目录
1. MobileNet
1.1 MobileNet v1
1.1.1 深度可分离卷积
1.1.2 宽度和分辨率调整
1.2 MobileNet v2
1.2.1 倒残差模块
1.3 MobileNet v3
1.3.1 MobieNet V3 Block
1.3.2 MobileNet V3-Large网络结构
1.3.3 MobileNet V3预测猫狗二分类问题
送书活动
1. MobileNet
1.1 MobileNet v1
MobileNet v1是MobileNet系列中的第一个版本,于2017年由Google团队提出。其主要目标是设计一个轻量级的深度神经网络,能够在移动设备和嵌入式系统上进行图像分类和目标检测任务,并且具有较高的计算效率和较小的模型大小。
MobileNet v1的核心创新在于使用深度可分离卷积(Depthwise Separable Convolution),这是一种卷积操作,将标准卷积分解成两个步骤:深度卷积和逐点卷积。
1.1.1 深度可分离卷积
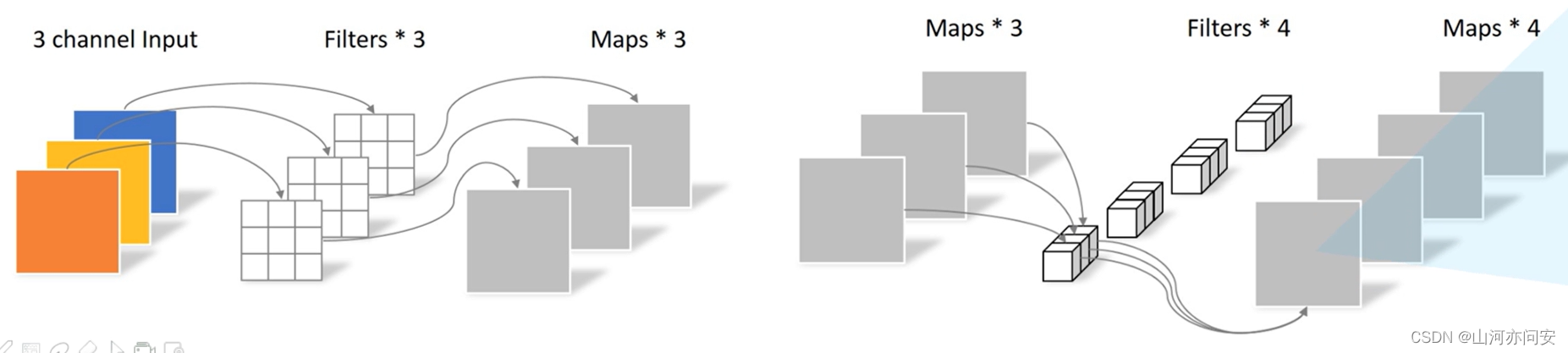
Depthwise Separable Convolution(深度可分离卷积): 传统卷积是在输入特征图的所有通道上应用一个共享的卷积核,这样会导致大量的计算开销。深度可分离卷积将这一步骤分解为两个较小的卷积操作:
- 深度卷积(Depthwise Convolution):在每个输入通道上应用一个单独的卷积核,得到一组“深度”特征图。
- 逐点卷积(Pointwise Convolution):使用1x1卷积核来组合前面得到的深度特征图,将通道数减少到期望的输出通道数。
1.1.2 宽度和分辨率调整
MobileNet v1允许通过调整网络的宽度和分辨率来权衡模型的速度和准确性。宽度表示在每个深度可分离卷积层中的输入和输出通道数。通过降低通道数,可以显著减少计算量,但可能损失一些准确性。分辨率指的是输入图像的大小,降低分辨率可以进一步减少计算开销,但可能会导致更低的准确性。
