大家好,我是若川。三天假期总是那么短暂,明天就要上班了。今天推荐一篇相对简单的文章。
点击下方卡片关注我、加个星标

之前有同学在前端技术分享时提到了SEO,另一同学问我SEO是什么,我当时非常诧异,作为前端应该对SEO很了解才对,不过仔细想想,现在前后端分离的大趋势下,SPA单页WEB应用也随之兴起,现在的前端新生对SEO不了解也是有原因的,所以本次就带着大家重识SEO!
什么是SEO
 SEO(Search Engine Optimization),中文翻译成
SEO(Search Engine Optimization),中文翻译成搜索引擎优化,是指通过采用易于搜索引擎索引的合理手段,使网站各项基本要素适合搜索引擎的检索原则并且对用户更友好,从而更容易被搜索引擎收录及优先排序
发展史
SEO在国内起步比较晚,主要经历了四个发展阶段:
2003年初到2004年底,Google刚进入中国不久,SEO在国内刚刚起步
2004年底到2005年上半年, 全国涌现出上百家SEO公司
2005年下半年至2006年9月,SEO作弊泛滥成灾,严重破坏了市场秩序,威胁到搜索引擎的利益,SEO一度成为作弊的代名词,引起一些主流搜索引擎的大量清理
2006年9月至今,随着SEO培训的兴起,SEO技术越来越普及化也更加正规合理化
优点
成本低
利用SEO来给网站做优化,不仅提升网站的排名,还能增加搜索引擎的友好度。企业除支付相关人员的费用外,一般不需要投入其它费用,所以成本很低。
通用性强
SEO人员通过对网站机构、布局、内容、关键词等要素的合理设计,让网站符合搜索引擎的规则。虽然有很多搜索引擎,但你只要做好百度所搜引擎优化,其它的搜索引擎排名也会跟着提高。
稳定性好
正常情况下,只要是正规方法优化的网站,排名都会比较稳定。只有搜索引擎算法更改或者竞争对手更有优势,才会让网站出现比较大的变化。
公平性
在搜索引擎中,所有网站展示机会都是均等的,需要企业公平的竞争排名。搜索引擎不是根据网站的规模、知名度来作为排名的依据,而是综合多方面的因素,这样就给网站提供了一个公平竞争的环境。
有效规避无效点击
有些企业为了增加知名度而选择付费推广,这种点击收费的推广方式,会遭到同行业的恶意点击,让你的费用迅速用完。而利用SEO技术优化的网站就不会出现这种问题,同行业点击的越多,对网站越有利,可以增加搜索引擎的友好度,进而提升网站的排名。
缺点
见效慢
SEO需要人工来做的,不会立刻收到效果的。一般来说,从开始优化到关键词有排名需要1至3个月左右,如果是竞争激烈的关键词,可能需要更长的时间。
