相信很多人都对之前大名鼎鼎的 Prisma 早有耳闻,Prisma 能够将一张普通的图像转换成各种艺术风格的图像,今天,我们将要介绍一下Prisma 这款软件背后的算法原理。就是发表于 2016 CVPR 一篇文章,
“ Image Style Transfer Using Convolutional Neural Networks”
算法的流程图主要如下:
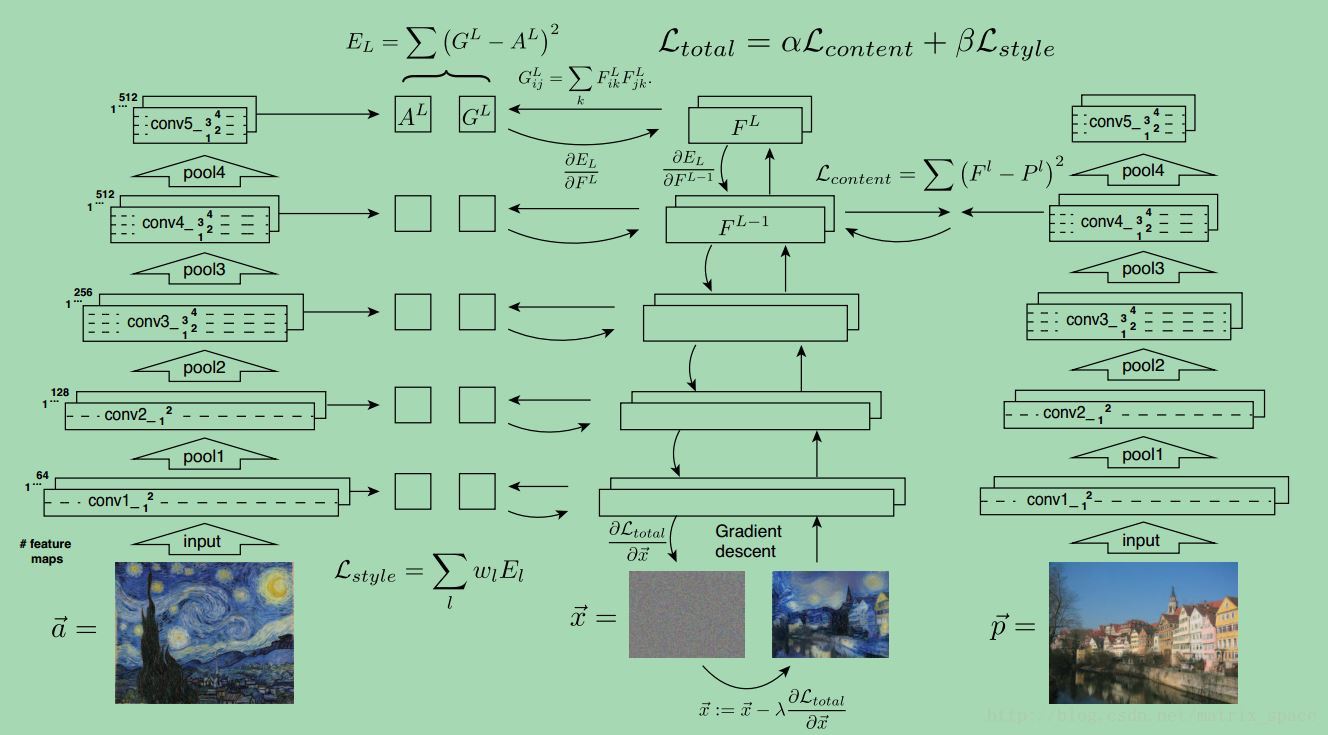
总得来说,就是利用一个训练好的卷积神经网络 VGG-19,这个网络在ImageNet 上已经训练过了。
给定一张风格图像 a 和一张普通图像 p,风格图像经过VGG-19 的时候在每个卷积层会得到很多 feature maps, 这些feature maps 组成一个集合 A,同样的,普通图像 p 通过 VGG-19 的时候也会得到很多 feature maps,这些feature maps 组成一个集合 P,然后生成一张随机噪声图像 x, 随机噪声图像 x 通过VGG-19 的时候也会生成很多feature maps,这些 feature maps 构成集合 G 和 F 分别对应集合 A 和 P, 最终的优化函数是希望调整 x 让 随机噪声图像 x 最后看起来既保持普通图像 p 的内容, 又有一定的风格图像 a 的风格。
content representation
在建立目标函数之前,我们需要先给出一些定义: 在CNN 中, 假设某一 layer 含有 Nl 个 filters, 那么将会生成 Nl 个 feature maps,每个 feature map 的维度为 Ml , Ml 是 feature map 的 高与宽的乘积。所以每一层 feature maps 的集合可以表示为 Fl∈RNl×Ml , Flij 表示第 i个 filter在 position j 上的 activation。
所以,我们可以给出 content 的 cost function:
style representation
为了建立风格的representation,我们先利用 Gram matrix 去表示每一层各个 feature maps 之间的关系,Gl∈RNl×Nl , Glij 是 feature maps i,j 的内积:
利用 Gram matrix,我们可以建立每一层的关于 style 的 cost :
结合所有层,可以得到总的cost
最后将 content 和 style 的 cost 相结合,最终可以得到:
α,β 表示权值,在建立 Lcontent 的时候,用到了 VGG-19 的 conv4_2 层,而在建立 Lstyle 的时候,用到了VGG-19 的 conv1_1, conv2_1, conv3_1, conv4_1 以及 conv5_1。
下一篇博客里,我们将介绍基于 TensorFlow 的代码实现。







)


 cannot be considered a valid collection.】)


)
 - buffer sizes do not match 解决方法)

)


