作者:却把清梅嗅
链接:https://github.com/qingmei2/blogs/issues/30
前言
本文将对Paging分页组件的设计和实现进行一个系统整体的概述,强烈建议 读者将本文作为学习Paging 阅读优先级最高的文章,所有其它的Paging中文博客阅读优先级都应该靠后。
本文篇幅 较长,整体结构思维导图如下:
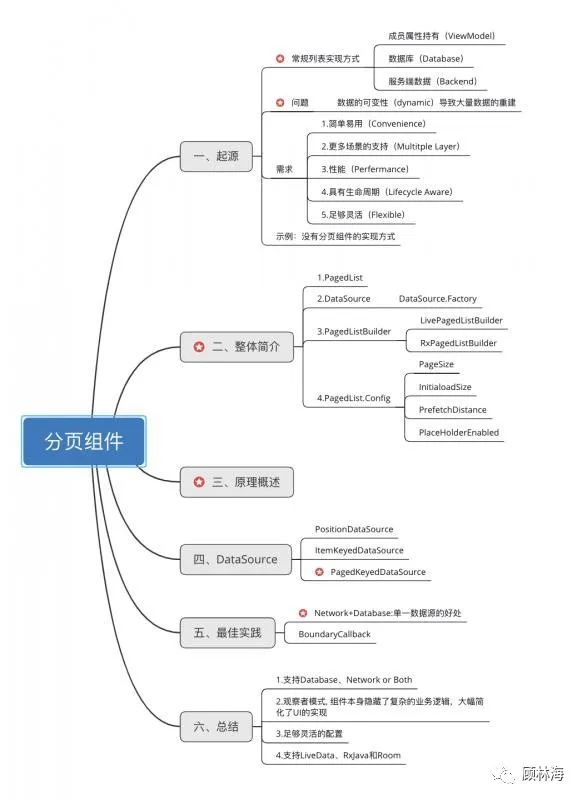
一、起源
手机应用中,列表是常见的界面构成元素,而对于Android开发者而言,RecyclerView是实现列表的不二选择。
在正式讨论Paging和列表分页功能之前,我们首先看看对于一个普通的列表,开发者如何通过代码对其进行建模:
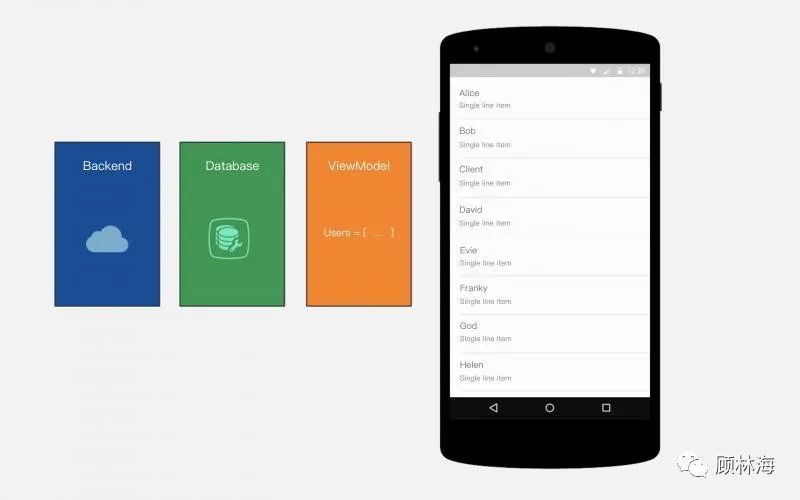
如图所示,针对这样一个简单 联系人界面 的建模,我们引出3个重要的层级:
1.服务端组件、数据库、内存
为什么说 服务端组件、数据库 以及 内存 是非常重要的三个层级呢?
首先,开发者为当前页面创建了一个ViewModel,并通过成员变量在 内存 中持有了一组联系人数据,因为ViewModel组件的原因,即使页面配置发生了改变(比如屏幕的旋转),数据依然会被保留下来。
而 数据库 的作用则保证了App即使在离线环境下,用户依然可以看到一定的内容——显然对于上图中的页面(联系人列表)而言,本地缓存是非常有意义的。
对于绝大多数列表而言,服务端 往往意味着是数据源,每当用户执行刷新操作,App都应当尝试向服务端请求最新的数据,并将最新的数据存入 数据库,并随之展示在UI上。
通常情况下,这三个层级并非同时都是必要的,读者需正确理解三者各自不同的使用场景。
现在,借助于 服务端组件、数据库 以及 内存,开发者将数据展示在RecyclerView上,这似乎已经是正解了。
2.问题在哪?
