MMDetectionV2 + Colab 超详细教程及踩坑实录
文章目录
-
- 前言
- 一、环境配置
- 二、准备自己的数据集
- Aug.14更新
- 三:修改config文件
- 3.1 文件结构
- 3.2 (本地)修改config文件
- 3.2.1 (本地)构造自己模型的权重文件
- 3.2.2 (本地)修改配置文件
- 3.3 在colab上修改config
- 3.5 在线训练
- 3.6 在线可视化模型效果
- 3.7 在线inference
- 4. 延伸思考
- 5. 总结
前言
为了参加讯飞的X光目标检测竞赛,我们组研究了目前通用的几种框架。包括Detectron2, Maskrcnn Benchmark和mmdetectionV2,最后决定采用MMDetectonV2,因为他有以下的几个特性:
- 相比较来说非常丰富的模型库可供选择。基础模型包括:
- Faster rcnn
- Mask rcnn
- Rpn rcnn
- Cascade mask rcnn
- Cascade rcnn
- Retinanet (据说精度差不多的情况下,inference速度最快,可以以后再多了解一下。
- 较多参考资料
- 安全的License,Apache License 2.0
先说明下,为什么我要这么执着的使用Colab:
- Colab Pro订阅能够提供一般学生无法获得的算力资源:P100, 16g内存,$9.9/month简直在做慈善。
- 服务器在国外,免除网速烦恼。所有模型,包都是秒下秒装。虽然每个session重启都要重新装包,不过有这个速度完全不用担心花费过多时间。
- 小白能专注上手跑模型,调参本身。配置环境的痛苦,想想你们学者最开始装Docker、Anaconda等工具的时候,一不小心环境全乱了,电脑都打不开,几个小时一事无成的感觉,懂得都懂。
However, 为了获得以上的好处,我尝试在mmdetection官网提供的tutorial 中更改,结果一言难尽。同时,目前绝大多数的mmdetection的笔记都是基于1.x版本,而且几乎没有在Colab环境的配置教程。基本所有能踩的坑我全部踩了个遍,为了纪念一下也为了给其他的目标检测学习者提供一下参考,就有了这篇笔记。
在主体上我将采用colab tutorial的框架来介绍,但是仍然强烈建议在本地安装配置好mmdetectionV2,能省下大把力气。
一、环境配置
# Check nvcc version
!nvcc -V
# Check GCC version
!gcc --version
编写时间:2020.8.11,colab预设为pytorch1.6.0 Cuda 10.1 gcc 7.5.0
# install dependencies: (use cu101 because colab has CUDA 10.1)
# 目前mmdetection只支持pytorch1.5.1及以下版本,使用1.6版本会报各种错。
!pip install -U torch==1.5.1+cu101 torchvision==0.6.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html
# !pip install -U torch==1.6+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html# install mmcv-full thus we could use CUDA operators,此步需要花费大量时间,be patient
!pip install mmcv-full
# 在2020二月份pycocotools api有更新,而colab没有配置最新的包,需要在这里重新安装,看情况需不需要重启runtime
# install albumentations
!pip install -U git+https://github.com/albu/albumentations --no-cache-dir
!pip install "git+https://github.com/open-mmlab/cocoapi.git#subdirectory=pycocotools"# Install mmdetection
!rm -rf mmdetection
!git clone https://github.com/open-mmlab/mmdetection.git
%cd mmdetection!pip install -e .# install Pillow 7.0.0 back in order to avoid bug in colab
!pip install Pillow==7.0.0
# Check Pytorch installation
import torch, torchvisionprint(torch.__version__, torch.cuda.is_available())# Check MMDetection installation
import mmdetprint(mmdet.__version__)# Check mmcv installation
from mmcv.ops import get_compiling_cuda_version, get_compiler_versionprint(get_compiling_cuda_version())
print(get_compiler_version())
Output:
1.5.1+cu101
True 2.3.0
10.1
GCC 7.5
挂载在自己的drive上:
from google.colab import drivedrive.mount('/content/drive')
在colab上,使用%cd或os.chdir(’…’)来切换工作目录
import os
os.chdir('../content/drive/My Drive/mmdetection')
!pwd
!ls
output:
/content/drive/My Drive/mmdetection/mmdetection
configs docs mmdet.egg-info requirements setup.cfg tools
demo LICENSE pytest.ini requirements.txt setup.py
docker mmdet README.md resources tests
二、准备自己的数据集
这是非常重要的一步,请务必按照以下的Tree准备自己的数据集,能给自己省下大量的麻烦。
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
│ ├── cityscapes
│ │ ├── annotations
│ │ ├── leftImg8bit
│ │ │ ├── train
│ │ │ ├── val
│ │ ├── gtFine
│ │ │ ├── train
│ │ │ ├── val
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ ├── VOC2012
这次任务中,提供给我们的是voc格式的数据。第一步需要做转化,voc2coco.ipynb.
