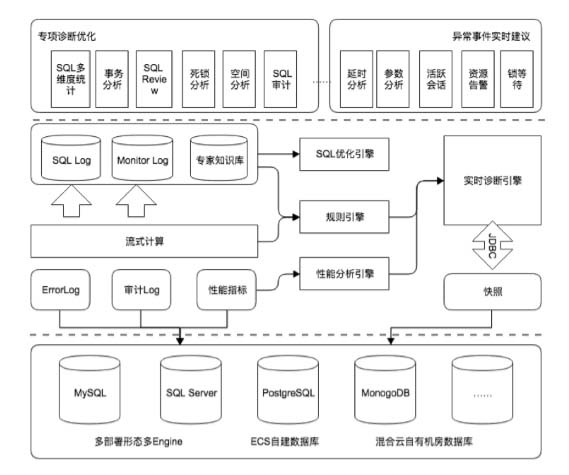
1.图解MapReduceMapReduce整体流程图
并行读取文本中的内容,然后进行MapReduce操作
Map过程:并行读取三行,对读取的单词进行map操作,每个词都以<key,value>形式生成
reduce操作是对map的结果进行排序,合并,最后得出词频。
2.简单过程:
MergeSort的过程(ps:2012-10-18)Map:
<Hello,1><World,1><Bye,1><World,1><Hello,1><Hadoop,1><Bye,1><Hadoop,1><Bye,1><Hadoop,1><Hello,1><Hadoop,1>
MergeSort:
- <Hello,1><World,1><Bye,1><World,1><Hello,1><Hadoop,1> | <Bye,1><Hadoop,1><Bye,1><Hadoop,1><Hello,1><Hadoop,1>
- <Hello,1><World,1><Bye,1> || <World,1><Hello,1><Hadoop,1> | <Bye,1><Hadoop,1><Bye,1> || <Hadoop,1><Hello,1><Hadoop,1>
- <Hello,1><World,1> ||| <Bye,1> || <World,1><Hello,1> ||| <Hadoop,1> | <Bye,1><Hadoop,1> ||| <Bye,1> || <Hadoop,1><Hello,1> ||| <Hadoop,1>
- MergeArray 结果:<Hello,1><World,1> ||| <Bye,1> || <Hello,1><World,1> ||| <Hadoop,1> | <Bye,1><Hadoop,1> ||| <Bye,1> || <Hadoop,1><Hello,1> ||| <Hadoop,1> 在|||这一层级
- MergeArray 结果:<Bye,1><Hello,1><World,1> || <Hadoop,1><Hello,1><World,1> | <Bye,1><Bye,1><Hadoop,1> || <Hadoop,1><Hadoop,1><Hello,1> 在||这一层级
- MergeArray 结 果:<Bye,1><Hadoop,1><Hello,1><World,1><Hello,1><World,1> | <Bye,1><Bye,1><Hadoop,1><Hadoop,1><Hello,1><Hadoop,1> 在|这一层级
- MergeArray结 果:<Bye,1><Bye,1><Bye,1><Hadoop,1><Hadoop,1><Hadoop,1><Hadoop,1><Hello,1><Hello,1><Hello,1><World,1><World,1> 排序完成
3.代码实例:
package cn.opensv.hadoop.ch1;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Hello world!
*
*/
public class WordCount1 {
public static class Map extends Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
public void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
context.write(key, new LongWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration cfg = new Configuration();
Job job = new Job(cfg);
job.setJarByClass(WordCount1.class);
job.setJobName("wordcount1"); // 设置一个用户定义的job名称
job.setOutputKeyClass(Text.class); // 为job的输出数据设置Key类
job.setOutputValueClass(LongWritable.class); // 为job输出设置value类
job.setMapperClass(Map.class); // 为job设置Mapper类
job.setCombinerClass(Reduce.class); // 为job设置Combiner类
job.setReducerClass(Reduce.class); // 为job设置Reduce类
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}












![[BZOJ1026] [SCOI2009] windy数 (数位dp)](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)