到目前为止,问题还没有完全暴露出来。
我们忽视了一个非常现实的问题,那就是 数据是动态的 ——这意味着,每当数据发生了更新(比如用户进行了下拉刷新操作),开发者都需要将最新的数据响应在UI上。
这意味着,当某个用户的联系人列表中有10000个条目时,每次数据的更新,都会对所有的数据进行重建——从而导致 性能非常低下,用户看到的只是屏幕中的几条联系人信息,为此要重新创建10000个条目?用户显然无法接受。
因此,分页组件的设计势在必行。
3.整理需求
3.1、简单易用
上文我们谈到,UI响应数据的变更,这种情况下,使用 观察者模式 是一个不错的主意,比如LiveData、RxJava甚至自定义一个接口等等,开发者仅需要观察每次数据库中数据的变更,并进行UI的更新:
class MyViewModel : ViewModel() {
val users: LiveData>>
}新的组件我们也希望能拥有同样的便利,比如使用LiveData或者RxJava,并进行订阅处理数据的更新—— 简单 且 易用。
3.2、处理更多层级
我们希望新的组件能够处理多层,我们希望列表展示 服务器 返回的数据、 或者 数据库 中的数据,并将其放入UI中。
3.3、性能
新的组件必须保证足够的快,不做任何没必要的行为,为了保证效率,繁重的操作不要直接放在UI线程中处理。
3.4、感知生命周期 如果可能,新的组件需要能够对生命周期进行感知,就像LiveData一样,如果页面并不在屏幕的可视范围内,组件不应该工作。
3.5、足够灵活
足够的灵活性非常重要——每个项目都有不同的业务,这意味着不同的API、不同的数据结构,新的组件必须保证能够应对所有的业务场景。
这一点并非必须,但是对于设计者来说难度不小,这意味着需要将不同的业务中的共同点抽象出来,并保证这些设计适用在任何场景中。
定义好了需求,在正式开始设计Paging之前,首先我们先来回顾一下,普通的列表如何实现数据的动态更新的。
4.普通列表的实现方式
我们依然通过 联系人列表 作为示例,来描述普通列表如何响应数据的动态更新。
首先,我们需要定义一个Dao,这里我们使用了Room组件用于 数据库 中联系人的查询:
@Dao
interface UserDao {
@Query("SELECT * FROM user")
fun queryUsers(): LiveData>
}这里我们返回的是一个LiveData,正如我们前文所言,构建一个可观察的对象显然会让数据的处理更加容易。
接下来我们定义好ViewModel和Activity:
class MyViewModel(val dao: UserDao) : ViewModel() {
// 1.定义好可观察的LiveData
val users: LiveData> = dao.queryUsers()
}class MyActivity : Activity {val myViewModel: MyViewModelval adapter: ListAdapterfun onCreate(bundle: Bundle?) {// 2.在Activity中对LiveData进行订阅
myViewModel.users.observe(this) {// 3.每当数据更新,计算新旧数据集的差异,对列表进行更新
adapter.submitList(it)
}
}
}这里我们使用到了ListAdapter,它是官方基于RecyclerView.Adapter的AsyncListDiffer封装类,其内创建了AsyncListDiffer的示例,以便在后台线程中使用DiffUtil计算新旧数据集的差异,从而节省Item更新的性能。
本文默认读者对ListAdapter一定了解,如果不是很熟悉,请参考DiffUtil、AsyncListDiffer、ListAdapter等相关知识点的文章。
此外,我们还需要在ListAdapter中声明DiffUtil.ItemCallback,对数据集的差异计算的逻辑进行补充:
class MyAdapter(): ListAdapter<User, UserViewHolder>(object: DiffUtil.ItemCallback<User>() {
override fun areItemsTheSame(oldItem: User, newItem: User)= oldItem.id == newItem.idoverride fun areContentsTheSame(oldItem: User, newItem: User)= oldItem == newItem
}
) {
// ...
}
That's all, 接下来我们开始思考,新的分页组件应该是什么样的。
二、分页组件简介
1.核心类:PagedList
上文提到,一个普通的RecyclerView展示的是一个列表的数据,比如List,但在列表分页的需求中,List明显就不太够用了。
为此,Google设计出了一个新的角色PagedList,顾名思义,该角色的意义就是 分页列表数据的容器 。
既然有了List,为什么需要额外设计这样一个PagedList的数据结构?本质原因在于加载分页数据的操作是异步的 ,因此定义PagedList的第二个作用是 对分页数据的异步加载 ,这个我们后文再提。
现在,我们的ViewModel现在可以定义成这样,因为PagedList也作为列表数据的容器(就像List一样):
class MyViewModel : ViewModel() {
// before
// val users: LiveData> = dao.queryUsers()
// after
val users: LiveData> = dao.queryUsers()
}在ViewModel中,开发者可以轻易通过对users进行订阅以响应分页数据的更新,这个LiveData的可观察者是通过Room组件创建的,我们来看一下我们的dao:
@Dao
interface UserDao {
// 注意,这里 LiveData> 改成了 LiveData>
@Query("SELECT * FROM user")
fun queryUsers(): LiveData>
}乍得一看似乎理所当然,但实际需求中有一个问题,这里的定义是模糊不清的——对于分页数据而言,不同的业务场景,所需要的相关配置是不同的。那么什么是分页相关配置呢?
最直接的一点是每页数据的加载数量PageSize,不同的项目都会自行规定每页数据量的大小,一页请求15个数据还是20个数据?显然我们目前的代码无法进行配置,这是不合理的。
2.数据源: DataSource及其工厂
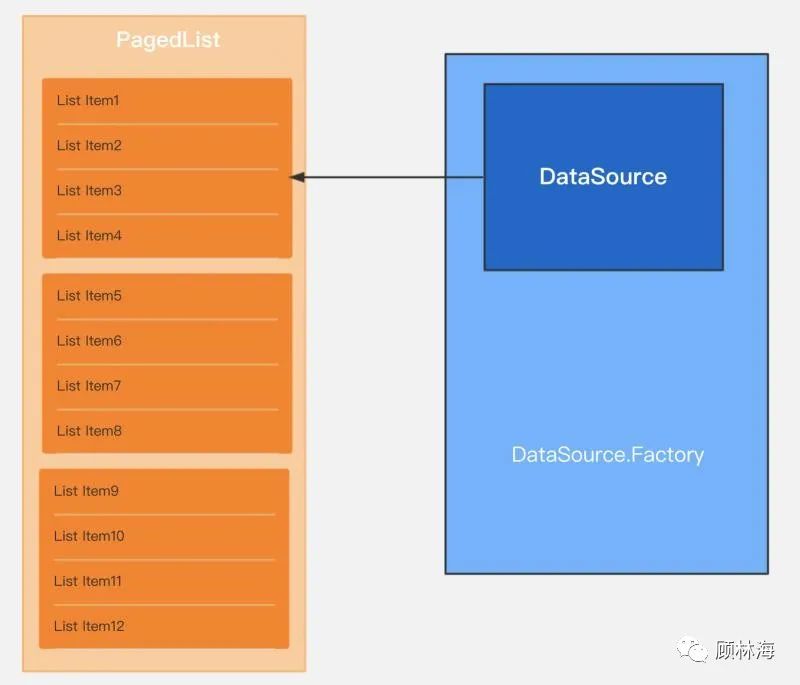
回答这个问题之前,我们还需要定义一个角色,用来为PagedList容器提供分页数据,那就是数据源DataSource。
什么是DataSource呢?它不应该是 数据库数据 或者 服务端数据, 而应该是 数据库数据 或者 服务端数据 的一个快照(Snapshot)。
每当Paging被告知需要更多数据:“Hi,我需要第45-60个的数据!”——数据源DataSource就会将当前Snapshot对应索引的数据交给PagedList。
但是我们需要构建一个新的PagedList的时候——比如数据已经失效,DataSource中旧的数据没有意义了,因此DataSource也需要被重置。
在代码中,这意味着新的DataSource对象被创建,因此,我们需要提供的不是DataSource,而是提供DataSource的工厂。
为什么要提供DataSource.Factory而不是一个DataSource? 复用这个DataSource不可以吗,当然可以,但是将DataSource设置为immutable(不可变)会避免更多的未知因素。
重新整理思路,我们如何定义Dao中接口的返回值呢?
