文章目录
- HuatuoGPT 模型介绍
- LLM4Med(医疗大模型)的作用
- ChatGPT 存在的问题
- HuatuoGPT的特点
- ChatGPT 与真实医生的区别
- 解决方案
- 用于SFT阶段的混合数据
- 基于AI反馈的RL
- 评估
- 单轮问答
- 多轮问答
- 人工评估
HuatuoGPT 模型介绍
HuatuoGPT(华佗GPT)是香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队训练并开源了一个新的医疗大模型,以使语言模型具备像医生一样的诊断能力和提供有用信息的能力。
论文地址:https://arxiv.org/pdf/2305.15075.pdf
github 地址:https://github.com/FreedomIntelligence/HuatuoGPT
Demo 地址:https://www.huatuogpt.cn/
HuatuoGPT的核心是在监督微调阶段利用来自ChatGPT的提取数据和来自医生的真实世界数据。ChatGPT的回答虽然具有流畅性和全面性,但它在一些方面不能像医生一样表现,例如在综合诊断方面。作者认为,可以在SFT阶段将来自医生的真实数据将与来自ChatGPT的提取数据进行互补,而为了更好地利用两种数据的优势,作者训练了一个奖励模型,以使语言模型与两种数据带来的优点保持一致,并遵循RLAIF(从人工智能反馈中强化学习)。
LLM4Med(医疗大模型)的作用
LLM4Med的预期目的是医疗和健康建议、分诊、诊断、开药、解释医疗报告等。一般来说,任何医疗或健康信息都可以合并到在线聊天过程中,类似于使用ChatGPT。在线医疗咨询提供了许多优势,包括:
- 成本效益:以在线方式为多个用户服务的成本与为单个用户服务的成本不成线性比例。一旦对模型进行了训练,这种可扩展性就可以实现经济高效的扩展。
- 减少医院拥挤:最近的疫情凸显了医院人满为患的风险,因为许多人即使不需要立即就医也会寻求线下咨询。通过提供在线替代方案,可以缓解医院的压力,以减轻未来流行病的风险。
- 解决心理障碍:一些人可能因为恐惧或迷信而不寻求医疗帮助或治疗。在线聊天平台可以为这些人提供一个更舒适的环境来讨论他们的担忧。
- 医疗平等:中国的医疗保健不平等是一个重大问题。一线城市居民与小城市和农村地区居民在医疗条件方面的差异非常显著。
ChatGPT 存在的问题
虽然 ChatGPT对一些非垂直领域的问题的回答通常是流畅和全面的,但在医疗领域存在以下问题:
- ChatGPT在医学领域表现不佳,尤其是在中文领域;
- ChatGPT因道德和安全问题拒绝诊断和开药;
- ChatGPT的表现不如医生,例如,它从不提问,即使患者的情况不完整,医生通常会询问更多细节。在这种情况下,ChatGPT会给出一个通用的响应,而不是专门的响应。
HuatuoGPT的特点
- HuatuoGPT是第一个使用RLAIF来利用真实数据和提取数据(包括指令和会话数据)的优点的医学语言模型。
- 人类评估显示,HuatuoGPT优于现有的开源LLM和ChatGPT(GPT-3.5-turbo)。其性能与医生最相似。
ChatGPT 与真实医生的区别
下图为ChatGPT 与医生回复的区别。

