系列文章目录
题目:Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
论文:https://arxiv.org/pdf/2304.06714.pdf
任务:无条件3D生成(如从噪音中,生成不同的车等)、单视图3D生成
机构:Hansheng Chen,1,* Jiatao Gu,2 Anpei Chen, 同济、苹果、加利福尼亚大学
代码:https://github.com/Lakonik/SSDNeRF
文章目录
- 系列文章目录
- 摘要
- 一、前言
- 二、相关工作
- 2.1. 3D GANs
- 2.2 View-Conditioned 回归和生成
- 2.3 自动解码器和 Diffusion NeRF
- 2.4 . NeRF 作为 Auto-Decoder
- 2.5 生成和重建中的挑战
- 2.6 潜在扩散模型
- 三、本文方法
- 3.1 单阶段扩散NeRF训练
- 3.2 图像引导下的采样和微调
- 3.3 一些细节
- 四、实验
- 41 数据集
- 4.2 无条件生成
- 4.3 稀疏视图NeRF重建
- 4.4 在稀疏视图数据上,训练SSDNeRF
- 4.5 NeRF插值
- 五、代码
- 局限性
- 拓展
- 1.FID和KID、LPIPS指标
- 2. TV 正则化
摘要
3D-aware image synthesis任务,包括场景生成和 image-based 的新视图合成。本文提出了SSDNeRF,使用扩散模型从不同对象的多视图图像中学习神经辐射场(NeRF)的可推广先验。先前的研究使用两阶段方法,依赖于Pretrained NeRF作为真实数据来训练扩散模型。相比之下,SSDNeRF作为单阶段、端到端的训练范式,联合优化NeRF的自动decode 和 latent Diffusion模型,实现同时三维重建和先验学习(甚至包括稀疏视图)。测试时,可以直接对扩散先验进行无条件生成,或将其与不可见物体的任意观测相结合,进行NeRF重建。在无条件生成和单/稀疏视图三维重建方面,SSDNeRF显示了与 task-specific 方法相当或更好的鲁棒结果。
一、前言
伴随 神经渲染和生成模型的发展,3D内容生成(如单/多视图3D重建和3D内容生成)的单一算法得以发展,但缺少全面的框架来连接多任务的技术。神经辐射场(NeRF)通过超分拟合求解逆渲染问题,在新视图合成中显示出令人印象深刻的结果(但只适用密集视图,难以推广到稀疏观测)。相比之下,许多稀疏视图三维重建方法[pixelNeRF,Mvsnerf,ViT NeRF] 依赖于前馈的 image-to-3D 编码器,但它们不能处理遮挡区域的模糊性,也不能生成清晰的图像。在无条件生成方面,3D感知生成对抗网络(GAN)[34,5,18,14]在单图像鉴别器的使用上受到了部分限制,这不能使交叉视图关系能够有效地从多视图数据中学习。