@Dao
interface UserDao {
// Int 代表按照数据的位置(position)获取数据
// User 代表数据的类型
@Query("SELECT * FROM user")
fun queryUsers(): DataSource.Factory<Int, User>
}返回的是一个数据源的提供者DataSource.Factory,页面初始化时,会通过工厂方法创建一个新的DataSource,这之后对应会创建一个新的PagedList,每当PagedList想要获取下一页的数据,数据源都会根据请求索引进行数据的提供。
当数据失效时,DataSource.Factory会再次创建一个新的DataSource,其内部包含了最新的数据快照(本案例中代表着数据库中的最新数据),随后创建一个新的PagedList,并从DataSource中取最新的数据进行展示——当然,这之后的分页流程都是相同的,无需再次复述。
笔者绘制了一幅图用于描述三者之间的关系,读者可参考上述文字和图片加以理解:
3.串联两者:PagedListBuilder
回归第一小节的那个问题,分页相关业务如何进行配置?我们虽然介绍了为PagedList提供数据的DataSource,但这个问题似乎还是没有得到解决。
此外,现在Dao中接口的返回值已经是DataSource.Factory,而ViewModel中的成员被观察者则是LiveData>类型,如何 将数据源的工厂和LiveData进行串联 ?
因此我们还需要定义一个新的角色PagedListBuilder,开发者将 数据源工厂 和 相关配置 统一交给PagedListBuilder,即可生成对应的LiveData>:
class MyViewModel(val dao: UserDao) : ViewModel() {
val users: LiveData>init {// 1.创建DataSource.Factoryval factory: DataSource.Factory = dao.queryUsers()// 2.通过LivePagedListBuilder配置工厂和pageSize, 对users进行实例化
users = LivePagedListBuilder(factory, 30).build()
}
}如代码所示,我们在ViewModel中先通过dao获取了DataSource.Factory,工厂创建数据源DataSource,后者为PagedList提供列表所需要的数据;此外,另外一个Int类型的参数则制定了每页数据加载的数量,这里我们指定每页数据数量为30。
我们成功创建了一个LiveData>的可观察者对象,接下来的步骤读者驾轻就熟,只不过我们这里使用的是PagedListAdapter:
class MyActivity : Activity {
val myViewModel: MyViewModel
// 1.这里我们使用PagedListAdapter
val adapter: PagedListAdapterfun onCreate(bundle: Bundle?) {
// 2.在Activity中对LiveData进行订阅
myViewModel.users.observe(this) {
// 3.每当数据更新,计算新旧数据集的差异,对列表进行更新
adapter.submitList(it)
}
}
}
PagedListAdapter内部的实现和普通列表ListAdapter的代码几乎完全相同:
// 几乎完全相同的代码,只有继承的父类不同
class MyAdapter(): PagedListAdapter<User, UserViewHolder>(object: DiffUtil.ItemCallback<User>() {
override fun areItemsTheSame(oldItem: User, newItem: User)= oldItem.id == newItem.idoverride fun areContentsTheSame(oldItem: User, newItem: User)= oldItem == newItem
}
) {
// ...