1.2 MobileNet v2
MobileNet v2 是 MobileNet 系列中的第二个版本,于2018年由 Google 团队提出。它是 MobileNet v1 的进一步改进,旨在提高性能并进一步降低计算复杂度,以适应移动设备和嵌入式系统的资源受限环境。
1.2.1 倒残差模块
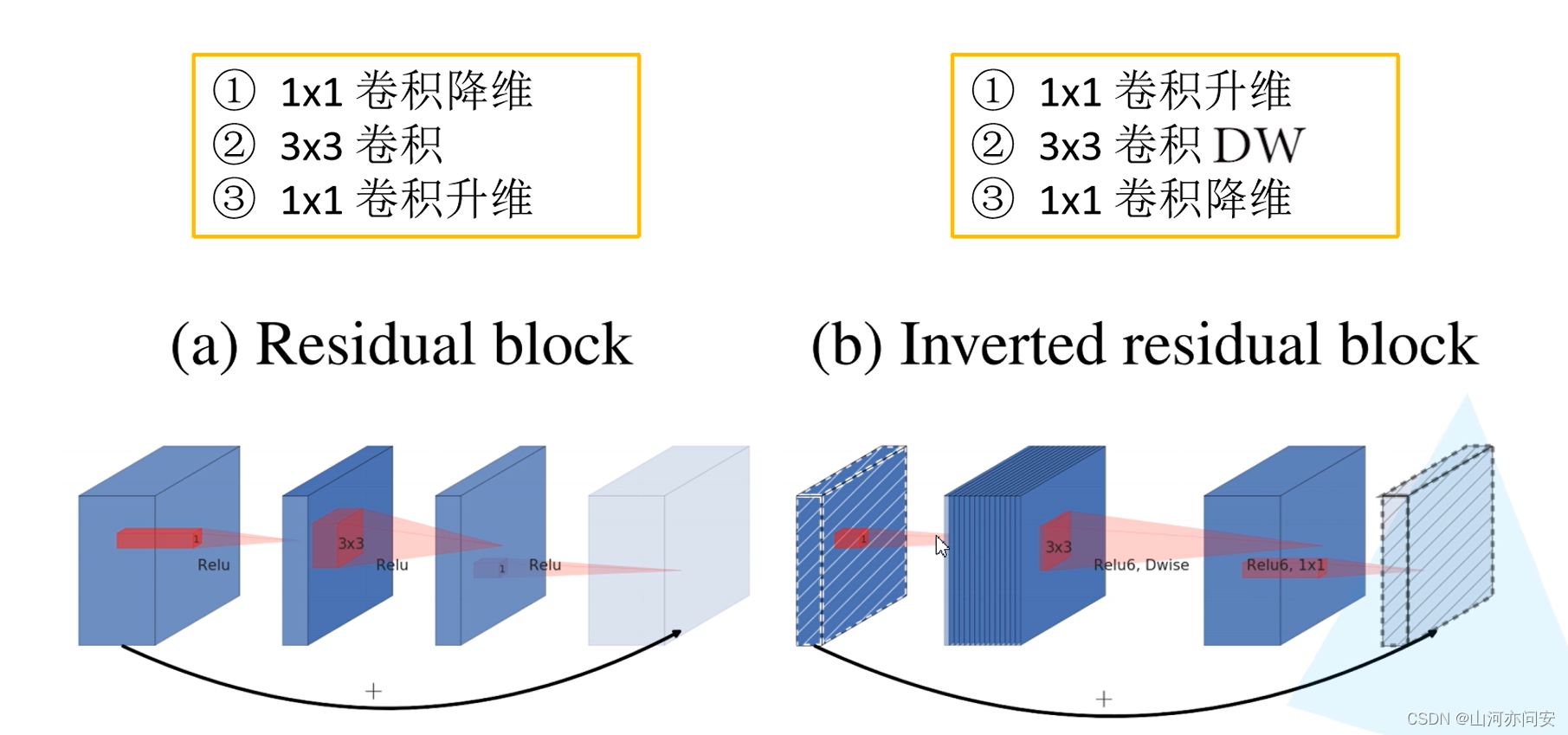
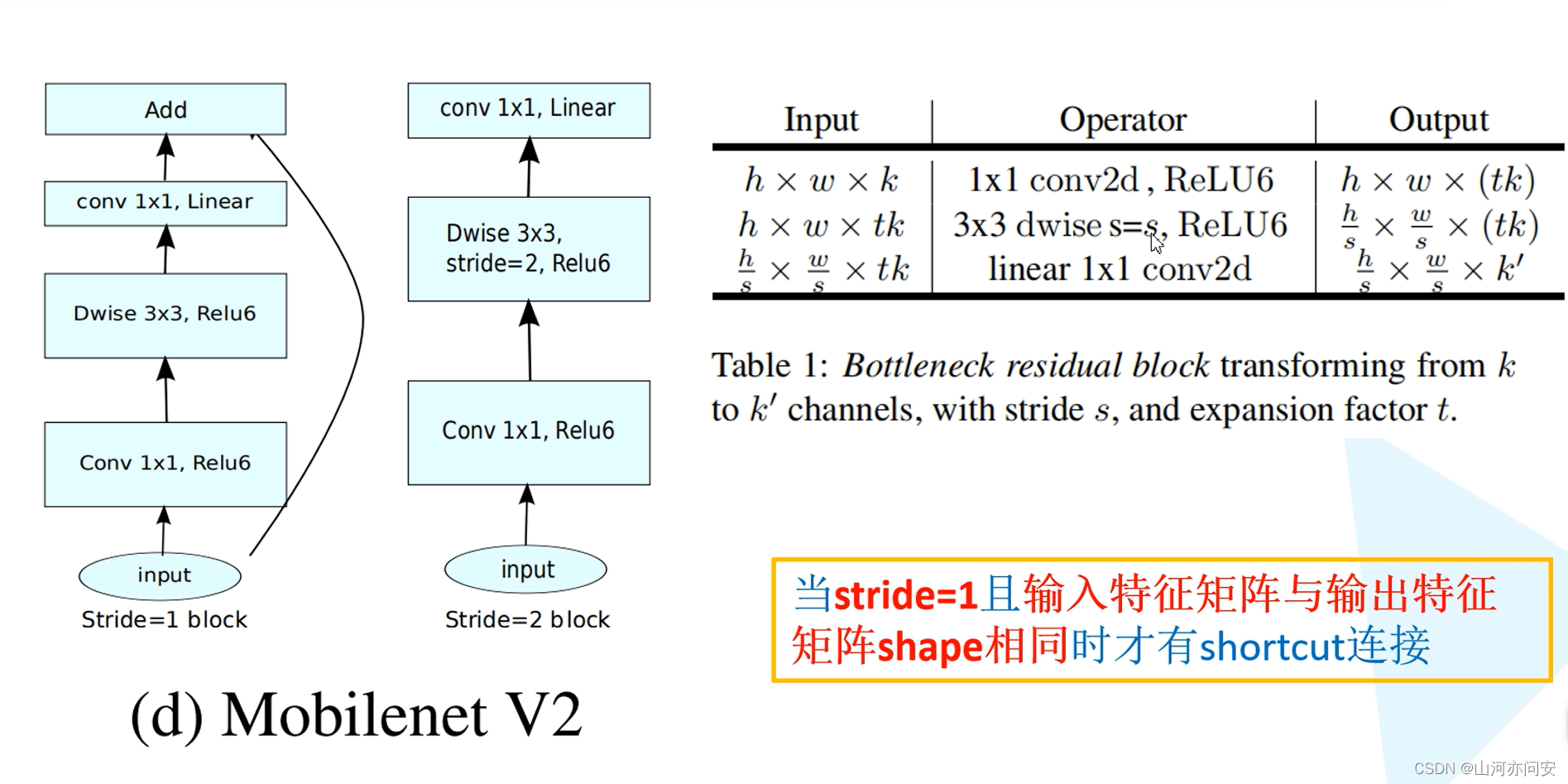
在传统的 ResNet(残差网络)中,残差模块的设计是在输入和输出的通道数相同的情况下进行,它采用两个 3x3 的卷积层,其中第一个卷积层用于扩展通道数,第二个卷积层用于压缩通道数。MobileNet v2 的倒残差模块则相反,它首先将输入特征图进行通道数的扩张,然后再应用深度可分离卷积,最后通过 1x1 卷积进行通道数的压缩。
倒残差模块的基本结构如下:
-
线性瓶颈(Linear Bottleneck): 在倒残差模块的第一步,输入特征图的通道数会先进行扩张,使用 1x1 的卷积核来增加通道数。这个步骤有时也被称为“瓶颈”,因为它增加了通道数,为后续的深度可分离卷积提供更多的信息。
-
深度可分离卷积(Depthwise Separable Convolution): 在线性瓶颈之后,倒残差模块应用深度可分离卷积。深度可分离卷积将卷积操作分解为两个步骤:深度卷积和逐点卷积。在深度可分离卷积中,先在每个输入通道上应用一个独立的卷积核,得到一组“深度”特征图;然后再使用 1x1 的卷积核来组合这些深度特征图,将通道数减少到期望的输出通道数。
-
线性瓶颈(Linear Bottleneck): 在深度可分离卷积之后,再应用一个线性瓶颈层。这个线性瓶颈层使用 1x1 的卷积核来进一步压缩通道数,减少计算量和参数数量。
具体如下图:
1.3 MobileNet v3
1.3.1 MobieNet V3 Block
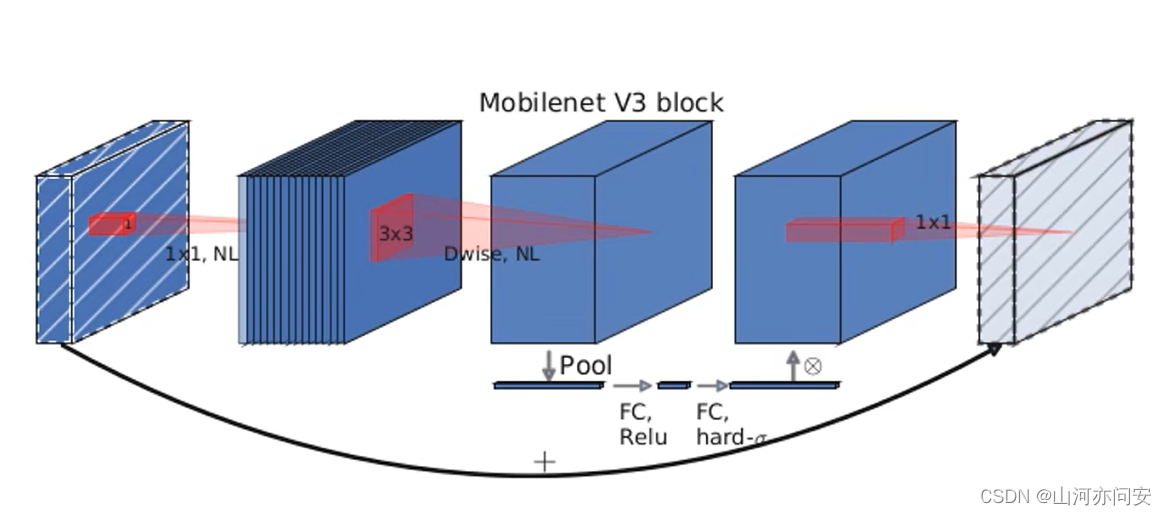
MobileNetV3 Block 是 MobileNet v3 网络中的基本组成单元,它采用了一系列的设计和优化,旨在提高网络性能并降低计算复杂度。MobileNetV3 Block 包含了倒残差模块、SE 模块、线性瓶颈层和 Hard Swish 激活函数等组件,下面将详细介绍每个组件及其工作原理。
MobileNetV3 Block 的基本结构如下:
-
线性瓶颈(Linear Bottleneck):倒残差模块中的第一步是线性瓶颈,它通过 1x1 卷积层来对输入特征图进行通道数的扩张。这个步骤有时也被称为“瓶颈”,因为它增加了通道数,为后续的深度可分离卷积提供更多的信息。
-
深度可分离卷积(Depthwise Separable Convolution):在线性瓶颈之后,MobileNetV3 Block 应用深度可分离卷积。深度可分离卷积将卷积操作分解为两个步骤:深度卷积和逐点卷积。在深度可分离卷积中,先在每个输入通道上应用一个独立的卷积核,得到一组“深度”特征图;然后再使用 1x1 的卷积核来组合这些深度特征图,将通道数减少到期望的输出通道数。
-
Squeeze-and-Excitation 模块:在深度可分离卷积之后,MobileNetV3 Block 添加了 SE 模块,用于增强网络的表示能力。SE 模块通过自适应地调整通道的权重,增加重要特征的表示能力,从而提高网络的准确性。SE 模块包含两个步骤:全局平均池化和全连接层。全局平均池化将特征图的每个通道进行平均池化,得到一个全局上下文信息;然后通过全连接层,自适应地调整每个通道的权重。
-
Hard Swish 激活函数:MobileNetV3 Block 使用了 Hard Swish 激活函数,这是一种计算简单且性能优秀的激活函数。相比于传统的 ReLU 激活函数,Hard Swish 在保持相近性能的情况下,计算复杂度更低,可以进一步加速网络的推理过程。
