1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着农业科技的不断发展,农作物病害的快速检测和准确诊断成为了农业生产中的重要问题。其中,桑叶病害对于桑树的生长和产量具有重要影响,因此对桑叶病害的检测和诊断具有重要的意义。
传统的桑叶病害检测方法主要依赖于人工观察和经验判断,这种方法存在着主观性强、效率低、准确性不高等问题。随着计算机视觉和深度学习技术的发展,基于图像处理和机器学习的桑叶病害检测系统逐渐成为了研究的热点。
目前,基于深度学习的目标检测算法YOLOv8在图像识别领域取得了很大的成功。然而,YOLOv8在桑叶病害检测中仍然存在一些问题。首先,YOLOv8对于图像中的通道信息没有充分利用,导致检测结果的准确性有待提高。其次,YOLOv8在处理空间对象时没有考虑到对象的注意力,导致对于小尺寸的病害区域检测效果不佳。
因此,本研究旨在改进YOLOv8桑叶病害检测系统,通过减少通道的空间对象注意力(RCS-OSA)来提高检测的准确性和效率。具体来说,本研究将从以下几个方面展开工作:
首先,本研究将通过引入注意力机制来增强YOLOv8对于图像中的通道信息的利用。通过对图像中不同通道的重要性进行学习和调整,可以提高检测系统对于不同病害类型的识别能力,从而提高检测的准确性。
其次,本研究将通过引入空间对象注意力机制来改善YOLOv8对于小尺寸病害区域的检测效果。通过对图像中不同空间对象的重要性进行学习和调整,可以提高检测系统对于小尺寸病害区域的关注度,从而提高检测的准确性和效率。
最后,本研究将通过实验验证改进后的YOLOv8桑叶病害检测系统的性能。通过对比实验结果,可以评估改进后的系统在准确性、效率和鲁棒性等方面的优势,为农业生产提供更好的桑叶病害检测解决方案。
总之,本研究的目标是改进YOLOv8桑叶病害检测系统,通过减少通道的空间对象注意力来提高检测的准确性和效率。该研究对于农业生产中的桑叶病害检测具有重要的意义,可以提高病害的诊断准确性,减少病害对桑树生长和产量的影响,为农业生产提供技术支持和决策依据。
2.图片演示



3.视频演示
【改进YOLOv8】桑叶病害检测系统:减少通道的空间对象注意力RCS-OSA改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集SYDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ET
import osclasses = [] # 初始化为空列表CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:classes.append(cls) # 如果类别不存在,添加到classes列表中cls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')xml_path = os.path.join(CURRENT_DIR, './label_xml/')# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:label_name = img_xml.split('.')[0]print(label_name)convert_annotation(label_name)print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data|-----train| |-----images| |-----labels||-----valid| |-----images| |-----labels||-----test|-----images|-----labels确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import opsclass DetectionPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):preds = ops.non_max_suppression(preds,self.args.conf,self.args.iou,agnostic=self.args.agnostic_nms,max_det=self.args.max_det,classes=self.args.classes)if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = []for i, pred in enumerate(preds):orig_img = orig_imgs[i]pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i]results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results