之前的工作[如Score-based NeRF、Gaudi、triplane diffusion、Diffrf]中,类似的ldm已经应用于2D和3D生成,但它们通常需要两阶段训练,第一阶段排除Diffusion model 只预训练 VAE( 变分自动编码器) 或自动解码器。然而,在扩散nerf的情况下,我们认为由于逆渲染的不确定性,两阶段训练在latent code 中诱发噪声模式和伪影(特别是稀疏视图时),这阻止了 Diffusion model 有效地学习干净的潜在流形。为了解决这个问题,
本文提出一个统一框架SSDNeRF(单阶段扩散NeRF),用三维潜在扩散模型(LDM)建模场景latent code 的生成先验,从多视图图像中学习可泛化的三维先验,用于处理各种三维任务(图1)。单阶段训练范式,使 Diffusion 和 NeRF 权重的端到端学习成为可能。这种方法将生成的bias和渲染的bias 一致地结合在一起,以提高整体性能,并允许对稀疏视图数据进行训练。此外,学习到的无条件扩散模型的三维先验可以用于任意观测的灵活测试场景采样。
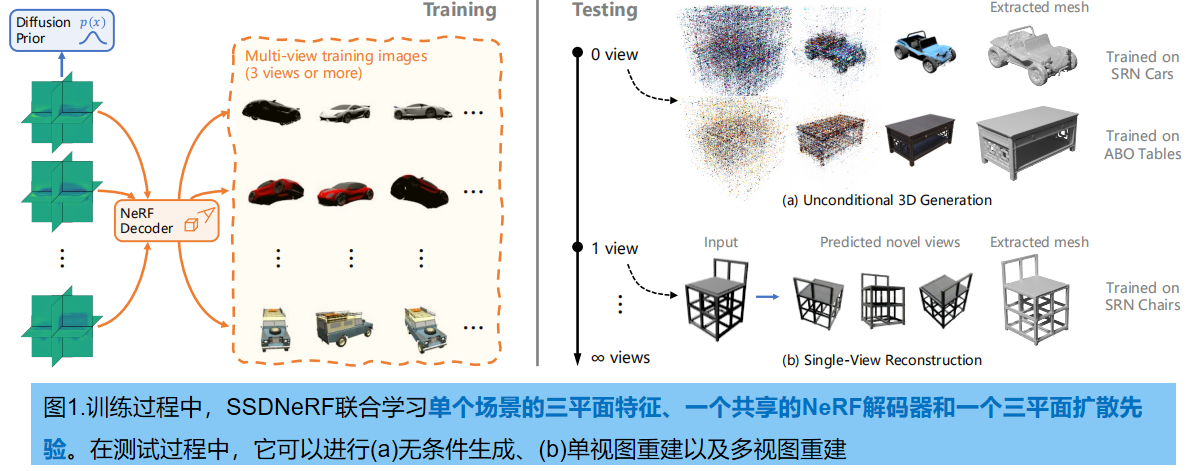
主要贡献如下:
1.提出SSDNeRF,一种统一的 un-conditional 3D生成和 image-base 3D重建方法;
2.作为新的单阶段训练范式,SSDNeRF从大量对象的多视图图像中联合学习NeRF重建和Diffusion模型(即使每个场景只有三个视图)
3.提出了一种 引导微调采样方案(guidance-finetuning sampling scheme),利用学习到的扩散先验,测试时从任意数量的视图进行3D重建.
二、相关工作
2.1. 3D GANs
通过将基于投影的渲染集成到生成器中,GAN 已经成功地用于三维生成。以前已经探索过各种3D表示(点云、长方体、球体[27]和体素);最近的NeRF 和带有体积渲染器的特征场[34,18,5],以及带有网格渲染器的可微表面[14]。上述方法都是用二维图像的Discrinimator 进行训练的,无法推理交叉视图关系,这使得它们严重依赖于三维一致性的模型 bias,不能有效地利用多视图数据来学习复杂和多样的几何图形。三维gan主要应用于无条件生成。虽然通过GAN inversion[12]可以完成图像的3D重建,但由于潜在表达能力有限,并不能保证真实度,如论文[Diffrf、RenderDiffusion]所述。
2.2 View-Conditioned 回归和生成
稀疏三维重建可以通过从输入图像中回归出的新视图来解决,提出的各种架构[8,59,28,61]将图像编码为 volume features,通过体渲染投影到监督的目标视图。然而,它们不能推理模糊性,并产生多样化和有意义的内容,这往往会导致模糊的结果。相比之下, image-conditioned 的生成模型能更好地合成不同的内容:3DiM [57]提出从 view-conditioned 的图像扩散模型中生成新的视图,但该模型缺乏三维一致性偏差。[Sparsefusion、Nerdi、Nerfdiff ] 将 image-conditioned 的二维扩散模型的先验提取成nerf,以加强三维约束。这些方法与我们的轨迹是平行的,因为它们建模了图像空间中的交叉视图关系,而我们的模型本质上是三维的
