引言:随着计算机,服务器的性能需求越来越高,DDR4开始应用在一些高端设计中,然而目前关于DDR4的资料非常少,尤其是针对SI(信号完整性)部分以及相关中文资料,另外一方面,DDR4的高速率非常容易引起SI问题,一旦出现比如DDR4 Margin测试Fail之类的问题,会让很多设计者感到头疼,Debug过程非常困难,信号测试变得越来越困难,越来越不准确,而且很难验证,PCBLayout优化以后再打板验证的方式效率低下也增加了很多成本,在这种情况下,用信号仿真的方法来分析验证问题就方便了许多。本文从DDR4基本概念出发,介绍了DDR4相关的关键技术和一些新方法,另外结合一个实际DDR4 Margin Fail问题,来简单说明问题分析思路和仿真方法。
1. DDR4关键技术和方法分析
1.1 DDR4与DDR3 不同之处
相对于DDR3, DDR4首先在外表上就有一些变化,比如DDR4将内存下部设计为中间稍微突出,边缘变矮的形状,在中央的高点和两端的低点以平滑曲线过渡,这样的设计可以保证金手指和内存插槽有足够的接触面从而确保内存稳定,另外,DDR4内存的金手指设计也有明显变化,金手指中间的防呆缺口也比DDR3更加靠近中央。当然,DDR4最重要的使命还是提高频率和带宽,总体来说,DDR4具有更高的性能,更好的稳定性和更低的功耗,那么从SI的角度出发,主要有下面几点, 下面章节对主要的几个不同点进行说明。
|
Spec Items
|
DDR3
|
DDR4
|
|
Voltage (VDD/VDDQ/VDP)
|
1.5
|
1.2
|
|
Data Rate (Mbps)
|
1600
|
3200
|
|
Vref
|
External (VDD/2)
|
Internal(Training)
|
|
Data IO
|
SSTL
|
POD
|
|
Data Bus Inversion(DBI)
|
No
|
Supported
|
表1 DDR3和DDR4差异
1.2 POD 和SSTL的比较
POD作为DDR4新的驱动标准,最大的区别在于接收端的终端电压等于VDDQ,而DDR3所采用的SSTL接收端的终端电压为VDDQ/2。这样做可以降低寄生引脚电容和I/O终端功耗,并且即使在VDD电压降低的情况下也能稳定工作。其等效电路如图1(DDR4), 图2(DDR3)。

图1 POD ((Pseudo Open Drain)

图2 SSTL(Stub Series TerminatedLogic)
可以看出,当DRAM在低电平的状态时,SSTL和POD都有电流流动

图3 DDR4

图4 DDR3
而当DRAM为高电平的状态时,SSTL继续有电流流动,而POD由于两端电压相等,所以没有电流流动。这也是DDR4更省电的原因

图5 DDR4

图6 DDR3
1.3 数据总线倒置 (DBI)
如上面描述,根据POD的特性,当数据为高电平时,没有电流流动,所以降低DDR4功耗的一个方法就是让高电平尽可能多,这就是DBI技术的核心。举例来说,如果在一组8-bit的信号中,有至少5-bit是低电平的话,那么对所有的信号进行反转,就有至少5-bit信号是高电平了。DBI信号变为低表示所有信号已经翻转过(DBI信号为高表示原数据没有翻转)。这种情况下,一组9根信号(8个DQ信号和1个DBI信号)中,至少有五个状态为高,从而有效降低功耗。

图7 DBI Example
1.4 ODT控制
为了提升信号质量, 从DDR2开始将DQ, DM, DQS/DQS#的Termination电阻内置到Controller和DRAM中, 称之为ODT (OnDie Termination)。Clock和ADD/CMD/CTRL信号仍需要使用外接的Termination电阻。