具体操作在这里不详细展开,我将来会详细写一篇各数据集转化到VOC,COCO数据集格式的文章。
Aug.14更新
本地做了mixup strategy数据增广,具体实现见后续博客。
每次做完本地的数据增广后,需要转化成COCO再重新上传。因为COCO的格式需要所有注释放在同一个json文件中,所以需要重新生成。
三:修改config文件
这里是我花了最多时间的地方,在tutorial中,官方是载入了一个config和它对应的模型,之后在colab即ipython 中用命令一行一行修改,这种方法在你非常明确MMDetectionV2的config结构和训练方式的情况下,是有一定灵活性的。但是如果不了解config的搭建方法,这会让你非常懵逼,多达一百多行的config命令实在非常难以轻松上手。这里我会介绍两种方法,一种是在本地修改好config文件上传,同时会介绍如何在colab cells中用命令修改。
3.1 文件结构
.
├── coco_exps
├── configs #configs主要修改的部分在这里,训练config也是从这里继承的
│ ├── albu_example
│ ├── atss
│ ├── _base_ #最根本的继承
│ │ ├── datasets #存在着不同数据集的训练方法,包含train_pipeline(augmentation), test_pipeline(TTA), data(batch_size, data root)等信息
│ │ ├── models #保存着基础模型,需要在这里修改num_classes来适配自己的任务
│ │ └── schedules #保存着lr_schedule:1x, 2x, 20e,每x意味着12个epochs
│ ├── carafe
│ ├── cascade_rcnn
│ ├── cityscapes
│ ├── cornernet
│ ├── dcn
│ ├── deepfashion
│ ├── detectors
│ ├── double_heads
│ ├── dynamic_rcnn
│ ├── empirical_attention
│ ├── faster_rcnn
│ ├── fast_rcnn
│ ├── fcos
│ ├── foveabox
│ ├── fp16
│ ├── free_anchor
│ ├── fsaf
│ ├── gcnet
│ ├── gfl
│ ├── ghm
│ ├── gn
│ ├── gn+ws
│ ├── grid_rcnn
│ ├── groie
│ ├── guided_anchoring
│ ├── hrnet
│ ├── htc
│ ├── instaboost
│ ├── legacy_1.x
│ ├── libra_rcnn
│ ├── lvis
│ ├── mask_rcnn
│ ├── ms_rcnn
│ ├── nas_fcos
│ ├── nas_fpn
│ ├── pafpn
│ ├── pascal_voc
│ ├── pisa
│ ├── point_rend
│ ├── regnet
│ ├── reppoints
│ ├── res2net
│ ├── retinanet
│ ├── rpn
│ ├── scratch
│ ├── ssd
│ └── wider_face
├── data
│ └── coco #把整理好的coco数据集放在这里
│ ├── annotations
│ ├── test2017
│ ├── train2017
│ └── val2017
├── mmdet #这里存放着mmdet的一些内部构件
│ ├── datasets #需要在这里的coco.py更改CLASSES,相当于Detectron2注册数据集
│ │ ├── pipelines
│ │ │ └── __pycache__
│ │ ├── __pycache__
│ │ └── samplers
│ │ └── __pycache__
│ ├── core
│ │ ├── evaluation #在这里修改evaluation相关的config。如在coco_classes中修改return的classes_names
3.2 (本地)修改config文件
这里非常建议在本地修改config文件再上传到drive上,或者在colab提供的文件目录中修改。如图所示:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YfTjwL0L-1597826737896)(evernotecid://BC7CFB48-5C18-439C-ADB2-AD1171DE2741/appyinxiangcom/18838120/ENResource/p258)]](https://img-blog.csdnimg.cn/20200819170518706.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L01vY2hhZHJvbmU=,size_16,color_FFFFFF,t_70#pic_center)
因为colab使用的ipython shell,每个参数的修改都需要使用cfg的api去修改,很容易漏项或lose track,而且mmdetection V2有一个非常精密的inherit config系统,不用结构化的IDE修改实在有点可惜。最后一点,在后期inference testset的时候,必须从.py文件中读取test_config,为什么不一劳永逸呢?