2.3 自动解码器和 Diffusion NeRF
NeRF的单一场景拟合方案,可以推广到多场景,通过在所有场景中共享部分参数,将其余的作为单独的场景代码[7]。因此,多场景NeRF 可以被训练为自动解码器[35],共同学习 code
bank和 共享Decoder 的权重。通过适当的架构,scene codes 可以被视为高斯先验的 latent,允许3D completion 甚至生成[24,48,38]。然而,就像3D GAN一样,这些 latent 并没有足够的表达力来忠实地重建详细的对象。[Gaudi、From data to functa、Rodin等] 改进了具有潜在扩散先验的普通自动解码器。DiffRF [32]在执行3D completion 之前利用DIffusion。这些方法在两阶段独立训练 Auto-Decoder 和 Diffusion models,受到局限。
2.4 . NeRF 作为 Auto-Decoder
给定一组场景的二维images和对应相机参数,可以在三维空间拟合出场景的光场,表示为光学函数 yψ (r)(其中r 用于参数化世界空间中一条射线的端点和方向,ψ表示模型参数,y∈R3+ 表示接收到光线的RGB格式。NeRF 将光场表示为 沿光线通过三维体积的集成辐射(具体原理见我的blog:【三维重建】NeRF原理+代码讲解)。
NeRF还可以通过在所有场景[7]中共享部分模型参数来推广到多场景设置。给定多个场景{yijgt,rijgt},其中yijgt,rijgt 是第 i 个场景的第 j 对RGB像素和射线,可以通过最小化L2渲染损失来优化每个场景码 {xi} 和共享参数 ψ:
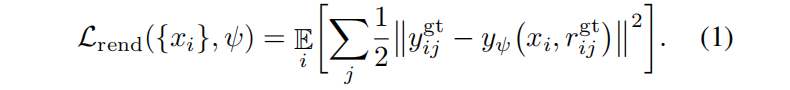
有了这个目标,模型被训练为一个自动解码器。场景码 {xi} 可以解释为latent code。在独立高斯分布的假设下,光学函数可以视为解码器的形式:
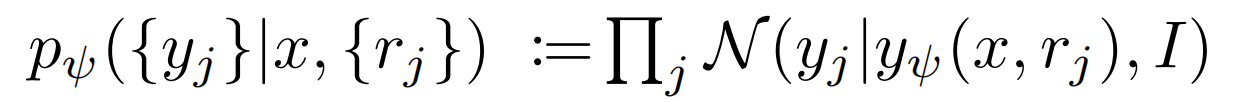
2.5 生成和重建中的挑战
具有训练权重ψ 的 auto-decoder 可以通过解码从高斯先验中提取的 latent code 来进行无条件生成。然而,为了保证生成的连续性,需要一个低维的潜在空间和一个复杂的解码器,这增加了优化中真实重建任何视图的困难。
2.6 潜在扩散模型
潜在扩散模型(LDM)在参数为ϕ的潜在空间中学习先验分布 pϕ(x),使更有表达能力的潜在表示(如二维图像网格)成为可能。在神经场生成方面,之前的工作[2,32,13,47]采用了两阶段的训练方案:首先训练自动解码器来获得每个场景的潜在码 xi,然后将其作为真实数据来训练LDM。LDM将高斯噪声 ϵ∼N(0,I)注入到 xi 中,在经验噪声调度函数α(t),σ(t) 的扩散时间步长 t 处产生噪声码 xi(t) := α(t)xi +σ(t)ϵ。然后,一个具有可训练权重 ϕ 的去噪网络去除 xi(t) 中的噪声,以预测一个去噪码 x ^ \hat{x} x^i。该网络常用简化的L2去噪损失来训练:
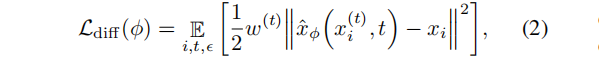
w(t) 是一个经验的时间相关的加权函数,和 x ^ \hat{x} x^ϕ(xi(t),t) 制定了时间分割去噪网络。
- 无条件/引导采样
使用训练好的权重 ϕ,各种解释器(例如DDIM )从扩散先验 pψ(x) 中采样,递归去噪x(t),从随机高斯噪声x(t)开始,直到达到去噪状态x(0)。采样过程可以由渲染损失对已知观测值的梯度来指导,允许在测试时从图像进行三维重建。
- 两阶段训练三维任务的局限性
使用2D图像VAEs的LDM 通常分两个阶段的]进行训练;使用NeRF自动解码器训练LDM时:通过基于渲染的优化,来获得一个expressive 的latent code是欠确定,导致去噪网络的噪声(图2左上角);此外,从没有学习先验的稀疏视图中重建nerf是非常困难的(图2的左下角),这将训练限制在密集视图设置中。

三、本文方法
SSDNeRF,一个expressive的三平面NeRF自动解码器与三平面 latent diffusion 模型连接起来的框架。图3提供了该模型的概述。
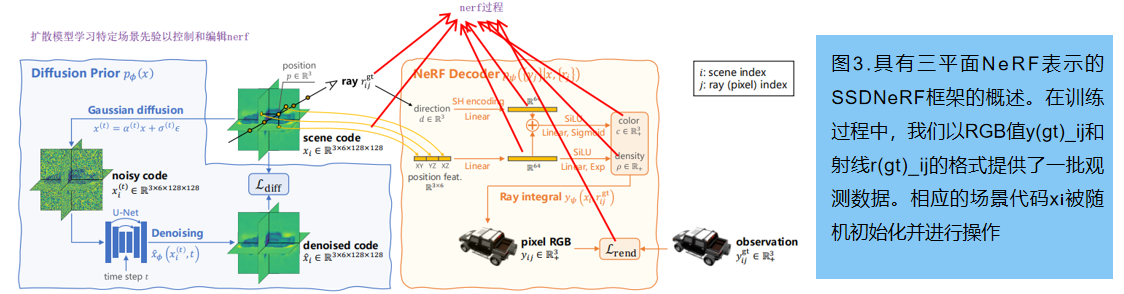
3.1 单阶段扩散NeRF训练
一个 auto-Decoder 可以看作是一种使用 lookup table Encoder的VAE,而不是典型的神经网络 Encoder。因此,训练目标可以以类似于VAEs的方式推导出。利用NeRF解码器
pψ({yj} | x, {rj}) 和扩散潜先验 pϕ(x),训练目标:最小化观测数据{yijgt,rijgt}的负对数似然(NLL)的变分上界。本文通过忽略 latent code 中的不确定性(方差),得到了一个简化的训练损失:
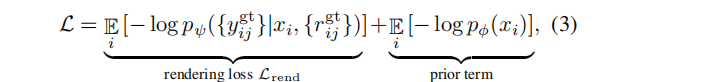
其中,场景码 {xi} 、先验参数 ϕ 和解码器参数 ψ 在单个训练阶段中共同进行优化。这个损失包括公式1中的渲染损失 Lrend,以及一个以NLL形式存在的扩散先验项。仿照[Maximum likelihood training of score-based diffusion models, Score-based generative modeling in latent space 等]论文,我们用等式(2)中的近似上界 Ldiff (也被称为分数蒸馏)代替扩散NLL 。加入经验权重因子,最终的训练目标:
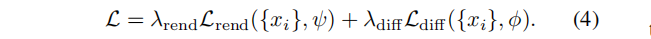
单阶段训练,使用以上损失约束场景码 {xi},允许学好的先验完成看不见的部分,这对于稀疏视图数据的训练特别有益(expressive triplane codes 严重不确定)
渲染和先验权重的平衡
渲染-先验的权重比 λrend/λdiff 是单阶段训练的关键。为保证泛化,设计了一个经验加权机制,其中扩散损失由场景码的 Frobenius 范数的指数移动平均(EMA)归一化,表示为:
λdiff := cdiff / EMA(||xi||2F) , cdiff 为固定尺度;
λrend := crend(1−e−0.1Nv)/Nv。 渲染权重由可见视图 Nv 的数量决定:基于Nv 的加权是对解码器 pψ 的校准,防止渲染损失根据射线数量线性缩放
与两阶段生成性神经场的比较
之前的两阶段方法[Gaudi,Diffrf,3d neural field generation using triplane diffusion] 在训练第一阶段,忽略了前项 λdiffLdiff。这可以看作是将 渲染-先验 的权重 λrend/λdiff 设置为无穷大,导致 biased和有噪声的场景码 xi。论文[3d neural field generation using triplane diffusion]通过在三平面场景代码上施加全变分(TV)正则化来强制进行平滑先验,部分地缓解了这一问题,类似于在潜在空间上的LDM约束(图2的中列)。 Control3Diff 提出对在单视图像上预训练的3D GAN生成的数据学习条件扩散模型。相比之下,我们的单阶段训练的目标是在促进端到端一致性之前直接纳入扩散。
3.2 图像引导下的采样和微调
为了实现可推广的快速NeRF重建,并覆盖了单视到密集多视的重建,我们建议执行图像引导采样,同时考虑扩散先验和渲染似然,对采样码进行微调。根据[Video diffusion models]重建引导的采样方法,计算了近似的渲染梯度g,即一个噪声码x(t):
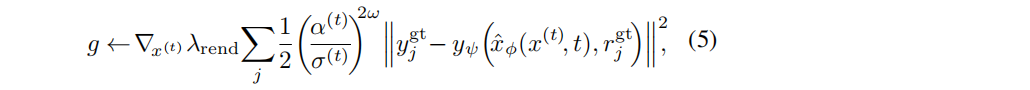
其中,(α(t)/σ(t))2ω 是一个基于信噪比(SNR)的附加加权因子 (超参数ω为0.5或0.25)。引导梯度g与无条件分数预测相结合,表示为对去噪输出 x ^ \hat{x} x^ 的修正:
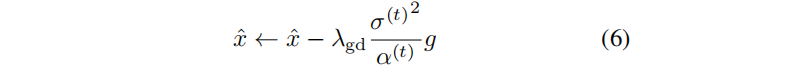
引导尺度为λgd。我们采用 预测-校正采样器[52],通过交替使用DDIM步骤和多个朗之万校正步骤来求解x(0)。
我们观察到,重建指导不能严格地执行忠实重建的渲染约束。为了解决这个问题,我们在等式4中重用,对采样的场景码 x 进行微调,同时冻结扩散和解码器参数:
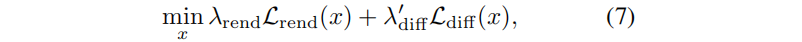
其中,λ’diff 是测试时间的先验权值,它应该低于训练权值 λdiff(因为从训练数据集学习到的先验在转移到不同的测试数据集时不太可靠)。使用Adam来优化代码x以进行微调
与以往的NeRF微调方法的比较
虽然用渲染损失进行微调在 view-conditioned 的NeRF回归方法[8,61]中很常见,但我们的微调方法在三维场景代码上使用扩散先验损失方面有所不同,这显著提高了对新视图的泛化,如5.3所示。
3.3 一些细节
- 先验梯度缓存
