最近因为人员离职,接手一个项目,是xxljob的客户端,部署在k8s上,在排查线上工单时,发现了一个问题:
在管理界面上,我惊讶的发现,三个月的时间,2个Pod,每个都重启了近400次,平均每天重启4次+
因为是无交接接手,业务不熟(最头疼),架构也不熟,硬着头皮去摸索,先从打印日志开始。
打了日志后,开始发现一些端倪,job只有开始,没有结束,也即是说,每次调度开始后,没跑完Pod就重启了,以我的经验,Pod重启可能有以下几种可能:
- 1,资源耗尽,包括CPU耗尽、JVM内存耗尽OOM;
- 2,心跳检测异常;
可以很快的排除2,首先是Pod是跑了一段时间才重启的,其次是即便是心跳检测异常,大概率是1引起,不太可能是单纯的心跳检测异常。
我首先是超OOM这个方面去排查,最后证明这个方向是正确的。
据我以往使用XXL-JOB的经验,阻塞策略如果配置的是【单机串行】,可能会导致大量任务堆积在客户端,最终导致OOM。
但当前场景不太可能是这个原因,因为配置的是2小时跑一次,最多也才堆积6个任务,事实上,由于Pod频繁重启,根本就没有任务堆积。
据此推断,单次任务的执行导致了OOM。
是因为数据量太大吗?
于是把并行改成串行,并加限制条件,以业务上的最小粒度执行任务,情况并无好转,单个任务仍然会导致OOM,Pod重启。
只能硬着头皮看代码了,非常痛苦,特别是看别人的代码,心里一直在反复念叨:写得真垃圾。倒没太多恶意,只是宣泄一下而已,别人看我的代码估计也会这样想吧,哈哈。
功夫不负有心人,在代码发现了一个递归调用:
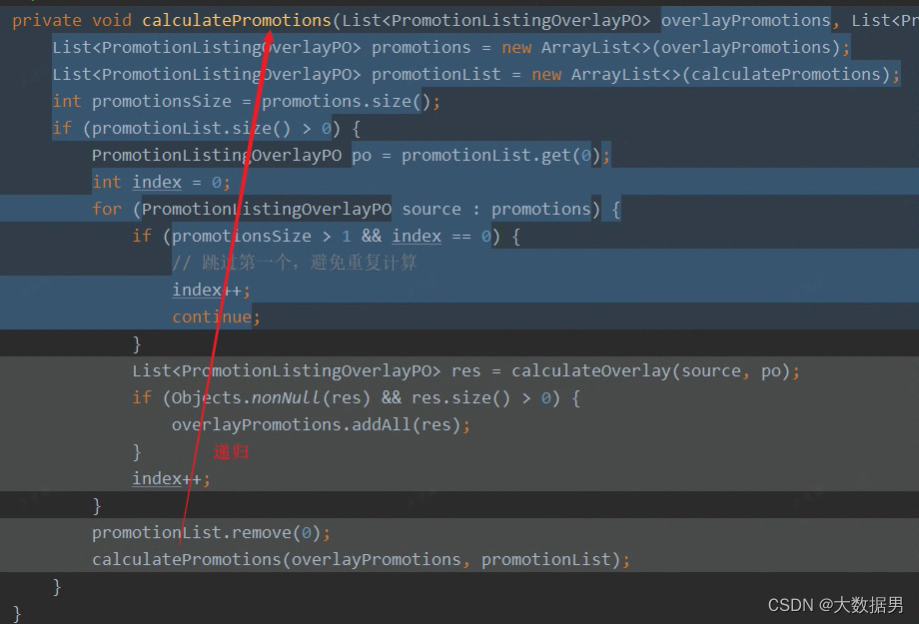
注意看这个函数的前两行,每次调用都把传进来的List集合保存到新的集合对象中,且其中一个集合的size只会增大不会减小,递归的层次是由第二个集合的初始size决定的,悲剧的是,第二个集合是可能很大的,最终导致的结果就是在使用jmap -histo 看到的有2700W+个PromotionListingOverlayPO对象在内存中:

到此,OOM就一点都不奇怪了。
找到问题了,自然就容易解决,一个双层for循环就搞定了,不知道当初那位同事为什么会这么写。

循环数组构建对象)








)
:HBase简介、HBase数据模型与基本架构)




)


)