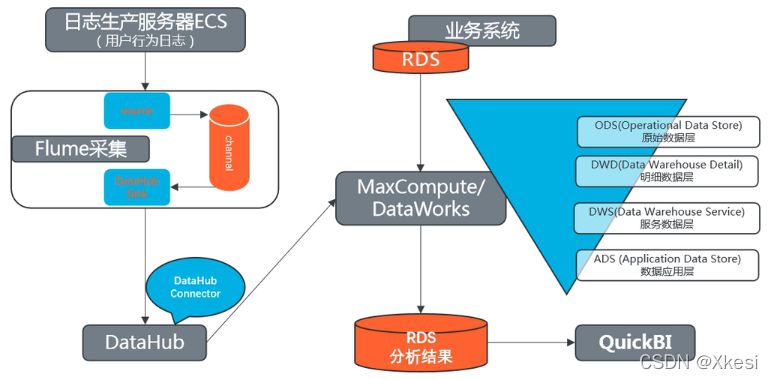
2.2.2 系统数据流程设计
第3章 数据生成模块
3.1 埋点数据基本格式
- 公共字段:比如基本所有安卓手机都包含的字段。
- 业务字段:埋点上报的字段,有具体的业务类型。
3.2 事件日志数据
3.2.1 商品列表页(loading)

3.2.2 商品曝光(display)
事件标签:display

3.2.3 商品详情页(newsdetail)
事件标签:newsdetail

3.2.4 购物车(cart)
事件名称:cart

3.2.5 广告(ad)
事件名称:ad
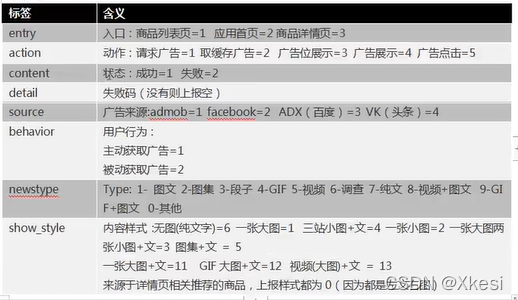
3.2.6 消息通知(notification)
事件标签:notification

3.2.7 评论(comment)
评论表标签:comment
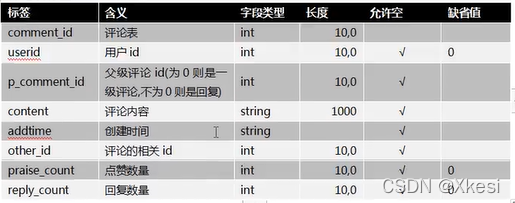
3.2.8 收藏(favorites)
收藏标签:favorites
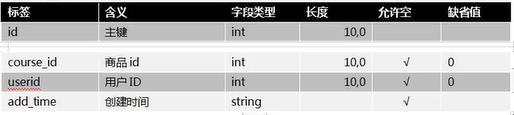
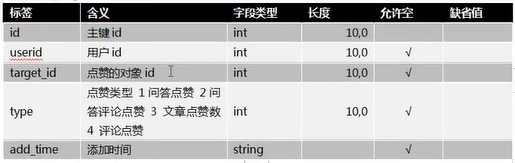
3.2.8 点赞(praise)
点赞标签:praise
3.2.10 错误日志(error)
错误日志标签:error,帮助发现问题,进行改善提升。