这里有争议,我在线训练并不需要修改权重,使用的预训练.pth模型在num_classes不匹配时会提示,然后自动适配cascade_rcnn_r50_1x.py中的num_classes。
不过修改后肯定不会错。
import torch
pretrained_weights = torch.load('checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth')num_class = 1
pretrained_weights['state_dict']['roi_head.bbox_head.fc_cls.weight'].resize_(num_class+1, 1024)
pretrained_weights['state_dict']['roi_head.bbox_head.fc_cls.bias'].resize_(num_class+1)
pretrained_weights['state_dict']['roi_head.bbox_head.fc_reg.weight'].resize_(num_class*4, 1024)
pretrained_weights['state_dict']['roi_head.bbox_head.fc_reg.bias'].resize_(num_class*4)torch.save(pretrained_weights, "mask_rcnn_r50_fpn_1x_%d.pth"%num_class)
其中num_class为你要训练数据的类别数 (不用加1) V2已经修改了,num_classes不再包含背景。
- mmdet/coco.py
在这里修改类别。
@DATASETS.register_module()
class CocoDataset(CustomDataset):#CLASSES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',# 'train', 'truck', 'boat', 'traffic light', 'fire hydrant',# 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',# 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',# 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',# 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',# 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',# 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',# 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',# 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',# 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',# 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',# 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')#在这里修改你所需要的CLASSESCLASSES =('knife, scissors, lighter, zippooil, pressure, slingshot, handcuffs, nailpolish, powerbank, firecrackers')- configs/_base_/datasets/coco_detection.py
在train pipeline修改Data Augmentation在train
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# 在这里加albumentation的aug
albu_train_transforms = [dict(type='ShiftScaleRotate',shift_limit=0.0625,scale_limit=0.0,rotate_limit=0,interpolation=1,p=0.5),dict(type='RandomBrightnessContrast',brightness_limit=[0.1, 0.3],contrast_limit=[0.1, 0.3],p=0.2),dict(type='OneOf',transforms=[dict(type='RGBShift',r_shift_limit=10,g_shift_limit=10,b_shift_limit=10,p=1.0),dict(type='HueSaturationValue',hue_shift_limit=20,sat_shift_limit=30,val_shift_limit=20,p=1.0)],p=0.1),dict(type='JpegCompression', quality_lower=85, quality_upper=95, p=0.2),dict(type='ChannelShuffle', p=0.1),dict(type='OneOf',transforms=[dict(type='Blur', blur_limit=3, p=1.0),dict(type='MedianBlur', blur_limit=3, p=1.0)],p=0.1),
]
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True, with_mask=True),#据说这里改img_scale即可多尺度训练,但是实际运行报错。dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),dict(type='Pad', size_divisor=32),dict(type='Albu',transforms=albu_train_transforms,bbox_params=dict(type='BboxParams',format='pascal_voc',label_fields=['gt_labels'],min_visibility=0.0,filter_lost_elements=True),keymap={'img': 'image','gt_masks': 'masks','gt_bboxes': 'bboxes'},
#train_pipeline = [
# dict(type='LoadImageFromFile'),
# dict(type='LoadAnnotations', with_bbox=True),
# dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
# dict(type='RandomFlip', flip_ratio=0.5),
# dict(type='Normalize', **img_norm_cfg),
# dict(type='Pad', size_divisor=32),
# dict(type='DefaultFormatBundle'),
# dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]
# 测试的pipeline
test_pipeline = [dict(type='LoadImageFromFile'),dict(type='MultiScaleFlipAug',# 多尺度测试 TTA在这里修改,注意有些模型不支持多尺度TTA,比如cascade_mask_rcnn,若不支持会提示# Unimplemented Errorimg_scale=(1333, 800),flip=False,transforms=[dict(type='Resize', keep_ratio=True),dict(type='RandomFlip'),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']),])
]
# 包含batch_size, workers和路径。
# 路径如果按照上面的设置好就不需要更改
data = dict(samples_per_gpu=2,workers_per_gpu=2,train=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_train2017.json',img_prefix=data_root + 'train2017/',pipeline=train_pipeline),val=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_val2017.json',img_prefix=data_root + 'val2017/',pipeline=test_pipeline),test=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_val2017.json',img_prefix=data_root + 'val2017/',pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')其中,batch_size和路径等频繁修改的参数在colab中可以快速修改:
# 举例
cfg.samples_per_gpu = 4
cfg.data.train.ann_file = '...'
