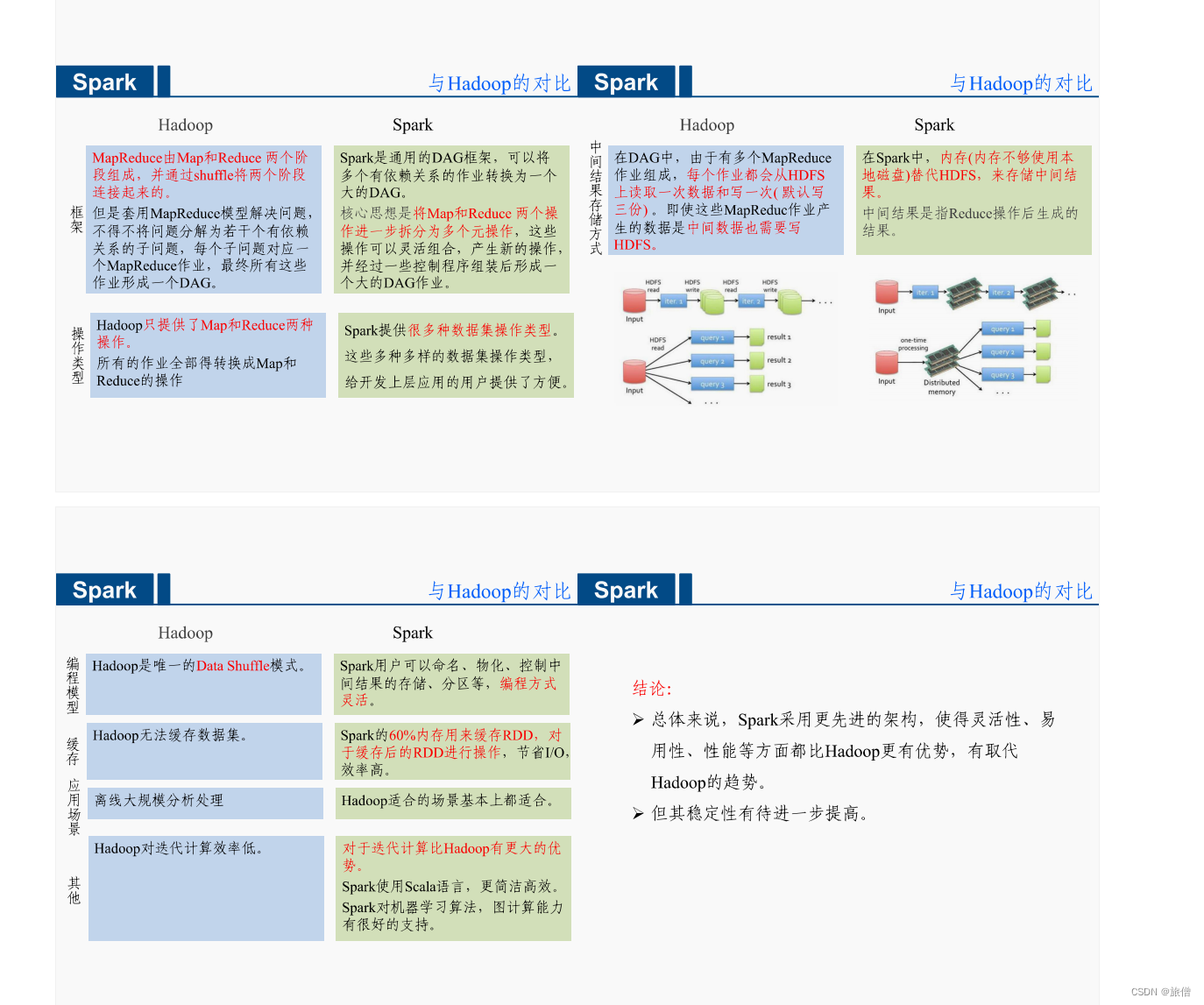
Hadoop
- 表达能力有限。
- 磁盘IO开销大,延迟度高。
- 任务和任务之间的衔接涉及IO开销。
- 前一个任务完成之前其他任务无法完成,难以胜任复杂、多阶段的计算任务。
Spark
-
Spark模型是对Mapreduce模型的改进,可以说没有HDFS、Mapreduce就没有Spark。
-
Spark可以使用Yarn作为他的资源管理器,并且可以处理HDFS数据。这对于已经部署了Hadoop集群的用户特别重要,因为他们不需要任何的数据迁移就可以使用到spark的强大功能了。
Spark模型是对Mapreduce模型的改进,可以说没有HDFS、Mapreduce就没有Spark。
Spark可以使用Yarn作为他的资源管理器,并且可以处理HDFS数据。这对于已经部署了Hadoop集群的用户特别重要,因为他们不需要任何的数据迁移就可以使用到spark的强大功能了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/230820.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!


-核心PPT资料下载)

,高版本多支持))