图8 On Die Termination
在DRAM中,On-Die Termination的等效电阻值通过Mode Register (MR)来设置,ODT的精度通过参考电阻RZQ来控制,DDR4的ODT支持240, 120, 80, 60, 48, 40, 34 欧姆。
和DDR3不同的是,DDR4的ODT有四种模式:Data termination disable, RTT_NOM,RTT_WR, 和 RTT_PARK。Controller可以通过读写命令以及ODT Pin来控制RTT状态,RTT_PARK是DDR4新加入的选项,它一般用在多Rank的DDR配置中,比如一个系统中有Rank0,Rank1以及Rank2, 当控制器向Rank0写数据时,Rank1和Rank2在同一时间内可以为高阻抗(Hi-Z)或比较弱的终端(240,120,80,etc.), RTT_Park就提供了一种更加灵活的终端方式,让Rank1和Rank2不用一直是高阻模式,从而可以让DRAM工作在更高的频率上。
一般来说,在Controller中可以通过BIOS调整寄存器来调节ODT的值,但是部分Controller厂商并不推荐这样做,以Intel为例,Intel给出的MRCCode中已经给出了最优化的ODT的值,理论上用户可以通过仿真等方法来得到其他ODT值并在BIOS中修改,但是由此带来的所有问题将有设计厂商来承担。下面表格是Intel提供的优化方案。

表2 DQ Write ODT Table for 3DPC

表3 DQ Read ODT Table for 3DPC
1.5 参考电压Vref
众所周知,DDR信号一般通过比较输入信号和另外一个参考信号(Vref)来决定信号为高或者低,然而在DDR4中,一个Vref却不见了,先来看看下面两种设计,可以看出来,在DDR4的设计中,VREFCA和DDR3相同,使用外置的分压电阻或者电源控制芯片来产生,然而VREFDQ在设计中却没有了,改为由芯片内部产生,这样既节省了设计费用,也增加了Routing空间。


图9 DDR3设计 图10 DDR4设计
DRAM内部VREFDQ通过寄存器(MR6)来调节,主要参数有Voltage range, step size, VREF step time, VREF full step time ,如下表所示。

表4 参考电压
每次开机的时候,DRAM Controller都会通过一系列的校准来调整DRMA端输入数据信号的VREFDQ,优化Timing和电压的Margin,也就是说,VREFDQ 不仅仅取决于VDD, 而且和传输线特性,接收端芯片特性都会有关系,所以每次Power Up的时候,VREFDQ的值都可能会有差异。
因为Vref的不同,Vih/Vil都会有差异,可以通过调整ODT来看Vref的区别,用一个仿真的例子来说明。对于DDR3,调整ODT波形会上下同步浮动,而调整DDR4 OOT的时候,波形只有一边移动。

图11 仿真拓扑

图12 DDR3仿真结果

图13 DDR4仿真结果
1.6 DDR4 Layout Routing新方法
在所有的Layout走线中,DDR无需质疑是最复杂的,不仅要考虑阻抗匹配,还要考虑长度匹配,而且数量众多的数据、地址线,不得不考虑串扰的影响。
DDR4数据速率提高以后,这些方面的影响变得更为严重,尤其是现在很多设计为了节省成本,PCB尺寸和层数都要求尽可能的变小,这样对阻抗和串扰的要求就变的更有挑战性,一般SI工程师和Layout工程师都会想各种办法来满足这些需求,很多时候也不得不妥协折衷,比如在做叠层设计的时候尽量让线宽变小,在BGA Breakout区域采用更细的线,等等。但这些方法只能对设计做微小的调整,其实很难从根本上解决问题。最近Intel研究发现的一种新方法很有意思,可以在一定程度上很好的平衡阻抗(线宽)和串扰(线间距)。在此整理出来供大家参考。
先来看一个实际的Layout例子,两根红线之间的走线采用锯齿形状。没错,这就是Intel新研究出来的新方法,官方名称为“Tabbed Routing”。

