//最近在复习,,java的进度会比较慢一些
目录
219 排序算法 基数排序2
220 排序算法 java排序
221 排序 e01 根据另一个数组次序排序
222 排序 e02 根据出现频率排序
thinking:关于比较器
223 排序 e03 最大间距 解法1(超出内存限制)
224 排序 e03 最大间距 解法2
225 排序 e03 最大间距 解法3
226 排序 e03 最大间距 解法4
227 图 基本概念
228 图 表示方式
229 图 java表示
230 图 DFS
219 排序算法 基数排序2
不可以先排百位再排个位的原因是因为,越到后面,优先级越高,最后排个位的话,个位的优先级最高,则会出现错误。
220 排序算法 java排序
221 排序 e01 根据另一个数组次序排序


题目说明:

竟然忘了。
 这里的i是指每一个元素,而不是索引。
这里的i是指每一个元素,而不是索引。
这是原先的,现在需要一开始的都按照数组二来排,因此要做更改。

于是,就按照数组二来排。
count[i]--:这个元素出现的次数减一。

在以上程序之后还要再加一个这个增强for,因为原先和数组二有重复元素的部分以及被count[i]--了,所以现在数组一中只剩下没有被采纳的数据,因此,再做一次增强for就好。
222 排序 e02 根据出现频率排序

把负数也纳进去,因此要i+100
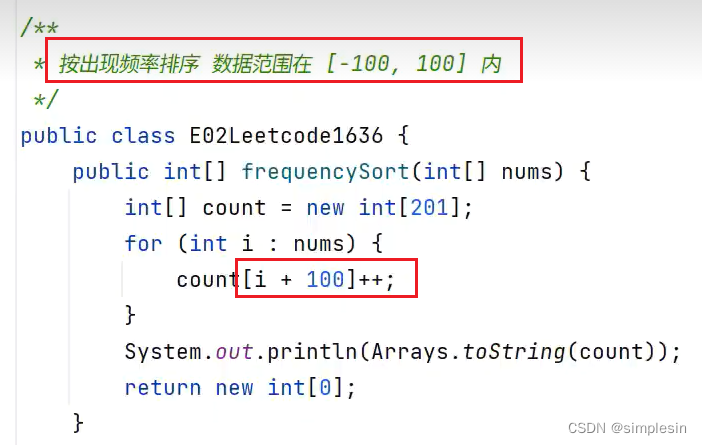
将这个数组放到流上面,对它进行包装,然后调用比较器方法(这里后面详细谈),之后再将包装类变为int,再变成数组return回去。

thinking:关于比较器
在Java中,我们可以使用`Arrays.stream(nums).boxed().sorted((a, b) -> { ... })`来实现一个自定义的比较器来进行排序。
在这个特定的例子中:
```java
Arrays.stream(nums).boxed().sorted((a,b)->{int af = count[a + 100];int bf = count[b + 100];if (af < bf){return -1;} else if(af >bf){return 1;}
```题目说,频率是按照升序来排列的,因此,af是第一个元素,bf是第二个元素。如果第一个元素的频率小于第二个元素的频率,那么就让它们保持原样并继续向下遍历下一个元素,因此返回-1。
为什么返回-1,是因为:
当你调用
return -1;这行代码的时候,你告诉 Java 要执行以下的操作:
- 当前正在比较的两个元素不需要改变其相对顺序;
- 继续向下游览其他尚未比较过的元素。
这是因为当我们遇到相同时,我们希望保留原来的顺序关系。也就是说,如果有两个元素具有相同的频率,我们不关心它们之间的具体顺序,只要它们仍然保持原来的位置即可。这就是为什么要返回
-1的原因——它意味着当前的两个元素无需互换位置,可以继续保持原有的顺序。而下一次循环会再次检查这些元素是否还需要调整顺序。
- 否则,如果我们发现第一个元素的频率大于第二个元素的频率,我们就需要将它放在前面以确保正确性。因此我们将返回 1 表示我们需要交换这两个元素的位置。
最后,他说要按照数值进行降序排列。