}
准确的来说,两者内部的实现还有微弱的区别,前者ListAdapter的getItem()函数的返回值是User,而后者PagedListAdapter返回值应该是User?(Nullable),其原因我们会在下面的Placeholder部分进行描述。
4.更多可选配置:PagedList.Config
目前的介绍中,分页的功能似乎已经实现完毕,但这些在现实开发中往往不够,产品业务还有更多细节性的需求。
在上一小节中,我们通过LivePagedListBuilder对LiveData>进行创建,这其中第二个参数是 分页组件的配置,代表了每页加载的数量(PageSize) :
// before
val users: LiveData> = LivePagedListBuilder(factory, 30).build()读者应该理解,分页组件的配置 本身就是抽象的,PageSize并不能完全代表它,因此,设计者额外定义了更复杂的数据结构PagedList.Config,以描述更细节化的配置参数:
// after
val config = PagedList.Config.Builder()
.setPageSize(15) // 分页加载的数量
.setInitialLoadSizeHint(30) // 初次加载的数量
.setPrefetchDistance(10) // 预取数据的距离
.setEnablePlaceholders(false) // 是否启用占位符
.build()
// API发生了改变
val users: LiveData<PagedList<User>> = LivePagedListBuilder(factory, config).build()
对复杂业务配置的API设计来说,建造者模式 显然是不错的选择。
接下来我们简单了解一下,这些可选的配置分别代表了什么。
4.1.分页数量:PageSize
最易理解的配置,分页请求数据时,开发者总是需要定义每页加载数据的数量。
4.2.初始加载数量:InitialLoadSizeHint
定义首次加载时要加载的Item数量。
此值通常大于PageSize,因此在初始化列表时,该配置可以使得加载的数据保证屏幕可以小范围的滚动。
如果未设置,则默认为PageSize的三倍。
4.3.预取距离:PrefetchDistance
顾名思义,该参数配置定义了列表当距离加载边缘多远时进行分页的请求,默认大小为PageSize——即距离底部还有一页数据时,开启下一页的数据加载。
若该参数配置为0,则表示除非明确要求,否则不会加载任何数据,通常不建议这样做,因为这将导致用户在滚动屏幕时看到占位符或列表的末尾。
4.4.是否启用占位符:PlaceholderEnabled
该配置项需要传入一个boolean值以决定列表是否开启placeholder(占位符),那么什么是placeholder呢?
我们先来看未开启占位符的情况:

如图所示,没有开启占位符的情况下,列表展示的是当前所有的数据,请读者重点观察图片右侧的滚动条,当滚动到列表底部,成功加载下一页数据后,滚动条会从长变短,这意味着,新的条目成功实装到了列表中。一言以蔽之,未开启占位符的列表,条目的数量和PagedList中数据数量是一致的。
接下来我们看一下开启了占位符的情况:

如图所示,开启了占位符的列表,条目的数量和DataSource中数据的总量是一致的。这并不意味着列表从DataSource一次加载了大量的数据并进行渲染,所有业务依然交给Paging进行分页处理。
当用户滑动到了底部尚未加载的数据时,开发者会看到还未渲染的条目,这是理所当然的,PagedList的分页数据加载是异步的,这时对于Item的来说,要渲染的数据为null,因此开发者需要配置占位符,当数据未加载完毕时,UI如何进行渲染——这也正是为何上文说到,对于PagedListAdapter来说,getItem()函数的返回值是可空的User?,而不是User。
随着PagedList下一页数据的异步加载完毕,伴随着RecyclerView的原生动画,新的数据会被重新覆盖渲染到placeholder对应的条目上,就像gif图展示的一样。
4.5.关于Placeholder
这里我专门开一个小节谈谈关于placeholder,因为这个机制和我们传统的分页业务似乎有所不同,但Google的工程师们认为在某些业务场景下,该配置确实很有用。
开启了占位符,用户总是可以快速的滑动列表,因为列表“持有”了整个数据集,因此不会像未开启占位符时,滑动到底部而被迫暂停滚动,直到新的数据的加载完毕才能继续浏览。顺畅的操作总比期望之外的阻碍要好得多 。
此外,开启了占位符意味着用户与 加载指示器 彻底告别,类似一个 正在加载更多... 的提示标语或者一个简陋的ProgressBar效果真的会提升用户体验吗?也许答案是否定的,相比之下,用户应该更喜欢一个灰色的占位符,并等待它被新的数据渲染。
但缺点也随之而来,首先,占位符的条目高度应该和正确的条目高度一致,在某些需求中,这也许并不符合,这将导致渐进性的动画效果并不会那么好。
其次,对于开发者而言,开启占位符意味着需要对ViewHolder进行额外的代码处理,数据为null或者不为null?两种情况下的条目渲染逻辑都需要被添加。
最后,这是一个限制性的条件,您的DataSource数据源内部的数据数量必须是确定的,比如通过Room从本地获取联系人列表;而当数据通过网络请求获取的话,这时数据的数量是不确定的,不开启Placeholder反而更好。
5.更多观察者类型的配置
在本文的示例中,我们建立了一个LiveData>的可观察者对象供用户响应数据的更新,实际上组件的设计应该面向提供对更多优秀异步库的支持,比如RxJava。
因此,和LivePagedListBuilder一样,设计者还提供了RxPagedListBuilder,通过DataSource数据源和PagedList.Config以构建一个对应的Observable:
// LiveData support
val users: LiveData> = LivePagedListBuilder(factory, config).build()// RxJava support
val users: Observable> = RxPagedListBuilder(factory, config).buildObservable()三、工作流程原理概述
Paging幕后是如何工作的?
