在 Spring Boot 项目中,数据库连接池已经成为标配,然而,我曾经遇到过不少连接池异常导致业务错误的事故。很多经验丰富的工程师也可能不小心在这方面出现问题。
在这篇文章中,我们将探讨数据库连接池,深入解析其实现机制,以便更好地理解和规避潜在的风险。
1 为什么需要连接池
假如没有连接池,我们操作数据库的流程如下:
- 应用程序使用数据库驱动建立和数据库的 TCP 连接 ;
- 用户进行身份验证 ;
- 身份验证通过,应用进行读写数据库操作 ;
- 操作结束后,关闭 TCP 连接 。
创建数据库连接是一个比较昂贵的操作,若同时有几百人甚至几千人在线,频繁地进行连接操作将占用更多的系统资源,但数据库支持的连接数是有限的,创建大量的连接可能会导致数据库僵死。
当我们有了连接池,应用程序启动时就预先建立多个数据库连接对象,然后将连接对象保存到连接池中。当客户请求到来时,从池中取出一个连接对象为客户服务。当请求完成时,客户程序调用关闭方法,将连接对象放回池中。

相比之下,连接池的优点显而易见:
1、资源重用:
因为数据库连接可以重用,避免了频繁创建,释放连接引起的大量性能开销,同时也增加了系统运行环境的平稳性。
2、提高性能
当业务请求时,因为数据库连接在初始化时已经被创建,可以立即使用,而不需要等待连接的建立,减少了响应时间。
3、优化资源分配
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源。
4、连接管理
数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
2 JDBC 连接池
下面的代码展示了 JDBC 操作数据库的流程 :
//1. 连接到数据库
Connection connection = DriverManager.getConnection(jdbcUrl, username, password);
//2. 执行SQL查询
String sqlQuery = "SELECT * FROM mytable WHERE column1 = ?";
PreparedStatement preparedStatement = connection.prepareStatement(sqlQuery);
preparedStatement.setString(1, "somevalue");
resultSet = preparedStatement.executeQuery();
//3. 处理查询结果
while (resultSet.next()) {int column1Value = resultSet.getInt("column1");String column2Value = resultSet.getString("column2");System.out.println("Column1: " + column1Value + ", Column2: " + column2Value);
}
//4. 关闭资源
resultSet.close();
preparedStatement.close();
connection.close();
上面的方式会频繁的创建数据库连接,在比较久远的 JSP 页面中会偶尔使用,现在普遍使用 JDBC 连接池。
JDBC 连接池有一个标准的数据源接口javax.sql.DataSource,这个类位于 Java 标准库中。
public interface DataSource extends CommonDataSource, Wrapper {Connection getConnection() throws SQLException;Connection getConnection(String username, String password) throws SQLException;
}
常用的 JDBC 连接池有:
- HikariCP
- C3P0
- Druid
Druid(阿里巴巴数据库连接池)是一个开源的数据库连接池库,它提供了强大的数据库连接池管理和监控功能。
1、配置Druid数据源
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/mydatabase");
dataSource.setUsername("yourusername");
dataSource.setPassword("yourpassword");
dataSource.setInitialSize(5); // 初始连接池大小
dataSource.setMinIdle(5); // 最小空闲连接数
dataSource.setMaxActive(20); // 最大活动连接数
dataSource.setValidationQuery("select 1 from dual"); // 心跳的 Query
dataSource.setMaxWait(60000); // 最大等待时间
dataSource.setTestOnBorrow(true); // 验证连接是否有效
2、使用数据库连接
Connection connection = dataSource.getConnection();
//使用连接执行数据库操作
// TODO 业务操作
// 使用后关闭连接连接
connection.close();
3、关闭数据源
dataSource.close();
3 连接池 Druid 实现原理
我们学习数据源的实现,可以从如下五个核心角度分析:
- 初始化
- 创建连接
- 回收连接
- 归还连接
- 销毁连接
3.1 初始化
首先我们查看数据源实现「获取连接」的接口截图,初始化可以主动和被动两种方式。
主从是指显示的调用 init 方法,而被动是指获取连接时完成初始化。