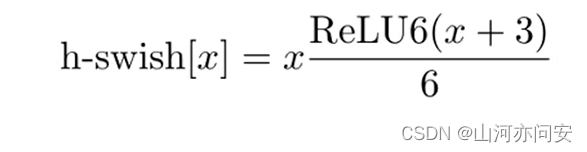
1.3.2 MobileNet V3-Large网络结构
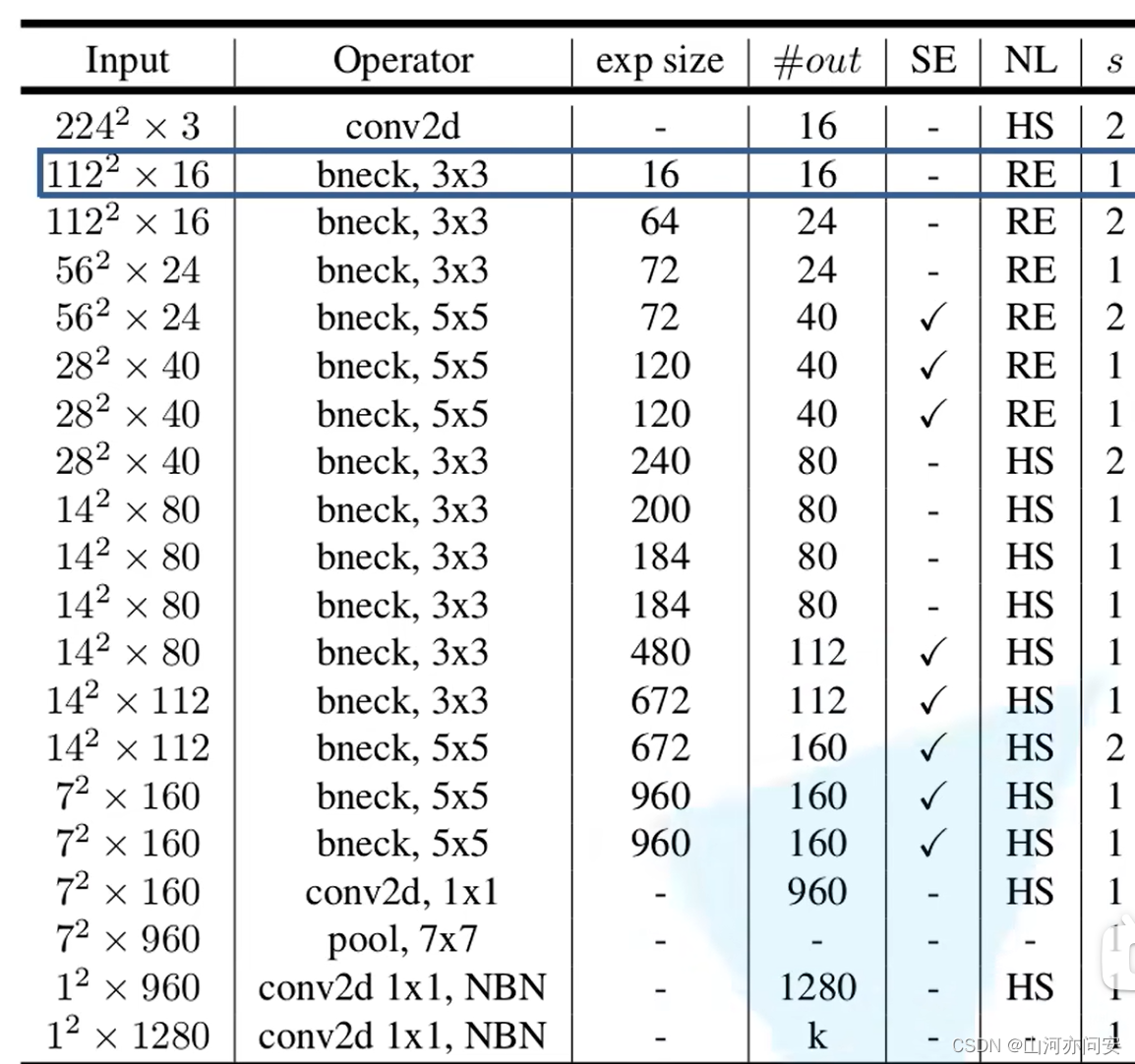
1.input输入层特征矩阵的shape
2.operator表示的是操作
3.out代表的输出特征矩阵的channel
4.NL代表的是激活函数,其中HS代表的是hard swish激活函数,RE代表的是ReLU激活函数;
5.s代表的DW卷积的步距;
6.exp size代表的是第一个升维的卷积要将维度升到多少,exp size多少,我们就用第一层1x1卷积升到多少维。
7.SE表示是否使用注意力机制,只要表格中标√所对应的bneck结构才会使用我们的注意力机制,对没有打√就不会使用注意力机制
8.NBN 最后两个卷积的operator提示NBN,表示这两个卷积不使用BN结构,最后两个卷积相当于全连接的作用
1.3.3 MobileNet V3预测猫狗二分类问题
首先,我们需要准备用于猫狗二分类的数据集。数据集可以从Kaggle上下载,其中包含了大量的猫和狗的图片。
在下载数据集后,我们需要将数据集划分为训练集和测试集。训练集文件夹命名为train,其中建立两个文件夹分别为cat和dog,每个文件夹里存放相应类别的图片。测试集命名为test,同理。然后我们使用ResNet50网络模型,在我们的计算机上使用GPU进行训练并保存我们的模型,训练完成后在测试集上验证模型预测的正确率。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from torchvision.models import mobilenet_v3_large# 设置随机种子
