文章目录
- 1. FIS 系统(Fuzzy Inference Systems)
- 1.1 什么是 FIS 系统?
- 1.2 使用 FIS 算法的几个步骤
- 2. GFS 系统(GA + FIS)
- 2.1 什么是基因遗传算法(GA)?
- 2.2 使用GA算法进化FIS规则库
在大规模的多智能体集群协同任务中,DRL往往很难取得较好的效用。一旦智能体数目规模变大,联合行为空间和联合观测空间规模就会变得巨大无比,因此在许多大规模的多智能体协同任务中,基于规则的控制器是解决规模庞大问题的一个有效的方法。但基于规则的方法缺陷在于:面对一个陌生场景下人们往往很难以制定出一套较好的规则库,这里的规则是指在 “什么样的情况下” Agent 应该采取什么样的 “行为”,其中 “情况” 和 “行为” 在大多数情况下我们都能够较为容易的获得,但 “情况-行为” 的规则映射是难以事先确定的。为此,人们想到可以预先定义一些随机的规则,通过遗传算法来尝试对这些规则进行重组,通过查看新规则在场景中的得分,摒弃低得分的规则,保留高得分的规则,最终自我学习出一套较为完备的规则库,这就是 GFS 的由来。
【参考连接】:GFS原理链接,FIS代码包链接。
1. FIS 系统(Fuzzy Inference Systems)
1.1 什么是 FIS 系统?
FIS(Fuzzy Inference Systems)的全称是模糊推理系统,其主要作用是对变量做 “模糊化” 和 “去模糊化”(参考资料:这里)。那么什么是模糊化和去模糊化?这里用一个例子作为引入:假设你是一个应届毕业生,现在需要选择一个工作,那么你在挑选工作的时候可能会有这么几个标准:
- 薪资高,工作时长少,优先考虑
- 薪资高,工作时长一般,一般考虑
- 薪资一般,工作时长长,一般考虑
- 薪资低,不考虑 (不管工作时间长短,只要工资低就不考虑)
现在有几家 offer 摆在了你面前,工作时长和薪资待遇都开放给你,你需要设计一个系统来帮你选择去哪一家公司,你该如何让计算机来理解你的标准呢?你该怎么样让计算机明白薪资多少算是 “高”,多少工作时长才算 ”长“?其实这里的 “薪资高” 和 “时长少” 都是人们内心的主观概念,人们也很难具体说出一个具体的数字,只能根据一个具体的数字来大致判断这个数字是 “多” 还是 “少”,这就是 “模糊逻辑” 的概念,即将一个连续变量的值做模糊化,使其具体的数值被模糊为一个程度值。这里可以简单理解为将一个具体的数值做分类,其被分类为 “少”、“中”、“多” 三类中的哪一类(真实得到的输出是这个值被分为这三类分别的置信度是多少,这和 softmax 函数的概念很像,如果不能理解就简单理解为归类为着三类中的其中一类就行了)。
因此,FIS 的核心思想就在于:将连续变量模糊化,根据既定的规则得到一个模糊化的行为,最终再将这个行为去模糊化。 注意,通过模糊化后推理出的行为也是一个模糊变量,拿上面的例子来说,在薪资高工作时长一般的时候,所采取的行为是 “优先考虑”,代表你很愿意去选择这个工作,“愿意程度” 其本质也应该是一个模糊变量,最终具体选择这个工作与否需要你自己根据 “愿意程度” 来作参考进行选择,这个过程就叫做 “去模糊化”。
1.2 使用 FIS 算法的几个步骤
使用 FIS 算法做推理包含以下几个关键性的步骤:
- 对输入变量做模糊化(分配隶属函数)
- 制定推理规则(根据输入值推断行为动作)
- 行为模糊变量推理,去模糊化行为变量
- 得到具体行为
以上 4 步是使用 FIS 算法最基本的 4 个步骤,下面将结合上面说到的找工作例子,使用 FIS 模糊推理来根据不同 offer 的薪资和工作时长来决定是否接受这个 offer。
- 输入变量模糊化(分配隶属函数)