这个程序文件是一个名为predict.py的文件,它是一个用于预测基于检测模型的类DetectionPredictor的扩展。它使用了Ultralytics YOLO库,该库是基于AGPL-3.0许可证的。
这个文件定义了一个名为DetectionPredictor的类,它继承自BasePredictor类。这个类用于进行基于检测模型的预测。
这个文件还定义了一个postprocess方法,用于对预测结果进行后处理,并返回一个Results对象的列表。在后处理过程中,它使用了ops.non_max_suppression函数对预测结果进行非最大值抑制处理,同时还进行了一些其他的处理操作。
这个文件还包含了一个示例代码,展示了如何使用DetectionPredictor类进行预测。示例代码中使用了yolov8n.pt模型和ASSETS作为输入源。
总的来说,这个文件是一个用于预测基于检测模型的类DetectionPredictor的程序文件,它使用了Ultralytics YOLO库,并定义了一些方法和示例代码。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_firstclass DetectionTrainer(BaseTrainer):def build_dataset(self, img_path, mode='train', batch=None):gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):assert mode in ['train', 'val']with torch_distributed_zero_first(rank):dataset = self.build_dataset(dataset_path, mode, batch_size)shuffle = mode == 'train'if getattr(dataset, 'rect', False) and shuffle:LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")shuffle = Falseworkers = 0return build_dataloader(dataset, batch_size, workers, shuffle, rank)def preprocess_batch(self, batch):batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255return batchdef set_model_attributes(self):self.model.nc = self.data['nc']self.model.names = self.data['names']self.model.args = self.argsdef get_model(self, cfg=None, weights=None, verbose=True):model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def label_loss_items(self, loss_items=None, prefix='train'):keys = [f'{prefix}/{x}' for x in self.loss_names]if loss_items is not None:loss_items = [round(float(x), 5) for x in loss_items]return dict(zip(keys, loss_items))else:return keysdef progress_string(self):return ('\n' + '%11s' *(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')def plot_training_samples(self, batch, ni):plot_images(images=batch['img'],batch_idx=batch['batch_idx'],cls=batch['cls'].squeeze(-1),bboxes=batch['bboxes'],paths=batch['im_file'],fname=self.save_dir / f'train_batch{ni}.jpg',on_plot=self.on_plot)def plot_metrics(self):plot_results(file=self.csv, on_plot=self.on_plot)def plot_training_labels(self):boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这个程序文件是一个用于训练检测模型的程序。它使用了Ultralytics YOLO库,其中包含了构建数据集、构建数据加载器、模型训练等功能。