三平面NeRF重建需要对每个场景码 xi 至少进行数百次优化迭代。公式(4)中单阶段损失中,扩散损失Ldiff 比原生NeRF渲染损失Lrend 需要更长的时间来验证,降低了整体效率。为了加速训练和微调,我们引入了一种技术称为先验梯度缓存:Prior Gradient Caching,缓存的反传梯度 ∇xλdiffLdiff 重用在多个Adam步中,同时在每一步中刷新渲染梯度 ∇xλrendLrend 。它允许更少的扩散渲染比。以下是一次算法的伪代码:
- 去噪的参数化和加权
去噪模型 x ^ \hat{x} x^ϕ(x(t),t) 被实现为一个DDPM中的U-Net网络(共计122M参数)。其输入和输出分别是有噪声和去噪的三平面特征(三个平面的通道堆叠在一起)。对于测试的形式,我们采用[43:Progressive distillation for fast sampling of diffusion models]中的 v-参数化 v ^ \hat{v} v^ϕ(x(t),t),使 x ^ \hat{x} x^ = α(t)x(t)−σ(t) v ^ \hat{v} v^。关于等式(2)中扩散损失的加权函数w(t),LSGM [54]分别采用两种不同的机制来优化 latent xi 和扩散权重 ϕ ;我们发现使用NeRF自动解码器是不稳定的。相反,我们观察到在公式5中使用的基于信噪比的加权w(t) =(α(t)/σ(t))2ω 表现很好。
四、实验
41 数据集
实验采用ShapeNet SRN [6,48]和Amazon Berkeley Objects(ABO)Tables[9]数据集。SRN数据集提供了两类的单对象场景,即汽车和椅子,汽车的 train/test 划分为2458/703,椅子为4612/1317。每个训练场景有50个来自一个球体的随机视图,每个测试场景有251个来自上半球的螺旋视图。ABO Tables数据集提供了1520/156个表场景的训练/测试划分,其中每个场景有来自上半球的91个视图。渲染分辨率为128×128。
4.2 无条件生成
使用SRN Cars和ABO Tables 数据集对无条件生成进行评估。Cars数据集在生成尖锐和复杂的纹理方面提出了挑战,而Tables 数据集由不同的几何图形和真实的材料组成。模型在训练集的所有图像上进行1M次iter 训练。
- 验证方案和指标
对于SRN Cars,按照Functa,我们从扩散模型中抽取704个场景,并使用测试集中固定的251个摄像机姿态渲染每个场景。对于ABO tabel,按照DiffRF采样了1000个场景,并使用10个随机摄像机渲染每个场景。生成质量度量标注:Frechet Inception Distance (FID)和 Kernel Inception Distance (KID)。
-
与最新方法对比:
如表1所示,在SRN汽车上,一阶段SSDNeRF在KID(更适合小数据集)中明显优于EG3D。同时,它的FID明显优于Functa(使用了一个LDM,但具有低维的latent code)。在ABO tabels中,SSDNeRF的性能明显优于EG3D和DiffRF。 -
单阶段&两阶段:
在SRN Cars上,比较了单阶段训练,以及相同模型架构下的TV正则化两阶段训练,表1结果表明单阶段的优势。