图14 DDR4 Tabbed Routing
Tabbed Routing主要的方法是在空间比较紧张的区域(一般为BGA区域和DIMM插槽区域),减小线宽,而增加凸起的小块(Tab),如下图所示。


图15 Tab routing方法
这种方法可以增加两根线之间的互容特性而保持其电感特性几乎不变,而增加的电容可以有效控制每一层的的阻抗,减小外层的远端串扰。仿真结果如下图所示。



图16 HFSS仿真结果
由仿真结果可以看出来,该方法对阻抗和远端串扰确实可以很好的平衡,当然,对于Tab的尺寸,需要根据实际PCB做详细的仿真设计,Intel也提供了一些Tool可以参考。有兴趣的读者,可以参阅更多资料
2. DDR4Simulation
2.1Pre-Simulation with HyperLynx
如果Controller和DRAM都有IBIS模型,可以用HyperLynx对DDR4进行很方便的Simulation, 仿真方法和其他DDR相同,通过Pre-Simulation, 可以对整个系统的拓扑以及一些细节进行确定,比如Impedance(由Stackup以及线宽和线间距来确定),ODT值的选择,T型结构中Stub长度的控制,ADD/CMD/CTRL终端电阻的取值大小等等。
2.1.1ADD/CMD/CTRL终端电阻取值
假设ADD电路如下,工作在2400MTs(Add/CMD为1.2Gbps),发送端为U16,采用Fly-By结构到五组DRAM芯片,每组DRAM采用T结构(实际Layout中,Top面一个DRAM芯片,Bottom面一个DRAM芯片),T型长度的Stub为77mil, 终端电阻为32欧姆,终端电压为0.6V。

图17 ADD仿真拓扑
由仿真结果可以看出来,T型结构两端因为完全对称,所以波形几乎一样,为了方便观察,只看其中一个波形,离Controller由近及远,DRAM分别为U5, U4, U3, U2, U1, 其眼图分别如下:





可以看出来,距离Controller越近的芯片,其波形越“乱”,但是上升沿却很快,而距离终端电阻越近的芯片,其波形越好,但是上升沿却变慢。那么如何才能得到最优化的波形呢,下面通过扫描终端电阻的值看看是否会提高信号质量,通过HyperLynx的Sweep功能,设置终端电阻阻值为27,33,39,45四个阻值。

图18 Sweep设置 图19 Sweep设置
U5(距离Controller最近)的眼图如下,依次对应终端电阻阻值为27,33,39,45欧姆:


U4的眼图如下,依次对应终端电阻阻值为27,33,39,45欧姆:

U3的眼图如下,依次对应终端电阻阻值为27,33,39,45欧姆:

U2的眼图如下,依次对应终端电阻阻值为27,33,39,45欧姆

U1的眼图如下,依次对应终端电阻阻值为27,33,39,45欧姆

从上面的波形可以看出来,对应每一个DRAM的第三张波形都是最好的,也就是说对应39欧姆的终端电阻可以得到最优化的波形。
2.1.1Data信号Stub的长度
一般DDR4的设计中,Data信号都采用Pin to Pin的设计方式,但在某些设计中,由于PCB空间限制或者控制器限制,也有需要采用一拖二的设计(T型结构),在笔者所遇到的一个设计中,就遇到这种情况,综合考虑下面两种方案,如果采用T型拓扑结构,如图20所示,可以最大可能的节约PCB空间,但是如果DIMM0或者DIMM1只插一根的时候,另一边会有较长的Stub出现,对信号质量会有影响。如果采用菊花链结构,如图21所示,在只插DIMM0的情况下,同样会有Stub影响。而且这种拓扑结构需要DIMM0和DIMM1之间的信号线之间满足长度匹配,在DIMM0和DIMM1比较靠近的情况下,绕线会有一定难度。而如果增加DIMM0和DIMM1的距离,其Stub会变得更长,信号质量没有办法得到控制。从信号完整性方面考虑,两种方案均会存在Stub的影响,但是从Layout的角度来看,方案一有一定便利性,而且其Stub可以控制在500mil以内。所以最终选择方案一作为最终方案。当然,这种设计是以牺牲信号Margin作为代价的,信号速率会收到一定影响,在笔者的项目中,在只插一根内存的时候,信号速率最大只能跑到1866Mb/s.


