一 背景
大致背景是这样的,笔者在做数据处理时,遇到一个棘手的事情,主要遇到如下字符串拼接变动的场景,场景主要为,需要考虑如下两张表的组合:
表1-原始文本样式
| 序号 | 文本样式 |
|---|---|
| 1 | A变量B |
| 2 | A变量C |
| 3 | A变量CD |
| 4 | E变量CF |
| 5 | C变量CE |
| 6 | B变量CD |
其中文本里的变量有一个取值范围,这个范围只有用户提供的时刻才知道有多少范围,大致的变量是这样
表2-变量取值范围
| 序号 | 变量 |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
| 6 | f |
如果做上述的变量组合,文本存在的组合场景有很多,简单举例A变量B的组合文本就有6种组合,组合参考如下:
| 序号 | 组合文本 |
|---|---|
| 1 | AaB |
| 2 | AbB |
| 3 | AcB |
| 4 | AdB |
| 5 | AeB |
| 6 | AfB |
二 数据处理
数据处理的思路可以参考如下几种:
第一种,手工复制粘贴
一开始我想在Excel做简单的复制粘贴草草了事,但是实际的数据量要比例子里的还要多很多倍,而且很可能手工处理粘贴处理错误,所以考虑下还是做特殊的自动化处理比较妥当。
第二种,使用powerBI
微软Excel工具,它的PowerBI功能可以组合出上述场景,但是由于笔者的电脑现在不是Windows,此方法暂时没有使用,如果有Windows电脑类似诉求的可以使用之前记录的powerBI文档:笛卡尔积在Excel中的连接使用
第三种,训练chatGPT
我尝试使用chatGPT来自动给我生成文本,但是尝试多次的数据沟通和训练,结果并不理想,还浪费了我很多检查和优化的对话时间。
第四种,使用代码辅助
最后我借用python代码做了如下的简单处理,主要处理步骤如下:
1.使用代码生成组合场景
2.导出数据到Excel
3.进行简单excel函数处理,做文本拼接
步骤1:python脚本参考样例
import itertools
import numpy as np
import pandas as pd# 定义两个数据集
raw_path = "./test_date/"
A = [1,2,3,4,5,6]
B = [ 'a','b','d']# 使用itertools库的product函数计算笛卡尔积
cartesian_product = list(itertools.product(A, B))
getform = pd.DataFrame(cartesian_product)
getform.to_csv('mytest.csv',index=False)# 打印结果
for item in cartesian_product:print(item)
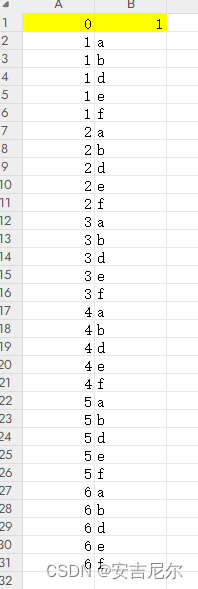
步骤2 导出Excel
导出Excel的数据截图长这个样子,考虑怎么简单怎么来,标黄的部分为表头,没有定义标题,默认为0和1
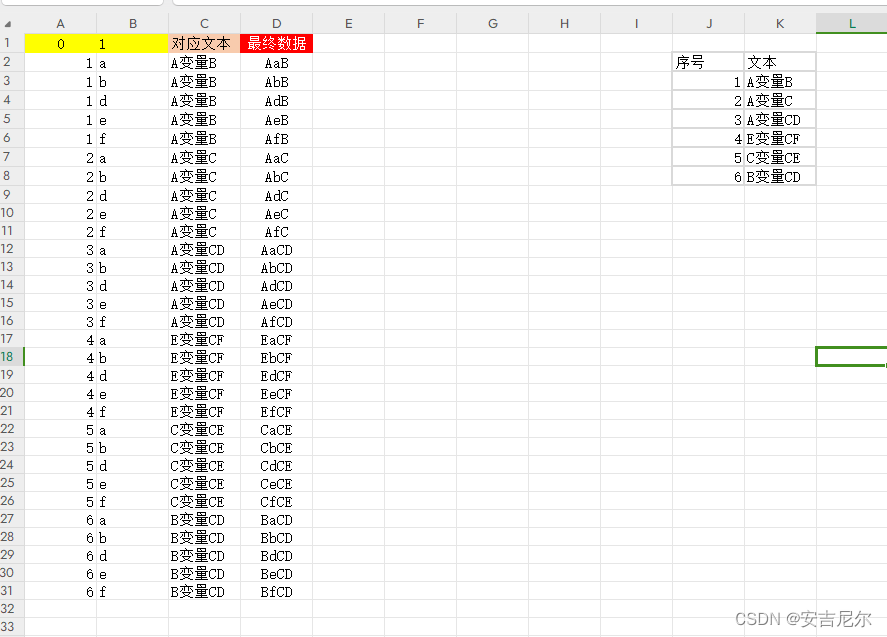
步骤3 简单Excel处理
主要使用的函数:
VLOOKUP函数:查询当前可能存在的原始文本模式
SUBSTITUTE函数:将当前的可替换变量,替换成要组合的实际字符
参考数据截图如下:
C2单元格的处理函数:VLOOKUP(A2,J:K,2,0)
D2单元格的处理函数:SUBSTITUTE(C2,“变量”,B2)
当然如果数据量比较大,也可以考虑将步骤3的函数做代码处理,一步生成对应的Excel报表,由于数据量还算适中,因此没有做这么复杂











![Next.js使用装饰器decorator 解决[作为表达式调用时,无法解析类修饰器的签名。]](http://pic.xiahunao.cn/Next.js使用装饰器decorator 解决[作为表达式调用时,无法解析类修饰器的签名。])





参数动态上线,制作惊艳动画短片)
)