医疗咨询中ChatGPT回复(左)和医生回复(右)的示例对话,将文本从中文翻译成英文。图中蓝色表示的是医生们提出的问题,下划线表示的是医学诊断。可以看出,ChatGPT通常不会提出问题以回应病人或像医生一样提供医疗诊断。且ChatGPT回复的数据的质量可能会有波动,表现为生成的对话中的不正确或模棱两可的信息。
ChatGPT的回复:在医疗领域,大规模语言模型(LLM)具有广阔的应用潜力。尽管像 ChatGPT 这样的语言模型能够生成内容详实、表述流畅、逻辑清晰的回复,但其在回应患者描述症状时,缺乏专业性和对患者输入的精确解读。其回复常常包含多种可能性,并以较高层次的建议形式呈现,但往往缺少深入的上下文理解能力,使得其帮助患者的具体情况有限。
真实医生的回复:相比之下,现实世界中医生与患者的互动数据能够更准确地反映医疗情景的复杂性,并提供准确无误的诊断建议,具有极高的专业性。然而,由于时间的限制,医生的回应常常简洁至不能充分传达信息,甚至有时会显得不连贯。若仅依靠这些数据来训练模型,得到的模型难以流畅地应对多样的指令或对话,其生成的回应也会显得短小、表述不佳,有时信息含糊,这对患者并不友好。
论文提出的语言模型训练方法结合了医生和 ChatGPT 的数据,充分发挥它们的互补作用,既保留真实医疗数据的专业性和准确性,又借助 ChatGPT 的多样性和内容丰富性的特点。
解决方案
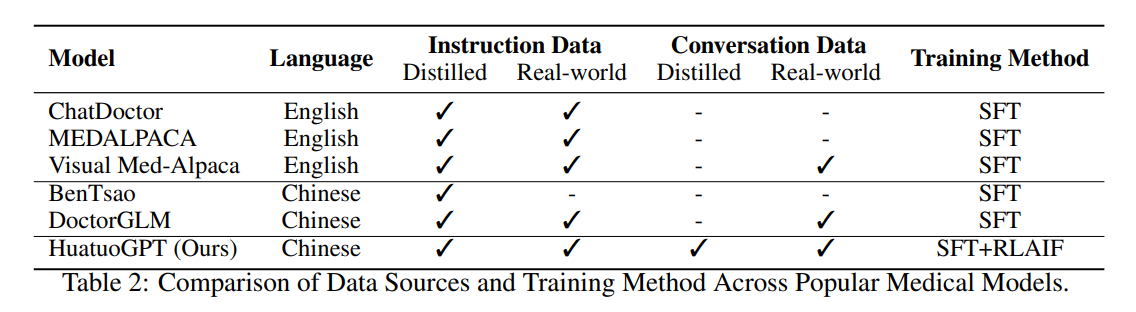
流行的医学模型中数据源和训练方法的比较。
HuatuoGPT 的示意图
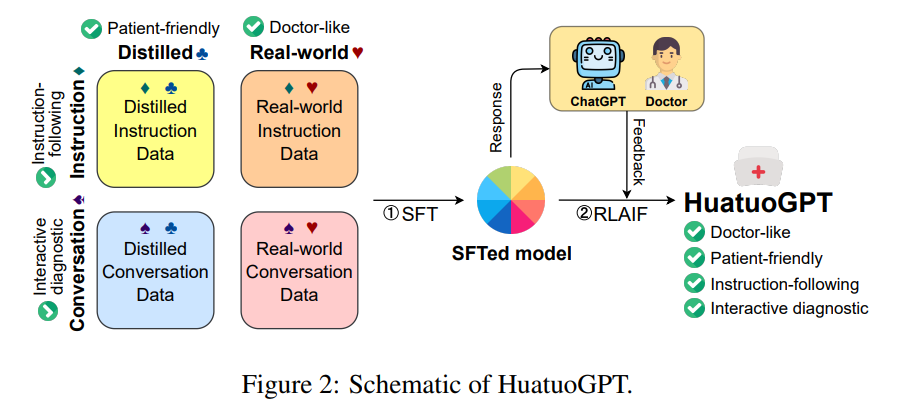
从上图可以看出,HuatuoGPT侧重于整合医生和ChatGPT的特征,通过两阶段训练策略提高医疗咨询中的反应质量:混合数据的SFT和人工智能反馈的RL。首先利用精心选择的混合数据(包含提取的指令数据和对话数据,以及真实的指令数据和对话数据),通过监督微调来训练模型,然后通过人工智能的反馈来加强所需响应的生成。使得最终得到的模型具有四个特点:类似医生,对患者友好,指令跟踪和交互式诊断。
用于SFT阶段的混合数据
从ChatGPT提取指令数据:遵循self-instruct的工作构建了一组医疗指导数据,旨在使模型能够遵循用户的医疗指导。不同之处在于,采用了自上而下的方式来创造更自然、更全面的应对措施。作者设计了一个分类法来收集或手动创建基于角色和用例的种子指令。根据每个角色或用例,使用自我指导分别生成指令。这可以提供广泛的说明,同时为每个角色或用例保留足够的说明。最后,将所有的种子指令混合在一起,进行自我指导;这可能有助于生成更加多样化的指令。

从医生获取真实世界指令:真实世界的指令数据来源于医生和患者之间的问答。医生的回答是专业知识,具有高度的相关性和简洁性。因此,通过提炼真实的医患QA对,进一步提高了single-turn指令数据的质量和可靠性。