参考以上。 前者是要添加的。不要死记硬背,多试试就知道是谁减谁了。
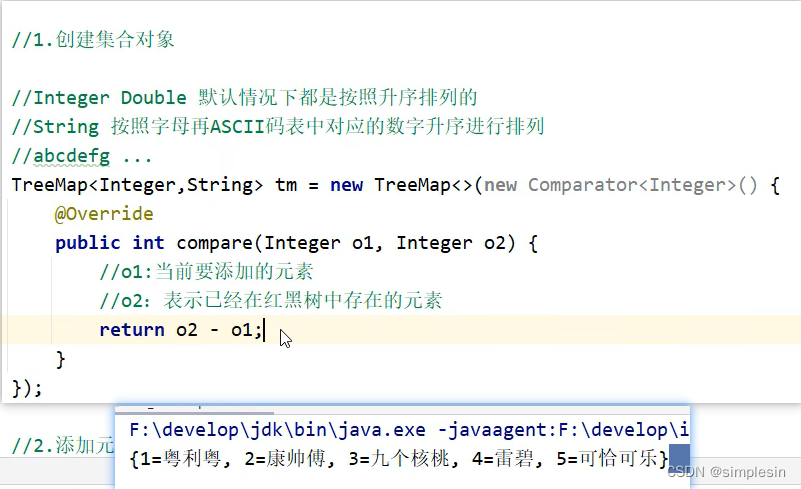
集合进阶-10-TreeMap的基本使用和基础练习1_哔哩哔哩_bilibili
因此,例子中,是b-a
223 排序 e03 最大间距 解法1(超出内存限制)


但是桶的个数太多了,超出了内存限制。
224 排序 e03 最大间距 解法2
因此桶的排序改为基数排序


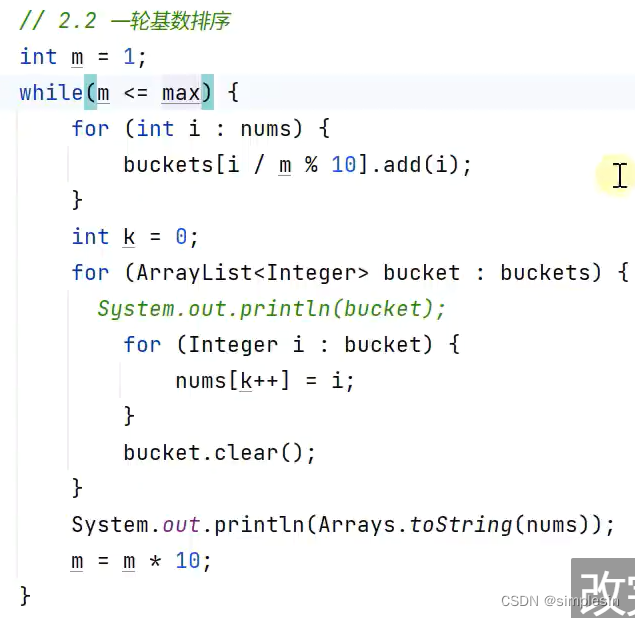
这个max是用来while循环时,判断何时退出循环的。因为在基数排序前,已经找出整个数组中最大的数字了,因此当m>max之后,就可以退出循环了。
225 排序 e03 最大间距 解法3
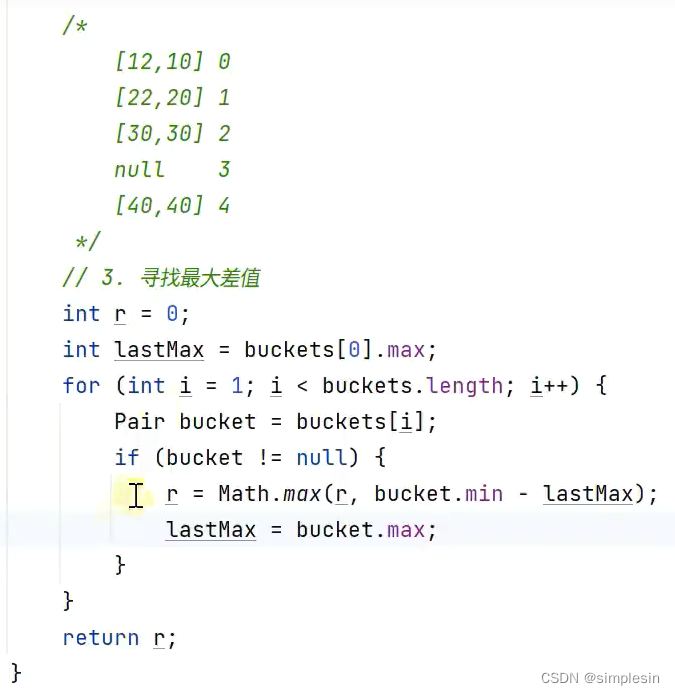
如果最小值和最大值差值特别大的时候,最大的桶减最小的桶的差值就是桶的个数这个计算方式,就会产生很多的桶,降低运行速度。