接下来,笔者将针对Paging分页组件的工作流程进行系统性的描述,探讨Paging是 如何实现异步分页数据的加载和响应 的。
为了便于理解,笔者将整个流程拆分为三个步骤,并为每个步骤绘制对应的一张流程图,这三个步骤分别是:
1、初次创建流程
2、UI渲染和分页加载流程
3、刷新数据源流程
1、初次创建流程
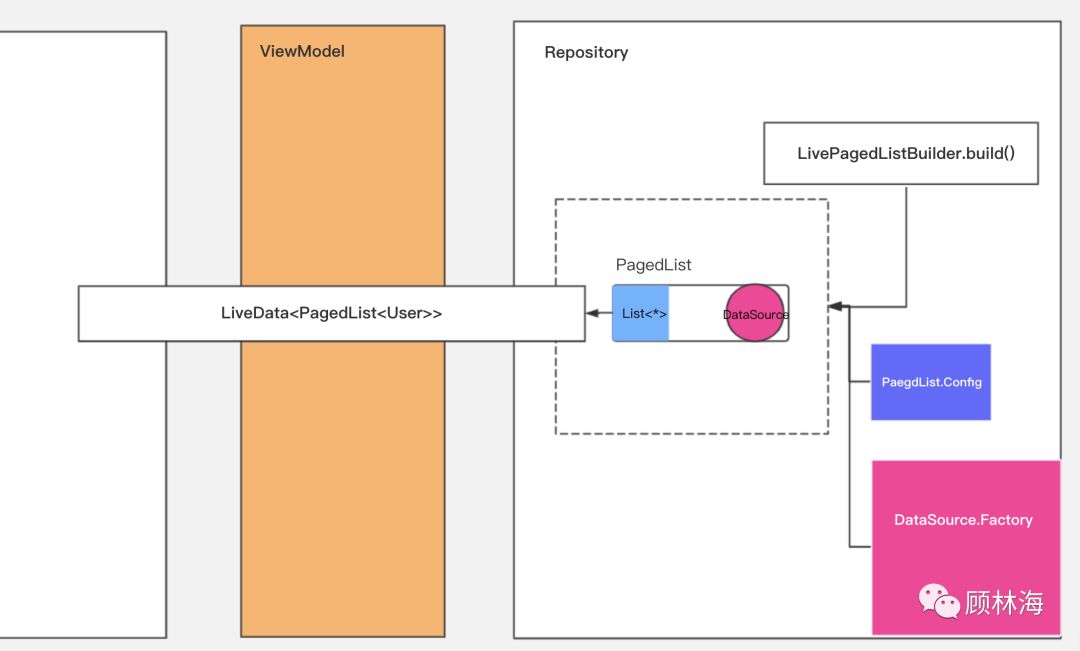
如图所示,我们定义了ViewModel和Repository,Repository内部实现了App的数据加载的逻辑,而其左侧的ViewModel则负责与UI组件的通信。
Repository负责为ViewModel中的LiveData>进行创建,因此,开发者需要创建对应的PagedList.Config分页配置对象和DataSource.Factory数据源的工厂,并通过调用LivePagedListBuilder相关的API创建出一个LiveData>。
当LiveData一旦被订阅,Paging将会尝试创建一个PagedList,同时,数据源的工厂DataSource.Factory也会创建一个DataSource,并交给PagedList持有该DataSource。
这时候PagedList已经被成功的创建了,但是此时的PagedList内部只持有了一个DataSource,却并没有持有任何数据,这意味着观察者角色的UI层即将接收到一个空数据的PagedList。
这没有任何意义,因此我们更希望PagedList第一次传递到UI层级的同时,已经持有了初始的列表数据(即InitialLoadSizeHint);因此,Paging尝试在后台线程中通过DataSource对PagedList内部的数据列表进行初始化。
现在,PagedList第一次创建完毕,并持有属于自己的DataSource和初始的列表数据,通过LiveData这个管道,即将向UI层迈出属于自己的第一个脚印。
2.UI渲染和分页加载流程
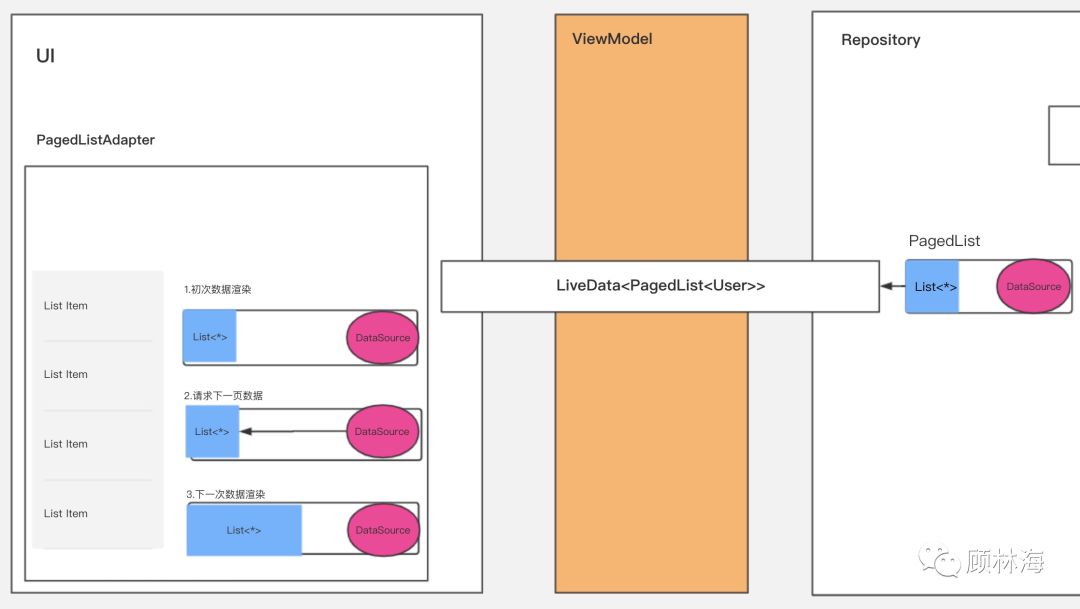
通过内部线程的切换,PagedList从后台线程切换到了UI线程,通过LiveData抵达了UI层级,也就是我们通常说的Activity或者Fragment中。
读者应该有印象,在上文的示例代码中,Activity观察到PagedList后,会通过PagedListAdapter.submitList()函数将PagedList进行注入。PagedListAdapter第一次接收到PagedList后,就会对UI进行渲染。
当用户尝试对屏幕中的列表进行滚动时,我们接收到了需要加载更多数据的信号,这时,PagedList在内部主动触发数据的加载,数据源提供了更多的数据,PagedList接收到之后将会主动触发RecyclerView的更新,用户通过RecyclerView原生动画观察到了更多的列表Item。
3.刷新数据源流程
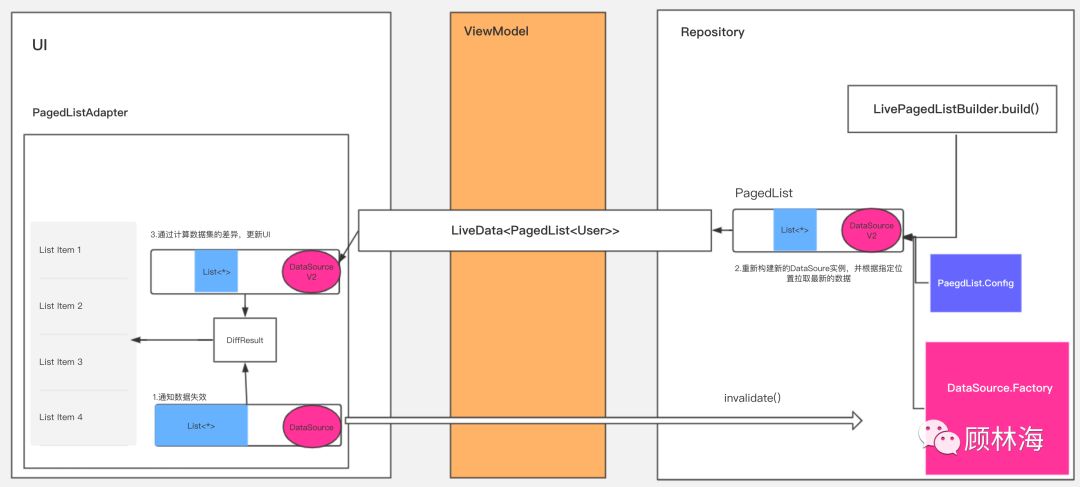
当数据发生了更新,Paging幕后又做了哪些工作呢?