程序中定义了一个名为DetectionTrainer的类,它继承自BaseTrainer类。DetectionTrainer类用于基于检测模型进行训练。它包含了构建数据集、构建数据加载器、预处理数据、设置模型属性、获取模型、获取验证器等方法。
程序的主函数是__main__函数,其中定义了训练的参数args,并创建了一个DetectionTrainer对象trainer,然后调用trainer的train方法进行模型训练。
整个程序的功能是使用Ultralytics YOLO库训练一个检测模型,使用的数据集是coco8.yaml,训练的轮数是200轮。
5.5 backbone\convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass LayerNorm(nn.Module):def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedError self.normalized_shape = (normalized_shape, )def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass Block(nn.Module):def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2)x = input + self.drop_path(x)return xclass ConvNeXtV2(nn.Module):def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList()stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList()dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6)self.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward(self, x):res = []for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)res.append(x)return res
该程序文件是一个实现了ConvNeXt V2模型的PyTorch模块。ConvNeXt V2是一个用于图像分类任务的卷积神经网络模型。
该程序文件包含以下主要部分:
- 导入所需的库和模块。
- 定义了一些辅助模块,如LayerNorm和GRN。
- 定义了ConvNeXtV2模块的核心组件,包括Block和ConvNeXtV2类。
- 定义了一些不同规模的ConvNeXtV2模型,如convnextv2_atto、convnextv2_femto等。
- 实现了一个辅助函数update_weight,用于加载预训练权重。
- 每个模型函数中,如果提供了权重文件路径,则加载对应的预训练权重。
总体来说,该程序文件实现了ConvNeXt V2模型的定义和预训练权重加载功能。可以根据需要选择不同规模的模型,并使用预训练权重进行初始化。
5.6 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):super().__init__()self.num_classes = num_classesself.depths = depthsself.num_features = self.embed_dim = embed_dimself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay ruleself.blocks = nn.ModuleList([CSWinBlock(dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,last_stage=(i == len(depths) - 1))for i in range(len(depths))])self.norm = norm_layer(embed_dim)self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()trunc_normal_(self.head.weight, std=.02)self.head.bias.data.fill_(0.)def get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)x = self.pos_drop(x)for blk in self.blocks:x = blk(x)x = self.norm(x)return xdef forward(self, x):x = self.forward_features(x)x = x[:, 0]x = self.head(x)return x
