目录
一、HBase简介
(一)概念
(二)特点
(三)HBase架构
二、HBase原理
(一)读流程
(二)写流程
(三)数据 flush 过程
(四)数据合并过程
三、HBase安装与配置
(一)解压并安装HBase
(二)配置HBase
(三)配置Spark
四、HBase的使用
(一)进入HBase shell
(二)表的管理
(三)表数据的增删改查
一、HBase简介
(一)概念
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
(二)特点
1、海量存储
HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与HBase的极易扩展性息息相关。正式因为HBase良好的扩展性,才为海量数据的存储提供了便利。
2、列式存储
这里的列式存储其实说的是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3、极易扩展
HBase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS) 。通过横向添加RegionSever的机器,进行水平扩展,提升HBase 上层的处理能力,提升HBsae服务更多Region 的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升 HBase的数据存储能力和提升后端存储的读写力。
4、高并发
由于目前大部分使用HBase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,HBase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5、稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
(三)HBase架构
HBase架构如图所示。
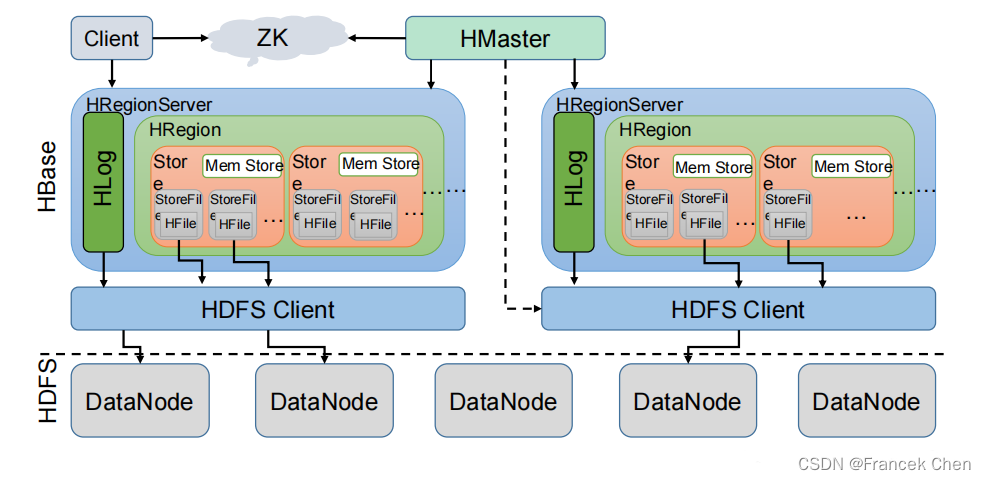
从图中可以看出 HBase 是由 Client、Zookeeper、Master、HRegionServer、HDFS 等几个组件组成,下面来介绍一下几个组件的相关功能:
1、Client
Client 包含了访问 HBase 的接口,另外 Client 还维护了对应的 cache 来加速 HBase 的访问,比如 cache 的.META.元数据的信息。
2、Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
(1)通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务。
(2)通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回调的形式通知 Master RegionServer 上下线的信息。
(3)通过 Zoopkeeper 存储元数据的统一入口地址。
3、Hmaster
master 节点的主要职责如下:
为 RegionServer 分配 Region
维护整个集群的负载均衡
维护集群的元数据信息
发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上
当 RegionSever 失效的时候,协调对应 Hlog 的拆分
4、HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理 master 为其分配的 Region
处理来自客户端的读写请求
负责和底层 HDFS 的交互,存储数据到 HDFS
负责 Region 变大以后的拆分
负责 Storefile 的合并工作
5、HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务
数据多副本,保证的高可靠和高可用性
二、HBase原理
(一)读流程