我们之前提到,对于一个输入变量具体值,我们需要对其进行模糊化,使其变为 “程度变量”,隶属函数的作用就是用来表征一个具体变量值属于“高”、“中”、“低”三种程度的置信度。我们假设给定薪资范围为:20 ~ 32(w),工作时长为:6 ~ 12(小时),我们画出这两个变量的隶属函数图像:
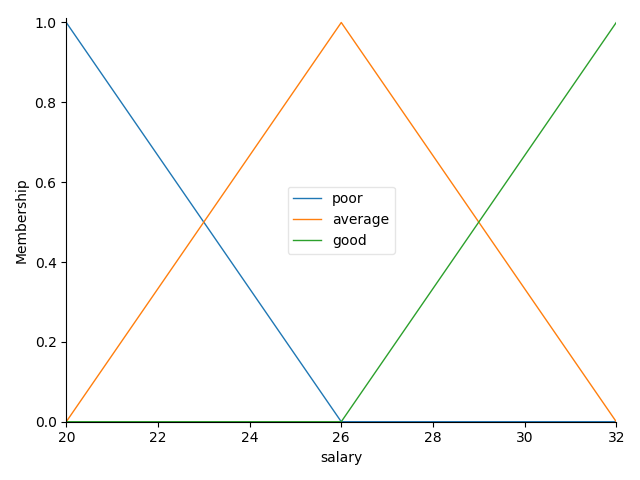
其中,“poor”、“average”、“good” 分别代表 “低”、“中”、“高” 三种不同的程度,隶属函数就是这个三角形的函数。怎么根据隶属函数来判断一个具体的薪资值属于哪一种程度呢?我们看这个图的纵坐标,这是一个 0 ~ 1 的取值,y 轴的值就是代表这个值属于这个程度的“置信度”。举例来说,我们看横坐标为 26 的点,这个横坐标对应的黄色线(average)的 y 值取值为 1,这代表 26w 的年薪在整个年薪区间中属于 “薪资中等” 这一个程度。我们现在换一个不这么特殊的点,当横坐标为 24 的时候,蓝线(poor)和黄线(average)都会有其对应的 y 值,蓝线取值大概在 0.4 左右,黄线取值大概在 0.6 左右,这意味着 24w 的薪资有 0.4 的置信度被认为是 “薪资低”,0.6 的置信度被认为是 “薪资中等”。因此,通过隶属函数我们能够轻松的将一个输入的 “具体值” 映射到一个 “程度” 上,这就是输入变量的模糊化。 工作时长的隶属函数也是同理,这里直接放上结果图,不再做分析:

- 制定推理规则(根据输入值推断行为动作)
至此,我们已经成功将输入变量模糊化了,接下来我们需要制定规则,即在什么情况下采取什么样的行为。参照 1.1 中提到的 4 条规则,这里我们把这些规则变成 FIS 算法内部需要的规则格式。在 FIS 算法中,一条规则长这个样子:
If "薪资高" and "工作时长少" Then "很愿意接受这份工作"
可以看出来,在 FIS 算法内部,规则由 “规则前件” + “行为后件” 组成,即 If 后面到 Then 之前的部分为规则前件,由多个模糊变量组成,各模糊变量之间由逻辑运算符 and 或者 or 连接;Then 之后为行为后件,代表在这样的规则下应该采取哪一个行为。逻辑运算符 and 和 or 用于表示各模糊变量之间的关联关系,这里的 and 和 or 和平时理解的稍有不同,平时 and 和 or 都是 0 和 1 之间运算,即 1 and 0 = 0,1 or 0 = 1。在 FIS 中,模糊变量的取值并不是非 0 即 1(因为是置信度),而是有可能为一个 float 值(0 ~ 1之间),因此这里的 and 指取两个变量值中的最小值,or 指取两个变量值中的最大值。(Example:0.8 and 0.2 = 0.2;0.7 or 0.4 = 0.7)
我们把上面的 4 条规则全部列举出来,形成该问题下的 “规则库”:
If "薪资高" and "工作时长少" Then "很愿意接受这份工作"
If "薪资高" and "工作时长中等" Then "中等愿意接受这份工作"
If "薪资中等" and "工作时长很长" Then "中等愿意接受这份工作"
If "薪资低" Then "不怎么愿意接受这份工作"
这样我们就能根据一组模糊变量来推得一个行为的模糊变量,即接受这份工作的 “愿意程度”。
- 行为模糊变量推理,行为变量去模糊化
至此输入模糊化和规则库都已经定义好了,我们现在就可以根据一组具体的输入数据来推理出行为模糊变量了,我们这里举例薪资为 22w,工作时长为 8 小时,输入该系统会得到怎么样的推理。首先对输入薪资 22w 进行模糊化,通过查看隶属函数,我们能够发现 22w 属于 “较少程度” 的类型,且置信度为 0.64 左右:
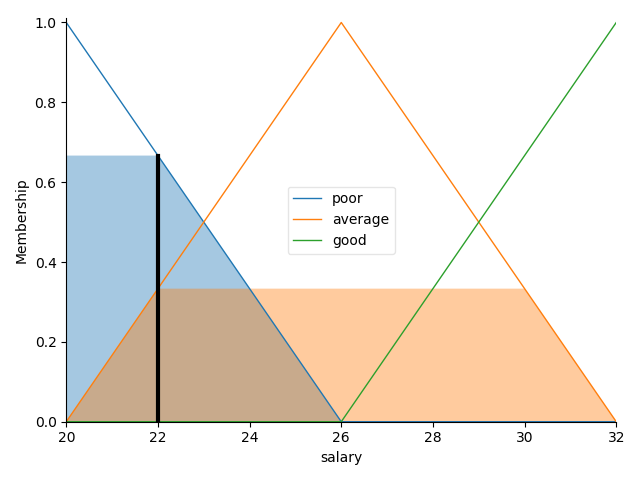
再对 worktime 做模糊化,可以得到 8 个小时的工作时间属于 “中等程度”,且置信度为 0.66 左右:
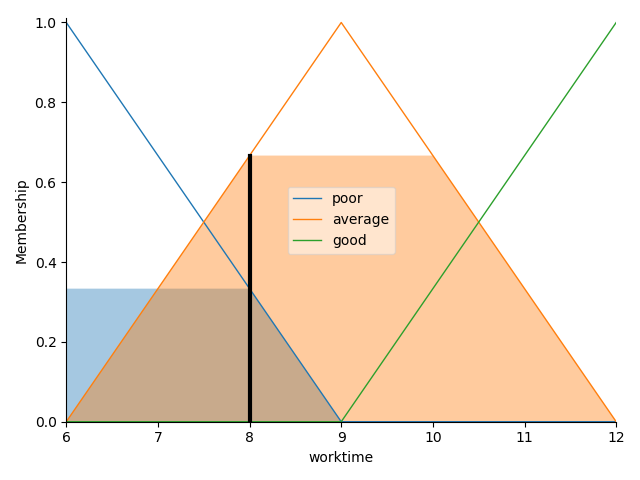
这样我们就分别得到了 worktime 和 salary 的所属程度类别以及他们的置信度,此时我们去规则库中寻找对应的规则:薪资为 “少” 且工作时长为 “中等” 的规则,通过查找与上述最后一条规则匹配:
If "薪资低" Then "不怎么愿意接受这份工作"
因此我们所采取的行为应该是 “不怎么愿意接受这份工作”,但我们之前说到,这个推理出的行为变量同样是一个 “模糊变量”(程度变量),代表着接受这个工作的 “愿意程度”。那么怎么去确定这个变量的置信度(这里可以理解为愿意程度)呢?这里就需要引入 “strength” 的概念,即 “置信强度 ” 的概念。其实这个值很好计算,如果规则是 A and B,那 strength 就等于 A 的置信度和 B 的置信度中较小的那一个,如果规则是 A or B,则取两者置信度较大的即可。由于这里我们定义只要 “薪资低” 就不用考虑这个工作了,所以这里 strength 就等于薪资低的置信度 0.64,“接受行为” 的模糊变量隶属函数如下:
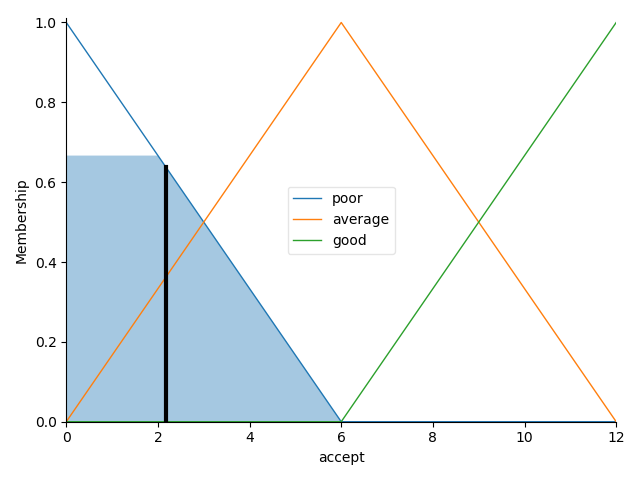
我们 strength 值(0.64)去对相应的行为程度(规则中是 “不大愿意接受”)进行截取,截取后我们就可以得到一个输出分布(Output Distribution),图中浅蓝色填充的部分就是输出分布。如何去根据输出分布确定行为的模糊程度值呢(去模糊化)?这里有两种方法:Mean of Maximum(mmo)法、Center of Mass(com)法。
mmo 法是指找到被截区域最高的直线部分,取直线中点横坐标作为行为去模糊化后的值,如下图所示:

com 法是指取被截区域的质心,将质心点的横坐标作为行为去模糊化后的值,如下图所示:
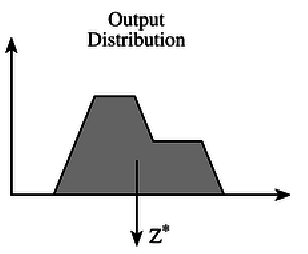
在我给的例子中我选用的是 com 质心法,可以看到去模糊化后 “愿意接受” 变量的行为值为 2.1 左右。
- 得到具体行为
现在我们已经拿到了行为的 “愿意程度值” 了,现在要参考这个值作为行为决策了。这个部分的自由度就比较高了,你可以按照你自己的想法来进行行为决策,例如这里我将愿意程度范围取值为 [0, 12],而最后可采取的行为只有 “接受” 和 “不接受”,因此我定义 “当愿意程度小于 6 则不接受”,“愿意程度大于 6 则接受”,上述例子中的行为值只有 2.1,因此选择不接受该 offer。
- 一些特殊情况
- 在有些时候,规则库中可能存在若干个规则对应同一个行为,那么应该怎么选择 strength 呢?答案是选择最小的 strength 作为截断置信强度。例如:
If "薪资高" and "工作时长很长" Then "中等愿意接受这份工作"和If "薪资中等" and "工作时长中等" Then "中等愿意接受这份工作"都对应的是 “中等愿意接受这份工作”,前者的 strength 是0.32,后者的 strength 为0.53,那么最后我们在做截断的时候就选择较小的 0.32。 - 一个行为包含若干个 “程度隶属函数” 怎么办?答案是将整个范围内的输出分布合起来,若不同程度的隶属函数之间有交集,则选择较大值,如下图所示:

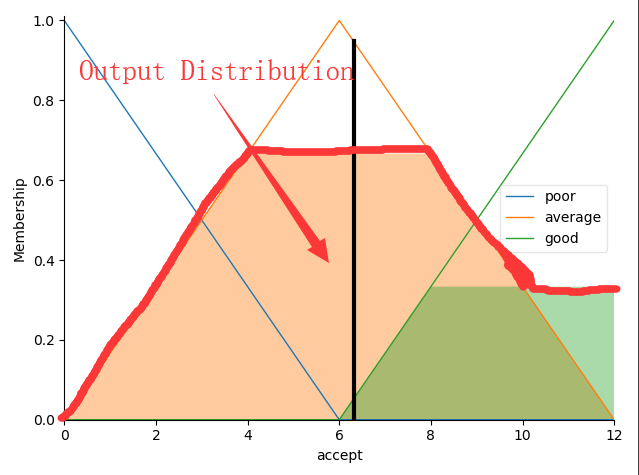