该程序文件是一个用于实现CSWin Transformer模型的Python文件。CSWin Transformer是一种用于图像分类任务的Transformer模型,可以用于处理图像数据。
该文件定义了以下几个类:
- Mlp类:实现了一个多层感知机(MLP)模块,用于处理输入特征。
- LePEAttention类:实现了一个基于局部位置编码(LePE)的注意力机制模块,用于计算输入特征的注意力权重。
- CSWinBlock类:实现了CSWin Transformer的一个基本块,包括多层感知机模块和注意力机制模块。
- Merge_Block类:实现了一个用于将特征图尺寸减半的模块。
除了这些类之外,该文件还定义了一些辅助函数,用于处理输入数据的转换和重组。
总体来说,该文件实现了CSWin Transformer模型的各个组件和功能,可以用于构建和训练CSWin Transformer模型。
6.系统整体结构
下面是对每个文件功能的整理:
| 文件路径 | 功能 |
|---|---|
| export.py | 导出模型为不同的格式,如PyTorch、TorchScript、ONNX等 |
| predict.py | 使用模型进行预测 |
| train.py | 训练模型 |
| ui.py | 实现了一个简单的图像识别界面 |
| backbone\convnextv2.py | 实现了ConvNeXt V2模型的定义和预训练权重加载功能 |
| backbone\CSwomTramsformer.py | 实现了CSWin Transformer模型的各个组件和功能 |
| backbone\EfficientFormerV2.py | 实现了EfficientFormer V2模型的定义和预训练权重加载功能 |
| backbone\efficientViT.py | 实现了EfficientViT模型的定义和预训练权重加载功能 |
| backbone\fasternet.py | 实现了Fasternet模型的定义和预训练权重加载功能 |
| backbone\lsknet.py | 实现了LSKNet模型的定义和预训练权重加载功能 |
| backbone\repvit.py | 实现了RepVIT模型的定义和预训练权重加载功能 |
| backbone\revcol.py | 实现了RevCoL模型的定义和预训练权重加载功能 |
| backbone\SwinTransformer.py | 实现了Swin Transformer模型的定义和预训练权重加载功能 |
| backbone\VanillaNet.py | 实现了VanillaNet模型的定义和预训练权重加载功能 |
| extra_modules\afpn.py | 实现了AFPN模块的定义和功能 |
| extra_modules\attention.py | 实现了注意力机制模块的定义和功能 |
| extra_modules\block.py | 实现了各种模块的定义和功能 |
| extra_modules\dynamic_snake_conv.py | 实现了动态蛇形卷积模块的定义和功能 |
| extra_modules\head.py | 实现了模型的头部部分的定义和功能 |
| extra_modules\kernel_warehouse.py | 实现了核心仓库模块的定义和功能 |
| extra_modules\orepa.py | 实现了OREPA模块的定义和功能 |
| extra_modules\rep_block.py | 实现了RepBlock模块的定义和功能 |
| extra_modules\RFAConv.py | 实现了RFAConv模块的定义和功能 |
| extra_modules_init_.py | 定义了extra_modules模块的初始化 |
| extra_modules\ops_dcnv3\setup.py | 安装DCNv3模块的依赖库 |
| extra_modules\ops_dcnv3\test.py | 测试DCNv3模块的功能 |
| extra_modules\ops_dcnv3\functions\dcnv3_func.py | 实现了DCNv3模块的函数功能 |