1、Client 先访问 zookeeper,从 meta 表读取 region 的位置,然后读取 meta 表中的数据。meta 中又存储了用户表的 region 信息;
2、根据 namespace、表名和 rowkey 在 meta 表中找到对应的 region 信息;
3、找到这个 region 对应的 regionserver;
4、查找对应的 region;
5、先从 MemStore 找数据,如果没有,再到 BlockCache 里面读;
6、BlockCache 还没有,再到 StoreFile 上读(为了读取的效率);
7、如果是从 StoreFile 里面读取的数据,不是直接返回给客户端,而是先写入 BlockCache,再返回给客户端。
(二)写流程
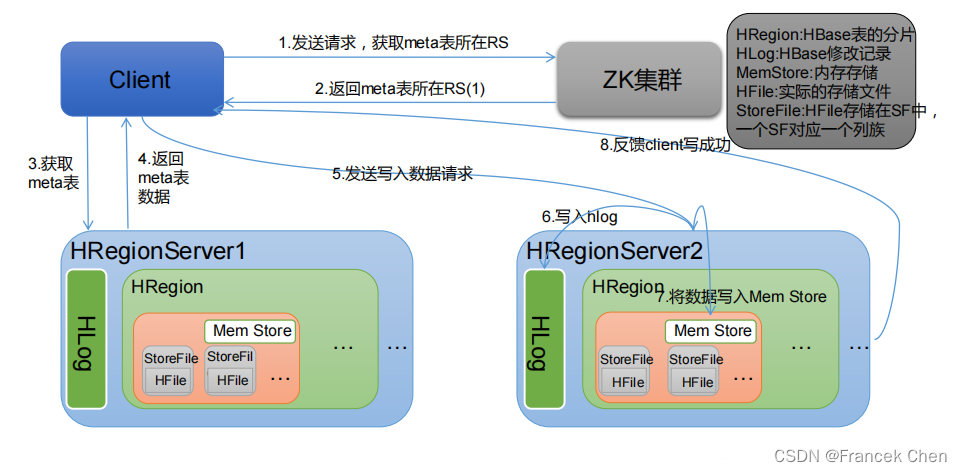
1、Client 向 HregionServer 发送写请求;
2、HregionServer 将数据写到 HLog(write ahead log)。为了数据的持久化和恢复;
3、HregionServer 将数据写到内存(MemStore);
4、反馈 Client 写成功。
(三)数据 flush 过程
1、当 MemStore 数据达到阈值(默认是 128M,老版本是 64M),将数据刷到硬盘,将内存中的数据删除,同时删除 HLog 中的历史数据;
2、并将数据存储到 HDFS 中;
3、在 HLog 中做标记点。
(四)数据合并过程
1、当数据块达到 4 块,Hmaster 触发合并操作,Region 将数据块加载到本地,进行合并;
2、当合并的数据超过 256M,进行拆分,将拆分后的 Region 分配给不同的 HregionServer 管理; 3、当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4、注意:HLog 会同步到 HDFS。
三、HBase安装与配置
(一)解压并安装HBase
首先,到HBase官网将HBase安装包下载到 /usr/local/uploads 目录下,再切换到该目录下解压安装到 /usr/local/servers 目录下。
Apache HBase – Apache HBase Downloads![]() https://hbase.apache.org/downloads.html
https://hbase.apache.org/downloads.html
[root@bigdata zhc]# cd /usr/local/uploads
[root@bigdata uploads]# tar -zxvf hbase-2.4.14-bin.tar.gz -C /usr/local/servers
[root@bigdata uploads]# cd ../servers
[root@bigdata servers]# mv hbase-2.4.14/ hbase
这些就是HBase包含的文件:

(二)配置HBase

1、修改环境变量hbase-env.sh
[root@bigdata conf]# vi hbase-env.sh在文件开头加入如下内容:
export JAVA_HOME=/usr/local/servers/jdk
export HBASE_CLASSPATH=/usr/local/servers/hbase/conf
export HBASE_MANAGES_ZK=true指定了jdk路径和HBase路径。

注意:另外,定位到(HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true")这一行。还要将如下图所示红框标出的那一行前面的“#”删掉,防止后面启动HBase日志冲突。