正如前文所说,数据是动态的, 假设用户通过操作添加了一个联系人,这时数据库中的数据集发生了更新。
因此,这时屏幕中RecyclerView对应的PagedList和DataSource已经没有失效了,因为DataSource中的数据是之前数据库中数据的快照,数据库内部进行了更新,PagedList从旧的DataSource中再取数据毫无意义。
因此,Paging组件接收到了数据失效的信号,这意味着生产者需要重新构建一个PagedList,因此DataSource.Factory再次提供新版本的数据源DataSource V2——其内部持有了最新数据的快照。
在创建新的PagedList的时候,针对PagedList内部的初始化需要慎重考虑,因为初始化的数据需要根据用户当前屏幕中所在的位置(position)进行加载。
通过LiveData,UI层级再次观察到了新的PagedList,并再次通过submitList()函数注入到PagedListAdapter中。
和初次的数据渲染不同,这一次我们使用到了PagedListAdapter内部的AsyncPagedListDiffer对两个数据集进行差异性计算——这避免了notifyDataSetChanged()的滥用,同时,差异性计算的任务被切换到了后台线程中执行,一旦计算出差异性结果,新的PagedList会替换旧的PagedList,并对列表进行 增量更新。
四、DataSource数据源简介
Paging分页组件的设计中,DataSource是一个非常重要的模块。顾名思义,DataSource中的Key对应数据加载的条件,Value对应数据集的实际类型, 针对不同场景,Paging的设计者提供了三种不同类型的DataSource抽象类:
PositionalDataSource<T>
ItemKeyedDataSource<Key, Value>
PageKeyedDataSource<Key, Value>
接下来我们分别对其进行简单的介绍。
本章节涉及的知识点非常重要,但不作为本文的重点,笔者将在该系列的下一篇文章中针对DataSource的设计与实现进行更细节的探究,欢迎关注。
1.PositionalDataSource
PositionalDataSource 是最简单的DataSource类型,顾名思义,其通过数据所处当前数据集快照的位置(position)提供数据。
PositionalDataSource 适用于 目标数据总数固定,通过特定的位置加载数据,这里Key是Integer类型的位置信息,并且被内置固定在了PositionalDataSource类中,T即数据的类型。
最容易理解的例子就是本文的联系人列表,其所有的数据都来自本地的数据库,这意味着,数据的总数是固定的,我们总是可以根据当前条目的position映射到DataSource中对应的一个数据。
来看Room组件配置的dao对应编译期生成的源码:
```java
// 1.Room自动生成了 DataSource.Factory
@Override
public DataSource.FactorygetAllStudent() {
// 2.工厂函数提供了PositionalDataSource
return new DataSource.Factory() {@Overridepublic PositionalDataSourcecreate() {return new PositionalDataSource(__db, _statement, false , "Student") {// ...
};
}
};
}2.ItemKeyedDataSource
ItemKeyedDataSource适用于目标数据的加载依赖特定条目的信息,比如需要根据第N项的信息加载第N+1项的数据,传参中需要传入第N项的某些信息时。
同样拿联系人列表举例,另外的一种分页加载方式是通过上一个联系人的name作为Key请求新一页的数据,因为联系人name字母排序的原因,DataSource很容易针对一个name检索并提供接下来新一页的联系人数据——比如根据Alice找到下一个用户Bob(A -> B)。
3.PageKeyedDataSource
更多的网络请求API中,服务器返回的数据中都会包含一个String类型类似nextPage的字段,以表示当前页数据的下一页数据的接口(比如Github的API),这种分页数据加载的方式正是PageKeyedDataSource的拿手好戏。
这是日常开发中用到最多的DataSource类型,和ItemKeyedDataSource不同的是,前者的数据检索关系是单个数据与单个数据之间的,后者则是每一页数据和每一页数据之间的。
同样拿联系人列表举例,这种分页加载方式是按照页码进行数据加载的,比如一次请求15条数据,服务器返回数据列表的同时会返回下一页数据的url(或者页码),借助该参数请求下一页数据成功后,服务器又回返回下下一页的url,以此类推。
总的来说,DataSource针对不同种数据分页的加载策略提供了不同种的抽象类以方便开发者调用,很多情况下,同样的业务使用不同的DataSource都能够实现,开发者按需取用即可。
五、最佳实践
现在读者对多种不同的数据源DataSource有了简单的了解,先抛开 分页列表 的业务不谈,我们思考另外一个问题:
当列表的数据通过多个层级 网络请求(Network) 和 本地缓存 (Database)进行加载该怎么处理?