4.3 稀疏视图NeRF重建
Cars数据提出了恢复不同纹理的挑战, chair 数据需要精确地重建不同的形状。模型在训练集的所有图像上进行训练8000次迭代,我们发现更长的时间表会导致重建看不见的物体的性能下降。这种行为与插值的结果相一致
- 评估方案和指标
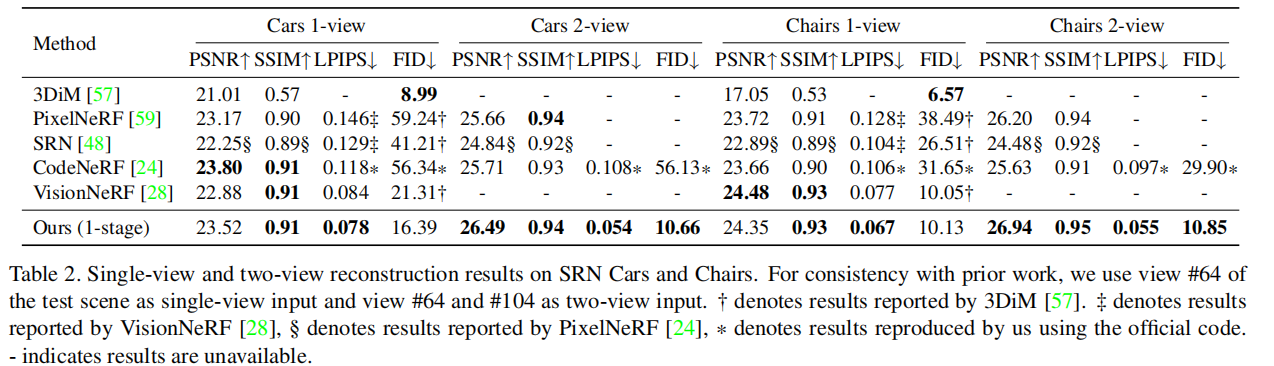
使用PixelNeRF [59]的评价指标:给定测试场景采样的输入图像,通过guidance-finetuning 获得三平面场景码,对未知视角图像,评估新视图质量。图像质量指标:平均峰值信号调压比(PSNR)、结构相似度(SSIM)和学习感知图像补丁相似度(LPIPS)[60]。以及合成图像和真实图像之间的FID(如3DiM)。
- 与其他方法比较
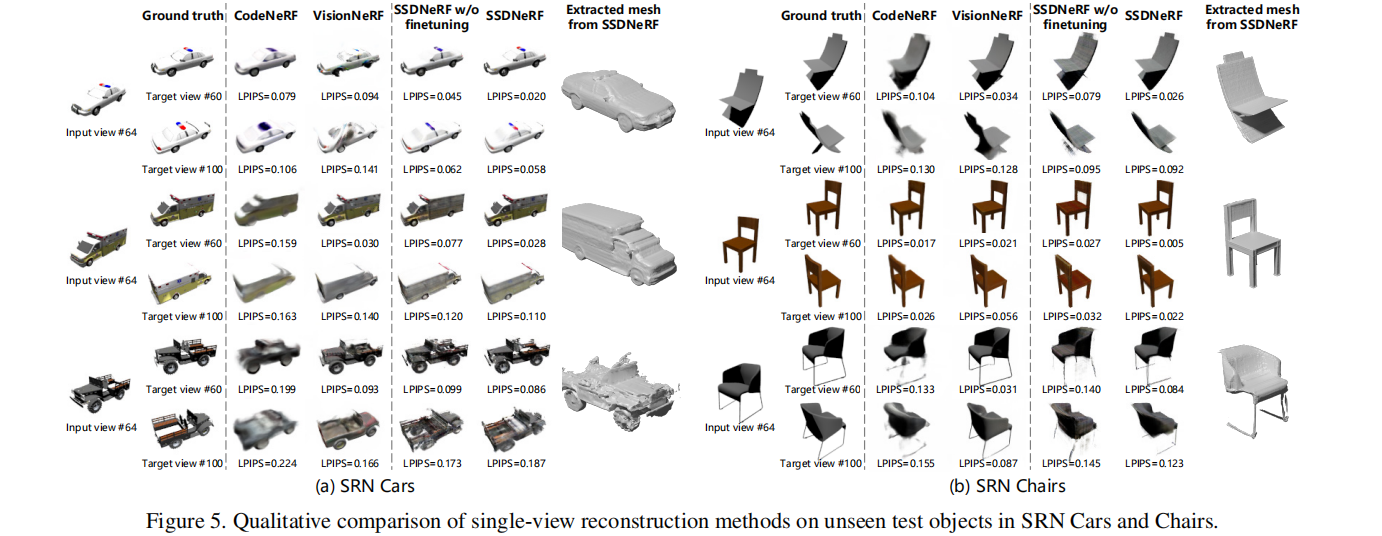
表2中:SSDNeRF有最好的LPIPS,感知保真度最好。3DiM生成高质量的图像(最好的FID),但对地面真相的保真度最低(PSNR);CodeNeRF报告了单视图汽车上最好的PSNR,但其有限的表达力导致输出模糊(图5)和LPIPS和FID;VisionNeRF在所有单视图指标上实现了平衡的性能,但可能难以在汽车看不见的一侧生成纹理细节(例如,图5中救护车的另一边)。此外,SSDNeRF在双视图重建方面具有明显的优势,在所有相关指标上取得最佳性能。
4.4 在稀疏视图数据上,训练SSDNeRF
本节在完整的SRN Cars训练集的稀疏视图子集上训练SSDNeRF,在每个场景中随机选取三个视图的固定集合。请注意,与密集视图训练相比,由于整个训练数据集已经减少到其原始大小的6%,因此性能将会有预期的合理下降。
- 无条件生成
在训练中途,将三平面code 重置到它们的平均值。这有助于防止模型陷入一个过度拟合几何伪影的局部最小值。相应地将训练时间延长一倍。该模型实现了一个良好的FID的19.04±1.10和一个KID/10−3的8.28±0.60。结果如图7所示。

- 单视角重建
我们采用与5.3相同的训练策略。通过我们的指导-微调方法,该模型获得了0.106的LPIPS分,甚至优于表2中之前使用完整训练集的大多数方法。
- 与TV正则化的比较
图8 (b)显示了在训练过程中从三个视图中学习到的场景latent code 所代表的RGB图像和几何图形。相比之下,采用电视正则化的普通三平面自动解码器(图8 (a))往往不能从稀疏视图重建场景,导致严重的几何伪影。因此,以前在稀疏视图数据上训练具有表达延迟的两阶段模型是不可行的。
4.5 NeRF插值
按照DDIM 的设置,对两个初始值 x(T)∼N(0,I) 进行采样,使用球面线性插值[46]( spherical linear interpolation)对其进行插值,然后使用确定性求解器得到插值样本。然而,正如[37,40]所指出的,标准的高斯扩散模型往往会导致非光滑的插值。在SSDNeRF中(结果如图9所示),我们发现早期停止稀疏视图重建训练的模型(a)产生合理的平滑过渡,而无条件生成训练的模型(b)产生不同但不连续的样本。这表明,早期停止保持了更平滑的先验,从而导致更好地泛化稀疏视图重建。