调用
getConnection方法时,返回的对象是连接接口的封装类DruidConnectionHolder。
在初始化方法内,数据源创建三个连接池数组 。
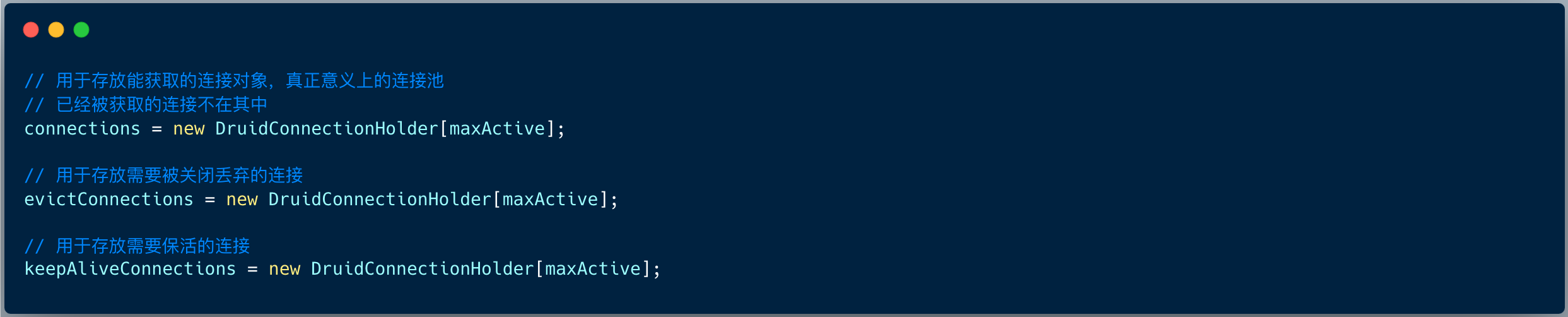
-
connections:用于存放能获取的连接对象。
-
evictConnections:用于存放需要丢弃的连接对象。
-
keepAliveConnections:用于存放需要保活的连接对象。
初始化阶段,需要进行连接池的「预热」:也就是需要按照配置首先创建一定数量的连接,并放入到池子里,这样应用在需要获取连接的候,可以直接从池子里获取。
数据源「预热」分为同步和异步两种方式 ,见下图:

从上图,我们可以看到同步创建连接时,是原生 JDBC 创建连接后,直接放入到 connections 数组对象里。
异步创建线程需要初始化 createScheduler , 但默认并没有配置。
数据源预热之后,启动了两个任务线程:创建连接和销毁连接。
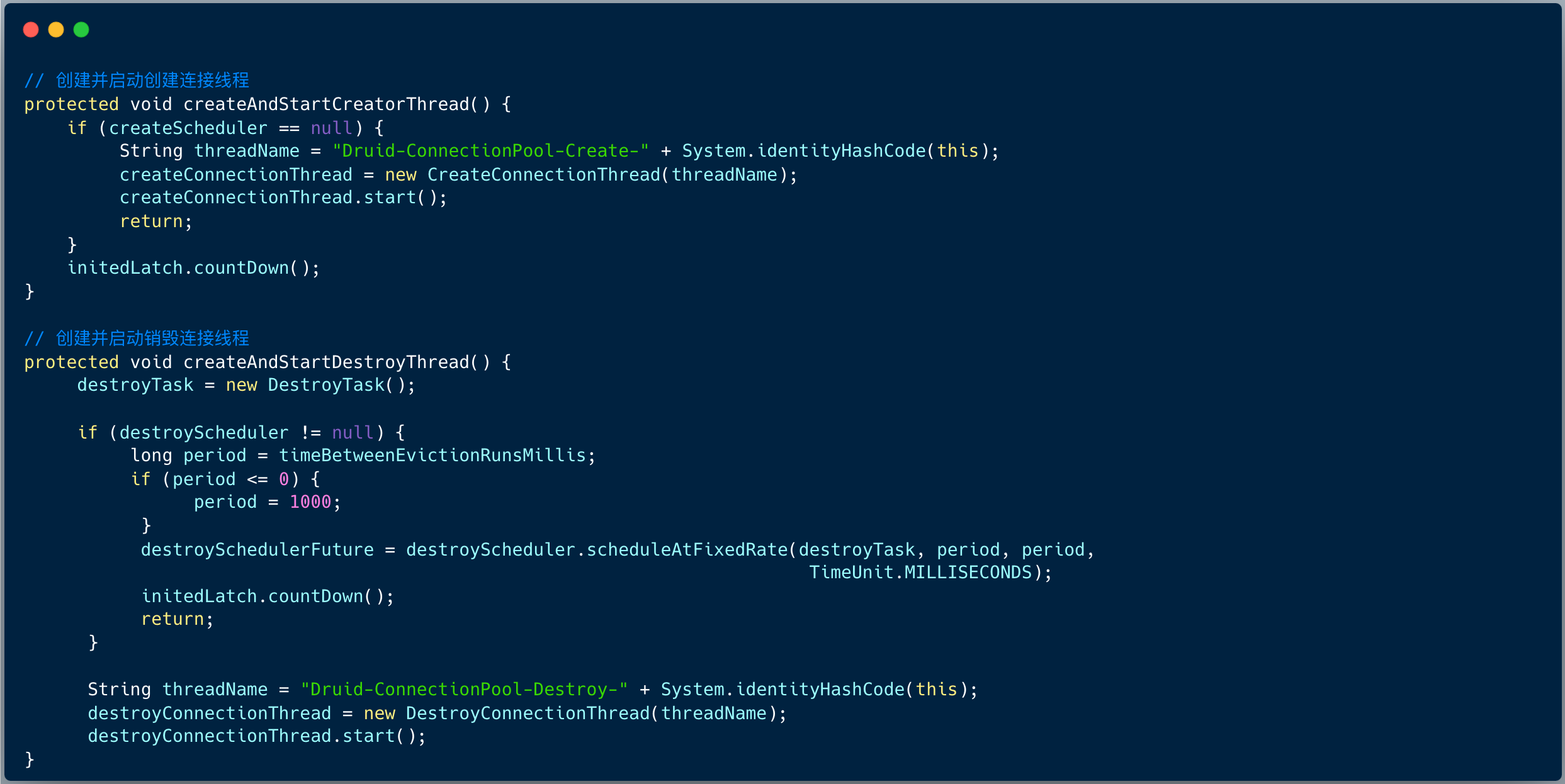
3.2 创建连接
这一节,我们重点学习 Druid 数据源如何创建连接。
CreateConnectionThread 本质是一个单线程在死循环中通过 condition 等待,被其他线程唤醒 ,并实现创建数据库连接逻辑。

笔者将 run 方法做了适当简化,当满足了条件之后,才创建数据库连接 :
- 必须存在线程等待,才创建连接
- 防止创建超过最大连接数 maxAcitve
创建完连接对象 PhysicalConnectionInfo 之后,需要保存到 Connections 数组里,并唤醒到其他的线程,这样就可以从池子里获取连接。

