作者:索增增(小红书)、宋泽辉(小红书)、张佐玮(阿里云)
背景介绍
Koordinator 是一个开源项目,基于阿里巴巴在容器调度领域多年累积的经验孵化诞生,目前已经支持了 K8s 生态内的在离线混部,然而在 K8s 生态外,仍有相当数量的用户会将大数据任务运行在 Apache Hadoop YARN [ 1] 这类资源管理系统中。虽然目前一些计算引擎提供了 K8s operator,将任务接入到了 K8s 生态,但不可否认的是,目前 YARN 生态依然保持一定的活跃度,典型的例子是包括阿里云在内的一系列主流云厂商仍然提供类似 E-MapReduce [ 2] 的产品,支持用户将大数据作业提交到 YARN 上运行,这点从产品的受欢迎程度上可见一斑。
小红书是 Koordinator 社区的活跃成员,为了进一步丰富 Koordinator 支持的在离线混部场景,社区会同来自阿里云、小红书、蚂蚁金服的开发者们共同启动了 Hadoop YARN 与 K8s 混部项目,支持将超卖的 Batch 资源提供给 Hadoop YARN 使用,进一步提升集群资源的使用效率,该项目目前已经在小红书生产环境正式投入使用。
技术原理
总体原则
在此之前,业界已经有关于 K8s 与 YARN 混部的一些内部实践,不过受限于落地场景,大部分的实现方式都对 YARN 系统本身做了相当多的侵入式改造,在运维和迭代上对普通用户来说不够友好。为了让更多用户享受到社区的开源技术红利,Koordinator 的设计将遵循以下几个原则。
- 离线作业的提交入口依然为 YARN 保持不变。
- 基于 Hadoop YARN 开源版本,原则上不对 YARN 做侵入式改造。
- Koordinator 提供的混部资源,既可被 K8s Pod 使用,也可被 YARN task 使用,不同类型的离线应用可在同一节点内共存。
- 单机 QoS 策略由 Koordlet 统一管理,并兼容 YARN task 的运行时。
方案设计
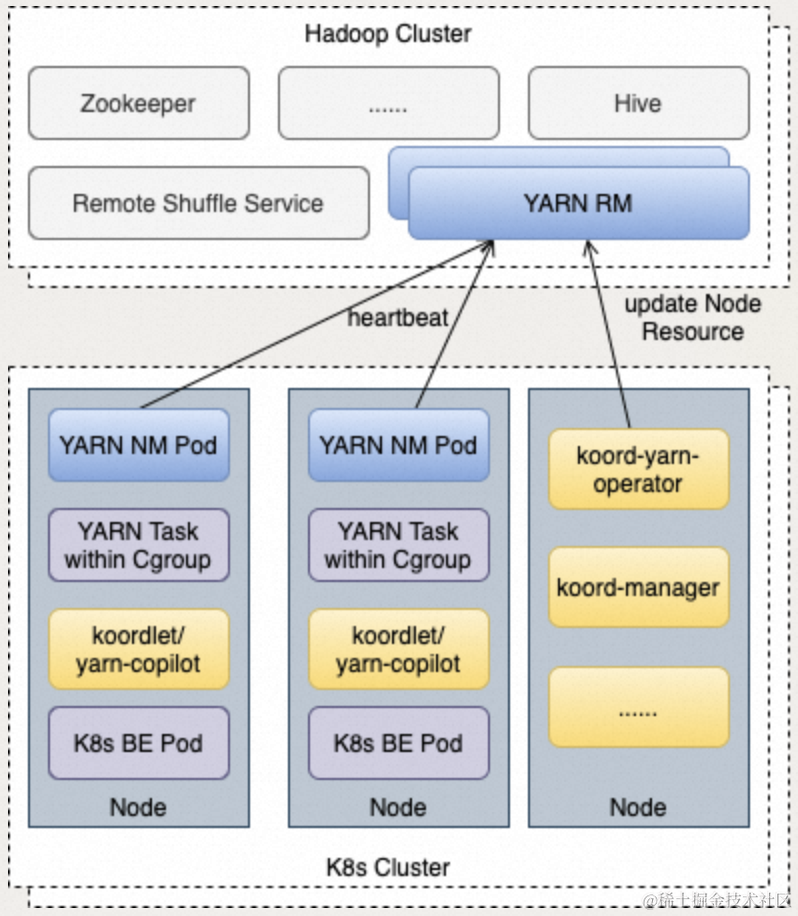
ResourceManager 和 NodeManger 是 YARN 的核心组件,ResourceManager 在管控侧负责接收任务以及资源调度,NodeManager 负责任务的生命周期管理。在 YARN & K8s 混部场景下,RM 将仍然作为 YARN 集群的核心组件独立部署,NM 将以容器的形式部署。
Koordinator 新增了 koord-yarn-operator 模块,负责将 Batch 资源量同步给 YARN RM。为了对资源进行更精细的管理,YARN task 将与 NM 的资源管理相互独立,NM 在部署时只需按自身开销申请 Batch 混部资源。YARN 任务的资源使用通过 cgroup 来管理(LinuxContainerExecutor 模式),将 cgroup 路径在 besteffort Pod QoS 下,确保可以和其他 K8s Pod 一样,统一在 besteffort 分组下管理。
koodlet 目前在单机支持了一系列的 QoS 策略,这些同样需要针对 YARN 场景进行适配。对于资源隔离参数,例如 Group Identity,Memory QoS,L3 Cache 隔离等,koordlet 将根据设计的 cgroup 层级进行适配。而对于驱逐和压制这类动态策略,koordlet 将新增一个 sidecar 模块 koord-yarn-copilot,用于对接 YARN 场景的各类数据和操作,包括 YARN task 元信息采集、资源指标采集、task 驱逐操作等,所有 QoS 策略仍然保留在 koordlet 内,koordlet 内部相关模块将以 plugin 形式对接 koord-yarn-copilot 接口。同时,koord-yarn-copilot 的接口设计将保留一定的扩展性,后续可用于对接其他资源框架。
更多有关 YARN & K8s 混部的详细设计,可参考社区设计文档 [ 3] 。
小红书在离线混部实践
业务背景