3.3 启动日志数据(start)
启动日志标签:start

第4章 数据采集模块
4.5 Flume安装及使用
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
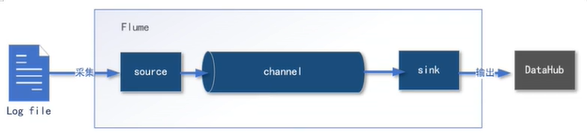
- Source:主要负责采集工作,采用 TailDir 组件用于监控文件或文件夹的变化。
- Channel:扮演数据管道的角色,对数据进行缓冲。采用非持久化的 Memory类型。
4.6 DataHub安装及使用
4.6.1 DataHub 简介
- Flume 部分已经可以输出后,就开始搭建真正需要输出的目的地—DataHub,即阿里云数据总线服务。 通俗来说这个 DataHub
- 类似于传统大数据解决方案中 Kafka 的角色,提供了一个数据队列功能。 对于离线计算,DataHub 除了提供了一个缓冲的队列作用。
- 同时由于DataHub提供了各种与其他阿里云上下游产品的对接功能,所以DataHub又扮演了一个数据的分发枢纽工作。
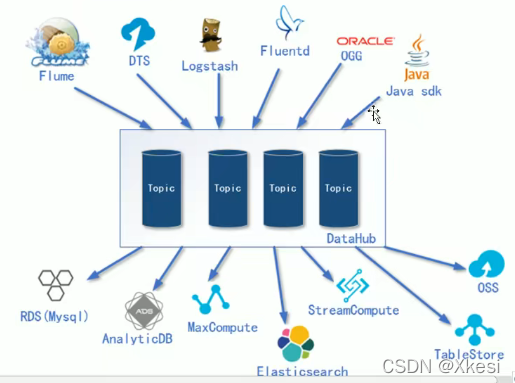
DataHub 输入组件包括
Flume:主流的开源日志采集框架。
DTS:类似 Canal,日志实时监控采集框架。
Logstash:也是日志采集框架,通常和 Elasticsearch、Kibana 集合使用。
Fluentd:Fluentd 是一个实时开源的数据收集器。
OGG:实时监控 Oracle 中数据变化。
DataHub 输出组件包括
RDS:类似于传统 MySQL 数据库。
DB:面向分析型的分布式数据库。
MaxCompute:离线分析框架。
Elasticsearch:数据分析,倒排索引。
StreamCompute:实时分析框架。
TableSotre:类似于 Redis,KV 形式存储数据。
OSS:类似于 HDFS,存储图片,视频。
4.8 DataWorks 和 MaxCompute
4.8.1 简介
MaxCompute(大数据计算服务)是阿里巴巴自主研发的海量数据处理平台,主要提供数据上传和下载通道,提供 SQL 及 MapReduce 等多种计算分析服务,同时还提供完善的安全解决方案。
DataWorks(数据工场,原大数据开发套件)是基于 MaxCompute 计算引擎的一站式大数据工场,它能帮助您快速完成数据集成、开发、治理、服务、质量、安全等全套数据研发工作。
图27-1:37
盘古:分布式文件系统,相当于Hadoop 中的 HDFS。
伏羲:分布式调度系统,相当于Hadoop 中的 YARN。
MaxCompute Engine:统一计算引擎,相当于MR、Tez等计算引擎。
MaxCompute 和 DataWorks 一起向用户提供完善的ETL 和数仓管理能力,以及 SQL、MR、Graph 等多种经典的分布式计算模型,能更快速地解决用户海量数据计算问题,有效降低企业成本,保障数据安全。
第5章 用户数据行为数仓搭建
5.1 数仓分层概念
5.1.1 数仓分层
图29-1:37
- ODS层:原始数据层,存放原始数据,直接加载原始日志、数据、数据保持原貌不做处理(备份)。
- DWD层:对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)
- DWS层:以DWD层为基础,进行轻度汇总。
- ADS层:为各种统计报表提供数据。
5.1.2 数仓分层优点
- 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简、并且方便定位问题。
- 减少重复开发:规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据:不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
5.1.3 数仓命名规范
- ODS层命名为ods前缀。
- DWD层命名为dwd前缀。
- DWS层命名为dws前缀。
- ADS层命名为ads前缀。
- 维度表命名为dim前缀。
- 每日全量导入命名为df(day full)后缀。
- 每日增量导入命名为di(day increase)后缀。
5.5 DataHub 推送数据到MaxCompute
之前 Flume 中的数据利用 DataHub Sink 把数据写入到了 DataHub 中,DataHub 中提供了很多的其他第三方的 DataConnector 可以连接各种例如:MaxCompute,ElasticSearch,ADB,RDS等数据库。
所以就要建立 DataConnector 把数据推送到 MaxCompute 中。
5.6 明细数据层(DWD层)
DWD 层主要是对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)。DWD 层处理后的表,能够成为非常明确可用的基础明细数据。
5.6.1 日志格式分析
1)日志格式:服务器时间 | json
2)其中 json 包括:
cm:公共字段的 key;
ap:app 的名称;
et:具体事件。
5.6.2 自定义UDTF(解析具体事件字段)
开发 UDTF 有两个方法:
- 方法1:在本地 IDEA 中创建工程,开发代码,打包,把 JAR 上传到 DataStudio 成为资源 JAR 包。然后基于资源 JAR 包,声明函数。
- 方法2:直接在 FunctionStudio 中开发,然后在线打包发布程序,声明函数。相比而言,从发布流程上来说,利用 FunctionStudio 更快捷方便。但是从 IDEA 开发角度来说,网页版本的 FunctionStudio,肯定不如客户端的功能强大、反应速度流畅。不多也可以两者配合起来使用。
p34:未详细学习。
5.6.5 数据导入脚本
1)在流程中加入一个数据开发脚本
去重有两种方式:
1.按照某一个字段进行 group by;
2.开窗函数。
向 dws_uv_detail_d 表中插入数据,数据来源于一个子查询;
子查询里是一个开窗,对于 mid(设备id)进行开窗,开窗之后只取第一条。
INSERT OVERRITE TABLE dws_uv_detail_d PARTITION (ds,hh,mm)
SELECTmid,user_id,version_code,version_name,lang,source,os,area,model,brand,sdk_version,email,height_width,network,lng,lat,event_time,ds,hh,mm
from
(select*,ROW_NUMBER() OVER(PARTITION BY mid ORDER BY event_tion asc) AS rn from dwd_start_logwhere ds='20191008'
) st where rn = 1;
5.7.3 数据导入脚本
DWS 层一般围绕某个主题进行聚合、拼接处理。
针对统计日活的需求,DWS 主要的工作就进行以日为单位的去重操作。
1)在流程中加入一个数据开发脚本
在数据开发中,新建一个ODPS SQL
图39-00:18
5.8 应用数据层(ADS层)
统计各个渠道的 uv 个数
第6章 业务数仓理论
6.1 表的分类
6.1.1 实体表
实体表:一般是指一个实现存在的业务对象,比如用户、商品、商家、销售员等等。