cfg.data.train.img_prefix = '...'
cfg.data.train.pipeline = train_pipeline- configs/_base_/models/cascade_rcnn_r50_fpn.py
我们选用的是dcn/cascade_rcnn_r101_20e.py模型进行训,mmdetectionV2的继承比较复杂,但是可维护性较好。一路到底,最根本的继承还是base model中的cascade_rcnn_r50_fpn.py,主要的改动也是在这里进行。
# model settings
model = dict(type='CascadeRCNN',pretrained='torchvision://resnet50',backbone=dict(type='ResNet',depth=50,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,norm_cfg=dict(type='BN', requires_grad=True),norm_eval=True,style='pytorch'),neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,num_outs=5),rpn_head=dict(type='RPNHead',in_channels=256,feat_channels=256,anchor_generator=dict(type='AnchorGenerator',scales=[8],ratios=[0.5, 1.0, 2.0],strides=[4, 8, 16, 32, 64]),bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0]),loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),# 在这里修改num_classes. roi_head=dict(type='CascadeRoIHead',# 3个stage就意味着要改三个num_classesnum_stages=3,stage_loss_weights=[1, 0.5, 0.25],bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=[dict(type='Shared2FCBBoxHead',in_channels=256,fc_out_channels=1024,roi_feat_size=7,# 这里修改,原为80.注意这里不需要加BG类(+1)num_classes=10,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2]),reg_class_agnostic=True,loss_cls=dict(type='CrossEntropyLoss',use_sigmoid=False,loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0,loss_weight=1.0)),dict(type='Shared2FCBBoxHead',in_channels=256,fc_out_channels=1024,roi_feat_size=7,# 这里修改,原为80.注意这里不需要加BG类(+1)num_classes=10,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.05, 0.05, 0.1, 0.1]),reg_class_agnostic=True,loss_cls=dict(type='CrossEntropyLoss',use_sigmoid=False,loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0,loss_weight=1.0)),dict(type='Shared2FCBBoxHead',in_channels=256,fc_out_channels=1024,roi_feat_size=7,# 这里修改,原为80.注意这里不需要加BG类(+1)num_classes=10,bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[0., 0., 0., 0.],target_stds=[0.033, 0.033, 0.067, 0.067]),reg_class_agnostic=True,loss_cls=dict(type='CrossEntropyLoss',use_sigmoid=False,loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))]))test_cfg = dict(rpn=dict(nms_across_levels=False,nms_pre=1000,nms_post=1000,max_num=1000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(score_thr=0.05,# 在这里可以修改为'soft_nms'nms=dict(type='nms', iou_threshold=0.5),max_per_img=100))
- mmdetection/configs/_base_/default_runtime.py /
这里比较简单,我是为了要用Tensorboard查看训练,所以在这里解掉注释。
可以从官网下载预训练模型,放在checkpoint/…文件夹中,在这里的load_from中写入路径就可以加载权重训练了。
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(interval=50,hooks=[dict(type='TextLoggerHook'),# 解掉注释就能看到Tensorboard了dict(type='TensorboardLoggerHook')])
# yapf:enable
# 在这里也可以修改load_from 和 resume_from
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
这里,load_from和resume_from都可以在colab上在线设置
cfg.load_from = ’...'
cfg.resume_from = '...'