小tips:
将1变成range

226 排序 e03 最大间距 解法4

不用再比较每一个桶内的元素的大小了,只要比较桶间的大小就可以了。所以我只要确定桶间的元素大于桶内的元素就可以了。
为什么要加空桶:
空桶的引入会使数据间隔变得更小,实际就是数学上分子不变分母变大使得range的值更小,在数据分入桶内时避免桶内间距大于桶间间距。



227 图 基本概念

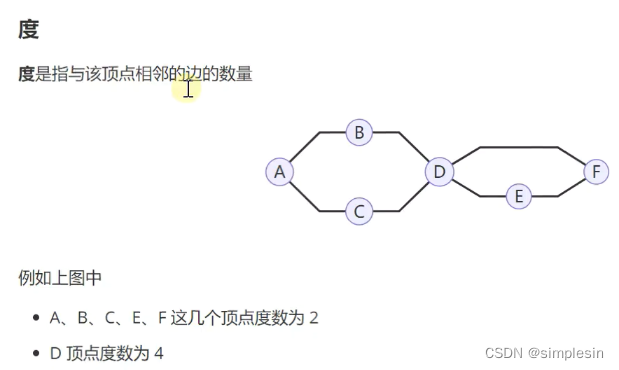
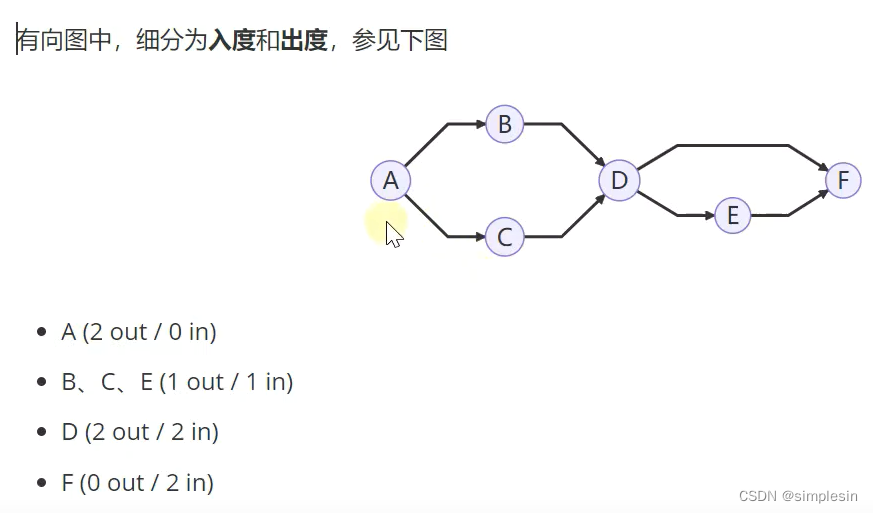