回答这个问题,需要先思考另外一个问题:
Network+Database的解决方案有哪些优势?
1.优势
读者认真思考可得,Network+Database的解决方案优点如下:
1、非常优秀的离线模式支持,即使用户设备并没有链接网络,本地缓存依然可以带来非常不错的使用体验;
2、数据的快速恢复,如果异常导致App的终止,本地缓存可以对页面数据进行快速恢复,大幅减少流量的损失,以及加载的时间。
3、两者的配合的效果总是相得益彰。
看起来Network+Database是一个非常不错的数据加载方案,那么为什么大多数场景并没有使用本地缓存呢?
主要原因是开发成本——本地缓存的搭建总是需要额外的代码,不仅如此,更重要的原因是,数据交互的复杂性也会导致额外的开发成本。
2.复杂的交互模型
为什么说Network+Database会导致 数据交互的复杂性 ?
让我们回到本文的 联系人列表 的示例中,这个示例中,所有联系人数据都来自 本地缓存,因此读者可以很轻易的构建出该功能的整体结构:
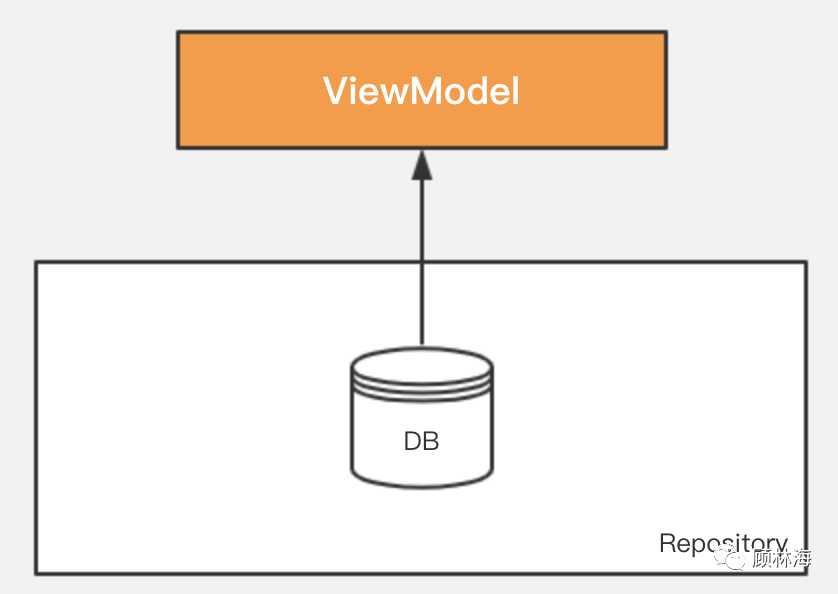
如图所示,ViewModel中的数据总是由Database提供,如果把数据源从Database换成Network,数据交互的模型也并没有什么区别—— 数据源总是单一的。
那么,当数据的来源不唯一时——即Network+Database的数据加载方案中会有哪些问题呢?
我们来看看常规的实现方案的数据模型:
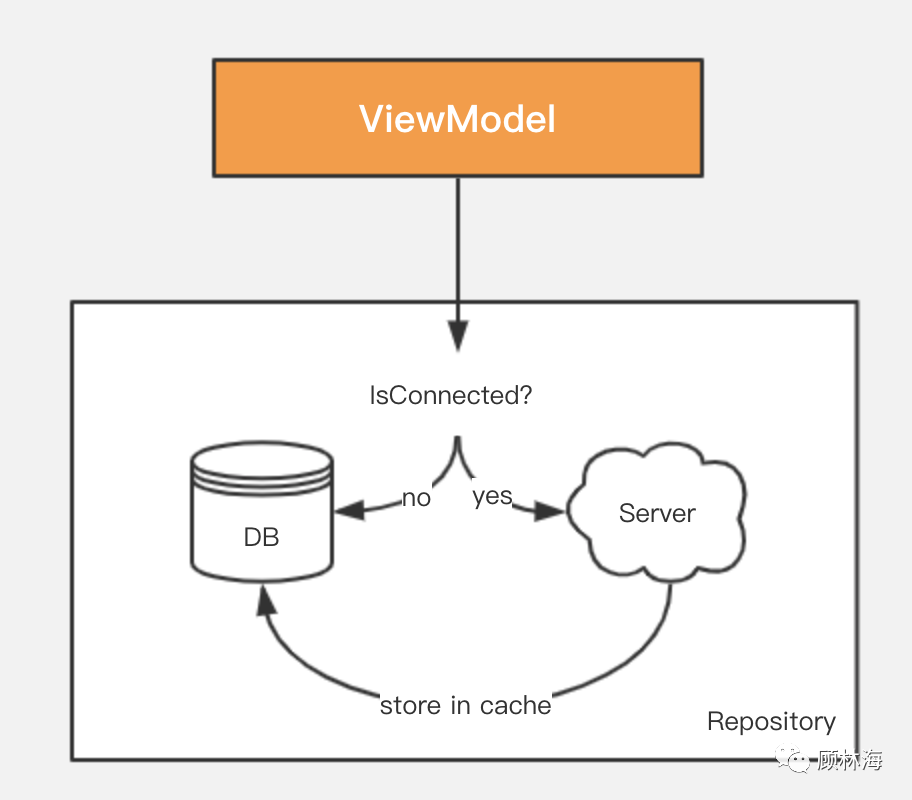
如图所示,ViewModel尝试加载数据时,总是会先进行网络判断,若网络未连接,则展示本地缓存,否则请求网络,并且在网络请求成功时,将数据保存本地。
乍得一看,这种方案似乎并没有什么问题,实际上却有两个非常大的弊端:
2.1 业务并非这么简单
首先,通过一个boolean类型的值就能代表网络连接的状态吗?显而易见,答案是否定的。
实际上,在某些业务场景下,服务器的连接状态可以是更为复杂的,比如接收到了部分的数据包?比如某些情况下网络请求错误,这时候是否需要重新展示本地缓存?