被动性
网站和搜索引擎是一种被动排名关系。网站的优化需要符合搜索引擎规则,这样才能让网站的排名靠前。搜索引擎的规则不是一成不变的,它会不定期的修改算法,将更好的内容展示给用户。因此,需要对网站的优化进行相对应的调整,以应对各种变化。
不确定性
SEO人员无法掌控搜索引擎运行规则的细节,只能通过经验来对网站进行优化,无法保证重要性的关键词需要多久能排在首页。另外,网站在搜索引擎的排名受到多种因素的综合影响,有可能出现优化后排名没有提升的情况。
原理
 通过总结搜索引擎的收录和排名规律,对网站进行合理优化,使你的网站在百度及其他搜索引擎网站的搜索结果排名提高。
通过总结搜索引擎的收录和排名规律,对网站进行合理优化,使你的网站在百度及其他搜索引擎网站的搜索结果排名提高。
爬行抓取,网络爬虫通过特定规则跟踪网页的链接,从一个链接爬到另一个链接,把爬行的数据存入本地数据库
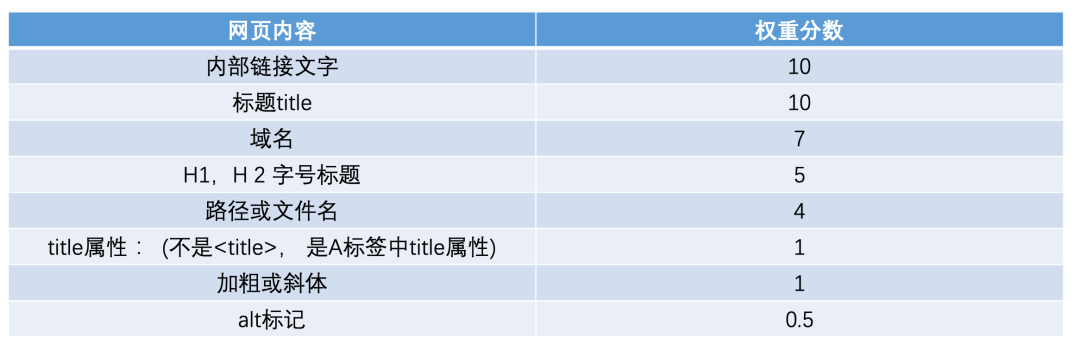
使用索引器对数据库中重要信息进行处理,如标题、关键字、摘要,或者进行全文索引,在索引数据库中,网页文字内容,关键词出现的位置、字体、颜色、加粗、斜体等相关信息都有相应记录。
索引器将用户提交的搜索词与数据中的信息进行匹配,从索引数据库中找出所有包含搜索词的网页,并且根据排名算法计算出哪些网页应该排在前面,然后按照一定格式返回给用户
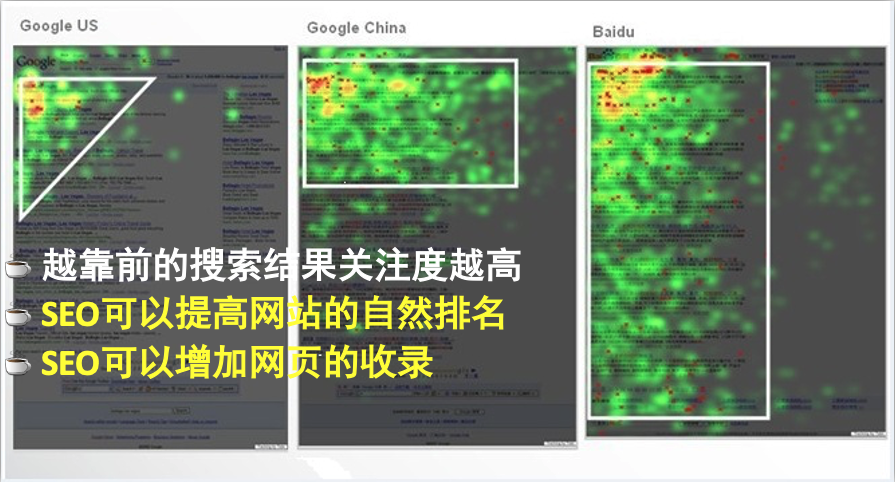
将检索的结果返回给用户,这就有一个先后顺序,搜索引擎的排序主要由以下方面共同确定:
三剑客:TDK
何谓 TDK?做前端的同学也都应该对它们熟稔于心:<title>标签、<meta name="description"> 标签和 <meta name="keywords"> 标签。顾名思义,它们分别代表当前页面的标题、内容摘要和关键词,对于 SEO 来说,title是其中最重要的一员。
<title> 标签
从用户的角度来看,它的值即用户在搜索引擎搜索结果中以及浏览器标签页中看到的标题,如下图:

title通常由当前页面的标题加几个关键词组成,同时力求简洁明了。总之,用最少的字让别人知道你接下来要说啥,控制在 40 字以内。比如:
<title>【转转】二手交易网,二手手机交易网,58闲置交易APP,转转客服</title>
好的 title 不仅让用户知道该页面要讲什么东西,提前判断有没有我需要的内容,对于搜索引擎也同样如此。所以,设置 title 时不但要注意以上几点,更重要的是,不要重复!