有多少个箭头往外走,就是多少个出度;相反,如此。
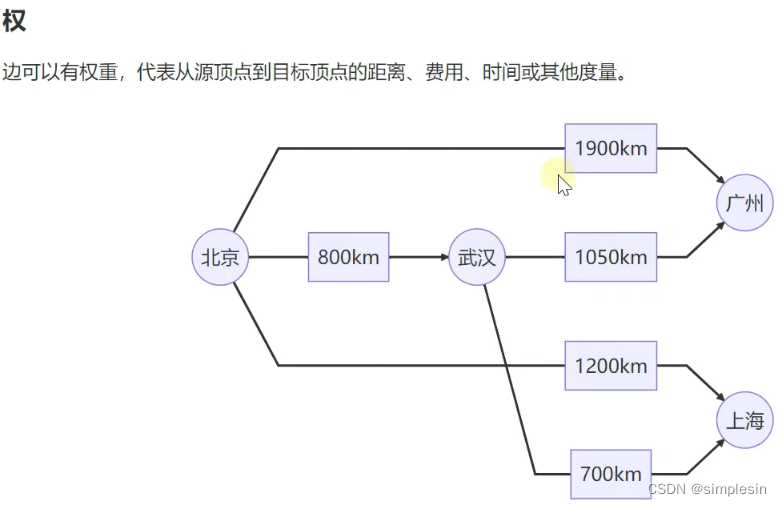
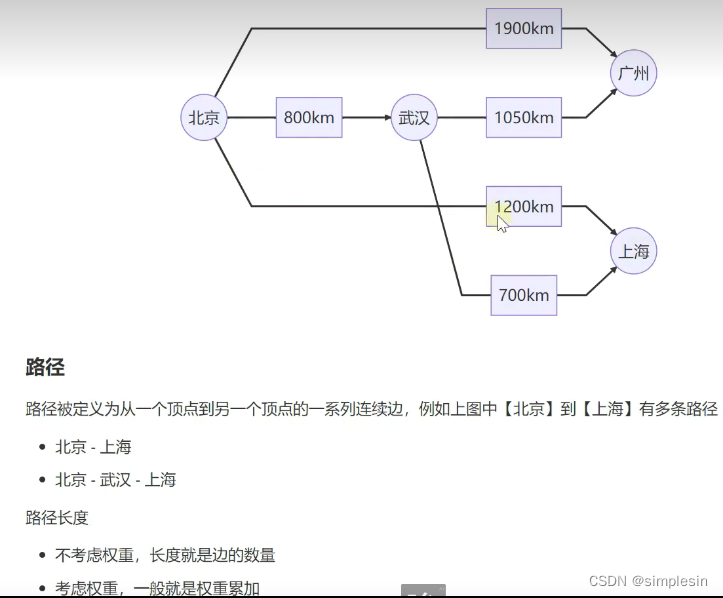
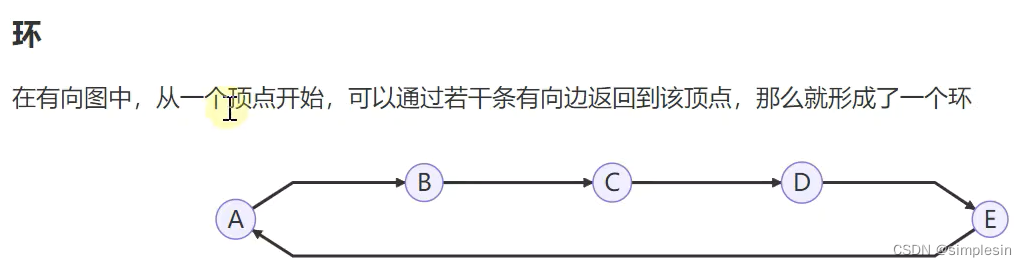
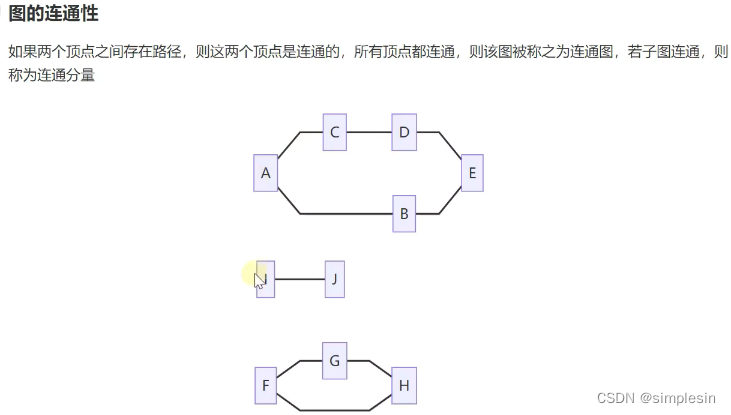
228 图 表示方式
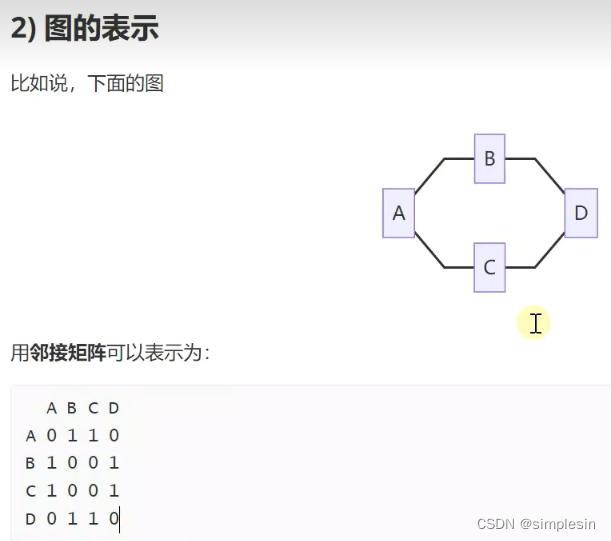

