Query Execution I
- Processing Models
- Iterator Model
- Materialization Model
- Vectorization Model
- Access Methods
- Sequential Scan
- Index Scan
- Modification Queries
- Halloween Problem
本节课主要介绍SQL语句执行的相关机制。
Processing Models
首先是处理模型,它定义了数据库系统执行查询计划的模式。常见的模型有以下三种:
- Iterator Model
- Materialization Model
- Vectorized Model
Iterator Model
在迭代器模型中,每个算子由Open()、Next()和Close()三个函数组成。Open()与Close()分别代表计算的开始与停止,Next()表示该算子计算结果中的下一条记录。当Next()函数被调用时,算子将进行计算并返回下一条记录。在迭代器模型中,结果中的记录是一条一条产生的,这对带有LIMIT关键字的查询十分友好,方便控制输出的记录数量。

Materialization Model
物化模型与迭代器模型截然不同,每个算子会将其输出打包起来(作为临时关系),作为其后继算子的输入或者最终结果。在物化模型中,每个算子的输出记录一次性产生,并输送给后续算子使用。该模型比较适合OLTP系统,因为不会产生太大的中间结果。
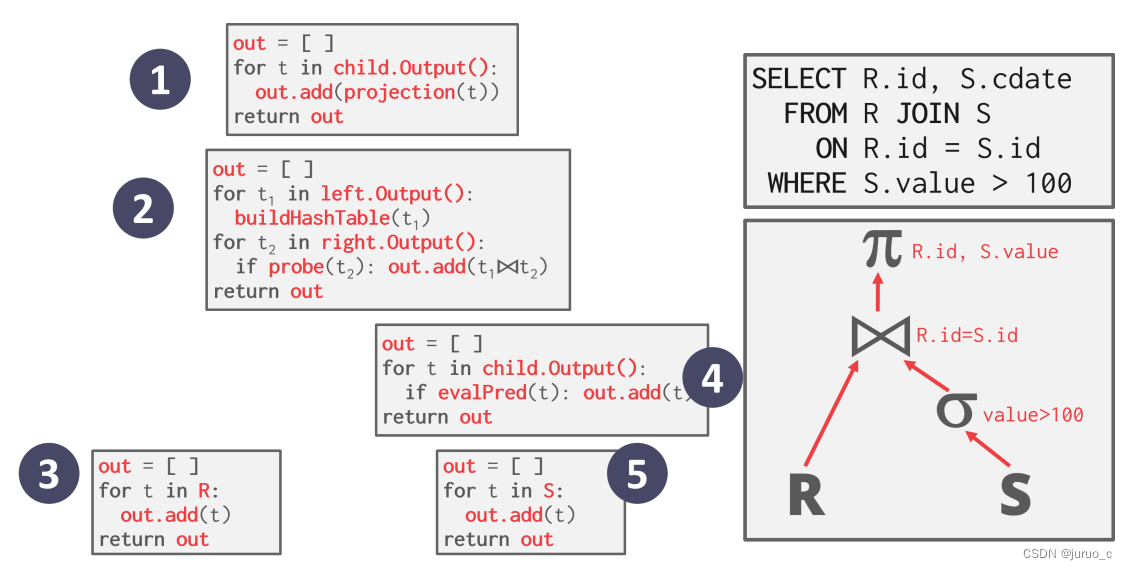
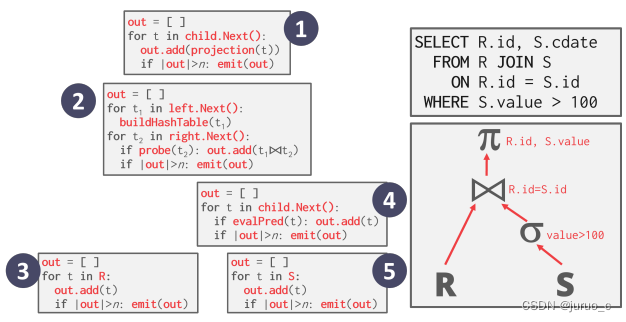
Vectorization Model
向量化模型结合了物化模型与迭代器模型的特点,每次处理返回一定量的记录,也称为batch Model。该模型适合OLAP数据库,使得中间结果不需要溢出到磁盘,也可以减少Next函数的调用次数。
Access Methods
在执行模型的叶子节点处,需要进行数据的访问,一般有两种方式:
- from table
- from index
Sequential Scan
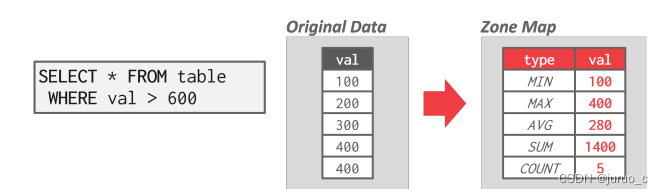
从table中进行顺序的访问数据通常效率低下,需要一些优化,在之前的章节中已经介绍过许多优化了,这里重点介绍一个Zone Map的优化。思想很简单,就是对每一页数据预处理出一些聚合属性,比如MIN、MAX等等,加速聚合查询。
Index Scan
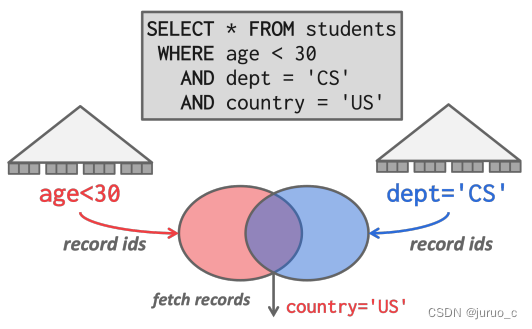
通过索引的访问分为单索引与多索引。
单索引需要考虑不同场景下所用的索引属性,如下图所示。

多索引则根据查询条件,在多个索引上查询结果并将结果集合做并集或者交集。
Modification Queries
Halloween Problem
当涉及UPDATE查询时,由于UPDATE可能使得记录的物理位置发生改变,导致一个记录被更新两次。这个问题是在万圣节发现的,因此称为万圣节问题。
解决思路比较简单,在更新过程中维护已经更新过的记录ID即可。



)
:制作一把AOE武器)




:木牌传送)
)


)


)

 、count(*) 和count(列名) 函数的区别)