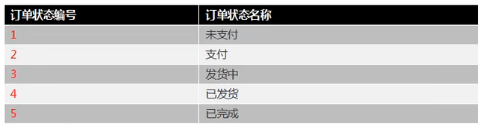
6.1.2 维度表
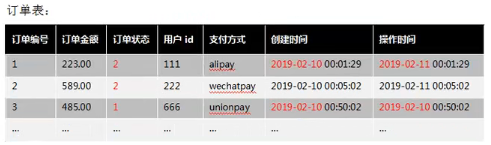
维度表:一般是指对应一些业务状态,编号的解释表。也可以称之为码表。比如地区表,订单状态,支付方式,审批状态,商品分类等等。

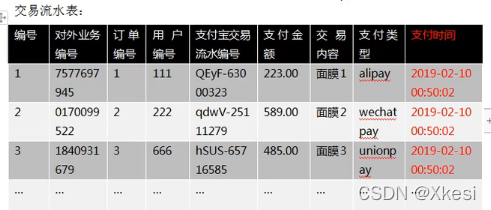
6.1.3 事务型事实表
事务型事实表:一般指随着业务发生不断产生的数据。特点是一旦发生不会再变化。一般比如:交易流水,操作日志,出库入库记录等等。
6.1.4 周期型事实表
周期型事实表,一般指随着业务发生不断产生的数据。
与事务型不同的是,数据会随着业务周期性的推进而变化。
比如订单,其中订单状态会周期性变化。再比如,请假、贷款申请,随着批复状态在周期性变化。
6.2 同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表。
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
6.2.1 实体表同步策略
实体表:比如用户、商品、商家、销售员等。
实体表数据量比较小:通常可以做每日全量,就是每天存一份完整数据,及每日全量。
6.2.2 维度表同步策略
维度表:比如订单状态,审批状态,商品 分类。
维度表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
说明:
- 针对可能会有变化的状态数据可以存储每日全量。
- 没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
6.2.3 事务型事实表同步策略
事务型事实表:比如交易流水,操作日志,出库入库记录等。
因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
6.2.4 周期型事实表同步策略
周期型事实表:比如,订单、请假、贷款申请等。
这类表从数据量的角度,存每日全量的话,数据量太大,冗余也太大。如果每日增量无法反应数据变化,则导每日新增及变化量,包括了当日的新增和修改。
第7章 业务数仓搭建
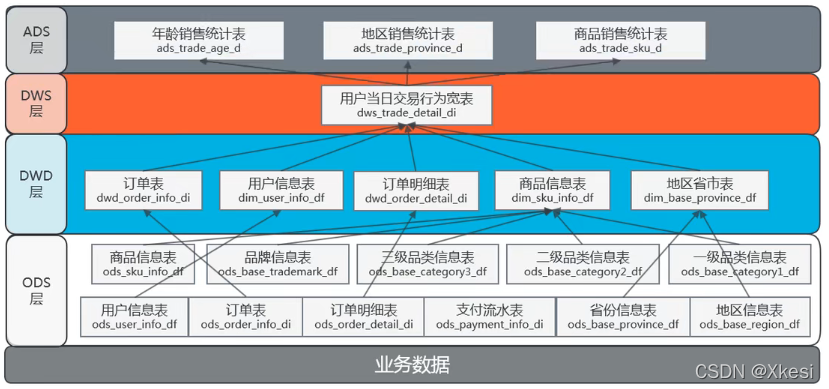
7.1 业务数仓架构图
7.2 RDS 服务器准备
7.2.1 RDS 服务器购买
阿里云关系型数据库(Relational DataBase Service, 简称 RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务器。
7.5.3 每日增量表同步
1)同步策略:每日增量
每日新增的表包括:ods_order_detail
每日增量的区别就是要按照日期进行过滤,只筛选出今天新产生的数据。
条件:
DATE_FORMAT(create_time,'%Y%m%d') = '${bizdate}'
7.5.4 每日新增及变化表同步
1)同步策略:每日新增及变化
每日新增及变化的表包括:ods_order_info
条件:如果创建时间是当日或者操作时间是当日,则满足条件。
DATE_FORMAT(create_time, '%Y%m%d')='${bizdate}' or
DATE_FORMAT(operate_time, '%Y%m%d')='${bizdate}'
7.6 DWD层
DWD 层,一般是对 ODS 层数据进行一定的清洗加工,如果是面对关系导入过来的数据表,还要把原本的关系型表结构,进行一定程度的维度退化。作为更易处理的明细数据。
比如:
ODS 地区 + ODS 省份 => DWD 省份地区
ODS 商品信息 + ODS 品牌 + ODS 商品一级分类 + ODS 商品二级分类 + ODS商品三级分类 => DWD 商品信息
7.6.2 手动将数据导入 DWD 层
1)在临时查询中执行
Insert overwrite table dwd_order_info_di partition(ds)
Select id,total_amont,order_status,user_id,payment_way,out_trade_no,province_id,create_time,operate_time,ds
from ods_order_info_di
where ds='${bizdate}' and id is not null; //过滤条件:id不能为空insert overwrite table dwd_order_detail_di partition(ds)
