1. 用requests库和BeautifulSoup库,爬取校园新闻首页新闻的标题、链接、正文。
import requests
from bs4 import BeautifulSoup url = requests.get("http://news.gzcc.cn/html/xiaoyuanxinwen/")url.encoding = "utf-8"
soup = BeautifulSoup(url.text,'html.parser')#print(soup.head.title.text)
for news in soup.select('li'):if len(news.select('.news-list-title'))>0:#print(news.select('.news-list-title')) #print(news.select('.news-list-title')[0]) #print(news.select('.news-list-title')[0].text) time = news.select('.news-list-info')[0].contents[0].text title = news.select('.news-list-title')[0].text href = news.select('a')[0]['href'] href_text = requests.get(href) href_text.encoding = "utf-8"href_soup = BeautifulSoup(href_text.text,'html.parser')href_text_body = href_soup.select('.show-content')[0].textprint(time,title,href,href_text_body)
2. 分析字符串,获取每篇新闻的发布时间,作者,来源,摄影等信息。
# print(news)
def analyseNewsArticle(href):print('**' * 5 + '详情页信息' + '**' * 10)res1 = requests.get(href)res1.encoding = 'UTF-8'soup1 = BeautifulSoup(res1.text, 'html.parser')news_info = soup1.select('.show-info')[0].textinfo_list = ['来源', '发布时间', '点击', '作者', '审核', '摄影'] # 需要解析的字段news_info_set = set(news_info.split('\xa0')) - {' ', ''} # 网页中的 获取后会解析成\xa0,所以可以使用\xa0作为分隔符# 循环打印文章信息for n_i in news_info_set:for info_flag in info_list:if n_i.find(info_flag) != -1: # 因为时间的冒号采用了英文符所以要进行判断if info_flag == '发布时间':print(info_flag + ':' + n_i[n_i.index(':') + 1:])elif info_flag == '点击': # 点击次数是通过文章id访问php后使用js写入,所以这里单独处理click_num_url = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'res2 = requests.get(click_num_url.format(href[href.rindex('/') + 1:href.index('.html')]))res2.encoding = 'UTF-8'print(info_flag + ':' + res2.text[res2.text.rindex("('") + 2:res2.text.rindex("')")])else:print(info_flag + ':' + n_i[n_i.index(':') + 1:])news_content = soup1.select('#content')[0].textprint(news_content) # 文章内容print('————' * 40)for n in news:# print(n)print('**' * 5 + '列表页信息' + '**' * 10)print('新闻链接:' + n.a.attrs['href'])print('新闻标题:' + n.select('.news-list-title')[0].text)print('新闻描述:' + n.a.select('.news-list-description')[0].text)print('新闻时间:' + n.a.select('.news-list-info > span')[0].text)print('新闻来源:' + n.a.select('.news-list-info > span')[1].text)analyseNewsArticle(n.a.attrs['href'])
3. 将其中的发布时间由str转换成datetime类型。
form datetime import datetime, timedeltaimport timestart_date = datetime.strptime("2018-04-03", "%Y-%m-%d")
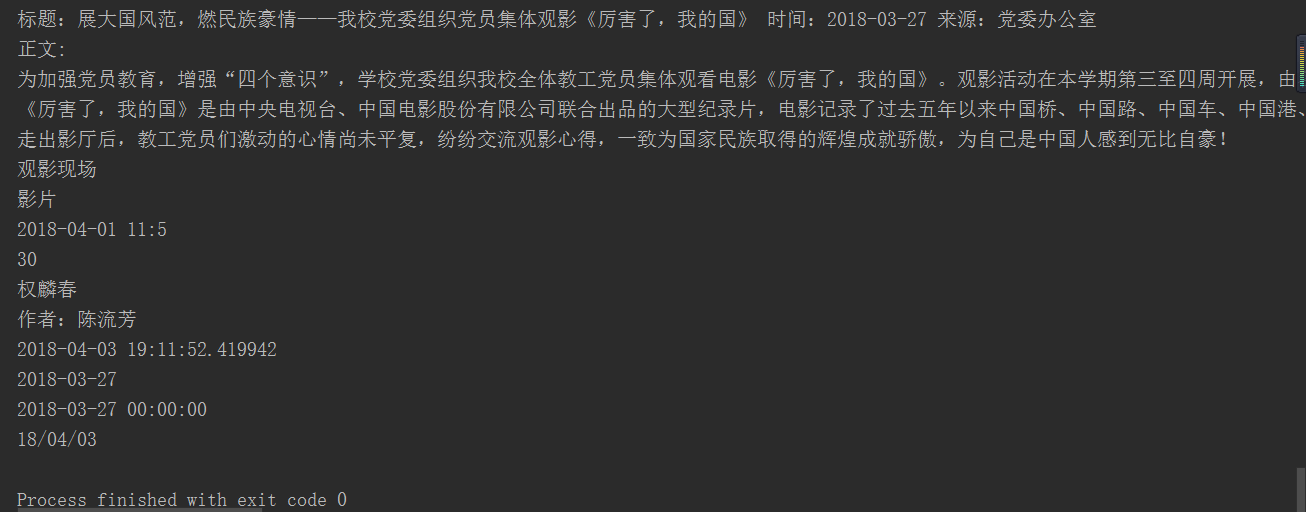
4. 将完整的代码及运行结果截图发布在作业上。









![iOS开发笔记[18/50]:在Mac OS X Lion系统中访问~/Library目录都需要点技巧](http://pic.xiahunao.cn/iOS开发笔记[18/50]:在Mac OS X Lion系统中访问~/Library目录都需要点技巧)



 概述)





