摘要:随着互联网的发展,数据的规模和类型都呈现一个爆炸性的增长,对于这么多类型的数据,如何进行有效的管理和存储,包括数据的分析,这是大家要面临的一个问题。在武汉云栖大会上,阿里云高级产品专家吴华剑做了名为“企业数据创新之旅-构建自己的数据湖”的精彩演讲。
阿里云存储产品系列
随着互联网的发展,整个云存储数据量的规模呈爆炸性的增长,包括日志型、交易、应用等数据,而且数据类型也越来越丰富。面对这样的需求,阿里云存储推出了一系列的云数据库类型,包括块存储、文件存储、对象存储、OSS归档存储和表格存储等。对于传统企业上云,阿里云也推出了面向混合云的产品,比如混合云存储阵列、容灾备份一体机、备份服务、闪电立方等产品。阿里云有这么全面的产品家族,那是什么支撑着呢?其实是因为阿里云有自研的分布式存储系统:盘古高性能存储引擎。目前盘古的存储不仅支撑阿里云公有云上的存储产品,也是阿里巴巴集团内部,像天猫、淘宝、蚂蚁金服等各类服务存储的基石。针对于面向金融、人工智能、能源、制造业等各个场景的低延时到高吞吐的存储需求,阿里云都有相应的产品类型。
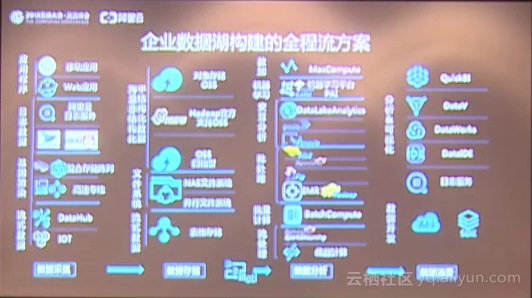
在整个企业数据湖的构建过程当中,从数据的采集到数据存储再到分析和消费,其实是有分多个阶段的,在这多个阶段里面,阿里云推出了一系列的解决方案。例如在数据采集方面,阿里云可以支持应用程序数据、日志数据、基因数据、流失的数据等等。另外阿里云推出了阿里云日志存储服务,OSS也支持像开源日志导入的服务,同时针对IoT的数据也有像IoT、DataHub这样的数据采集的产品。在存储方面,阿里云推出了对象存储,可以支持海量的结构化和非结构化的数据存储,同时OSS也是Hadoop官方支持的默认存储类型,这也是中国唯一一家被Hadoop官方支持的存储产品,用户的Hadoop应用可以完全不改任何代码去处理OSS上的数据。同时阿里云的表格存储,能够非常好的支持像IoT这样的流失数据的存储。在整个数据湖构建的采集、存储、消费等整个流程,阿里云都提供了相应的解决方案,满足大家对数据湖的构建要求。
企业应用构建案例
阿里云存储其实不光是支持互联网音视频等普通数据的访问和读写,如今利用阿里云存储稳定、安全、可靠和高性能等的特点,结合阿里云丰富的机器学习平台、大数据、批量计算等产品以及阿里云与Hadoop官方的合作,阿里云存储可以进行离线分析、基因渲染等大规模数据的计算,满足不同场景的数据处理需求。现在已经应用到新能源、新媒体、包括点播、直播等应用场景。下面是两个企业应用构建的例子:
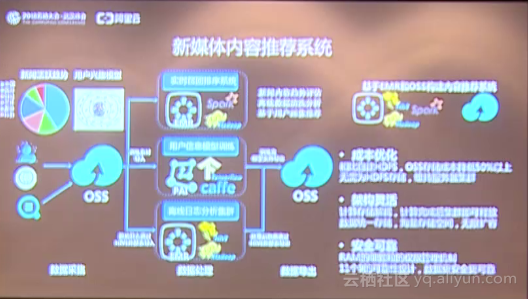
1.新媒体内容推荐系统 用户的访问日志,包括手机app、应用服务上收集的日志、新闻阅读的记录都可以导入到OSS上,满足海量存储的需求。同时Hadoop官方也支持OSS存储的应用,因此用户可以基于Hadoop生态的应用去搭建像离线分析的系统,并且可以利用机器学习进行用户兴趣的训练,训练完的模型数据也可以导入到OSS上面,形成数据处理的闭环,当用户用完整个架构系统之后,整个数据存储成本降低了50%以上。
2.批处理(在线视频日志)
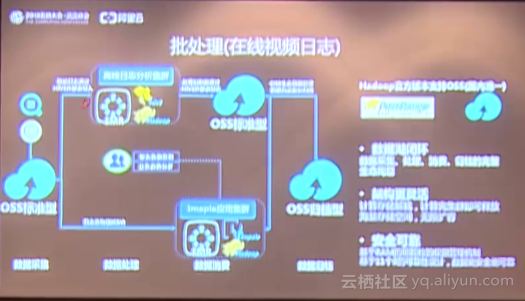