- mmdetection/configs/_base_/schedules/schedule_20e.py
这里是调整学习率的schedule的位置,可以设置warmup schedule和衰减策略。
1x, 2x分别对应12epochs和24epochs,20e对应20epochs,这里注意配置都是默认8块gpu的训练,如果用一块gpu训练,需要在lr/8
# optimizer
optimizer = dict(type='SGD', lr=0.02/8, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='step',warmup='linear',warmup_iters=500,warmup_ratio=0.001,step=[16, 19])
total_epochs = 20
- mmdetection/mmdet/core/evaluation/class_names.py
这里把coco_classes改成自己对应的class名称,不然在evaluation的时候返回的名称不对应。
def coco_classes():return ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train','truck', 'boat', 'traffic_light', 'fire_hydrant', 'stop_sign','parking_meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep','cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella','handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard','sports_ball', 'kite', 'baseball_bat', 'baseball_glove', 'skateboard','surfboard', 'tennis_racket', 'bottle', 'wine_glass', 'cup', 'fork','knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange','broccoli', 'carrot', 'hot_dog', 'pizza', 'donut', 'cake', 'chair','couch', 'potted_plant', 'bed', 'dining_table', 'toilet', 'tv','laptop', 'mouse', 'remote', 'keyboard', 'cell_phone', 'microwave','oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase','scissors', 'teddy_bear', 'hair_drier', 'toothbrush']return ['knife, scissors, lighter, zippooil, pressure, slingshot, handcuffs, nailpolish, powerbank, firecrackers']总结一下,需要在本地修改的参数有(以使用dcn/cascade_rcnn_r101_20e.py为例):
1. mmdet/datasets/coco.py
2. configs/\_base_/default_runtime.py
3. configs/\_base_/datasets/coco_detection.py
4. configs/\_base_/models/cascade_rcnn_r50_20e.py
5. mmdet/core/evaluation/class_names.py
当把这些修改好的文件上传后,有时需要等待1分钟左右让colab与drive同步。
3.3 在colab上修改config
- 载入修改好的config
from mmcv import Config
import albumentations as albu
cfg = Config.fromfile('./configs/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_20e_coco.py')
- 可以使用以下的命令检查几个重要参数:
cfg.data.train
cfg.total_epochs
cfg.data.samples_per_gpu
cfg.resume_from
cfg.load_from
cfg.data
...
- 改变config中某些参数
from mmdet.apis import set_random_seed# Modify dataset type and path# cfg.dataset_type = 'Xray'
# cfg.data_root = 'Xray'cfg.data.samples_per_gpu = 4
cfg.data.workers_per_gpu = 4# cfg.data.test.type = 'Xray'
cfg.data.test.data_root = '../mmdetection_torch_1.5'
# cfg.data.test.img_prefix = '../mmdetection_torch_1.5'# cfg.data.train.type = 'Xray'
cfg.data.train.data_root = '../mmdetection_torch_1.5'
# cfg.data.train.ann_file = 'instances_train2014.json'
# # cfg.data.train.classes = classes
# cfg.data.train.img_prefix = '../mmdetection_torch_1.5'# cfg.data.val.type = 'Xray'
cfg.data.val.data_root = '../mmdetection_torch_1.5'
# cfg.data.val.ann_file = 'instances_val2014.json'
# # cfg.data.train.classes = classes
# cfg.data.val.img_prefix = '../mmdetection_torch_1.5'# modify neck classes number
# cfg.model.neck.num_outs
# modify num classes of the model in box head
# for i in range(len(cfg.model.roi_head.bbox_head)):
# cfg.model.roi_head.bbox_head[i].num_classes = 10# cfg.data.train.pipeline[2].img_scale = (1333,800)cfg.load_from = '../mmdetection_torch_1.5/coco_exps/latest.pth'
# cfg.resume_from = './coco_exps_v3/latest.pth'# Set up working dir to save files and logs.
cfg.work_dir = './coco_exps_v4'# The original learning rate (LR) is set for 8-GPU training.
# We divide it by 8 since we only use one GPU.
cfg.optimizer.lr = 0.02 / 8
# cfg.lr_config.warmup = None
# cfg.lr_config = dict(
# policy='step',
# warmup='linear',
# warmup_iters=500,
# warmup_ratio=0.001,
# # [7] yields higher performance than [6]
# step=[7])
# cfg.lr_config = dict(
# policy='step',
# warmup='linear',
# warmup_iters=500,
# warmup_ratio=0.001,
# step=[36,39])
cfg.log_config.interval = 10# # Change the evaluation metric since we use customized dataset.