红色划线部分为最终的联合输出分布,行为的横坐标为划线部分的质心点横坐标。上述例子的薪资输入为 30w,工作时长为 8 小时,通过规则推理 “高薪资” + “一般工作时长” = “中等愿意接受工作”,可见 FIS 最终计算出的 accept 行为的去模糊值也落在 6.1,正好是 “中等愿意接受” 的范围,和我们的预期相符。
- 实现代码
上述代码实现如下,代码中使用了模糊推理运算三方库 skfuzzy,安装命令:
pip install -U scikit-fuzzy
具体安装细节和 API 相关见:这里。
"""
@author: P_k_y
"""import skfuzzy as fuzz
import numpy as np
from skfuzzy import control as ctrlACTION_RANGE_MIN = 0
ACTION_RANGE_MAX = 13def main():# define fuzzy variablesalary = ctrl.Antecedent(np.arange(20, 33, 1), 'salary')worktime = ctrl.Antecedent(np.arange(6, 13, 1), 'worktime')# define fuzzy actionaccept = ctrl.Consequent(np.arange(ACTION_RANGE_MIN, ACTION_RANGE_MAX, 1), 'accept')# define the membership functionsalary.automf(3)worktime.automf(3)accept.automf(3)salary.view()worktime.view()# define the rulesrule1 = ctrl.Rule(salary["good"] & worktime["poor"], accept["good"])rule2 = ctrl.Rule(salary["good"] & worktime["average"], accept["average"])rule3 = ctrl.Rule(salary["average"] & worktime["good"], accept["average"])rule4 = ctrl.Rule(salary["poor"], accept["poor"])# define the simulationaccept_actor_ctrl = ctrl.ControlSystem([rule1, rule2, rule3, rule4])accept_actor = ctrl.ControlSystemSimulation(accept_actor_ctrl)# compute the final resultaccept_actor.input["salary"] = 30accept_actor.input["worktime"] = 8accept_actor.compute()print("How much would like to accept this offer: %.2f%%" % (float(accept_actor.output['accept']) / (ACTION_RANGE_MAX - 1) * 100))accept.view(sim=accept_actor)salary.view(sim=accept_actor)worktime.view(sim=accept_actor)if __name__ == '__main__':main()2. GFS 系统(GA + FIS)
2.1 什么是基因遗传算法(GA)?