类似短视频的在线视频应用,如何保持竞争力呢?用户需要对终端用户访问的一些视频,做一些大数据的挖掘和分析,不断地去改进自己的产品设计。用户将日志数据上传到OSS上面之后,可以通过阿里云的Hadoop离线分析系统做分析,同时可以基于Hadoop应用去搭建集群,进行数据交互分析。由于用户每天产生的海量访问日志非常大,可能经过一段时间以后这个数据就没那么热了,用户不需要经常去分析和处理它,那用户可以通过OSS生命周期管理功能对数据进行自动归档。整个用户的数据采集、存储、消费和自动归档等流程都可以在OSS上处理。
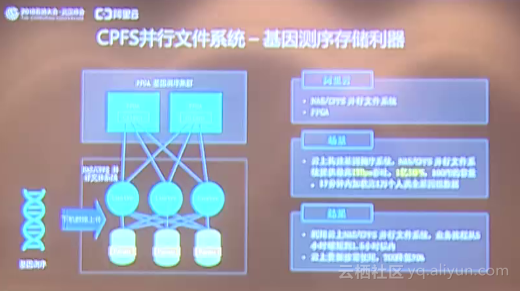
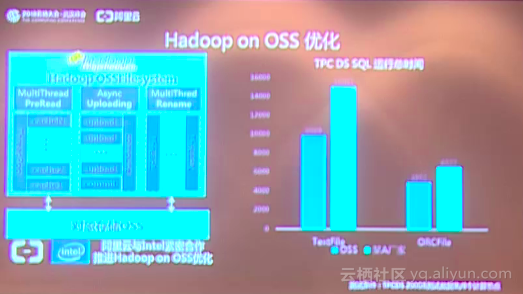
云存储技术引擎 阿里云存储针对数据进行计算和分析,在近期又取得了巨大的进展。首先是阿里云对于文件系统家族,推出了CPFS并行文件系统,这个产品阿里云正在公测,而且有些做科研的客户正在使用这个产品。CPFS并行文件系统有一个非常明显的特点,它可以极大地提高阿里云单用户的吞吐。同时阿里云和战略合作伙伴Intel一起在Hadoop社区里面,针对Hadoop的应用访问OSS做了大量的优化。Hadoop在访问OSS的时候,阿里云在Hadoop的客户端进行了多线程预读的优化,同时在整个数据写入到OSS的时候,阿里云也进行了异步的性能提升。另外对于元数据的操作,阿里云也进行了大量的优化。当整个系统优化完之后,阿里云进行了一个TPC DS测试,阿里云测试了200G的数据集并与其他厂商进行对比,阿里云OSS的运行效率提升了15%左右,可以为用户节省15%的计算资源,不但提升了业务的效率,而且大大降低了成本。
同时阿里云OSS在服务端也进行了大量的技术优化,最近阿里云会提供一个服务端预读的功能,阿里云面向像Hadoop的大数据分析、机器学习等场景会进行优化,会在近期上线,让大家使用。关于服务端优化,现在也已经有客户在使用,而且运行效率提升了35%以上,对客户的业务有很大的帮助。另外OSS select现在也开始公测,原来的数据存储到OSS之后,当读取数据的时候需要把整个数据都读取出来。比如搭一个spark应用的时候,需要把整个数据读取出来之后再去做一些分析和处理,现在可以使用OSS select功能,只要使用简单的SQL语句,就可以选取需要的内容,大大地减少运行的时间。阿里云也做了个基于OSS select的测试,整个运行时间从78秒减少到11秒,性能提升了600%。阿里云最近推出的DataLakeAnalytics产品,它可以支持对OSS上的产品做查询分析,将OSS上存储的CSV、TEXT、JSON和一些链式存储的数据,可以使用DataLakeAnalytics做查询分析,这个产品兼容标准SQL,包括JDBC、ODBC的标准,可以帮助大家快速去搭建一个查询、分析的平台,可以减少时间,提升研发效率。
以下是OSS select和DataLakeAnalytics的公测链接,大家可以扫描二维码去申请公测。




![BZOJ1565[NOI2009]植物大战僵尸——最大权闭合子图+拓扑排序](http://pic.xiahunao.cn/BZOJ1565[NOI2009]植物大战僵尸——最大权闭合子图+拓扑排序)














计算加减乘除的BUG)