若涉及到网络请求的重试则更复杂,成功展示网络数据,再次失败展示缓存——业务越来越复杂,我们甚至会逐渐沉浸其中无法自拔,最终醒悟,这种数据的交互模型完全不够用了 。
2.2 无用的本地缓存
另外一个很明显的弊端则是,当网络连接状态良好的时候,用户看到的数据总是服务器返回的数据。
这种情况下,请求的数据再次存入本地缓存似乎毫无意义,因为网络环境的通畅,Database中的缓存从来未作为数据源被展示过。
3.使用单一数据源
使用 单一数据源 (single source of truth)的好处不言而喻,正如上文所阐述的,多个数据源 反而会将业务逻辑变得越来越复杂,因此,我们设计出这样的模型:

ViewModel如果响应Database中的数据变更,且Database作为唯一的数据来源?
其思路是:ViewModel只从Database中取得数据,当Database中数据不够时,则向Server请求网络数据,请求成功,数据存入Database,ViewModel观察到Database中数据的变更,并更新到UI中。
这似乎无法满足上文中的需求?读者认真思考可知,其实是没问题的,当网络连接发生故障时,这时向服务端请求数据失败,并不会更新Database,因此UI展示的正是期望的本地缓存。
ViewModel仅仅响应Database中数据的变更,这种使用 单一数据源 的方式让复杂的业务逻辑简化了很多。
4.分页列表的最佳实践
现在我们理解了 单一数据源 的好处,该方案在分页组件中也同样适用,我们唯一需要实现的是,如何主动触发服务端数据的请求?
这是当然的,因为Database中依赖网络请求成功之后的数据存储更新,否则列表所展示的永远是Database中不变的数据——别忘了,ViewModel和Server之间并没有任何关系。
针对Database中的数据更新,简单的方式是 直接进行网络请求,这种方式使用非常普遍,比如,列表需要下拉刷新,这时主动请求网络,网络请求成功后将数据存入数据库即可,这时ViewModel响应到数据库中的更新,并将最新的数据更新在UI上。
另外一种方式则和Paging分页组件本身有关,当列表滚动到指定位置,需要对下一页数据进行加载时,如何向网络拉取最新数据?
Paging为此提供了BoundaryCallback类用于配置分页列表自动请求分页数据的回调函数,其作用是,当数据库中最后一项数据被加载时,则会调用其onItemAtEndLoaded函数:
class MyBoundaryCallback(val database : MyLocalCacheval apiService: ApiService
) : PagedList.BoundaryCallback<User>() {
override fun onItemAtEndLoaded(itemAtEnd: User) {
// 请求网络数据,并更新到数据库中
requestAndAppendData(apiService, database, itemAtEnd)
}
}
BoundaryCallback类为Paging通过Network+Database进行分页加载的功能完成了最后一块拼图,现在,分页列表所有数据都来源于本地缓存,并且复杂的业务实现起来也足够灵活。
5.更多优势
通过Network+Database进行Paging分页加载还有更多好处,比如更轻易管理分页列表 额外的状态 。
不仅仅是分页列表,这种方案使得所有列表的 状态管理 的更加容易,笔者为此撰写了另外一篇文章去阐述它,篇幅所限,本文不进行展开,有兴趣的读者可以阅读。
Android官方架构组件Paging-Ex:列表状态的响应式管理
https://juejin.im/post/5ce6ba09e51d4555e372a562
六、总结
本文对Paging进行了系统性的概述,最后,Paging到底是一个什么样的分页库?
首先,它支持Network、Database或者两者,通过Paging,你可以轻松获取分页数据,并直接更新在RecyclerView中。
其次,Paging使用了非常优秀的 观察者模式 ,其简单的API的内部封装了复杂的分页逻辑。
第三,Paging灵活的配置和强大的支持——不同DataSource的数据加载方式、不同的响应式库的支持(LiveData、RxJava)等等,Paging总是能够胜任分页数据加载的需求。
更多 & 参考
再次重申,强烈建议 读者将本文作为学习Paging 阅读优先级最高的文章,所有其它的Paging中文博客阅读优先级都应该靠后。
——是因为本文的篇幅较长吗?(1w字的确...)不止如此,本文尝试对Paging的整体结构进行拆分,笔者认为,只要对整体结构有足够的理解,一切API的调用都轻而易举。但如果直接上手写代码的话,反而容易造成 只见树木,不见森林 之感,上手效率反而降低。
推荐阅读
(点击标题可跳转阅读)
App流畅度优化:利用字节码插桩实现一个快速排查高耗时方法的工具
谈谈Android AOP技术方案
代理模式以及在Android中的使用
看完这篇 HTTPS,和面试官扯皮就没问题了
觉得本文对你有帮助?请分享给更多人


wx号:gulinhai531
顾林海公众号
不定期推出优质文
章,喜欢的朋友们
给我个好看。
好文章,我在看❤️












)