GA(Genetic Algorithm)算法是一种仿生学算法,其仿照生物进化时基因通过不断重组和变异,优胜劣汰,最终生存下来的都是优秀的基因群组的原理。当我们现在有一堆规则的时候,我们并不能保证这些规则中定义在一种 “情况” 下采取某种 “行为” 是最优的,因此我们可以考虑使用遗传算法,将规则中的不同 “情况” 和不同 “行为” 做重组形成新的规则,最后按照这些新规则的表现好坏来决定保留或是摒弃这些新产生的规则。在有些很复杂的场景下,我们无法为规则库中的每一条规则手动赋予对应行为,因此一般来说我们会为每一种 “情况” 随机赋予一个 “行为”,再通过遗传算法来学习到一个 “情况” 下所对应的最高效用的 “行为”。
我们还是拿找工作的例子来做说明,薪资待遇有高、中、低三种等级,工作时长同样有高、中、低三种程度等级,则这两个模糊变量做组合一共可以得到 3 * 3 = 9 条规则,因此一个完整的规则库应该包含 9 条规则:
If "薪资高" and "工作时长长" Then ...
If "薪资高" and "工作时长中等" Then ...
If "薪资高" and "工作时长少" Then ...
If "薪资中等" and "工作时长长" Then ...
If "薪资中等" and "工作时长中等" Then ...
If "薪资中等" and "工作时长短" Then ...
If "薪资短" and "工作时长长" Then ...
If "薪资短" and "工作时长中等" Then ...
If "薪资短" and "工作时长短" Then ...
规则前件的组合我们可以通过穷举列出来,但是所对应的行为怎么办呢,我们无法为每一个规则前件都赋予一个适合的动作行为,因此通常来说我们都可以随机初始化这些前件对应的动作值,在这个例子中我们 “愿意接受offer” 模糊变量同样也有高、中、低三个程度,我们用数字 0、1、2 来分别代替这3个行为变量,于是初始规则库变为了:
If "薪资高" and "工作时长长" Then 0
If "薪资高" and "工作时长中等" Then 1
If "薪资高" and "工作时长少" Then 1
If "薪资中等" and "工作时长长" Then 0
If "薪资中等" and "工作时长中等" Then 2
If "薪资中等" and "工作时长短" Then 1
If "薪资短" and "工作时长长" Then 2
If "薪资短" and "工作时长中等" Then 0
If "薪资短" and "工作时长短" Then 0
011021200 就代表了规则库策略,因为规则前件的顺序是不变的,因此这一串数字就是我们的规则库策略,能够根据一中特定情况来选择一个行为。但是这个数字串是我们随机生成的,并不具有好的策略效用,因此我们需要通过遗传算法来对这串数字串进行进化,从而得到一个具有较高得分的规则库策略。
2.2 使用GA算法进化FIS规则库
使用 GA 算法优化 FIS 规则库通常包括以下几个步骤:
- 建立初始规则染色体群(population)→\rightarrow→ Initialize
- 染色体群中各规则染色体(chromosome)之间交叉/变异,得到新一代规则染色体群 →\rightarrow→ Train
- 在重复若干轮进化迭代后,保存当前代染色体群中得分最高规则染色体,将其作为学习出的最优策略 →\rightarrow→ Save
- 建立初始规则染色体群(population)
一个染色体群 population 中包含多条规则染色体,其中规则染色体是指一个具体的规则策略,2.1中提到的 “011021200” 就是一条规则染色体,其代表了一个具体的规则策略。初始的 population 中会包含多条 chromosome,一般都是通过随机生成来得到的,chromosome 的长度为规则库中所有规则的数目总和(该示例中为 9 ),例如一个 size 为 5 的 population 如下:
011021200
222010120