2、修改配置文件hbase-site.xml
[root@bigdata conf]# vi hbase-site.xml在两个<configuration>标签之间加入如下内容:
<property><name>hbase.rootdir</name><value>hdfs://localhost:9000/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/servers/zookeeper/data</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
3、设置环境变量,编辑系统配置文件/etc/profile。
[root@bigdata conf]# vi /etc/profile
[root@bigdata conf]# source /etc/profile #使文件生效将下面代码加到文件末尾。
export HBASE_HOME=/usr/local/servers/hbase
export PATH=$PATH:$HBASE_HOME/bin
export CLASSPATH=$CLASSPATH:$HBASE_HOME/lib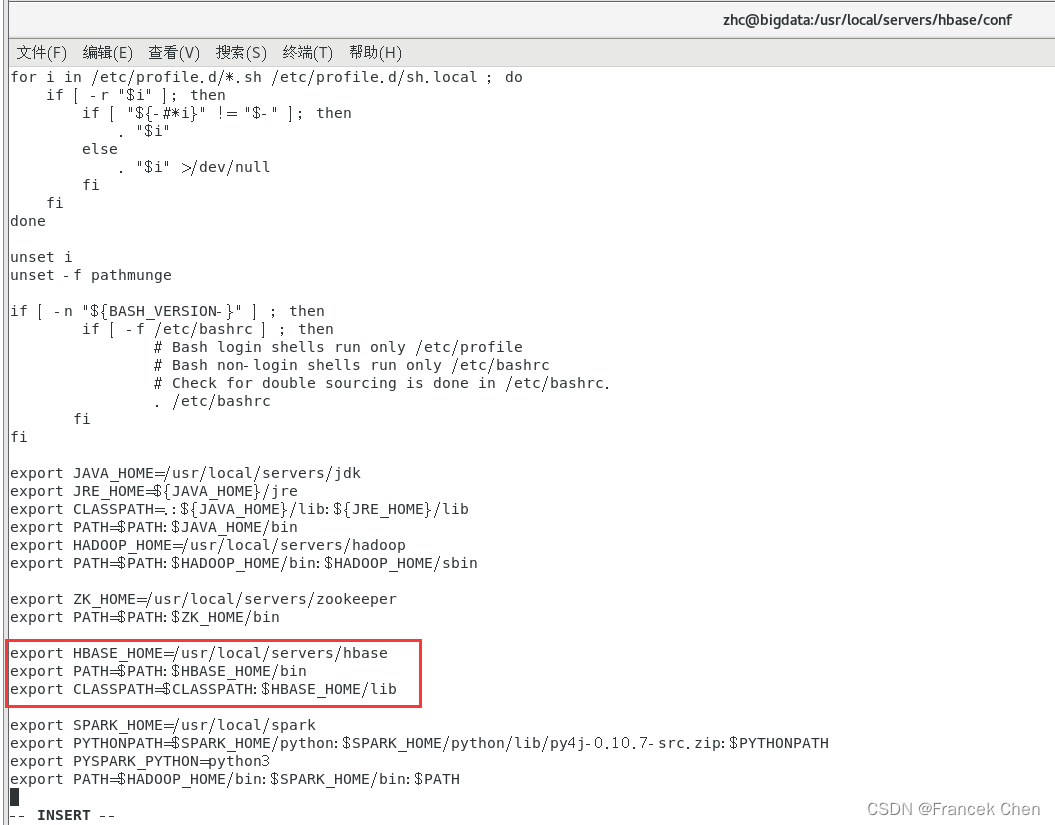
4、启动并验证HBase
由于HBase是基于Hadoop的,所以要先启动Hadoop。
[root@bigdata conf]# start-dfs.sh
[root@bigdata conf]# start-hbase.sh
这便是有无日志冲突的区别!(下图是有日志冲突的)
所以务必要将 HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" 这一行前的“#”删除!

由此可以发现,多了HRegionServer、HQuorumPeer、HMaster 三个进程。
进入HBase-shell,并输入“version”查看当前HBase版本。
[root@bigdata hbase]# hbase shell
hbase:001:0> version

(三)配置Spark
配置Spark的目的是为了以后可以通过pypark向HBase中读取和写入数据。
把HBase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程时需要引入的jar包,需要拷贝的jar文件包括:所有hbase开头的jar文件、guava-11.0.2.jar和protobuf-java-2.5.0.jar。
执行如下命令:
[root@bigdata hbase]# cd /usr/local/spark/jars
[root@bigdata jars]# mkdir hbase
[root@bigdata jars]# cd hbase
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/hbase*.jar ./
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/guava-11.0.2.jar ./
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/protobuf-java-2.5.0.jar ./
htrace-core-3.1.0-incubating.jar 下载地址:
https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar![]() https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar
https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar
[root@bigdata hbase]# cp /usr/local/uploads/htrace-core-3.1.0-incubating.jar ./此外,在Spark 2.0以上版本中,缺少把HBase数据转换成Python可读取数据的jar包,需要另行下载。可以访问下面地址下载spark-examples_2.11-1.6.0-typesafe-001.jar:
https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001![]() https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001
https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001
[root@bigdata hbase]# cp /usr/local/uploads/spark-examples_2.11-1.6.0-typesafe-001.jar ./拷贝完成后,/usr/local/spark/jars/hbase 目录下的 jar 包如下图所示;