图20 DDR4 T型结构 图21DDR4菊花链结构
从仿真的角度出发,这种仿真需要考虑的因素很多,控制器模型,PCB模型,Connector模型,以及最后的内存条模型,而通常情况下,Connector模型和内存条模型很难拿到,而且有时候就算拿到,也是不同类型的模型,整体Channel仿真需要更多时间和精力来完成。
如果时间有限,需要对设计做快速评估,用HyperLynx做快速仿真也是可以参考的,在下面的例子中,假设一个Conntorller需要驱动两根DIMM或者两颗内存颗粒,系统工作在2400Mb/s, TL2和TL3的长度可以用来大概评估PCB Stub长度加上Connector长度加上内存条长度。(此处只是用来做大概评估,如果时间条件运行,强烈建议拿到各个部分精确模型做比较准确的仿真)。
从这个简单的仿真可以看出来,Stub对于信号质量的影响还是很明显的,特别对于一根内存槽悬空的状态下,上面的例子中,Stub达到1000 mil的时候,在只插一根内存的情况下,眼图已经非常糟糕,所以在实际设计中,需要在设计成本和信号速率之间进行均衡,取舍。在笔者所做的设计中,因为PCB空间限制,最终选择在单根内存的时候只跑到1866Mb/s。

图22 数据线仿真拓扑
在Stub长度为500mil的时候,两根内存都插和只插一根的眼图如下:

在Stub长度为1000mil的时候,两根内存都插和只插一根的眼图如下:

在用Intel的芯片作为DDR Controller做设计的时候,Intel所提供的SI Model可以提供一个比较完整的仿真,Intel所提供的Simulation Deck中,包含了DDR连接器,DIMM模型,如果能找到和实际项目匹配的模型,可以替换Deck中的模型,如果找不到模型,直接用Deck中所提供的模型也是非常有参考意义的。
2.2 Intel SISTAI仿真
Intel所提供的Memory Bit Error Rate Executable (MBERE) tool集成在其Intel SISTAI(Signal Integrity Support Tools for Advanced InteRFaces)网站系统上面,SISTAI可以进行PCIE,SATA,USB,QPI等等高速信号的仿真,DDR4仿真模块为MBER, 其基本思想是先基于Hspice产生一个StepResponse, 然后把仿真结果.TR0文件放进SISTAI系统进行计算,产生Worse Case的眼图,大致仿真流程如下:
2.2.1 DDR通道建模
Intel的仿真基于10根线模型,八根DQ线加上两根DQS线,可以用Intel提供的Causal-W Element Tool来产生W Element models, 也可以用ADS,Hspice等工具对传输线建模,对于Post-Layout来说,可以使用PowerSI, siwave等软件提取DDR通道的S参数。注意这里的DQ和DQS的顺序必须和Intel提供的顺序相同,如图23所示。

图23 DDR数据线建模
2.2.2Hspice仿真
Intel仿真模型还是比较详细,提供了各种模型以及各种不同情况下的Simulation Deck, 在实际仿真的时候,需要用实际设计的模型替换Deck中的参数,以S参数为例,假设提取了整个DDR通道的S参数,那么需要在pcakage的参数之后加入PCB通道模型,如下图第二个红框所示,之前的一些参数,可以删除或者加上*号来Block掉。

图24 Intel仿真模型

图25 Hspice编辑实例
Hspice仿真得到Step Response, 结果如下:

图26 Hspice仿真结果
2.2.3SISTAI仿真
得到Tr0文件后,需要把Tro放到SISTAI系统中进行计算,操作流程如下:
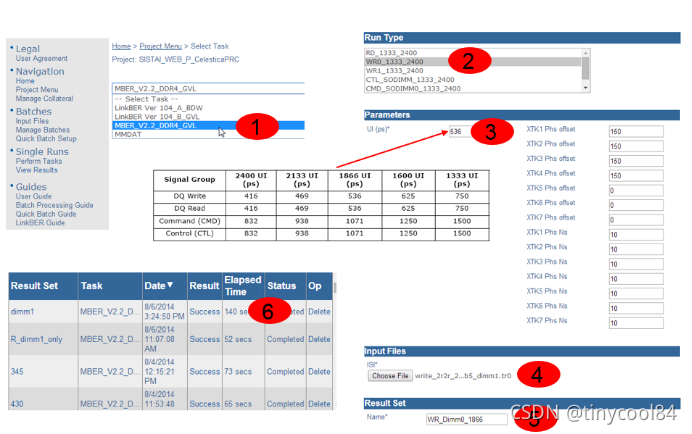
图27 SISTAI仿真方法
点击Success可以得到仿真结果,比较遗憾的是,SISTAI只能看到眼宽,眼高等仿真数据,并不提供眼图的显示。

图28 SISTAI仿真结果
Intel的文件中也提供了Spec可以对仿真结果进行对比判断

表5 DQ Write Eye Target Minimums

表6 DQ Read Eye Target Minimums
3. DDR4 RMTMargin测试Fail问题实例
3.1 设计情况
该设计采用Intel Haswell-EP CPU作为DDR4Controller, 采用3DPC(DIMM Per Channel)的设计,如下图29所示。DDR4运行速率为1600Mb/s。

图29 DDR4设计拓扑
3.2 问题描述
主板做好后,需要对DDR4信号进行测试验证,但是对于内存条类的DDR4,测试点非常难找,测试结果也很不准确,所有选择只测试Memory Margin。在用Intel提供的Margin测试工具RMT进行测试的时候,测试了各种不同厂商的内存条,分别有Hynix 8G, Hynix 16G, Samsung 8G, Samsung 16G, Samsung 32G, Micron8G, Micron 16G, 其中只有Micron 8G 结果显示RxVLow, RxVhigh的值小于14(Spec为大于等于14),其他内存条测试结果均满足Spec要求。

表6 RMT测试结果
3.3Memory Margin Test
上面说了RMT测试Fail,但是RMT测试是什么呢?下面对Memory的一般测试做大概介绍。众所周知,实际PCB做好后,我们需要对其进行测试以验证信号完整性。 通常是采用示波器测试对DDR信号线在读写时的信号质量,但是这种测试存在很大的局限性,比如DDR信号到达每一个Component端的测点无法被点测到,测试点往往距离芯片pad还有一段距离,需要一些额外的测试设备,这样势必会影响准确性,另外,DDR信号读写分离一直都比较难处理,即使使用仪器厂商提供的专业测试软件,也往往看不到非常准确的波形,还有测试点只位于芯片外部, Memory Controller内部对信号Timing的调整无法被测到,所以在采用示波器测试波形之外, 还非常有必要进行Memory Margin测试。


图30 DDR4测试设备 图31 DDR4测试眼图
简单的Memory Margin的测试方法是, 在Controller和DRAM都使用外部VREF供电的条件下, 调节VREF的电压幅度, 同时运行Memory Stress Test软件(如: Golden Memory, MSTRESS 等等), 直到出现测试Fail的VREF值同默认VREF值间的差值, 记为VREFMargin。调节VREF并不会影响信号传输的波形, 因为VREF只是芯片接收端(Controller或DRAM)判断输入为0或1的判断依据。然而在DDR4时代,Vrefdq已经集成到芯片内部,我们无法对其进行调节。
这个时候一些专门的测试软件就比较方便,比如Intel就提供了RMT和EVTS做为DDR Margin测试。