从ChatGPT获取对话:提取的对话由两个ChatGPT生成,每个ChatGPT使用精心设计的提示与一个角色(医生或患者)进行关联。首先,利用第三方医学诊断数据库作为生成合成对话数据的医学知识和专业知识的来源。基于患者的基本背景和医生的最终诊断,两个ChatGPT被要求逐一生成对话。在这些对话中,LLM产生的回答通常信息丰富、详细、呈现良好,并遵循一致的风格;格式和信息通常对患者友好。


从医生获得真实世界对话:真实世界的对话是从真实的场景中收集的,医生的反应通常需要不同的能力,包括长期推理和提出问题来指导患者描述自己的症状。然而,这种数据有时过于简洁和口语化。为了解决这一问题,作者利用语言模型来增强和细化基于原始内容的数据,从而生成高质量的真实对话数据集。
通过以上四种方式生成的数据如下:

基于AI反馈的RL
在监督微调(SFT)阶段,作者引入了一个多样化的数据集,旨在使HuatuoGPT能够模仿医生的询问和诊断策略,同时保持LLM反应的丰富、逻辑和连贯特征。为了进一步使模型的生成偏好与人类需求相一致,建议将强化学习与人工智能反馈相结合,以提高模型响应(response)的质量。此前,OpenAI引入了带有人类反馈的强化学习,以使LLM与人类偏好保持一致,但需要付出大量的时间和人力成本。作者设计了一个新的奖励模型,以迫使模型在不偏离医生诊断的情况下生成信息和逻辑响应。
奖励模型的构建
使用真实的指令和对话作为训练数据,从微调的模型中采样多个响应。对于多回合对话,提供对话历史,以调整模型的响应生成。然后,这些response由LLM(如ChatGPT)进行评分,考虑到信息性、连贯性、对人类偏好的遵守以及基于给定真实医生诊断的事实准确性。评分LLM评估每个响应并分配一个分数。使用这些成对的响应数据来训练奖励模型,使用微调模型作为其主干,以更好地泛化。
在RL过程中,通过对当前策略 π \pi π 对给定query x x x的 k k k 个不同response { y 1 , … , y k } \left\{y_1, \ldots, y_k\right\} {y1,…,yk}进行采样。每个response y i y_i yi被送到奖励模型以得到奖励分数 r R M r_{R M} rRM。