010201020
111020012
210120120
- 进化规则染色体群
初始的染色体群是我们随机生成的,里面的每一条规则染色体都不一定具有较好的效用,因此我们需要对该群组进行进化训练,进化训练一共分为以下 3 个步骤:选择下一代父染色体群(select)、染色体交叉重组(cross)、染色体变异(mutate)。
- 选择下一代父染色体群(select)
由于染色体进化是一轮一轮迭代的,因此在下一轮进化迭代时我们需要选择保留这一轮中哪些优秀的染色体到下一轮。这和 “优胜劣汰” 的思路很像,我们将这一代中那些得分高的规则染色体按较高概率保留到下一代中去,将那些得分低的规则染色体按照较低的概率保留,其中规则染色体的 “得分” 是通过将这个规则染色体应用到实际问题中去运行得到的反馈回报。例如,011021200 这个染色体中,对于 “薪资高” 且 “工作时长短” 这一个情况选择的是 “不太愿意接受这个 offer” 这个行为,那很明显你会觉得这是一个很差的行为决策,因此你会给这条规则染色体一个很低的得分,以表示这个规则是很差的规则,尽量不要保留到下一代 population 中去。具体示例如下:
当代染色体群:011021200 -> 0.82 score 222010120 -> 0.22 score010201020 -> 0.35 score111020012 -> 0.19 score210120120 -> 0.08 score下代父染色体群:011021200 (0.82 )011021200 (0.82 )010201020 (0.35 )011021200 (0.82 )222010120 (0.22 )
上面展示了一个具体的例子,上半部分 -> 后代表的是当代的当前染色体得分,下半部分()内是该染色体在上代染色体群中的得分。可以看出,当代染色体群中得分越高的染色体越有较高的概率被保留到下一代中去。
- 染色体交叉重组(cross)
染色体交叉重组是指一个 population 中相邻的两条染色体之间进行交叉重组,从而得到新的规则染色体。交叉重组过程首先会随机在染色体中随机选择一个点作为交换切断点,两条染色体交换被切断点切断的染色体片段,具体示例如下:
交叉前:01102 1200 # chromosome 1,切断点 index 为 5 ( 1 条规则染色体被分为 2 段)22201 0120 # chromosome 2,切断点 index 为 5 ( 1 条规则染色体被分为 2 段)交叉后:22201 1200 # 新的子代 chromosome 1(与另一染色体交换了第 1 个染色体片段)01102 0120 # 新的子代 chromosome 2(与另一染色体交换了第 1 个染色体片段)
- 染色体变异(mutate)
染色体变异是指在一条染色体上的某一个位置上的基因发生突变,基因突变分为前向突变与后向突变,首先随机选择一个突变切断点,前向突变指切断点前面的基因全部随机突变成另一个行为值,后向突变指切断点以后的基因全部随机突变为另一个行为值,例如:
突变前:01102 1200 # 切断点 index 为 5 ( 1 条规则染色体被分为 2 段)前向突变:10201 1200 # 前向突变子代 chromosome(突变断点前的基因均重新随机取值)后向突变:01102 2012 # 后向突变子代 chromosome(突变断点后的基因均重新随机取值)
- 保存最优规则策略
在完成了若干轮的进化后,通过筛选出该 population 中得分最高的一条 chromosome 即可得到最优规则策略。在设定进化轮数的时候,我们可以使用阈值限定的方法,查看在一轮中最高得分的规则染色体得分是否到达了我们设置的阈值点,如果已有染色体满足了我们设置的得分阈值即可停止进化,并保存满足得分的规则染色体作为最终策略。
至此,这就是对 GFS 系统的全部内容讲解了,完整 GFS 代码可以参见 我的GitHub。

)





介绍 - 什么是 Blazor?)


—点击展示与隐藏全文)
用法比较)