五、代码
即将到来。。。
局限性
目前,该方法训练和测试过程中都依赖于Ground Truth 摄像机的参数。未来的工作可能会探索transform-invariant 模型。此外,随着训练时间的延长,扩散先验会变得不连续,从而影响泛化。虽然暂时使用了早期停止,但更好的网络设计或更大的训练数据集可能能够从根本上解决这个问题。
拓展
1.FID和KID、LPIPS指标
Frechet Inception Distance (FID) 是一种用于评估 GAN 生成的图像质量的指标。它基于生成的图像与真实图像之间的Fréchet距离,该距离衡量了两个图像分布之间的相似性。FID越低,表示生成的图像质量越好。
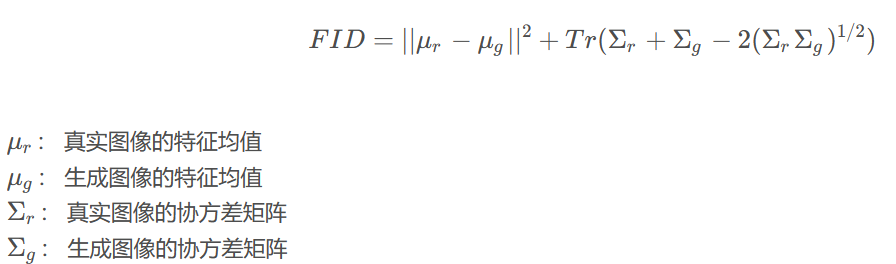
LPIPS:来自论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》
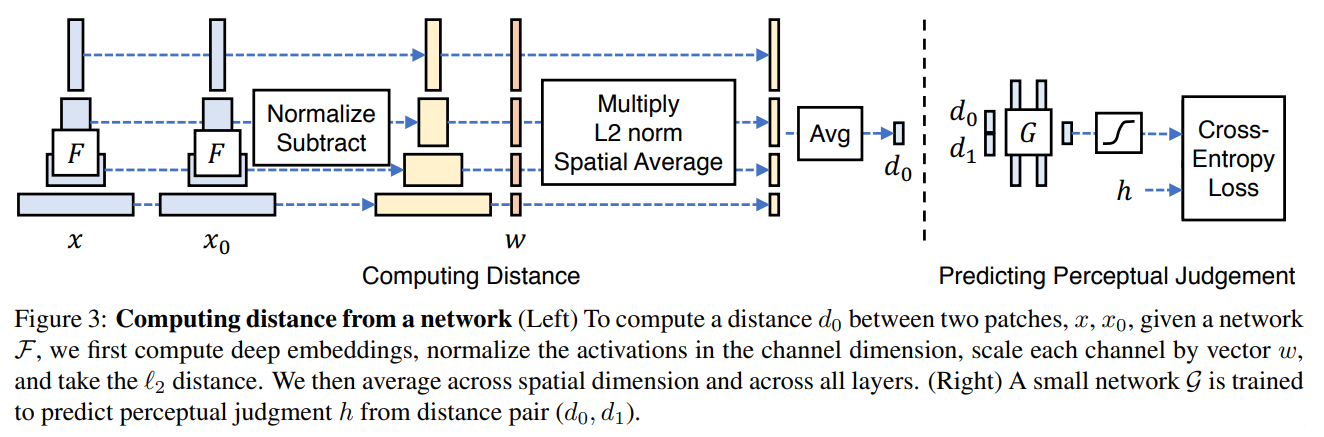
数值越小代表两张图像越相似。将两个输入送入神经网络F(可以为VGG、Alexnet、Squeezenet)中进行特征提取,对每个层的输出进行激活后归一化处理,然后经过w层权重点乘后计算L2距离。
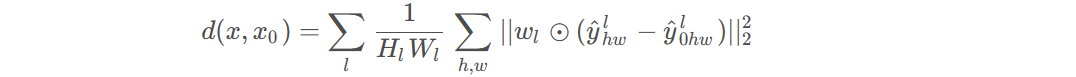
Kernel Inception Distance (KID) 是另一种评估 GAN 生成的图像质量的指标。它基于生成的图像与真实图像之间的核函数距离,通过将特征向量映射到高维空间,并计算它们之间的核矩阵的Frechet距离来衡量真实图像和生成图像之间的差异。KID也是一种衡量生成图像质量的指标,与FID类似。
具体代码实现,见 https://blog.51cto.com/u_16175458/6906283
2. TV 正则化
TV正则化,全称是Total Variation Regularization。TV正则化通过最小化图像的梯度幅度来实现对图像的平滑处理,
具体来说,对于一个二维图像,TV正则化可以通过最小化图像的梯度幅度来实现平滑处理。从而抑制图像中的噪声和细节。使图像变得更加平滑。TV正则化通常会被应用于优化问题的正则化项中,以平衡数据拟合和平滑度之间的关系。
对于NeRF(Neural Radiance Fields)等主要用于三维重建的方法,TV正则化有助于改善重建结果的质量。这是因为在三维重建中,由于数据的稀疏性和噪声等因素,重建结果往往会包含不必要的细节和噪声。
另外,TV正则化还可以帮助增强对深度学习模型的约束,有助于提高模型的泛化能力和抗噪声能力。因此,对于NeRF等三维重建任务,应用TV正则化有助于改善重建结果的质量,并提高模型的稳健性。
![[C++]模板进阶](https://img-blog.csdnimg.cn/direct/435583046bfe4e3b844d7dcf6bd64045.png)