3.3 获取连接
我们详细解析了创建连接的过程,接下来就是应用如何获取连接的过程。
DruidDataSource#getConnection 方法会调用到 DruidDataSource#getConnectionDirect 方法来获取连接,实现如下所示。
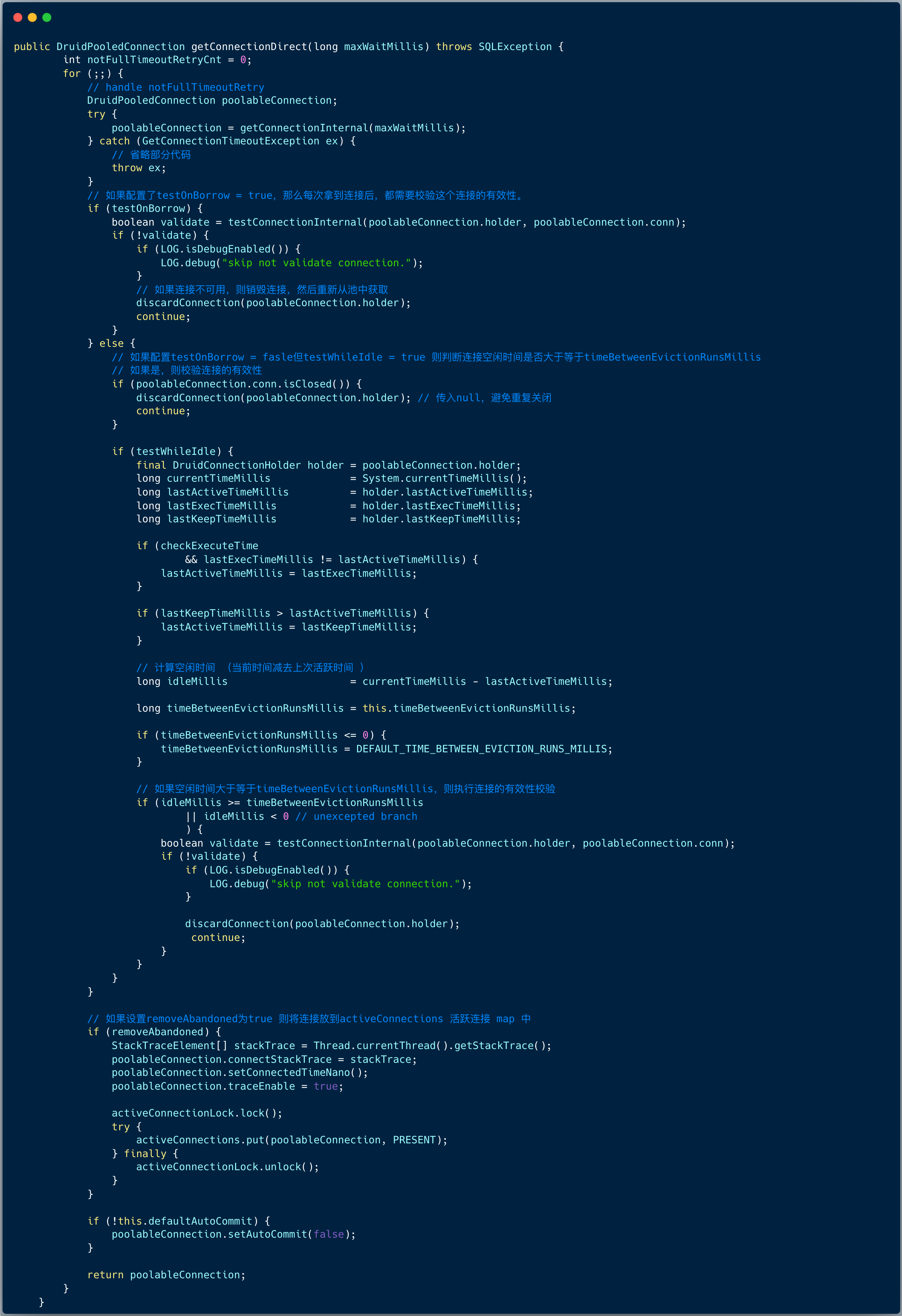
核心流程是
1、在 for 循环内,首先调用 getConnectionDirect内,调用getConnectionInternal 从池子里获取连接对象;
2、获取连接后,需要根据 testOnBorrow 、testWhileIdle 参数配置判断是否需要检测连接的有效性;
3、最后假如需要判断连接是否有泄露,则配置 removeAbandoned 来关闭长时间不适用的连接,该功能不建议再生产环境中使用,仅用于连接泄露检测诊断。
接下来进入获取连接的重点:getConnectionInternal 方法如何从池子里获取连接。

getConnectionInternal()方法中拿到连接的方式有三种:
-
直接创建连接(默认配置不会执行)
需要配置定时线程池
createScheduler,当连接池已经没有可用连接,且当前借出的连接数未达到允许的最大连接数,且当前没有其它线程在创建连接 ; -
pollLast 方法:从池中拿连接,并最多等待 maxWait 的时间,需要设置了maxWait;