torch.manual_seed(42)# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 10# 定义数据转换
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载数据集
train_dataset = ImageFolder("train", transform=transform)
test_dataset = ImageFolder("test", transform=transform)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)# 加载预训练的MobileNetV3-Large模型
model = mobilenet_v3_large(pretrained=True)
num_ftrs = model.classifier[3].in_features
model.classifier[3] = nn.Linear(num_ftrs, 2) # 替换最后一层全连接层,以适应二分类问题device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)# 前向传播outputs = model(images)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (i + 1) % 100 == 0:print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item()}")
torch.save(model, 'model/m.pth')
# 测试模型
model.eval()
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Accuracy on test images: {(correct / total) * 100}%")
预测截图如下:
![]()
本篇文章到此结束,当然相关内容还有很多,更详细内容可以看论文。
送书活动
Java虚拟机核心技术一本通:通过实战案例+执行效果图+核心代码,剖析探索JVM核心底层原理,强化推动JVM优化落地,手把手教你吃透Java虚拟机深层原理!
编辑推荐
系统:全书内容层层递进,深入浅出,手把手教你吃透JVM虚拟机核心技术
深入:剖析探索JVM核心底层原理,强化推动JVM优化落地
实战:原理与实践相结合,懂理论,能落地,实战化案例精准定位技术细节
资源:附赠全书案例源代码,知其然更知其所以然,快速上手不用愁
内容简介
本书主要以 Java 虚拟机的基本特性及运行原理为中心,深入浅出地分析 JVM 的组成结构和底层实现,介绍了很多性能调优的方案和工具的使用方法。最后还扩展介绍了 JMM 内存模型的实现原理和 Java 编译器的优化机制,让读者不仅可以学习 JVM 的核心技术知识,还能夯实 JVM 调优及代码优化的技术功底。
本书适合已具有一定 Java 编程基础的开发人员、项目经理、架构师及性能调优工程师参考阅读,同时,本书还可以作为广大职业院校、计算机培训班相关专业的教学参考用书。
作者简介
李博,资深架构师,InfoQ平台、阿里云社区专家博主,CSDN博客专家,51CTO讲师,慕课网讲师,Quarkus技术社区的热衷参与者,参与过多个开源项目(Skywalking、Nacos、Pulsar等)的开发和深入研究。目前担任公司内部架构委员会副主席,主要研究方向是“基于Quarkus的云原生Java微服务架构的推进”和“GraalVM虚拟机的内部化落地”。

京东链接:https://item.jd.com/13762401.html
关注博主、点赞、收藏、
评论区评论 “ 人生苦短,我爱java”
即可参与送书活动!

:详解与示例)










保留寄存器(包含实例))
————词典分词)

)