description
它通常不参与搜索引擎的收录及排名,但它会成为搜索引擎在搜索结果页中展示网页摘要的备选目标之一,当然也可能选取其他内容,比如网页正文开头部分的内容。以 title 部分的示例图对应的页面为例,它的 description 对应的内容是这样的:
<meta name="description" content="58同城“转转”为二手买卖双方提供快人一步的闲置交易平台,担保交易,微信支付,30秒发布,3天出手,让您随时随地买个便宜,下载转转APP,快速出手赚的更多!转转官方客服请联系微信公众号,转转暂未开通客服电话,请不要相信假冒转转的客服电话。">
可以看到,正是搜索结果摘要显示的内容。
有鉴于此, description的值要尽可能表述清楚页面的内容,从而让用户更清楚的认识到即将前往的页面是否对他有价值。同时字数最好控制在 80 - 100 字以内,各页面间不要重复!
keywords
<meta name="keywords" content="转转,二手闲置,二手交易网,二手手机交易网,转转APP下载,转转客服">它主要为搜索引擎提供当前页面的关键词信息,关键词之间用英文逗号间隔,通常建议三五个词就足够了,表达清楚该页面的关键信息,建议控制在 50 字以内。切忌大量堆砌关键词!
其他元信息标签
SEO 三剑客 “TDK” 都属于元信息标签。元信息标签即用来描述当前页面 HTML 文档信息的标签们,与语义化标签相对,它们通常不出现在用户的视野中,所以,只是给机器看的信息,比如浏览器、搜索引擎等
meta:robots 标签
撇开 “TDK”,其中与 SEO 相关的有一个 <meta name="robots"> 标签(通常含有 name 属性的 meta 标签都会有一个 content 属性相伴,这我们已经在 D 和 K “剑客”身上领略过了)。默认的,有这样的标签属性设置:<meta name="robots" content="index,follow,archive">。它跟上文中提到的带有 rel 属性的 a 标签略有相似。
| CONTENT | 含义 |
|---|---|
| INDEX | 允许抓取当前页面 |
| NOINDEX | 不许抓取当前页面 |
| FOLLOW | 允许从当前页面的链接向下爬行 |
| NOFOLLOW | 不许从当前页面的链接向下爬行 |
| ARCHIVE | 允许生成快照 |
| NOARCHIVE | 不许生成快照 |
通过以上三组值的相互组合,可以向搜索引擎表达很多有用的信息。比如,对于一个博客站来说,其文章列表页其实对于搜索引擎收录来说没什么意义,但又不得不通过列表页去爬取收录具体的文章页面,于是可以作如下尝试:
<meta name="robots" content="index,follow,noarchive">
canoncial 和 alternate 标签
还有一组标签是含有 rel 属性的 <link rel="" href="">标签,它们分别是:
<link rel="canoncial" href="https://www.zhuanzhuan.com" />
<link rel="alternate" href="https://m.zhuanzhuan.com" />
先来看 canoncial 标签。当站内存在多个内容相同或相似的页面时,可以使用该标签来指向其中一个作为规范页面。要知道,不只是主路由不同,即便是 http 协议不同(http/https)、查询字符串的微小差异,搜索引擎都会视为完全不同的页面/链接。假如有很多这种雷同页面,其权重便被无情稀释了。比如文章列表页有很多个,比如同一个商品页面的链接含有不同的业务参数等。以后者为例,假设有如下链接:
www.zhuanzhuan.com/goods/xxxxwww.zhuanzhuan.com/goods/xxxx?…www.zhuanzhuan.com/goods/xxxx?…
此时我们可以为后两者在 head 中添加 link 标签:
<link rel="canoncial" href="www.shop.com/goods/xxxx" />
以此彰显第一个链接的正统地位,告诉搜索引擎,其他那俩都是“庶出”,不必在意。假如搜索引擎遵守该标签的约定,则会很大程度避免页面权重的分散,不至影响搜索引擎的收录及排名情况。它的含义与 http``301 永久重定向相似,不同之处在于,用户访问标记了 canonical 标签的页面并不会真的重定向到其他页面。
再来看 alternate 标签。假如你为移动端和 pc 端设备分别提供了单独的站点,这个标签或许能派上用场。有两个链接如下:
https://www.zhuanzhuan.comhttps://m.zhuanzhuan.com
它们分别是转转网站首页的 pc 端和移动端,于是就可以在它们的 head 标签中提供如下标签,标志其互相对应的关系:
<link rel="canoncial" href="https://www.zhuanzhuan.com" />
<link rel="alternate" href="https://m.zhuanzhuan.com" media="only screen and (max-width: 750px)"/>
前者放在移动端的页面中,表示 pc 端页面大哥马首是瞻;后者则放在 pc 端对应的页面中,表示当屏幕尺寸小于 750px 的时候,就应该我移动端页面小弟上场服务了!