pollLast 方法的核心是:死循环内部,通过 Condition 对象 notEmpty 的 awaitNanos 方法执行等待,若池子中有连接,将最后一个连接取出,并将最后一个数组元素置为空。
- takeLast 方法:从池中拿连接,并一直等待直到拿到连接。
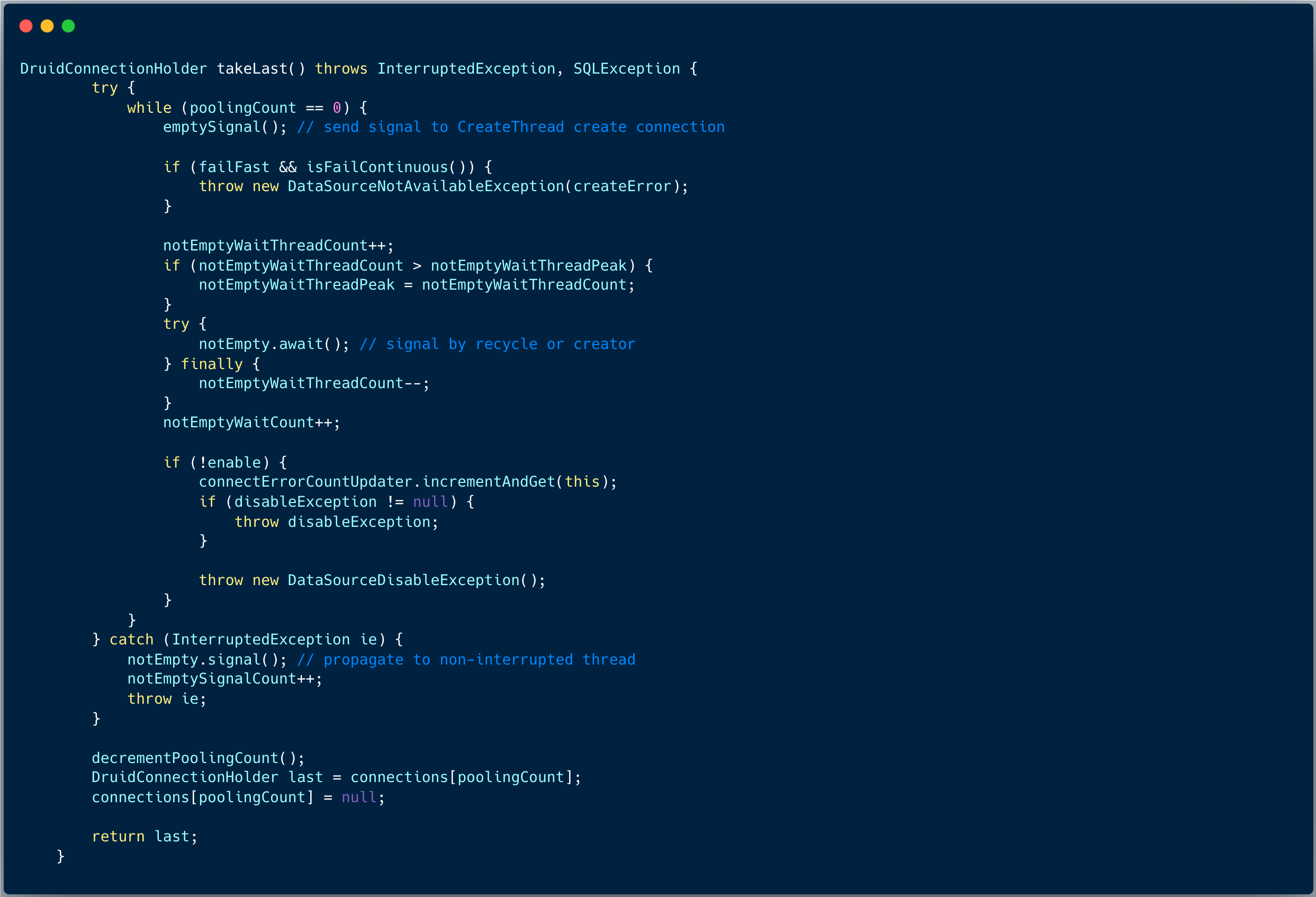
和 pollLast 方法不同,首先方法体内部并没有死循环,通过 Condition 对象 notEmpty 的 await 方法等待,直到池子中有连接,将最后一个连接取出,并将最后一个数组元素置为空。
3.4 归还连接
DruidDataSource 连接池中,每一个物理连接都会被包装成DruidConnectionHolder,在提供给应用线程前,还会将 DruidConnectionHolder 包装成 DruidPooledConnection。