| extra_modules\ops_dcnv3\functions_init_.py | 定义了DCNv3模块函数的初始化 |
| extra_modules\ops_dcnv3\modules\dcnv3.py | 实现了DCNv3模块的定义和功能 |
| extra_modules\ops_dcnv3\modules_init_.py | 定义了DCNv3模块的初始化 |
| models\common.py | 包含了一些通用的模型函数和辅助函数 |
| models\experimental.py | 包含了一些实验性的模型函数和辅助函数 |
| models\tf.py | 包含了一些与TensorFlow相关的模型函数和辅助函数 |
7.YOLOv8简介
Neck模块设计
骨干网络和 Neck 的具体变化为:
第一个卷积层的 kernel 从 6x6 变成了 3x3
所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作

去掉了 Neck 模块中的 2 个卷积连接层
Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型。
Head模块设计
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
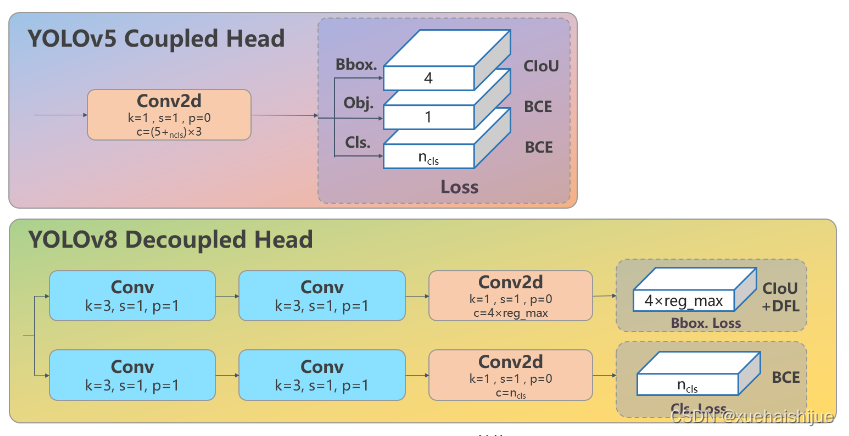
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
Loss 计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。 现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。 TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics 。
对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
分类分支依然采用 BCE Loss
回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
Loss 采用一定权重比例加权即可。
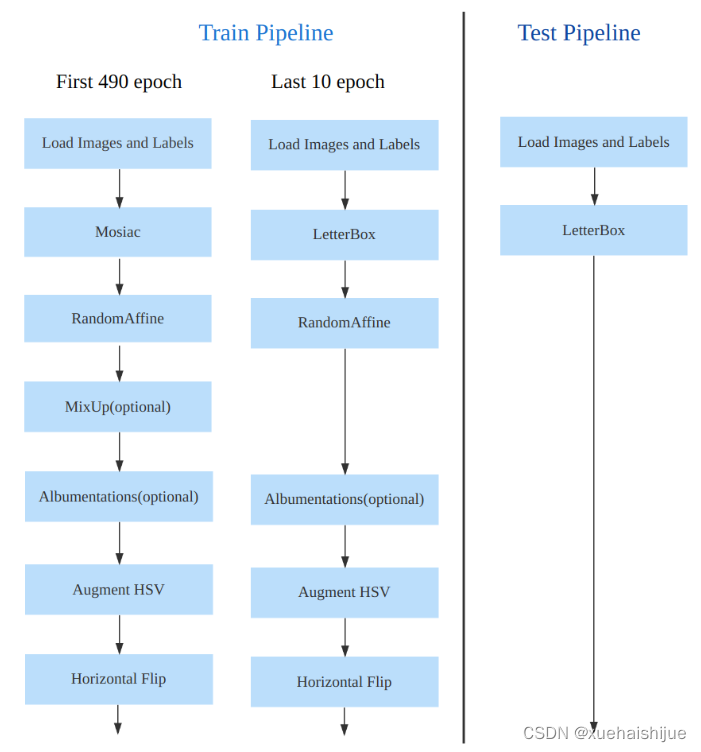
训练数据增强
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
8. RCS-OSA的基本原理
参考该博客,RCSOSA(RCS-One-Shot Aggregation)是RCS-YOLO中提出的一种结构,我们可以将主要原理概括如下:
-
RCS(Reparameterized Convolution based on channel Shuffle): 结合了通道混洗,通过重参数化卷积来增强网络的特征提取能力。
-
RCS模块: 在训练阶段,利用多分支结构学习丰富的特征表示;在推理阶段,通过结构化重参数化简化为单一分支,减少内存消耗。
-
OSA(One-Shot Aggregation): 一次性聚合多个特征级联,减少网络计算负担,提高计算效率。
-
特征级联: RCS-OSA模块通过堆叠RCS,确保特征的复用并加强不同层之间的信息流动。
RCS
RCS(基于通道Shuffle的重参数化卷积)是RCS-YOLO的核心组成部分,旨在训练阶段通过多分支结构学习丰富的特征信息,并在推理阶段通过简化为单分支结构来减少内存消耗,实现快速推理。此外,RCS利用通道分割和通道Shuffle操作来降低计算复杂性,同时保持通道间的信息交换,这样在推理阶段相比普通的3×3卷积可以减少一半的计算复杂度。通过结构重参数化,RCS能够在训练阶段从输入特征中学习深层表示,并在推理阶段实现快速推理,同时减少内存消耗。
RCS模块
RCS(基于通道Shuffle的重参数化卷积)模块中,结构在训练阶段使用多个分支,包括1x1和3x3的卷积,以及一个直接的连接(Identity),用于学习丰富的特征表示。在推理阶段,结构被重参数化成一个单一的3x3卷积,以减少计算复杂性和内存消耗,同时保持训练阶段学到的特征表达能力。这与RCS的设计理念紧密相连,即在不牺牲性能的情况下提高计算效率。

上图为大家展示了RCS的结构,分为训练阶段(a部分)和推理阶段(b部分)。在训练阶段,输入通过通道分割,一部分输入经过RepVGG块,另一部分保持不变。然后通过1x1卷积和3x3卷积处理RepVGG块的输出,与另一部分输入进行通道Shuffle和连接。在推理阶段,原来的多分支结构被简化为一个单一的3x3 RepConv块。这种设计允许在训练时学习复杂特征,在推理时减少计算复杂度。黑色边框的矩形代表特定的模块操作,渐变色的矩形代表张量的特定特征,矩形的宽度代表张量的通道数。
