scrapy中使用FormRequest向网页提交数据
Scrapy post使用
如何post data:
http://httpbin.org/post
FormRequest : post请求
GitHub Login
借助浏览器分析登陆行为。
- 分析post的内容
- 先尝试一次错误的登陆:
- 如下:分析:
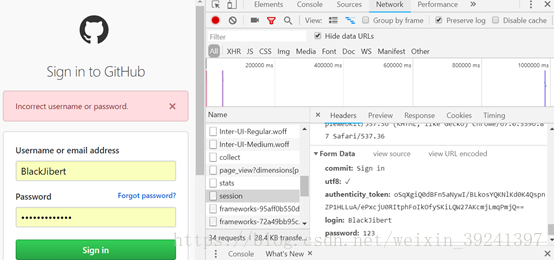
需要post的数据有:
- token:
- utf-8:
- commit:
- login:
- password:
- 以上只有token不是固定的
- 将以上内容组装出来。
scrapy 如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import FormRequest, Requestclass SpiderpostSpider(scrapy.Spider):name = "spiderpost"# allowed_domains = ["httpbin.org"]# starturls = 'http://httpbin.org/post'# "oSqXgiQ0dBFn5aNywI/BLkosYQKNlKd0K4QspnZP1HLLuA/ePxcjU0RItphFoIkOfySKiLQW27AKcmjLmqPmjQ=="# "wOgMHIwtyvdS1iwLG05afiq0/+gSkFr0RjS+x6f0nP/DALNvQiBVvuKsLRVMHfDJEtfNdTga2MdmYid0OcqxwQ=="starturls='https://github.com/login'loginurls='https://github.com/session'def start_requests(self):yield Request(self.starturls, callback=self.pre_parse)def pre_parse(self, response):# print(response.url)# passform =response.xpath('//form[@action="/session"]').extract()# print(form)keys=['utf8', 'authenticity_token', 'commit']values=[]for key in keys:xpath_ = '//form[@action="/session"]//input[@name="%s"]/@value'%keyvalue = response.xpath(xpath_).extract()[0]values.append(value)# print(values)postdata=dict(zip(keys,values))postdata['login'] = 'your nanme'postdata['password']='your password'# print(postdata)yield FormRequest(self.loginurls, formdata=postdata,callback=self.login_parse)def login_parse(self,response):# print(response.url)#检验是否登陆成功print(response.xpath('//meta[@name="user-login"]/@content').extract()))








码率和视频质量关系的研究 2 (实验结果))







猜想)