图32 Margin测试原理
RMT(DDRRank Margin Tool),其原理是修改设置, 让BIOS在开机时自动运行Training程序, 同时通过DebugPort输出Training的结果, 然后分析输出的打印信息, 从而得到Memory Margin。所得到的结果不仅仅包含VREF Margin, 还包含Write/Read Timing Margin,ADD/CMD Timing Margin…而EVTS是对RMT的一个补充,可以进行per-bit margin测试,如果Margin不佳,左右或上下不对称的时候,可以用EVTS 2D Margin来了解成因是否为眼图形状所致。
3.4 问题分析
本体分析
因为其他内存条RMT测试都是PASS的,唯有Micron8G的测试是Fail,第一点想到的就是DIMM本身问题,联系Micron FAE后,Micron怀疑是测试的内存条生产日期太老,版本变更会影响测试结果,然而拿到最新的样品后,测试结果仍然没有任何改善。
同时,用这些样品在Intel CRB(Custom reference board)上进行测试,却是可以PASS的。
由此可以判断,Micron 8G本身并不是Margin Fail的唯一因素,只能试图增加主板PCB Margin来改善RMT结果
3.4.2 通过Simulation来分析问题
从问题的描述来看,主板+大部分内存条测试PASS, 有问题的内存条+其他主板测试PASS, 看起来是遇到了最让人头疼的Worst Case+Worse Case的情况,这种情况下,单纯的从设计本身来看,各项设计指标都可以满足相关文档或者Design Guide,只能从细节入手,从一些细微的调整和优化来提高彼此的Margin, 就这个Case来说,Micron 8G的Module已经量产,在没有足够的证据之前,没有办法要求厂商来做任何修改,而主板正在设计阶段,看来只能想办法来优化提高主板Layout从而提高Margin了。
然而对于DDR来说,如上面所描述,各项设计指标都满足相关设计规则,仅仅通过经验猜测,改版,测试的方式来做,无疑毫无效率性和针对性而言,而通过仿真的方法,来做各种各样不同Case的仿真,找到对于提高Margin比较明显的改善点,然后修改Layout,就比较有针对性,也避免了多次改版所带来时间和费用上的浪费。
回到设计本身,如本文3.1节所描述,本设计采用一个通道三根内存的设计(一个Controller加三个DIMM),如图33所示,仔细分析测试结果,Marign最差的均为DIMM2(距离CPU最近的一个),做一个简单的理论分析,不管从CPU写数据到DIMM2或者从DIMM2读数据到CPU,无论DIMM1和DIMM0处于何种状态,L2和L3始终存在,对于DIMM2来说,相当于有一段Stub存在,而Stub会引起信号反射,从而导致Margin减小,哇,找到Root cause了哎,原来问题这么简单,快快改版做下一批PCB吧,可是,万一下一批还是不行怎么办?冷静一下,还是先做仿真验证一下吧。

图33 PCB Layout
冷静一下,再仔细分析,对比主板和Intel CRB的PCB设计,果然在这边存在差异,CRB板子L2和L3长度大概为398 mil, 而我们的主板L2和L3长度大概为462 mil, 确实有差异,既然这边的长度有差异,从前面我们的分析来看,仿真结果也肯定会有差异,我们来仿真看看,如前面所说,Intel SISTAI只能提供仿真数据,而无法显示波形,仿真结果整理如下图。

表7 Write仿真结果

表8 Read 仿真结果
从仿真结果可以看出来两点,第一,仿真数据最差的也是DIMM2,和实际测试结果吻合;第二,我们的主板仿真结果比Intel CRB的结果要差,和我们之前分析和猜测吻合。那么,缩小L2,L3的长度以后,仿真结果是不是会改善呢?由于PCB和Connector本身差异,我们的主板L2和L3最短只能缩小到410 mil左右,那么,PCB改善后的结果如何呢?仿真数据如下表。可以看出来,无论Write和Read, D2的结果都有了改善,可是为什么还是和Intel CRB差异很大呢?