然后,使用vim编辑器打开spark-env.sh文件,设置Spark的spark-env.sh文件,告诉Spark可以在哪个路径下找到HBase相关的jar文件,命令如下:
[root@bigdata hbase]# cd /usr/local/spark/conf
[root@bigdata conf]# vi spark-env.sh打开spark-env.sh文件以后,可以在文件最前面增加下面一行内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/servers/hadoop/bin/hadoop classpath):$(/usr/local/servers/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*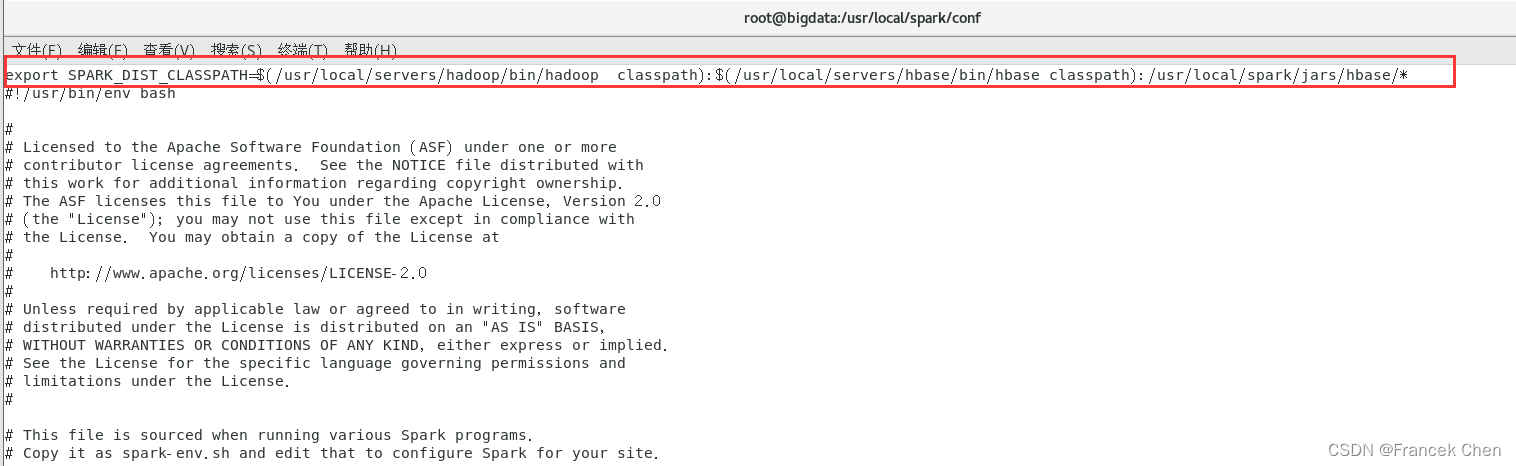
这样,后面编译和运行过程才不会出错。
四、HBase的使用
(一)进入HBase shell
[root@bigdata conf]# cd /usr/local/servers/hbase
[root@bigdata hbase]# hbase shell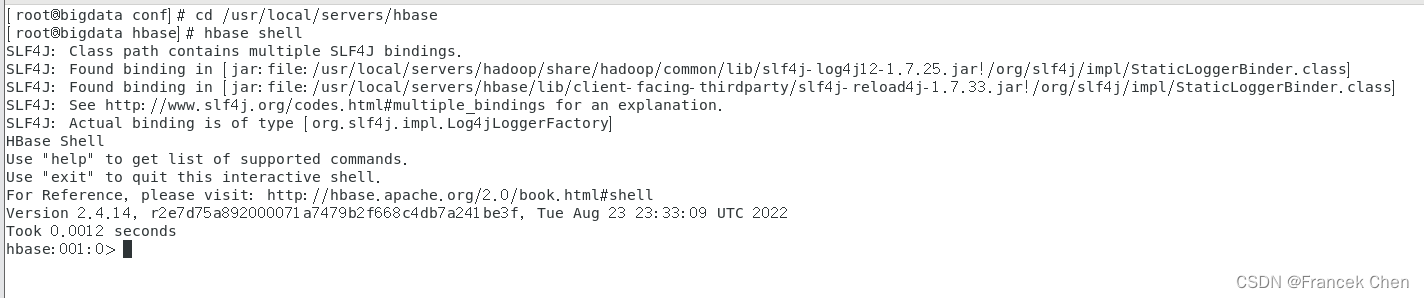
(二)表的管理
1、列举表
命令如下:
hbase(main)> list2、创建表
语法格式:create <table>,{NAME => <family>,VERSIONS => <VERSIONS>}
例如,创建表t1,有两个family name:f1、f2,且版本数均为2,
命令如下:
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}3、删除表
删除表分两步:首先使用disable 禁用表,然后再用drop命令删除表。
例如,删除表t1操作如下:
hbase(main)> disable 't1'
hbase(main)> drop 't1'4、查看表的结构
语法格式:describe <table>
例如,查看表t1的结构,命令如下:
hbase(main)> describe 't1'5、修改表的结构
修改表结构必须用disable禁用表,才能修改。
语法格式:alter 't1',{NAME => 'f1'},{NAME => 'f2',METHOD => 'delete'}
例如,修改表test1的cf的TTL为180天,命令如下:
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'6、权限管理
① 分配权限
语法格式:grant <user> <permissions> <table> <column family> <column qualifier>
说明:参数后面用逗号分隔。
权限用“RWXCA”五个字母表示,其对应关系为:
READ('R')、WRITE('W')、EXEC('X')、CREATE('C')、ADMIN('A')。
例如,为用户‘test’分配对表t1有读写的权限,命令如下:
hbase(main)> grant 'test','RW','t1'② 查看权限
语法格式:user_permission <table>
例如,查看表t1的权限列表,命令如下:
hbase(main)> user_permission 't1'③ 收回权限
与分配权限类似,语法格式:revoke <user> <table> <column family> <column qualifier>