robots.txt
robots.txt 文件由一条或多条规则组成。每条规则可禁止(或允许)特定抓取工具抓取相应网站中的指定文件路径。通俗一点的说法就是:告诉爬虫,我这个网站,你哪些能看,哪些不能看的一个协议。
为什么要使用 robots.txt
搜索引擎(爬虫),访问一个网站,首先要查看当前网站根目录下的robots.txt,然后依据里面的规则,进行网站页面的爬取。也就是说,robots.txt起到一个基调的作用,也可以说是爬虫爬取当前网站的一个行为准则。那使用robots.txt的目的,就很明确了。
更好地做定向SEO优化,重点曝光有价值的链接给爬虫
将敏感文件保护起来,避免爬虫爬取收录
robots.txt的示例
如下:
# first group
User-agent: Baiduspider
User-agent: Googlebot
Disallow: /article/# second group
User-agent: *
Disallow: /Sitemap: https://www.xxx.com/sitemap.xml
以上:
允许百度和谷歌的搜索引擎访问站内除 article 目录下的所有文件/页面(eg: article.html 可以,article/index.html 不可以);
不允许其他搜索引擎访问网站;
指定网站地图所在。
假如你允许整站都可以被访问,则可以不在根目录添加 robots 文件
文件规范
文件格式和命名
文件格式为标准
ASCII或UTF-8文件必须命名为
robots.txt只能有 1 个
robots.txt文件
文件位置 必须位于它所应用到的网站主机的根目录下
常用的关键字
User-agent:网页抓取工具的名称
Disallow:不应抓取的目录或网页
Allow:应抓取的目录或网页
Sitemap:网站的站点地图的位置
React & Vue 服务器渲染对SEO友好的SSR框架
React(Next.js):
https://www.nextjs.cn
https://github.com/vercel/next.js
Vue(Nuxt.js):
https://www.nuxtjs.cn
https://github.com/nuxt/nuxt.js
结束语
正确认识SEO,不过分追求SEO,网站还是以内容为主。
提供一个常用的SEO综合查询的地址(http://seo.chinaz.com),感兴趣的可以去了解下。
参考文章
https://juejin.cn/post/6844904029923835911
https://www.sohu.com/a/320507630_120165202
最近组建了一个江西人的前端交流群,如果你是江西人可以加我微信 ruochuan12 拉你进群。
今日话题
时光飞逝,端午节三天假期马上结束了,快乐的时光总是短暂的。欢迎分享、收藏、点赞、在看我的公众号文章~
一个愿景是帮助5年内前端人走向前列的公众号
可加我个人微信 ruochuan12,长期交流学习
推荐阅读
我在阿里招前端,我该怎么帮你(可进模拟面试群)
2年前端经验,做的项目没技术含量,怎么办?
点击上方卡片关注我、加个星标

················· 若川简介 ·················
你好,我是若川,毕业于江西高校。现在是一名前端开发“工程师”。写有《学习源码整体架构系列》多篇,在知乎、掘金收获超百万阅读。
从2014年起,每年都会写一篇年度总结,已经写了7篇,点击查看年度总结。
同时,活跃在知乎@若川,掘金@若川。致力于分享前端开发经验,愿景:帮助5年内前端人走向前列。





)








![罗马数字 java_【leetcode刷题】[简单]13.罗马数字转整数(roman to integer)-java](http://pic.xiahunao.cn/罗马数字 java_【leetcode刷题】[简单]13.罗马数字转整数(roman to integer)-java)



)