建议用邻接表,因为邻接矩阵比较浪费空间。
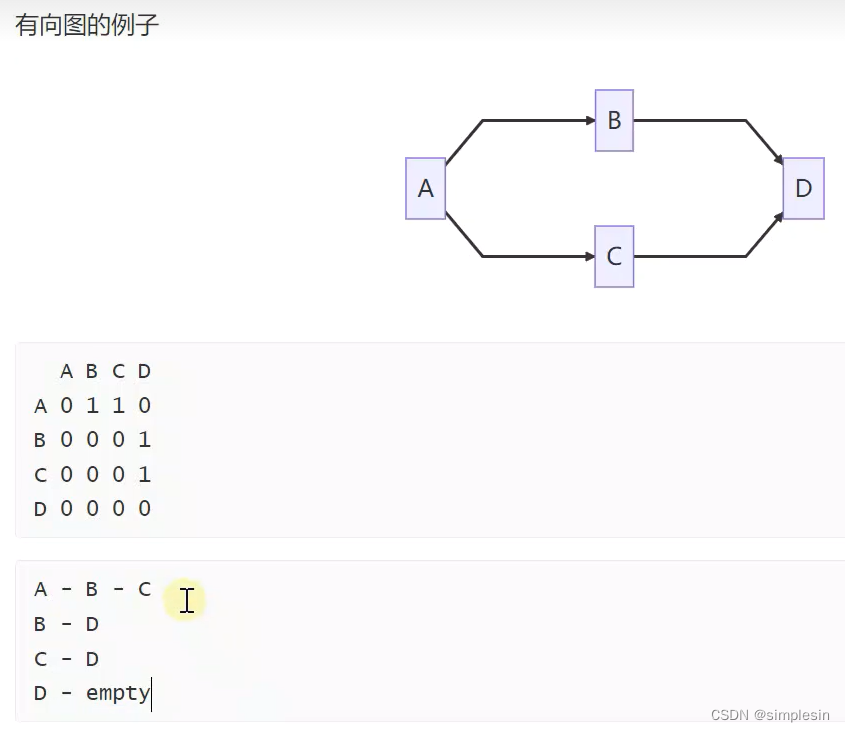
229 图 java表示



230 图 DFS


访问过的点要记录一下,这样下次就不要再访问它了,避免进入死循环。

用栈。弹栈的时候是与入栈的顺序是反的,因此:









)





)


:程序结构与运行关系和JDK,JRE,JVM的关系)

解决方案来打破智能网络性能极限)