原生的 JDBC 操作, 每次执行完业务操作之后,会执行关闭连接,对于连接池来讲,就是归还连接,也就是将连接放回连接池。
下图展示了 DruidPooledConnection 的 close 方法 :

在关闭方法中,我们重点关注 recycle 回收连接方法。

我们可以简单的理解:将连接放到 connections 数组的 poolingCount 位置,并将其自增,然后通过 Condition 对象 notEmpty 唤醒等待获取连接的一个应用程序。
3.5 销毁连接
DruidDataSource连接的销毁 DestroyConnectionThread 线程完成 :

从定时任务(死循环)每隔 timeBetweenEvictionRunsMillis 执行一次,我们重点关注destroyTask的run方法。

destroyTask的run方法 会调用DruidDataSource#shrink方法来根据设定的条件来判断出需要销毁和保活的连接。

核心流程:
1、遍历连接池数组 connections:
内部分别判断这些连接是需要销毁还是需要保活 ,并分别加入到对应的容器数组里。
2、销毁场景:
- 空闲时间
idleMillis>= 允许的最小空闲时间minEvictableIdleTimeMillis - 空闲时间
idleMillis>= 允许的最大空闲时间maxEvictableIdleTimeMillis
3、保活场景:
- 发生了致命错误(onFatalError == true)且致命错误发生时间(
lastFatalErrorTimeMillis)在连接建立时间之后 - 如果开启了保活机制,且连接空闲时间大于等于了保活间隔时间
4、销毁连接:
遍历数组 evictConnections 所有的连接,并逐一销毁 。
5、保活连接:
遍历数组 keepAliveConnections 所有的连接,对连接进行验证 ,验证失败,则关闭连接,否则加锁,重新加入到连接池中。
4 保证连接有效
本节,我们讲解如何合理的配置参数保证数据库连接有效。
很多同学都会遇到一个问题:“长时间不进行数据库读写操作之后,第一次请求数据库,数据库会报错,但第二次就正常了。"
那是因为数据库为了节省资源,会关闭掉长期没有读写的连接。
笔者第一次使用 Druid 时就遇到过这样的问题,有兴趣的同学可以看看笔者这篇文章:
追源码的平凡之路 | 勇哥Java实战
下图展示了 Druid 数据源配置样例:

我们简单梳理下 Druid 的保证连接有效有哪些策略:
1、销毁连接线程定时检测所有的连接,关闭空闲时间过大的连接 ,假如配置了保活参数,那么会继续维护待保活的连接;
2、应用每次从数据源中获取连接时候,会根据testOnBorrow、testWhileIdle参数检测连接的有效性。
因此,我们需要重点配置如下的参数:
A、timeBetweenEvictionRunsMillis 参数:间隔多久检测一次空闲连接是否有效。
B、testWhileIdle 参数:启空闲连接的检测,强烈建议设置为 true 。
C、minEvictableIdleTimeMillis 参数:连接池中连接最大空闲时间(毫秒),连接数 > minIdle && 空闲时间 > minEvictableIdleTimeMillis 。
D、maxEvictableIdleTimeMillis 参数:连接池中连接最大空闲时间,空闲时间 > maxEvictableIdleTimeMillis,不管连接池中的连接数是否小于最小连接数 。
E、testOnBorrow 参数:开启连接的检测,获取连接时检测是否有效,假如设置为 true ,可以最大程度的保证连接的可靠性,但性能会变很差 。




——raid5与btrfs文件系统无损原数据扩容)
)













频率脉冲信号转换器)