# cfg.evaluation.metric = 'mAP'
# # We can set the evaluation interval to reduce the evaluation times
# cfg.evaluation.interval = 12
# # We can set the checkpoint saving interval to reduce the storage cost
# cfg.checkpoint_config.interval = 12# # Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# cfg.total_epochs = 40# # We can initialize the logger for training and have a look
# # at the final config used for training
print(f'Config:\n{cfg.pretty_text}')- 使用Tensorboard进行可视化
如果有在default_runtime中解除注释tensorboard,键入下面的命令可以开启实时更新的tensorboard可视化模块。
# Load the TensorBoard notebook extension
%load_ext tensorboard
# logdir需要填入你的work_dir/+tf_logs
%tensorboard --logdir=coco_exps_v4/tf_logs
3.5 在线训练
如果以上的configs都做了正确的修改,直接运行下面的代码就可以开始训练了。
import mmcv
import matplotlib.pyplot as plt
import copy
import os.path as ospfrom mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.apis import train_detector# Build dataset
datasets = [build_dataset(cfg.data.train)]# Build the detector
model = build_detector(cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
# Add an attribute for visualization convenience
model.CLASSES = datasets[0].CLASSES# Create work_dir
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
print(model)
train_detector(model, datasets, cfg, distributed=False, validate=True)
这里的validate其实很玄学,有些时候运行完第一个epoch后的validate过程会中断报错。以下是我碰到的报错和解决办法:
Error: List range out of index.
一般报这个错,就要求你检查num_classes到底有没有修改正确。一定要在选用的模型的base model中修改所有的num_classes,并且注意MMDV2开始不需要num_classes+1(背景类)了。
ValueError: Expected x_max for bbox(0.94, 0.47, 1.003, 0.637, 0) to be in range[0,1], got 1.003.
这个错误是Albumentation报的错,需要检查的是configs/_base_/coco_detection.py中的数据增广albu部分是否正确,我的这个任务虽然是COCO格式的数据集但是不知道为什么需要在这里用pascal_voc格式的转化。从Coco改回pascal_voc就不报错了。
dict(type='Albu',transforms=albu_train_transforms,bbox_params=dicttype='BboxParams',format='pascal_voc',.......}
另外还有一个可能是在其他数据集转化到CoCo格式数据集的过程中代码出错,w,h需要xmax-xmin-1来转化,仔细检查一下。
OSError: Can't read data (file read failed: time = Mon May 20 00:34:07 2019
, filename = '/content/drive/My Drive/train/trainX_file1', file descriptor = 83, errno = 5, error message = 'Input/output error', buf = 0xc71d3864, total read size = 42145, bytes this sub-read = 42145, bytes actually read = 18446744073709551615, offset = 119840768)
这个是colab的bug,一般这个情况下先检查是不是指向的文件corrupt了,如果不是的话,可以试着重启runtime。如果还是不能load,可以用重新force remount,一般就会解决了。
Cuda out of memory
经典爆显存错误。需要注意的是中途停止训练后需要重启runtime才可以重置显存的占用量。所以碰到很多奇怪的错误第一件事可以尝试重新runtime。
...."Acyclic'
追溯可以看到,lr_schedule是一个pop的函数读取的,也就是说读取一次就没了。所以每次终止训练后,需要从config重新导入一次。
3.6 在线可视化模型效果
在模型训练完之后,除了看tensorboard或者log的可视化结果,也可以自己选出几个图片看看效果。
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
import mmcv
import random# Use your modified config file
config_file = './configs/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_20e_coco.py'
# Use your trained model
checkpoint_file = './coco_exps_v4/latest.pth'