为了确保模型不会偏离初始状态 π 0 \pi_0 π0 太远,作者添加了经验估计的KL惩罚项,最终的奖励函数如下: r = r R M − λ K L D K L ( π ∥ π 0 ) r=r_{R M}-\lambda_{K L} D_{K L}\left(\pi \| \pi_0\right) r=rRM−λKLDKL(π∥π0)其中 λ K L \lambda_{K L} λKL是KL惩罚的超参数, D K L D_{K L} DKL 是KL函数。 λ K L \lambda_{K L} λKL通常设置为0.05。输入查询被消除重复并从剩余的SFT混合数据中采样。这确保了输入的多样性,同时在单轮指令和多轮对话场景中都保留了模型的response偏好。
评估
在评估 HuatuoGPT 的性能表现上,团队成员采用了自动评估和人工评估两种方式相互验证,在单轮问答场景和多轮交互式诊断场景中分别进行了评估。
单轮问答
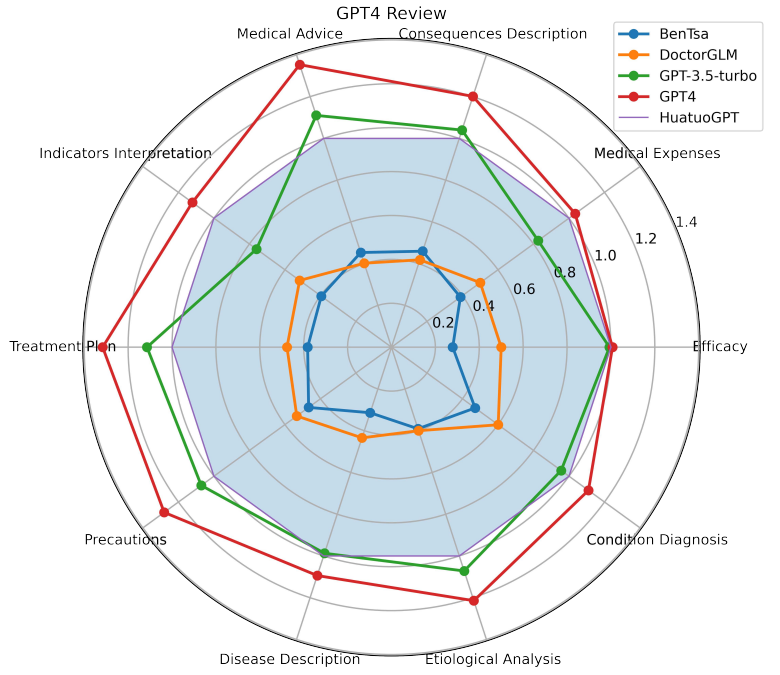
针对单轮问答场景,团队成员精心收集了涵盖 10 个医疗领域意图的 100 个问题,并利用 GPT-4 进行自动评估。具体来说,团队提供了两个模型对同一问题生成回复,并使用 GPT-4 对每个模型的回复进行分析和打分。最终的测试结果显示,相较于基于 LLaMa 和 ChatGLM 的开源中文医疗模型,HuatuoGPT 表现显著优秀(以 HuatuoGPT 为基准)。这一优势得益于 HuatuoGPT 同时使用了从 ChatGPT 蒸馏的数据和真实世界数据进行训练,并借助来自 ChatGPT 和专业医生的混合反馈进行了优化。
多轮问答
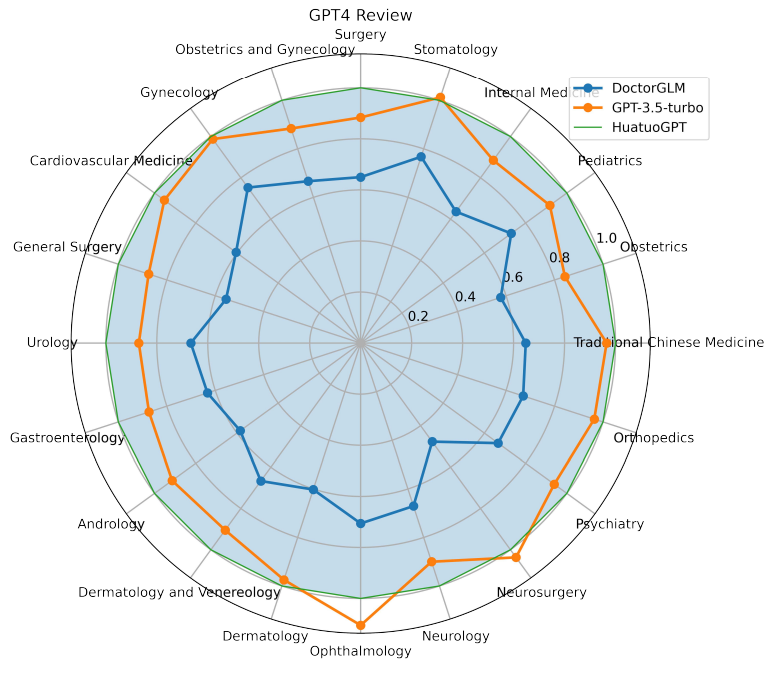
对于多轮问诊场景,团队成员收集了涵盖 20 个科室的 100 个多轮对话进行了评估。评估结果显示,HuatuoGPT 不仅全面优于目前的开源中文医疗模型,而且在大部分科室的表现上均优于 GPT-3.5-turbo,这为 HuatuoGPT 在处理更加复杂的多轮问诊场景中的优异性能提供了有力的证据。
人工评估
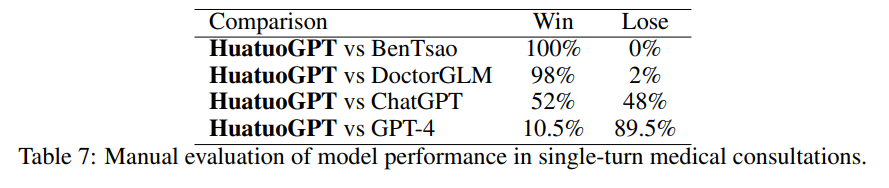
在人工评估方面,团队成员使用了自动评估中的样本进行评估验证。团队成员邀请专业医生为模型的输出结果进行人工评估。下表是单轮问答场景和多轮诊断场景的评估结果。评估结果表明,无论是单轮的人工评测还是多轮的人工评测结果都与自动评估的结果保持了一致,这充分验证了模型性能评估的一致性和可靠性。
单轮对话
多轮对话






)
课程学习笔记day3)





CLIPScore:图像标题的无参考评估指标)


)