例如,收回test用户在表t1上的权限,命令如下:
hbase(main)> revoke 'test','t1'(三)表数据的增删改查
1、添加数据
语法格式:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
例如,给表t1的添加一行记录,其中,rowkey是rowkey001,family name是f1,column name是col1,value是value01,timestamp为系统默认。则命令如下:
hbase(main)> put 't1','rowkey001','f1:col1','value01'2、查询数据
① 查询某行记录
语法格式:get <table>,<rowkey>,[<family:column>,....]
例如,查询表t1,rowkey001中的f1下的col1的值,命令如下:
hbase(main)> get 't1','rowkey001', 'f1:col1'或者用如下命令:
hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}查询表t1,rowke002中的f1下的所有列值,命令如下:
hbase(main)> get 't1','rowkey001'② 扫描表
语法格式:scan <table>,{COLUMNS => [ <family:column>,.... ],LIMIT => num}
另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能。
例如,扫描表t1的前5条数据,命令如下:
hbase(main)> scan 't1',{LIMIT=>5}③ 查询表中的数据行数
语法格式:count <table>,{INTERVAL => intervalNum,CACHE => cacheNum}
其中,INTERVAL设置多少行显示一次及对应的rowkey,默认为1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度。
例如,查询表t1中的行数,每100条显示一次,缓存区为500,命令如下:
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}3、删除数据
① 删除行中的某个值
语法格式:delete <table>,<rowkey>,<family:column>,<timestamp>
这里必须指定列名。
例如,删除表t1,rowkey001中的f1:col1的数据,命令如下:
hbase(main)> delete 't1','rowkey001','f1:col1' ② 删除行
语法格式:deleteall <table>,<rowkey>,<family:column>,<timestamp>
这里可以不指定列名,也可删除整行数据。
例如,删除表t1,rowk001的数据,命令如下:
hbase(main)> deleteall 't1','rowkey001'③ 删除表中的所有数据
语法格式:truncate <table>
其具体过程是:disable table -> drop table -> create table
例如,删除表t1的所有数据,命令如下:
hbase(main)> truncate 't1'最后友情提醒:使用完HBase和Hadoop后,要先关闭HBase,再关闭Hadoop!









:贝尔曼-福特算法、狄克斯特拉算法和A*算法)


)






)