# build the model from a config file and a checkpoint file
model = init_detector(config_file, checkpoint_file, device='cuda:0')
# get random test image and visualize it with model
images = os.listdir('data/coco/test2017')
rand_num = random.randint(0, len(images))
image = 'data/coco/test2017/'+images[rand_num]
result = inference_detector(model, image)# show the results
show_result_pyplot(model, image, result)
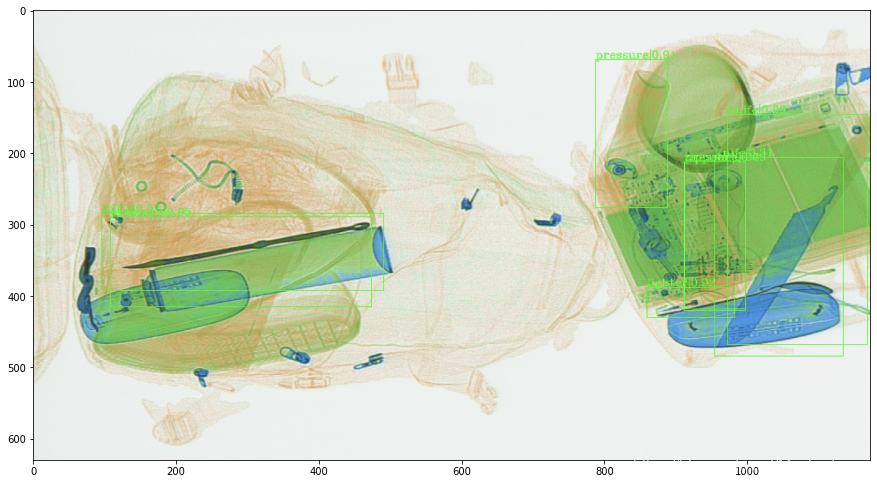
可以看到20个epoch的效果还可以,检出率和准确率都还可以接受。
3.7 在线inference
时间原因我们没有做出一个在线inference的脚本。采取的方案是下载下来到本地,在本地进行inference。代码如下
from argparse import ArgumentParserfrom mmdet.apis import inference_detector, init_detector, show_result_pyplotfrom glob import glob
import os
from tqdm import tqdmdef get_single_out(result,score_thr):tmp=[i.tolist() for i in result]res=[i.tolist() for i in result]# print(res)for cls_idx,item in enumerate(tmp):if(len(item)!=0):res[cls_idx]=[i for i in item if i[4]>score_thr]# print(res)return resdef main():parser = ArgumentParser()parser.add_argument('--imgdir',default='./data/coco/test2017', help='Image file')parser.add_argument('--config',default='./configs/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_20e_coco.py', help='Config file')parser.add_argument('--checkpoint',default='coco_exps_v4/epoch_7.pth', help='Checkpoint file')parser.add_argument('--device', default='cuda:0', help='Device used for inference')parser.add_argument('--score-thr', type=float, default=0.01, help='bbox score threshold')args = parser.parse_args()imgdir=args.imgdirimgs=glob(os.path.join(imgdir,"*.jpg"))imgs.sort()out=[]# build the model from a config file and a checkpoint filemodel = init_detector(args.config, args.checkpoint, device=args.device)for imgpath in tqdm(imgs):print(imgpath)# # test a single imageresult = inference_detector(model, imgpath)single_out=get_single_out(result,args.score_thr)out.append(single_out)# # show the results# show_result_pyplot(model, imgpath, result, score_thr=args.score_thr)#将结果写入到文件中f=open('coco_exps_v4/output_8_softnms.json','w')f.write(str(out))f.close()if __name__ == '__main__':main()最后的结果是本次比赛要求的格式,读者可以根据需要修改成适合自己的任务。
4. 延伸思考
基础的训练任务到这里就告一段落了,但是对于一个项目或者一个比赛来说,只掌握基础的训练技巧是远远不够的。比如我简短涉及到的soft_nms,多尺度训练,TTA,这些tricks可以一定程度上提高成绩,但我认为相比较聚焦于tricks,一个highlevel的视角更重要。以下是我认为完成一个任务需要具备的几个条件:
1. 对于数据的深入了解。包括但不限于:w、h的分布,分辨率的分布,目标物体的w/h比(用来确定anchor shape)
2. 整体的思路要清晰:选用不同的baseline model测试,加tricks,怎么对数据集做处理,以及实验记录。
3. 有时候算力确实是决定一个队伍能走多远的瓶颈。
5. 总结
作为一个只了解目标检测原理的小白,经过几十个小时的摸索,我能够掌握mmdetection+colab的基础操作和相关error的debug,这个过程还是比较有成就感的。中间参考了许多CSDN和知乎的大佬的博客,让我受益良多,也让我觉得有必要整理一下自己的踩坑实录,这篇文章权当做抛砖引玉,给其他大佬们一些启发。中间如果有不正确和不efficient的部分欢迎探讨。
我今后会发表更多的与目标检测相关的工具的详细教程以及论文笔记,有兴趣的朋友欢迎关注。
都看到这里了,点个赞呗。
本文链接http://smartadmin.com.cn/smartadmin/show-1159.html

的返评)




)

![[dts]Device Tree机制【转】](http://pic.xiahunao.cn/[dts]Device Tree机制【转】)