表9 仿真结果对比
再来对比Layout,Trace走线已经找不出差异,之前没有关注过的叠层(Stackup)成为最大的差异点,CRB为8层板,而我们的主板为18层板,而且我们的主板DDR走线靠近TOP层,这么大的叠层差异直接导致了PTH Via孔所造成的Stub长度不同,同样,DIMM插槽的针脚长度差异也会造成Stub影响,CRB采用的DIMM插槽针脚长度为2.4mm, 我们主板DIMM插槽针脚长度为3.2 mm, 没有找到相对应的DIMM插槽模型,只能采用删减或增加PCB叠层厚度来简单模拟DIMM插槽针脚长度,减小主板DIMM插槽针脚长度(采用Stackup变更来简单模拟) 到2.4 mm,仿真结果如下,已经非常接近CRB的结果了。这个仿真虽然不是非常准确,但是也是可以看出来Stub对信号质量的影响。
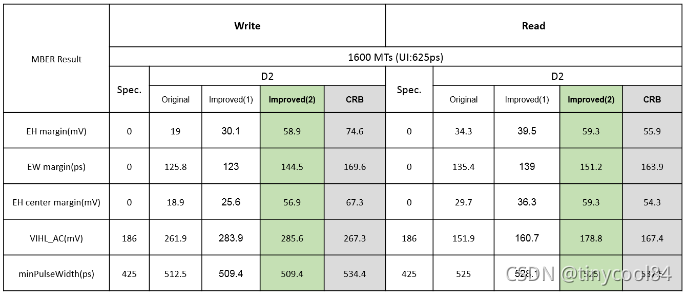
表10 最终仿真结果对比
按照分析结果,缩短L2,L3的长度,改为阵脚比较短的DIMM插槽(因为设计已经基本定型,只能进行小的改动,没有办法把DDR走线移动到靠近Bottom层的Layer),重新改版后,之前测试Fail的Margin提高了2~3Step, 终于可以PASS了。
至此,对于此Case的分析和仿真基本结束,DIMM to DIMM之间的长度以及DIMM插槽针脚长度(以及PTH VIA Stub)所造成的Stub对于提高信号Margin有一定的贡献,所以在针对3DPC(DIMM per Channel)的设计,在设计初期,就应该尽可能减小DIMMTO DIMM的长度,对于板厚比较大的Case,尽可能把DDR走线靠近Bottom面,以减小Stub对信号质量的影响。
4. 小结
DDR的设计,仿真,测试,一直以来都是大部分设计者比较关心的地方,也是让大部分工程师比较头疼的问题,首先从理论理解来说,DDR包含了很多技术难点,比如接口电路,比如Timing, DriverStrength, ODT等等概念都需要理解。其次从Layout角度来看,DDR不像串行总线一样,只有几对差分线,问题很容易定位,而DDR一旦出现问题,如果定位问题,成为众多设计者感到棘手的问题,需要做大量的测试和实验。最后,从仿真角度来说,DDR的仿真也比串行总线的仿真复杂很多,需要考虑PCB,连接器,内存条,还要考虑各种参数的设置等等。
本文针对DDR设计中普遍存在的一些困惑,先是对DDR4的新技术和关键技术做了大概描述,然后介绍了DDR4目前的仿真方法,以及Intel对于DDR4的仿真Solution。最后通过一个Memory Margin的实际案例,介绍分析和解决问题的思路。
在写作本文的过程中,笔者参阅了多种网络上的资料以及一些前辈的文章,同时,也加入了很多自己的看法,由于本人水平有限,错误之处在所难免,有理解不对的地方希望大家及时指正。同时也希望大家能完善补充, 相互讨论, 共同进步。

:CBO优化器是如何计算代价的?)










 垃圾回收(2)-垃圾回收器)