在降本增效的大背景下,小红书内部商业化,社区搜索等业务存在大量的算法类 Spark 任务因为离线集群资源紧张导致任务堆积,不能得到及时处理,同时在线集群在业务低峰时段资源使用率较低;另一方面,相当占比的 Spark 任务资源调度仍旧运行在 YARN 调度器上;基于此现状,结合小红书在在离线混部方面的既有能力,通过打通 K8s 调度器与 YARN 调度器之间的资源视图,并在单机侧支持了 YARN task 粒度的驱逐与 QoS 保障策略,最终实现了在维持离线业务提交入口和使用习惯不发生任何改变的前提下,让大量的 Spark 任务稳定运行在在线闲时资源上,有效提升在线集群资源利用率的同时,大大缓解业务资源压力,并且有效降低业务离线资源使用成本。
在小红书的实践经验中,有以下几个关键技术点值得分享:
- 针对 local shuffle 带来的磁盘性能瓶颈问题, 我们通过 RemoteShuffleService 技术手段降低本地磁盘 IO 开销,提升 IO 性能,有效提升离线业务运行效率与稳定性,另一方面,也能有效规避离线对在线在 IO 层面的干扰问题。
- 小红书参与在离线混部的业务场景复杂,除了大数据 Spark 场景以外,还有转码,离线推理,训练等其他业务场景,为了确保高优 Spark 任务运行时稳定性,我们在 YARN 资源同步,单机的驱逐策略,QoS 保障策略等方面,都做了细粒度的优先级区分和策略优化,例如:离线资源超量上报(为了压榨资源,提高利用率),单机冲突处理,资源冲突或者离线资源满足度过低优先驱逐转码等时效性要求不高的离线,离线差异化 QoS 保障策略等。综合以上优化手段,最终实现了 Spark 任务的稳定高效运行和资源的充分利用。
落地收益
截止目前,小红书在离线混部方案已大规模落地,取得了以下业务结果:
- 覆盖数万台在线集群节点,为离线业务稳定提供数十万核的计算资源
- 离线任务驱逐率低于 1%,作业混部后基本不受影响
- 混部集群 CPU 利用率平均增长 8% ~ 10%,部分均值 CPU 利用率能达到 45% 以上,大幅提升了集群资源使用效率
随着增量业务场景的不断接入,上述收益规模还在持续增长。
如何使用
支持 K8s 与 YARN 混部的相关功能目前已经基本研发完成,Koordinator 团队目前正努力完成发布前的一系列准备工作,敬请期待!
如果您也有意参与项目的合作共建,或是对 K8s & YARN 混部感兴趣,欢迎您到社区专项讨论区 [ 4] 下方留言,我们将第一时间联系您。参考留言格式:
联系人(gihub-id/e-mail):, e.g. @koordinator-dev
您任职/就读/参与的公司/学校/组织名称:e.g. koordinator community
社区参与意向:e.g. 希望能够参与研发/学习大数据&云原生混部/将 K8s&YARN 混部功能在生产环境落地/其它。
您对 “K8s&YARN混部” 的期待:
相关链接:
[1] Apache Hadoop YARN
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
[2] E-MapReduce
https://www.aliyun.com/product/bigdata/emapreduce
[3] 设计文档
https://koordinator.sh/zh-Hans/docs/next/best-practices/colocation-of-hadoop-yarn/
[4] 专项讨论区
https://github.com/koordinator-sh/koordinator/discussions/1297
点击此处,即可查看 Koordinator 的详细介绍和使用方法!
)



)
)
![[管理者与领导者-129]:很多人对高情商的误解,工程师要扩展自己的情商吗?工程师如何扩展自己的情商?](http://pic.xiahunao.cn/[管理者与领导者-129]:很多人对高情商的误解,工程师要扩展自己的情商吗?工程师如何扩展自己的情商?)






)


)
制图)