OSA
OSA(One-Shot Aggregation)是一个关键的模块,旨在提高网络在处理密集连接时的效率。OSA模块通过表示具有多个感受野的多样化特征,并在最后的特征映射中仅聚合一次所有特征,从而克服了DenseNet中密集连接的低效率问题。
OSA模块的使用有两个主要目的:
-
提高特征表示的多样性:OSA通过聚合具有不同感受野的特征来增加网络对于不同尺度的敏感性,这有助于提升模型对不同大小目标的检测能力。
-
提高效率:通过在网络的最后一部分只进行一次特征聚合,OSA减少了重复的特征计算和存储需求,从而提高了网络的计算和能源效率。
在RCS-YOLO中,OSA模块被进一步与RCS(基于通道Shuffle的重参数化卷积)相结合,形成RCS-OSA模块。这种结合不仅保持了低成本的内存消耗,而且还实现了语义信息的有效提取,对于构建轻量级和大规模的对象检测器尤为重要。
下面我将为大家展示RCS-OSA(One-Shot Aggregation of RCS)的结构。

在RCS-OSA模块中,输入被分为两部分,一部分直接通过,另一部分通过堆叠的RCS模块进行处理。处理后的特征和直接通过的特征在通道混洗(Channel Shuffle)后合并。这种结构设计用于增强模型的特征提取和利用效率,是RCS-YOLO架构中的一个关键组成部分旨在通过一次性聚合来提高模型处理特征的能力,同时保持计算效率。
特征级联
特征级联(feature cascade)是一种技术,通过在网络的一次性聚合(one-shot aggregate)路径上维持有限数量的特征级联来实现的。在RCS-YOLO中,特别是在RCS-OSA(RCS-Based One-Shot Aggregation)模块中,只保留了三个特征级联。
特征级联的目的是为了减轻网络计算负担并降低内存占用。这种方法可以有效地聚合不同层次的特征,提高模型的语义信息提取能力,同时避免了过度复杂化网络结构所带来的低效率和高资源消耗。
下面为大家提供的图像展示的是RCS-YOLO的整体架构,其中包括RCS-OSA模块。RCS-OSA在模型中用于堆叠RCS模块,以确保特征的复用并加强不同层之间的信息流动。图中显示的多层RCS-OSA模块的排列和组合反映了它们如何一起工作以优化特征传递和提高检测性能。
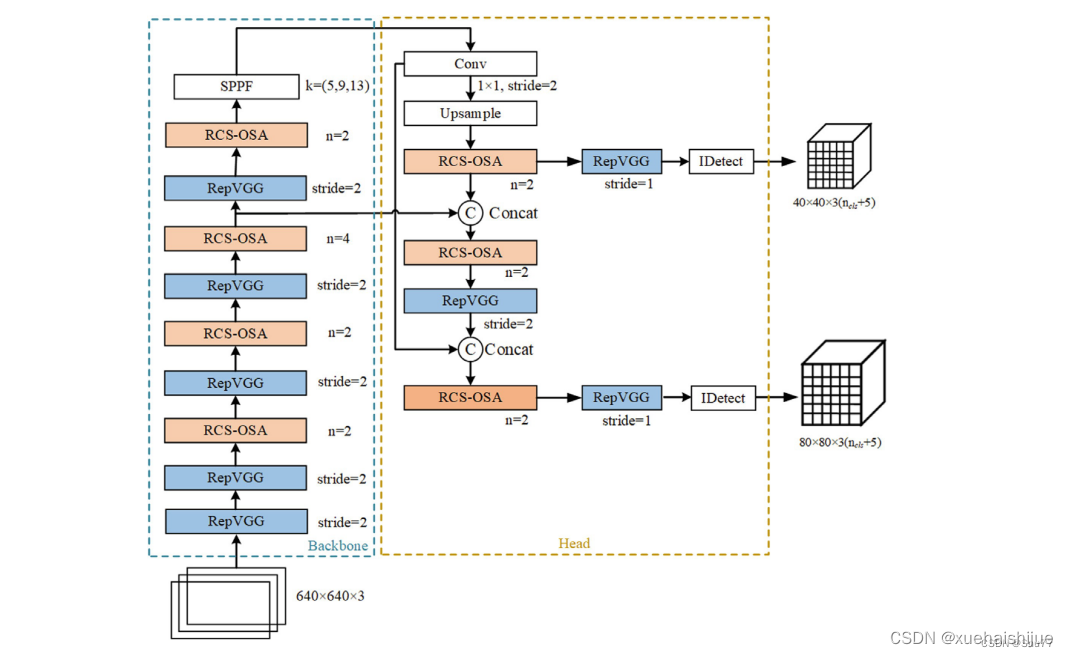
总结:RCS-YOLO主要由RCS-OSA(蓝色模块)和RepVGG(橙色模块)构成。这里的n代表堆叠RCS模块的数量。n_cls代表检测到的对象中的类别数量。图中的IDetect是从YOLOv7中借鉴过来的,表示使用二维卷积神经网络的检测层。这个架构通过堆叠的RCS模块和RepVGG模块,以及两种类型的检测层,实现了对象检测的任务。
9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOv8】桑叶病害检测系统:减少通道的空间对象注意力RCS-OSA改进YOLOv8》
10.参考文献
[1]黄旭华,潘志新,韦廷秀,等.家蚕微粒子病治疗药物筛选和应用技术研究[J].广西蚕业.2016,(1).DOI:10.3969/j.issn.1006-1657.2016.01.002 .
[2]罗梅兰.三级原种母蛾微粒子病复检技术的效果分析[J].广西蚕业.2014,(2).
[3]黄景滩,贾雪峰,施祖珍,等.桑叶全程消毒清洗机自动化系统的工艺介绍[J].广西蚕业.2011,(3).DOI:10.3969/j.issn.1006-1657.2011.03.017 .
[4]邢东旭,杨琼,罗国庆,等.家蚕品种资源对家蚕微粒子病的抗性测定[J].广东蚕业.2011,(4).24-26.
[5]韦伟,黄景滩,罗建生,等.SXQ-750型桑叶消毒清洗成套设备的研制[J].广西蚕业.2010,(2).DOI:10.3969/j.issn.1006-1657.2010.02.011 .
[6]宋忠林,浦月霞.做好三级原种微粒子病预知检查工作的体会[J].广西蚕业.2006,(1).25-26.
[7]沈中元,徐莉,徐安英,等.家蚕品种资源对微粒子病的抗性调查[J].蚕业科学.2003,(4).DOI:10.3969/j.issn.0257-4799.2003.04.022 .
[8]马万勇,徐建生,陈玉君,等.桑叶浸消控制家蚕微粒子病技术[J].中国蚕业.2002,(2).32-33.
[9]孙孝龙,杨帆,童朝亮,等.桑叶全程浸消技术规范的应用[J].广西蚕业.2002,(1).27-28.
[10]吴怀民,费建明,薛坤荣.原蚕全龄桑叶洗消在"微防"中的应用[J].中国蚕业.2002,(2).33-34.




-k8s存储对象Persistent Volume Claim)








——卷积神经网络)
享元模式 代理模式 桥接模式)
)


覆盖优化 - 附代码)