select od.id,order_id,oi.user_id,sku_idsku_name,order_price,sku_num,oi.province_id,od.create_time,od.ds
from ods_order_detail_di od join ods_order_info_di oi and od.ds = '${bizdate}' and od.id is not null;//商品表
insert overwrite table dim_sku_info_df partition(ds)
select sku.id,sku.spu_id,sku.price,sku.sku_name,sku.sku_desc,sku.weight,sku,tm_id,tm.tm_name,sku.category3_id,c2.id category2_id,c1.id cate gory1_id,c3.name category3_name,c2.name category2_name,c1.name category1_name,sku.create_time,sku.ds
from
(select *form ods_sku_info_dfwhere ds='${bizdate}' and id is not null
) sku
join ods_base_category3_df c3 on sku.category3_id = c3.id and c3.ds = '${bizdate}'
join ods baase category2 df c2 on c3.category2_id = c2.id and c2.ds = '${bizdate}'
join ods_base_category1_df c1 on c2.category1_id = c1.id and c1.ds = '${bizdate}'
join ods_base_trademark_df tm on tm.tm_id = sku.tm_id and tm.ds = '${bizdate}';insert overwrite table dim_user_info_df partition(ds)
select id,name,birthday,gender,email,user_level,create_time,ds from ods_user_info_df
where ds='${bizdate}' and id is not null;insert overwrite table dim_base_province_df partition(ds)
select p.id,p.name,p.region_id,r.region_name,p.ds
from ods_base_province_df p join ods_base_region_df r
on p.region_id = r.id and p.ds='${bizdate}' and r.ds = '${bizdate}';7.7 DWS层
DWS 层主要指针对明细粒度的数据进行短周期的汇总。DWS 公共汇总层是面向分析对象的主题聚集建模。
在本教程中,最终的分析目标为:最近一天某个类目、某个地区、某类人群购买商品的销售总额、购买力分析。因此,我们可以以最终交易成功的商品、买家、地区等角度对最近一天的数据进行组合 ,组合成为涵盖多个维度的事实宽表。
7.8 ADS层
ADS 层主要是指针对某一个特定的维度进行的汇总。
在本课程中,主要分析三个需求:用户各个年龄段统计、地区销售统计、热门商品排行。所以主要是针对年龄、地区、商品进行汇总统计,统计四个指标下单数、购买商品个数、销售额、平均客单价。
第8章 数据导出与作业调度
将 MaxCompute 中的计算完的结果,需要导入到RDS数据库中,用于后续的可视化。
8.1 创建结果数据库
1)在 RDS 服务器中,新建一个 gmall_adb 数据库,用来保存之后从 MaxCompute 中的结果数据。
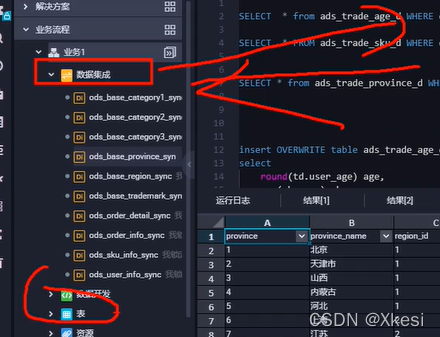
8.2 创建商品销售数据同步节点
将ADS层数据导出到 MaxCompute。
1)数据开发 -> 数据集成 -> 新建数据集成节点 -> 数据同步
数据集成:用于 MaxCompute 对外的输入输出。
数据开发:是 MaxCompute 内部层与层之间的脚本编写。
函数使用总结)




![[转]svn常用命令](http://pic.xiahunao.cn/[转]svn常用命令)






)






)